

Motion Vector Extrapolation for Video Object Detection


Abstract
:1. Introduction
- 1.
- A novel parallelism-based approach for incorporating motion vector data with CNN object detection, bypassing the existing bottleneck associated with high-latency DNN inferencing currently present in existing single-threaded motion-based detection and tracking methodologies;
- 2.
- A comparative analysis demonstrating that motion vectors stored as part of the video encoding, when utilized as a coarse approximation to optical flow, can be effective for frame-by-frame motion prediction while maintaining backward compatibility for current state-of-the-art dense optical flow methods such as FlowNet2.0 [10] with this methodology;
- 3.
- A comprehensive evaluation across multiple datasets that demonstrates the efficacy of the approach in reducing object detection latency in video while quantifying the accuracy impacts. (Sample characteristic curves are provided for understanding the trade-off between latency and accuracy.)
2. Related Work
- Compute object detection;
- Compute data association from the previously observed data.
2.1. Object Detection Approaches
2.1.1. Faster R-CNN
2.1.2. YOLOv4
2.2. Motion Vector-Based Object Tracking
2.3. Deep Feature Flow
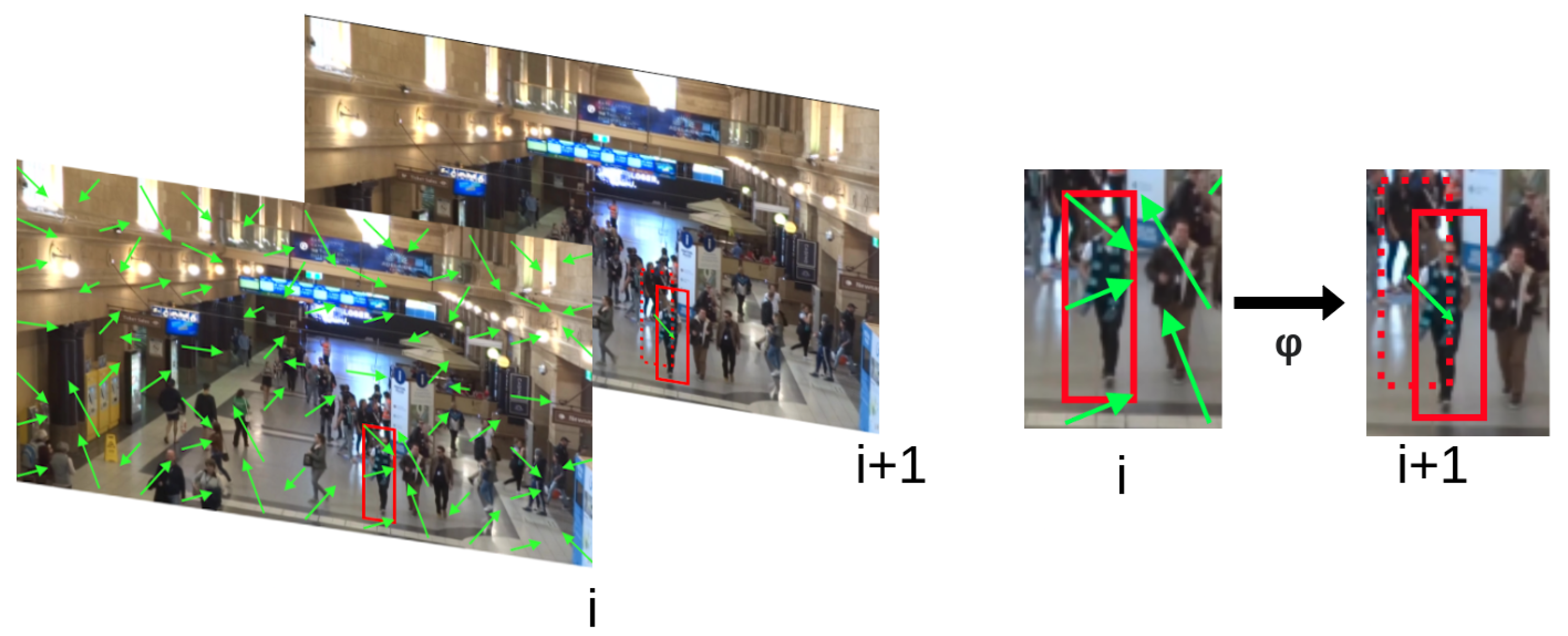
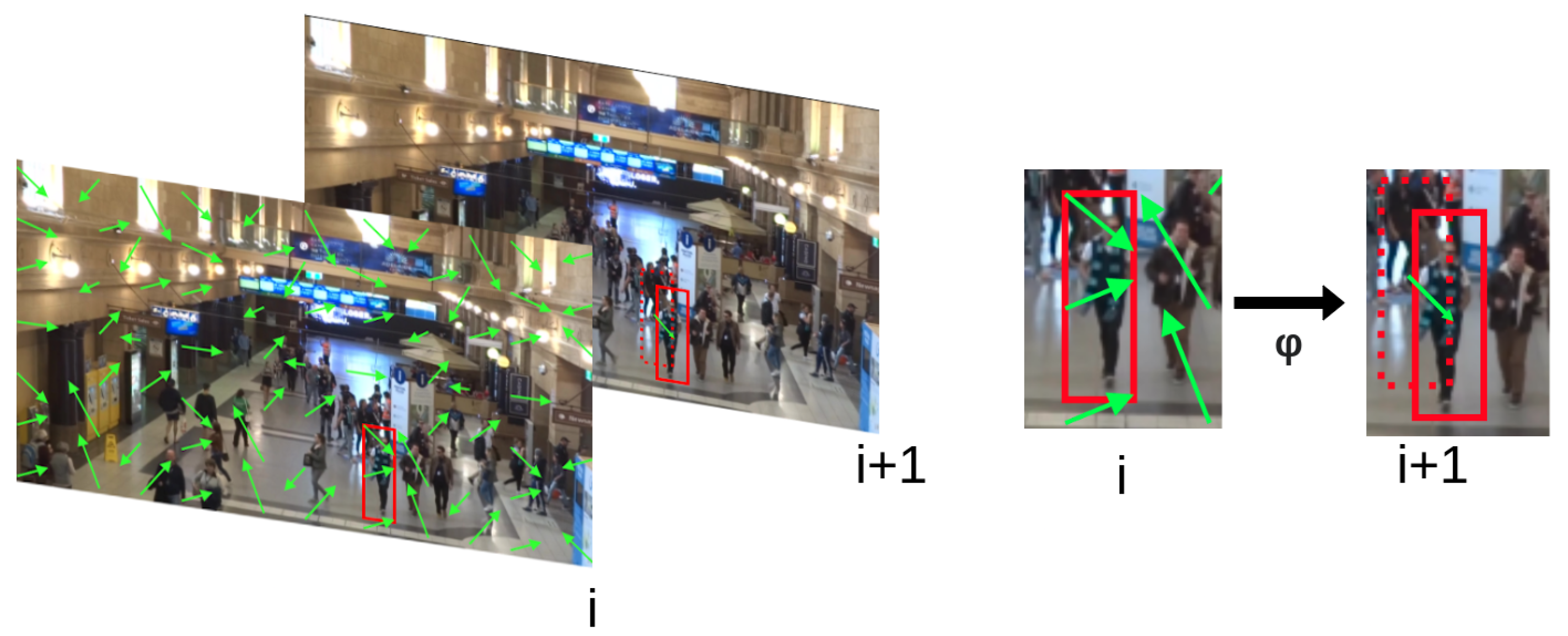
3. Motion Vector Extrapolation (MOVEX)
- 1.
- Motion vectors stored as part of the video encoding are evaluated as a coarse approximation to optical flow while maintaining backward compatibility for dense optical flow methods such as FlowNet2.0 [10].
- 2.
- The sparse feature propagation function is reimagined as statistical aggregation followed by perturbation. This has the benefit of not requiring a GPU to perform pixel-wise computations for propagating features to the next frame, as required by the original technique [12].
- 3.
- A parallelism strategy building on the sparse feature propagation idea was implemented to remove the bottleneck of key frame computation present in the original sparse feature propagation approach. This method is called optimistic sparse detection propagation.
3.1. Coarse Optimal Flow Approximation
3.2. Optimistic Sparse Detection Propagation
4. Experiments
4.1. Set-Up
4.2. Evaluations
- 1.
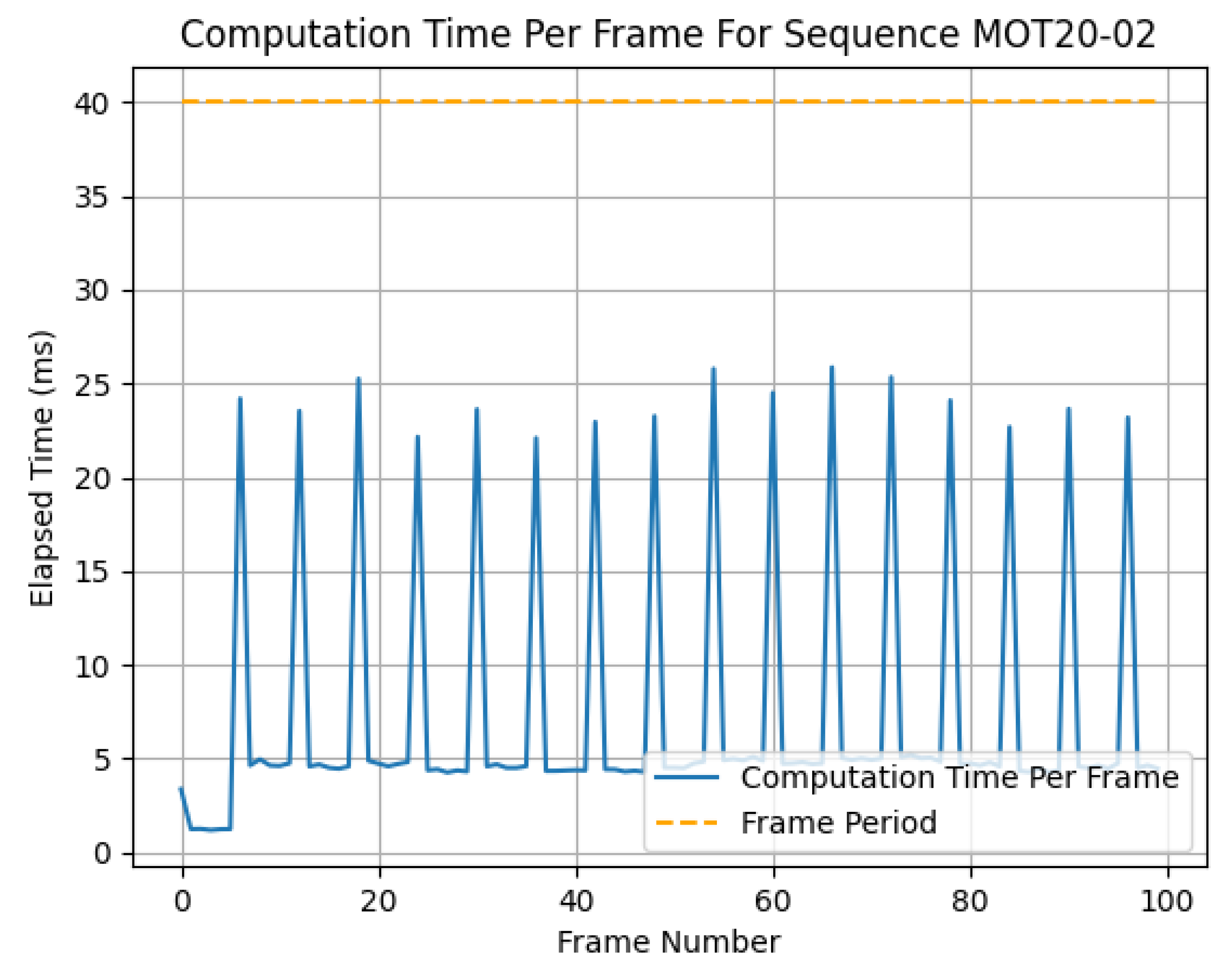
- Object detector latency versus accuracy: we show the latency decrease versus the accuracy characteristics of the technique.
- 2.
- H.264 motion vectors and flowNet2.0: we show the performance implications of using H.264 motion vectors as opposed to a state-of-the-art method such as FlowNet2.0 [9].
- 3.
- High-resolution versus low-resolution object detection models: we show the viability of increasing the accuracy while decreasing the latency through the use of higher-input resolution models.
- 4.
- Object detection model inference on a CPU versus a GPU: we show the impacts of running the object detection model on a CPU instead of a GPU.
- 1.
- Global frame compensation was removed from the SPDF so that only the motion vectors located inside a given detection were considered in the propagating detections. We expected that through removing this component, the performance on the MOT20 dataset would remain roughly the same as there was very little camera movement. However, we expected that the performance on the MOT16 dataset would fall since there was a significant amount of camera movement in half the video sequences.
- 2.
- 3.
- The aggregation function was replaced with a center sample approach to aggregating motion vectors. Rather than considering all motion vectors contained in a detection, only the center-most motion vector was considered. This test was performed in order to assess the impact of aggregation on the performance of the detection propagation function.
- 4.
- Detection propagation based on motion vectors was removed entirely, and instead, individual detections were persisted in place until a new detection was received, hence demonstrating the efficacy of the SPDF in its entirety. It was our expectation to see the performance fall significantly in the MOT16 dataset with this ablation, as that dataset has a great deal of variation from frame to frame. We also expected a less significant yet still large drop in accuracy in the MOT20 dataset. The reason we expected this is due to the sheer volume of the detection targets per frame moving in many different directions, as well as the associated occlusions.
- 5.
- The encoding quality was varied from high- to low-quality H.264 encodings as defined by the FFMPEG presets for the H.264 codec [34]. Not every application is able to use the specific encoding described in our approach, and as such, we quantified the effects the encoding quality had on MOVEX based on said common FFMPEG presets.
5. Results and Discussion
5.1. Object Detector Latency versus Accuracy and Overall Latency
5.2. H.264 Motion Vectors and FlowNet2.0
5.3. High-Resolution versus Low-Resolution Object Detection Models
5.4. Object Detection Model Inference on the CPU versus the GPU
5.5. Ablation Study
5.5.1. Global Frame Compensation
5.5.2. Multi-Processing
5.5.3. Aggregation Function
5.5.4. Detection Propagation
5.5.5. Encoding Quality
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Park, H.J.; Kang, J.W.; Kim, B.G. ssFPN: Scale Sequence (S 2) Feature-Based Feature Pyramid Network for Object Detection. Sensors 2023, 23, 4432. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Pandey, V.; Anand, K.; Kalra, A.; Gupta, A.; Roy, P.P.; Kim, B.G. Enhancing object detection in aerial images. Math. Biosci. Eng. 2022, 19, 7920–7932. [Google Scholar] [CrossRef] [PubMed]
- Mao, H.; Yang, X.; Dally, W.J. A delay metric for video object detection: What average precision fails to tell. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 573–582. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1655. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Häusser, P.; Hazirbas, C.; Golkov, V.v.d.; Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Dai, J.; Yuan, L.; Wei, Y. Towards High Performance Video Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7210–7218. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep Feature Flow for Video Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4141–4150. [Google Scholar] [CrossRef] [Green Version]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S. MOTChallenge 2015: Towards a Benchmark for Multi-Target Tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. MOT20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]
- Krebs, S.; Duraisamy, B.; Flohr, F. A survey on leveraging deep neural networks for object tracking. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 411–418. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ujiie, T.; Hiromoto, M.; Sato, T. Interpolation-Based Object Detection Using Motion Vectors for Embedded Real-Time Tracking Systems. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, Q.; Liu, B.; Wu, Y.; Li, W.; Yu, N. Real-Time Online Multi-Object Tracking in Compressed Domain. IEEE Access 2019, 7, 76489–76499. [Google Scholar] [CrossRef]
- Tabani, H.; Fusi, M.; Kosmidis, L.; Abella, J.; Cazorla, F.J. IntPred: Flexible, Fast, and Accurate Object Detection for Autonomous Driving Systems. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, SAC’20, New York, NY, USA, 30 March–3 April 2020; pp. 564–571. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- JV Team. Draft ITU-T Recommendation and Final Draft International Standard of Joint Video Specification. ITU-T Rec. H.264 2003. Available online: https://www.itu.int/wftp3/av-arch/jvt-site/2003_09_SanDiego/JVT-I023r1.doc (accessed on 11 May 2023).
- You, W.; Sabirin, H.; Kim, M. Moving object tracking in H.264/AVC bitstream. In Proceedings of the Multimedia Content Analysis and Mining: International Workshop, MCAM 2007, Weihai, China, 30 June–1 July 2007; Volume 4577, pp. 483–492. [Google Scholar] [CrossRef] [Green Version]
- Milan, A.; Leal-Taixe, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Menze, M.; Heipke, C.; Geiger, A. Object Scene Flow. ISPRS J. Photogramm. Remote Sens. (JPRS) 2018, 140, 60–76. [Google Scholar] [CrossRef]
- Menze, M.; Heipke, C.; Geiger, A. Joint 3D Estimation of Vehicles and Scene Flow. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 427. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. POI: Multiple Object Tracking with High Performance Detection and Appearance Feature. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–16 October 2016; Hua, G., Jégou, H., Eds.; Springer: Cham, Switzerland, 2016; pp. 36–42. [Google Scholar]
- FFMPEG Documentation. Available online: https://ffmpeg.org/ffmpeg.html (accessed on 11 May 2023).
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; Proceedings Part VI 12; Springer: Berlin/Heidelberg, Germany, 2012; pp. 611–625. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Resolution | Dense Flow Vectors | 16 × 16 MVs |
|---|---|---|
| 9.216 × | 3600 | |
| 8100 | ||
| 32,400 |
| Method | Dataset | Avg Latency (ms) ↓ | AP ↑ |
|---|---|---|---|
| FRCNN [14] | MOT20 | ||
| FRCNN [14] with MOVEX + FlowNet2 | MOT20 | ||
| FRCNN [14] with MOVEX + H.264 MVs | MOT20 | ||
| YOLOv4 [1] (960 × 960) | MOT20 | ||
| YOLOv4 [1] (960 × 960) | MOT20 | ||
| with MOVEX + H.264 MVs | |||
| YOLOv4 [1] (416 × 416) | MOT20 | ||
| YOLOv4 [1] (416 × 416) on CPU | MOT20 | ||
| YOLOv4 [1] (416 × 416) on CPU | MOT20 | ||
| with MOVEX + H.264 MVs | |||
| FRCNN [33] | MOT16 | ||
| FRCNN [33] with MOVEX + FlowNet2 | MOT16 | ||
| FRCNN [33] with MOVEX + H.264 MVs | MOT16 | ||
| YOLOv4 [1] (960 × 960) | MOT16 | ||
| YOLOv4 [1] (960 × 960) | MOT16 | ||
| with MOVEX + H.264 MVs | |||
| YOLOv4 [1] (416 × 416) | MOT16 | ||
| YOLOv4 [1] (416 × 416) on CPU | MOT16 | ||
| YOLOv4 [1] (416 × 416) on CPU | MOT16 | ||
| with MOVEX + H.264 MVs |
| Method | Dataset | Avg Latency (ms) | AP |
|---|---|---|---|
| Proposed | MOT20 [14] | ||
| Without Global Comp | MOT20 [14] | ||
| Proposed | MOT16 [30] | ||
| Without Global Comp | MOT16 [30] |
| Method | Dataset | Avg Latency (ms) | AP |
|---|---|---|---|
| Proposed | MOT20 [14] | ||
| Fifth Frame | MOT20 [14] | ||
| Tenth Frame | MOT20 [14] | ||
| Proposed | MOT16 [30] | ||
| Fifth Frame | MOT16 [30] | ||
| Tenth Frame | MOT16 [30] |
| Method | Dataset | Avg Latency (ms) | AP |
|---|---|---|---|
| Proposed (Median) | MOT20 [14] | ||
| Center Sample | MOT20 [14] | ||
| Proposed (Median) | MOT16 [30] | ||
| Center Sample | MOT16 [30] |
| Method | Dataset | Avg Latency (ms) | AP |
|---|---|---|---|
| Proposed | MOT20 [14] | ||
| No Perturbation | MOT20 [14] | ||
| Proposed | MOT16 [30] | ||
| No Perturbation | MOT16 [30] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
True, J.; Khan, N. Motion Vector Extrapolation for Video Object Detection. J. Imaging 2023, 9, 132. https://doi.org/10.3390/jimaging9070132
True J, Khan N. Motion Vector Extrapolation for Video Object Detection. Journal of Imaging. 2023; 9(7):132. https://doi.org/10.3390/jimaging9070132
Chicago/Turabian StyleTrue, Julian, and Naimul Khan. 2023. "Motion Vector Extrapolation for Video Object Detection" Journal of Imaging 9, no. 7: 132. https://doi.org/10.3390/jimaging9070132
APA StyleTrue, J., & Khan, N. (2023). Motion Vector Extrapolation for Video Object Detection. Journal of Imaging, 9(7), 132. https://doi.org/10.3390/jimaging9070132