
Placental Vessel Segmentation Using Pix2pix Compared to U-Net

 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Acquisition
2.2. Network Architecture
2.2.1. U-Net
2.2.2. Pix2pix cGAN
2.2.3. Training
2.2.4. Evaluation Metrics
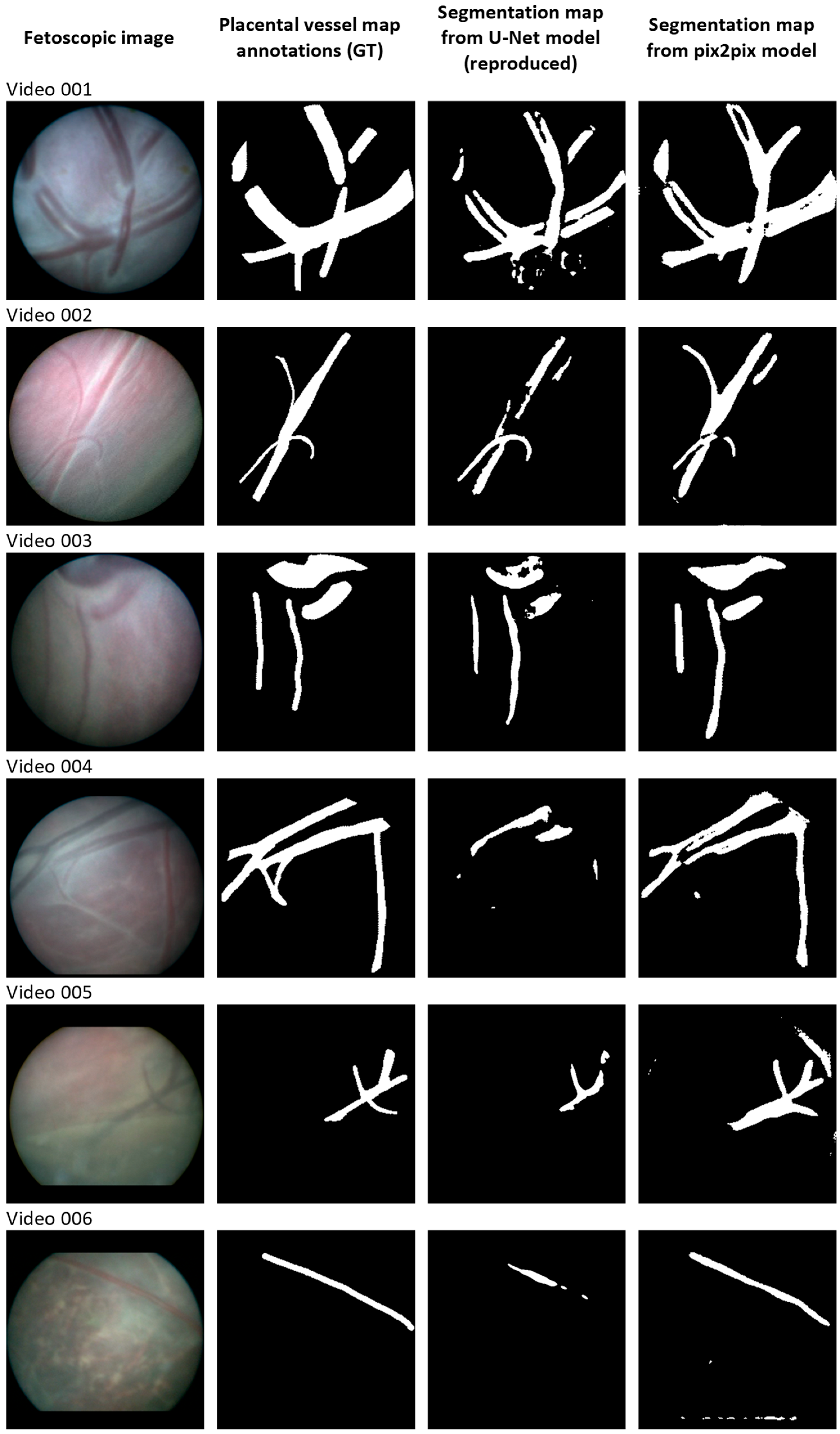
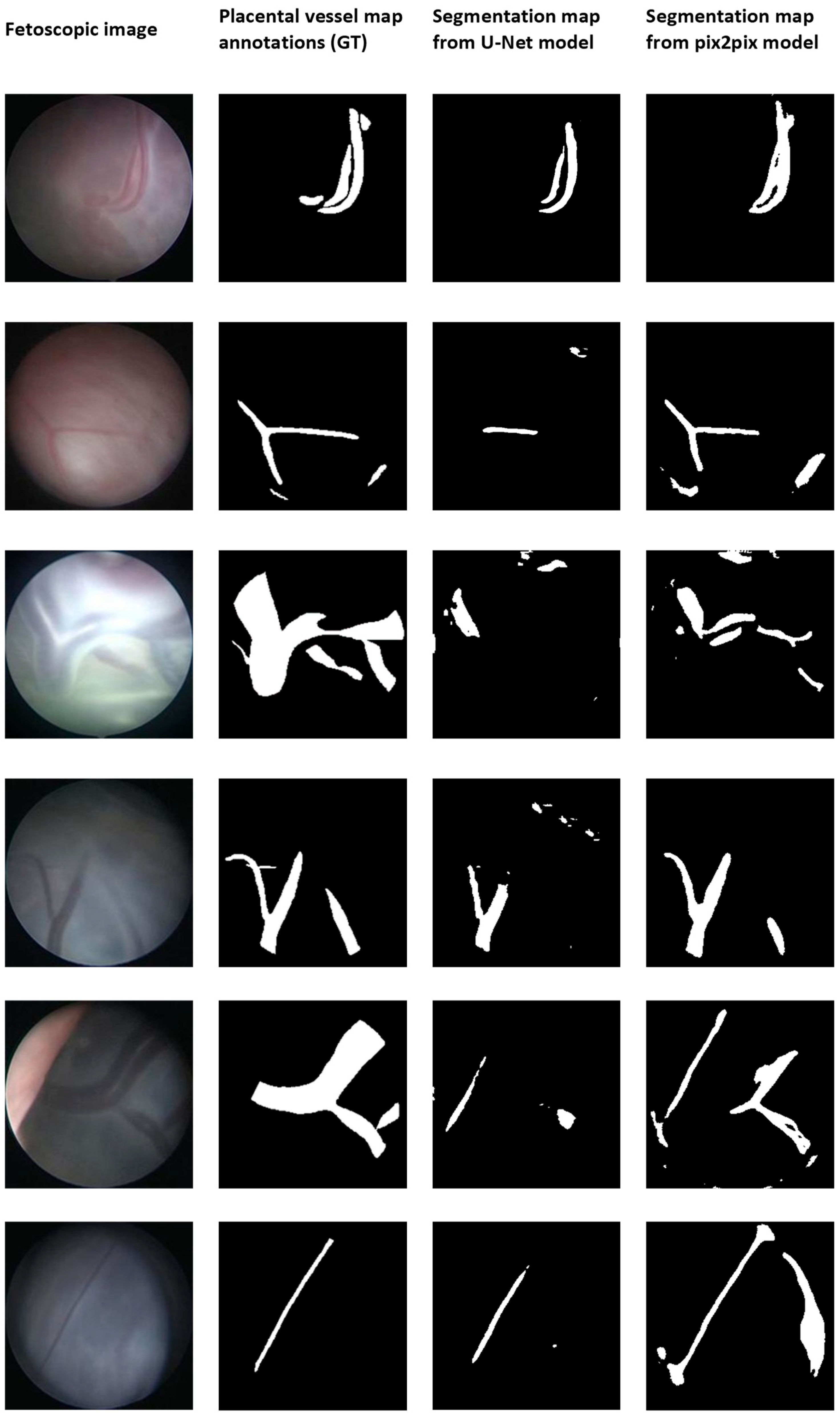
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Loss Functions
Appendix A.1.1. U-Net
Appendix A.1.2. Pix2pix
References
- Baschat, A.; Chmait, R.H.; Deprest, J.; Gratacós, E.; Hecher, K.; Kontopoulos, E.; Quintero, R.; Skupski, D.W.; Valsky, D.V. Twin-to-twin transfusion syndrome (TTTS). J. Perinat. Med. 2011, 39, 107–112. [Google Scholar] [CrossRef]
- Van der Schot, A.M.; Sikkel, E.; Spaanderman, M.E.; Vandenbussche, F.P. Computer-assisted fetal laser surgery in the treatment of twin-to-twin transfusion syndrome: Recent trends and prospects. Prenat. Diagn. 2022, 42, 1225–1234. [Google Scholar] [CrossRef] [PubMed]
- Bano, S.; Vasconcelos, F.; Shepherd, L.M.; Poorten, E.V.; Vercauteren, T.; Ourselin, S.; David, A.L.; Deprest, J.; Stoyanov, D. Deep placental vessel segmentation for fetoscopic mosaicking. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; pp. 763–773. [Google Scholar]
- Bano, S.; Casella, A.; Vasconcelos, F.; Qayyum, A.; Benzinou, A.; Mazher, M.; Meriaudeau, F.; Lena, C.; Cintorrino, I.A.; De Paolis, G.R. FetReg2021: A Challenge on Placental Vessel Segmentation and Registration in Fetoscopy. arXiv 2022, arXiv:2206.12512. [Google Scholar] [CrossRef]
- Patnaik, P.; Khodee, A.; Vasam, G.; Mukherjee, A.; Salsabili, S.; Ukwatta, E.; Grynspan, D.; Chan, A.D.; Bainbridge, S. Automated Detection of Maternal Vascular Malperfusion Lesions of the Placenta using Machine Learning. medRxiv 2023, 2023.2006. [Google Scholar]
- Rabbani, A.; Babaei, M. Resolution enhancement of placenta histological images using deep learning. arXiv 2022, arXiv:2208.00163. [Google Scholar]
- Rabbani, A.; Babaei, M.; Gharib, M. Automated segmentation and morphological characterization of placental intervillous space based on a single labeled image. Micron 2023, 169, 103448. [Google Scholar] [CrossRef] [PubMed]
- Salsabili, S.; Mukherjee, A.; Ukwatta, E.; Chan, A.D.; Bainbridge, S.; Grynspan, D. Automated segmentation of villi in histopathology images of placenta. Comput. Biol. Med. 2019, 113, 103420. [Google Scholar] [CrossRef] [PubMed]
- Sadda, P.; Imamoglu, M.; Dombrowski, M.; Papademetris, X.; Bahtiyar, M.O.; Onofrey, J. Deep-learned placental vessel segmentation for intraoperative video enhancement in fetoscopic surgery. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 227–235. [Google Scholar] [CrossRef] [PubMed]
- Casella, A.; Moccia, S.; Cintorrino, I.A.; De Paolis, G.R.; Bicelli, A.; Paladini, D.; De Momi, E.; Mattos, L.S. Deep-Learning Architectures for Placenta Vessel Segmentation in TTTS Fetoscopic Images. In Proceedings of the International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; pp. 145–153. [Google Scholar]
- Bano, S.; Casella, A.; Vasconcelos, F.; Moccia, S.; Attilakos, G.; Wimalasundera, R.; David, A.L.; Paladini, D.; Deprest, J.; De Momi, E. FetReg: Placental vessel segmentation and registration in fetoscopy challenge dataset. arXiv 2021, arXiv:2106.05923. [Google Scholar] [CrossRef]
- Xun, S.; Li, D.; Zhu, H.; Chen, M.; Wang, J.; Li, J.; Chen, M.; Wu, B.; Zhang, H.; Chai, X. Generative adversarial networks in medical image segmentation: A review. Comput. Biol. Med. 2022, 140, 105063. [Google Scholar] [CrossRef] [PubMed]
- Popescu, D.; Deaconu, M.; Ichim, L.; Stamatescu, G. Retinal blood vessel segmentation using pix2pix gan. In Proceedings of the 29th Mediterranean Conference on Control and Automation (MED), Puglia, Italy, 22–25 June 2021; pp. 1173–1178. [Google Scholar]
- Son, J.; Park, S.J.; Jung, K.-H. Towards accurate segmentation of retinal vessels and the optic disc in fundoscopic images with generative adversarial networks. J. Digit. Imaging 2019, 32, 499–512. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Jaccard, P. The distribution of the flora in the alpine zone. 1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Tsuda, H.; Hotta, K. Cell image segmentation by integrating pix2pixs for each class. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1065–1073. [Google Scholar]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-net and its variants for medical image segmentation: A review of theory and applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced pix2pix dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8160–8168. [Google Scholar]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for infrared small object detection. IEEE Trans. Image Process. 2022, 32, 364–376. [Google Scholar] [CrossRef] [PubMed]
- Casella, A.; Moccia, S.; Paladini, D.; Frontoni, E.; De Momi, E.; Mattos, L.S. A shape-constraint adversarial framework with instance-normalized spatio-temporal features for inter-fetal membrane segmentation. Med. Image Anal. 2021, 70, 102008. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| No. of Validation Images | Evaluation Metrics | Bano et al. (Baseline) | U-Net Model (Reproduced) | Pix2pix Model | Wilcoxon Signed Rank Test (p-Value) | |
|---|---|---|---|---|---|---|
| Fold 1 | 120 | Dice | 0.85 ± 0.07 | 0.83 [0.74; 0.87] | 0.86 [0.82; 0.88] | <0.01 |
| IoU | 0.74 ± 0.10 | 0.74 [0.64; 0.79] | 0.77 [0.73; 0.80] | <0.01 | ||
| Fold 2 | 101 | Dice | 0.77 ± 0.16 | 0.81 [0.73; 0.85] | 0.81 [0.74; 0.86] | 0.97 |
| IoU | 0.64 ± 0.17 | 0.72 [0.64; 0.77] | 0.71 [0.64; 0.77] | 0.59 | ||
| Fold 3 | 39 | Dice | 0.83 ± 0.08 | 0.83 [0.78; 0.89] | 0.85 [0.78; 0.88] | 0.66 |
| IoU | 0.72 ± 0.12 | 0.74 [0.68; 0.81] | 0.75 [0.68; 0.81] | 0.47 | ||
| Fold 4 | 88 | Dice | 0.75 ± 0.18 | 0.51 [0.48; 0.61] | 0.72 [0.60; 0.81] | <0.01 |
| IoU | 0.62 ± 0.20 | 0.49 [0.45; 0.54] | 0.63 [0.53; 0.72] | <0.01 | ||
| Fold 5 | 37 | Dice | 0.70 ± 0.18 | 0.75 [0.62; 0.83] | 0.70 [0.67; 0.76] | 0.22 |
| IoU | 0.56 ± 0.19 | 0.65 [0.53; 0.73] | 0.62 [0.56; 0.66] | 0.05 | ||
| Fold 6 | 97 | Dice | 0.75 ± 0.12 | 0.72 [0.60; 0.76] | 0.73 [0.65; 0.80] | <0.01 |
| IoU | 0.62 ± 0.15 | 0.62 [0.53; 0.67] | 0.63 [0.57; 0.70] | 0.01 | ||
| Overall | 483 | Dice | 0.78 ± 0.13 | 0.75 [0.60; 0.84] | 0.80 [0.70; 0.86] | <0.01 |
| IoU | 0.66 ± 0.15 | 0.66 [0.53; 0.75] | 0.70 [0.61; 0.77] | <0.01 | ||
| Internal validation dataset | 245 | Dice | - | 0.53 [0.49; 0.64] | 0.68 [0.53; 0.79] | <0.01 |
| IoU | - | 0.49 [0.17; 0.56] | 0.59 [0.49; 0.69] | <0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van der Schot, A.; Sikkel, E.; Niekolaas, M.; Spaanderman, M.; de Jong, G. Placental Vessel Segmentation Using Pix2pix Compared to U-Net. J. Imaging 2023, 9, 226. https://doi.org/10.3390/jimaging9100226
van der Schot A, Sikkel E, Niekolaas M, Spaanderman M, de Jong G. Placental Vessel Segmentation Using Pix2pix Compared to U-Net. Journal of Imaging. 2023; 9(10):226. https://doi.org/10.3390/jimaging9100226
Chicago/Turabian Stylevan der Schot, Anouk, Esther Sikkel, Marèll Niekolaas, Marc Spaanderman, and Guido de Jong. 2023. "Placental Vessel Segmentation Using Pix2pix Compared to U-Net" Journal of Imaging 9, no. 10: 226. https://doi.org/10.3390/jimaging9100226