Abstract
In many scientific fields, the dynamics of the system are often known, and the main challenge is to estimate the parameters that model the behavior of the system. The question then arises whether one can use experimental measurements of the system response to derive the parameters? This problem has been addressed in many papers that focus mainly on data from a deterministic model, but few efforts have been made to use stochastic data instead. In this paper, we address this problem using the following procedure: first, we build the probabilistic stochastic differential models using a natural extension of the commonly used deterministic models. Then, we use the data from the stochastic models to estimate the model parameters by solving a nonlinear regression problem. Since the stochastic solutions are not differentiable, we use the well-known Nelder–Mead algorithm. Our numerical results show that the fitting procedure is able to obtain good estimates of the parameters requiring only a few sample data.
1. Introduction
The most common approach to studying many biological, ecological, or engineering systems is based on nonlinear dynamic models. One of the major challenges is the calibration of these dynamical models, also known as the parameter estimation problem, which involves finding the unknown parameters of the model that best fit a set of experimental data. Parameter estimation belongs to the class of so-called inverse problems [1], which require not only a prior assumption about the unknown parameters but also a posterior study of the determinability of the parameters. This problem has been tackled by many authors in various fields of science (see reference [2] for practical applications and numerical solutions, and reference [3] for a comprehensive review).
Parameter estimation in finite-dimensional stochastic differential equations (SDEs) has also been addressed in the literature (see [4,5,6,7]).
The classical nonlinear regression problem, which often arises in applications, concerns how to find the values of the parameters when the equations governing the system are known. The main challenge then is to use experimental results or experimental data to derive the values of the system parameters. This problem is currently being addressed by many machine learning techniques, see [8] (Cap. 9) or [9] (Cap. 7).
In this paper, we address this problem considering stochastic data, which seems to be a challenging task.
For an n-dimensional system, the stochastic differential equations (SDE) governing its dynamics are of the form
where is the n-dimensional state vector, refers to m independent Wiener processes, is the vector drift function, and is the diffusion matrix. In practice, as we will see in the following sections, these SDEs depend on a number of parameter whose values determine the behavior of the solutions.
The main idea now is to use the data from Equation (1) to derive the values of the parameters . To do this, we use the least squares method, which is a common approach in regression analysis to solve over-determined systems. The error function has the form for n steps
where are the solutions of the deterministic part computed with the "ode45" command from Matlab; these solutions are obviously dependent on the values of the parameters, and is the stochastic solution ant time for the run or trial using the classical numerical Euler–Maruyama method (we refer to [10,11] and more recently [12] for an overview of numerical solutions of SDEs).
Since we are dealing with a nonlinear optimization problem involving stochastic data, we used the Nelder–Mead algorithm [13,14] (p. 325) or [15] (p. 368) to minimize Equation (2), which proved to be more suitable in these cases.
On the order hand, from the two papers [16,17], in our opinion, it would seem that the most natural extension of moving from a deterministic model to a stochastic model would be to use probabilities instead of simply adding white noise. In these stochastic models that we studied in this paper, which we refer to as probabilistic models, we use tables of probabilities of change and compute the means and variances following [18].
This article is structured as follows. In Section 2 we consider a classical predator–prey model, in Section 3 an epidemic model, and finally in Section 4 a chemical-reaction model. For these three models, we first build the stochastic model and then try to calibrate the parameters using the Nelder–Mead algorithm and solve the deterministic part using the "ODE45" Matlab solver. Finally, in Section 5 we analyze the numerical results and draw the main conclusions and possible future research.
2. A Predator–Prey Model
In this first model, we study the well-known Lotka–Volterra predator–prey system, where the preys are rabbits, which have an infinite food supply, and the predators are foxes. This example was previously studied in [17,19], assuming that the changes and their probabilities are those given in Table 1.

Table 1.
Population changes and their probabilities.
That is, given the parameter , the fox encounters the rabbit with a probability proportional to the product of their numbers, and is a coefficient for the reproduction of the rabbits.
Fixing at time t, we calculate the expected change for
and the covariance matrix
results in the following SDE system:
where and are two independent Wiener processes.
Fitting Model to Data
In this example, the error function is
where and are the stochastic data averaged over a given number of trials (nrum) using the Euler–Maruyama method. and are the solution of the deterministic equations. The goal is then to find the values of and using a fitting method. To evaluate the error function for a given solution , the deterministic part of the system (5) is first solved numerically. This solution is then used to construct a clamped cubic spline interpolation function that can be evaluated to obtain values for R and F at the various ’s appearing in the error function.
Table 2 reports the average values of the parameters obtaind using the Nelder–Mead algorithm as a function of the number of trials and the number of iteration steps. The initial point is , , and the parameters are , and .
Table 2.
Estimated average values of the parameters obtained using the Nelder–Mead algorithm as a function of the number of trials and the number of iteration steps for , and .
Given these results, it is perhaps most surprising that our algorithm achieves good approximation of the actual parameters with just a single trial. On the other hand, we note that the performance of the algorithm is achieved with few iterations, regardless of the number of trials.
For graphical illustration, we have plotted (see Figure 1) the phase space corresponding to a stochastic simulation of the Lotka–Volterra model with the estimated parameters (red colour) and the actual parameters (blue colour). The results are shown for a single trial (left panel) and the average over 100 trials (right panel). We also plotted the average values of the parameters as a function of the number of trials (see Figure 2).
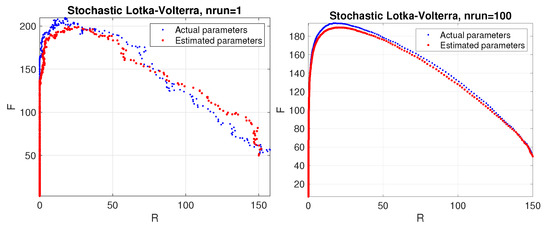
Figure 1.
Predator–prey model. Phase space corresponding to a stochastic simulation of the Lotka–Volterra model using the estimated parameters (red color) compared to the actual ones (blue color). Results are shown for a single trial (left panel) and average over 100 trials (right panel).
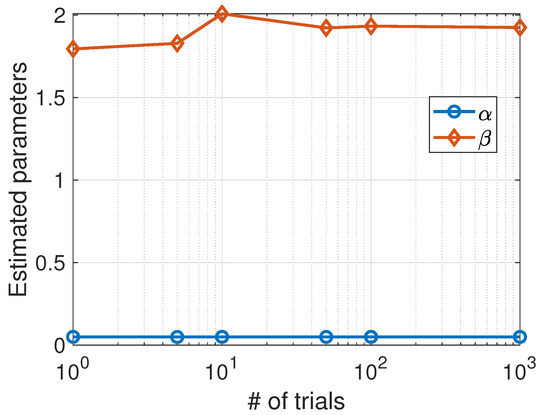
Figure 2.
Predator–prey model. Average values of the parameters estimated using the Nelder–Mead algorithm as a function of the number of trials.
3. A Stochastic SIS Model with Deaths
Here, we review the main points of the SIS model with demography [20,21]. In this paper, we consider an infection model of the population where only deaths of infected individuals are considered. The changes and their first-order probabilities in the are those in Table 3.
Table 3.
Population changes and probabilities of infection, death, and recovery of infected individuals.
As in the previous example, the mean and variance were calculated according to [18] (p. 148) and using Symbolic Math Toolbox of Matlab©. The obtained stochastic model is then:
where
and
with
The deterministic version of this model is given by
The asymptotic behavior of this system depends on the basic reproduction number , and according to [22], this model reaches a disease-free equilibrium when . In this paper, we consider the particular case with the parameters , , and , such that .
Fitting Model to Data
For this model, the error function is given as a function of three parameters,
where and refer to the average stochastic data over a number of trials using the Euler–Maruyama method, while and are the solution of the deterministic equations.
The results given in Table 4 were obtained with initial conditions , and parameters , and . The phase space corresponding to a stochastic simulation of the SIS model with the estimated parameters (red colour) and the actual parameters (blue colour) is shown in Figure 3.
Table 4.
Average values of the parameters estimated using the Nelder–Mead algorithm as a function of the number of trials. The number of required iteration steps to achieve these estimated parameters is also reported. The values of actual parameters are .
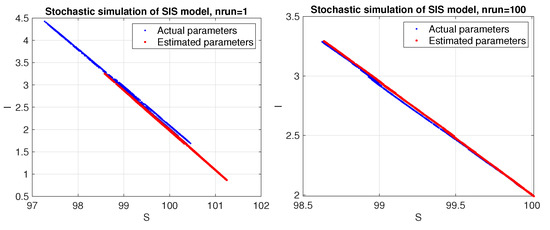
Figure 3.
SIS model. Phase space corresponding to a stochastic simulation using the estimated parameters (red color) compared to the actual ones (blue color). Results are shown for a single trial (left panel) and average over 100 trials (right panel).
Unlike the Lotka–Volterra model, the SIS model appears to be more sensitive to random data and requires averaging stochastic data over a sufficient number of trials to obtain good estimates for the parameters. As can be seen in Figure 4, the estimated parameters converge toward the actual values as the number of trials increases.
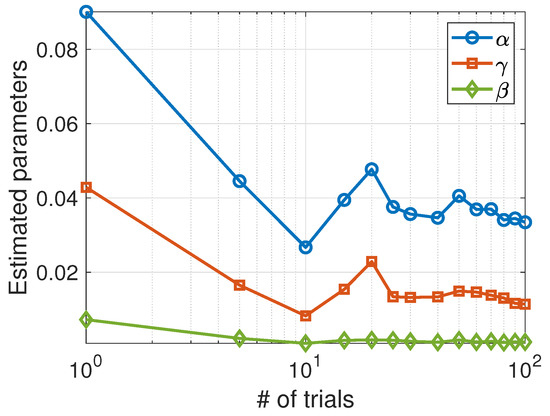
Figure 4.
Average values of the parameters estimated using the Nelder–Mead algorithm as a function of the number of trials.
4. A Chemical-Reaction Model
In our third experiment, we consider the Michaelis–Menten model for chemical reactions. In this model, we consider a system with four nonnegative variables: , , , and , which refer to the concentrations of substrate, enzyme, complex, and product, respectively. These chemical reactions are described in the following form:
where , and are the reaction constants.
To construct the stochastic system, we define the new variables
where is the Avogadro’s number. The possible random changes at each time step are given in Table 5 where
Table 5.
Possible change in and their probabilities.
In this paper, we set the values of the parameters as given in [23]. The molecular data corresponding to concentrations within a volume of liters are given as follows:
Following [24], we obtain a stochastic differential system with four independent Brownian motions and show that is equivalent to the chemical Langevin model (see e.g. [25,26,27] or [28]), i.e.,
with only three independent Brownian motions and the state change vectors
we will use this second model (12) because it is easier to simulate.
Fitting Model to Data
Following the same procedure as in the previous two cases, the error function is
where refer to the average stochastic data over a number of trials using the Euler–Maruyama method, while are the solution of the deterministic equations.
The average values of the estimated parameters obtained by the Nelder–Mead algorithm as a function of the number of trials and the number of iterations are given in Table 6.
Table 6.
Average values of the parameters obtained using the Nelder–Mead algorithm as a function of the number of trials and the number of iteration steps. The original values of parameters are , , and .
In this case, the achieved results are less dependent on the level of randomness of the data and show a stable behavior as can be seen in Figure 5. We also plotted the phase space corresponding to a stochastic simulation of the Higham chemical model using the estimated parameters (red color) compared to the actual parameters (blue color). The results are shown in Figure 6 for a single trial (left panel) and the average over 100 trials (right panel).
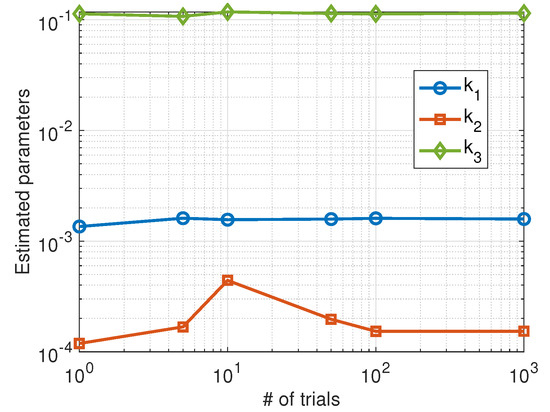
Figure 5.
Average values of the parameters estimated using the Nelder–Mead algorithm as a function of the number of trials.
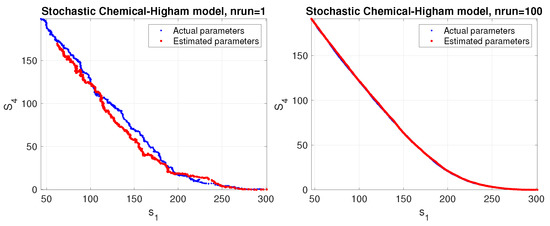
Figure 6.
Phase space corresponding to a stochastic simulation of the Higham chemical model using the estimated parameters (red color) compared to the actual parameters (blue color). The results are shown for a single trial (left panel) and average over 100 trials (right panel).
5. Conclusions
The main conclusion we draw from our research is that the fitting procedure used in this paper to determine parameters from data is valid even when the data come from stochastic models. The approach has been successfully tested on three stochastic models from different domains. Moreover, in all cases it seems that few samples are sufficient to obtain good estimates for the parameters.
We wonder if this procedure will be applicable in general SDE. The error function (2) for large can be written as
assuming that the mean of the stochastic solution equals the deterministic solution. In particular when the drift is linear is true [12] (p. 66) but is false when the SDE is nonlinear, for example, the SDE
the mean satisfies , while the solution of the deterministic part is .
However, for our models, the procedure achieves excellent results. Perhaps the previous hypothesis applies to our models; we do not know at the moment.
Consistent with the work and our preliminary studies, techniques developed in recent years [29,30] for discovering nonlinear dynamical equations from data, without making assumptions about the underlying equations of motion, appear to work with stochastic data and provide promising results. In the future, we plan to investigate various differential models and attempt to discover their dynamics using data from the corresponding stochastic models.
On the other hand, since derivatives of a non-integer order [31] are a natural generalization of the ordinary differentiation of integer order, mathematical models using fractional-order differential equations have proven to be a suitable tool to study and understand temporal memory and intrinsic dissipative processes in many physical and biological systems. To our knowledge, however, there have been few attempts to estimate the parameters of fractional-order stochastic systems. In [32], the authors investigated estimation problems for difusion processes satisfying SDEs driven by mixed fractional Brownian motion. In the future, we hope to be able to extend the approach presented in this paper to consider fractional-order SDEs.
Author Contributions
Conceptualization, F.V. and A.M.; methodology, F.V. and A.M.; software, validation and formal analysis F.V. and A.M.; writing—original draft preparation F.V. and A.M.; writing—review and editing F.V. and A.M.; funding acquisition, F.V. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Spanish Ministry of Sciences Innovation and Universities with the project PGC2018-094522-B-100 and by the Basque Government with the project IT1247-19.
Data Availability Statement
The numerical methods were implemented in Matlab; the codes are available on request. The experiments were carried out in an Intel(R) Core(TM)i7-8665U CPU @ 1.90G.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Clermont, G.; Zenker, S. The inverse problem in mathematical biology. Math. Biosci. 2015, 260, 11–15. [Google Scholar] [CrossRef] [PubMed]
- Schittkowski, K. Numerical Data Fitting in Dynamical Systems: A Practical Introduction with Applications and Software; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002; Volume 77. [Google Scholar]
- McGoff, K.; Mukherjee, S.; Pillai, N. Statistical inference for dynamical systems: A review. Stat. Surv. 2012, 9, 209–252. [Google Scholar] [CrossRef]
- Liu, Q.A.; Varshney, D.; McAuley, K.B. Parameter and uncertainty estimation in stochastic differential equation models with multi-rate data and nonstationary disturbances. Chem. Eng. Res. Des. 2022, 183, 118–133. [Google Scholar] [CrossRef]
- Nielsen, J.N.; Madsen, H.; Young, P.C. Parameter estimation in stochastic differential equations: An overview. Annu. Rev. Control. 2000, 24, 83–94. [Google Scholar] [CrossRef]
- Bishwal, J.P. Bayes and Sequential Estimation in Stochastic PDEs. In Parameter Estimation in Stochastic Differential Equations; Springer: Berlin/Heidelberg, Germany, 2008; pp. 79–97. [Google Scholar]
- Bishwal, J.P. Maximum Likelihood Estimation in Fractional Diffusions. In Parameter Estimation in Stochastic Differential Equations; Springer: Berlin/Heidelberg, Germany, 2008; pp. 99–122. [Google Scholar]
- Deisenroth, M.; Faisal, A.A.; Ong, C.S. Mathematics for Machine Learning. Available online: https://mml-book.github.io/book/mml-book.pdf (accessed on 2 November 2022).
- Murphy, L. Machine Learning. A Probabilistic Perspective; Massachusetts Institute of Technology: Cambridge, MA, USA, 2012. [Google Scholar]
- Higham, D. An Algorithmic Introduction to Numerical Simulation of Stochastic Differential Equations. SIAM Rev. 2001, 43, 525–546. [Google Scholar] [CrossRef]
- Kloeden, P.; Platen, E. Numerical Solution of Stochastic Differential Equations; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Higham, D.; Kloeden, E. An Introduction to the Numerical Simulation of Stochastic Differential Equations; SIAM: Philadelphia, PA, USA, 2021. [Google Scholar]
- Lagarias, J.; Reeds, J.; Wright, M.; Wright, P. Convergence Properties of the Nelder–Mead Simplex Methos in Low Dimensions. SIAM J. Optimition 1998, 9, 112–147. [Google Scholar] [CrossRef]
- Yang, W.; Cao, W.; Chung, T.; Morris, J. Applied Numerical Methods Using MATLAB; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Holmes, M. Introduction to Scientific Computing and Data Analysis; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Skvortsov, A.; Ristic, B.; Kamenev, A. Predicting population extinction from early observations of the Lotka–Volterra system. Appl. Math. Comput. 2018, 320, 371–379. [Google Scholar] [CrossRef]
- Vadillo, F. Comparing stochastic Lotka–Volterra predator–prey models. Appl. Math. Comput. 2019, 360, 181–189. [Google Scholar] [CrossRef]
- Allen, E. Modeling with Itô Stochastic Differential Equations; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- de la Hoz, F.; Vadillo, F. A mean extinction-time estimate for a stochastic Lotka–Volterra predator–prey model. Appl. Math. Comput. 2012, 219, 170–179. [Google Scholar] [CrossRef]
- Nasell, I. Stochastic models for some epidemica infectios. Math. Biosci. 2002, 179, 1–19. [Google Scholar] [CrossRef]
- Greenhalgh, D.; Mao, Y.L.X. SDE SIS epidemicmodel with demographic stochasticity and varying populations ize. Appl. Math. Comput. 2016, 276, 218–238. [Google Scholar]
- de la Hoz, F.; Doubova, A.; Vadillo, F. Persistence-time Estimation for some Stochastic SIS Epidemic Models. Discret. Countinous Dyn. Syst. Ser. B 2015, 20, 2933–2947. [Google Scholar] [CrossRef]
- Higham, D. Modeling and Simulating Chemical Reactions. SIAM Rev. 2008, 50, 347–368. [Google Scholar] [CrossRef]
- Vadillo, F. On Stochastic Models of Chemical Reactions. Chem. Phys. 2021, 549, 111259. [Google Scholar] [CrossRef]
- Gillespie, D. Approximate accelerated stochastic simulation of chemically. J. Chem. Phys. 2001, 115, 1716–1733. [Google Scholar] [CrossRef]
- Gillespie, D. The Chemical Langevin and Fokker-Planck Equations for the Reversible Isomerization Reaction. J. Phys. Chem. 2002, 106, 5063–5071. [Google Scholar] [CrossRef]
- Gillespie, D.; Petzold, L. Numerical simulation for biochemicalkinetics. In System Modeling in Cellular Biology From Concepts to Nuts and Bolts; Szallasi, Z., Stelling, J., Periwal, V., Eds.; MIT Press: Cambridge, MA, USA, 2006; p. 331353. [Google Scholar]
- Schilick, T. Molecular Modeling and Simulation. An Interdisciplinary Guide, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Brunton, S.L.; Proctor, J.L.; Kutz, J.N. Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proc. Natl. Acad. Sci. 2016, 113, 3932–3937. [Google Scholar] [CrossRef] [PubMed]
- Brunton, S.; Kutz, J. Data-Driven Science and Enginnering. Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Samko, S.G.; Kilbas, A.A.; Marichev, O.I. Fractional Integrals and Derivatives: Theory and Applications; Transl. from the Russian; Gordon and Breach: New York, NY, USA, 1993. [Google Scholar]
- Song, N.; Liu, Z. Parameter Estimation for Stochastic Differential Equations Driven by Mixed Fractional Brownian Motion. Abstr. Appl. Anal. 2014, 2014, 1–6. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).