
AI vs. AI: Can AI Detect AI-Generated Images?



Abstract
:1. Introduction
2. Related Work
2.1. Image-to-Image Synthesis
2.1.1. Image-to-Image Synthesis through Conditional GAN (cGAN)
2.1.2. Image-to-Image Synthesis through Transformers
2.2. Sketch-to-Image Synthesis
2.3. Text-to-Image Synthesis
2.3.1. Text-to-Image Synthesis though Attention Module
2.3.2. Text-to-Image Synthesis though Contrastive Learning
2.3.3. Text-to-Image Synthesis though Deep Fusion Block (DFBlock)
3. Data Collection and Methodology
3.1. Data Collection: Real or Synthetic Images (RSI)
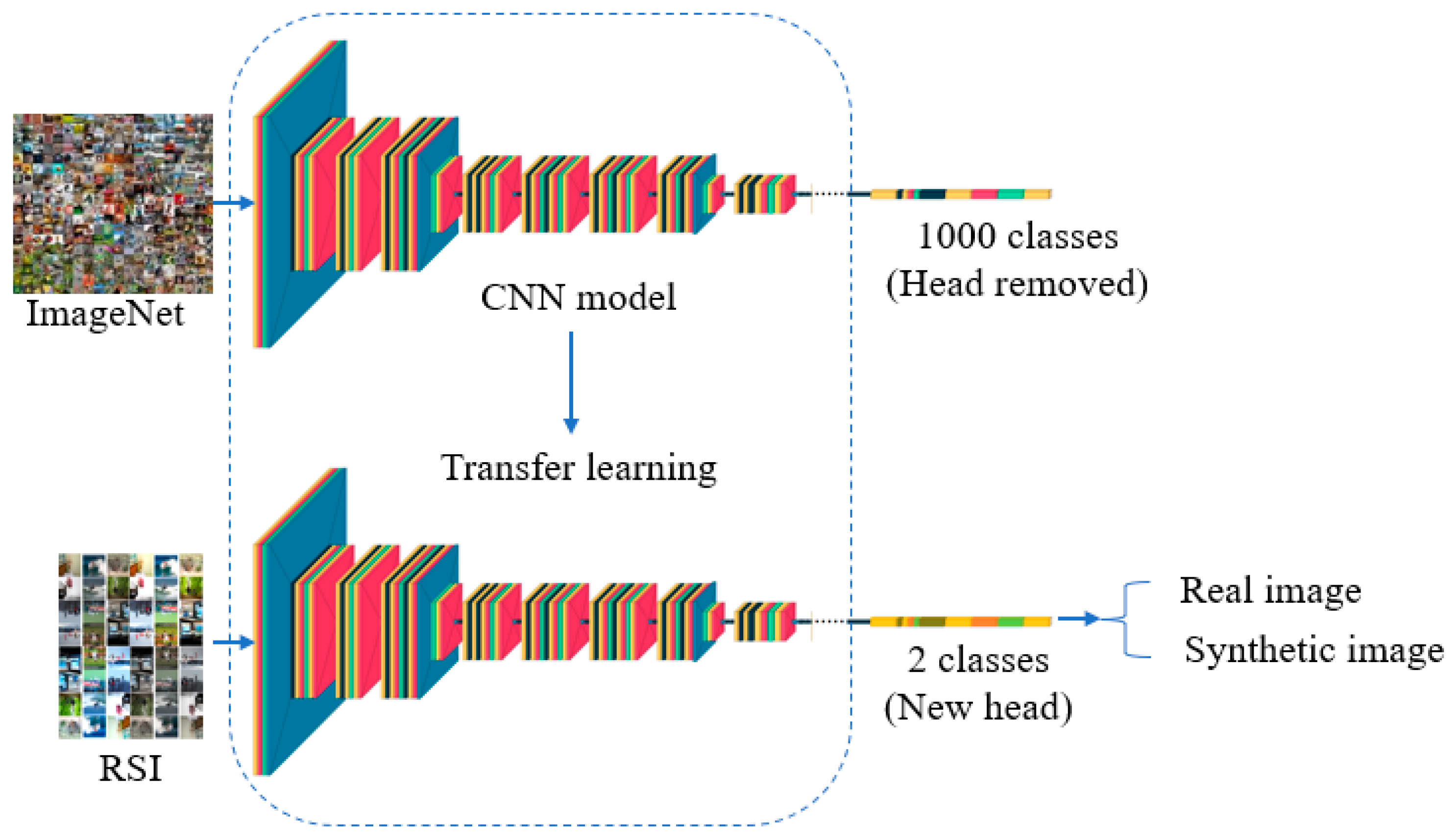
3.2. Methodology
4. Results and Analysis
4.1. Evaluation Metrics
4.2. Experimental Results on RSI
4.3. Effectiveness of Our Model
4.4. Ablation Study
4.5. Experimental Results on Other Datasets
5. Discussion and Limitations
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baraheem, S.S.; Le, T.-N.; Nguyen, T.V. Image synthesis: A review of methods, datasets, evaluation metrics, and future outlook. Artif. Intell. Rev. 2023, 56, 10813–10865. [Google Scholar] [CrossRef]
- Elgammal, A.; Liu, B.; Elhoseiny, M.; Mazzone, M. CAN: Generating ‘art’ by learning about styles and deviating from style norms. arXiv 2017, arXiv:1706.07068. [Google Scholar]
- Chen, J.; Shen, Y.; Gao, J.; Liu, J.; Liu, X. Language-Based Image Editing with recurrent attentive models. arXiv 2017, arXiv:1711.06288. [Google Scholar]
- Yan, Z.; Zhang, H.; Wang, B.; Paris, S.; Yu, Y. Automatic photo adjustment using deep neu-ral networks. arXiv 2014, arXiv:1412.7725. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with con-textual attention. arXiv 2018, arXiv:1801.07892. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. EdgeConnect: Generative image inpainting with adversarial edge learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- Thaung, L. Advanced Data Augmentation: With Generative Adversarial Networks and Computer-Aided Design. 2020, Dissertation. Available online: http://liu.diva-portal.org/smash/record.jsf?pid=diva2%3A1484523&dswid=6768 (accessed on 1 April 2022).
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 2, pp. 2672–2680. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do GANs Leave Artificial Fingerprints? In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval, San Jose, CA, USA, 28–30 March 2019; pp. 506–511. [Google Scholar]
- Yu, N.; Davis, L.; Fritz, M. Attributing Fake Images to GANs: Learning and Analyzing GAN Fingerprints. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, X.; Karaman, S.; Chang, S.-F. Detecting and Simulating Artifacts in GAN Fake Images. In Proceedings of the 2019 IEEE International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; pp. 1–6. [Google Scholar]
- Dzanic, T.; Shah, K.; Witherden, F. Fourier spectrum discrepancies in deep network generated images. arXiv 2019, arXiv:1911.06465. [Google Scholar]
- Frank, J.; Eisenhofer, T.; Sch, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging Frequency Analysis for Deep Fake Image Recognition. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Sushko, V.; Schönfeld, E.; Zhang, D.; Gall, J.; Schiele, B.; Khoreva, A. You only need adversarial supervision for semantic image synthesis. arXiv 2020, arXiv:2012.04781. [Google Scholar]
- Liu, X.; Yin, G.; Shao, J.; Wang, X.; Li, H. Learning to predict layout-to-image conditional convolutions for semantic image synthesis. arXiv 2019, arXiv:1910.06809. [Google Scholar]
- Park, T.; Liu, M.-Y.; Wang, T.-C.; Zhu, J.-Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Baraheem, S.S.; Nguyen, T.V. Sketch-to-image synthesis via semantic masks. In Multimedia Tools and Applications; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–20. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-grained text to image generation with attentional generative adversarial networks. arXiv 2017, arXiv:1711.10485. [Google Scholar]
- Ye, H.; Yang, X.; Takac, M.; Sunderraman, R.; Ji, S. Improving text-to-image synthesis using contrastive learning. arXiv 2021, arXiv:2107.02423. [Google Scholar]
- Tao, M.; Tang, H.; Wu, S.; Sebe, N.; Wu, F.; Jing, X.-Y. DF-GAN: Deep fusion generative adversarial networks for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16515–16525. [Google Scholar] [CrossRef]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H.S. Controllable Text-to-Image Generation. arXiv 2019, arXiv:1909.07083. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. arXiv 2016, arXiv:1611.07004. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Qiao, S.; Chen, L.-C.; Yuille, A. DetectoRS: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid Task Cascade for Instance Segmentation. arXiv 2019, arXiv:1901.07518. [Google Scholar]
- Fang, Y.; Yang, S.; Wang, X.; Li, Y.; Fang, C.; Shan, Y.; Feng, B.; Liu, W. Instances as Queries. arXiv 2021, arXiv:2105.01928. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Beyeler, M. Design and develop advanced computer vision projects using OpenCV with Python. In OpenCV with Python Blueprints; Packt Publishing Ltd.: London, UK, 2015; ISBN 978-178528269-0. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ding, L.; Goshtasby, A. On the Canny edge detector. Pattern Recognit. 2001, 34, 721–725. [Google Scholar] [CrossRef]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Caesar, H.; Uijlings, J.; Ferrari, V. COCO-stuff: Thing and stuff classes in context. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1209–1218. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. MixConv: Mixed Depthwise Convolutional Kernels. arXiv 2019, arXiv:1907.09595. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxvit: Multi-axis vision transformer. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 459–479. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Desai, S.; Ramaswamy, H.G. Ablation-CAM: Visual explanations for deep convolutional network via gradient-free localization. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 972–980. [Google Scholar]
- Jiang, P.-T.; Zhang, C.-B.; Hou, Q.; Cheng, M.-M.; Wei, Y. LayerCAM: Exploring hierarchical class activation maps for localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, DC, USA, 14–19 June 2020. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should I trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5122–5130. [Google Scholar]
- Sangkloy, P.; Burnell, N.; Ham, C.; Hays, J. The sketchy database: Learning to retrieve badly drawn bunnies. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S.J. The Caltech-UCSD Birds-200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Model | Input | Training Set | Validation Set | Testing Set | Total |
|---|---|---|---|---|---|---|
| Image-to-image synthesis | OASIS [14] | Semantic mask map | 2000 | 1000 | 1000 | 4000 |
| CC-FPSE [15] | 2000 | 1000 | 1000 | 4000 | ||
| SPADE [16] | 2000 | 1000 | 1000 | 4000 | ||
| Taming-transformers [17] | 2000 | 1000 | 1000 | 4000 | ||
| Sketch-to-image synthesis | S2I-DetectoRS [18] | Sketch | 2000 | 1000 | 1000 | 4000 |
| S2I-HTC [18] | 2000 | 1000 | 1000 | 4000 | ||
| S2I-QueryInst [18] | 2000 | 1000 | 1000 | 4000 | ||
| S2I-MaskRCNN [18] | 2000 | 1000 | 1000 | 4000 | ||
| Text-to-image synthesis | AttnGAN [19] | Text | 2000 | 1000 | 1000 | 4000 |
| DM-GAN+CL [20] | 2000 | 1000 | 1000 | 4000 | ||
| DF-GAN [21] | 2000 | 1000 | 1000 | 4000 | ||
| ControlGAN [22] | 2000 | 1000 | 1000 | 4000 | ||
| 24,000 | 12,000 | 12,000 | 48,000 |
| Precision | Recall | F1 | Accuracy | AP | ROC-AUC | FPR | FNR | |
|---|---|---|---|---|---|---|---|---|
| VGG19 | 0.94 | 0.94 | 0.94 | 0.94 | 0.9819 | 0.9803 | 0.053 | 0.064 |
| ResNet50 | 0.93 | 0.91 | 0.91 | 0.91 | 0.9933 | 0.9927 | 0.0035 | 0.168 |
| ResNet101 | 0.95 | 0.95 | 0.95 | 0.95 | 0.9879 | 0.9877 | 0.028 | 0.08 |
| ResNet152 | 0.92 | 0.92 | 0.92 | 0.92 | 0.9743 | 0.9718 | 0.042 | 0.118 |
| InceptionV3 | 0.98 | 0.98 | 0.98 | 0.98 | 0.9976 | 0.9974 | 0.016 | 0.03 |
| Xception | 0.97 | 0.97 | 0.97 | 0.97 | 0.9995 | 0.9994 | 0.0003 | 0.054 |
| DenseNet121 | 0.97 | 0.97 | 0.97 | 0.97 | 0.9969 | 0.9966 | 0.012 | 0.044 |
| InceptionResNetV2 | 0.96 | 0.96 | 0.96 | 0.96 | 0.9942 | 0.9943 | 0.037 | 0.036 |
| MixConv | 0.94 | 0.94 | 0.94 | 0.94 | 0.9411 | 0.9412 | 0.057 | 0.056 |
| MaxViT | 0.92 | 0.86 | 0.89 | 0.89 | 0.9375 | 0.9375 | 0.087 | 0.137 |
| EfficientNetB4 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.0 | 0.0 |
| Precision | Recall | F1 | Accuracy | AP | ROC-AUC | FPR | FNR | |
|---|---|---|---|---|---|---|---|---|
| S2I_T2I | 0.99 | 0.99 | 0.99 | 0.99 | 0.9998 | 0.9997 | 0.026 | 0.001 |
| I2I_T2I | 0.87 | 0.83 | 0.82 | 0.83 | 0.9684 | 0.9801 | 0.347 | 0.0 |
| I2I_S2I | 0.96 | 0.95 | 0.95 | 0.95 | 0.99997 | 0.99997 | 0.093 | 0.0 |
| Precision | Recall | F1 | Accuracy | AP | ROC-AUC | FPR | FNR | |
|---|---|---|---|---|---|---|---|---|
| Image-to-image (I2I) | 0.97 | 0.97 | 0.97 | 0.9690 | 0.9961 | 0.9957 | 0.032 | 0.03 |
| Sketch-to-image (S2I) | 0.98 | 0.98 | 0.98 | 0.9790 | 0.9977 | 0.9974 | 0.012 | 0.03 |
| Text-to-image (T2I) | 0.98 | 0.98 | 0.98 | 0.9835 | 0.9991 | 0.9990 | 0.003 | 0.03 |
| Input Modality | Precision | Recall | F1 | Accuracy | AP | ROC-AUC | FPR | FNR | |
|---|---|---|---|---|---|---|---|---|---|
| OASIS [14] | I2I | 0.96 | 0.96 | 0.96 | 0.964 | 0.9958 | 0.9951 | 0.042 | 0.03 |
| CC-FPSE [15] | 0.98 | 0.98 | 0.98 | 0.983 | 0.9983 | 0.9981 | 0.004 | 0.03 | |
| SPADE [16] | 0.98 | 0.98 | 0.98 | 0.978 | 0.9979 | 0.9977 | 0.014 | 0.03 | |
| Taming-transformers [17] | 0.95 | 0.95 | 0.95 | 0.951 | 0.9928 | 0.9920 | 0.068 | 0.03 | |
| S2I-DetectoRS [18] | S2I | 0.98 | 0.98 | 0.98 | 0.981 | 0.9977 | 0.9974 | 0.008 | 0.03 |
| S2I-HTC [18] | 0.98 | 0.98 | 0.98 | 0.977 | 0.9977 | 0.9973 | 0.016 | 0.03 | |
| S2I-QueryInst [18] | 0.98 | 0.98 | 0.98 | 0.978 | 0.9977 | 0.9975 | 0.014 | 0.03 | |
| S2I-MaskRCNN [18] | 0.98 | 0.98 | 0.98 | 0.980 | 0.9978 | 0.9974 | 0.010 | 0.03 | |
| AttnGAN [19] | T2I | 0.98 | 0.98 | 0.98 | 0.984 | 0.9990 | 0.9989 | 0.002 | 0.03 |
| DM-GAN+CL [20] | 0.98 | 0.98 | 0.98 | 0.984 | 0.9996 | 0.9996 | 0.002 | 0.03 | |
| DF-GAN [21] | 0.98 | 0.98 | 0.98 | 0.982 | 0.9986 | 0.9985 | 0.006 | 0.03 | |
| ControlGAN [22] | 0.98 | 0.98 | 0.98 | 0.984 | 0.9991 | 0.9990 | 0.002 | 0.03 |
| Input Modality | Used Dataset | Precision | Recall | F1 | Accuracy | AP | ROC-AUC | FPR | FNR | |
|---|---|---|---|---|---|---|---|---|---|---|
| OASIS [14] | I2I | ADE20K [57] | 0.91 | 0.89 | 0.89 | 0.889 | 0.9839 | 0.9826 | 0.008 | 0.22 |
| S2I-DetectoRS [18] | S2I | Sketchy [58] | 0.95 | 0.94 | 0.94 | 0.943 | 0.9998 | 0.9998 | 0.0 | 0.13 |
| AttnGAN [19] | T2I | CUB-200-2011 [59] | 0.98 | 0.98 | 0.98 | 0.978 | 0.9991 | 0.9988 | 0.0 | 0.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baraheem, S.S.; Nguyen, T.V. AI vs. AI: Can AI Detect AI-Generated Images? J. Imaging 2023, 9, 199. https://doi.org/10.3390/jimaging9100199
Baraheem SS, Nguyen TV. AI vs. AI: Can AI Detect AI-Generated Images? Journal of Imaging. 2023; 9(10):199. https://doi.org/10.3390/jimaging9100199
Chicago/Turabian StyleBaraheem, Samah S., and Tam V. Nguyen. 2023. "AI vs. AI: Can AI Detect AI-Generated Images?" Journal of Imaging 9, no. 10: 199. https://doi.org/10.3390/jimaging9100199
APA StyleBaraheem, S. S., & Nguyen, T. V. (2023). AI vs. AI: Can AI Detect AI-Generated Images? Journal of Imaging, 9(10), 199. https://doi.org/10.3390/jimaging9100199