


Comparison of Convolutional Neural Networks and Transformers for the Classification of Images of COVID-19, Pneumonia and Healthy Individuals as Observed with Computed Tomography



Abstract
:1. Introduction
- A well-structured experimental setup for the evaluation and unbiased comparison of the performance of five representative deep learning architectures (CaiT-24-XXS-224, DesNet-121, MobileNet-v3-large, ResNet-50 and ResNet-50r) for the classification of COVID-19 as observed with Computed Tomography was proposed.
- The ResNet-50r architecture, which is based on ResNet-50 but the convolutional layer (Conv1) with filters of size , was used to observe the effect of the kernels size (filters) on the classification of COVID-19.
- Bootstrapping technique was applied to derive a very large number of samples, which will compensate for any cases of outliers for non-normal distributed data.
- The results of each deep network architecture and experiment with different optimisers and loss functions were compared using non-parametric statistical comparison of the performance of deep network architectures.
- The results show that less resource-demanding networks can outperform more complex architectures. This is a significant consideration related to the energy consumption necessary to train deep learning architectures in the light of the current climate emergency, and given the climate emergency of the present world [57,58,59].
2. Materials and Methods
2.1. Data Collection
2.2. Deep Learning Architectures
2.3. Experimental Setup
2.4. Training and Validation
2.5. Performance Metrics for Evaluation
2.6. Statistical Comparison
3. Results and Discussion
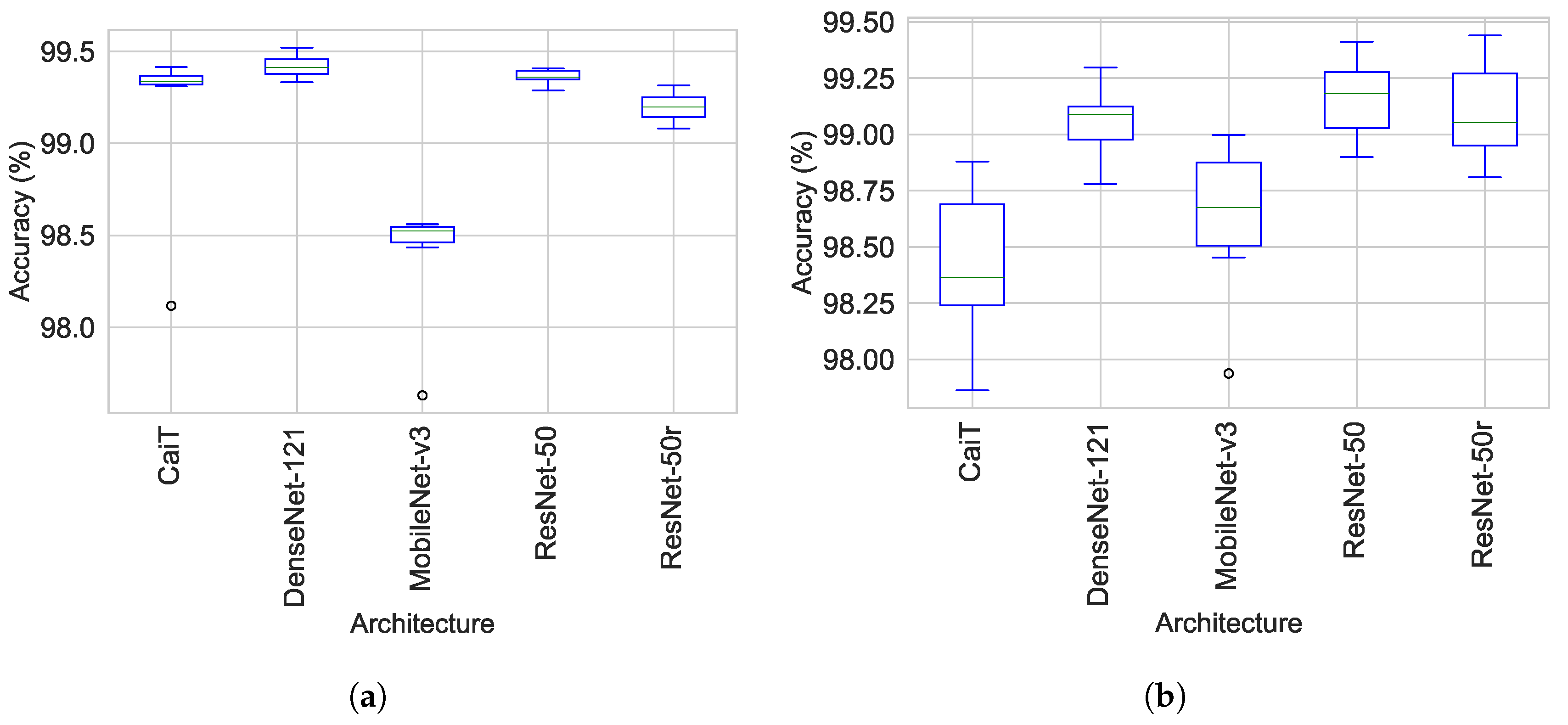
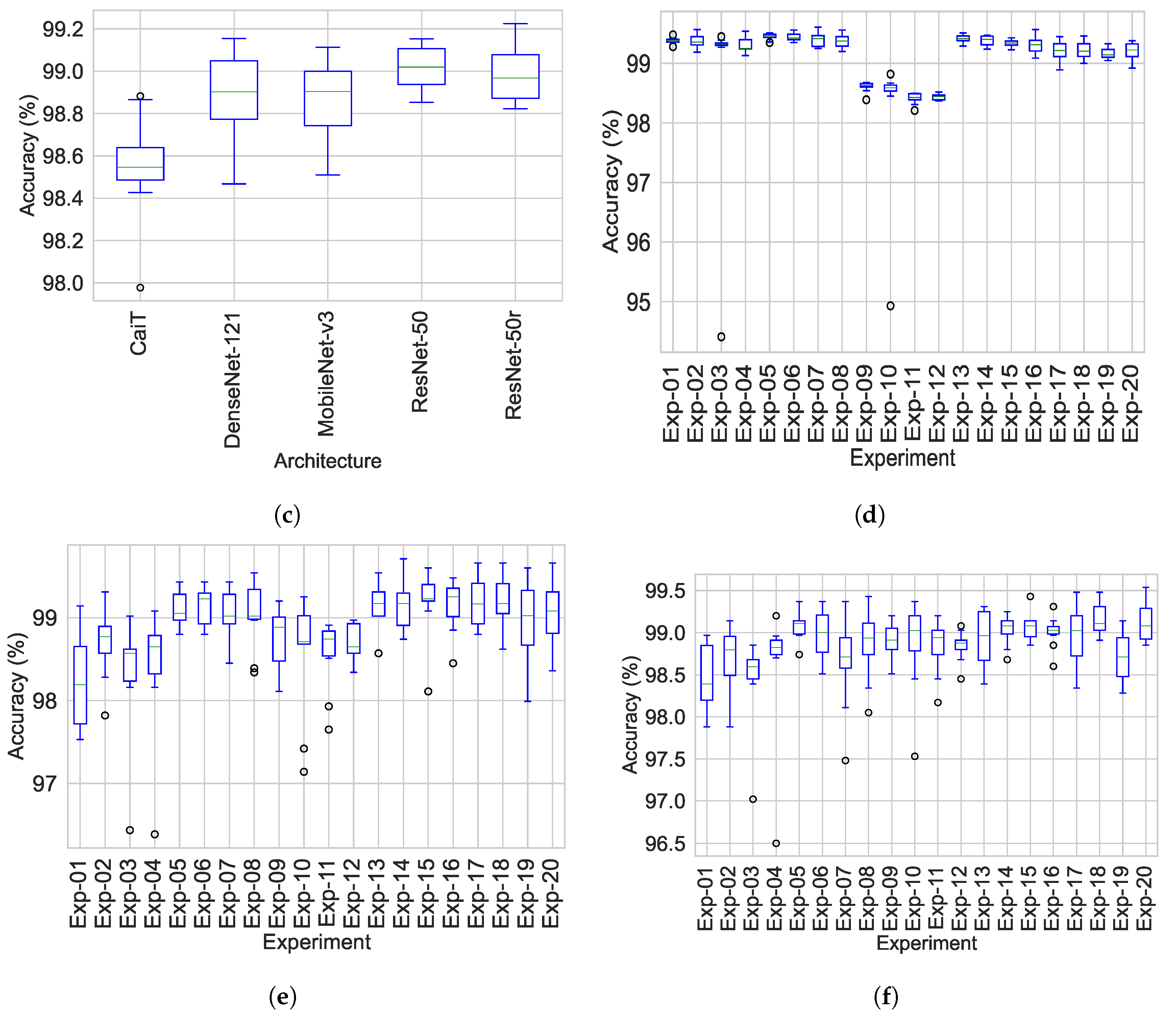
3.1. Training, Test and Validation Accuracy
3.2. Performance Metrics Prior to Bootstrapping
3.3. Ranking and Confidence Intervals Post-Bootstrapping
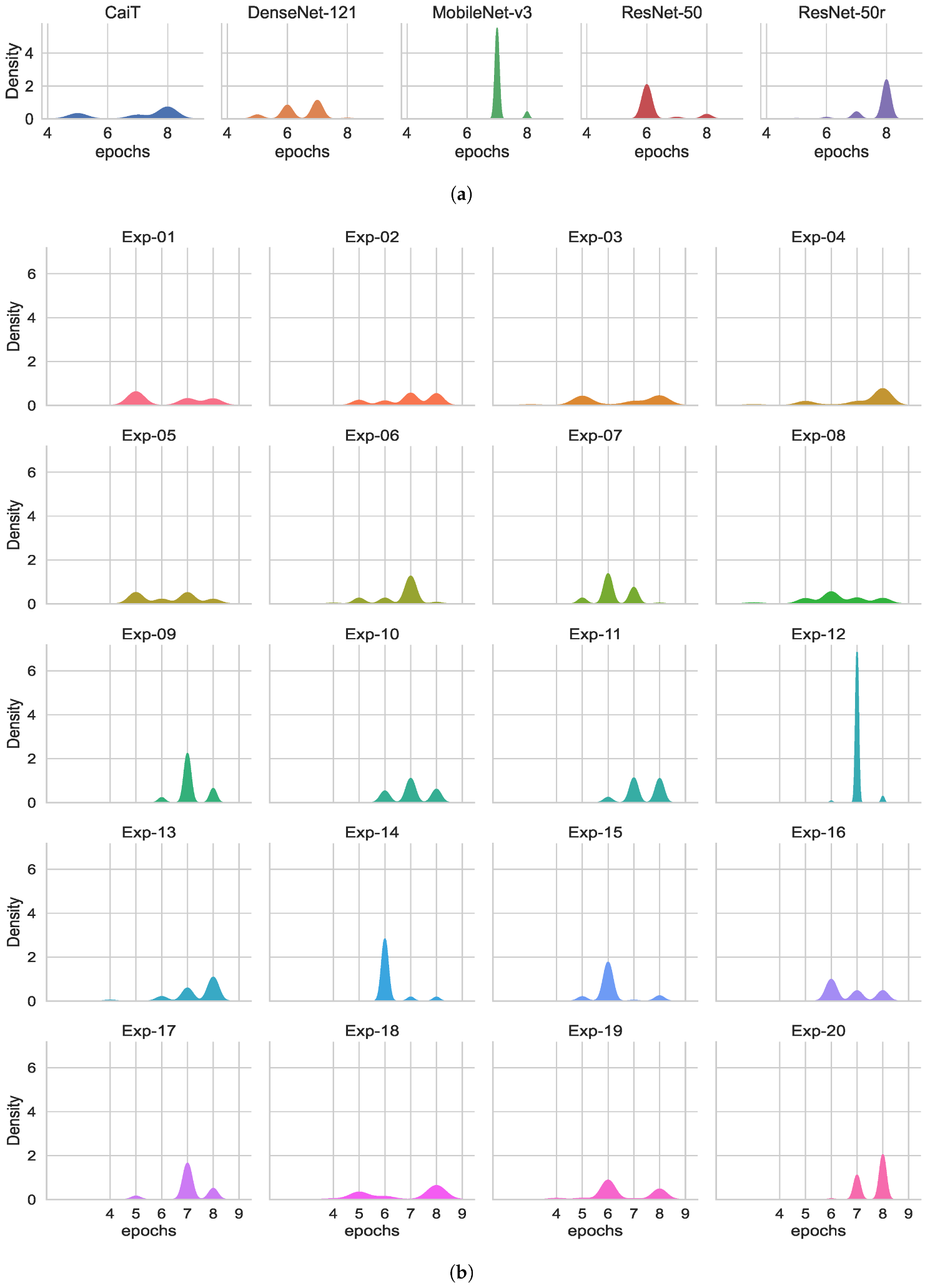
3.4. Maximum Training Epochs
3.5. Non-Parametric Ranks Comparisons
3.6. Limitations of the Present Work
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Acc | Accuracy |
| ATTE | Average training time per epoch |
| BA | Balanced accuracy |
| CAP | Community acquired pneumonia |
| CE | Cross entropy |
| CT | Computed tomography |
| MCC | Mathew’s correlation coefficient |
| Sens | Sensitivity |
| Spec | Specificity |
| Val | Validation |
| wCE | Weighted cross entropy |
References
- Coronaviridae Study Group of the International Committee on Taxonomy of Viruses. The species Severe acute respiratory syndrome-related coronavirus: Classifying 2019-nCoV and naming it SARS-CoV-2. Nat. Microbiol. 2020, 5, 536–544. [Google Scholar] [CrossRef] [PubMed]
- Fatoye, F.; Gebrye, T.; Arije, O.; Fatoye, C.T.; Onigbinde, O.; Mbada, C.E. Economic Impact of COVID-19 lockdown on households. Pan Afr. Med. J. 2021, 40, 225. [Google Scholar] [CrossRef]
- Güner, O.; Öztürk, R. Psychological and social impact and lifestyle changes among pregnant women of COVID-19 pandemic: A qualitative study. Arch. Psychiatr. Nurs. 2022, 36, 70–77. [Google Scholar] [CrossRef] [PubMed]
- Kanji, J.N.; Zelyas, N.; MacDonald, C.; Pabbaraju, K.; Khan, M.N.; Prasad, A.; Hu, J.; Diggle, M.; Berenger, B.M.; Tipples, G. False negative rate of COVID-19 PCR testing: A discordant testing analysis. Virol. J. 2021, 18, 13. [Google Scholar] [CrossRef] [PubMed]
- Kortela, E.; Kirjavainen, V.; Ahava, M.J.; Jokiranta, S.T.; But, A.; Lindahl, A.; Jääskeläinen, A.E.; Jääskeläinen, A.J.; Järvinen, A.; Jokela, P.; et al. Real-life clinical sensitivity of SARS-CoV-2 RT-PCR test in symptomatic patients. PLoS ONE 2021, 16, e0251661. [Google Scholar]
- Li, W.; Deng, X.; Shao, H.; Wang, X. Deep Learning Applications for COVID-19 Analysis: A State-of-the-Art Survey. Comput. Model. Eng. Sci. 2021, 129, 65. [Google Scholar] [CrossRef]
- Pokhrel, P.; Hu, C.; Mao, H. Detecting the Coronavirus (COVID-19). ACS Sens. 2020, 5, 2283–2296. [Google Scholar] [CrossRef]
- Xie, X.; Zhong, Z.; Zhao, W.; Zheng, C.; Wang, F.; Liu, J. Chest CT for Typical Coronavirus Disease 2019 (COVID-19) Pneumonia: Relationship to Negative RT-PCR Testing. Radiology 2020, 296, E41–E45. [Google Scholar] [CrossRef]
- Litmanovich, D.E.; Chung, M.; Kirkbride, R.R.; Kicska, G.; Kanne, J.P. Review of Chest Radiograph Findings of COVID-19 Pneumonia and Suggested Reporting Language. J. Thorac. Imaging 2020, 35, 354–360. [Google Scholar] [CrossRef]
- Axiaq, A.; Almohtadi, A.; Massias, S.A.; Ngemoh, D.; Harky, A. The role of computed tomography scan in the diagnosis of COVID-19 pneumonia. Curr. Opin. Pulm. Med. 2021, 27, 163–168. [Google Scholar] [CrossRef]
- Muhammad, U.; Hoque, M.Z.; Oussalah, M.; Keskinarkaus, A.; Seppänen, T.; Sarder, P. SAM: Self-augmentation mechanism for COVID-19 detection using chest X-ray images. Knowl.-Based Syst. 2022, 241, 108207. [Google Scholar] [CrossRef]
- Bernheim, A.; Mei, X.; Huang, M.; Yang, Y.; Fayad, Z.A.; Zhang, N.; Diao, I.; Lin, B.; Zhu, X.; Li, K.; et al. Chest CT Findings in Coronavirus Disease-19 (COVID-19): Relationship to Duration of Infection. Radiology 2020, 295, 200463. [Google Scholar] [CrossRef]
- Carotti, M.; Salaffi, F.; Sarzi-Puttini, P.; Agostini, A.; Borgheresi, A.; Minorati, D.; Galli, M.; Marotto, D.; Giovagnoni, A. Chest CT features of coronavirus disease 2019 (COVID-19) pneumonia: Key points for radiologists. Radiol. Med. 2020, 125, 636–646. [Google Scholar] [CrossRef]
- Grassi, R.; Fusco, R.; Belfiore, M.P.; Montanelli, A.; Patelli, G.; Urraro, F.; Petrillo, A.; Granata, V.; Sacco, P.; Mazzei, M.A.; et al. Coronavirus disease 2019 (COVID-19) in Italy: Features on chest computed tomography using a structured report system. Sci. Rep. 2020, 10, 17236. [Google Scholar] [CrossRef]
- Zuo, H. Contribution of CT Features in the Diagnosis of COVID-19. Can. Respir. J. 2020, 2020, e1237418. [Google Scholar] [CrossRef]
- Aleksander, I.; Thomas, W.; Bowden, P. WISARD·a radical step forward in image recognition. Sens. Rev. 1984, 4, 120–124. [Google Scholar] [CrossRef]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Aleksander, I. Neural computing: Hype or reality? Eur. Manag. J. 1988, 6, 114–117. [Google Scholar] [CrossRef]
- Mitchell, M. Why AI is Harder Than We Think. arXiv 2021, arXiv:2104.12871. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Chauhan, T.; Palivela, H.; Tiwari, S. Optimization and fine-tuning of DenseNet model for classification of COVID-19 cases in medical imaging. Int. J. Inf. Manag. Data Insights 2021, 1, 100020. [Google Scholar] [CrossRef]
- Chen, J.; Wu, L.; Zhang, J.; Zhang, L.; Gong, D.; Zhao, Y.; Hu, S.; Wang, Y.; Hu, X.; Zheng, B.; et al. Deep learning-based model for detecting 2019 novel coronavirus pneumonia on high-resolution computed tomography: A prospective study. medRxiv 2020. Available online: https://www.medrxiv.org/content/early/2020/03/01/2020.02.25.20021568.full.pdf (accessed on 25 August 2022).
- Hu, K.; Huang, Y.; Huang, W.; Tan, H.; Chen, Z.; Zhong, Z.; Li, X.; Zhang, Y.; Gao, X. Deep Supervised Learning Using Self-Adaptive Auxiliary Loss for COVID-19 Diagnosis from Imbalanced CT Images. Neurocomputing 2021, 458, 232–245. [Google Scholar] [CrossRef]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Using Artificial Intelligence to Detect COVID-19 and Community-acquired Pneumonia Based on Pulmonary CT: Evaluation of the Diagnostic Accuracy. Radiology 2020, 296, E65–E71. [Google Scholar] [CrossRef]
- Pham, T.D. A comprehensive study on classification of COVID-19 on computed tomography with pretrained convolutional neural networks. Sci. Rep. 2020, 10, 16942. [Google Scholar] [CrossRef]
- Singh, D.; Kumar, V.; Vaishali; Kaur, M. Classification of COVID-19 patients from chest CT images using multi-objective differential evolution–based convolutional neural networks. Eur. J. Clin. Microbiol. Infect. Dis. 2020, 39, 1379–1389. [Google Scholar] [CrossRef]
- Mousavi, Z.; Shahini, N.; Sheykhivand, S.; Mojtahedi, S.; Arshadi, A. COVID-19 detection using chest X-ray images based on a developed deep neural network. SLAS Technol. 2022, 27, 63–75. [Google Scholar] [CrossRef]
- Sheykhivand, S.; Mousavi, Z.; Mojtahedi, S.; Yousefi Rezaii, T.; Farzamnia, A.; Meshgini, S.; Saad, I. Developing an efficient deep neural network for automatic detection of COVID-19 using chest X-ray images. Alex. Eng. J. 2021, 60, 2885–2903. [Google Scholar] [CrossRef]
- Zhou, T.; Canu, S.; Ruan, S. Automatic COVID-19 CT segmentation using U-Net integrated spatial and channel attention mechanism. Int. J. Imaging Syst. Technol. 2021, 31, 16–27. [Google Scholar] [CrossRef]
- Zhang, Q.; Ren, X.; Wei, B. Segmentation of infected region in CT images of COVID-19 patients based on QC-HC U-net. Sci. Rep. 2021, 11, 22854. [Google Scholar] [CrossRef]
- Das, A. Adaptive UNet-based Lung Segmentation and Ensemble Learning with CNN-based Deep Features for Automated COVID-19 Diagnosis. Multimed. Tools Appl. 2022, 81, 5407–5441. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Reyes-Aldasoro, C.C.; Bhalerao, A. Volumetric Texture Analysis in Biomedical Imaging. In Biomedical Diagnostics and Clinical Technologies: Applying High-Performance Cluster and Grid Computing, 1st ed.; IGI Global: Hershey, PA, USA, 2011; pp. 200–248. ISBN 9781605662800. [Google Scholar] [CrossRef]
- Bougourzi, F.; Distante, C.; Ouafi, A.; Dornaika, F.; Hadid, A.; Taleb-Ahmed, A. Per-COVID-19: A Benchmark Dataset for COVID-19 Percentage Estimation from CT-Scans. J. Imaging 2021, 7, 189. [Google Scholar] [CrossRef]
- Yang, J.; Wu, B.; Li, L.; Cao, P.; Zaiane, O. MSDS-UNet: A multi-scale deeply supervised 3D U-Net for automatic segmentation of lung tumor in CT. Comput. Med. Imaging Graph. 2021, 92, 101957. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, Q.; Tian, L.; Zhou, X.; Rekik, I.; Huang, H. HFCF-Net: A hybrid-feature cross fusion network for COVID-19 lesion segmentation from CT volumetric images. Med. Phys. 2022, 49, 3797–3815. [Google Scholar] [CrossRef]
- Ali Ahmed, S.A.; Yavuz, M.C.; Şen, M.U.; Gülşen, F.; Tutar, O.; Korkmazer, B.; Samancı, C.; Şirolu, S.; Hamid, R.; Eryürekli, A.E.; et al. Comparison and ensemble of 2D and 3D approaches for COVID-19 detection in CT images. Neurocomputing 2022, 488, 457–469. [Google Scholar] [CrossRef]
- Zheng, W.; Yan, L.; Gou, C.; Zhang, Z.C.; Jason Zhang, J.; Hu, M.; Wang, F.Y. Pay attention to doctor-patient dialogues: Multi-modal knowledge graph attention image-text embedding for COVID-19 diagnosis. Inf. Fusion 2021, 75, 168–185. [Google Scholar] [CrossRef]
- Jayachitra, V.P.; Nivetha, S.; Nivetha, R.; Harini, R. A cognitive IoT-based framework for effective diagnosis of COVID-19 using multimodal data. Biomed. Signal Process. Control 2021, 70, 102960. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Zhang, X.; Zhu, Z.; Lan, X.; Fu, L.; Wang, H.; Wen, H. Cohesive Multi-Modality Feature Learning and Fusion for COVID-19 Patient Severity Prediction. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2535–2549. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Lu, H.; Yang, Z.; Qiu, S.; Huo, B.; Dong, Y. The ensemble deep learning model for novel COVID-19 on CT images. Appl. Soft Comput. 2021, 98, 106885. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Wang, S.H.; Zhang, Y.D. EDNC: Ensemble Deep Neural Network for COVID-19 Recognition. Tomography 2022, 8, 869–890. [Google Scholar] [CrossRef]
- Zazzaro, G.; Martone, F.; Romano, G.; Pavone, L. A Deep Learning Ensemble Approach for Automated COVID-19 Detection from Chest CT Images. J. Clin. Med. 2021, 10, 5982. [Google Scholar] [CrossRef]
- Gibney, E. How to shrink AI’s ballooning carbon footprint. Nature 2022, 607, 648. [Google Scholar] [CrossRef]
- Subramanian, N.; Elharrouss, O.; Al-Maadeed, S.; Chowdhury, M. A review of deep learning-based detection methods for COVID-19. Comput. Biol. Med. 2022, 143, 105233. [Google Scholar] [CrossRef]
- Soomro, T.A.; Zheng, L.; Afifi, A.J.; Ali, A.; Yin, M.; Gao, J. Artificial intelligence (AI) for medical imaging to combat coronavirus disease (COVID-19): A detailed review with direction for future research. Artif. Intell. Rev. 2022, 55, 1409–1439. [Google Scholar] [CrossRef]
- Shah, A.; Shah, M. Advancement of deep learning in pneumonia/COVID-19 classification and localization: A systematic review with qualitative and quantitative analysis. Chronic Dis. Transl. Med. 2022, 1–18. [Google Scholar] [CrossRef]
- Siddiqui, S.; Arifeen, M.; Hopgood, A.; Good, A.; Gegov, A.; Hossain, E.; Rahman, W.; Hossain, S.; Al Jannat, S.; Ferdous, R.; et al. Deep Learning Models for the Diagnosis and Screening of COVID-19: A Systematic Review. SN Comput. Sci. 2022, 3, 397. [Google Scholar] [CrossRef]
- Bohmrah, M.K.; Kaur, H. Classification of COVID-19 patients using efficient fine-tuned deep learning DenseNet model. Glob. Transitions Proc. 2021, 2, 476–483. [Google Scholar] [CrossRef]
- Jaiswal, A.; Gianchandani, N.; Singh, D.; Kumar, V.; Kaur, M. Classification of the COVID-19 infected patients using DenseNet201 based deep transfer learning. J. Biomol. Struct. Dyn. 2021, 39, 5682–5689. [Google Scholar] [CrossRef]
- Biswas, S.; Chatterjee, S.; Majee, A.; Sen, S.; Schwenker, F.; Sarkar, R. Prediction of COVID-19 from Chest CT Images Using an Ensemble of Deep Learning Models. Appl. Sci. 2021, 11, 7004. [Google Scholar] [CrossRef]
- Kundu, R.; Singh, P.K.; Ferrara, M.; Ahmadian, A.; Sarkar, R. ET-NET: An ensemble of transfer learning models for prediction of COVID-19 infection through chest CT-scan images. Multimed. Tools Appl. 2022, 81, 31–50. [Google Scholar] [CrossRef]
- López-Cabrera, J.D.; Orozco-Morales, R.; Portal-Diaz, J.A.; Lovelle-Enríquez, O.; Pérez-Díaz, M. Current limitations to identify COVID-19 using artificial intelligence with chest X-ray imaging. Health Technol. 2021, 11, 411–424. [Google Scholar] [CrossRef]
- Taddeo, M.; Tsamados, A.; Cowls, J.; Floridi, L. Artificial intelligence and the climate emergency: Opportunities, challenges, and recommendations. One Earth 2021, 4, 776–779. [Google Scholar] [CrossRef]
- Dhar, P. The carbon impact of artificial intelligence. Nat. Mach. Intell. 2020, 2, 423–425. [Google Scholar] [CrossRef]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Maftouni, M. Large COVID-19 CT Scan Slice Dataset. Available online: https://www.kaggle.com/datasets/maedemaftouni/large-covid19-ct-slice-dataset (accessed on 3 August 2021).
- Maftouni, M. Curated_COVID_CT. Available online: https://github.com/maftouni/Curated_Covid_CT (accessed on 1 July 2022).
- Maftouni, M.; Law, A.C.C.; Shen, B.; Zhou, Y.; Ayoobi Yazdi, N.; Kong, Z. A Robust Ensemble-Deep Learning Model for COVID-19 Diagnosis based on an Integrated CT Scan Images Database. In Proceedings of the 2021 IISE Annual Conference, Virtual, 23–25 May 2021; pp. 632–637. [Google Scholar]
- Yan, T.; Wong, P.K.; Ren, H.; Wang, H.; Wang, J.; Li, Y. Automatic distinction between COVID-19 and common pneumonia using multi-scale convolutional neural network on chest CT scans. Chaos Solitons Fractals 2020, 140, 110153. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going deeper with Image Transformers. arXiv 2021, arXiv:2103.17239. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Choi, D.; Shallue, C.J.; Nado, Z.; Lee, J.; Maddison, C.J.; Dahl, G.E. On Empirical Comparisons of Optimizers for Deep Learning. arXiv 2020, arXiv:1910.05446. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Tanha, J.; Abdi, Y.; Samadi, N.; Razzaghi, N.; Asadpour, M. Boosting methods for multi-class imbalanced data classification: An experimental review. J. Big Data 2020, 7, 70. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar] [CrossRef]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Friedman, M. The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Nemenyi, P.B. Distribution-Free Multiple Comparisons. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 1963. [Google Scholar]
- Japkowicz, N.; Shah, M. Error Estimation. In Evaluating Learning Algorithms: A Classification Perspective; Cambridge University Press: Cambridge, UK, 2011; Chapter 5; pp. 161–205. [Google Scholar]
- Lingelbach, K.; Bui, M.; Diederichs, F.; Vukelić, M. Exploring Conventional, Automated and Deep Machine Learning for Electrodermal Activity-Based Drivers’ Stress Recognition. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 1339–1344. [Google Scholar]
- Corizzo, R.; Ceci, M.; Zdravevski, E.; Japkowicz, N. Scalable Auto-Encoders for Gravitational Waves Detection from Time Series Data. Expert Syst. Appl. 2020, 151, 113378. [Google Scholar] [CrossRef]
- Japkowicz, N.; Shah, M. Statistical Significance Testing. In Evaluating Learning Algorithms: A Classification Perspective; Cambridge University Press: Cambridge, UK, 2011; Chapter 6; pp. 206–291. [Google Scholar]
- Chicco, D.; Tötsch, N.; Jurman, G. The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min. 2021, 14, 13. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 326–366. [Google Scholar]
- Yang, Y.; Chen, J.; Wang, R.; Ma, T.; Wang, L.; Chen, J.; Zheng, W.S.; Zhang, T. Towards Unbiased COVID-19 Lesion Localisation And Segmentation Via Weakly Supervised Learning. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 1966–1970. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Parameters | Inference (ms) | Operation | Memory | Year |
|---|---|---|---|---|---|
| CaiT | 11,763,843 | CPU: 75.522 GPU: 57.952 | attention matrix multiplication | 1.02 Gb | 2021 |
| DenseNet-121 | 6,956,931 | CPU: 49.303 GPU: 41.284 | convolutions | 689 Mb | 2017 |
| MobileNet-v3 | 4,205,875 | CPU: 22.692 GPU: 11.40 | convolutions | 269.01 Mb | 2019 |
| ResNet-50 | 23,514,179 | CPU: 42.971 GPU: 40.537 | convolutions batch norm | 678.85 Mb | 2015 |
| ResNet-50r | 23,509,571 | CPU: 45.068 GPU: 42.788 | convolutions batch norm | 731.66 Mb | 2015 |
| Class | Training | Validation | Test | Total |
|---|---|---|---|---|
| COVID-19 | 6074 | 759 | 760 | 7593 |
| Non-COVID | 5514 | 689 | 690 | 6893 |
| CAP | 2357 | 295 | 294 | 2946 |
| Experiment | Architecture | Loss | Optimizer |
|---|---|---|---|
| Exp-01 | CaiT | CE | Adam |
| Exp-02 | CaiT | CE | AdamW |
| Exp-03 | CaiT | wCE | Adam |
| Exp-04 | CaiT | wCE | AdamW |
| Exp-05 | DenseNet-121 | CE | Adam |
| Exp-06 | DenseNet-121 | CE | AdamW |
| Exp-07 | DenseNet-121 | wCE | Adam |
| Exp-08 | DenseNet-121 | wCE | AdamW |
| Exp-09 | MobileNet-v3 | CE | Adam |
| Exp-10 | MobileNet-v3 | CE | AdamW |
| Exp-11 | MobileNet-v3 | wCE | Adam |
| Exp-12 | MobileNet-v3 | wCE | AdamW |
| Exp-13 | ResNet-50 | CE | Adam |
| Exp-14 | ResNet-50 | CE | AdamW |
| Exp-15 | ResNet-50 | wCE | Adam |
| Exp-16 | ResNet-50 | wCE | AdamW |
| Exp-17 | ResNet-50r | CE | Adam |
| Exp-18 | ResNet-50r | CE | AdamW |
| Exp-19 | ResNet-50r | wCE | Adam |
| Exp-20 | ResNet-50r | wCE | AdamW |
| Architecture | Train Accuracy | Validation Accuracy | Test Accuracy |
|---|---|---|---|
| CaiT | 99.23 ± 0.79 | 98.43 ± 0.64 | 98.55 ± 0.54 |
| DenseNet-121 | 99.42 ± 0.10 | 99.07 ± 0.29 | 98.89 ± 0.40 |
| MobileNet-v3 | 98.42 ± 0.58 | 98.65 ± 0.46 | 98.86 ± 0.33 |
| ResNet-50 | 99.36 ± 0.10 | 99.16 ± 0.32 | 99.02 ± 0.22 |
| ResNet-50r | 99.20 ± 0.14 | 99.10 ± 0.40 | 98.99 ± 0.32 |
| Experiment | Train Accuracy | Validation Accuracy | Test Accuracy |
|---|---|---|---|
| Exp-01 | 99.38 ± 0.06 | 98.25 ± 0.60 | 98.47 ± 0.41 |
| Exp-02 | 99.38 ± 0.12 | 98.70 ± 0.43 | 98.64 ± 0.44 |
| Exp-03 | 98.84 ± 1.56 | 98.35 ± 0.73 | 98.44 ± 0.52 |
| Exp-04 | 99.31 ± 0.13 | 98.41 ± 0.76 | 98.64 ± 0.76 |
| Exp-05 | 99.45 ± 0.06 | 99.10 ± 0.20 | 99.08 ± 0.17 |
| Exp-06 | 99.44 ± 0.06 | 99.13 ± 0.22 | 98.97 ± 0.30 |
| Exp-07 | 99.40 ± 0.12 | 99.01 ± 0.34 | 98.67 ± 0.55 |
| Exp-08 | 99.38 ± 0.12 | 99.03 ± 0.40 | 98.86 ± 0.42 |
| Exp-09 | 98.61 ± 0.09 | 98.77 ± 0.36 | 98.89 ± 0.22 |
| Exp-10 | 98.24 ± 1.17 | 98.57 ± 0.71 | 98.87 ± 0.54 |
| Exp-11 | 98.41 ± 0.09 | 98.56 ± 0.43 | 98.83 ± 0.32 |
| Exp-12 | 98.44 ± 0.05 | 98.70 ± 0.22 | 98.84 ± 0.18 |
| Exp-13 | 99.42 ± 0.07 | 99.17 ± 0.29 | 98.94 ± 0.33 |
| Exp-14 | 99.38 ± 0.08 | 99.15 ± 0.30 | 99.04 ± 0.18 |
| Exp-15 | 99.34 ± 0.06 | 99.18 ± 0.41 | 99.08 ± 0.16 |
| Exp-16 | 99.31 ± 0.15 | 99.14 ± 0.31 | 99.01 ± 0.19 |
| Exp-17 | 99.22 ± 0.17 | 99.19 ± 0.30 | 98.97 ± 0.34 |
| Exp-18 | 99.22 ± 0.15 | 99.19 ± 0.35 | 99.16 ± 0.19 |
| Exp-19 | 99.17 ± 0.10 | 98.94 ± 0.53 | 98.71 ± 0.29 |
| Exp-20 | 99.20 ± 0.15 | 99.08 ± 0.39 | 99.13 ± 0.23 |
| Architecture | F | F | ||
| CaiT | 98.55 ± 0.54 | 98.71 ± 0.66 | 98.70 ± 0.63 | 98.70 ± 0.65 |
| DenseNet-121 | 98.89 ± 0.40 | 99.10 ± 0.34 | 99.10 ± 0.34 | 99.08 ± 0.37 |
| MobileNet-v3 | 98.86 ± 0.33 | 99.06 ± 0.30 | 99.06 ± 0.29 | 99.06 ± 0.29 |
| ResNet-50 | 99.02 ± 0.22 | 99.19 ± 0.20 | 99.15 ± 0.22 | 99.16 ± 0.22 |
| ResNet-50r | 98.99 ± 0.32 | 99.16 ± 0.32 | 99.16 ± 0.30 | 99.18 ± 0.31 |
| Architecture | ||||
| CaiT | 97.64 ± 0.86 | 98.72 ± 0.67 | 99.17 ± 0.28 | |
| DenseNet-121 | 98.27 ± 0.60 | 99.11 ± 0.34 | 99.36 ± 0.23 | |
| MobileNet-v3 | 98.18 ± 0.52 | 99.08 ± 0.29 | 99.35 ± 0.25 | |
| ResNet-50 | 98.42 ± 0.37 | 99.17 ± 0.22 | 99.43 ± 0.13 | |
| ResNet-50r | 98.41 ± 0.51 | 99.17 ± 0.32 | 99.43 ± 0.18 |
| Experiments | Acc | BA | F1 | F2 | MCC | Sens | Spec |
|---|---|---|---|---|---|---|---|
| Exp-01 | 98.47 ± 0.41 | 98.61 ± 0.40 | 98.65 ± 0.36 | 98.62 ± 0.40 | 97.52 ± 0.65 | 98.63 ± 0.41 | 99.12 ± 0.23 |
| Exp-02 | 98.64 ± 0.44 | 98.89 ± 0.36 | 98.83 ± 0.43 | 98.86 ± 0.39 | 97.84 ± 0.69 | 98.88 ± 0.36 | 99.25 ± 0.23 |
| Exp-03 | 98.44 ± 0.52 | 98.52 ± 1.06 | 98.62 ± 0.76 | 98.56 ± 0.95 | 97.52 ± 0.83 | 98.56 ± 1.09 | 99.12 ± 0.30 |
| Exp-04 | 98.64 ± 0.76 | 98.81 ± 0.63 | 98.71 ± 0.90 | 98.77 ± 0.74 | 97.66 ± 1.23 | 98.81 ± 0.63 | 99.19 ± 0.38 |
| Exp-05 | 99.08 ± 0.17 | 99.23 ± 0.15 | 99.22 ± 0.21 | 99.22 ± 0.17 | 98.51 ± 0.28 | 99.23 ± 0.15 | 99.47 ± 0.09 |
| Exp-06 | 98.97 ± 0.30 | 99.16 ± 0.25 | 99.14 ± 0.26 | 99.15 ± 0.26 | 98.35 ± 0.48 | 99.16 ± 0.25 | 99.38 ± 0.16 |
| Exp-07 | 98.67 ± 0.55 | 98.96 ± 0.50 | 98.97 ± 0.46 | 98.86 ± 0.53 | 98.04 ± 0.83 | 98.97 ± 0.51 | 99.25 ± 0.32 |
| Exp-08 | 98.86 ± 0.42 | 99.05 ± 0.36 | 99.08 ± 0.36 | 99.09 ± 0.37 | 98.17 ± 0.65 | 99.09 ± 0.35 | 99.34 ± 0.24 |
| Exp-09 | 98.89 ± 0.22 | 99.08 ± 0.19 | 99.06 ± 0.16 | 99.10 ± 0.20 | 98.22 ± 0.34 | 99.10 ± 0.21 | 99.37 ± 0.13 |
| Exp-10 | 98.87 ± 0.54 | 99.07 ± 0.48 | 99.03 ± 0.46 | 99.07 ± 0.47 | 98.20 ± 0.85 | 99.09 ± 0.48 | 99.36 ± 0.34 |
| Exp-11 | 98.83 ± 0.32 | 99.03 ± 0.30 | 99.04 ± 0.21 | 99.04 ± 0.25 | 98.14 ± 0.50 | 99.08 ± 0.23 | 99.30 ± 0.34 |
| Exp-12 | 98.84 ± 0.18 | 99.06 ± 0.15 | 99.12 ± 0.29 | 99.04 ± 0.17 | 98.15 ± 0.28 | 99.05 ± 0.16 | 99.35 ± 0.12 |
| Exp-13 | 98.94 ± 0.33 | 99.13 ± 0.29 | 99.11 ± 0.31 | 99.12 ± 0.29 | 98.30 ± 0.55 | 99.13 ± 0.28 | 99.39 ± 0.19 |
| Exp-14 | 99.04 ± 0.18 | 99.19 ± 0.20 | 99.11 ± 0.22 | 99.12 ± 0.25 | 98.48 ± 0.30 | 99.12 ± 0.25 | 99.47 ± 0.10 |
| Exp-15 | 99.08 ± 0.16 | 99.26 ± 0.14 | 99.23 ± 0.13 | 99.22 ± 0.14 | 98.53 ± 0.26 | 99.23 ± 0.15 | 99.46 ± 0.11 |
| Exp-16 | 99.01 ± 0.19 | 99.18 ± 0.17 | 99.13 ± 0.17 | 99.16 ± 0.16 | 98.38 ± 0.31 | 99.20 ± 0.21 | 99.42 ± 0.11 |
| Exp-17 | 98.97 ± 0.34 | 99.13 ± 0.37 | 99.11 ± 0.35 | 99.15 ± 0.34 | 98.36 ± 0.55 | 99.15 ± 0.37 | 99.43 ± 0.19 |
| Exp-18 | 99.16 ± 0.19 | 99.32 ± 0.15 | 99.32 ± 0.15 | 99.32 ± 0.15 | 98.66 ± 0.31 | 99.32 ± 0.15 | 99.52 ± 0.11 |
| Exp-19 | 98.71 ± 0.29 | 98.90 ± 0.35 | 98.90 ± 0.27 | 98.92 ± 0.34 | 97.94 ± 0.46 | 98.90 ± 0.35 | 99.27 ± 0.17 |
| Exp-20 | 99.13 ± 0.23 | 99.28 ± 0.20 | 99.30 ± 0.21 | 99.31 ± 0.20 | 98.66 ± 0.35 | 99.31 ± 0.20 | 99.51 ± 0.13 |
| Architecture | Rank | ||||||
| Acc | BA | F1 | F2 | MCC | Sens | Spec | |
| CaiT | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 | 5.00 |
| DenseNet-121 | 3.20 | 2.98 | 2.82 | 3.18 | 3.05 | 2.92 | 3.30 |
| MobileNet-v3 | 3.63 | 3.62 | 3.58 | 3.50 | 3.72 | 3.54 | 3.56 |
| ResNet-50 | 1.40 | 1.38 | 1.92 | 1.84 | 1.53 | 1.75 | 1.51 |
| ResNet-50r | 1.77 | 2.02 | 1.68 | 1.47 | 1.71 | 1.80 | 1.63 |
| Architecture | Median | ||||||
| Acc | BA | F1 | F2 | MCC | Sens | Spec | |
| CaiT | 98.56 | 98.72 | 98.71 | 98.72 | 97.65 | 98.73 | 99.17 |
| DenseNet-121 | 98.89 | 99.10 | 99.11 | 99.08 | 98.27 | 99.12 | 99.36 |
| MobileNet-v3-large | 98.86 | 99.07 | 99.07 | 99.06 | 98.19 | 99.08 | 99.35 |
| ResNet-50 | 99.02 | 99.19 | 99.14 | 99.15 | 98.42 | 99.17 | 99.43 |
| ResNet-50r | 98.99 | 99.16 | 99.16 | 99.18 | 98.41 | 99.18 | 99.43 |
| Architecture | Accuracy | BA | F1 | F2 |
| CaiT | 98.37–98.71 | 98.49–98.90 | 98.50–98.87 | 98.49–98.88 |
| DenseNet-121 | 98.76–99.00 | 98.99–99.20 | 99.00–99.20 | 98.96–99.19 |
| MobileNet-v3 1 | 98.75–98.95 | 98.97–99.15 | 98.96–99.15 | 98.97–99.15 |
| ResNet-50 | 98.95–99.09 | 99.13–99.25 | 99.07–99.21 | 99.09–99.22 |
| ResNet-50r | 98.90–99.08 | 99.05–99.25 | 99.07–99.25 | 99.09–99.26 |
| Architecture | MCC | Sens | Spec | |
| CaiT | 97.36–97.88 | 98.48–98.90 | 99.08–99.25 | |
| DenseNet-121 | 98.07–98.44 | 99.00–99.21 | 99.29–99.43 | |
| MobileNet-v3 | 98.01–98.33 | 98.98–99.16 | 99.26–99.42 | |
| ResNet-50 | 98.31–98.53 | 99.10–99.24 | 99.39–99.47 | |
| ResNet-50r | 98.25–98.57 | 99.07–99.26 | 99.38–99.48 |
| Experiment | Rank | Median | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | BA | F1 | F2 | MCC | Sens | Spec | Acc | BA | F1 | F2 | MCC | Sens | Spec | |
| Exp-01 | 18.70 | 19.14 | 18.89 | 18.96 | 18.84 | 19.05 | 18.78 | 98.46 | 98.61 | 98.65 | 98.62 | 97.52 | 98.62 | 99.12 |
| Exp-02 | 16.51 | 16.03 | 16.67 | 16.11 | 16.49 | 16.40 | 15.69 | 98.64 | 98.90 | 98.84 | 98.87 | 97.85 | 98.89 | 99.26 |
| Exp-03 | 18.90 | 18.96 | 18.59 | 18.75 | 18.85 | 18.75 | 18.68 | 98.45 | 98.54 | 98.64 | 98.58 | 97.53 | 98.57 | 99.12 |
| Exp-04 | 15.82 | 16.51 | 17.15 | 16.96 | 17.30 | 16.84 | 16.79 | 98.64 | 98.85 | 98.74 | 98.78 | 97.70 | 98.82 | 99.20 |
| Exp-05 | 3.90 | 4.50 | 4.40 | 4.70 | 4.64 | 4.78 | 4.20 | 99.08 | 99.24 | 99.23 | 99.22 | 98.51 | 99.23 | 99.47 |
| Exp-06 | 7.92 | 7.87 | 7.77 | 7.69 | 8.15 | 7.84 | 9.88 | 98.97 | 99.16 | 99.14 | 99.15 | 98.35 | 99.16 | 99.38 |
| Exp-07 | 15.98 | 14.18 | 13.62 | 15.75 | 13.55 | 13.83 | 15.41 | 98.67 | 98.97 | 98.98 | 98.87 | 98.07 | 98.98 | 99.25 |
| Exp-08 | 11.58 | 11.50 | 10.42 | 10.02 | 11.57 | 10.59 | 11.75 | 98.86 | 99.06 | 99.08 | 99.09 | 98.18 | 99.09 | 99.35 |
| Exp-09 | 10.88 | 10.92 | 11.46 | 9.84 | 10.86 | 10.48 | 10.23 | 98.89 | 99.08 | 99.06 | 99.10 | 98.23 | 99.10 | 99.38 |
| Exp-10 | 10.82 | 10.72 | 11.36 | 10.22 | 10.88 | 9.93 | 10.57 | 98.89 | 99.08 | 99.05 | 99.08 | 98.22 | 99.11 | 99.37 |
| Exp-11 | 12.44 | 12.49 | 11.89 | 12.26 | 12.60 | 11.18 | 13.31 | 98.84 | 99.04 | 99.05 | 99.04 | 98.14 | 99.08 | 99.31 |
| Exp-12 | 12.38 | 11.70 | 8.64 | 12.45 | 12.51 | 12.56 | 11.58 | 98.84 | 99.07 | 99.11 | 99.04 | 98.15 | 99.05 | 99.35 |
| Exp-13 | 8.98 | 9.10 | 9.23 | 8.68 | 9.19 | 8.85 | 8.97 | 98.95 | 99.13 | 99.11 | 99.13 | 98.31 | 99.14 | 99.40 |
| Exp-14 | 5.49 | 6.44 | 8.93 | 9.03 | 5.24 | 9.51 | 4.49 | 99.05 | 99.20 | 99.12 | 99.12 | 98.48 | 99.12 | 99.47 |
| Exp-15 | 4.29 | 3.76 | 4.11 | 4.57 | 4.29 | 4.76 | 5.33 | 99.08 | 99.26 | 99.23 | 99.22 | 98.52 | 99.23 | 99.45 |
| Exp-16 | 6.87 | 6.66 | 8.05 | 7.37 | 7.58 | 6.11 | 7.65 | 99.01 | 99.19 | 99.14 | 99.16 | 98.38 | 99.20 | 99.42 |
| Exp-17 | 8.23 | 8.95 | 8.98 | 7.68 | 7.85 | 8.31 | 7.07 | 98.97 | 99.14 | 99.12 | 99.15 | 98.36 | 99.16 | 99.43 |
| Exp-18 | 1.84 | 1.66 | 1.70 | 1.69 | 2.06 | 1.87 | 1.70 | 99.16 | 99.32 | 99.32 | 99.32 | 98.66 | 99.32 | 99.53 |
| Exp-19 | 15.55 | 15.90 | 15.81 | 15.07 | 15.52 | 16.09 | 15.30 | 98.71 | 98.90 | 98.90 | 98.93 | 97.95 | 98.90 | 99.27 |
| Exp-20 | 2.92 | 3.03 | 2.32 | 2.20 | 2.03 | 2.28 | 2.62 | 99.12 | 99.28 | 99.30 | 99.31 | 98.66 | 99.31 | 99.50 |
| Experiment | Acc | BA | F1 | F2 | MCC | Sens | Spec |
|---|---|---|---|---|---|---|---|
| Exp-01 | 98.24–98.71 | 98.36–98.85 | 98.45–98.86 | 98.39–98.85 | 97.14–97.91 | 98.40–98.88 | 98.99–99.25 |
| Exp-02 | 98.38–98.87 | 98.67–99.10 | 98.56–99.06 | 98.62–99.08 | 97.40–98.21 | 98.67–99.08 | 99.09–99.37 |
| Exp-03 | 98.09–98.67 | 97.82–98.92 | 98.13–98.92 | 97.91–98.92 | 96.96–97.88 | 97.83–99.00 | 98.92–99.25 |
| Exp-04 | 98.12–98.94 | 98.42–99.12 | 98.13–99.11 | 98.26–99.11 | 96.89–98.24 | 98.39–99.12 | 98.96–99.38 |
| Exp-05 | 98.99–99.18 | 99.15–99.32 | 99.08–99.34 | 99.11–99.31 | 98.35–98.66 | 99.15–99.32 | 99.42–99.52 |
| Exp-06 | 98.80–99.14 | 99.02–99.30 | 98.99–99.29 | 99.01–99.30 | 98.08–98.63 | 99.02–99.31 | 99.28–99.47 |
| Exp-07 | 98.33–98.95 | 98.64–99.21 | 98.68–99.20 | 98.55–99.17 | 97.48–98.47 | 98.64–99.25 | 99.06–99.42 |
| Exp-08 | 98.61–99.10 | 98.85–99.26 | 98.85–99.27 | 98.87–99.29 | 97.79–98.54 | 98.88–99.28 | 99.20–99.47 |
| Exp-09 | 98.75–99.02 | 98.97–99.19 | 98.96–99.16 | 98.98–99.20 | 98.02–98.41 | 98.96–99.21 | 99.29–99.45 |
| Exp-10 | 98.50–99.14 | 98.74–99.32 | 98.72–99.26 | 98.77–99.31 | 97.69–98.62 | 98.79–99.34 | 99.14–99.53 |
| Exp-11 | 98.64–99.00 | 98.84–99.19 | 98.91–99.15 | 98.89–99.18 | 97.82–98.40 | 98.94–99.21 | 99.07–99.46 |
| Exp-12 | 98.73–98.94 | 98.97–99.14 | 98.99–99.31 | 98.94–99.13 | 97.99–98.30 | 98.95–99.14 | 99.28–99.41 |
| Exp-13 | 98.74–99.13 | 98.95–99.29 | 98.91–99.28 | 98.94–99.29 | 97.95–98.61 | 98.96–99.29 | 99.29–99.50 |
| Exp-14 | 98.93–99.14 | 99.06–99.30 | 98.97–99.24 | 98.95–99.25 | 98.29–98.63 | 98.96–99.25 | 99.41–99.52 |
| Exp-15 | 98.99–99.18 | 99.17–99.34 | 99.16–99.30 | 99.14–99.31 | 98.38–98.68 | 99.15–99.32 | 99.39–99.52 |
| Exp-16 | 98.90–99.11 | 99.08–99.27 | 99.03–99.22 | 99.06–99.24 | 98.17–98.56 | 99.08–99.33 | 99.35–99.49 |
| Exp-17 | 98.75–99.16 | 98.90–99.33 | 98.89–99.30 | 98.94–99.35 | 98.05–98.69 | 98.91–99.35 | 99.31–99.53 |
| Exp-18 | 99.06–99.28 | 99.24–99.41 | 99.23–99.41 | 99.24–99.41 | 98.48–98.86 | 99.23–99.41 | 99.47–99.59 |
| Exp-19 | 98.55–98.87 | 98.70–99.08 | 98.73–99.06 | 98.72–99.11 | 97.69–98.22 | 98.68–99.08 | 99.16–99.36 |
| Exp-20 | 98.99–99.26 | 99.17–99.40 | 99.18–99.42 | 99.19–99.43 | 98.46–98.87 | 99.20–99.43 | 99.44–99.58 |
| Architecture | Max Accuracy | Epochs | |||||
|---|---|---|---|---|---|---|---|
| Rank | Median | CI | Rank | Median | CI | ATTE (s) | |
| CaiT | 4.92 | 98.82 | 98.73–98.91 | 3.38 | 8 | 5–8 | 503.66 220.57 1 |
| DenseNet-121 | 2.78 | 99.31 | 99.26–99.35 | 2.19 | 7 | 5–7 | 177.08 |
| MobileNet-v3 | 4.08 | 98.92 | 98.82–99.02 | 3.14 | 7 | 7–8 | 87.60 |
| ResNet-50 | 1.85 | 99.34 | 99.30–99.38 | 1.93 | 6 | 6–8 | 100.31 |
| ResNet-50r | 1.37 | 99.36 | 99.30–99.42 | 4.36 | 8 | 6–8 | 106.05 |
| Experiment | Max Accuracy | Epochs | ||
|---|---|---|---|---|
| Rank | Median | Rank | Median | |
| Exp-01 | 17.59 | 98.80 | 8.14 | 5 |
| Exp-02 | 17.05 | 98.84 | 11.39 | 7 |
| Exp-03 | 19.05 | 98.76 | 9.79 | 7 |
| Exp-04 | 16.42 | 98.88 | 13.45 | 8 |
| Exp-05 | 7.55 | 99.32 | 8.09 | 6 |
| Exp-06 | 5.69 | 99.35 | 9.31 | 7 |
| Exp-07 | 9.21 | 99.30 | 7.18 | 6 |
| Exp-08 | 9.69 | 99.28 | 8.11 | 6 |
| Exp-09 | 15.10 | 98.93 | 12.28 | 7 |
| Exp-10 | 16.41 | 98.88 | 11.75 | 7 |
| Exp-11 | 15.53 | 98.91 | 13.64 | 7 |
| Exp-12 | 14.76 | 98.95 | 11.61 | 7 |
| Exp-13 | 6.98 | 99.33 | 14.11 | 8 |
| Exp-14 | 8.38 | 99.31 | 6.58 | 6 |
| Exp-15 | 5.25 | 99.36 | 6.65 | 6 |
| Exp-16 | 4.27 | 99.37 | 9.95 | 6 |
| Exp-17 | 1.91 | 99.43 | 12.13 | 7 |
| Exp-18 | 4.98 | 99.36 | 11.20 | 8 |
| Exp-19 | 9.16 | 99.28 | 9.28 | 6 |
| Exp-20 | 5.02 | 99.37 | 15.36 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ascencio-Cabral, A.; Reyes-Aldasoro, C.C. Comparison of Convolutional Neural Networks and Transformers for the Classification of Images of COVID-19, Pneumonia and Healthy Individuals as Observed with Computed Tomography. J. Imaging 2022, 8, 237. https://doi.org/10.3390/jimaging8090237
Ascencio-Cabral A, Reyes-Aldasoro CC. Comparison of Convolutional Neural Networks and Transformers for the Classification of Images of COVID-19, Pneumonia and Healthy Individuals as Observed with Computed Tomography. Journal of Imaging. 2022; 8(9):237. https://doi.org/10.3390/jimaging8090237
Chicago/Turabian StyleAscencio-Cabral, Azucena, and Constantino Carlos Reyes-Aldasoro. 2022. "Comparison of Convolutional Neural Networks and Transformers for the Classification of Images of COVID-19, Pneumonia and Healthy Individuals as Observed with Computed Tomography" Journal of Imaging 8, no. 9: 237. https://doi.org/10.3390/jimaging8090237
APA StyleAscencio-Cabral, A., & Reyes-Aldasoro, C. C. (2022). Comparison of Convolutional Neural Networks and Transformers for the Classification of Images of COVID-19, Pneumonia and Healthy Individuals as Observed with Computed Tomography. Journal of Imaging, 8(9), 237. https://doi.org/10.3390/jimaging8090237