Abstract
This paper deals with the maximum likelihood estimator for the parameter of first-order autoregressive models driven by the stationary Gaussian noises (Colored noise) together with an input. First, we will find the optimal input that maximizes the Fisher information, and then, with the method of the Laplace transform, both the asymptotic properties and the asymptotic design problem of the maximum likelihood estimator will be investigated. The results of the numerical simulation confirm the theoretical analysis and show that the proposed maximum likelihood estimator performs well in finite samples.
1. Introduction
The experiment design has been given a great deal of interest over the last decades from the early statistical literature [1,2,3,4] as well as in the engineering literature [5,6,7]. The classical approach for experiment design consists of two-step procedures: Maximize Fisher information under the energy constraint of the input and find an adaptive estimator that is asymptotically normal with an optimal convergence rate, and the variance achieves the inverse of this Fisher information, as presented in [8].
In the research of [9], the authors showed that real inputs exhibit long-range dependence: the behavior of a real process after a given time t depends on the entire history of the process up to time t, the classical examples are presented in finance [10,11,12], that is why the researchers considered controlled problems not only with white noise or standard Brownian motion, but also with fractional type noise such as the fractional Brownian motion [13,14]. The applications of fractional case can be seen in [15,16,17,18]. Let us take [13] for the example: The authors considered the controlled drift estimation problem in fractional Ornstein–Ulenbeck (FOU) process:
where is a fractional Brownian motion with a known Hurst parameter , whose covariance function is
is a deterministic function in a control space and is the unknown drift parameter. They have achieved the goal of the experiment design.
However, in the real world, we always try to deal with high-frequency or low-frequency data, but not with continuous ones, as presented in the previous example. So, can we find a discrete model which will be pretty close to (1)? To achieve this goal, we apply the Euler approximation with discrete time to , then we have a time series:
where , is a fractional Gaussian noise with distance . When is a positive constant, we can take some special such that then the Equation (2) is a controlled AR(1) (Autoregressive model of order 1) process with fractional Gaussian noise. For simplicity, we rewrite this model with
where is the fractional Gaussian noise (fGn) with the covariance function defined in (20) (when the variance will not affect the final results, here we always suppose that it will be 1). In fact, according to [19] we can extend the noise to the centered regular stationary Gaussian noise with
where is the spectral density of . A similar change-point and Kalman–Bucy problem can be found in [20,21].
Now, let us return to the model (3), the same as the function in (1), denotes a deterministic function of . Obviously, when considering the problem of estimating the unknown parameter, with the observation data , if , it has been solved in [19]. When – the control space defined in (17), Let us denote the likelihood function for , then the Fisher information can be written as
Therefore, we denote
our main goal is to find a function, say, such that
and then with this we will find an adapted estimator of the parameter , which is asymptotically efficient in the sense that, for any compact set ,
as .
In this paper, with the computation of the Laplace transform, we will find for the model (3) and we check that the Maximum Likelihood Estimator (MLE) satisfy (5).
Remark 1.
Here, we assume that the covariance structure of the noise ξ is known. In fact, if this covariance depends only on one parameter, for example, the Hurst parameter H of the fractional Gaussian noise presented in Section 4 we can estimate this parameter with the log-periodogram method [22] or with generalized quadratic variation [23] and study the plug-in estimator. All details can be found in [24].
Remark 2.
In this paper, we will not estimate the function , but we will simply find one function that maximizes Fisher information.
The organization of this paper is as follows. In Section 2, we give some basic results of regular stationary noise , find the likelihood function, and the formula for Fisher information. Section 3 provides the main results of this paper, and Section 4 shows some simulation examples to show the performance of the proposed MLE. All proofs are collected in Appendix A.
2. Preliminaries and Notations
2.1. Stationary Gaussian Sequences
First of all, let us construct the connection between stationary Gaussian noise and the independent case. Suppose that the covariance of the stationary Gaussian process is defined by
when it is positive, then there exists an associated innovation sequence where , are independent, defined by the following relations:
From the theorem of Normal Correlation (Theorem 13.1, [25]) that there exists a deterministic kernel such that and
For , we will denote by the partial correlation coefficient
As with the Levinson–Durbin algorithm (see [26]), we have the following relationship between , the covariance function defined in (6), the sequence of partial correlation coefficients and the variances of innovation :
Since the covariance matrix of is positively defined, there also exists an inverse deterministic kernel such that
The relationship of the kernel k and K can be found in [19].
Remark 3.
It is worth mentioning that the condition (4) implies that
This condition is theoretically verified for classical autoregressive-moving-average (ARMA) noises. To our knowledge, no explicit form of the partial autocorrelation coefficients for fractional Gaussian noise (fGn) is known, but because the explicit formula of the spectral density of fGn sequences has been exhibited in [27], condition (4) is fulfilled for any Hurst index . For very similar fractional autoregressive integrated moving average (fractional ARIMA) processes, it has been proven that in [28].
2.2. Model Transformation
From the Equalities (13) and (14) the process has the same filtration of . In the following parts, let the observation be . Actually, it was shown in [19] that the process Z can be considered as the first component of a 2-dimensional AR(1) process , which is defined by:
It is not hard to obtain that is a 2-dimensional Markov process, which satisfies the following equation:
with
and are independent. Following from the idea of [13] we will define the control space of the function :
From the control space of we can define that for the function :
where is just the absolute value.
2.3. Fisher Information
As we have interpreted, the observation will be the first component of the process . Now, from Equation (15), it is easy to write the likelihood function , which depends on the function :
Consequently, Fisher information can be written as
where .
3. Main Results
In this part, we will present the main results of this paper. First of all, from the presentation of Fisher information (19), we have the following.
Theorem 1.
The asymptotical optimal input in the class of control is for and or for . Furthermore,
where for and for .
Remark 4.
Theorem 1 can be generalized to the AR(p) case with the norm of the Fisher information matrix, but this purpose is not as clear as AR(1), that is: when the Fisher information is larger, the error will be smaller. For this reason, we will illustrate only the result of the first order, but not of the order p.
From Theorem 1, since the optimal input does not depend on the unknown parameter , we can consider as the MLE . The following theorem states that will reach the efficiency of (5).
Theorem 2.
With the optimal input defined in Theorem 1, for , the MLE has the following properties:
- is strong consistency, that is, as .
- is uniformly consistent on compact , i.e. for any
- is uniformly on compacts asymptotically normal, i.e., as ,where ξ is a zero mean Gaussian random variable with variance defined in Theorem 1. Moreover, we have the uniform on convergence of the moments: for any ,
Remark 5.
From Theorem 2, we can see that the asymptotical properties of the MLE do not depend on the structure of the noise, which is the same as described in [19].
4. Simulation Study
In this section, Monte-Carlo simulations are done just for the verification of the asymptotical normality of the MLE with different Gaussian noise such as AR(1), MA(1) and fractional Gaussian noise(fGn). When defined in (8) for the ARMA case is explicit, we can easily obtain the result of MLE, so here we just take the fGn as an example. In fact, the covariance function of fGn is
As presented in Remark 5, the asymptotical normality for the MLE does not depend on the structure of the stationary noise, which means it does not depend on the Hurst parameter H. So, different from [29] and other LSE methods, which have a change at or another point in the fractional case, we only need to verify the asymptotical normality with only one fixed H, and we take this value . Here we compare the different and in Figure 1 and Figure 2.
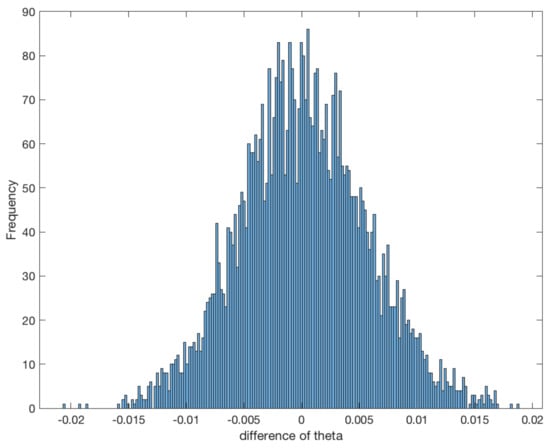
Figure 1.
Histogram of the statistic with and .
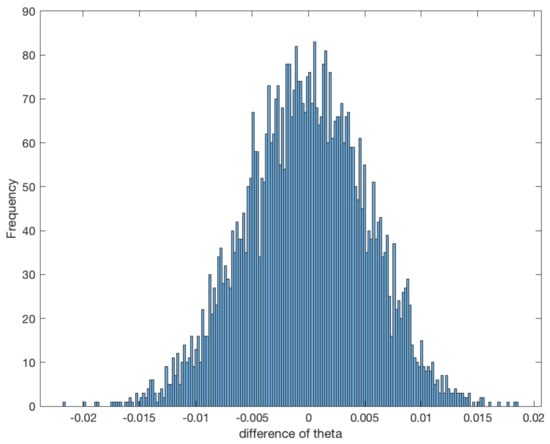
Figure 2.
Histogram of the statistic with and .
Even if we have got the optimal input in Theorem 1, our simulation will not use the initial model (1) because obviously this is so complicated in the fractional case. We will compute our MLE with the transformation (15) with the corresponding using the method of Wood and Chan (see [30]) for the simulation of fractional Gaussian noise. All the simulations will be the same as presented in [19].
Remark 6.
From the two figures, we can see that the statistical error of the MLE is asymptotically normal, and we also have verified that the variance is nearly the same as the inverse of the Fisher information.
5. Conclusions
With the approximation of the controlled fractional Ornstein–Ulenbeck model in (1), we considered the optimal input problem in the AR(1) process driven by stationary Gaussian noise. We have found the controlled function, which maximizes the Fisher information, and with the Laplace Transform, we have proved the asymptotical normality of the MLE, whose asymptotical variance does not depend on the structure of the noise. Our future study will focus on the non-Gaussian case, such as the general fractional ARIMA, and so on.
Author Contributions
Methodology, L.S., M.Z. and C.C.; formal analysis, M.Z.; Writing—original draft, C.C.; Writing—review and editing, L.S. and M.Z. All authors have read and agreed to the published version of the manuscript.
Funding
Lin Sun is supported by the Humanities and Social Sciences Research and Planning Fund of the Ministry of Education of China No. 20YJA630053.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank the editor and reviewers for their valuable comments, which improved the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The appendix provides the proofs of Theorems 1 and 2. Without special note, we only consider , for the proofs will be the same.
Appendix A.1. Proof of Theorem 1
To prove Theorem 1, we separate the Fisher Information of (19) into two parts:
where satisfies the following equation:
Obviously, does not depend on . Thus, and as presented in [19], we have
and which can be deduced by (9) in [19].
A standard calculation yields
To compute , let . Then, we can see that satisfies the following equation:
where and it is bounded.
Note that and , we assume that for , and for the sufficiently small positive constant and . Consequently, we can state the following result.
Lemma A1.
Let be the 2-dimension vector, which satisfies the following equation:
Then, we have
Proof.
For the sake of notational simplicity, we introduce a 2-dimensional vector , which satisfies the following equation:
In this situation, we have three comparisons. First, we compare . A standard calculation implies that
since , we have
which implies .
Now, we compare . A simple calculation shows that
on both sides of this equation, then we have
which implies .
Finally, since and the component of is bounded, we can easily obtain , which demonstrates the proof. □
Now, we define . Then , where is in the space of . Since the initial value will not change our result, we assume without loss of generality.
Let . Then, it is clear that
Now to prove Theorem 1, we only need the following lemma.
Lemma A2.
Proof.
First of all, taking , then , we can conclude that
we can easily abtain that
It is easy to get the lower bound
Furthermore, a simple calculation shows that
where
Obviously, we can rewrite as
or
where
Let with are independent. Then, we have
and
Let us mention that is a compact symmetric operator for fixed N. We should estimate the spectral gap (the first eigenvalue ) of the operator. The estimation of the spectral gap is based on the Laplace transform of , which is written as
for sufficiently small negative . On the one hand, when , is a centered Gaussian process with a covariance operator . Using Mercer’s theorem and Parseval’s identity, can be represented by
where is the sequence of positive eigenvalues of the covariance operator. A straightforward algebraic calculation shows the following.
where
For
there exists two real eigenvalues of the matrix
Then, we can see that
That is to say for and for any , . Thus, and we complete the proof. □
Remark A1.
For , means and . As a consequence, we have .
Appendix A.2. Proof of Theorem 2
Let and be the process with the function . Then, we have
To estimate the parameter from observations , we can write the MLE of with the help of (18)
where
A standard calculation yields
where
The second and third conclusions on the asymptotic normality of Theorem 2 are crucially based on the asymptotical study of the Laplace transform
for .
First, we can rewrite by the following formula:
where .
As presented in [19] and using the Cameron–Martin formula [31], we have the following result.
Lemma A3.
For any N, the following equality holds:
where is the unique solution of the equation
and the function is the solution of the Ricatti equation:
It is worth mentioning that is the unique solution of the equation
where .
With the explicit formula of the Laplace transform presented in Lemma A3, we have its asymptotical property.
Lemma A4.
Proof.
In [19], we have stated that
Since the component of is bounded, we have
From this conclusion, it follows immediately that
Furthermore, using the central limit theorem for martingale, we have
Consequently, the asymptotical part of Theorem 2 is obtained.
Strong consistency is immediate when we change with a positive proper constant in the Lemma A4 because the determinant part tends to 0 as presented in Section 5.2 of [19] and the extra part is bounded.
References
- Kiefer, J. On the Efficient Design of Statistical Investigation. Ann. Stat. 1974, 2, 849–879. [Google Scholar]
- Mehra, R. Optimal Input Signal for Linear System Identification. IEEE Trans. Autom. Control 1974, 19, 192–200. [Google Scholar] [CrossRef]
- Mehra, R. Optimal Inputs Signal for Parameter Estimation in Dynamic Systems-Survey and New Results. IEEE Trans. Autom. Contrl 1974, 19, 753–768. [Google Scholar] [CrossRef]
- Ng, T.S.; Qureshi, Z.H.; Cheah, Y.C. Optimal Input Design for An AR Model with Output Constraints. Automatica 1984, 20, 359–363. [Google Scholar] [CrossRef]
- Gevers, M. From the Early Achievement to the Revival of Experiment Design. Eur. J. Control 2005, 11, 1–18. [Google Scholar] [CrossRef]
- Goodwin, G.; Rojas, C.; Welsh, J.; Feuer, A. Robust Optimal Experiment Design for System Indentification. Automatica 2007, 43, 993–1008. [Google Scholar]
- Ljung, L. System Identification-Theory for the User; Prentice Hall: Englewood Cliffs, NJ, USA, 1987. [Google Scholar]
- Ovseevich, A.; Khasminskii, R.; Chow, P. Adaptative Design for Estimation of Unknown Parameters in Linear System. Probl. Inf. Transm. 2000, 36, 125–153. [Google Scholar]
- Leland, W.E.; Taqqu, M.S.; Willinger, W.; Wilson, D.V. On the Self-similar Nature of Ethernet Traffic. IEEE/ACM Trans. Netw. 1994, 2, 1–15. [Google Scholar] [CrossRef]
- Comte, F.; Renault, E. Long Memory in Continuous-time Stochastic Volatility Models. Math. Financ. 1998, 8, 291–323. [Google Scholar] [CrossRef]
- Gatheral, J.; Jaisson, T.; Rosenbaum, M. Volatility is Rough. Quant. Financ. 2018, 18, 933–949. [Google Scholar] [CrossRef]
- Yajima, Y. On Estimation of Long-Memory Time Series Models. Aust. J. Stat. 1985, 27, 302–320. [Google Scholar] [CrossRef]
- Brouste, A.; Cai, C. Controlled Drift Estimation in Fractional Diffusion Process. Stoch. Dyn. 2013, 13, 1250025. [Google Scholar] [CrossRef]
- Brouste, A.; Marina, K.; Popier, A. Design for Estimation of Drift Parameter in Fractional Diffusion System. Stat. Inference Stoch. Process. 2012, 15, 133–149. [Google Scholar] [CrossRef]
- Cao, K.; Gu, J.; Mao, J.; Liu, C. Sampled-Data Stabilization of Fractional Linear System under Arbitrary Sampling Periods. Fractal Fract. 2022, 6, 416. [Google Scholar] [CrossRef]
- Chen, S.; Huang, W.; Liu, Q. A New Adaptive Robust Sliding Mode Control Approach for Nonlinear Singular Fractional Oder System. Fractal Fract. 2022, 6, 253. [Google Scholar] [CrossRef]
- Jia, T.; Chen, X.; He, L.; Zhao, F.; Qiu, J. Finite-Time Synchronization of Uncertain Fractional-Order Delayed Memristive Neural Networks via Adaptive Sliding Mode Control and Its Application. Fractal Fract. 2022, 6, 502. [Google Scholar] [CrossRef]
- Liu, R.; Wang, Z.; Zhang, X.; Ren, J.; Gui, Q. Robust Control for Variable-Order Fractional Interval System Subject to Actuator Saturation. Fractal Fract. 2022, 6, 159. [Google Scholar] [CrossRef]
- Brouste, A.; Cai, C.; Kleptsyna, M. Asymptotic Properties of the MLE for the Autoregressive Process Coefficients Under Stationary Gaussian Noise. Math. Methods Stat. 2014, 23, 103–115. [Google Scholar] [CrossRef]
- Brouste, A.; Cai, C.; Soltane, M.; Wang, L. Testing for The Change of the Mean-Reverting Parameter of An Autoregressive Model with Stationary Gaussian Noise. Stat. Inference Stoch. Process. 2020, 23, 301–318. [Google Scholar] [CrossRef]
- Brouste, A.; Kleptsyna, M. Kalman Type Filter Under Stationary Noises. Syst. Control Lett. 2012, 61, 1229–1234. [Google Scholar] [CrossRef]
- Robinson, P. Log-periodogram Regression of Time Series with Long-Range Dependence. Ann. Stat. 1995, 23, 1048–1072. [Google Scholar] [CrossRef]
- Istas, J.; Lang, G. Quadratic Variation and Estimation of Local Holder Index of a Gaussian Process. Ann. l’I.H.P. Sect. B 1997, 33, 407–436. [Google Scholar] [CrossRef]
- Ben Hariz, S.; Brouste, A.; Cai, C.; Soltane, M. Fast and Asymptotically-Efficient Estimation in a Fractional Autoregressive Process. 2021. Available online: https://hal.archives-ouvertes.fr/hal-03221391 (accessed on 8 May 2021).
- Liptser, R.S.; Shiryaev, A.N. Statistics of Random Processes II: Applications; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2. [Google Scholar]
- Durbin, J. The Fitting of Time Series Models. Rev. Inst. Int. Stat. 1960, 28, 233–243. [Google Scholar] [CrossRef]
- Sinai, Y.G. Self-Similar Probability Distribution. Theory Probab. Appl. 1976, 21, 64–80. [Google Scholar] [CrossRef]
- Hosking, J. Fractional Differencing. Biometrika 1981, 68, 165–176. [Google Scholar] [CrossRef]
- Chen, Y.; Li, T.; Li, Y. Second Estimator for An AR(1) Model Driven by a Long Momory Gaussian Noise. arXiv, 2020; arXiv:2008.12443. [Google Scholar]
- Wood, A.; Chan, G. Simulation of Stationary Gaussian Processes in [0,1]d. J. Comput. Graph. Stat. 1994, 3, 409–432. [Google Scholar] [CrossRef]
- Kleptsyna, M.L.; Le Breton, A.; Viot, M. New Formulas Concerning Laplace transforms of Quadratic Forms for General Gaussian Sequences. Int. J. Stoch. Anal. 2002, 15, 309–325. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).