
A Comparative Study of YOLO, SSD, Faster R-CNN, and More for Optimized Eye-Gaze Writing



Abstract
1. Introduction
- Applying computer vision and machine learning models to increase the speed of the eye-gaze writing: We evaluate the efficiency of deep learning algorithms for real-time eye-gaze writing, aiming to enhance both speed and accuracy. Specifically, we assess three object detection models —- YoLOv8, SSD, and Faster R-CNN- to address the challenge of detecting the small iris with high precision. For image segmentation, we employ DeepLab and U-Net to improve robustness in scenarios where users wear glasses or makeup or have eye conditions such as amblyopia or strabismus. Additionally, we explore SimCLR for self-supervised learning to enhance feature representation without requiring extensive labeled data.
- Overcome the limitations of eye-gaze writing: Eye-tracking technology struggles in low light conditions or when users experience eye fatigue, irritation, excessive head motion, or blinking, affecting accuracy [2]. To address these challenges, we create a new dataset by combining multiple datasets, providing diverse training data for various eye states and lighting conditions.
- Overcome fatigue caused by blinking: To overcome fatigue caused by blinking for a significant amount of time, we design our models to focus on a letter for seconds so that the letter will be written and cancel blinking.
2. Related Work
2.1. Pupil Center Corneal Reflection Technique (PCCR)
2.2. Appearance-Based Methods
2.3. Saccadic and Fixational Analysis
2.4. Model-Based Methods
2.5. The Haar Cascade Classifier
3. Methodology
3.1. Workflow Overview
3.2. Datasets and Data Preprocessing
- Eyes Dataset and Dataset-Pupil: applied Gaussian blur (kernel size: 0–1.25 pixels) to reduce noise and brightness adjustments (−25% to +25%) to simulate varying lighting conditions.
- Pupil Detection Computer Vision Project: introduced diverse augmentations, including brightness adjustments (−5% to +5%), cropping (0−5%) for occlusion handling, rotations (−10° to +10°) for camera angle variations, and exposure adjustments (−3% to +3%).
- Pupils Computer Vision Project: converted images to grayscale to remove color dependency, supplemented by Gaussian blur and brightness adjustments to enhance generalization.

3.3. Proposed Gaze Prediction Models
3.4. Model Selection
- YOLOv8: Balances speed and accuracy, making it ideal for real-time applications.
- SSD: efficiently detects objects in a single forward pass, reducing computational cost.
- Faster R-CNN: achieves high detection accuracy, particularly for small objects like pupils, though with longer inference times.
- DeepLabv3: excels in semantic segmentation, improving precise boundary detection of the pupil.
- U-Net: well suited for detailed segmentation tasks, commonly used in medical imaging.
- SimCLR: Enhances feature extraction using contrastive learning, beneficial when labeled data are limited.
3.4.1. YOLO: You Only Look Once
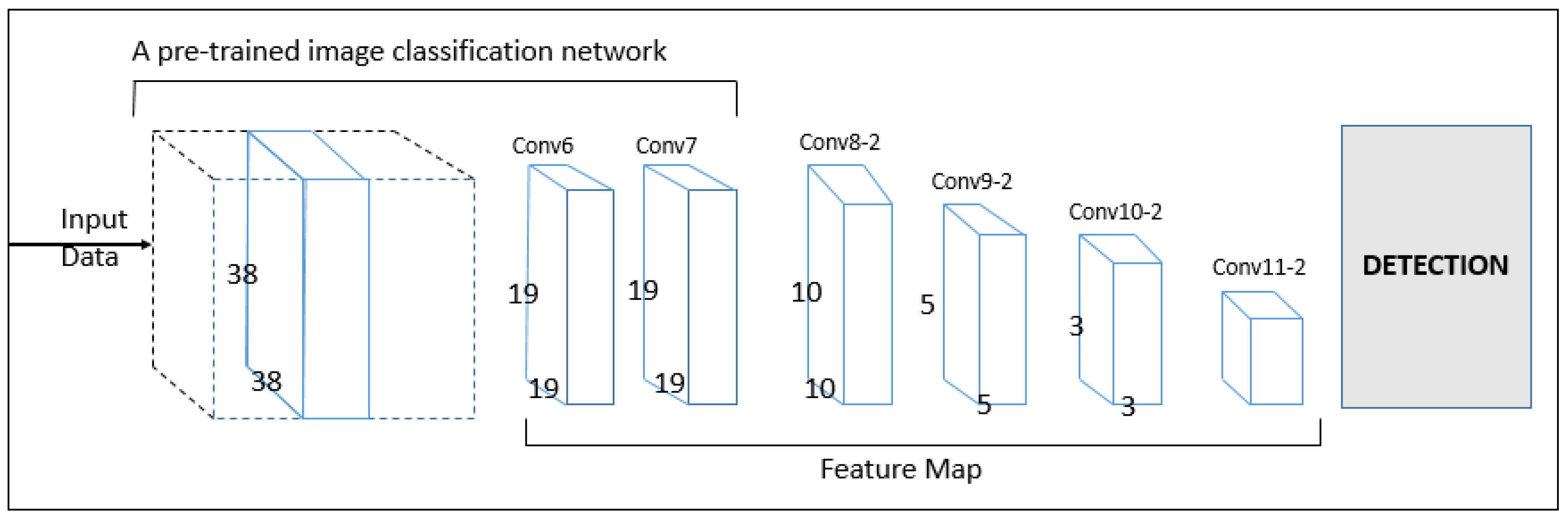
3.4.2. SSD: Single Shot Multi-Box Detector
3.4.3. Faster R-CNN: Faster Region-Based Convolutional Neural Network
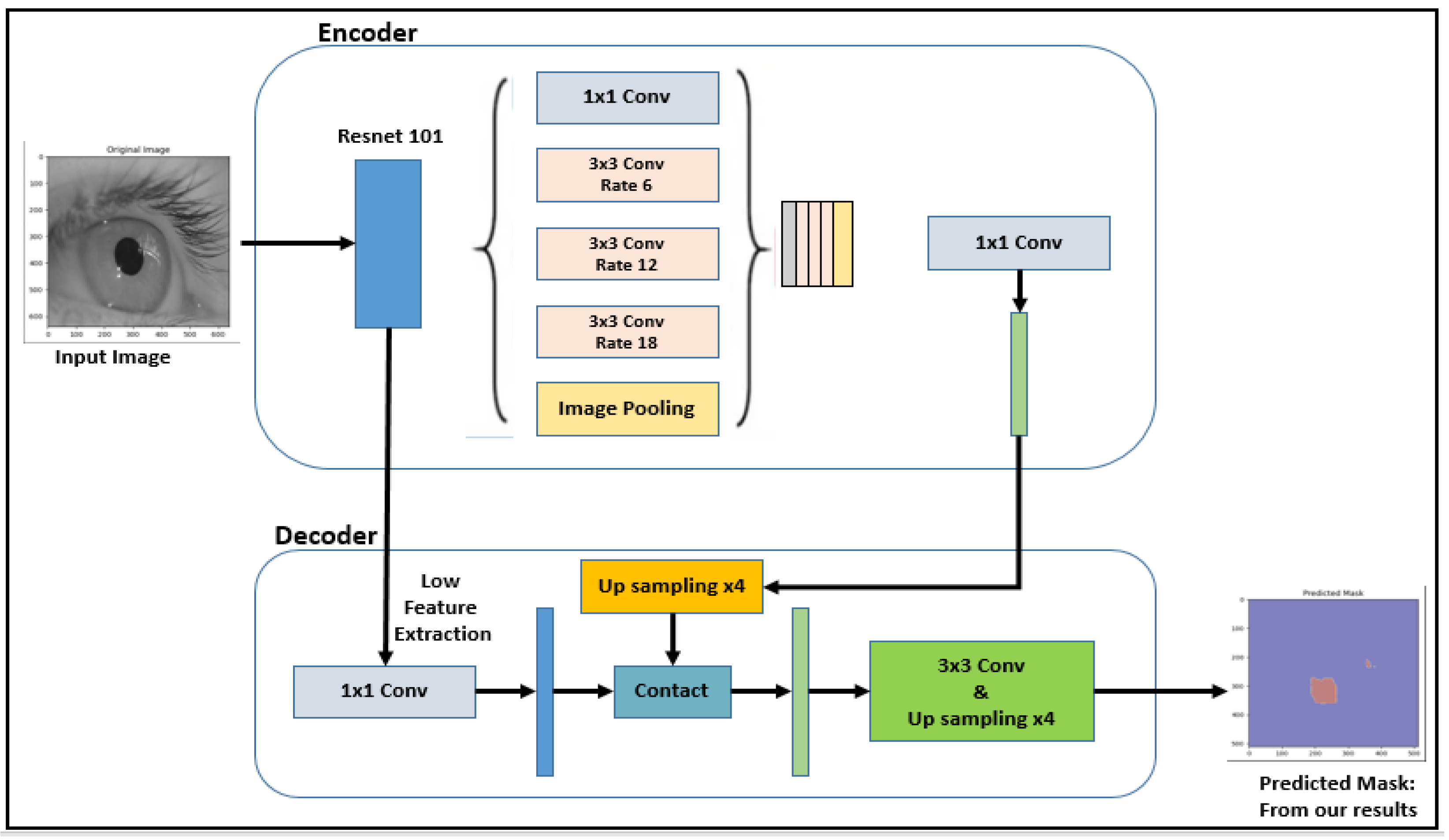
3.4.4. DeepLab: Deep Convolutional Neural Networks
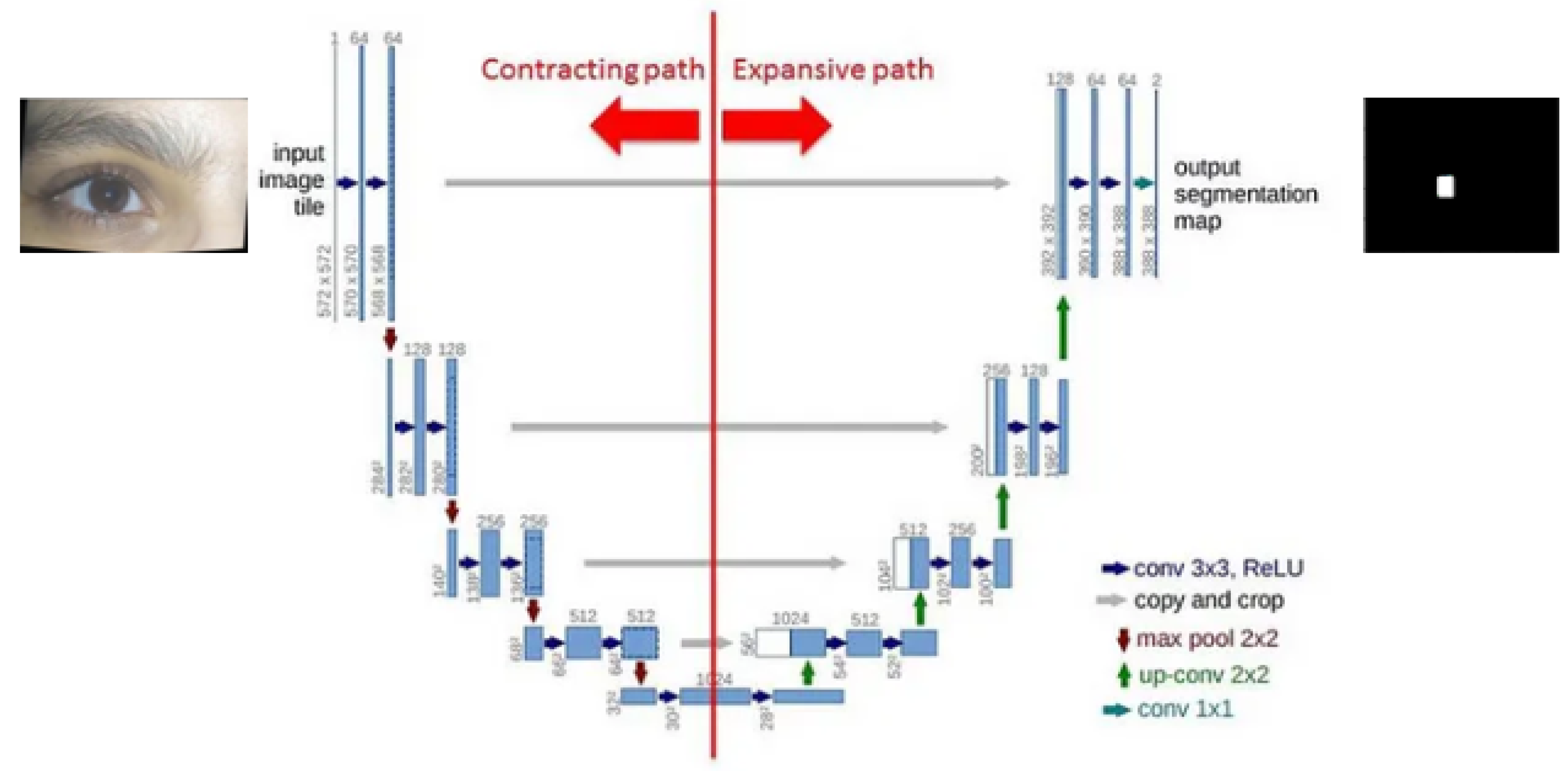
3.4.5. U-Net
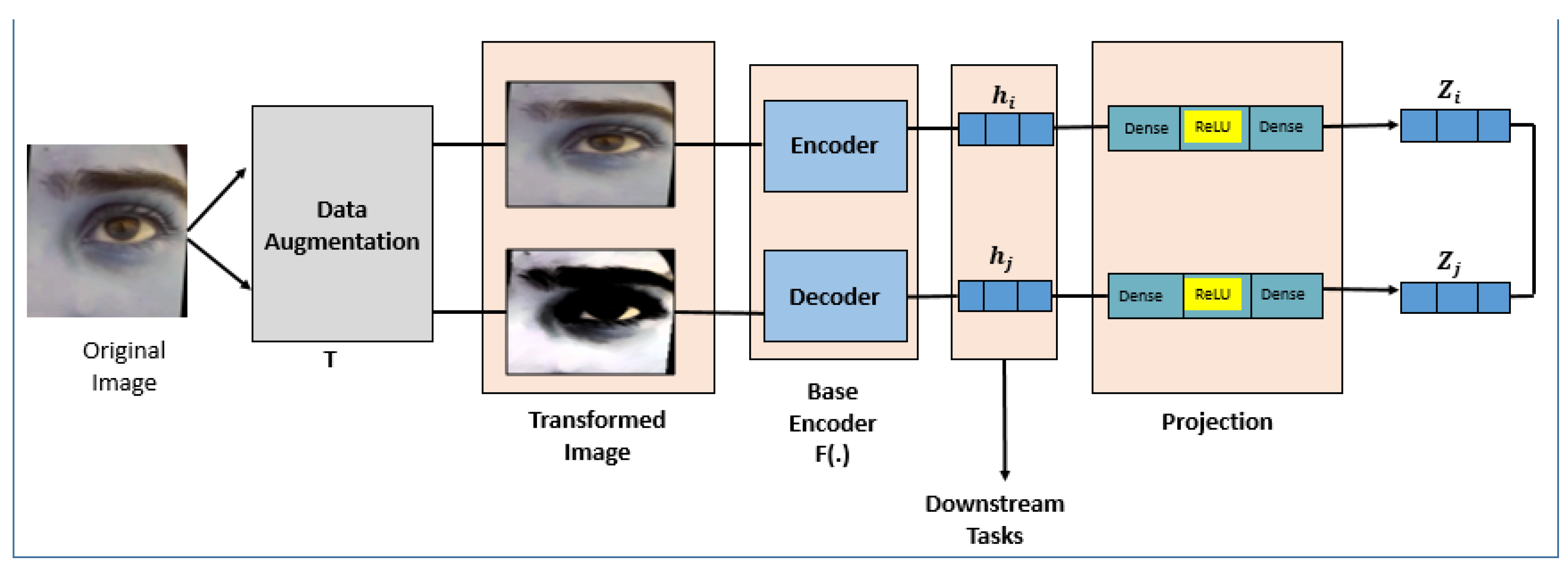
3.4.6. SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
- Data augmentation [40]: a single image is subjected to two distinct random augmentations, producing two augmented views of the original image, denoted as and .
- Base encoder [41]: Typically a convolutional neural network, the base encoder extracts high-level feature representations from the two augmented views generated in the previous step, resulting in representations and .
- Projection head: this step employs a multilayer perceptron (MLP) [42] with one hidden layer to project the feature representations and into a lower-dimensional space, facilitating the learning of more discriminative representations.
- Contrastive loss: This step optimizes the model by maximizing the similarity between positive pairs—the two augmented versions of the same image—while minimizing the similarity with negative pairs, which are augmented views of different images. Cosine similarity is used to measure the closeness between the positive pair and , ensuring the model effectively differentiates between similar and dissimilar images.
3.5. Evaluation Metrics
3.6. Experimental Setup
4. Results and Discussion
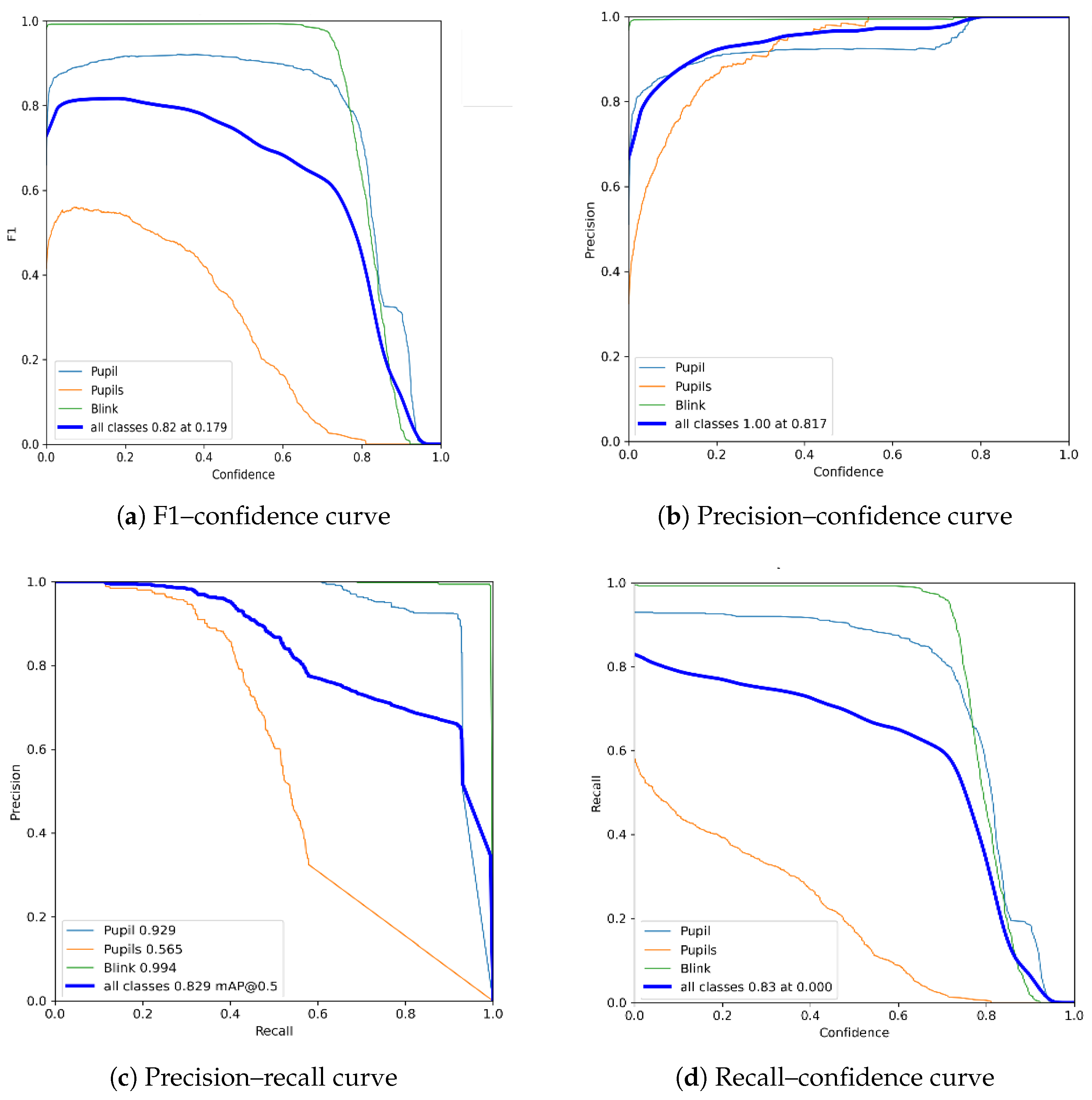
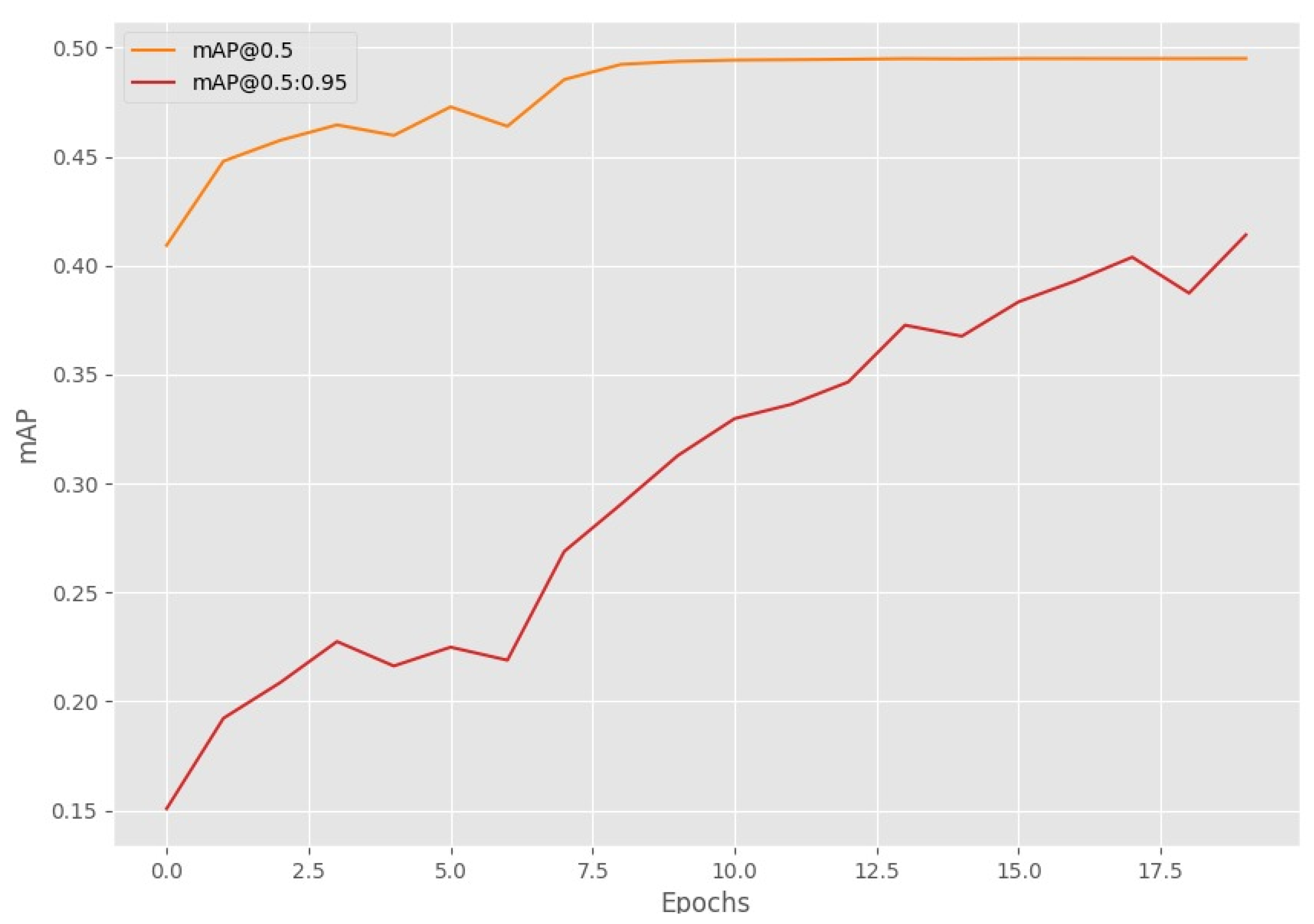
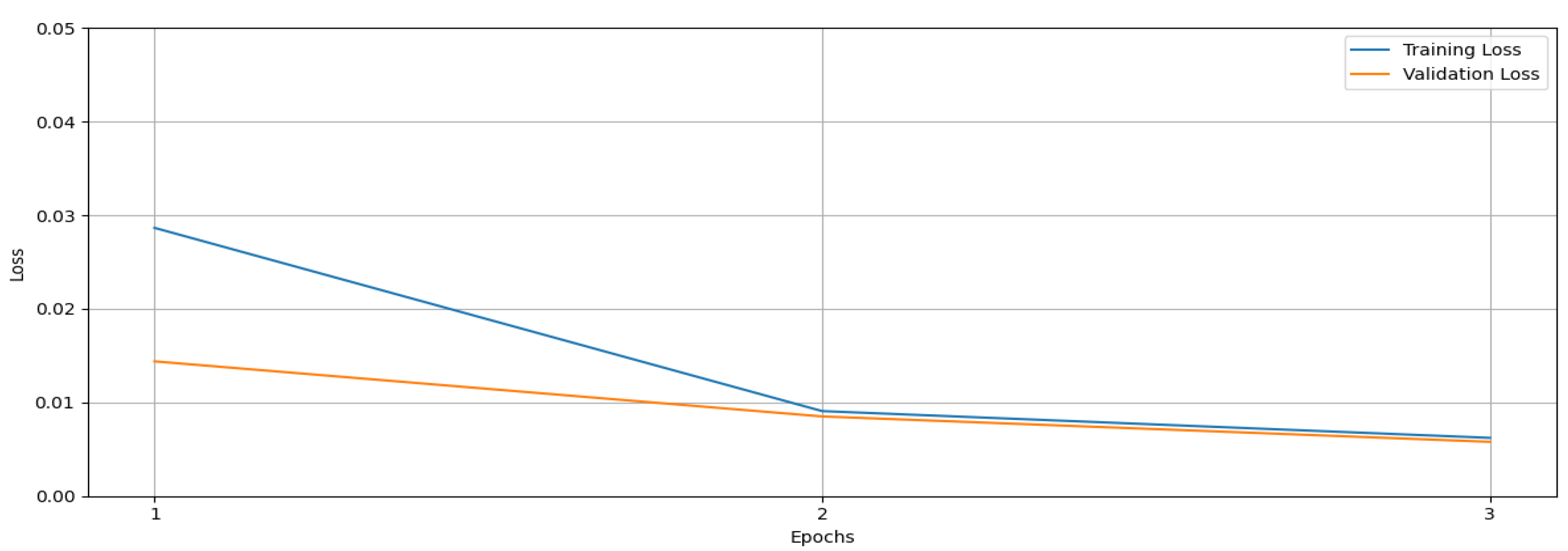
4.1. YOLOv8 Training Results
4.2. SSD Training Results
4.3. Faster R-CNN Training Results
4.4. DeepLabv3 Training Results
4.5. U-Net Training Results
4.6. SimCLR Training Results
4.7. User Testing and Evaluation
- Initial setup calibration: The system was designed to record eye-gaze direction coordinates at four specific points—upper left, upper right, lower left, and lower right—before each trial for every user. These coordinates were subsequently utilized in the calculations to determine the user’s point of gaze precisely.
- Lighting control: Participants were instructed to complete the test under consistent lighting conditions to minimize the impact of environmental factors on eye-gaze tracking accuracy.
- Position standardization: Participants were instructed to maintain a perpendicular gaze toward the camera during testing to ensure consistent alignment and reduce variations in eye-gaze tracking.
- Eyeglass reflection handling: For the participant wearing glasses, adjustments were made to minimize reflections by altering the lighting position. The user was rotated 360 degrees to identify the optimal angle that reduced glare and ensured more accurate eye-gaze tracking.
4.7.1. Test User Analysis
4.7.2. Similarity Score Analysis
- YOLO: as shown in Figure 14, Achieves a median similarity score around –, with some scores reaching . This indicates that YOLO effectively balances speed and accuracy, making it suitable for real-time applications requiring high detection precision.
- Haar: Shows a stable performance with a median similarity score around and a range between and . Its robust performance could be attributed to its feature-based approach, which works well with structured patterns, particularly in face and object detection tasks.
- DeepLab: The median similarity score is about , but the high variability (ranging from 0 to ) indicates an inconsistent performance. This variability could stem from its reliance on pixel-wise classification, which can struggle with fine object boundaries and diverse backgrounds.
- SSD: Achieves a median similarity around , reflecting a moderate performance. SSD trades off accuracy for faster inference by detecting objects in a single shot, which may explain its lower similarity scores compared to YOLO and Haar.
- U-Net: shows a lower median similarity score of about –, likely due to its design for segmentation tasks rather than object detection, making it less effective in capturing object boundaries in this context.
- SimCLR and FRCNN: Both models have similarity scores close to 0, indicating poor performance in this task. SimCLR, as a contrastive learning model, focuses on learning feature representations rather than direct object detection. Similarly, Faster R-CNN’s performance might be hindered by its complex two-stage architecture, leading to slower inference and missed detections in real-time scenarios.
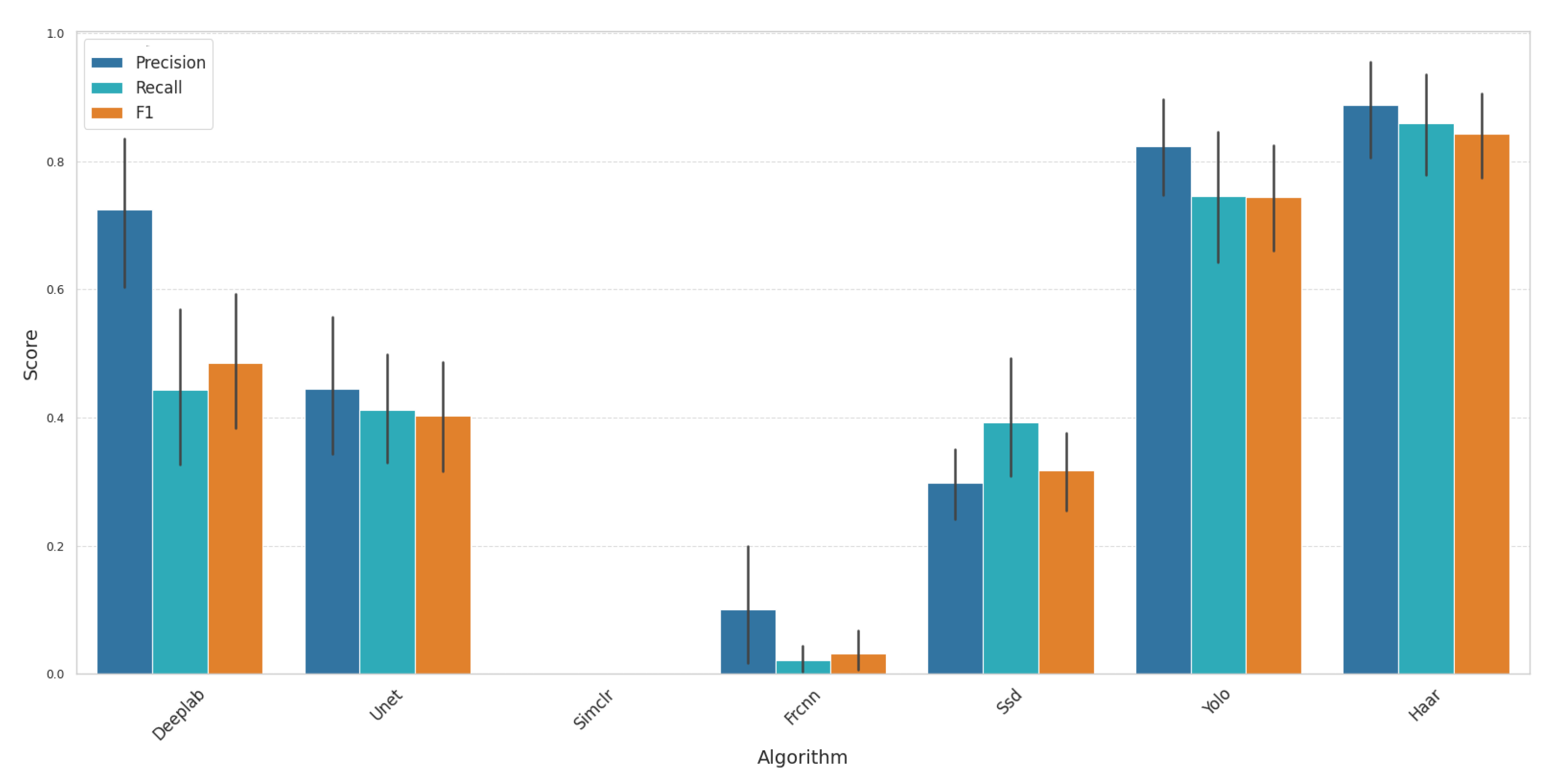
4.7.3. Precision, Recall, and F1 Score Analysis
- Haar demonstrated the best overall performance, achieving the highest scores across all metrics: precision: 0.88, recall: 0.86, and F1 score: 0.85. This can be attributed to Haar’s effective feature-based detection, which excels in structured environments with distinct object boundaries.
- YOLO also performed very well, presenting itself as a strong alternative. It achieved a precision of 0.85, a recall of 0.80, and an F1 score of 0.80. YOLO’s real-time detection capability, combined with its balance of speed and accuracy, makes it suitable for applications requiring rapid responses with reliable accuracy.
- DeepLab and U-Net showed a moderate performance but lacked consistency. DeepLab achieved a precision of 0.70, recall of 0.48, and F1 score of 0.55. These models are primarily designed for segmentation tasks, which may explain their reduced effectiveness in object detection tasks, especially in detecting fine-grained features.
- SSD, Faster R-CNN, and SimCLR performed poorly. SSD’s single-shot architecture sacrifices accuracy for speed, resulting in lower precision and recall. Faster R-CNN, despite its two-stage detection process, struggled with speed and accuracy balance, leading to suboptimal results. SimCLR showed no effectiveness in this context, as its focus on contrastive learning is less suited for direct object detection.
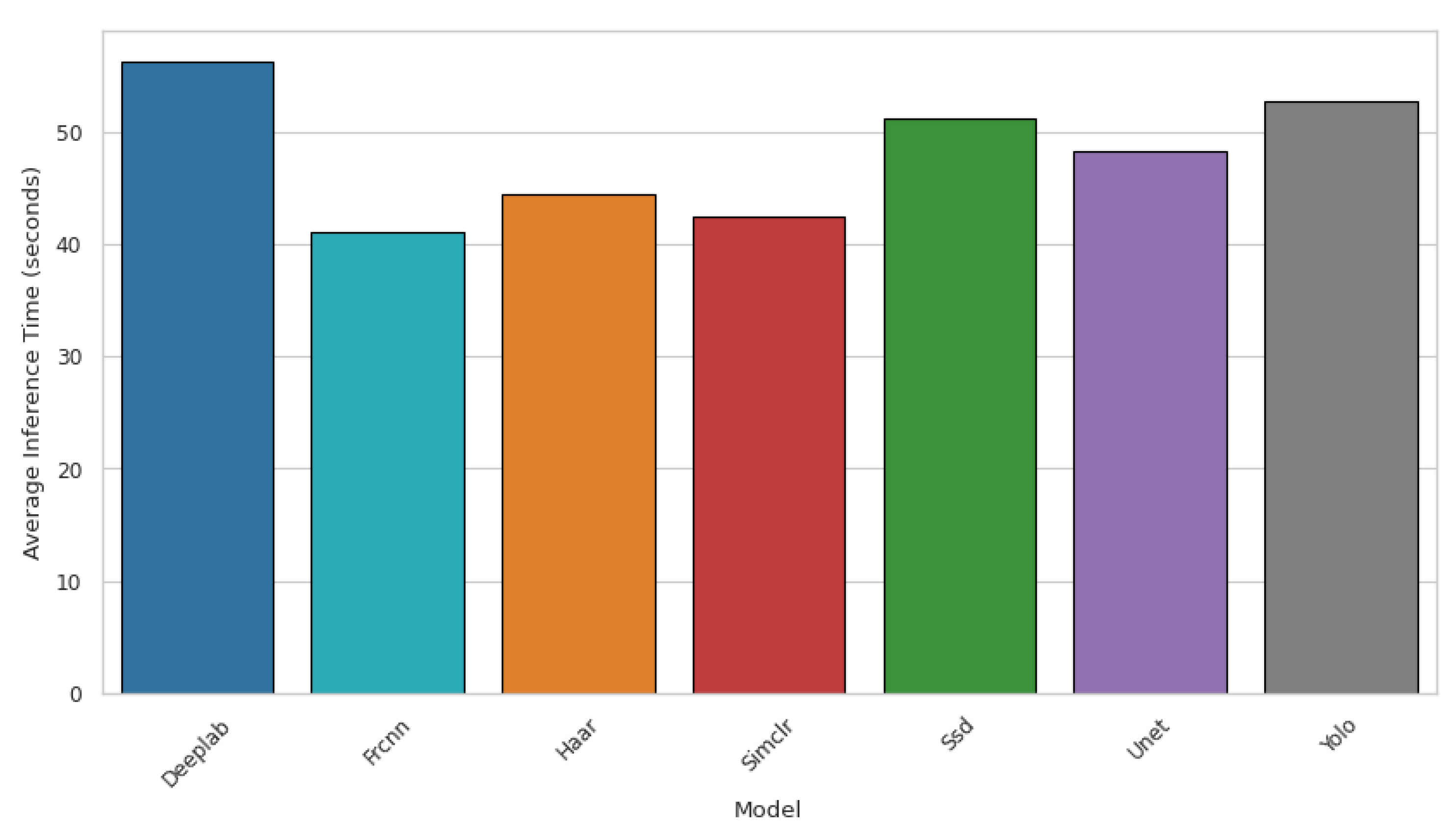
4.7.4. Total Inference Time
4.8. Comparison of ALL Model Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| EGW | Eye-gaze writing. |
| YOLO | You Only Look Once. |
| SSD | Single Shot Multi-Box Detector. |
| Faster R-CNN | Faster region-based convolutional neural network. |
| SimCLR | Simple Contrastive Learning of Visual Representations. |
| DNN | Deep Neural Network. |
| CNN | Convolutional neural network. |
| PCCR | Pupil Center Corneal Reflection. |
| DCNNs | Deep convolutional neural networks. |
| FCN | Fully Convolutional Network. |
| SSL | Self-supervised learning. |
| MLP | Multilayer perception. |
| Caffe | Convolutional Architecture for Fast Feature Embedding. |
References
- Nerişanu, R.A.; Cioca, L.I. A Better Life in Digital World: Using Eye-Gaze Technology to Enhance Life Quality of Physically Disabled People. In Digital Transformation: Exploring the Impact of Digital Transformation on Organizational Processes; Springer: Berlin/Heidelberg, Germany, 2024; pp. 67–99. [Google Scholar]
- Paraskevoudi, N.; Pezaris, J.S. Eye movement compensation and spatial updating in visual prosthetics: Mechanisms, limitations, and future directions. Front. Syst. Neurosci. 2019, 12, 73. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Chi, J.N.; Zhang, Z.H.; Wang, Z.L. A novel eye gaze tracking technique based on pupil center cornea reflection technique. Jisuanji Xuebao—Chin. J. Comput. 2010, 33, 1272–1285. [Google Scholar] [CrossRef]
- Zhu, Z.; Ji, Q. Eye gaze tracking under natural head movements. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 918–923. [Google Scholar]
- Roth, P.M.; Winter, M. Survey of Appearance-Based Methods for Object Recognition; Technical Report ICGTR0108 (ICG-TR-01/08); Institute for Computer Graphics and Vision, Graz University of Technology: Graz, Austria, 2008. [Google Scholar]
- Fischer, T.; Chang, H.J.; Demiris, Y. Rt-gene: Real-time eye gaze estimation in natural environments. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–352. [Google Scholar]
- Wang, Y.; Shen, T.; Yuan, G.; Bian, J.; Fu, X. Appearance-based gaze estimation using deep features and random forest regression. Knowl.-Based Syst. 2016, 110, 293–301. [Google Scholar] [CrossRef]
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar]
- Hansen, D.W.; Ji, Q. In the eye of the beholder: A survey of models for eyes and gaze. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 478–500. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Sugano, Y.; Bulling, A. Evaluation of appearance-based methods and implications for gaze-based applications. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Whitehill, J.; Omlin, C.W. Haar features for FACS AU recognition. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 24 April 2006; p. 5. [Google Scholar]
- Li, Y.; Xu, X.; Mu, N.; Chen, L. Eye-gaze tracking system by haar cascade classifier. In Proceedings of the 2016 IEEE 11th Conference on Industrial Electronics and Applications (ICIEA), Hefei, China, 5–7 June 2016; pp. 564–567. [Google Scholar]
- Ngo, H.T.; Rakvic, R.N.; Broussard, R.P.; Ives, R.W. An FPGA-based design of a modular approach for integral images in a real-time face detection system. In Proceedings of the Mobile Multimedia/Image Processing, Security, and Applications 2009, Orlando, FL, USA, 13–17 April 2009; Volume 7351, pp. 83–92. [Google Scholar]
- Bulling, A. DaRUS Dataset: Eye-Gaze Writing Models. Available online: https://darus.uni-stuttgart.de/dataset.xhtml?persistentId=doi:10.18419/darus-3230&version=1.0 (accessed on 1 March 2025).
- RoboFlow. Eyes Dataset. Available online: https://universe.roboflow.com/rethinkai2/eyes-mv4fm/dataset/1 (accessed on 1 March 2025).
- RoboFlow. Dataset Pupil. Available online: https://universe.roboflow.com/politeknik-negeri-padang-yeiym/dataset-pupil (accessed on 1 March 2025).
- RoboFlow. Pupil Detection Dataset. Available online: https://universe.roboflow.com/rocket-vhngd/pupil-detection-fqerx (accessed on 1 March 2025).
- RoboFlow. Pupils Dataset. Available online: https://universe.roboflow.com/artem-bdqda/pupils-3wyx2/dataset/5 (accessed on 1 March 2025).
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Zhai, S.; Shang, D.; Wang, S.; Dong, S. DF-SSD: An improved SSD object detection algorithm based on DenseNet and feature fusion. IEEE Access 2020, 8, 24344–24357. [Google Scholar] [CrossRef]
- Theckedath, D.; Sedamkar, R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 2020, 1, 79. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Lee, C.; Kim, H.J.; Oh, K.W. Comparison of faster R-CNN models for object detection. In Proceedings of the 2016 16th International Conference on Control, Automation and Systems (ICCAS), Gyeongju, Republic of Korea, 16–19 October 2016; pp. 107–110. [Google Scholar]
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Mijwil, M.M.; Aggarwal, K.; Doshi, R.; Hiran, K.K.; Gök, M. The Distinction between R-CNN and Fast RCNN in Image Analysis: A Performance Comparison. Asian J. Appl. Sci. 2022, 10, 429–437. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Du, G.; Cao, X.; Liang, J.; Chen, X.; Zhan, Y. Medical Image Segmentation based on U-Net: A Review. J. Imaging Sci. Technol. 2020, 64, jist0710. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- He, J.; Li, L.; Xu, J.; Zheng, C. ReLU deep neural networks and linear finite elements. arXiv 2018, arXiv:1807.03973. [Google Scholar]
- Christlein, V.; Spranger, L.; Seuret, M.; Nicolaou, A.; Král, P.; Maier, A. Deep generalized max pooling. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 1090–1096. [Google Scholar]
- Zhou, D.X. Theory of deep convolutional neural networks: Downsampling. Neural Netw. 2020, 124, 319–327. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Jiang, W.; Zhang, K.; Wang, N.; Yu, M. MeshCut data augmentation for deep learning in computer vision. PLoS ONE 2020, 15, e0243613. [Google Scholar] [CrossRef] [PubMed]
- Yeh, C.H.; Hong, C.Y.; Hsu, Y.C.; Liu, T.L.; Chen, Y.; LeCun, Y. Decoupled contrastive learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 668–684. [Google Scholar]
- Taud, H.; Mas, J.F. Multilayer perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios; Springer: Berlin/Heidelberg, Germany, 2017; pp. 451–455. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technique | Accuracy | Low Light | Speed |
|---|---|---|---|
| Saccadic and Fixational | High | Low | Medium |
| Model-based | High | Medium | Low |
| Appearance-based | Medium | Low | Slow |
| PCCR technique | High | Medium | Slow |
| Haar Cascade Classifier | High | Medium | Fast |
| YOLOv8 (our model) | High | High | Fast |
| SSD (our model) | High | High | Fast |
| Storage capacity | 512 GB |
| Processor model | Intel Core i7 |
| Graphics card model | NVIDIA GeForce RTX 3050 GDDR6 Graphics |
| Camera type | HD RGB camera |
| Model | Precision | Total Inference Time (s) | Recall | F1 Score | Similarity |
|---|---|---|---|---|---|
| DeepLab | 0.7252 | 56.1962 | 0.4436 | 0.4845 | 0.4214 |
| FRCNN | 0.1000 | 41.1021 | 0.0207 | 0.0324 | 0.0255 |
| Haar | 0.8881 | 44.4113 | 0.8600 | 0.8431 | 0.7474 |
| SimCLR | 0.0000 | 42.4106 | 0.0000 | 0.0000 | 0.0000 |
| SSD | 0.2988 | 51.1207 | 0.3929 | 0.3183 | 0.2334 |
| U-Net | 0.4456 | 48.1702 | 0.4125 | 0.4026 | 0.2196 |
| YOLO | 0.8235 | 52.6745 | 0.7460 | 0.7445 | 0.6733 |
| Model | SD of Precision | SD of F1 | SD of Recall | SD of Total Inference Time | SD of Similarity |
|---|---|---|---|---|---|
| DeepLab | 0.3304 | 0.2926 | 0.3486 | 10.7725 | 0.2467 |
| FRCNN | 0.2754 | 0.0855 | 0.0563 | 25.3946 | 0.0661 |
| Haar | 0.2041 | 0.1883 | 0.2234 | 12.6458 | 0.1830 |
| SimCLR | 0 | 0 | 0 | 26.6170 | 0 |
| SSD | 0.1568 | 0.1709 | 0.2728 | 12.0616 | 0.1298 |
| U-Net | 0.3210 | 0.2498 | 0.2496 | 15.7996 | 0.1574 |
| YOLO | 0.2155 | 0.2287 | 0.2874 | 9.7165 | 0.2524 |
| Model | Precision | Recall | F1 Score | Inference Time (s) | Model Size (KB) | Performance Evaluation | Usability |
|---|---|---|---|---|---|---|---|
| Haar | 0.85 | 0.83 | 0.85 | 45 | 97.358 | Best overall (high accuracy and reasonable speed) | Best choice |
| YOLOv8 | 0.88 | 0.80 | 0.83 | 52 | 6.083 | High accuracy and smallest model | Best compact model |
| DeepLabv3 | 0.72 | 0.50 | 0.82 | 55 | 238.906 | High accuracy but large model and slow | Inefficient |
| U-Net | 0.50 | 0.42 | 0.84 | 48 | 121.234 | Moderate accuracy, large size | Not ideal |
| Faster R-CNN | 0.15 | 0.05 | 0.82 | 41 | 534.013 | Too large model, low efficiency | Avoid |
| SSD | 0.40 | 0.38 | 0.49 | 51 | 87.071 | Low accuracy, moderate size | Poor choice |
| SimCLR | 0.05 | 0.02 | 0.77 | 43 | 45.327 | Worst accuracy, poor similarity | Avoid |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shobaki, W.A.; Milanova, M. A Comparative Study of YOLO, SSD, Faster R-CNN, and More for Optimized Eye-Gaze Writing. Sci 2025, 7, 47. https://doi.org/10.3390/sci7020047
Shobaki WA, Milanova M. A Comparative Study of YOLO, SSD, Faster R-CNN, and More for Optimized Eye-Gaze Writing. Sci. 2025; 7(2):47. https://doi.org/10.3390/sci7020047
Chicago/Turabian StyleShobaki, Walid Abdallah, and Mariofanna Milanova. 2025. "A Comparative Study of YOLO, SSD, Faster R-CNN, and More for Optimized Eye-Gaze Writing" Sci 7, no. 2: 47. https://doi.org/10.3390/sci7020047
APA StyleShobaki, W. A., & Milanova, M. (2025). A Comparative Study of YOLO, SSD, Faster R-CNN, and More for Optimized Eye-Gaze Writing. Sci, 7(2), 47. https://doi.org/10.3390/sci7020047