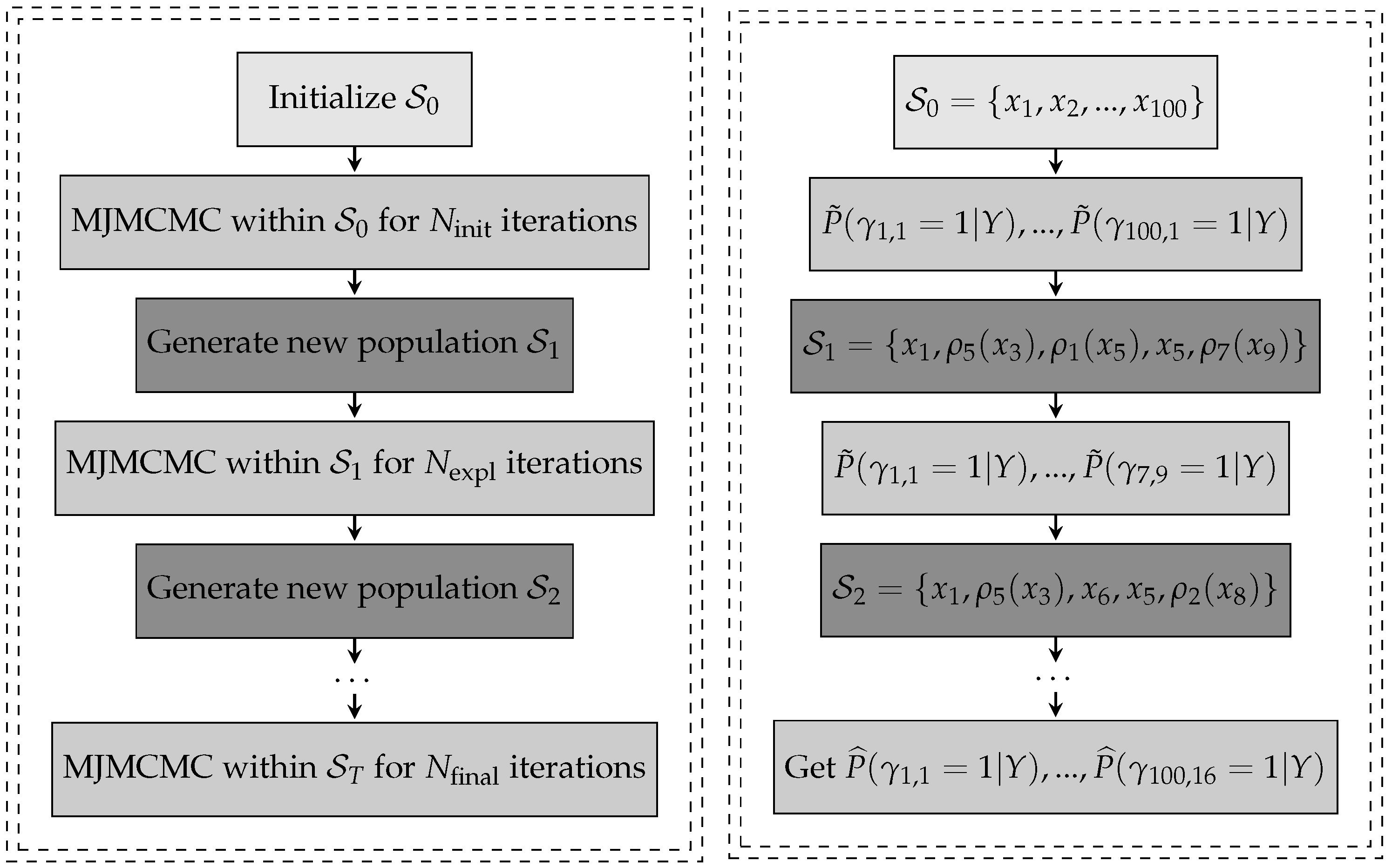
1. Introduction
Linear regression models are arguably among the most popular tools in statistics, especially their generalized versions (GLM). As the name suggests, they model a (function of a) response variable with a linear function of the predictors. While imposing a linear structure has many advantages, including the reduction in the variance, often it may not adequately reflect the functional form of the association of a predictor with the response and may lead to nonlinear structures of the residuals, which indicates a violation of the model assumptions and inappropriateness of the standard asymptotic inference procedures. For example, mis-specifying a truly nonlinear functional form of the predictor–response relationship as linear may result in biased estimates of the regression coefficients, a non-constant variance, and finally in a wrong interpretation of the modeling results. Heteroscedasticity can still be a problem in Bayesian linear regression models. The reason is that the posterior distributions of the regression coefficients depend on the likelihood, which in turn depends on the residuals. Residuals with non-constant variance may affect the shape of the likelihood and lead to incorrect posteriors for the regression coefficients.
Nonlinearities in the predictor–response relationship can be adequately captured by flexible modeling approaches such as splines, often used within the framework of (generalized) additive models. Although powerful and effective, these approaches have the strong drawback of making the model interpretation hard. Roughly speaking, these methods do not supply regression coefficients that can be easily interpreted. For this reason, it is often convenient to transform the predictors with specific global functions, for example, by taking the logarithm or the square root, and then assuming a linear relationship of the transformed predictor with the response variable. In a linear model, the corresponding regression coefficient will then have the familiar interpretation of “expected difference in the response variable for a unit difference of the—now transformed—predictor”. Following this way of thinking, Royston and Altman [
1] introduced the fractional polynomial approach. The basic idea is to select a transformation of a predictor
x from a set of eight possible functions (
), which is then used as an independent variable in the linear model. This set corresponds to a set of powers of polynomials
for the Box–Tidwell transformation, where
[
2].
Many refinements have been considered, including combinations of these functions’ fractional polynomials of order
d (see Royston and Altman [
1]), a multivariable approach [
3], a modification to account for interactions [
4,
5], and others. In particular, the fractional polynomials of order
d, hereafter
, allow multiple transformations of the predictor such that, for a simple linear model,
where
belong to
. By convention, the case that
for any
indicates a repeated power with transformations
and
. While in theory fractional polynomials of any order
d are possible, in practice only fractional polynomials of order 1 or 2 have typically been used ([
5], Ch 5.9).
Multivariable fractional polynomials are the natural extension of the procedure to multivariable regression problems. In this case, each predictor
receives a specific transformation among those allowed by the order of the fractional polynomial. While conceptually straightforward, this modification complicates the fitting procedure due to the high complexity of the model space. Sauerbrei and Royston [
3] proposed a sort of back-fitting algorithm to fit multivariable fractional polynomial (MFP) models. Herein, all variables are first ordered based on the significance of their linear effect (increasing
p-values for the hypothesis of no effect). Then, variable by variable, a function selection procedure (FSP) based on a closed testing procedure with likelihood ratio tests is used to decide whether the variable must be included or can be omitted and if it should be included with the best-fitting second-order fractional polynomial, with the best-fitting first-order fractional polynomial, or without transformation. The FSP is performed for all predictors, keeping the remaining fixed (as transformed in the previous step) for a pre-specified number of rounds or until there are no differences with the results of the previous cycle.
Limited to Gaussian linear regression, Sabanés Bové and Held [
6] implemented an approach to MFP under the Bayesian paradigm. Based on hyper-
g priors [
7], their procedure explores the model space by MCMC and provides a framework in which inferential results are not affected, for example, by the repeated implementation of likelihood-ratio tests. The restriction to Gaussian linear regression problems highly limits the applicability of this procedure. Moreover, while computationally attractive, the MCMC algorithm may struggle to efficiently explore the complicated model space induced by highly correlated predictors.
To address these drawbacks, here, we propose a novel approach based on the characterization of the fractional polynomial models as special cases of Bayesian generalized nonlinear models ([
8], BGNLM) and the implementation of a fitting algorithm based on the genetically modified mode jumping MCMC (GMJMCMC) algorithm of Hubin et al. [
9]. Bayesian generalized nonlinear models provide a very general framework that allows us a straightforward implementation of MFP beyond the linear Gaussian regression case, including, but not limited to, generalized linear models, generalized linear mixed models, Cox regression, and models with interactions. In addition, GMJMCMC enables searching through the model space to find the set of models with substanital probability mass. GMJMCMC is an extension of the mode jumping MCMC, which is an MCMC variant designed to better explore the posterior distributions, particularly useful when the posterior distribution is complex and has multiple modes. Mode jumping struggles when the dimensionality increases, which can be an issue in the case of fractional polynomials, as one needs to explore
models (in the case of the first-order fractional polynomials described above) as compared to
for the linear models. The GMJMCMC algorithm resolves these limitations by creating a genetic evolution of sets of features controlled by the genetic component, where simple mode jumping MCMCs can be run. In this work, therefore, we provide a powerful tool for fitting fractional polynomials in various applications.
Thus, the main contributions and innovations of this paper include building a novel Bayesian framework for fitting fractional polynomials using the genetically modified mode jumping Markov chain Monte Carlo (GMJMCMC) algorithm. Further, our priors ensure theoretically consistent model selection. The approach is validated through a comprehensive simulation study, demonstrating its reliable model selection consistency and good predictive performance of the method in three real-data examples, including regression, classification, and survival tasks. The inclusion of interactions in the fractional polynomial model enhances its interpretability and captures complex relationships between predictors and the response. The versatility of our framework allows for generalization to different types of responses and predictors from the exponential family, making it applicable to a wide range of real-world problems. Overall, our work provides a robust and interpretable Bayesian method for fitting fractional polynomials with strong predictive ability in various data analysis tasks.
The rest of the paper is organized as follows.
Section 2 describes the multivariable Bayesian fractional polynomial models in the framework of BGNLM, including the fitting algorithm based on GMJMCMC. In
Section 3, the performance of our procedure is evaluated via simulations, while three applications to real data are reported in
Section 4, where we show our approach applied to regression, classification, and time-to-event data problems. Finally, some remarks conclude the paper in
Section 5.
4. Real-Data Applications
In this section, we contrast our approach with many competitors in real-data examples with responses of different natures, namely, a continuous response, a binary response, and a time-to-event response. Note that the Bayesian approaches considered here are based on sampling from the posterior, and, therefore, contain a stochastic component. For these algorithms, we perform 100 runs and report the median, the minimum, and the maximum result. As a consequence, we can also evaluate their stability. All scripts are available on GitHub
https://github.com/aliaksah/EMJMCMC2016/tree/master/supplementaries/BFP (accessed on 3 August 2023).
4.1. Regression Task on the Abalone Shell Dataset
The Abalone dataset, publicly available at
https://archive.ics.uci.edu/ml/datasets/Abalone (accessed on 3 August 2023), has served as a reference dataset for prediction models for more than two decades. The goal is to predict the age of the abalone from physical measurements such as gender, length, diameter, height, whole weight, peeled weight, the weight of internal organs, and the shell. The response variable, age in years, is obtained by adding 1.5 to the number of rings. There are a total of 4177 observations in this dataset, of which 3177 were used for training and the remaining 1000 for testing. To compare all approaches, we use the following metrics: root mean square error (RMSE); mean absolute error (MAE); and Pearson’s correlation between observed and predicted response (CORR), also defined in Hubin et al. [
8].
In our case, 1000 was the test sample size. In addition to the aforementioned approaches, here we also include the original BGNLM (see Equation (
1)) from Hubin et al. [
8] and a version with only linear terms BGLM (see Equation (
2), with
).
For BGNLM_FP, GMJMCMC was run on 32 parallel threads for each of the 100 seeds. Each thread was run until 10,000 unique models were visited, with a mutation rate of 250 and the last mutation at iteration 10,000. The population size of the GMJMCMC algorithm was set to 15. For all runs, we used the following hyperparameters for the model priors: and . Further, was chosen to be for , for , and for .
The best performance (see
Table 1) is obtained with the general BGNLM approach. This is probably not surprising as the relationship between response and explanatory variables seems complex (see also
Table 2) and BGNLM is the most flexible approach, which contains all the other models as special cases. Notably, this result seems to show that the GMJMCMC algorithm is effective in exploring the huge model space. On the other hand, the performance of BGLM, ranking the worst in all the three metrics considered, shows the importance of including nonlinear effects in the model when analyzing this dataset.
Between these two extremes lie all the FP implementations. Our proposed approach BGNLM_FP seems slightly better than MFP and BFP_D but worse than the other two implementations of BFP (BFP_F and BFP_S), which, in this case, have exactly the same performances. Nonetheless, no matter which metrics we consider, the differences among all FP-based approaches are very small. Additionally, results for other less related statistical learning baselines are added to
Appendix A of the paper. They confirm the overall robustness and good performance of the Bayesian nonlinear method for this task.
Table 2 provides insight into the variable selection for our approach. This helps us to identify nonlinear effects and give us a hint of each variable’s importance for the prediction task. The frequency of inclusion shows that all nine explanatory variables were selected in all 100 simulation runs, meaning that each variable is relevant, at least with a linear effect. In addition, many nonlinear effects had a posterior probability larger than 0.1 (see the right column of
Table 2). In particular, the variables WholeWeight, ShuckedWeights, Height, Length, and VisceraWeights seem to have an effect between quadratic and cubic, while ShellWeight seems to have a logarithmic effect, as the logarithmic transformation is selected 58% of the time (third row of
Table 2), against around 20% for other transformations (quadratic 21%, cubic 16%, and
13%). The presence of these nonlinear polynomials in the model indicates that the relationship between the explanatory variables and the response (abalone age) is most probably nonlinear and highlights the importance of using methods such as BGNLM_FP to predict the outcome.
4.2. Classification Task on the Wisconsin Breast Cancer Dataset
This example uses breast cancer data with 357 benign and 212 malignant tissue observations, which were obtained from digitized fine needle aspiration images of a breast mass. The data can be found at the website
https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic) (accessed on 3 August 2023). Each cell nucleus is described by 10 characteristics, including radius, texture, perimeter, area, smoothness, compactness, concavity, points of concavity, symmetry, and fractal dimension. For each variable, the mean, standard error, and mean of the top three values per image were calculated, resulting in 30 explanatory variables per image. The study used a randomly selected quarter of the images as the training dataset, and the rest of the images were used as the test set.
As in the previous example, we compare the performance of the BGNLM_FP to that of other methods, namely, MFP, BGNLM, and its linear version BGLM. As BFP is not available for classification tasks, it could not be included in the comparison. BGNLM_FP uses Bernoulli observations and a logit link function, and the variance parameter is fixed at . Forecasts are made using , where represents the response variable in the test set. The model averaging approach is used for prediction, where marginal probabilities are calculated using the Laplace approximation.
For BGNLM_FP, GMJMCMC was run on 32 parallel threads for each of the 100 seeds. Each thread was run until
unique models were visited, with a mutation rate every 250 iterations and the last mutation at iteration
. The population size of the GMJMCMC algorithm was set to 45. For all runs, we used the following hyperparameters for the model priors:
and
.
was chosen to be as follows:
for
,
for
, and
for
. To evaluate the performance of the models we computed the following metrics: prediction accuracy (ACC), false positive rate (FPR), and false negative rate (FNR). The choice of these metrics is in line with that of Hubin et al. [
8], and allows direct comparison with the results therein. Detailed definitions of the metrics are also available in Hubin et al. [
8].
Table 3 presents the results for each metric. We can see that BGNLM_FP performs better than MFP both in terms of prediction accuracy and false negative rate, while it is slightly worse than MFP when it concerns the false positive rate. Both FP-based models, however, perform worse than both BGNLM and its linear version BGLM. The very good performance of the latter, almost as good as the former in terms of accuracy and FNR, and even slightly better in terms of FPR, seems to suggest that nonlinearities are not very important for this classification problem. This also explains why there is not much advantage in using an FP-based method. Both the frequentist approach and our proposed procedures tend to only select linear effects, as can be seen (for BGNLM_FP) from
Table 4, where all the effects selected in more than 10 (out of 100) runs are reported. The same happens for BGNLM (see [
8], Table 4): even the most general model only selects mostly linear effects. The reason why BGNLM and BGLM have better results in this example is most probably related to better use of the priors (see the Discussion for more on this point). Furthermore, additional baselines, reported in
Appendix B of the paper, confirm our main conclusions of the linear relationship between the covariates and the responses and of the high robustness of the proposed BFP approach.
4.3. Time-to-Event Analysis on the German Breast Cancer Study Group Dataset
As an example outside the GLM context, we consider a dataset with a time-to-event response. In particular, the German Breast Cancer Study Group dataset contains data from 686 patients with primary node-positive breast cancer enrolled in a study from July 1984 to December 1989. Out of the 686 patients, 299 experience the event of interest (death or cancer recurrence), while the remaining 387 are censored observations. The data are publicly available at
https://www.uniklinik-freiburg.de/fileadmin/mediapool/08_institute/biometrie-statistik/Dateien/Studium_und_Lehre/Lehrbuecher/Multivariable_Model-building/gbsg_br_ca.zip (accessed on 3 August 2023) and contain information about eight variables: five continuous (age, tumor size, number of positive nodes, progesterone status, and estrogen status), two binary (menopausal status and hormonal treatment) and one ordinal variable with three stages (tumor grade). The training set contains about two-thirds of the observations (457), with the remaining one-third forming the test set. The observations are randomly split, but the proportion of censored observations is forced to be the same in the two sets.
As in the previous examples, here we compare our approach BGNLM_FP with a few competitors, namely, the general BGNLM, its linear version BGLM, the classical MFP, and a linear version of the latter as well. All approaches are based on the partial likelihood of Equation (
9), so all approaches provide a Cox model, with the latter model being the simple Cox regression model. Furthermore, in this case, BFP is not used as it is only developed for Gaussian responses.
For BGNLM_FP, GMJMCMC was run on 32 parallel threads for each of the 100 seeds. Each thread was run for 20,000 iterations, with a mutation rate of 250 and the last mutation at iteration 15,000. The population size of the GMJMCMC algorithm was set to 15. For all runs, we had the same hyperparameters of the model priors as in all of the other examples: and . Further, was chosen to be for , for , and for .
To evaluate the performance of the models, here we compute the standard metrics: integrated Brier score (IBS) and concordance index (C-index). Both IBS and C-index are defined and computed following the notation from
pec [
26].
Table 5 reports the results of this experiment. This dataset was used by Royston and Sauerbrei [
5] to illustrate the fractional polynomials, so probably not surprisingly the two FP-based approaches have the best performance. Both MFP and our proposed BGNLM_FP are better than the competitors, especially those based on linear effects. It is known, indeed, that the effect of the variable nodes is not linear ([
5], Section 3.6.2), and our approach finds this nonlinearity 100% of the time (see
Table 6). A bit more surprisingly, BGNLM does not perform so well in this example, but this is most probably related to the fact that the extreme simplicity of a good model (at least the one found by BGNLM_FP only contains two explanatory variables, one of them even with a simple linear effect) does not justify the use of complex machinery.
4.4. Including Interaction Terms into the Models
As discussed in
Section 2.6.3, our approach makes it straightforward to add interaction terms in the Bayesian fractional polynomial models. Mathematically, we need to go back to Formula (
1) and also consider bivariate transformation, while algorithmically we need to enable multiplication operators in the GMJMCMC algorithm. In this section, we report the results obtained by BGNLM_FP with interactions. We keep all other tuning parameters of GMJMCMC unchanged, except for allowing multiplications. Furthermore, all hyperparameters of the models are unchanged, except for setting
and
.
4.4.1. Abalone Data
As we can see in
Table 7, allowing interactions into the model enhances the performance of the BGNLM_FP model on the abalone shell age dataset. Adding the interactions is not sufficient to reach the performances of the general BGNLM, but it considerably reduces the gap.
4.4.2. Breast Cancer Classification Data
As expected from the results of
Table 3, in the case of the breast cancer classification dataset, in which BGLM already performs better than BGNLM_FP, incorporating interaction terms into the FP model does not produce any substantial advantage (see
Table 8). This does not come as a surprise, as nonlinearities do not seem to play a credible role in the prediction model.
4.4.3. German Breast Cancer Study Group Data
Finally,
Table 9 shows the results of the model with interactions for the time-to-event data analysis. There is no advantage in allowing for interactions here as well. This is a typical case of the advantage related to the bias-variance trade-off when using simpler models for prediction tasks. We can notice from its IBS values that the model with interactions can have the best performance (0.1597), but the performance varies so much (as bad as 0.1660) that the median is worse than for the simpler model (that without interactions). Note, moreover, that
Table 6 seems to suggest that there are only two relevant variables, so it is not likely to detect relevant interactions.
5. Discussion
In this paper, we studied how BGNLM fitted by GMJMCMC introduced by Hubin et al. [
8] can deal with fractional polynomials. It can be seen as an opportunity of fitting a BGNLM that can handle nonlinearities without any loss in model interpretability, and, more importantly, as a convenient implementation of a fractional polynomial model that assures a coherent inferential framework, without losing (if not gaining) anything in terms of prediction ability. The broad generality of the BGNLM framework, moreover, allows adding complexity with a minimum effort, as we show for the inclusion of interaction terms.
Note that the current implementation is based on a direct adaptation of the priors defined in Hubin et al. [
8]. Further investigations on the choice of the priors will certainly be beneficial and further improve the performance of BGNLM_FP, as we already noticed in the simulation study in
Section 3. For example, a better balance between the penalty for the different fractional polynomial forms can be implemented. Our real-data experiments never showed evidence in favor of a fractional polynomial of order 2. This may be related to the implausibility of an FP(2) transformation, especially in a prediction context where simplicity is often awarded, but it may also indicate that we penalized these terms too much.
One drawback with the Bayesian versions of the fractional polynomial models is the computational costs of fitting them. This is not specific to our approach, it also concerns the current BFP implementation of Sabanés Bové and Held [
6] and can become an issue in the case of very large datasets. Currently, we distribute the computational workload across multiple processors to achieve convergence to descent regions in the model space. In the future, subsampling the data could allow for a reduction in computational cost when computing the marginal likelihoods. This will allow the use of the Bayesian fractional polynomial approach in big data problems as well. Furthermore, in the case of large datasets, Laplace approximations of the marginal likelihoods become very accurate, making this approach even more appealing. To make the computations efficient, stochastic gradient descent (SGD) can be used to compute the Laplace approximations, which also guarantees convergence [
27] of MJMCMC in the class of Bayesian GLMs. Therefore, incorporating data subsampling and using SGD to compute the Laplace approximations may be a promising future direction in inference on Bayesian fractional polynomials under the setting of a large
n.
Another challenge is selecting appropriate values for the tuning parameters of GMJMCMC. The tuning parameters in GMJMCMC control the proposal distributions, population size, frequencies of genetic operators, and other characteristics of the Markov chain. Their values can significantly affect the convergence and mixing properties of the algorithm. To deal with this challenge, one may perform extensive tuning of the algorithm, which involves testing a range of values for the tuning parameters and evaluating the performance of the algorithm using problem-specific diagnostic tools such as power (TPR)-FDR in simulations or RMSE for regression prediction tasks. A detailed discussion of setting the tuning parameters in GMJMCMC is given in the "Rejoinder to the Discussion" in Hubin et al. [
9]. In the future, it may also be interesting to develop adaptive tuning methods that automatically adjust the tuning parameters based on the performance of the algorithm as it is running.
GMJMCMC is a Markov chain Monte Carlo algorithm that is designed to explore the space of models with non-zero posterior probabilities. However, as with any MCMC algorithm, there is a risk that the chain may not converge to the desired target distribution in a finite time. This means in our settings that the set of models with non-zero posterior probabilities may not be fully explored in a single run of the algorithm. One consequence of this is that the estimates obtained from GMJMCMC may vary from run to run, since different runs may explore different parts of the model space. Even if the algorithm is run for a long time, there is still a positive probability that it may miss some of the models with non-zero posterior probabilities. Variance in the estimated posterior in turn induces variance in the predictions if the latter is of interest. To mitigate this issue, it is recommended to run the algorithm multiple times, using as many of the available resources as one can and check for convergence of the estimates. Additionally, it may be helpful to use informative model priors or other techniques to help guide the algorithm toward the most relevant parts of the model space.
Even though there are still a few challenges and limitations in the current state of Bayesian fractional polynomials, these models have potential applications in a variety of areas where uncertainty handling, explainability, and nonlinear relationships are essential. These include but are not limited to fields such as pharmacology, epidemiology, finance, and engineering. In pharmacology, for example, fractional polynomials can be used to model the dose–response relationship between a drug and a patient’s response, taking into account the nonlinear and complex relationships between the variables. In finance, fractional polynomials can be used to model the relationship between financial variables such as stock prices, interest rates, and exchange rates, and to quantify the uncertainty associated with these relationships. Similarly, in engineering, fractional polynomials can be used to model the relationship between variables such as stress, strain, and material properties, providing a way to make predictions while taking into account nonlinear relationships and the associated uncertainty. In all of these cases, Bayesian fractional polynomials offer a flexible and robust way to handle uncertainty and model nonlinear relationships, making them a useful tool for a wide range of applications in the future. Given the important role that uncertainty handling, explainability, and nonlinear relationships play in various applications, we hope that the novel Bayesian fractional polynomial inference algorithm presented in this paper, as well as the suggested extensions to various practical settings such as survival analysis and GLM, will allow these often overlooked models to be more widely used in the future.





{kind=link}
{kind=link}
{kind=link}
{kind=link}