
MirrorCampus: A Synchronous Hybrid Learning Environment That Supports Spatial Localization of Learners for Facilitating Discussion-Oriented Behaviors


Abstract
:1. Introduction
2. Related Works
3. Research Question and Hypothesis
4. Methods
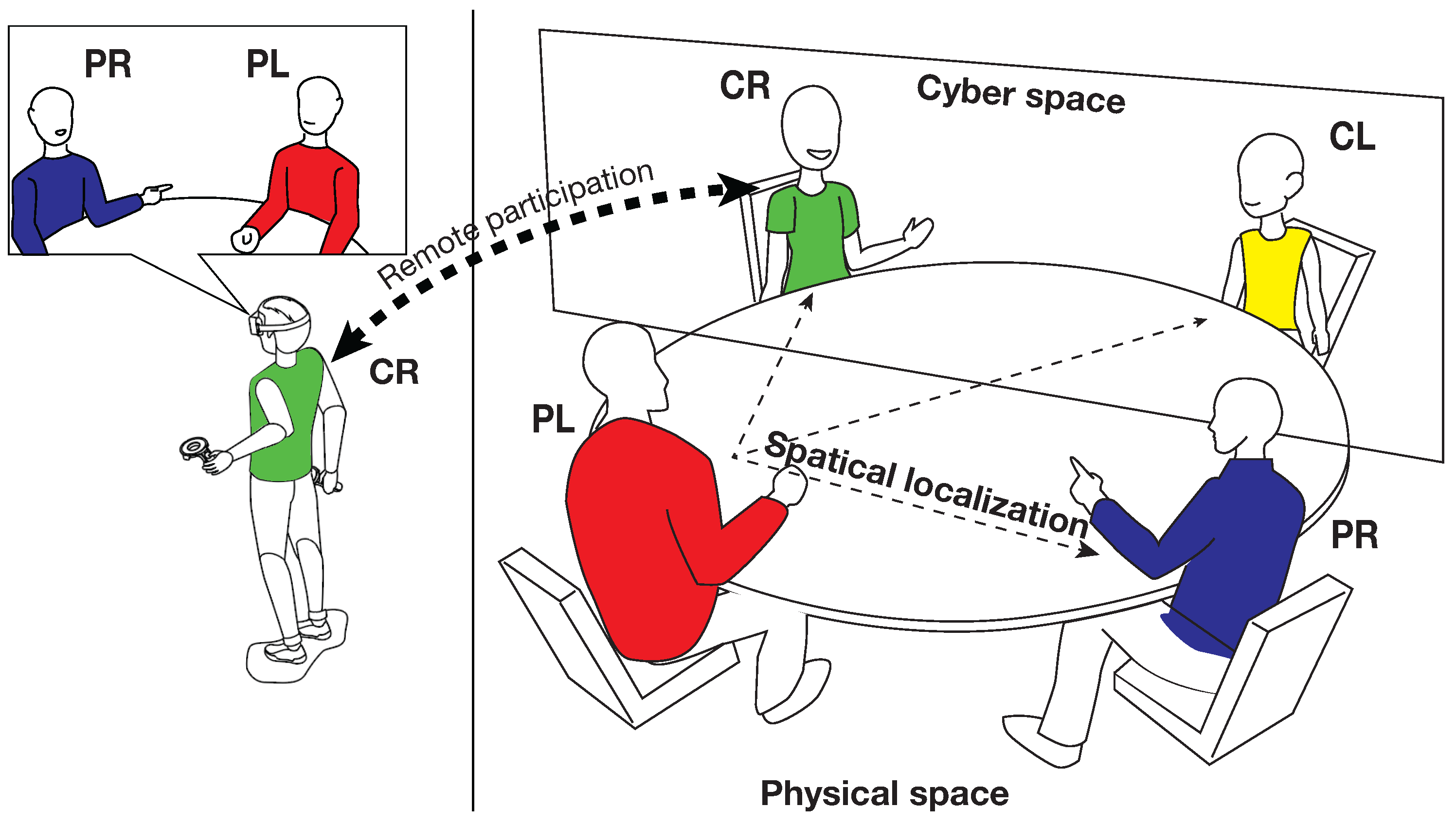
4.1. Overview
4.2. Facing Behavior
4.3. Speech Behavior
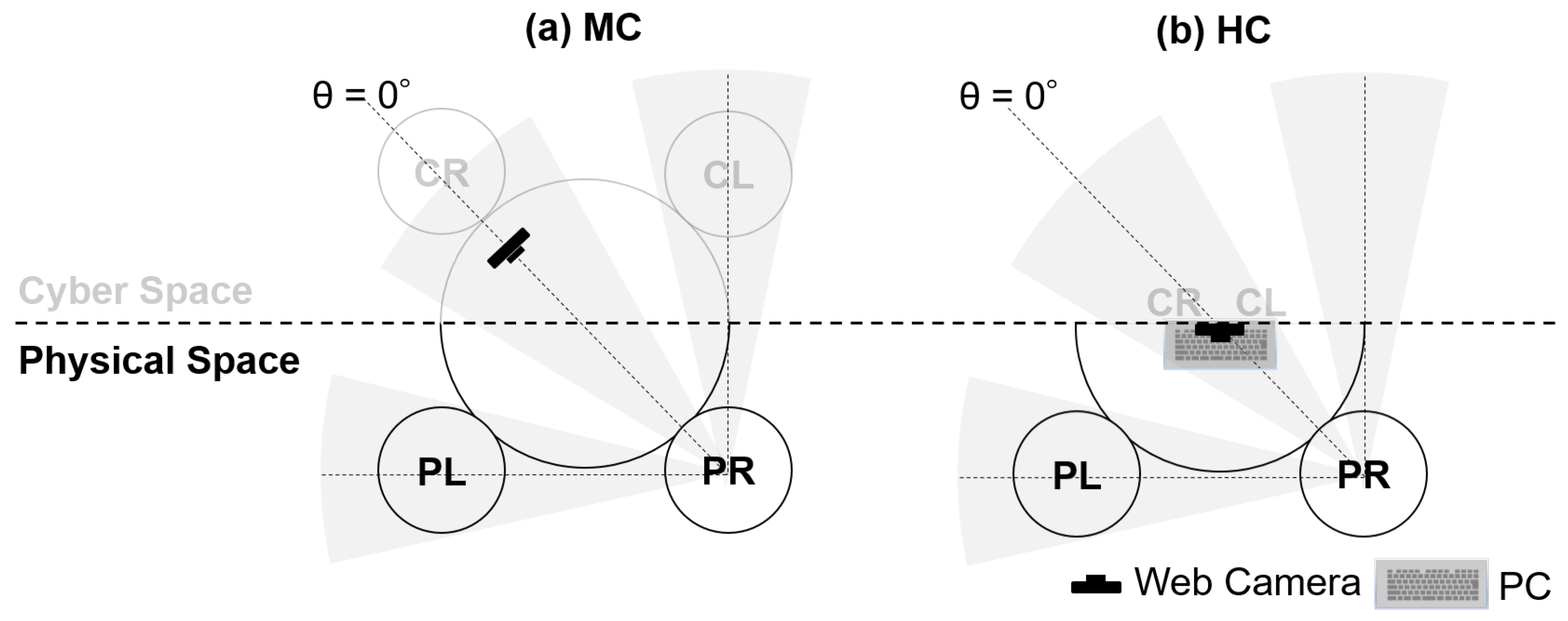
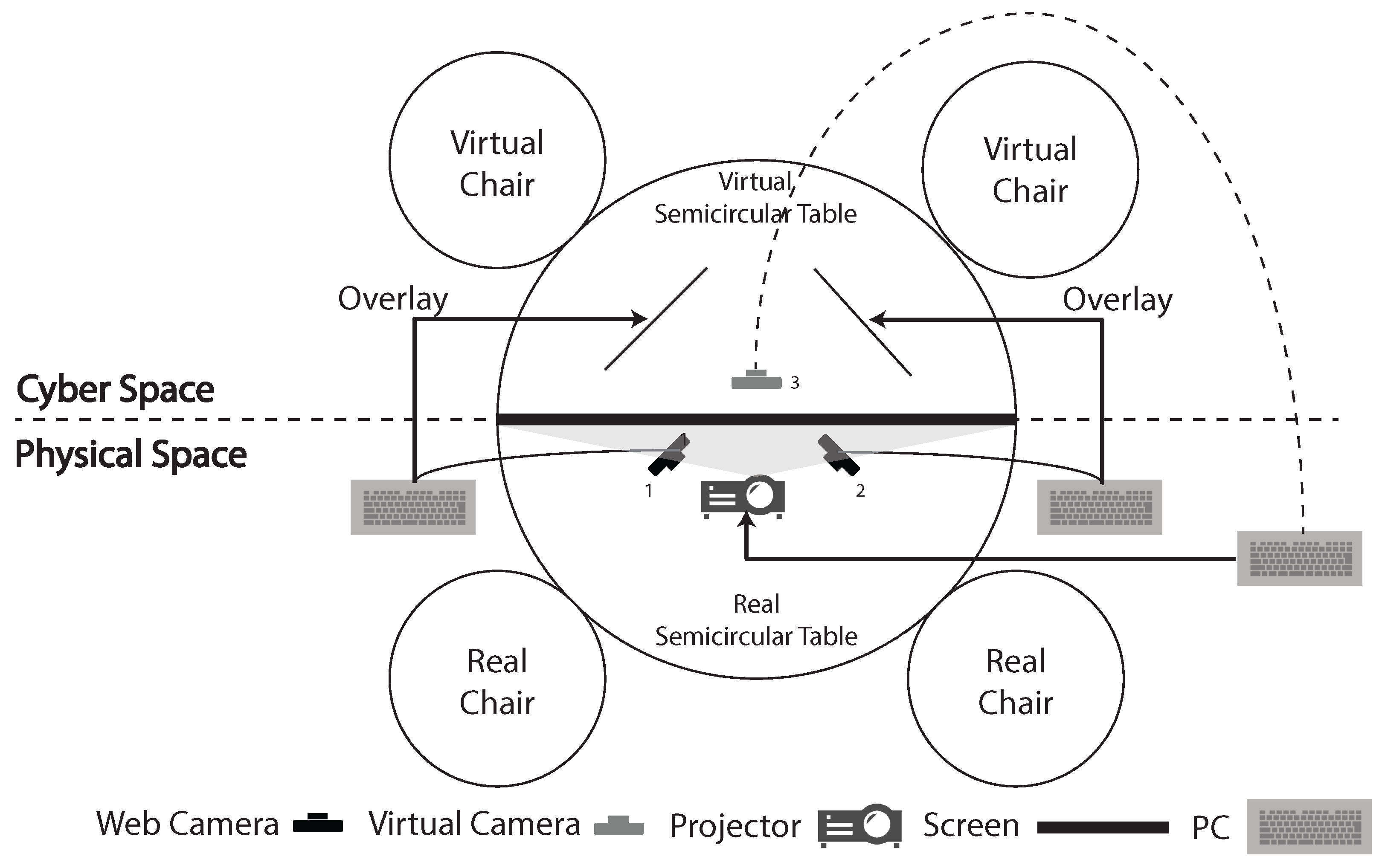
5. System Configuration
5.1. Synchronous Hybrid Learning Environment from Physical Space
5.2. Synchronous Hybrid Learning Environment from Cyberspace
6. Experiment
6.1. Participants
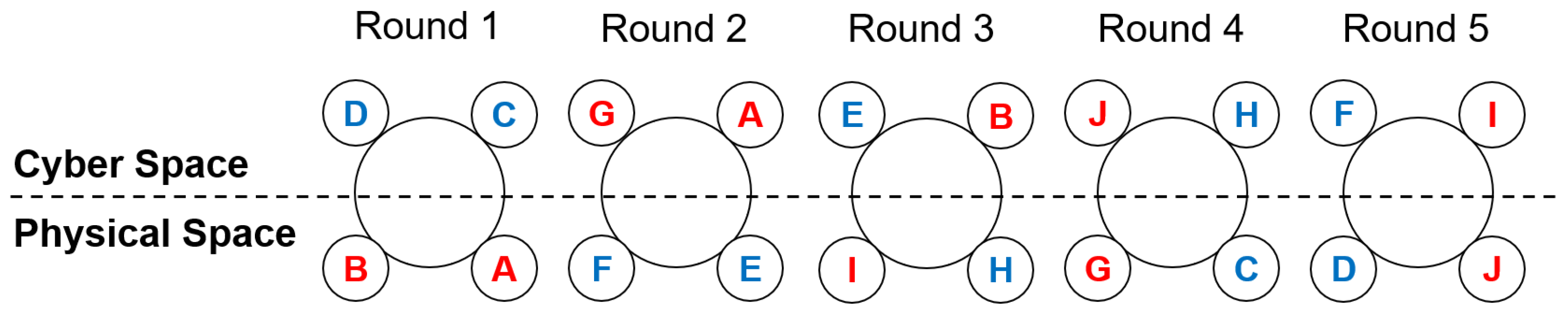
6.2. Grouping Design of the Participants
6.3. Discussion Topics
- Optimal approaches for enhancing English conversational skills of Japanese individuals
- Key initiatives for the new urban development in a city of Japan
- Efficient strategies for utilizing multiple social networking services
- Maximizing the quality of life during the COVID-19 pandemic self-isolation period
- Essential competencies required of humans in the era of artificial intelligence
6.4. Experiment Procedure
6.5. Measurements
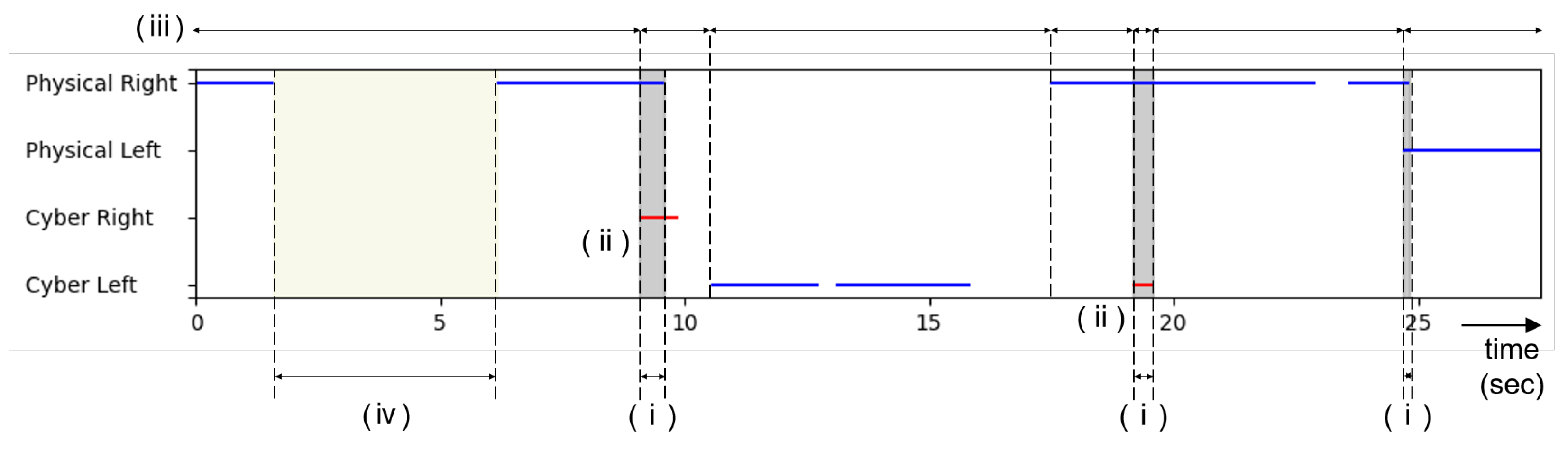
6.5.1. Facing Behavior
6.5.2. Utterance
6.5.3. Rubric Assessment
6.5.4. Questionnaire
6.6. Results
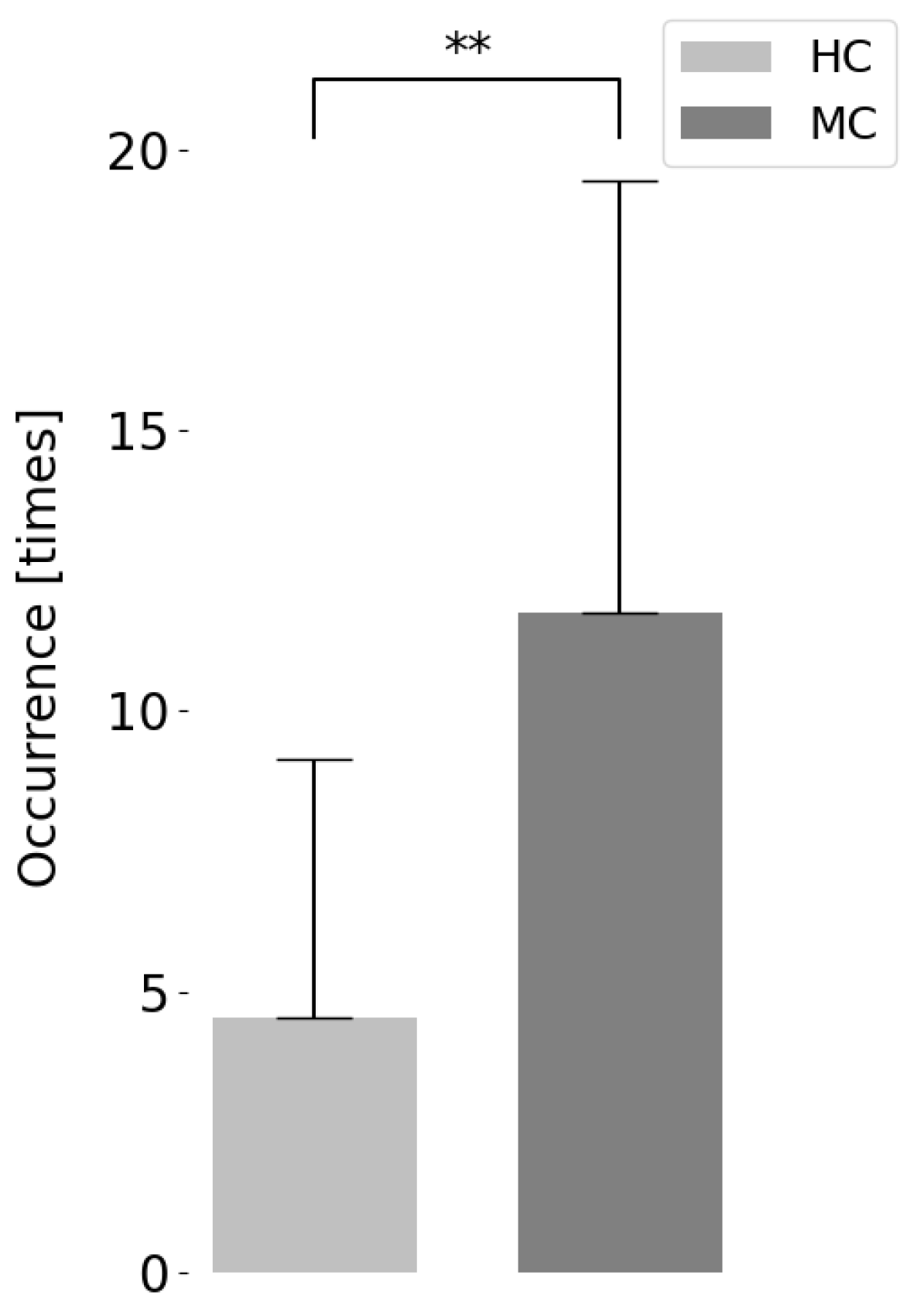
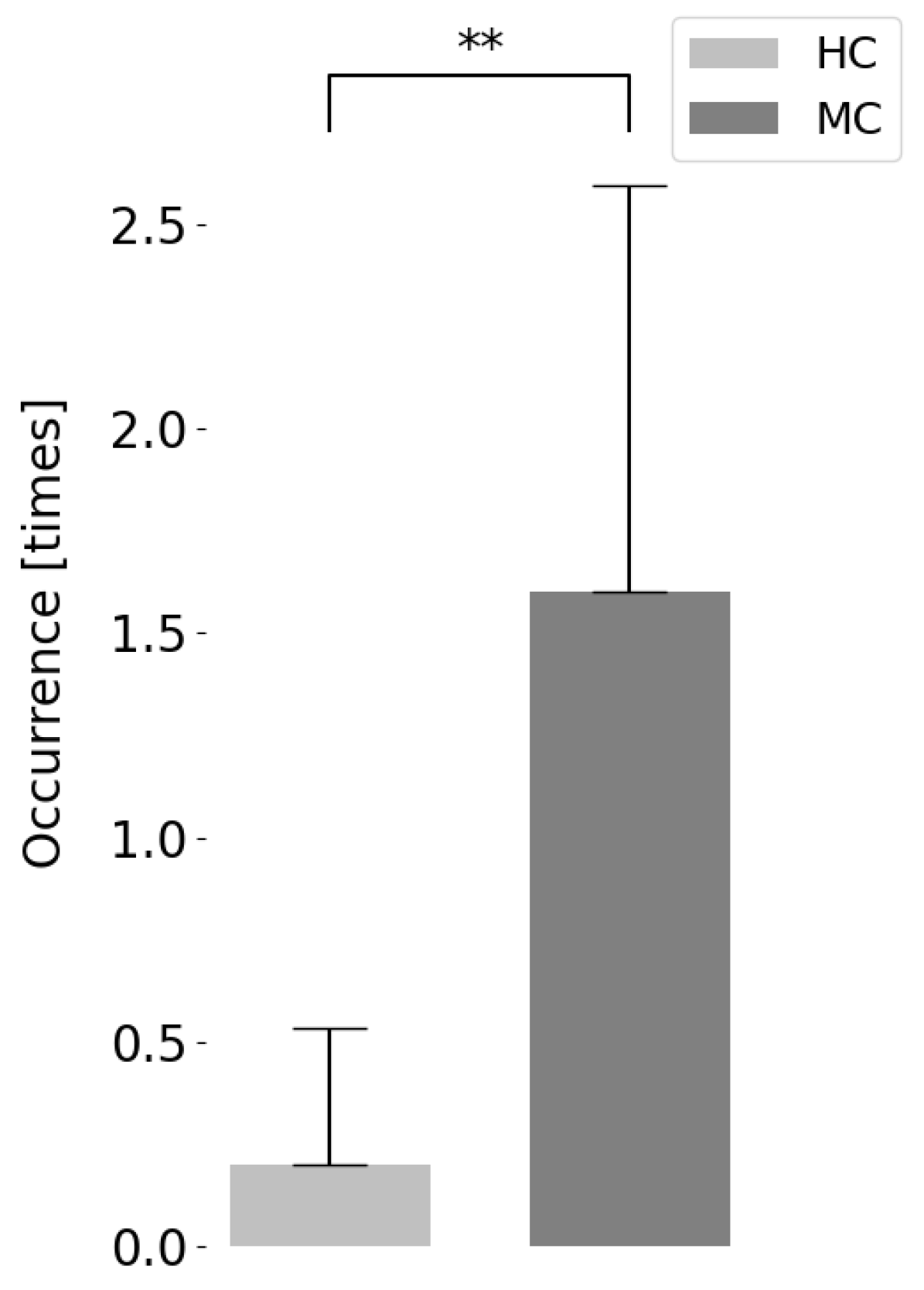
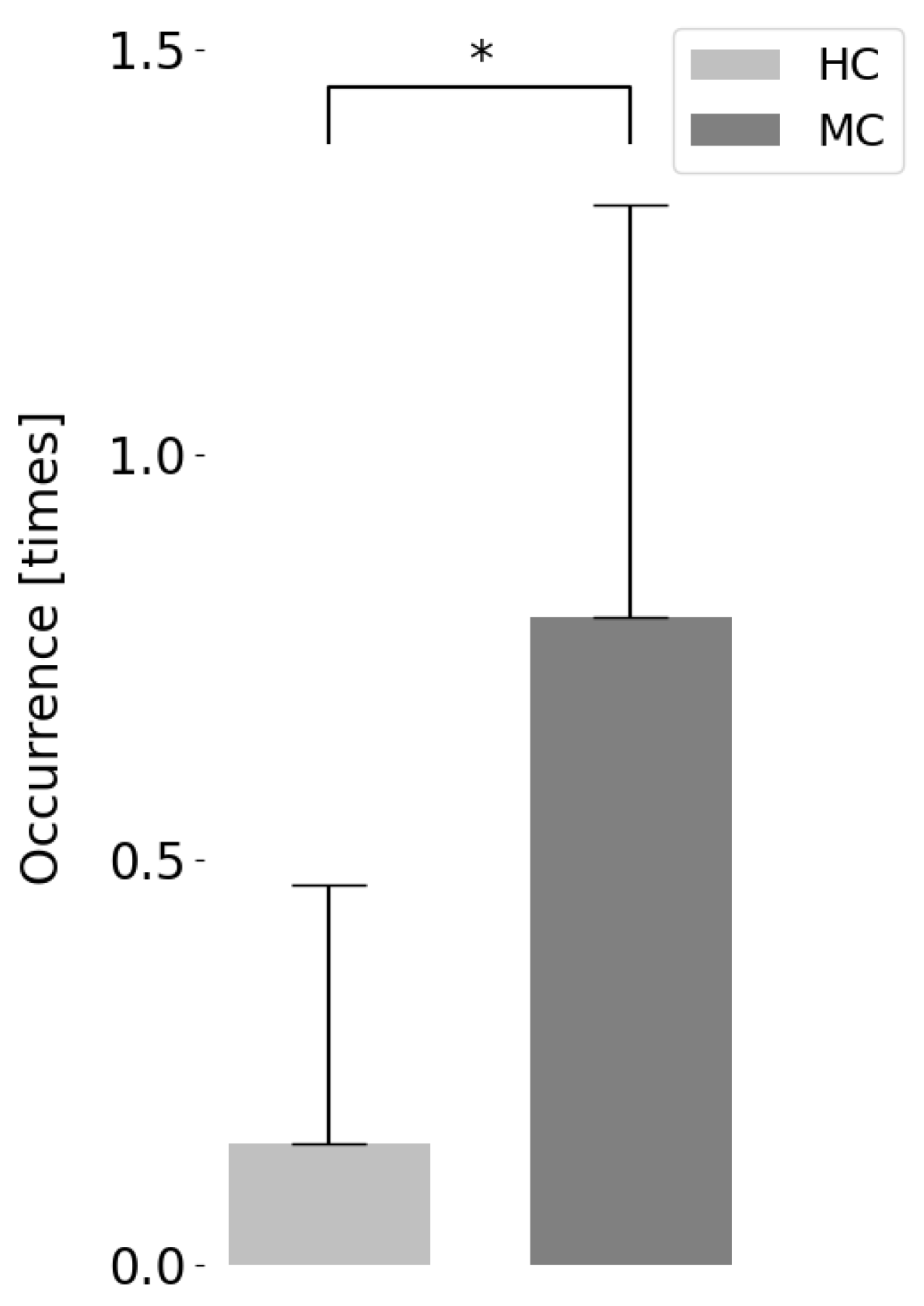
6.6.1. Facing Behavior
6.6.2. Utterance
6.6.3. Rubric Assessment
6.6.4. Questionnaire
7. Discussion
7.1. Learning Behaviors and Outcomes in Active Learning
- The fluidity of discussions
- A sense of depth and immersion in both visuals and sound
- The usability of body movements to change individuals’ perspective
7.2. Limitations
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AL | Active Learning |
| CA | California |
| CL | Cyber Left |
| CR | Cyber Right |
| FR | Full Real |
| HC | Hybrid Conference |
| HMD | Head-Mounted Display |
| MC | Mirror Campus |
| PC | Personal Computer |
| PL | Physical Left |
| PR | Physical Right |
| SDK | Software Development Kit |
| SVRE | Social Virtual Reality Environment |
| USA | United States of America |
| VAD | Voice Activity Detection |
| VR | Virtual Reality |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scores | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| Listening | Listens carefully and respectfully to classmates all of the time. | Listens carefully and respectfully to classmates most of the time. | Listens carefully and respectfully to classmates some of the time. | Spaces out a lot during discussion and/or interrupted the speaker. |
| Speaking | Contributes several meaningful comments to the whole group discussion based on evidence from the text, without dominating the discussion. | Contributes some meaningful comments to the whole group discussion based on evidence from the text, without dominating the discussion. | Contributes one meaningful comment to the whole group discussion based on evidence from the text, without dominating the discussion. | Does not contribute to the group discussion at all or alternately dominated the discussion. |
| Depth of Thought | All questions and comments show deep understanding and original, profound thought. | Some questions and comments show deep understanding and original, profound thought. | A few questions and comments show deep understanding and original, profound thought. | Questions and comments do not show very deep, original thinking. |
| Contributes to Team Meetings | Helps the team move forward by articulating the merits of alternative ideas or proposals. | Offers alternative solutions or courses of action that build on the ideas of others. | Offers new suggestions to advance the work of the group. | Shares ideas but does not advance the work of the group. |
| Facilitates the Contributions of Team Members | Engages team members in ways that facilitate their contributions to meetings by both constructively building upon or synthesizing the contributions of others as well as noticing when someone is not participating and inviting them to engage. | Engages team members in ways that facilitate their contributions to meetings by constructively building upon or synthesizing the contributions of others. | Engages team members in ways that facilitate their contributions to meetings by restating the views of other team members and/or asking questions for clarification. | Engages team members by taking turns and listening to others without interrupting. |
| Responds to Conflict | Addresses destructive conflict directly and constructively, helping to manage/resolve it in a way that strengthens overall team cohesiveness and future effectiveness. | Identifies and acknowledges conflict and stays engaged with it. | Redirects focus toward common ground, toward task at hand (away from conflict). | Passively accepts alternate viewpoints/ideas/opinions. |
| Scores | 4 | 3 | 2 | 1 |
|---|---|---|---|---|
| Define Problem | Demonstrates the ability to construct a clear and insightful problem statement with evidence of all relevant contextual factors. | Demonstrates the ability to construct a problem statement with evidence of most relevant contextual factors, and problem statement is adequately detailed. | Begins to demonstrate the ability to construct a problem statement with evidence of most relevant contextual factors, but problem statement is superficial. | Demonstrates a limited ability in identifying a problem statement or related contextual factors. |
| Identify Strategies | Identifies multiple approaches for solving the problem that apply within a specific context. | Identifies multiple approaches for solving the problem, only some of which apply within a specific context. | Identifies only a single approach for solving the problem that does apply within a specific context. | Identifies one or more approaches for solving the problem that do not apply within a specific context. |
| Propose Solutions/Hypotheses | Proposes one or more solutions or hypotheses that indicates a deep comprehension of the problem. Solution/hypotheses are sensitive to contextual factors as well as all of the following: ethical, logical, and cultural dimensions of the problem. | Proposes one or more solutions or hypotheses that indicates comprehension of the problem. Solutions/hypotheses are sensitive to contextual factors as well as one of the following: ethical, logical, or cultural dimensions of the problem. | Proposes one solution or hypothesis that is “off the shelf” rather than individually designed to address the specific contextual factors of the problem. | Proposes a solution or hypothesis that is difficult to evaluate because it is vague or only indirectly addresses the problem statement. |
| Evaluate Potential | Solutions Evaluation of solutions is deep and elegant (for example, contains thorough and insightful explanation) and includes, deeply and thoroughly, all of the following: considers history of problem, reviews logic/ reasoning, examines feasibility of solution, and weighs impacts of solution. | Evaluation of solutions is adequate (for example, contains thorough explanation) and includes the following: considers history of problem, reviews logic/ reasoning, examines feasibility of solution, and weighs impacts of solution. | Evaluation of solutions is brief (for example, explanation lacks depth) and includes the following: considers history of problem, reviews logic/reasoning, examines feasibility of solution, and weighs impacts of solution. | Evaluation of solutions is superficial (for example, contains cursory, surface level explanation) and includes the following: considers history of problem, reviews logic/reasoning, examines feasibility of solution, and weighs impacts of solution. |
| Variety of ideas | Large number of important and appropriate ideas that span multiple contexts or disciplines. | Ideas represent important and appropriate concepts from different contexts or disciplines. | Ideas are predictable and/ or from the same or similar contexts or disciplines. | Few ideas; ideas are very obvious. |
| Combination of ideas | Ideas are combined in markedly original and surprising ways to solve a problem, address an issue, or make something new. | Ideas are combined in original ways to solve a problem, address an issue, or make something new. | Ideas are combined in ways that are derived from the thinking of others (for example, of the authors in sources consulted). | Ideas are copied or restated from sources. |
References
- Roseth, C.; Akcaoglu, M.; Zellner, A. Blending synchronous face-to-face and computer-supported cooperative learning in a hybrid doctoral seminar. Techtrends Tech. Trends 2013, 57, 54–59. [Google Scholar] [CrossRef]
- Hastie, M.; Hung, I.; Chen, N.; Kinshuk. A blended synchronous learning model for educational international collaboration. Innov. Educ. Teach. Int. 2010, 47, 9–24. [Google Scholar] [CrossRef]
- Raes, A.; Detienne, L.; Windey, I.; Depaepe, F. A systematic literature review on synchronous hybrid learning: Gaps identified. Learn. Environ. Res. 2020, 23, 269–290. [Google Scholar] [CrossRef]
- Li, K.; Wong, B.; Kwan, R.; Wu, M. Learning in a hybrid synchronous mode: Experiences and views of university students. Int. J. Innov. Learn. 2023, 34, 197–207. [Google Scholar] [CrossRef]
- Wang, Q.; Huang, Q. Engaging online learners in blended synchronous learning: A systematic literature review. IEEE Trans. Learn. Technol. 2024, 17, 594–607. [Google Scholar] [CrossRef]
- Bakx, I.; Turnhout, K.; Terken, J. Facial Orientation During Multi-party Interaction with Information Kiosks. In Proceedings of the Human-Computer Interaction INTERACT ’03: IFIP TC13 International Conference On Human-Computer Interaction, Zurich, Switzerland, 1–5 September 2003. [Google Scholar]
- Duncan, S.; Fiske, D. Face-To-Face Interaction: Research, Methods, and Theory. 2015. Available online: https://books.google.co.jp/books?hl=ja&lr=lang_en|lang_ja&id=o7XMCgAAQBAJ&oi=fnd&pg=PA1&dq=Starkey+Duncan+Jr+and+Donald+W.+Fiske,+Face-to-face+interaction:+research,+methods+and+theory,+Hillsdale,+New+Jersy:+lawrence+Erlbaum,+1977.&ots=McmoWE8r1J&sig=Y6uOaIQtKwcpfFM6aEwqgpliZdE (accessed on 7 April 2024).
- Cunningham, U. Teaching the disembodied: Othering and activity systems in a blended synchronous learning situation. Int. Rev. Res. Open Distrib. Learn. 2014, 15, 33–51. [Google Scholar] [CrossRef]
- Johnson, D.; Johnson, R.; Smith, K. Cooperative learning returns to college what evidence is there that it works? Chang. Mag. High. Learn. 1998, 30, 26–35. [Google Scholar] [CrossRef]
- Hmelo-Silver, C. Problem-based learning: What and how do students learn? Educ. Psychol. Rev. 2004, 16, 235–266. [Google Scholar] [CrossRef]
- Freeman, S.; Eddy, S.; McDonough, M.; Smith, M.; Okoroafor, N.; Jordt, H.; Wenderoth, M. Active learning increases student performance in science, engineering, and mathematics. Proc. Natl. Acad. Sci. USA 2014, 111, 8410–8415. [Google Scholar] [CrossRef]
- Fink, L. Creating Significant Learning Experiences: An Integrated Approach to Designing College Courses. 2013. Available online: https://books.google.co.jp/books?hl=ja&lr=lang_en|lang_ja&id=cehvAAAAQBAJ&oi=fnd&pg=PR7&dq=Fink,+L.+D.+(2013).+Creating+significant+learning+experiences:+An+integrated+approach+to+designing+college+courses.+John+Wiley+%26+Sons.&ots=GDpIuU9qEL&sig=7u-sFzU7EvOnOeIAolOuFllSYuI#v=onepage&q=Fink%2C%20L.%20D.\%20(2013).%20Creating%20significant%20learning%20experiences%3A%20An%20integrated%20approach%20to%20designing%20college%20courses.%20John%20Wiley%20%26%20Sons.&f=false (accessed on 7 April 2024).
- Bower, M.; Dalgarno, B.; Kennedy, G.; Lee, M.; Kenney, J. Design and implementation factors in blended synchronous learning environments: Outcomes from a cross-case analysis. Comput. Educ. 2015, 86, 1–17. [Google Scholar] [CrossRef]
- Carruana Martin, A.; Alario-Hoyos, C.; Delgado Kloos, C. A Study of Student and Teacher Challenges in Smart Synchronous Hybrid Learning Environments. Sustainability 2023, 15, 11694. [Google Scholar] [CrossRef]
- Kendon, A. Conducting Interaction: Patterns of Behavior in Focused Encounters. 1990. Available online: https://books.google.co.jp/books?hl=ja&lr=lang_en|lang_ja&id=7-8zAAAAIAAJ&oi=fnd&pg=PA1&dq=Conducting+interaction:+Patterns+of+behavior+in+focused+encounters&ots=oAiabTWYC-&sig=aW6c1muxBuoQSSlTIUTPt2BudnQ (accessed on 7 April 2024).
- Lang, J. Creating Architectural Theory, The Role of The Behavioral Sciences in Environmental Design. 1987. Available online: https://books.google.co.jp/books/about/Creating_Architectural_Theory.html?id=lHlwQgAACAAJ&redir_esc=y (accessed on 7 April 2024).
- Scott-Webber, L. Environmental Behavior Research and the Design of Learning Spaces. 2004. Available online: https://www.academia.edu/24124687/Environmental_Behavior_Research_and_the_Design_of_Learning_Spaces (accessed on 7 April 2024).
- Chessa, M.; Solari, F. The sense of being there during online classes: Analysis of usability and presence in web-conferencing systems and virtual reality social platforms. Behav. Inf. Technol. 2021, 40, 1237–1249. [Google Scholar] [CrossRef]
- Girvan, C.; Tangney, B.; Savage, T. SLurtles: Supporting constructionist learning in second life. Comput. Educ. 2013, 61, 115–132. [Google Scholar] [CrossRef]
- Mystakidis, S.; Berki, E.; Valtanen, J. Deep and meaningful e-learning with social virtual reality environments in higher education: A systematic literature review. Appl. Sci. 2021, 11, 2412. [Google Scholar] [CrossRef]
- Sawada, S.; Kim, S.; Hirokawa, M.; Suzuki, K. Effect of Using Embodied Avatars on Turn-taking during Conversational Activities in a Social VR Space. IEEE Int. Conf. Eng. Technol. Educ. 2021, 1, 934–937. [Google Scholar]
- Ooko, R.; Ishii, R.; Nakano, Y. Estimating a user’s conversational engagement based on head pose information. In Proceedings of the Intelligent Virtual Agents: 10th International Conference, IVA 2011, Reykjavik, Iceland, 15–17 September 2011; pp. 262–268. [Google Scholar]
- Maroni, B.; Gnisci, A.; Pontecorvo, C. Turn-taking in classroom interactions: Overlapping, interruptions and pauses in primary school. Eur. J. Psychol. Educ. 2008, 23, 59–76. [Google Scholar] [CrossRef]
- Hachisu, T.; Pan, Y.; Matsuda, S.; Bourreau, B.; Suzuki, K. FaceLooks: A smart headband for signaling face-to-face behavior. Sensors 2018, 18, 2066. [Google Scholar] [CrossRef] [PubMed]
- Setting up the SDK. Available online: https://creators.vrchat.com/sdk/ (accessed on 6 November 2023).
- Integrate a Character Creator into Your Game or App in Days. Available online: https://readyplayer.me/ (accessed on 6 November 2023).
- Fahlenbrach, K.; Schröter, F. Embodied avatars in video games: Audiovisual metaphors in the interactive design of player characters. In Embodied Metaphors in Film, Television, and Video Games; Routlede: London, UK, 2015; pp. 251–268. [Google Scholar]
- XSOverlay. Available online: https://store.steampowered.com/app/1173510/XSOverlay/? (accessed on 6 November 2023).
- Webb, N.; Kenderski, C. Gender differences in small-group interaction and achievement in high-and low-achieving classes. Gend. Influ. Classr. Interact. 1985, 1, 209–236. [Google Scholar]
- Hackman, J. Effects of task characteristics on group products. J. Exp. Soc. Psychol. 1968, 4, 162–187. [Google Scholar] [CrossRef]
- Straus, S.; McGrath, J. Does the medium matter? The interaction of task type and technology on group performance and member reactions. J. Appl. Psychol. 1994, 79, 87. [Google Scholar] [CrossRef]
- Quick Guide to Creating Your Personalized Zoom Avatar. Available online: https://www.askdavetaylor.com/quick-guide-to-creating-your-personalized-zoom-avatar/ (accessed on 29 October 2023).
- Ratan, R.; Miller, D.; Bailenson, J. Facial appearance dissatisfaction explains differences in zoom fatigue. Cyberpsychol. Behav. Soc. Netw. 2022, 25, 124–129. [Google Scholar] [CrossRef] [PubMed]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. OpenFace: A General-Purpose Face Recognition Library with Mobile Applications. 2016. Available online: http://cmusatyalab.github.io/openface/ (accessed on 8 November 2023).
- VRChat API. Available online: https://udonsharp.docs.vrchat.com/vrchat-api/ (accessed on 8 November 2023).
- Faster Whisper Transcription with CTranslate2. Available online: https://github.com/guillaumekln/faster-whisper (accessed on 8 November 2023).
- Team, S. Silero VAD: Pre-Trained Enterprise-Grade Voice Activity Detector (VAD), Number Detector and Language Classifier. 2021. Available online: https://github.com/snakers4/silero-vad (accessed on 8 November 2023).
- Barkley, E.; Major, C. Learning Assessment Techniques: A Handbook for College Faculty. 2015. Available online: https://books.google.co.jp/books?hl=ja&lr=lang_en|lang_ja&id=0pstCwAAQBAJ&oi=fnd&pg=PR5&ots=b0QhYZ0HMv&sig=b0pnm6HZhxi2JgecG5oqcawYBQE (accessed on 7 April 2024).
- Discussion Rubric. Available online: https://www.edutopia.org/pdfs/stw/edutopia-stw-assessment-9th-grade-humanities-discussion-rubric.pdf (accessed on 29 October 2023).
- Brookhart, S. Assessing Creativity. Educ. Leadersh. 2013, 70, 28–34. [Google Scholar]
- Value Rubrics. Available online: https://www.aacu.org/initiatives/value-initiative/value-rubrics (accessed on 29 October 2023).
- Martin, F.; Sun, T.; Turk, M.; Ritzhaupt, A. A meta-analysis on the effects of synchronous online learning on cognitive and affective educational outcomes. Int. Rev. Res. Open Distrib. Learn. 2021, 22, 205–242. [Google Scholar] [CrossRef]
- Siler, S.; VanLehn, K. Learning, interactional, and motivational outcomes in one-to-one synchronous computer-mediated versus face-to-face tutoring. Int. J. Artif. Intell. Educ. 2009, 19, 73–102. [Google Scholar]
- Francescucci, A.; Rohani, L. Exclusively synchronous online (VIRI) learning: The impact on student performance and engagement outcomes. J. Mark. Educ. 2019, 41, 60–69. [Google Scholar] [CrossRef]
- Kemp, N.; Grieve, R. Face-to-face or face-to-screen? Undergraduates’ opinions and test performance in classroom vs. online learning. Front. Psychol. 2014, 5, 1278. [Google Scholar] [CrossRef]
- Yee, N.; Bailenson, J. The Proteus effect: The effect of transformed self-representation on behavior. Hum. Commun. Res. 2007, 33, 271–290. [Google Scholar] [CrossRef]
- Ratan, R.; Klein, M.; Ucha, C.; Cherchiglia, L. Avatar customization orientation and undergraduate-course outcomes: Actual-self avatars are better than ideal-self and future-self avatars. Comput. Educ. 2022, 191, 104643. [Google Scholar] [CrossRef]
- Oyanagi, A.; Narumi, T.; Lugrin, J.; Aoyama, K.; Ito, K.; Amemiya, T.; Hirose, M. The Possibility of Inducing the Proteus Effect for Social VR Users. Int. Conf. -Hum. Interact. 2022, 13518, 143–158. [Google Scholar]












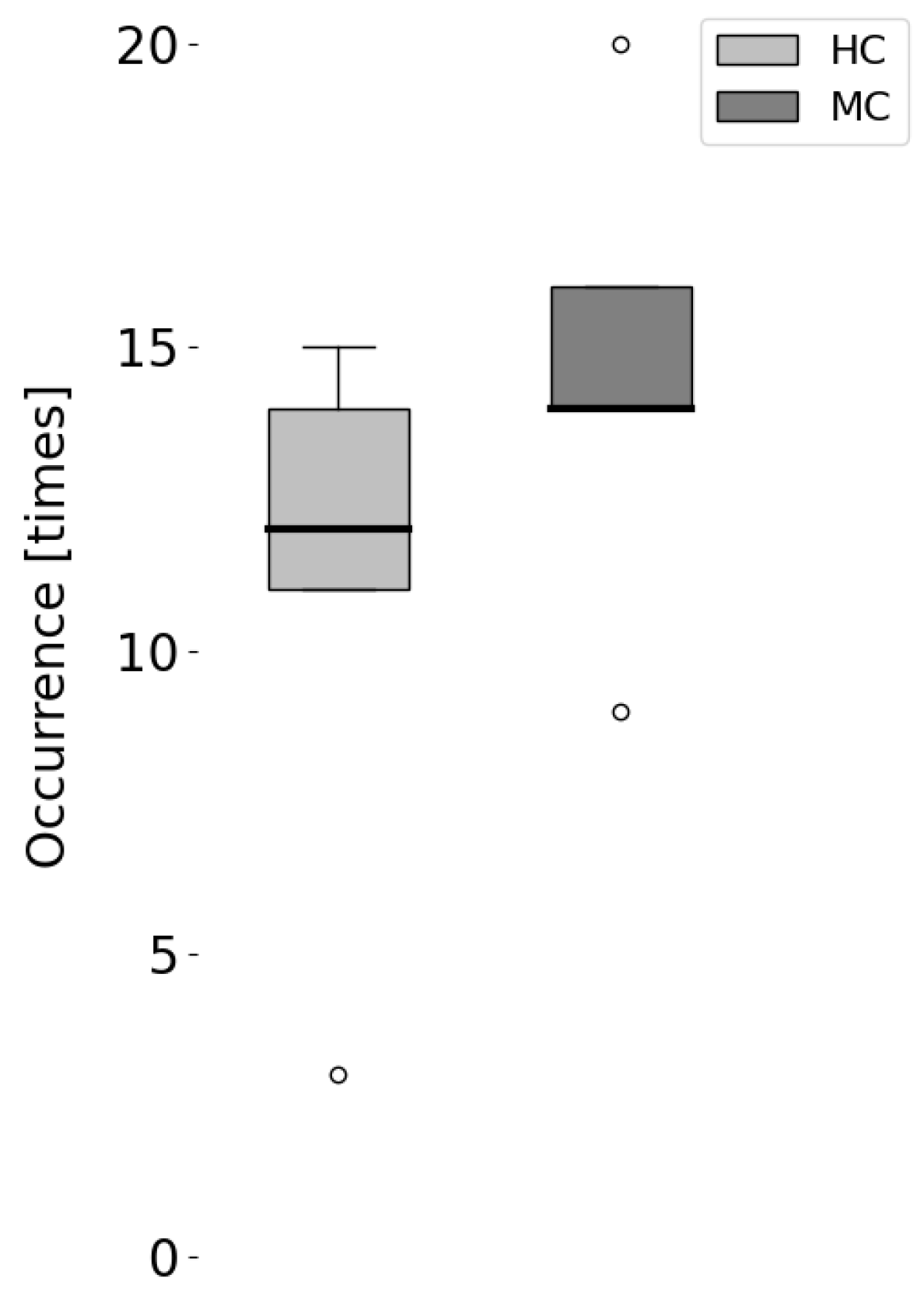
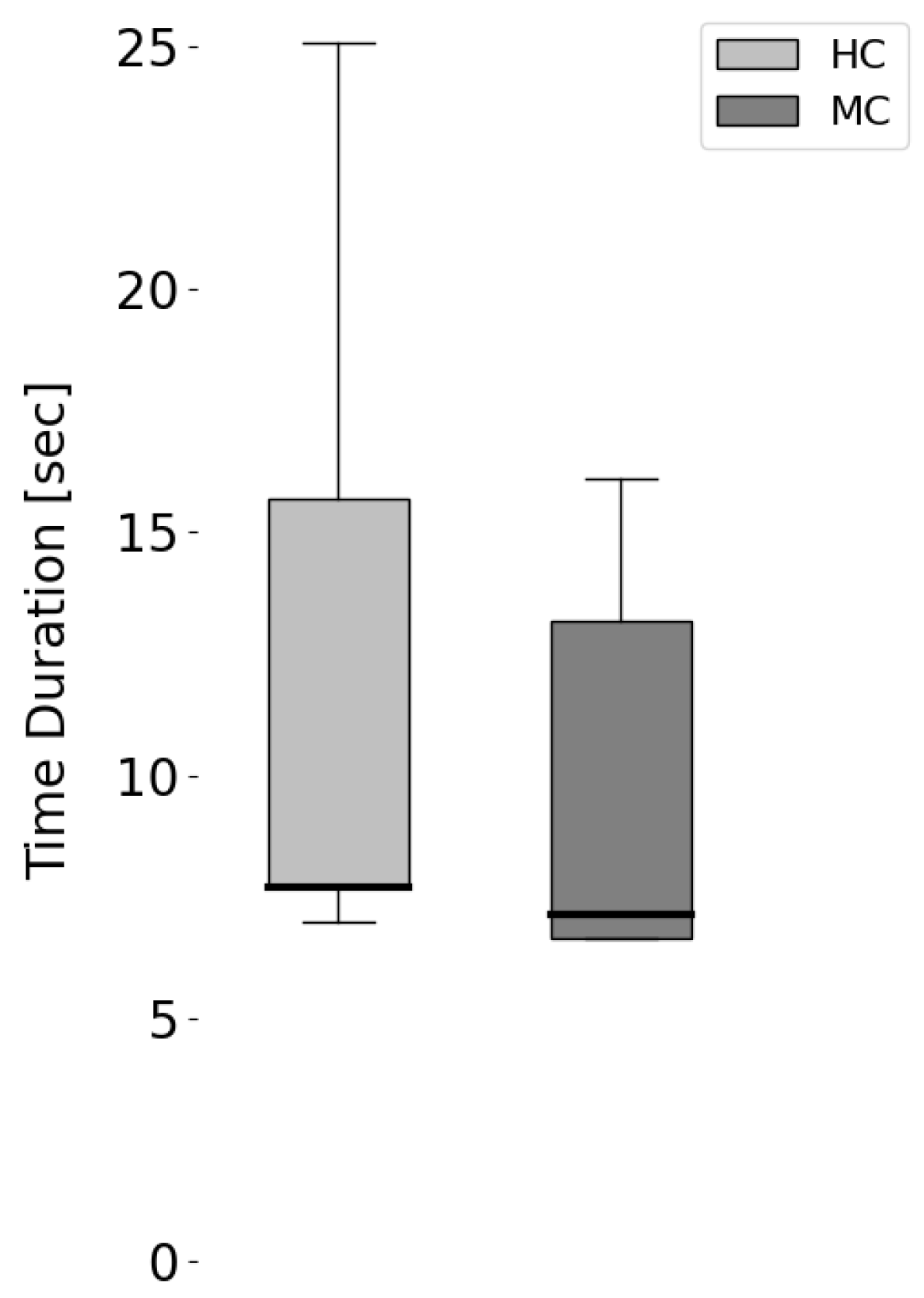
| Aspect of Speech Behavior | Condition | Min | 25% | Median | 75% | Max |
|---|---|---|---|---|---|---|
| Turn Takings | HC | 11 | 11 | 12 | 14 | 15 |
| MC | 14 | 14 | 14 | 16 | 16 | |
| Silent Time | HC | 7.0 | 7.7 | 7.7 | 15.7 | 25.1 |
| MC | 6.6 | 6.6 | 7.1 | 13.2 | 16.1 |
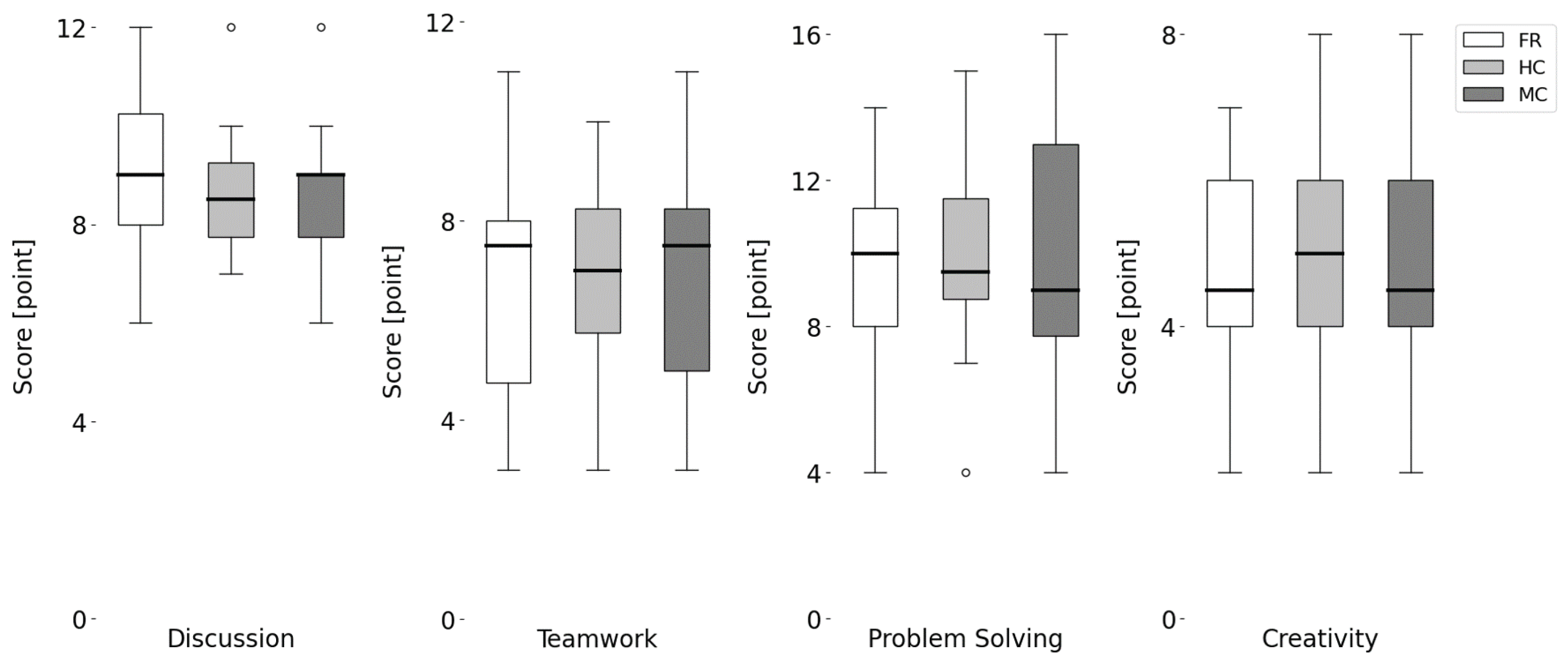
| Rubric Criterion | Full Score | Condition | Min | 25% | Median | 75% | Max | Scoring Ratio |
|---|---|---|---|---|---|---|---|---|
| Discussion | 12 | FR | 6 | 8 | 9 | 10.25 | 12 | 0.75 |
| HC | 7 | 7.75 | 8.5 | 9.25 | 10 | 0.71 | ||
| MC | 6 | 7.75 | 9 | 9 | 10 | 0.75 | ||
| Teamwork | 12 | FR | 3 | 4.75 | 7.5 | 8 | 11 | 0.63 |
| HC | 3 | 5.75 | 7 | 8.25 | 10 | 0.58 | ||
| MC | 3 | 5 | 7.5 | 8.25 | 11 | 0.63 | ||
| Problem Solving | 16 | FR | 4 | 8 | 10 | 11.25 | 14 | 0.63 |
| HC | 7 | 8.75 | 9.5 | 11.5 | 15 | 0.59 | ||
| MC | 4 | 7.75 | 9 | 13 | 16 | 0.56 | ||
| Creativity | 8 | FR | 2 | 4 | 4.5 | 6 | 7 | 0.56 |
| HC | 2 | 4 | 5 | 6 | 8 | 0.63 | ||
| MC | 2 | 4 | 4.5 | 6 | 8 | 0.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sawada, S.; Kim, S.; Hirokawa, M.; Suzuki, K. MirrorCampus: A Synchronous Hybrid Learning Environment That Supports Spatial Localization of Learners for Facilitating Discussion-Oriented Behaviors. Multimodal Technol. Interact. 2024, 8, 31. https://doi.org/10.3390/mti8040031
Sawada S, Kim S, Hirokawa M, Suzuki K. MirrorCampus: A Synchronous Hybrid Learning Environment That Supports Spatial Localization of Learners for Facilitating Discussion-Oriented Behaviors. Multimodal Technologies and Interaction. 2024; 8(4):31. https://doi.org/10.3390/mti8040031
Chicago/Turabian StyleSawada, Shota, SunKyoung Kim, Masakazu Hirokawa, and Kenji Suzuki. 2024. "MirrorCampus: A Synchronous Hybrid Learning Environment That Supports Spatial Localization of Learners for Facilitating Discussion-Oriented Behaviors" Multimodal Technologies and Interaction 8, no. 4: 31. https://doi.org/10.3390/mti8040031