
Parameter Estimation for Several Types of Linear Partial Differential Equations Based on Gaussian Processes


Abstract
:1. Introduction
2. Mathematical Model and Methodology
2.1. Gaussian Process Prior
2.2. Data Training
2.3. Gaussian Process Posterior
3. Inverse Problem for Fractional PDEs and the System of Linear PDEs
3.1. Processing of Fractional PDEs
3.2. Processing of the System of Linear PDEs
4. Numerical Tests
4.1. Simulation for a High-Order Partial Differential Equation
4.2. Simulation for a Fractional Partial Differential Equation
4.3. Simulation for a Partial Integro-Differential Equation
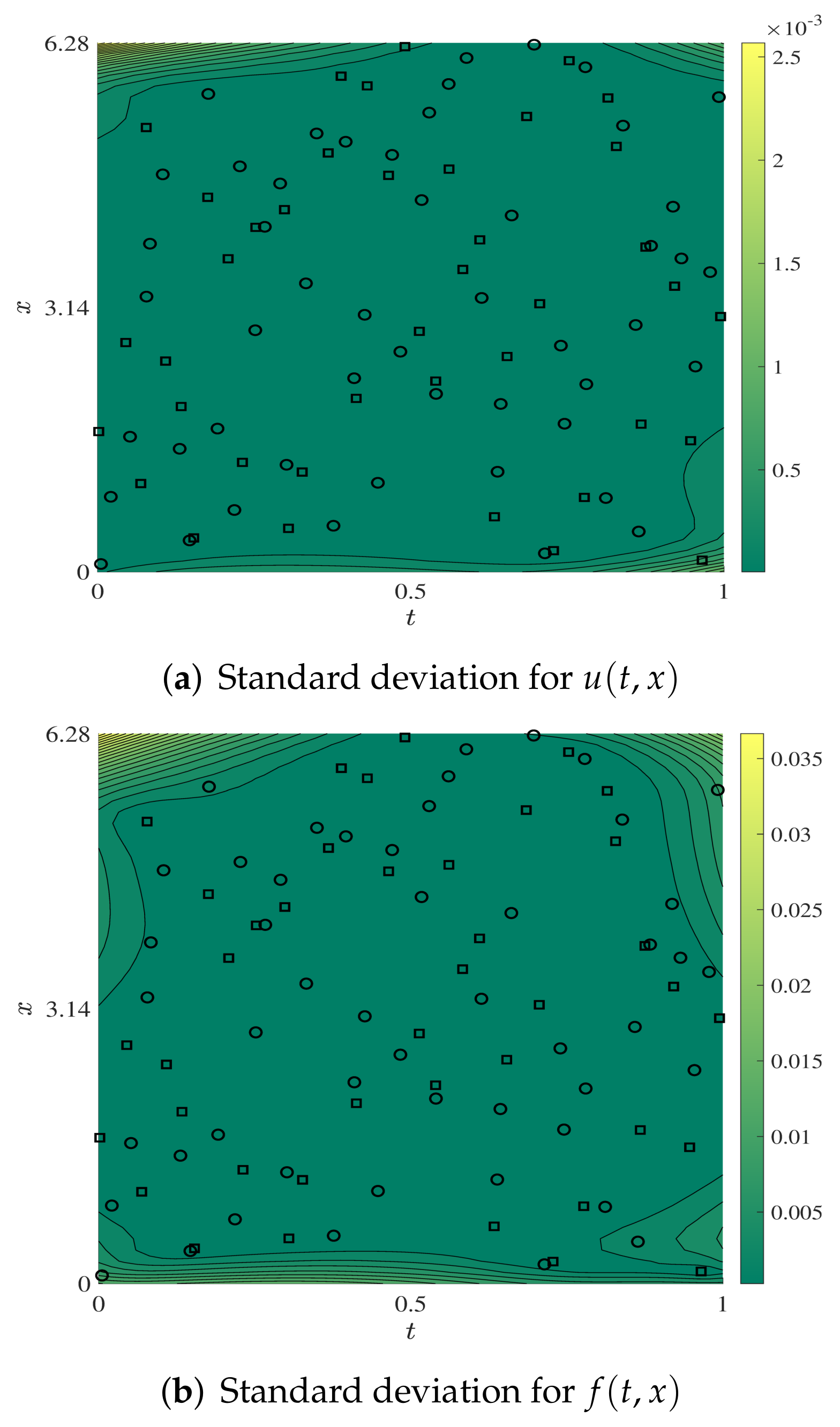
4.4. Simulation for a System of Partial Differential Equations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rudy, S.H.; Brunton, S.L.; Proctor, J.L.; Kutz, J.N. Data-driven discovery of partial differential equations. Sci. Adv. 2017, 3, e1602614. [Google Scholar] [CrossRef] [PubMed]
- Ghahramani, Z. Probabilistic machine learning and artificial intelligence. Nature 2015, 521, 452–459. [Google Scholar] [CrossRef] [PubMed]
- Chen, I.Y.; Joshi, S.; Ghassemi, M.; Ranganath, R. Probabilistic machine learning for healthcare. Annu. Rev. Biomed. Data Sci. 2021, 4, 393–415. [Google Scholar] [CrossRef]
- Maslyaev, M.; Hvatov, A.; Kalyuzhnaya, A.V. Partial differential equations discovery with EPDE framework: Application for real and synthetic data. J. Comput. Sci. 2021, 53, 101345. [Google Scholar] [CrossRef]
- Lorin, E. From structured data to evolution linear partial differential equations. J. Comput. Phys. 2019, 393, 162–185. [Google Scholar] [CrossRef]
- Arbabi, H.; Bunder, J.E.; Samaey, G.; Roberts, A.J.; Kevrekidis, I.G. Linking machine learning with multiscale numerics: Data-driven discovery of homogenized equations. JOM 2020, 72, 4444–4457. [Google Scholar] [CrossRef]
- Chang, H.; Zhang, D. Machine learning subsurface flow equations from data. Comput. Geosci. 2019, 23, 895–910. [Google Scholar] [CrossRef]
- Martina-Perez, S.; Simpson, M.J.; Baker, R.E. Bayesian uncertainty quantification for data-driven equation learning. Proc. R. Soc. A 2021, 477, 20210426. [Google Scholar] [CrossRef]
- Dal Santo, N.; Deparis, S.; Pegolotti, L. Data driven approximation of parametrized PDEs by reduced basis and neural networks. J. Comput. Phys. 2020, 416, 109550. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Kaipio, J.; Somersalo, E. Statistical and Computational Inverse Problems; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Kremsner, S.; Steinicke, A.; Szölgyenyi, M. A deep neural network algorithm for semilinear elliptic PDEs with applications in insurance mathematics. Risks 2020, 8, 136. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Soling partial differential equations using deep learning and physical constraints. Appl. Sci. 2020, 10, 5917. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Y.; Sun, H. Physics-informed learning of governing equations from scarce data. Nat. Commun. 2021, 12, 6136. [Google Scholar] [CrossRef]
- Gelbrecht, M.; Boers, N.; Kurths, J. Neural partial differential equations for chaotic systems. New J. Phys. 2021, 23, 43005. [Google Scholar] [CrossRef]
- Cheung, K.C.; See, S. Recent advance in machine learning for partial differential equation. CCF Trans. High Perform. Comput. 2021, 3, 298–310. [Google Scholar] [CrossRef]
- Omidi, M.; Arab, B.; Rasanan, A.H.; Rad, J.A.; Par, K. Learning nonlinear dynamics with behavior ordinary/partial/system of the differential equations: Looking through the lens of orthogonal neural networks. Eng. Comput. 2021, 38, 1635–1654. [Google Scholar] [CrossRef]
- Lagergren, J.H.; Nardini, J.T.; Lavigne, G.M.; Rutter, E.M.; Flores, K.B. Learning partial differential equations for biological transport models from noisy spatio-temporal data. Proc. R. Soc. A 2020, 476, 20190800. [Google Scholar] [CrossRef]
- Koyamada, K.; Long, Y.; Kawamura, T.; Konishi, K. Data-driven derivation of partial differential equations using neural network model. Int. J. Model. Simul. Sci. Comput. 2021, 12, 2140001. [Google Scholar] [CrossRef]
- Kalogeris, I.; Papadopoulos, V. Diffusion maps-aided Neural Networks for the solution of parametrized PDEs. Comput. Methods Appl. Mech. Eng. 2021, 376, 113568. [Google Scholar] [CrossRef]
- Rifkin, R.; Yeo, G.; Poggio, T. Regularized least-squares classification. Nato Sci. Ser. Sub Ser. III Comput. Syst. Sci. 2003, 190, 131–154. [Google Scholar]
- Drucker, H.; Wu, D.; Vapnik, V.N. Support vector machines for spam categorization. IEEE Trans. Neural Netw. 2002, 10, 1048–1054. [Google Scholar] [CrossRef]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Machine learning of linear differential equations using Gaussian processes. J. Comput. Phys. 2017, 348, 683–693. [Google Scholar] [CrossRef]
- Yang, S.; Xiong, X.; Nie, Y. Iterated fractional Tikhonov regularization method for solving the spherically symmetric backward time-fractional diffusion equation. Appl. Numer. Math. 2021, 160, 217–241. [Google Scholar] [CrossRef]
- Bernardo, J.M.; Smith, A.F. Bayesian Theory; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Oates, C.J.; Sullivan, T.J. A modern retrospective on probabilistic numerics. Stat. Comput. 2019, 29, 1335–1351. [Google Scholar] [CrossRef]
- Hennig, P.; Osborne, M.A.; Girolami, M. Probabilistic numerics and uncertainty in computations. Proc. R. Soc. A Math. Phys. Eng. Sci. 2015, 471, 20150142. [Google Scholar] [CrossRef]
- Conrad, P.R.; Girolami, M.; Särkkä, S.; Stuart, A.; Zygalakis, K. Statistical analysis of differential equations: Introducing probability measures on numerical solutions. Stat. Comput. 2017, 27, 1065–1082. [Google Scholar] [CrossRef]
- Hennig, P. Fast probabilistic optimization from noisy gradients. In Proceedings of the International Conference on Machine Learning PMLR, Atlanta, GA, USA, 17–19 June 2013; pp. 62–70. [Google Scholar]
- Kersting, H.; Sullivan, T.J.; Hennig, P. Convergence rates of Gaussian ODE filters. Stat. Comput. 2020, 30, 1791–1816. [Google Scholar] [CrossRef]
- Raissi, M.; Karniadakis, G.E. Hidden physics models: Machine learning of nonlinear partial differential equations. J. Comput. Phys. 2018, 357, 125–141. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Inferring solutions of differential equations using noisy multi-fidelity data. J. Comput. Phys. 2017, 335, 736–746. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Numerical Gaussian processes for time-dependent and nonlinear partial differential equations. SIAM J. Sci. Comput. 2018, 40, A172–A198. [Google Scholar] [CrossRef]
- Scholkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Konig, H. Eigenvalue Distribution of Compact Operators; Birkhäuser: Basel, Switzerland, 2013. [Google Scholar]
- Berlinet, A.; Thomas-Agnan, C. Reproducing Kernel Hilbert Spaces in Probability and Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Zhu, C.; Byrd, R.H.; Lu, P.; Nocedal, J. Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization. ACM Trans. Math. Softw. (TOMS) 1997, 23, 550–560. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Dorigo, M.; Stützle, T. Ant colony optimization: Overview and recent advances. In Handbook of Metaheuristics; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Raissi, M.; Babaee, H.; Karniadakis, G.E. Parametric Gaussian process regression for big data. Comput. Mech. 2019, 64, 409–416. [Google Scholar] [CrossRef]
- Snelson, E.; Ghahramani, Z. Sparse Gaussian processes using pseudo-inputs. In Advances in Neural Information Processing Systems 18 (NIPS 2005); MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Liu, H.; Ong, Y.S.; Shen, X.; Cai, J. When Gaussian process meets big data: A review of scalable GPs. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4405–4423. [Google Scholar] [CrossRef]
- Milici, C.; Draganescu, G.; Machado, J.T. Introduction to Fractional Differential Equations; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Podlubny, I. Fractional Differential Equations; Academic Press: San Diego, CA, USA, 1998. [Google Scholar]
- Povstenko, Y. Linear Fractional Diffusion-Wave Equation for Scientists and Engineers; Birkhäuser: New York, NY, USA, 2015. [Google Scholar]
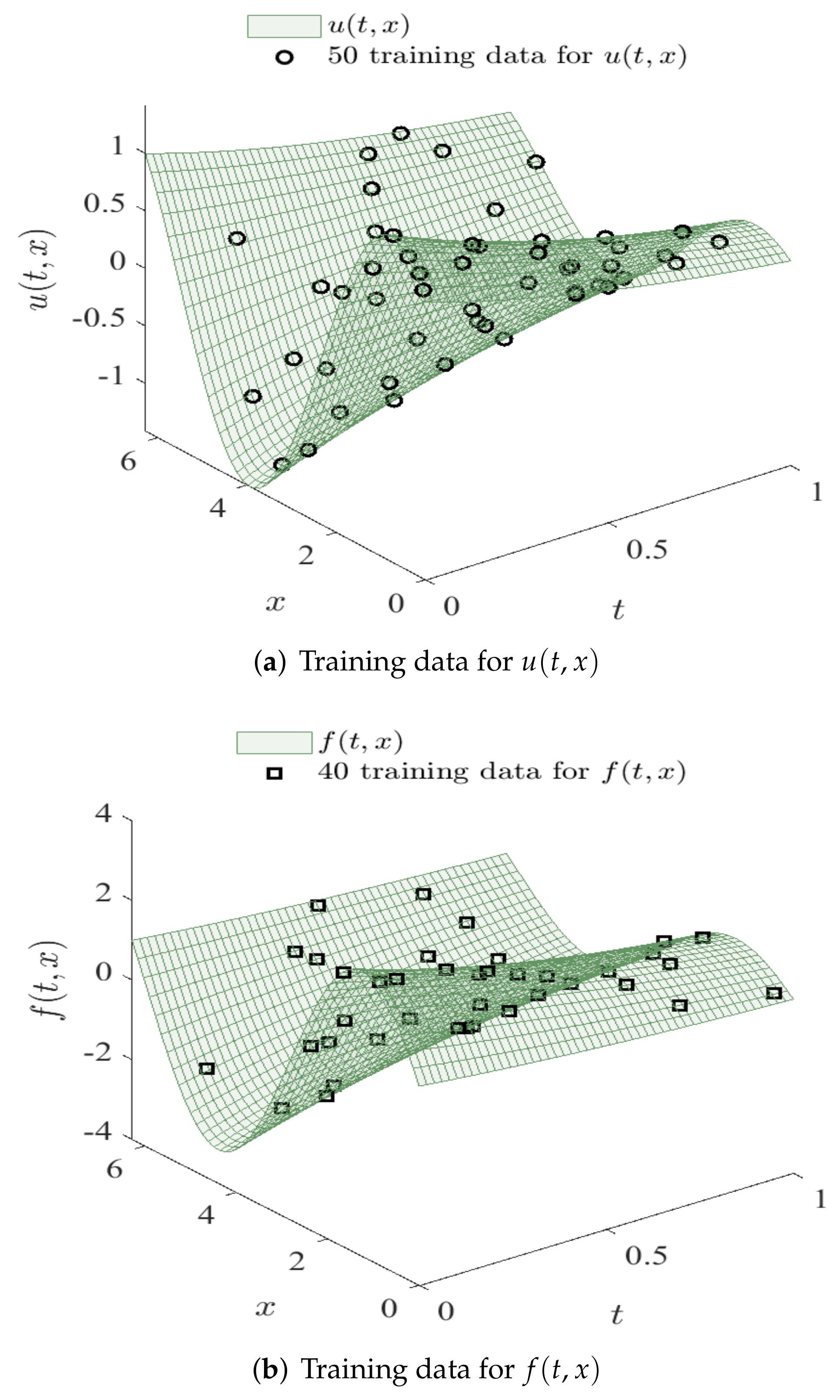

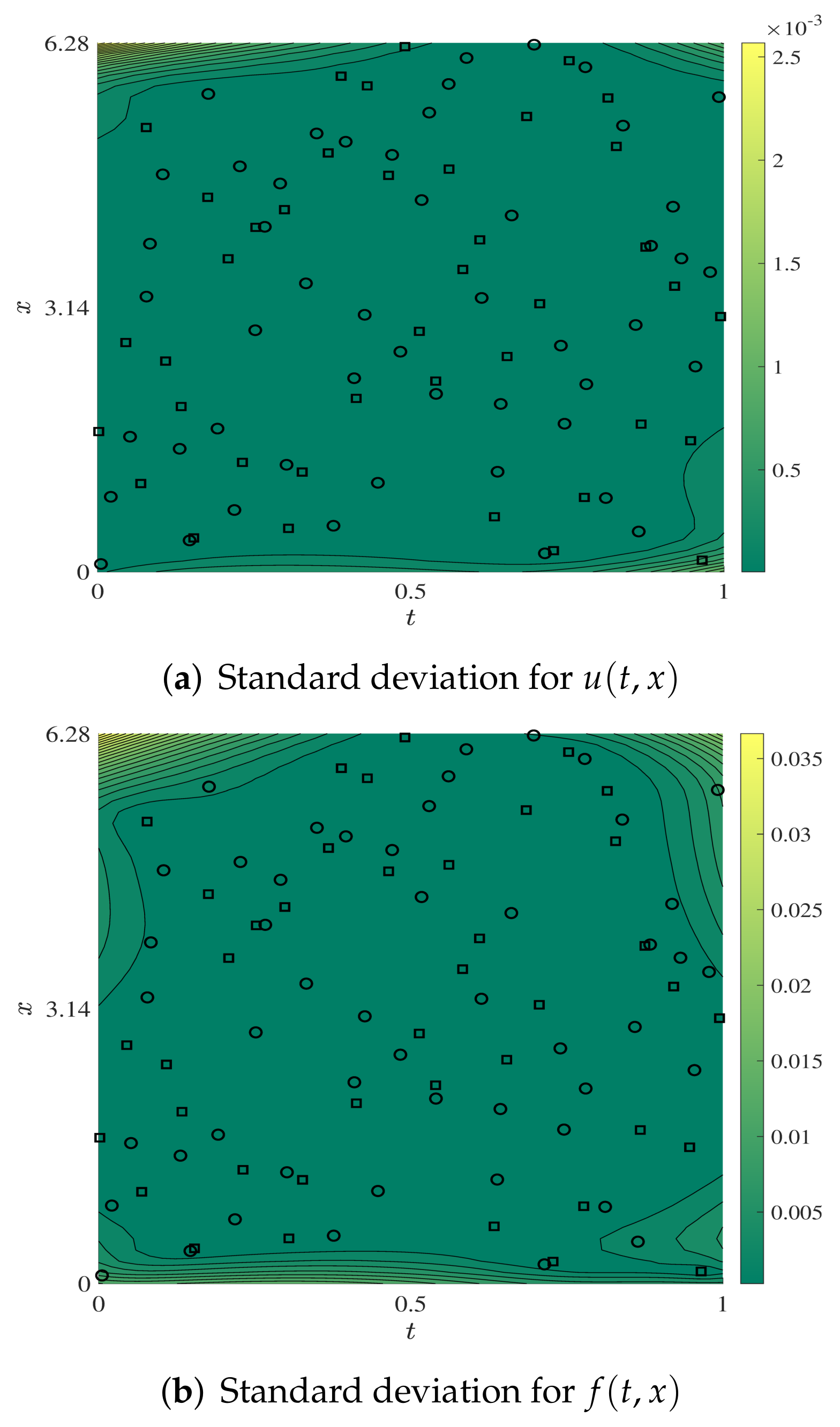

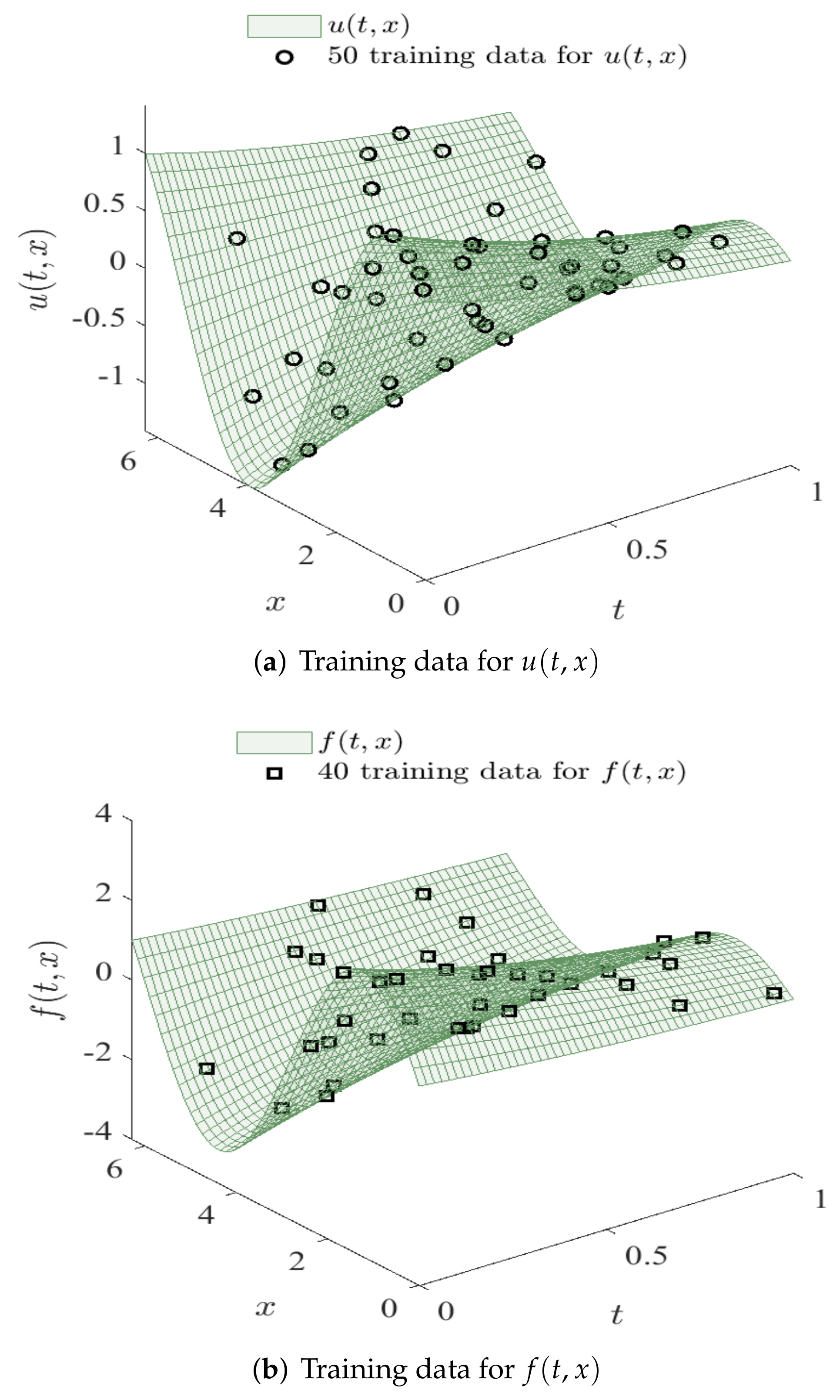{kind=link}
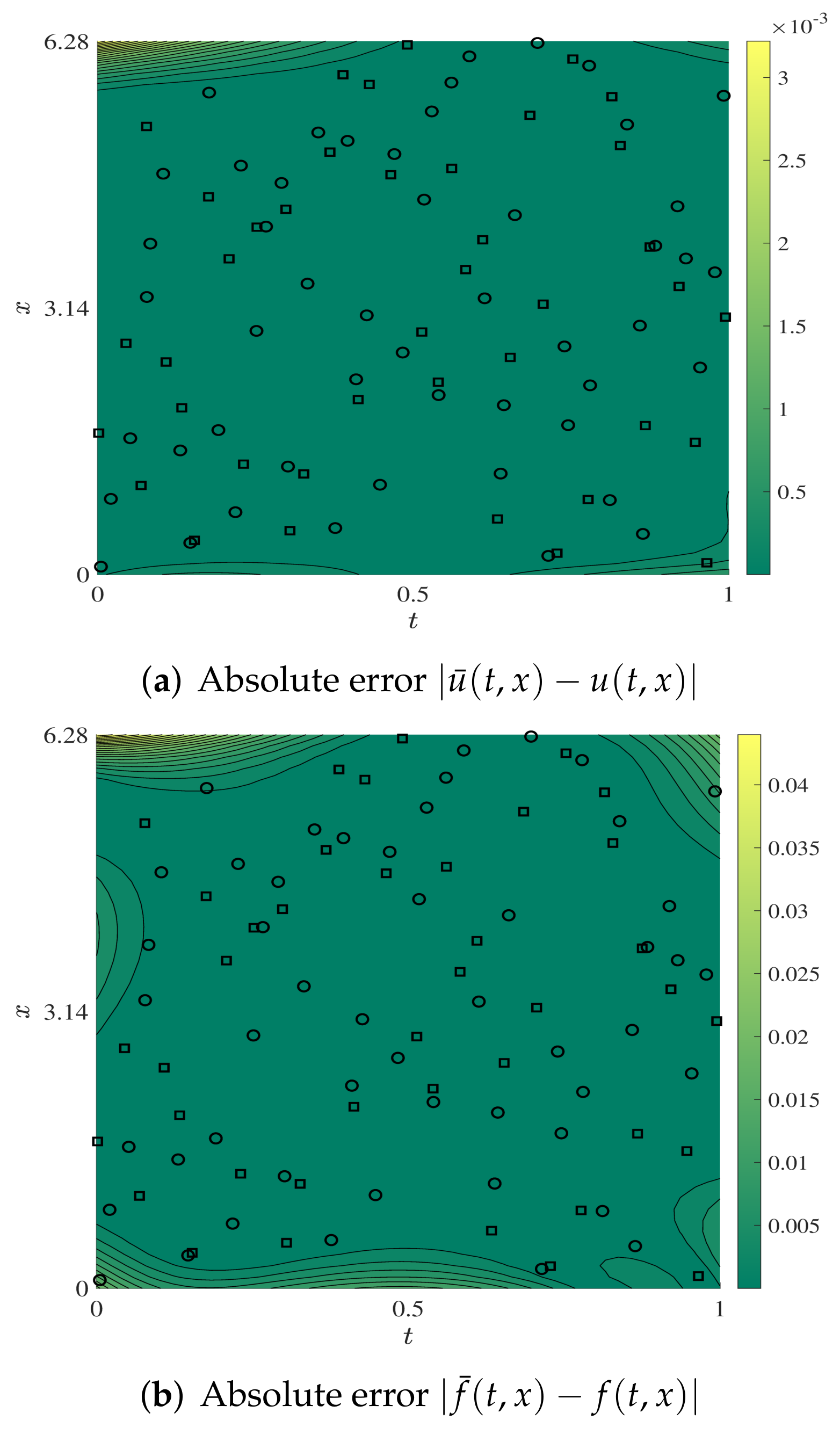{kind=link}
{kind=link}
| 1.014005 | 1.021724 | 2.006856 | 2.008363 | |
| 1.014634 | 2.032989 | 1.006408 | 2.020304 | |
| for u | 3.201 × 10 | 5.615 × 10 | 1.869 × 10 | 3.319 × 10 |
| for f | 2.665 × 10 | 1.825 × 10 | 3.037 × 10 | 2.823 × 10 |
| 1.000262 | 1.000115 | 0.999436 | 2.000810 | 1.999836 | 1.995571 | |
| for u | 1.147 × 10 | 1.075 × 10 | 8.409 × 10 | 8.935 × 10 | 8.555 × 10 | 7.244 × 10 |
| for f | 1.562 × 10 | 1.552 × 10 | 1.488 × 10 | 1.462 × 10 | 1.474 × 10 | 1.524 × 10 |
| 1.000103 | 0.999282 | 2.000769 | 2.000163 | |
| 0.999468 | 2.001618 | 0.996979 | 1.998910 | |
| for u | 3.077 × 10 | 6.223 × 10 | 4.726 × 10 | 3.202 × 10 |
| for f | 6.331 × 10 | 4.784 × 10 | 5.294 × 10 | 3.857 × 10 |
| 10 | 20 | 30 | 40 | 50 | |
|---|---|---|---|---|---|
| 0.887239 | 1.000103 | 0.999763 | 1.000057 | 0.999051 | |
| 1.343989 | 0.999468 | 1.001156 | 0.999610 | 1.005044 | |
| for u | 1.979 × 10 | 3.077 × 10 | 6.761 × 10 | 2.510 × 10 | 2.752 × 10 |
| for f | 1.759 × 10 | 6.331 × 10 | 6.737 × 10 | 4.779 × 10 | 9.552 × 10 |
| 1.000103 | 0.983124 | 0.977075 | 0.974645 | 0.941651 | 0.926553 | |
| 0.999468 | 1.125553 | 1.243469 | 1.450893 | 1.511768 | 1.582164 | |
| for u | 3.077 × 10 | 1.467 × 10 | 1.684 × 10 | 4.594 × 10 | 4.274 × 10 | 5.241 × 10 |
| for f | 6.331 × 10 | 1.134 × 10 | 1.483 × 10 | 3.814 × 10 | 1.800 × 10 | 2.734 × 10 |
| (a, b, c, d) | ||||
|---|---|---|---|---|
| 1.000803 | 1.000828 | 2.001061 | 2.000685 | |
| 1.000120 | 1.000112 | 2.000256 | 2.000255 | |
| 0.999639 | 2.000954 | 0.998905 | 2.000404 | |
| 0.999927 | 1.999879 | 0.999935 | 1.999898 | |
| for u | 1.363 × 10 | 1.409 × 10 | 1.215 × 10 | 1.230 × 10 |
| for v | 4.805 × 10 | 4.601 × 10 | 4.754 × 10 | 4.395 × 10 |
| for | 1.383 × 10 | 1.368 × 10 | 1.354 × 10 | 1.335 × 10 |
| for | 1.396 × 10 | 1.374 × 10 | 1.366 × 10 | 1.339 × 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Gu, W. Parameter Estimation for Several Types of Linear Partial Differential Equations Based on Gaussian Processes. Fractal Fract. 2022, 6, 433. https://doi.org/10.3390/fractalfract6080433
Zhang W, Gu W. Parameter Estimation for Several Types of Linear Partial Differential Equations Based on Gaussian Processes. Fractal and Fractional. 2022; 6(8):433. https://doi.org/10.3390/fractalfract6080433
Chicago/Turabian StyleZhang, Wenbo, and Wei Gu. 2022. "Parameter Estimation for Several Types of Linear Partial Differential Equations Based on Gaussian Processes" Fractal and Fractional 6, no. 8: 433. https://doi.org/10.3390/fractalfract6080433
APA StyleZhang, W., & Gu, W. (2022). Parameter Estimation for Several Types of Linear Partial Differential Equations Based on Gaussian Processes. Fractal and Fractional, 6(8), 433. https://doi.org/10.3390/fractalfract6080433