Abstract
This paper addresses the decentralized composite optimization problem, where a network of agents cooperatively minimize the sum of their local objective functions with non-differentiable terms. We propose a novel communication-efficient decentralized ADMM framework, termed as CE-DADMM, by combining the ADMM framework with the three-point compressed (3PC) communication mechanism. This framework not only covers existing mainstream communication-efficient algorithms but also introduces a series of new algorithms. One of the key features of the CE-DADMM framework is its flexibility, allowing it to adapt to different communication and computation needs, balancing communication efficiency and computational overhead. Notably, when employing quasi-Newton updates, CE-DADMM becomes the first communication-efficient second-order algorithm based on compression that can efficiently handle composite optimization problems. Theoretical analysis shows that, even in the presence of compression errors, the proposed algorithm maintains exact linear convergence when the local objective functions are strongly convex. Finally, numerical experiments demonstrate the algorithm’s impressive communication efficiency.
1. Introduction
The recent increase in the number of mobile devices with enhanced computing and communication capabilities has led to significant development of multiagent systems [1,2]. Within these systems, many applications, including smart grid management [3,4], wireless communications [5], multi-robot coordination [6,7], large-scale machine learning [8], etc., can be cast to decentralized optimization problems, in which a network of nodes cooperatively solve a finite-sum optimization problem using local information.
A vast of decentralized optimization algorithms have been proposed, since the pioneer work DGD [9], in which each node performs gradient descent and simultaneously communicates decision vector with its neighbors for consensus. As DGD requires diminishing stepsize, which might slower the convergence rate, gradient tracking (GT) based algorithms using constant stepsizes are then developed [10,11] and have been extensively investigated under various scenarios [12,13,14,15], to name a few. However, GT-based methods require to transmit both the decision vector and an additional gradient estimation vector, which increase the communication cost. In parallel, another type of decentralized algorithms based on alternating direction method of multipliers (ADMM) are proposed and analyzed [16,17]. Compared with GT-based algorithms, ADMM-type algorithms can achieve the same convergence rate but require the transmission of only decision vector, which can be more communication-efficient. Following this line, some decentralized optimization algorithms are proposed for accelerating the convergence rate by introducing second-order information [18,19,20,21]. More recently, Ref. [22] proposed a family of decentralized curvature aided primal dual algorithms, which can include gradient, Newton, and BFGS type of updates.
In the decentralized algorithms, it is of great significance to improve communication-efficiency. The methods can be classified into two types. One method is to adopt compressed communication scheme, using quantization [23] or sparsification [24,25] techniques to reduce communication overhead per transmission. Recently, the compressed communication scheme has been combined with DGD [26,27], GT-based algorithms [28,29], and ADMM-type algorithms [30,31]. Another method is to employ intermittent communication scheme which aims to reduce the communication frequency. Such type of methods includes event-triggered communication [32,33,34], lazy aggregation scheme (LAG) [35], etc. Besides, there are also some works combining the both methods [36,37,38]. In particular, ref. [39] combined event-triggered and compressed communication scheme with an ADMM-type algorithm and proposed a communication-efficient decentralized second-order optimization algorithm, which improve both computation and communication efficiency. It is worthy noting that the information distortion arisen by compressed communication scheme may have a negative effect on the convergence performance of the decentralized optimization algorithms. To overcome this shortage, Ref. [40] developed an error-feedback communication scheme (EF21) to avoid the negative effect of information distortion. Recently, a more general efficient communication scheme termed as three point compressor (3PC) is proposed in [41], which provides a unified method including EF21 and LAG as special cases. However, 3PC scheme is only investigated in distributed gradient descent algorithms under the parameter-server framework.
Despite of the progress, the development of communication-efficient decentralized optimization algorithms over the general networks is still lack an in-deep analysis, especially for the objective with non-differentiable part, i.e., decentralized composite optimization problems. Note that such problems have widely applications in the field of machine learning due to the existence of the non-differentiable regularization terms. Currently, some decentralized composite optimization algorithms have been proposed [22,42,43,44], but without employing efficient-communication schemes. Moreover, to the best of our knowledge, no work has been reported on communication-efficient decentralized composite optimization using second-order information. To fill this gap, in this paper, we incorporate the general efficient communication scheme 3PC [41] into the ADMM-based decentralized optimization framework [22], which result in a family of communication-efficient decentralized composite optimization algorithms with theoretical guarantees. It is worthy noting that such incorporation is not trivial as we need to overcome the negative effect arisen by the propagation of communication error over networks. The main contribution of this work can be summarized in the following two aspects:
- First, we propose a flexible framework termed as CE-DADMM for communication-efficient decentralized composite optimization problems. The framework not only encompasses some existing algorithms, such as COLA [32] and CC-DQM [39], but also introduces several new algorithms. Specifically, by incorporating quasi-Newton updates into CE-DADMM, we derive CE-DADMM-BFGS, the first communication-efficient decentralized second-order algorithm for composite optimization. Compared with CC-DQM, it avoids computing the Hessian matrix and its inversion, significantly reducing the computational cost. Compared with DRUID [22], CE-DADMM can reduce the communication cost due to the efficient communication scheme.
- Second, we theoretically prove that CE-DADMM can achieve exact linear convergence under the assumption of strong convexity by carefully analyzing the mixing error arisen by the efficient communication scheme and the disagreement of decision vectors. The dependency of the convergence rate on the parameters of the compression mechanism is also established. Additionally, sufficient numerical experiments are presented to substantiate the superior performance of our algorithms in terms of the communication efficiency.
Notation. If not specified, and represent the Euclidean norm and the spectral norm, respectively. For a positive definite matrix , let . Use to denote the set . The proximal mapping for a function is defined by . Let represent the d-dimensional identity matrix, and represent the Kronecker product of matrices and .
2. Problem Setting
In this paper, we study the decentralized composite optimization problem on an undirected connected network with n agents (or, nodes), which takes the form
where refers to the decision vector and is a convex and smooth function accessible only by node i and is a convex (possibly non-smooth) regularizer.
Next, we equivalently reformulate problem (1) into a compact form in terms of the whole network following the same idea in [22]. Denote the communication graph as , where is the set of agents and is the set of edges containing the pair if and only if agent i can communicate with agent j. There is no self-loops in , i.e., for any . Note that the edges in are enumerated in arbitrary order, with denoting the k-th edge, where and is the number of edges. The neighbor set of agent i is . Let and be the local decision vectors corresponding the ith-node kth-edge, respectively. We assume that is connected. Then, problem (1) is equivalent to the following constrained form:
where is an auxiliary variable for decoupling the smooth and non-smooth functions. Denote the optimal solution of problem (1) and (2) as and , respectively. It is straightforward to verify that for all and .
In what follows, define and . In addition, define two matrices and as follows: the k-th row of both and represents the k-th edge . Specifically, the entries and are both equal to 1 if and only if the edge ; otherwise, they are 0. We also define , where is a vector with a 1 at its l-th position and 0 elsewhere. Clearly, the matrix extracts the component of that corresponds to agent l, meaning that . Let . Then, problem (2) can be written as
Note that problem (3) is written from the network level, which will be the basis for designing our algorithm.
3. Algorithm Formulation
In this section, we first introduce the basic iterations of our algorithm based on ADMM method. Then, by combining compressed communication techniques with the ADMM-based algorithm, we will devise our algorithm and discuss its relationship with existing algorithms.
3.1. Background: ADMM-Based Algorithm
ADMM is a powerful tool to solve an optimization problem with several blocks of variables. To apply ADMM for solving problem (3), define its augmented Lagrangian as:
where and are positive constants, and are Lagrange multipliers. Then, the kth-iteration in ADMM is written as
Define , , , , . In addition, define , and similarly for , and . Similar as [22], if we initialize the multiplier with , , there is . Let , and approximate the augmented Lagrangian in (5a) by employing a second-order expansion at as
where is short for , and is an invertible matrix representing the approximated Hessian of the augmented Lagrangian, then the iteration (5) can be simplified as
Compared with (5), the iteration (6) contains fewer vectors by eliminating the vector and replacing by to halve the dimension of . Note that the iteration (6) is written in terms of the whole network. To implement (6) in a decentralized manner, we require the matrix be block-diagonal, so that each block can be computed independently by each agent. Here, we assume that . The choice of will be discussed later. Then, agent i will perform the following iteration:
where if , otherwise .
3.2. Communication-Efficient Decentralized ADMM
Recalling the iteration (7a) and (7b), it can be seen that agent i will communicate the information on to its neighbors at each iteration. However, such communication might not be realized for scenarios with limited communication resources. To reduce the communication overhead, we introduce the idea of compressed communication scheme into iteration (7), which results in our algorithm, termed as communication-efficient decentralized ADMM for composite optimization (CE-DADMM).
To compress the communication, we first give a definition of compressor.
Definition 1
(Compressor). A randomized map is called a compressor if there exists a constant such that holds for any .
In Definition 1, the compressor is characterized using the relationship between the compression error and the original state. Clearly, refers to the compression ratio. We can also call a -compressor. In our algorithm, we do not apply directly to the transmitted , as it will lead to a non-dismissing compression error. Instead, we will adopt a general compressor termed as Three Point Compressor (3PC) [41], whose definition is given below.
Definition 2
(Three Point Compressor, see [41]). A randomized map is called a three point compressor (3PC) if there exist constants and such that
where and are parameters of the compressor.
3PC can be realized using -compressor . Two examples of are given below [41]:
It can be checked that and for EF21, and and for CLAG.
Next, we formulate our algorithm based on 3PC, whose pseudo code is presented in Algorithm 1. We introduce a new state relating to , which refers to the estimation on of agent i’s neighbors. The computation of relies on , and since consists of compressed information, this significantly reduces the computational cost associated with the inverse of . Then, at iteration t, agent i transmits the compressed vector rather than to its neighbors, which lead to the new iterations as below:
| Algorithm 1 CE-DADMM | |
| 1: Initialization: , , , , , . | |
| 2: for t = 0,1,… do | |
| 3: for agent i do | |
| 4: Compute using (13), (14), or (15) according to its choice; | |
| 5: Compute using (11a); | |
| 6: | // Compressing information |
| 7: Broadcast to neighbors | |
| 8: | |
| 9: if then | // Dealing with the non-smooth function |
| 10: | |
| 11: | |
| 12: end if | |
| 13: end for | |
| 14: end for | |
3.3. Discussion
Our algorithm CE-DADMM presents a flexible framework that accommodates gradient updates, Newton updates, and quasi-Newton updates, depending on the choice of matrix . Here, has the following general structure:
where is used to provide additional robustness and is a matrix to be determined. A detailed discussion is presented below.
Case 1: Gradient Updates. By choosing , (12) equals to
Clearly, is diagonal. The computation of requires computational cost. Compared with COLA [45], CE-DADMM considers the presence of the non-smooth term and allows for more options in the choice of the compression mechanism . When is excluded, only the lazy aggregation compression mechanism is applied, and Gradient Updates are used, CE-DADMM aligns with the form of COLA.
Case 2: Newton Updates. By choosing , (12) equals to
According to the definition of , is a block diagonal matrix with the ith block being . The computation of incurs computational cost. When CE-DADMM uses Newton updates, excludes , and adopts the same communication compression approach as CC-DQM [39], it recovers the form consistent with CC-DQM.
Case 3: Quasi-Newton Updates. Inspire by the distributed BFGS scheme in [22], we can derive a novel decentralized algorithm termed as CE-DADMM-BFGS, which combines the BFGS method with communication-efficient mechanisms. According to secant condition, each agent i constructs a model of the inverse Hessian directly using the pairs defined as
The Hessian inverse approximation is then iteratively updated as:
Notably, the explicit inverse of is unnecessary, as this expression serves merely as a formal representation. Consequently, the computational cost for each agent is reduced from to .
4. Convergence Analysis
In this section, we propose a unified framework to analyze the proposed algorithms that incorporate gradient, Newton, and BFGS updates, along with a communication-efficient mechanism. First, we make the following assumptions throughout of the paper.
Assumption 1.
Each is twice continuously differentiable, -strongly convex, and –smooth, i.e., , where . is proper, closed, and convex, i.e., holds for any subgradients and .
Assumption 2.
Each is Lipschitz continuous with constant , i.e., holds for any
Assumption 3.
Each is uniformly upper bounded, i.e., for any , there exists a constant such that
It is worthy noting that Assumption 3 is only required for the quasi-Newton update case. Next, we introduce the optimal condition of problem (3), which is independent of the algorithm and has been proved in [22]. The result is given below.
Lemma 1
(optimal condition, see Lemma 2 in [22]). Suppose is a primal-dual optimal pair of problem (3), if and only if the following holds:
Moreover, there exists a unique dual optimal pair that lies in the column space of .
Now, we are ready to analyze our algorithm CE-DADMM. First, we write (11) into a compact form:
According to the discussion in Section 3.1, we have and hold in (17). Then, it follows from Lemma 1 that the convergence of CE-DADMM can be obtained by showing converges to .
Due to the existence of the efficient communication scheme, we need to analyze the impact of communication error on the convergence of CE-DADMM. Define , where for all agent i. Clearly, describes the error caused by efficient communication scheme. Regarding , the following result holds.
Lemma 2.
The error in CE-DADMM satisfies , where A and B are the parameters of 3PC.
Proof.
According to the definition of 3PC, we have
which completes the proof. □
Clearly, if 3PC is set as EF21 (9), it follows from Lemma 2 that
If 3PC is set as CLAG (10), we have
Then, to characterize the suboptimality of the iterates when (5a) is replaced by (17a), we introduce the following error term:
The bound of the error term (18) is give below, which is important for our main result.
Lemma 3.
It holds that , where and correspond to the update case as below:
Proof.
See Appendix A. □
Lemma 3 extends the results in [17,18] by providing an upper bound on the error introduced when replacing the exact sub-optimization step (5a) with a one-step update using the compressed variable (17a). Under Newton updates, as the error approaches zero, the term becomes smaller than in (20). In the case of Quasi-Newton updates, the error remains bounded by a constant, ensuring it do not grow indefinitely.
Let and denote the maximum and minimum eigenvalues of , respectively. Let denote the maximum eigenvalue of . Denote by the smallest positive eigenvalue of , where is given in Lemma 1. Define , , and . Consider the following Lyapunov function:
Clearly, converges to zero implies that converges to the optimal solution. We will use to establish the convergence result of our algorithm, which is given below.
Theorem 1.
Suppose Assumptions 1–3 hold. Let , , , and . If ζ satisfies
then the iterates generated by CE-DADMM satisfy , where
Proof.
See Appendix B. □
Clearly, Theorem 1 implies that CE-DADMM can achieve exact linear convergence at a rate of with . The larger is, the faster CE-DADMM converges. To ensure positive in (23), it can be obtain that the step size should not be too large. Besides, excessive compression of should be avoided. This is because, when the compression ratio A is very small, B approaches infinity. According to (23), as , the first term in (23) becomes negative. It is worth noting that when , the compression ratio A can be arbitrarily small, making the approach highly applicable in scenarios with extremely limited bandwidth. Also, at this situation, we can get the fastest convergence rate and the smallest communication cost. However, setting implies solving the subproblem (5a) exactly, which may result in high computational cost. This shows a trade-off between communication cost and computation cost in decentralized optimization.
5. Numerical Experiments
In this section, CE-DADMM is compared with existing state-of-the-art algorithms, including DRUID [22], PG-EXTRA [42], P2D2 [43], and CC-DQM [39], in distributed logistic/ridge/lasso regression problems. Noting that CC-DQM do not support non-smooth terms.
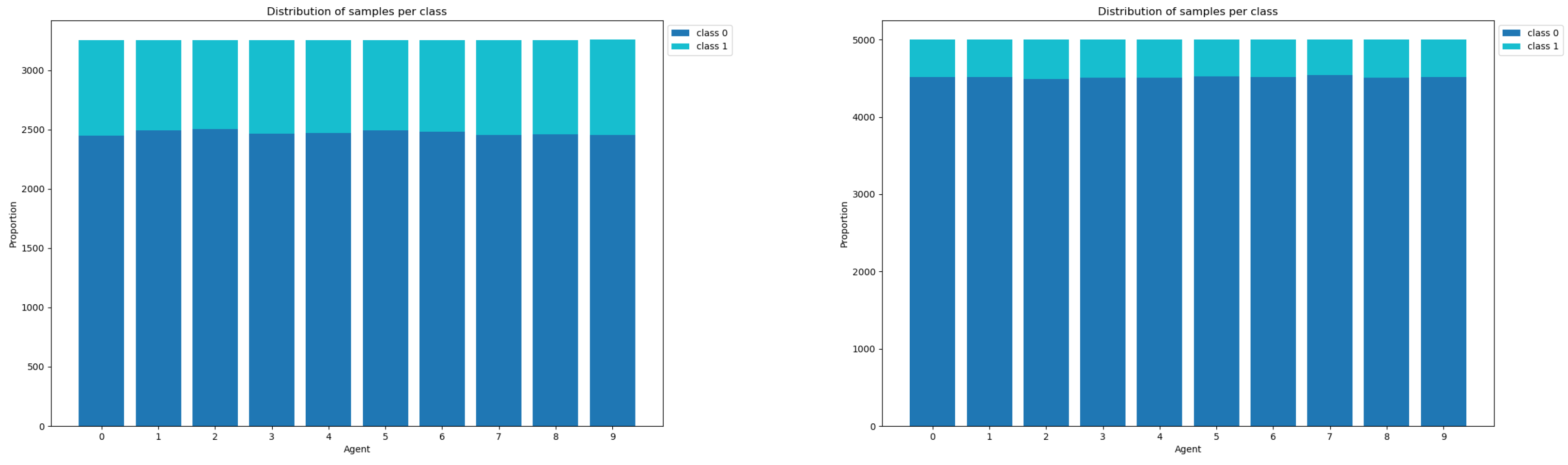
Datasets. We use real-world datasets from the LIBSVM library (Available Online: https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html, accessed on 3 December 2024): a9a (32,561 samples, 123 dimensions) and ijcnn1 (49,990 samples, 22 dimensions). The samples are evenly distributed across n agents. The distribution of samples across agents for the a9a dataset (left) and ijcnn1 (right) is shown in Figure 1. Our experiments are implemented in Python 3.10.13.
Figure 1.
Distribution of samples across agents for the a9a dataset (left) and ijcnn1 (right).
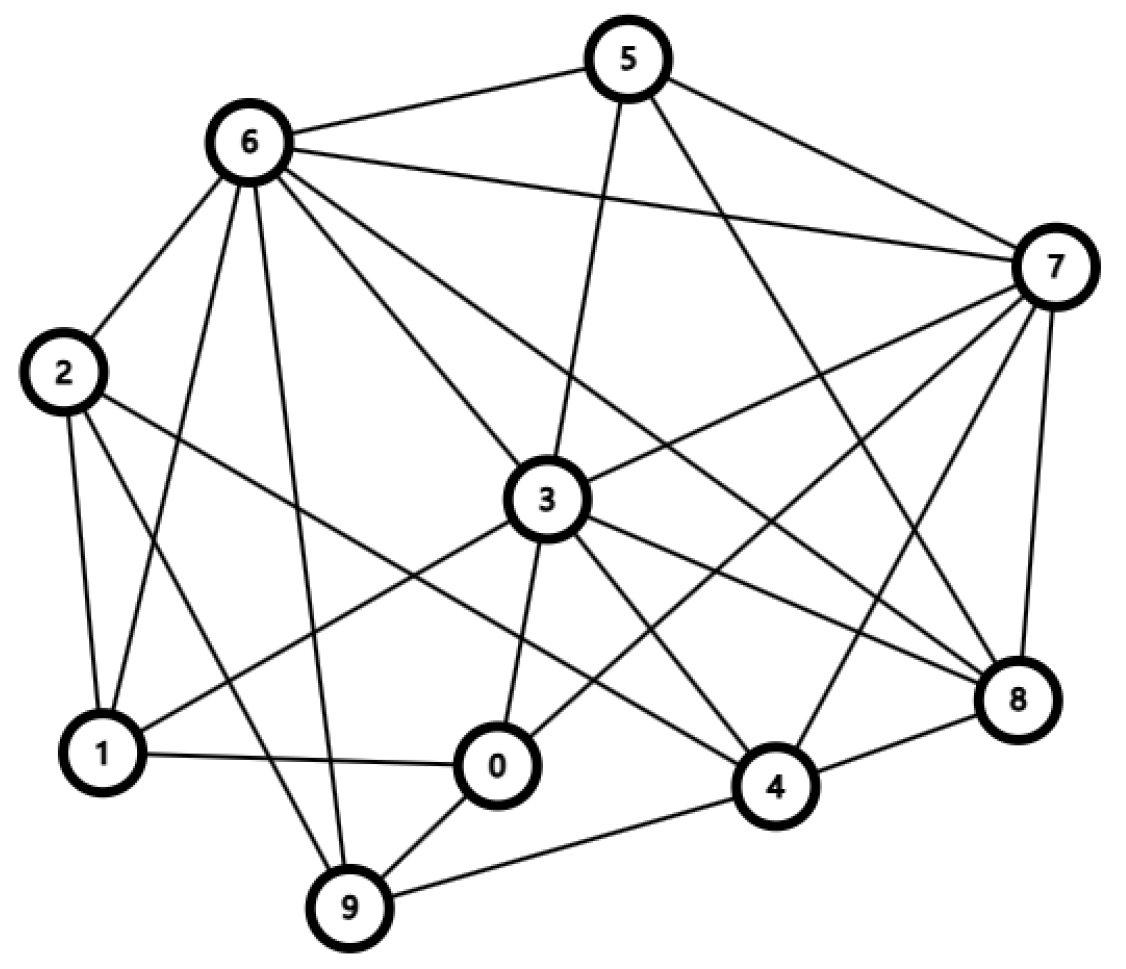
Experimental setting. The communication graph is randomly generated, with connections based on a Bernoulli distribution () among agents, as shown in Figure 2. We evaluate performance based on the total communication bits and the number of iterations. CE-DADMM employs compression mechanisms EF21 and CLAG, using a Top-K compressor to reduce dimensions to 30 dimensions for the a9a dataset and 6 dimensions for the ijcnn1 dataset. In the experiment, we examine the algorithms from two perspectives: the number of iterations and total communication bits. The number of iterations refers to the number of times the algorithm runs, while total communication bits is calculated based on the cumulative number of bits of variable transmitted between agents. Additionally, we define to measure the algorithm’s convergence.
Figure 2.
Random communication graph of network with 10 agents.
5.1. Distributed Logistic Regression
The distributed logistics regression solves problem (1) with , defined as:
where represents the feature vector, denotes the label, and is the number of sample data for agent i. The parameters and are regularization terms.
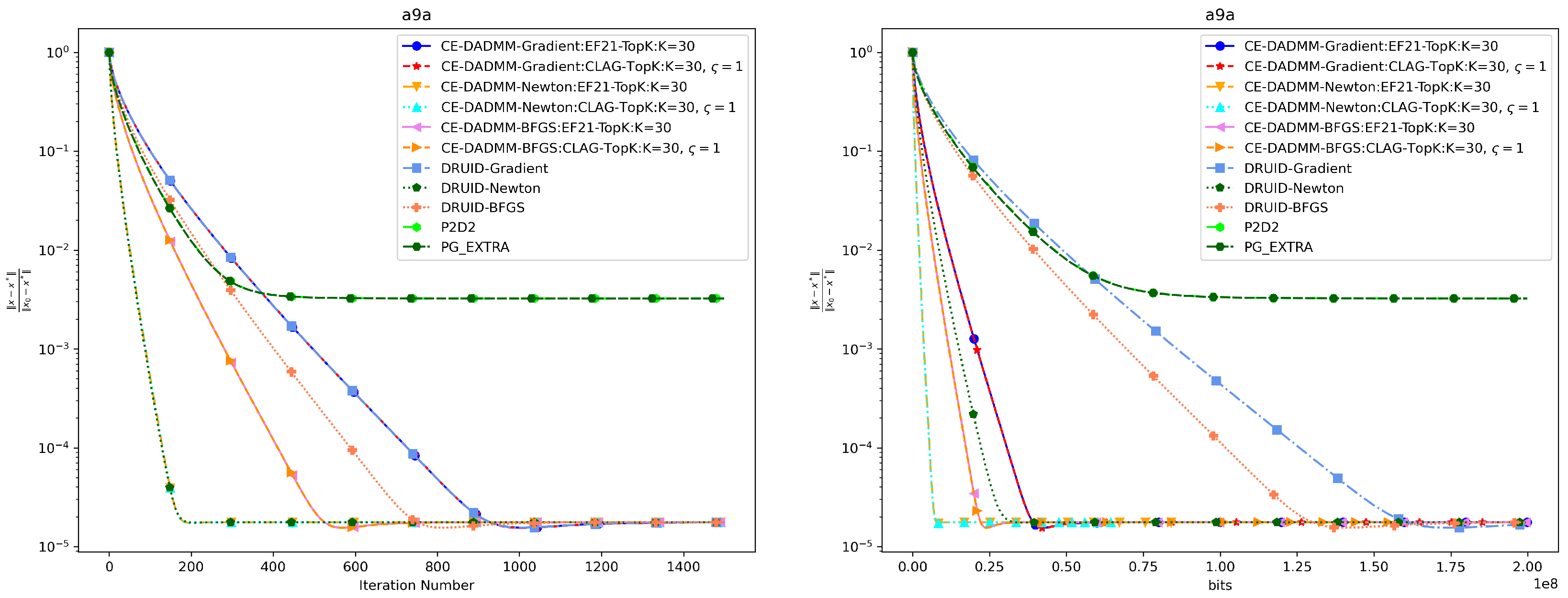
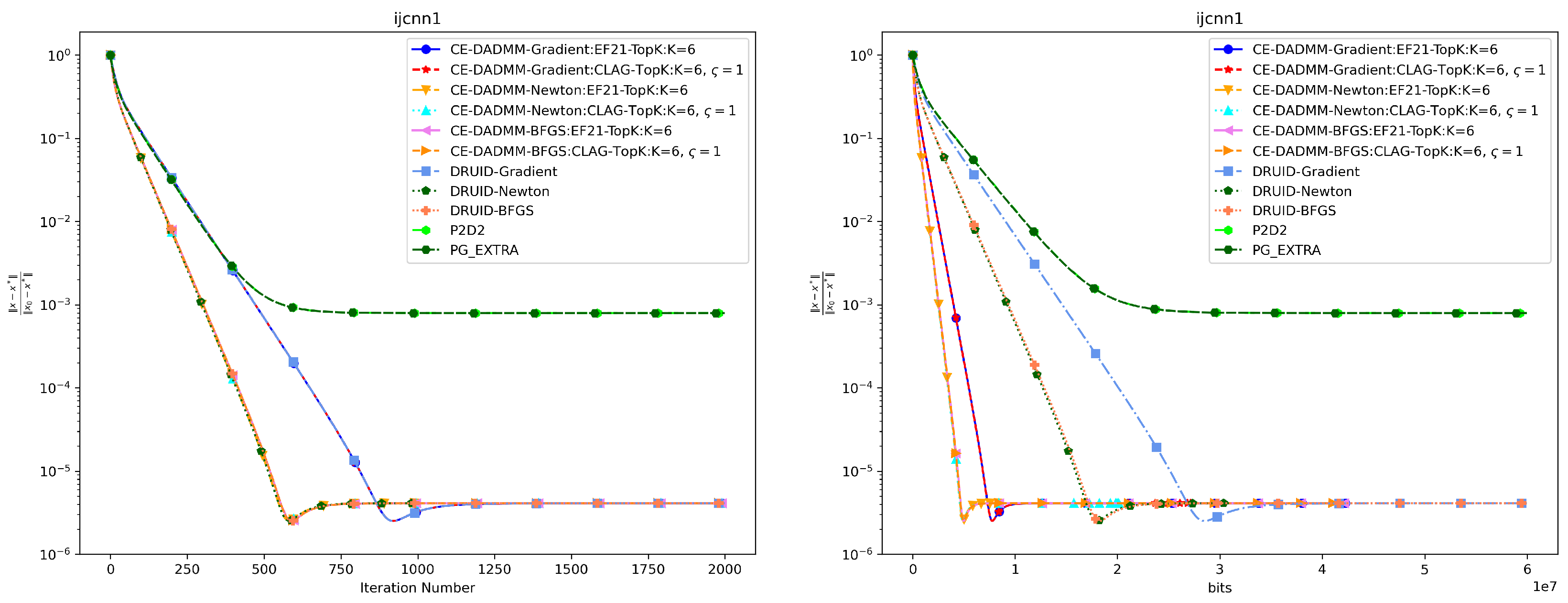
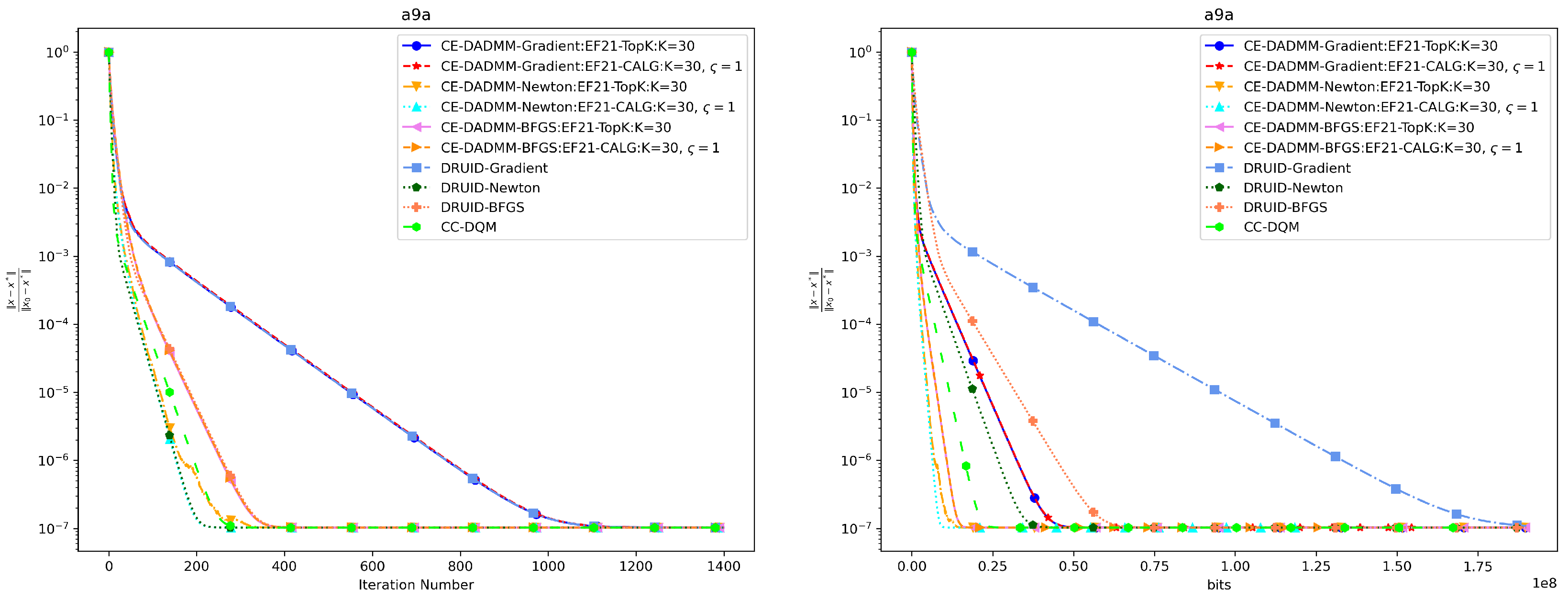
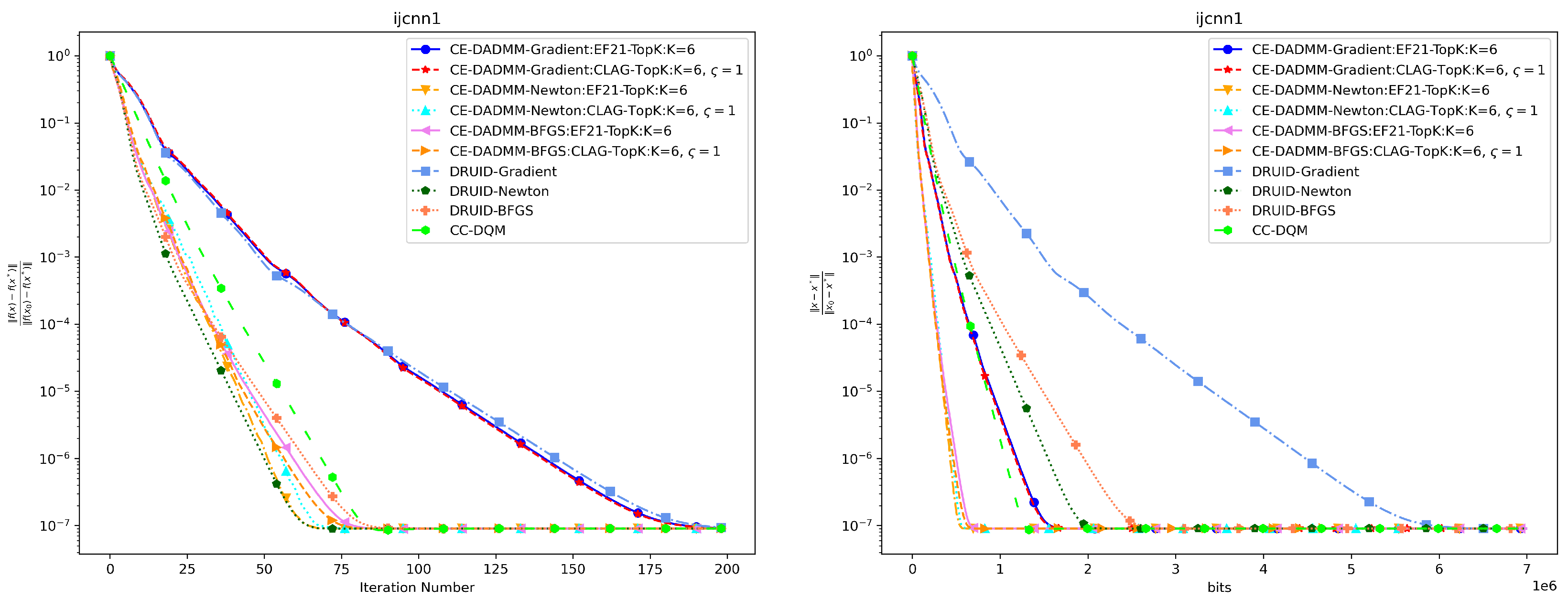
In Figure 3 and Figure 4, when measured by the number of iterations, CE-DADMM with EF21 and CLAG compression mechanisms performs on par with DRUID without compression, and surpasses P2D2 and PG-EXTRA in both convergence speed and accuracy. Additionally, we observe that CE-DADMM, when using (quasi) Newton methods, significantly reduces the number of iterations required to reach a given accuracy compared to first-order methods. When measured by total communication bits, the introduction of EF21 and CLAG in CE-DADMM allows for a substantial reduction in communication overhead compared to DRUID, even under the same update scheme. Notably, when using quasi-Newton updates, CE-DADMM requires fewer communication bits to achieve the same accuracy than DRUID-Newton updates, and also outperforms P2D2 and PG-EXTRA in this regard. When achieving the same convergence accuracy as shown in Table 1, the detailed numerical results are presented in Table 2 and Table 3. Note that for P2D2 and PG-EXTRA, since they fail to reach the predefined convergence accuracy, we use the number of iterations required for them to converge to their optimal values as a benchmark.
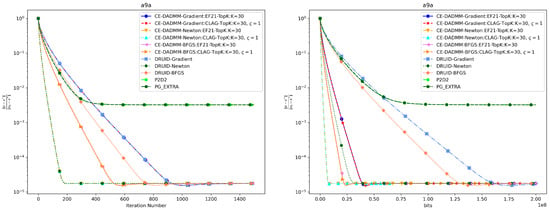
Figure 3.
Performance comparison of distributed logistic regression the on a9a dataset: Plots of iteration number (left) and total communication bits (right) versus distance error.
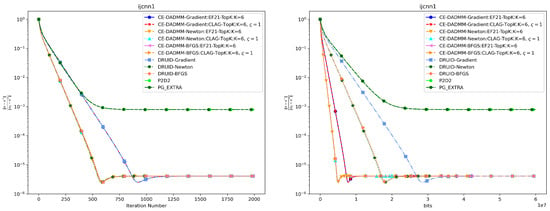
Figure 4.
Performance comparison of distributed logistic regression the on ijcnn1 dataset: Plots of iteration number (left) and total communication bits (right) versus distance error.

Table 1.
Convergence accuracy () for different experiments.
Table 2.
Comparison of iterations.
Table 3.
Comparison of communication bits.
5.2. Distributed Ridge Regression
In Figure 5 and Figure 6, we observe that when measured by the number of iterations, CE-DADMM with EF21 and CLAG compression mechanisms performs similarly to DRUID without compression. However, CE-DADMM using (quasi) Newton updates converges faster compared to CC-DQM, which also employs an communication-efficient mechanism. On the other hand, when CE-DADMM employs first-order method, its convergence is slower than second-order method, CC-DQM, due to the latter benefiting from additional Hessian information. When measured by total communication bits, CE-DADMM with (quasi) Newton updates requires fewer bits to achieve the same accuracy compared to CC-DQM. Additionally, CE-DADMM benefits from communication-efficient mechanisms, resulting in a substantial reduction in communication bits needed to achieve the same convergence accuracy compared to DRUID. Similarly, the corresponding numerical results are also presented in Table 2 and Table 3.
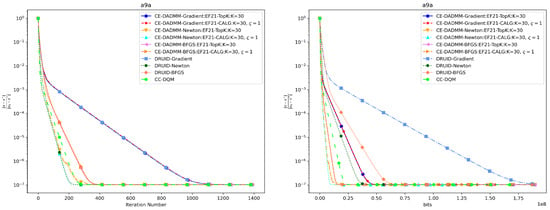
Figure 5.
Performance comparison of distributed ridge regression on the a9a dataset: Plots of iteration number (left) and total communication bits (right) versus distance error.
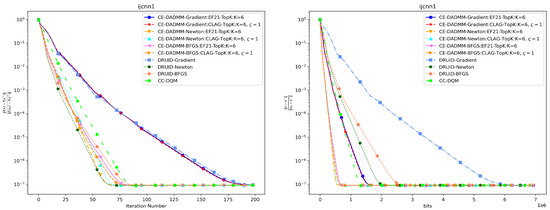
Figure 6.
Performance comparison of distributed ridge regression on the ijcnn1 dataset: Plots of iteration number (left) and total communication bits (right) versus distance error.
5.3. Distributed LASSO
The distributed LASSO solves problem (1) with , defined as:
where , , and are as defined in Section 5.1. The parameters and are regularization terms.
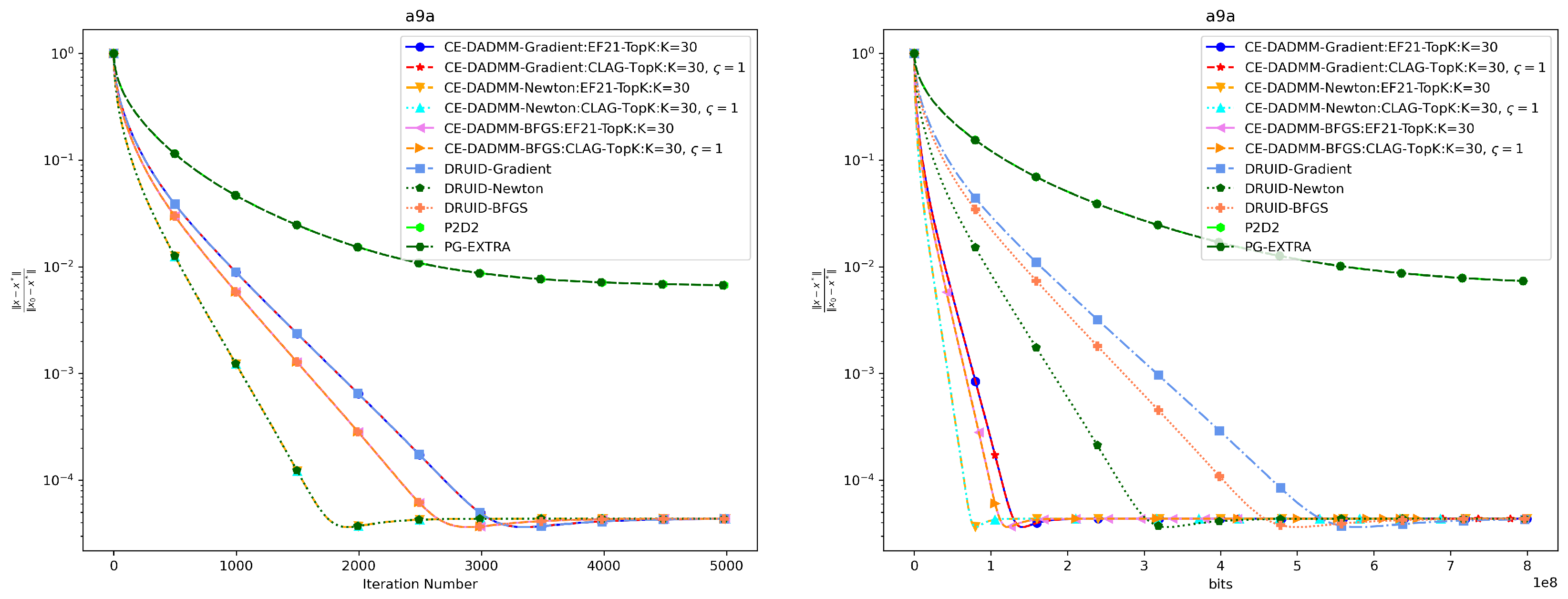
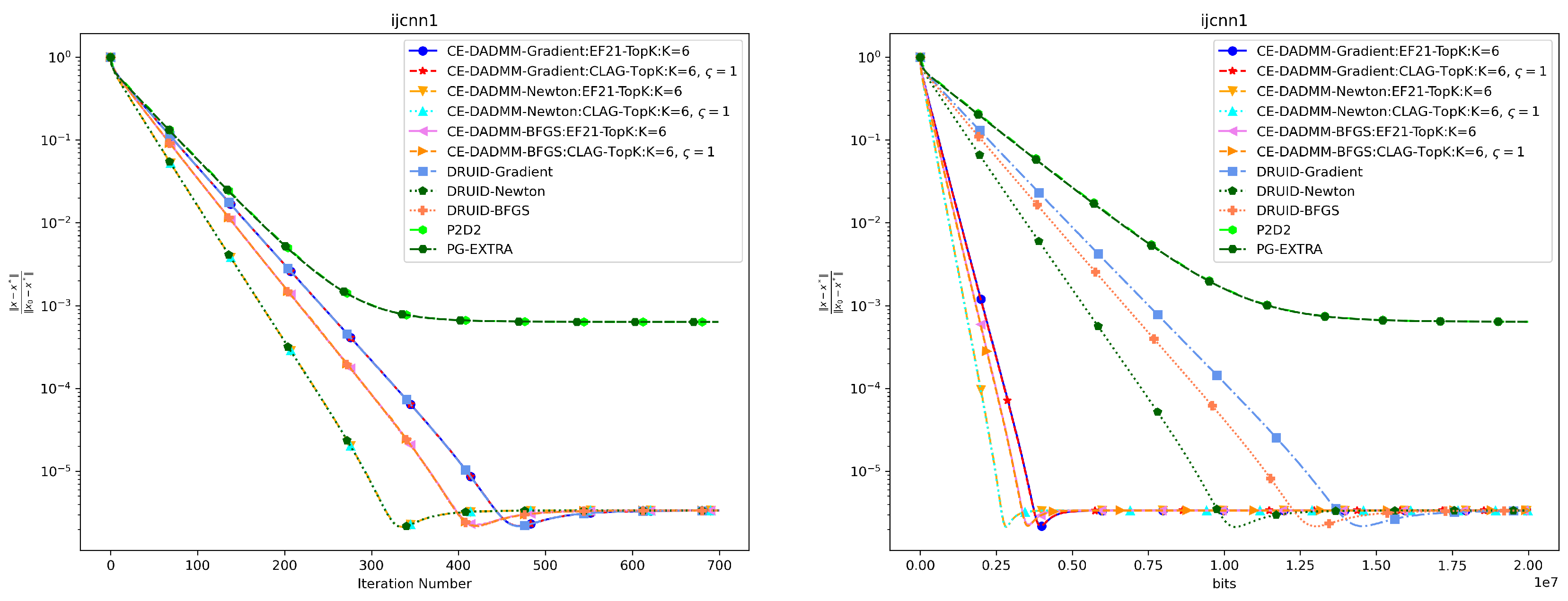
In Figure 7 and Figure 8, when measured by the number of iterations, CE-DADMM performs similarly to DRUID and outperforms P2D2 and PG-EXTRA in terms of convergence speed and accuracy, indicating that the introduction of the 3PC compression mechanism does not negatively affect the convergence speed of the CE-DADMM algorithm. When measured by total communication bits, after introducing the EF21 and CLAG compression mechanisms, CE-DADMM significantly reduces communication overhead compared to DRUID, while also outperforming P2D2 and PG-EXTRA, demonstrating that the communication compression mechanisms can significantly lower communication costs between agents. Similarly, the corresponding numerical results are also presented in Table 2 and Table 3.
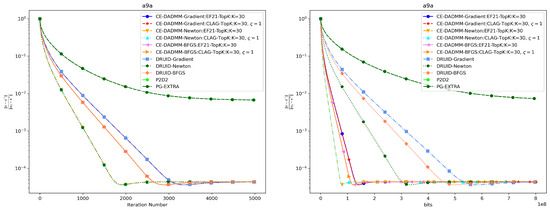
Figure 7.
Performance comparison of distributed LASSO on the a9a dataset: Plots of iteration number (left) and total communication bits (right) versus distance error.
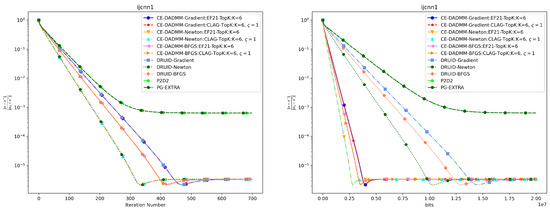
Figure 8.
Performance comparison of distributed LASSO on the ijcnn1 dataset: Plots of iteration number (left) and total communication bits (right) versus distance error.
6. Conclusions
This paper presents a communication-efficient ADMM algorithm for composite optimization, named as CE-DADMM. The algorithm utilizes the ADMM framework with the 3PC communication mechanism, effectively adapting to various communication and computational demands while balancing communication efficiency and computational cost. Notably, when employing quasi-Newton updates, CE-DADMM becomes the first compression-based second-order communication-efficient algorithm. Theoretical analysis demonstrates that the proposed algorithm achieves linear convergence when the local objective functions are strongly convex. Numerical experiments further validate the effectiveness and superior performance of the algorithm. Future work will focus on extending the algorithm to fully asynchronous settings and stochastic problems.
Author Contributions
Z.C.: Conceptualization, writing—original draft and methodology; Z.Z.: Conceptualization, writing—original draft and methodology; S.Y.: writing—review and editing and supervision; J.C.: writing—review and editing and supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China under Grant 62176056, and in part by the Young Elite Scientists Sponsorship Program by the China Association for Science and Technology (CAST) under Grant 2021QNRC001.
Data Availability Statement
The data supporting the findings of this study are openly available in a9a and ijcnn1 at https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html (accessed on 3 December 2024).
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this article.
Appendix A. Proof of Lemma 3
Proof of Lemma 3.
First, according to (18), it follows from the triangle inequality and Cauchy–Schwartz inequality that
For case 1 (gradient updates), there is . By Assumption 1, we obtain .
For case 2 (Newton updates), there is . Applying Assumption 1 and (A1) yields
In parallel, by the fundamental theorem of calculus, we can obtain
which implies that
For case 3 (quasi-Newton updates), according to Assumption 3, the secant condition , and the definition of , we have
which completes the proof of case 3. □
Appendix B. Proof of Theorem 1
Lemma A1.
Let be the unique dual optimal pair which lies in the column space of as established in Lemma 1. The following inequality holds:
Proof.
We rewrite (17b) and (17d) as
First, we show that the column space of belongs to the column space of . We fix all as , i.e., , then it holds that , which shows . By setting , we conclude that lies in the column space of . □
Lemma A2.
The following two inequalities hold:
Proof.
From the definition of the proximal operator, it holds that
By the optimal condition of (A9) and the dual update (17d), we obtain
which implies that . Then, it follows from the convexity of that
Similarly, using (16b), we also have
The proof is completed. □
Proof of Theorem 1.
To make the proof more concise, let . As is strongly convex with Lipschitz continuous gradient, the following inequality holds:
For , we have
For , since , it follows from (16c) that
For , using and (16d), there is
For , using (16e), we have
For , using and (16c), we have
For , using (17d) and (16e), we have
Substituting (A11)–(A16) into (A10) yields
where and can be further estimated as
and
where (A19) uses the fact that the largest eigenvalue of is 1. Finally, substituting (A18) and (A19) into (A17), we obtain
Recall the definitions of and , and define and . The inequalities and hold, along with the assumption that . Thus, (A20) can be rewritten as
To establish linear convergence, we need to show the following holds for some :
Note that
Next, we establish an upper bound for each component of (A23), primarily using the inequality and . First, according to Lemma A1, we obtain
Next, since , we have
Then, from (17d) and (16e), we obtain
References
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and cooperation in networked multi-agent systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef]
- Yoo, S.J.; Park, B.S. Dynamic event-triggered prescribed-time consensus tracking of nonlinear time-delay multiagent systems by output feedback. Fractal Fract. 2024, 8, 545. [Google Scholar] [CrossRef]
- Liu, H.J.; Shi, W.; Zhu, H. Distributed voltage control in distribution networks: Online and robust implementations. IEEE Trans. Smart Grid 2017, 9, 6106–6117. [Google Scholar] [CrossRef]
- Molzahn, D.K.; Dorfler, F.; Sandberg, H.; Low, S.H.; Chakrabarti, S.; Baldick, R.; Lavaei, J. A survey of distributed optimization and control algorithms for electric power systems. IEEE Trans. Smart Grid 2017, 8, 2941–2962. [Google Scholar] [CrossRef]
- Liu, Y.F.; Chang, T.H.; Hong, M.; Wu, Z.; So, A.M.C.; Jorswieck, E.A.; Yu, W. A survey of recent advances in optimization methods for wireless communications. IEEE J. Sel. Areas Commun. 2024, 42, 2992–3031. [Google Scholar] [CrossRef]
- Huang, J.; Zhou, S.; Tu, H.; Yao, Y.; Liu, Q. Distributed optimization algorithm for multi-robot formation with virtual reference center. IEEE/CAA J. Autom. Sin. 2022, 9, 732–734. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, W.; Yuan, J.; Chen, T.; Zhang, C.; Wang, L. Distributed optimization for fractional-order multi-agent systems based on adaptive backstepping dynamic surface control technology. Fractal Fract. 2022, 6, 642. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, C. Distributed learning systems with first-order methods. Found. Trends Databases 2020, 9, 1–100. [Google Scholar] [CrossRef]
- Nedic, A.; Ozdaglar, A. Distributed subgradient methods for multi-agent optimization. IEEE Trans. Autom. Control 2009, 54, 48–61. [Google Scholar] [CrossRef]
- Nedic, A.; Olshevsky, A.; Shi, W. Achieving geometric convergence for distributed optimization over time-varying graphs. SIAM J. Optim. 2017, 27, 2597–2633. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, S.; Soh, Y.C.; Xie, L. Convergence of asynchronous distributed gradient methods over stochastic networks. IEEE Trans. Autom. Control 2018, 63, 434–448. [Google Scholar] [CrossRef]
- Wen, X.; Luan, L.; Qin, S. A continuous-time neurodynamic approach and its discretization for distributed convex optimization over multi-agent systems. Neural Netw. 2021, 143, 52–65. [Google Scholar] [CrossRef]
- Feng, Z.; Xu, W.; Cao, J. Alternating inertial and overrelaxed algorithms for distributed generalized Nash equilibrium seeking in multi-player games. Fractal Fract. 2021, 5, 62. [Google Scholar] [CrossRef]
- Che, K.; Yang, S. A snapshot gradient tracking for distributed optimization over digraphs. In Proceedings of the CAAI International Conference on Artificial Intelligence, Beijing, China, 27–28 August 2022; pp. 348–360. [Google Scholar]
- Zhou, S.; Wei, Y.; Liang, S.; Cao, J. A gradient tracking protocol for optimization over Nabla fractional multi-agent systems. IEEE Trans. Signal Inf. Process. Over Netw. 2024, 10, 500–512. [Google Scholar] [CrossRef]
- Shi, W.; Ling, Q.; Wu, G.; Yin, W. EXTRA: An exact first-order algorithm for decentralized consensus optimization. SIAM J. Optim. 2015, 25, 944–966. [Google Scholar] [CrossRef]
- Ling, Q.; Shi, W.; Wu, G.; Ribeiro, A. DLM: Decentralized linearized alternating direction method of multipliers. IEEE Trans. Signal Process. 2015, 63, 4051–4064. [Google Scholar] [CrossRef]
- Mokhtari, A.; Shi, W.; Ling, Q.; Ribeiro, A. DQM: Decentralized quadratically approximated alternating direction method of multipliers. IEEE Trans. Signal Process. 2016, 64, 5158–5173. [Google Scholar] [CrossRef]
- Eisen, M.; Mokhtari, A.; Ribeiro, A. A primal-dual quasi-Newton method for exact consensus optimization. IEEE Trans. Signal Process. 2019, 67, 5983–5997. [Google Scholar] [CrossRef]
- Mansoori, F.; Wei, E. A fast distributed asynchronous Newton-based optimization algorithm. IEEE Trans. Autom. Control 2019, 65, 2769–2784. [Google Scholar] [CrossRef]
- Jiang, X.; Qin, S.; Xue, X.; Liu, X. A second-order accelerated neurodynamic approach for distributed convex optimization. Neural Netw. 2022, 146, 161–173. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Voulgaris, P.G.; Stipanović, D.M.; Freris, N.M. Communication efficient curvature aided primal-dual algorithms for decentralized optimization. IEEE Trans. Autom. Control 2023, 68, 6573–6588. [Google Scholar] [CrossRef]
- Alistarh, D.; Grubic, D.; Li, J.Z.; Tomioka, R.; Vojnovic, M. QSGD: Communication-efficient SGD via gradient quantization and encoding. In Proceedings of the 30th NeurIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 1710–1721. [Google Scholar]
- Wangni, J.; Wang, J.; Liu, J.; Zhang, T. Gradient sparsification for communication-efficient distributed optimization. In Proceedings of the 31st NeurIPS 2018, Montreal, QC, Canada, 2–8 December 2018; pp. 1306–1316. [Google Scholar]
- Stich, S.U.; Cordonnier, J.B.; Jaggi, M. Sparsified SGD with memory. In Proceedings of the 31st NeurIPS 2018, Montreal, QC, Canada, 2–8 December 2018; pp. 4447–4458. [Google Scholar]
- Doan, T.T.; Maguluri, S.T.; Romberg, J. Fast convergence rates of distributed subgradient methods with adaptive quantization. IEEE Trans. Autom. Control 2020, 66, 2191–2205. [Google Scholar] [CrossRef]
- Taheri, H.; Mokhtari, A.; Hassni, H.; Pedarsani, R. Quantized decentralized stochastic learning over directed graphs. In Proceedings of the 37th ICML, Virtual, 13–18 July 2020; pp. 9324–9333. [Google Scholar]
- Song, Z.; Shi, L.; Pu, S.; Yan, M. Compressed gradient tracking for decentralized optimization over general directed networks. IEEE Trans. Signal Process. 2022, 70, 1775–1787. [Google Scholar] [CrossRef]
- Xiong, Y.; Wu, L.; You, K.; Xie, L. Quantized distributed gradient tracking algorithm with linear convergence in directed networks. IEEE Trans. Autom. Control 2022, 68, 5638–5645. [Google Scholar] [CrossRef]
- Zhu, S.; Hong, M.; Chen, B. Quantized consensus ADMM for multi-agent distributed optimization. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4134–4138. [Google Scholar]
- Elgabli, A.; Park, J.; Bedi, A.S.; Issaid, C.B.; Bennis, M.; Aggarwal, V. Q-GADMM: Quantized group ADMM for communication efficient decentralized machine learning. IEEE Trans. Commun. 2020, 69, 164–181. [Google Scholar] [CrossRef]
- Li, W.; Liu, Y.; Tian, Z.; Ling, Q. Communication-censored linearized ADMM for decentralized consensus optimization. IEEE Trans. Signal Inf. Process. Over Netw. 2020, 6, 18–34. [Google Scholar] [CrossRef]
- Gao, L.; Deng, S.; Li, H.; Li, C. An event-triggered approach for gradient tracking in consensus-based distributed optimization. IEEE Trans. Netw. Sci. Eng. 2021, 9, 510–523. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, S.; Xu, W.; Di, K. Privacy-preserving distributed ADMM with event-triggered communication. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 2835–2847. [Google Scholar] [CrossRef]
- Chen, T.; Giannakis, G.; Sun, T.; Yin, W. LAG: Lazily aggregated gradient for communication-efficient distributed learning. Adv. Neural Inf. Process. Syst. 2018, 31, 5050–5060. [Google Scholar]
- Sun, J.; Chen, T.; Giannakis, G.; Yang, Z. Communication-efficient distributed learning via lazily aggregated quantized gradients. Adv. Neural Inf. Process. Syst. 2019, 32, 3370–3380. [Google Scholar]
- Singh, N.; Data, D.; George, J.; Diggavi, S. SPARQ-SGD: Event-triggered and compressed communication in decentralized optimization. IEEE Trans. Autom. Control 2022, 68, 721–736. [Google Scholar] [CrossRef]
- Yang, X.; Yuan, J.; Chen, T.; Yang, H. Distributed adaptive optimization algorithm for fractional high-order multiagent systems based on event-triggered strategy and input quantization. Fractal Fract. 2023, 7, 749. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, S.; Xu, W. Decentralized ADMM with compressed and event-triggered communication. Neural Netw. 2023, 165, 472–482. [Google Scholar] [CrossRef]
- Richtárik, P.; Sokolov, I.; Fatkhullin, I. EF21: A new, simpler, theoretically better, and practically faster error feedback. In Proceedings of the 34th NeurIPS, Virtual, 6–14 December 2021; pp. 4384–4396. [Google Scholar]
- Richtarik, P.; Sokolov, I.; Fatkhullin, I.; Gasanov, E.; Li, Z.; Gorbunov, E. 3PC: Three point compressors for communication-efficient distributed training and a better theory for Lazy aggregation. In Proceedings of the 39th ICML, Baltimore, MD, USA, 17–23 July 2022; pp. 18596–18648. [Google Scholar]
- Shi, W.; Ling, Q.; Wu, G.; Yin, W. A proximal gradient algorithm for decentralized composite optimization. IEEE Trans. Signal Process. 2015, 63, 6013–6023. [Google Scholar] [CrossRef]
- Alghunaim, S.; Yuan, K.; Sayed, A.H. A linearly convergent proximal gradient algorithm for decentralized optimization. In Proceedings of the 32nd NeurIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Guo, L.; Shi, X.; Yang, S.; Cao, J. DISA: A dual inexact splitting algorithm for distributed convex composite optimization. IEEE Trans. Autom. Control 2024, 69, 2995–3010. [Google Scholar] [CrossRef]
- Li, W.; Liu, Y.; Tian, Z.; Ling, Q. COLA: Communication-censored linearized ADMM for decentralized consensus optimization. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5237–5241. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).