1. Introduction
Optimization based on stochastic gradients is of central practical significance in many scientific and engineering fields. Many problems in these areas can be reduced to optimization problems of some scalar parameterized objective function for which parameters need to be maximized or minimized. Recent years have witnessed the great success of machine learning, especially deep learning, in many fields, including computer vision, speech processing, and natural language processing. For many machine learning tasks, a critical and challenging problem is to design optimization algorithms to train neural network models. If the objective function is differentiable, stochastic gradient descent (SGD) is an efficient and effective optimization method that plays a central role in many machine learning successes. The SGD algorithm can be traced back to Robbins and Monro [
1], who stated that the classical convergence analysis depends on the decreasing positive learning rate condition. Stochastic approximation methods have been widely studied in various areas of the literature [
2,
3,
4], mainly focusing on the convergence of algorithms in different environments.
In recent years, the convergence speed of standard SGD has been greatly improved, and a number of methods to reduce variance have been adopted, such as vanilla SGD in the non-convex case [
5]. However, vanilla SGD is too sensitive to the learning rate, making it difficult to adjust the appropriate learning rate, and its convergence performance is poor. There have been many attempts to achieve easily tunable learning rates and improve SGD performance, For example, in the case of the smooth and strongly convex objective function, the variance of stochastic gradient decrease [
6,
7,
8,
9], adaptive learning rate [
10,
11,
12,
13,
14,
15,
16], averaging [
17], momentum acceleration mechanism [
18,
19,
20,
21], and the Powerball method [
22] are used, and a better self optimization control method is proposed using fractional-order Gaussian noise [
23]. The most promising variance reduction technique is the stochastic variance reduction gradient (SVRG) [
8,
9]. In fact, these stochastic methods need to store and use the full batch of past gradients in order to progressively reduce the variance of the stochastic gradient estimator. For stochastic optimization problems, the number of training samples is usually large; consequently, the algorithm can be difficult to implement if the storage space is limited. Therefore, adaptive learning rate and momentum mechanisms are more suitable for stochastic optimization problems than variance reduction.
In addition to the classical optimization algorithms, several other popular stochastic optimization algorithms can be found in the current literature, for example, genetic algorithms, which are inspired by biological evolution [
24], particle swarm optimization derived from the natural behavior of clusters [
25,
26], and the most recent dynamic stochastic fractal search optimization algorithm based on the adaptive strategy of fuzzy logic for diffusion parameters [
27]. However, because heuristic algorithms are proposed based on experience without a theoretical basis, they lack a unified and complete theoretical framework. In addition, due to the use of non-deterministic polynomial theory, global optimality cannot be guaranteed when using the heuristic polynomial approach.
Adaptive step sizes have a long history in convex settings. They were first proposed in the online learning literature [
28] and later applied to the random learning literature [
12]. In a recent study, an adaptive projection gradient algorithm has been proposed for a special nonlinear fractional optimization problem with an objective function that is smooth convex in the numerator and smooth concave in the denominator [
29]. In [
30], a very weak condition is proposed for the non-convex function to converge to the global optimum almost everywhere, and in [
31], a new convergence analysis method for SGD under a decreasing learning rate regime is proposed. In [
16,
32,
33], the authors studied several classes of stochastic optimization algorithms enriched with heavy ball momentum, showing a linear rate for the stochastic heavy ball method (i.e., stochastic gradient descent method with momentum (SGDM)). This does not require large memory, merely requiring slightly more computation in each iteration compared with the vanilla SGD method. Therefore, both techniques have been widely used and demonstrated to be effective for training deep neural networks [
10,
13]. On the one hand, common SGD variants have been designed and analyzed under convex settings [
12], and the results may not provide a relevant guarantee of convergence [
13]. On the other hand, it is well known that linear convergence can be achieved even with constant step-size gradient descent under certain conditions. However, while most of the advanced SGD variants can achieve faster convergence rates by applying adaptive step size, the convergence rate is not yet ideal.
We summarize the main contributions of the present paper to the existing results in the literature as follows:
For smooth and convex functions, a novel adaptive step-size stochastic gradient descent (AdaSGD) method is proposed, and a momentum acceleration variant (AdaSGDM) is studied as well. It is proven that both have a convergence rate of , where T is the maximum number of iterations.
For smooth but non-convex functions, we show that both AdaSGD and AdaSGDM achieve global optimization with a convergence rate of .
The rest of this paper is organized as follows. In
Section 2, we describe the optimization problem and present the AdaSGD and AdaSGDM method along with details of the adaptive step sizes. In
Section 3, we prove the convergence rates of the proposed AdaSGD and AdaSGDM theoretically.
Section 4 presents a practical implementation and discusses the experimental results on problems arising from machine learning. Finally, a brief conclusion and discussion of possible future work is presented in
Section 5.
2. Problem Statement
Consider the following unconstrained minimization problem:
where
is a differentiable function (though not necessarily convex). More concretely, we assume that
has a Lipschitz gradient.
Assumption 1. The continuously differentiable function is bounded below by , and its gradient is L-Lipschitz; i.e., there exists a constant such that, for all ,where denotes the Euclidean norm. Notice that the inequality does not imply the convexity of
f. However, the assumption that
f is
L-smooth for any
implies that ([
34], Lemma 1.2.3)
Because we are interested in solving (
1) using stochastic gradient methods, we assume that at each
we have access to an unbiased estimator of the true gradient
, denoted by
, where
is a source of randomness. Thus, we need the following assumptions, which analyze SGD under the assumptions that
is lower bounded and that the stochastic gradients
are unbiased and have bounded variance [
5].
Assumption 2. For any , the stochastic gradient oracle provides us an independent unbiased estimate of upon receiving query :where ξ is a random variable satisfying certain specific distributions and the variance of the random variable is bounded as follows:for some parameter . It is worth noting that in the standard setting for SGD, the random vectors
are independent of each other (and of
; see, e.g., [
17]). Note that due to unbiasedness, Assumption 2 is the standard stochastic gradient oracle assumption used for SGD analysis and the standard variance bound is equivalent to
. Classic convergence analysis of the SGD algorithm relies on placing conditions on the positive step size
[
1]. In particular, sufficient conditions are that
The first condition is both necessary and intuitive, as it is necessary for the algorithm to be able to travel an arbitrary distance in order to reach the stationary point from the initial point. However, the second condition is actually unnecessary. Many popular step size choices, such as that of Adagrad [
12], find it difficult to satisfy this condition, even when the step size can guarantee the convergence of Adagrad on convex sets.
2.1. Adaptive Step Size Stochastic Gradient Descent
More specifically, Adagrad [
11] can be used to solve problem (
1), as follows:
where the element-wise matrix-vector multiplication ⊙ between
and
, which here is
, is a diagonal matrix in which each diagonal element
i,
is the sum of the squares of the gradients with respect to
up to time step
k, while
is a smoothing term that avoids division by zero (usually on the order of
). Interestingly, without the square root operation, the algorithm performs much more poorly. In this work, we focus on SGD with adaptive step size promotion, which iteratively updates the solution via
with an arbitrary initial point
and adaptive step-size
;
is a random variable obeying some distribution. In the sequelae, we let
denote a stochastic gradient and assume that we have access to a stochastic first-order black-box oracle that returns a noisy estimate of the gradient of
f at any point
. Unlike [
11], in this paper we use the expectation of the stochastic gradient
and its second moment to design a new adaptive step size, then obtain a new kind of adaptive stochastic gradient descent method (AdaSGD).
The pseudo-code of our proposed AdaSGD algorithm is presented in Algorithm 1.
| Algorithm 1 Adaptive Stochastic Gradient Descent (AdaSGD) Method |
- 1:
Initialization: initialize and the maximum number of iterations T - 2:
Iterate: - 3:
fordo - 4:
Compute the step size (i.e., learning rate) . - 5:
Generate a random variable . - 6:
Compute a stochastic gradient . - 7:
Update the new iterate . - 8:
End for
|
2.2. Adaptive Step Size Stochastic Gradient Descent with Momentum
In addition, we consider the momentum acceleration variant of the proposed AdaSGD for application of the algorithm. Similarly, the difference from stochastic heavy-ball in [
35] is the different selection of adaptive step size. The updates to the AdaSGDM are as follows:
with
, where
is the momentum constant. Equivalently, denoting by
, AdaSGDM can be implemented in two steps for
where
,
. It is notable that during updating of
, a momentum term is constructed based on the auxiliary sequence
. When
, the method returns to AdaSGD. The pseudo-code of the AdaSGDM algorithm is presented in Algorithm 2.
| Algorithm 2 Adaptive Stochastic Gradient Descent Momentum (AdaSGDM) Method |
- 1:
Initialization:, initialize and the maximum number of iterations T - 2:
Iterate: - 3:
fordo - 4:
Compute the step size (i.e., learning rate) . - 5:
Generate a random variable . - 6:
Compute a stochastic gradient . - 7:
Update the new iterate: - 8:
, - 9:
. - 10:
End for
|
To facilitate analysis of the stochastic momentum methods, we note that (
3) implies the following recursions, which are straightforward to verify:
where
is provided by
and
. Let
; then,
3. Convergence Analysis
In this section, without knowledge of the noise, we state the convergence results of AdaSGD and AdaSGDM under the convex settings in
Section 3.1. Similarly, the convergence of the two methods under non-convex settings is analyzed in
Section 3.2.
3.1. Adaptive Convergence Rates for Convex Functions
In this section, the convergence of AdaSGD and AdaSGDM under convex settings is discussed using the classical convergence analysis method under the specific adaptive step size iteration. Before stating the theorem for the convergence conclusion, we first provide the following technical Lemma for proving the theorem.
Lemma 1 ([
15]).
When f is L-smooth, then , where . Next, we first provide the convergence results of AdaSGD and AdaSGDM in the case of convex functions.
Theorem 1. Assumptions 1 and 2 hold if f is convex by designing an appropriate adaptive step size, as follows:where is a parameter. Then, the iterates of AdaSGD () and AdaSGDM () satisfy the following bound:where , , are random initial points, C is a positive constant, and T is the maximum number of iterations. Proof. From the iterative format (
4), we can obtain
The adaptive step-size we analyze here is a generalization of ones widely used in the online and stochastic optimization literature. As such, their good performance has already been validated using numerous empirical results. In particular, we consider in the following parts that the step size satisfies (
7). In addition, for
and
, there always exists
and
such that
and
Taking the conditional expectation with respect to
, we can find that
The first inequality is provided by (
10), and the second inequality by the convexity of the function. The last inequality is provided by defining where
and
. Hence, by summing (
9) over
to
T and incorporating (
12), we have
Notice the initial conditions
,
; then,
Next, we consider the boundedness of the second term on the right side of (13):
the first inequality is provided by (
11) and the second by Lemma 1. Substituting (14) into (13), we have
By recombining (15) and the definition of
,
and we choose
such that
.
Note that
and
can be obtained from (
10) and (
11). Per the definition of
and
, and without loss of generality, we can assume that
. Then,
Let
; then,
which means that
Now, from Jensen’s inequality, we have
where
. □
3.2. Adaptive Convergence for Non-Convex Optimization
We now turn to the case where f is non-convex. In practice, most loss functions are non-convex. Because the convexity of a function plays an important role in convergence analysis, the convergence conclusion is not valid in the case of non-convexity. However, there are few theoretical results about stochastic optimization convergence in non-convex environments. In this section, we analyze the convergence of AdaSGD and AdaSGDM under non-convex settings by applying the expectation of the stochastic gradient and the second moment to the design of the adaptive step size.
Theorem 2. Let Assumptions 1 and 2 hold if f is non-convex. We choose the step size as in (7). Then, the iterates of AdaSGD satisfy the following bound:where is one of the minimum point of the function over , is a random initial point, is a positive constant, and T is the maximum number of iterations. Proof. Because
is an
L-smooth function, we have
Using the expectation on both sides of (16),
Now, by taking the adaptive step size as (
7), we have
From (
10) and (
11),
we choose
such that
. Let
; then,
By summing (17) for
and averaging it,
then,
where
is one of the minimum point of the function
over
. □
In order to prove the convergence of AdaSGDM under a non-convex setting, we first analyze the relationship between the local error bound of the function and the local variation and gradient. Second, the relationship between the local variation of gradient and gradient is further analyzed. Finally, the boundary of the gradient is obtained, that is, the convergence of AdaSGDM under a non-convex setting. Before we state the adaptive convergence of AdaSGDM for non-convex optimization, we first present the following two Lemmas.
Lemma 2. Let . For AdaSGDM, we have the following for any :where L is the Lipschitz constant of f, is the momentum constant as mentioned in (2), and are parameters in (10) and (11), and is the parameter in (7). Proof. Because
is a smooth function, we have
We define
; then, from Assumption 2,
can be obtained. Then,
Recombining (18) and using the expectation of both sides,
where the second inequality uses the inequality of the arithmetical and geometric means
. By taking the adaptive step-size as (
7) and substituting it into (19), we have
using (
10) and (
11). □
Lemma 3. For AdaSGDM, for any , we havewhere , L is the Lipschitz constant of f, and is the momentum constant as mentioned in (2). For , and are parameters in (10) and (11), respectively, and is the parameter in (7). Proof. Because
f is
L-smooth,
, and (
5), we have
Recall the recursion in (
6), that is,
. Note that
. By induction, for
,
Let
; then,
Taking the expectation over both sides of (23) and noting the step size (
7), we have
Then, taking the expectation of both sides of (21) and substituting the above inequality into it, we have
which means that (20) is established. □
Based on the previous Lemmas 2 and 3, we can now state the convergence analysis of AdaSGDM under non-convex settings.
Theorem 3. Let Assumptions 1 and 2 hold, and let f be a non-convex and L-smooth function. Choosing the step size as in (7), the iteration sequence obtained by AdaSGDM satisfies the following bound:where , are constants, , and T is the maximum number of iterations. Proof. From the initial conditions, it follows that
; thus, Lemmas 2 and 3 imply the following inequality:
By summing (24) for
,
where
and
. For
, we choose
. Thus, it is true that
for
as well as that
. Then,
Furthermore, because
and
, we have
where
. □
4. Experiments
In this section, we present experimental results of applying our adaptive schemes to several test problems.
Section 4.1 focuses on regularized linear regression problem and regularized logistic regression problem, which are widely used in the machine learning community, while
Section 4.2 considers the non-convex support vector machine (SVM) problem and non-convex quadratic problem. In both, we report the performance of AdaSGD and AdaSCDM and compare them with SGDM, Adam and Adagrad. In each instance, we set the step size for AdaSGD and AdaSGDM using the procedure in (
7). To make the comparison equitable, the default parameter values for Adam are selected according to [
9], especially
and
. For Adagrad, the initial step size is
. Using random datasets, we prove that the proposed adaptive SGD can effectively solve practical deep learning problems.
The parameters in SGDM are set to a step size of and momentum coefficient of in the following applications. We repeated the experiment ten times and report the average results. All methods use the same random initialization; all figures in this section are in log–log scale, and the maximum number of iterations T = 10,000. Finally, all the algorithms involved in the experiment were implemented using MATLAB R2017a (9.2.0.538062) 64 bit software in Windows 10.
4.1. Convex Functions
Consider the following two convex optimization problems: an -regularized quadratic function with , and an -regularized logistic regression for binary classification with with the penalty parameter , where and . The entries of b are randomly −1 or 1. Rows in A are generated by an i.i.d multivariate Gaussian distribution conditioned on . We use a mini-batch of size n to compute a stochastic gradient at each iteration. Note that the gradients of functions and are continuous; we assume that random sampling of small batches from the datasets satisfies Assumption 2.
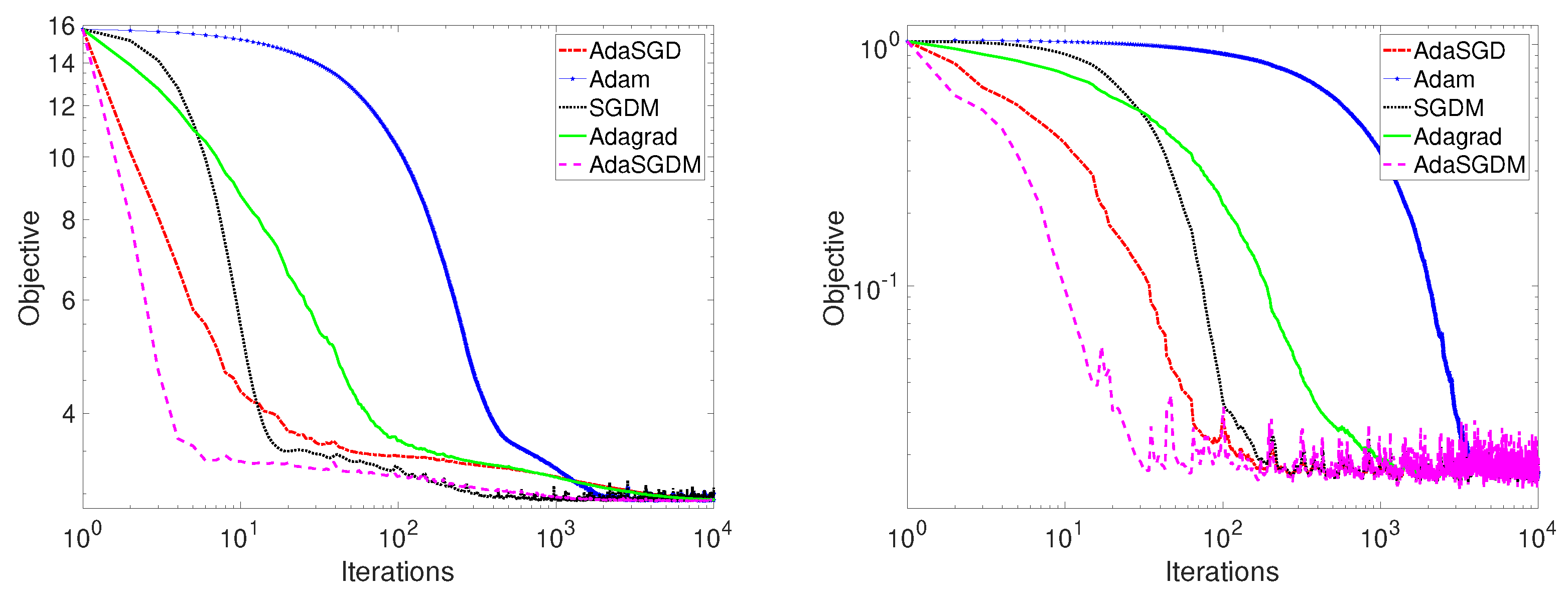
When
and
, the convergence paths of the procedure for minimizing different convex functions in SGDM, Adam, Adagrad, and the proposed AdaSGD and AdaSGDM is demonstrated in
Figure 1, where the left subfigure in
Figure 1, corresponding to function
, takes 10.337139 s, and the right subfigure in
Figure 1, corresponding to function
, takes 4.947887 s. When
and
. The results are shown in
Figure 2, where the left and right subgraphs in
Figure 2, corresponding to
and
, take 2130.277402 s and 442.714215 s, respectively.
From the left and right figures in
Figure 1 and
Figure 2, it is not difficult to see that AdaSGD and AdaSGDM show better convergence than existing stochastic optimization methods when considering the convex optimization problems of different models. Observe that SGDM displays local acceleration close to the optimal point and attains convergence rate of
, as shown in [
36]. Adagrad shows a convergence rate of
, as mentioned in [
11]. Adam eventually attains a rate of convergence of
, as shown in [
10]. The proposed methods, AdaSGD and AdaSGDM, tend to converge faster than the SGDM, Adam, or Adagrad, showing a convergence of
, which is consistent with our theory results in this paper.
4.2. Non-Convex Functions
Consider the following non-convex support vector machine (SVM) problem with a sigmoid loss function, which has previously been considered in [
5] (the data points are generated in the same way as in
Section 4.1):
, where
is a regularization parameter. In addition, consider the following non-convex optimization problem corresponding to the elastic regression network model [
37]:
, where
and
. Here, we use a mini-batch of size
n to compute a stochastic gradient at each iteration. For minimizing the two non-convex functions
and
, the gradient of
is obviously continuous. For
it is easy to know that the derivative of
at point
does not exist; however, we can use the subgradient at this point. For example, one of the subgradients of
here is
. Although this gradient is discontinuous, it satisfies the Lipschitz condition, meaning that the conclusion in Theorem 3 holds. The convergence paths of the algorithms SGDM, Adam, Adagrad, AdaSGD, and AdaSGDM when (
,
) and (
,
) are shown in
Figure 3 and
Figure 4. The CPU times of the left and right subfigures corresponding to
and
in
Figure 3 are 10.808409 s and 5.824761 s, respectively, and those of
and
in
Figure 4 are 2369.346180 s and 455.041079 s, respectively.
From the figures in
Figure 3 and
Figure 4, it can be seen that AdaSGD and AdaSGDM maintain good convergence when considering non-convex optimization problems of different models. For different non-convex objective functions with Lipschitz continuous gradients, it can be observed that the gradient converges in expectation at the order of
of SGDM, as shown in [
36]. As described in [
10], the convergence analysis for Adam is not applicable to non-convex problems, and it is only through experience that Adam is likely to perform better than other methods. The Adagrad algorithm displays a convergence rate of
under non-convex setting, as showed in [
38]. For the proposed methods in this paper, AdaSGD and AdaSGDM, tend to converge faster than SGDM, Adam, and Adagrad under non-convex settings, showing a convergence of
, which is consistent with our theory result in this paper.
5. Conclusions and Future Work
In this paper, two shortcomings of the adaptive stochastic gradient descent method for stochastic optimization problems are studied. The first is the assumption of a convex setting, which is often harsh in many practical optimization problems of machine learning. The second is slow convergence, which is a result of using the adaptive step size of past stochastic gradients, and is generally up to . As a consequence, in this paper we first propose a new adaptive SGD in which the new step size is a function of the expectation of the past stochastic gradient and its second moment. In both convex and non-convex settings, the adaptive SGD with the new designed step size converges at the rate of . Second, the new adaptive SGD is extended to the case with momentum, and again achieves a convergence rate of , irrespective of convex or non-convex settings. To sum up, our results indicate that the designed adaptive step size is able to alleviate the problem of slow convergence caused by inherent variance to a certain extent. The proposed approach achieves accelerated convergence in convex setting, and works in non-convex settings as well. Experimental results show that the proposed adaptive stochastic gradient descent methods, both with and without momentum, have better convergence performance than existing methods. In the future, we hope to apply this method to large datasets or to actual data collection in order to better analyze its effectiveness.



{kind=link}
{kind=link}
{kind=link}
{kind=link}



