
Lightweight Oriented Detector for Insulators in Drone Aerial Images


Abstract
1. Introduction
- We designed a lightweight insulator feature pyramid network (LIFPN) that effectively reduces the number of feature fusion paths and convolutions, greatly reducing the number of model parameters while ensuring a high detection accuracy.
- We designed a lightweight insulator oriented detection head (LIHead) that can not only generate rotation boxes with rotation angles but also has fewer parameters and a lower computational complexity.
- We selected the suitable lightweight backbone through experiments and combined it with LIFPN and LIHead to form a lightweight oriented detector. We deployed it on the edge device Nvidia AGX Orin and verified the real-time performance of the model.
2. Related Work
2.1. Object Detection
2.2. Insulator Detection
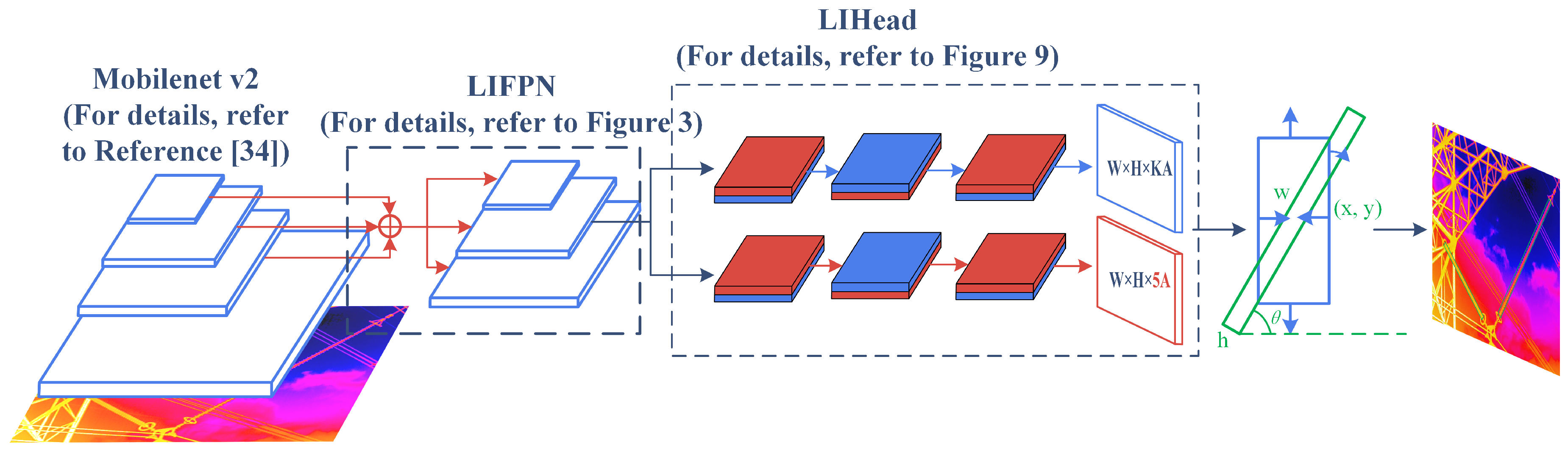
3. Methods
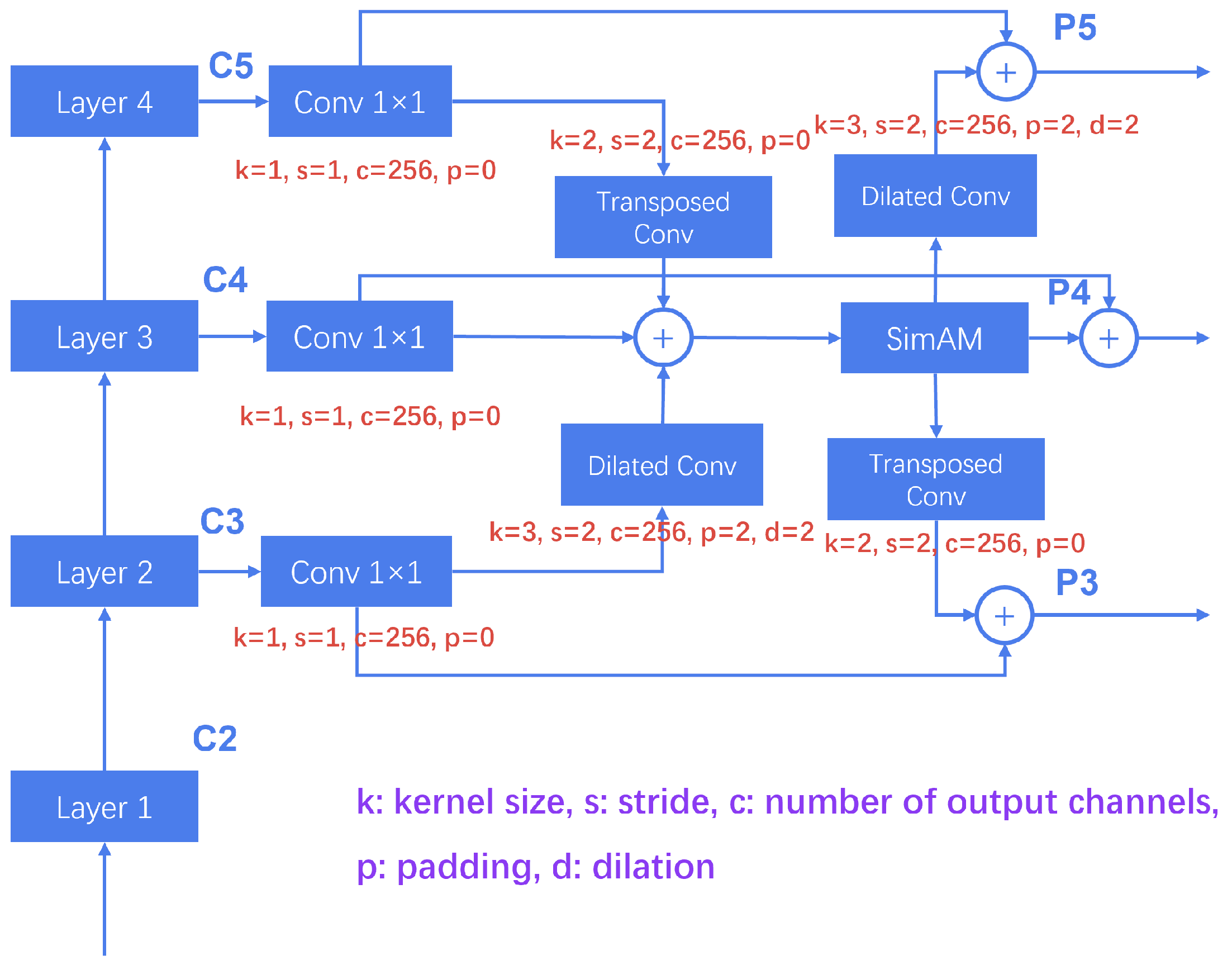
3.1. LIFPN
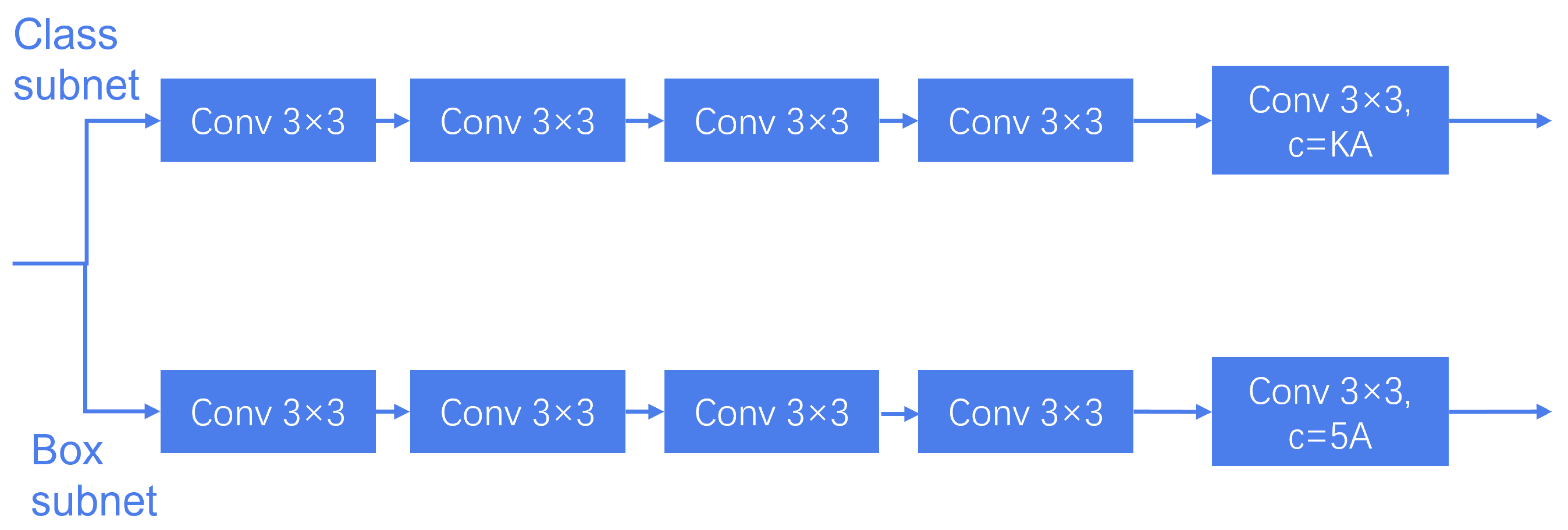
3.2. LIHead
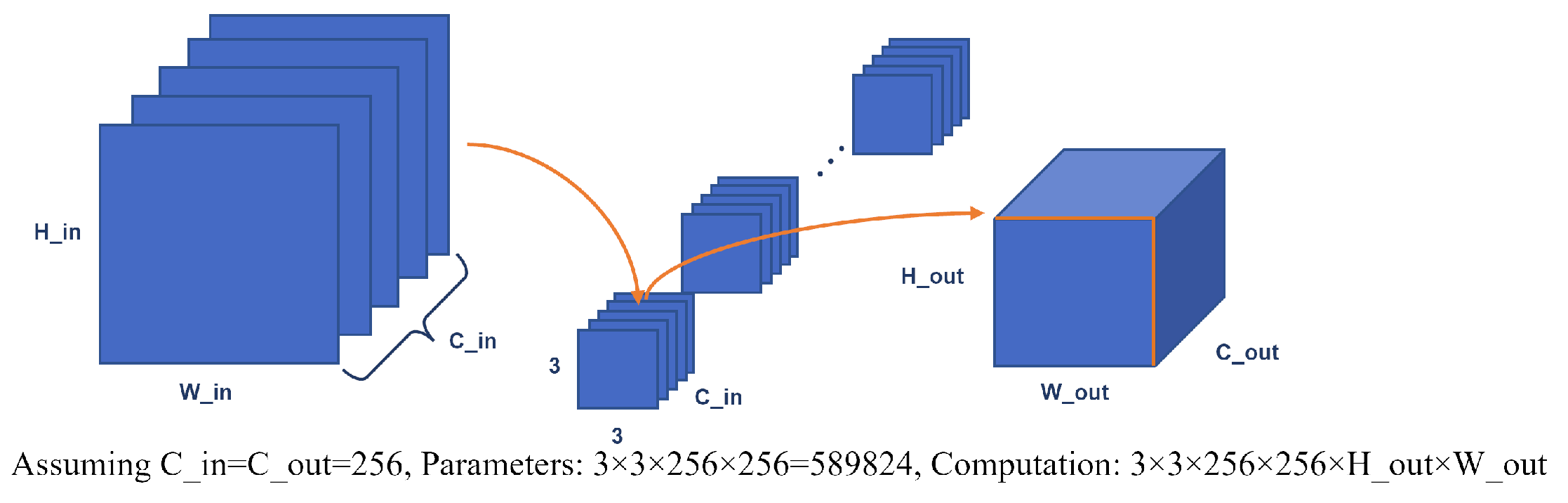
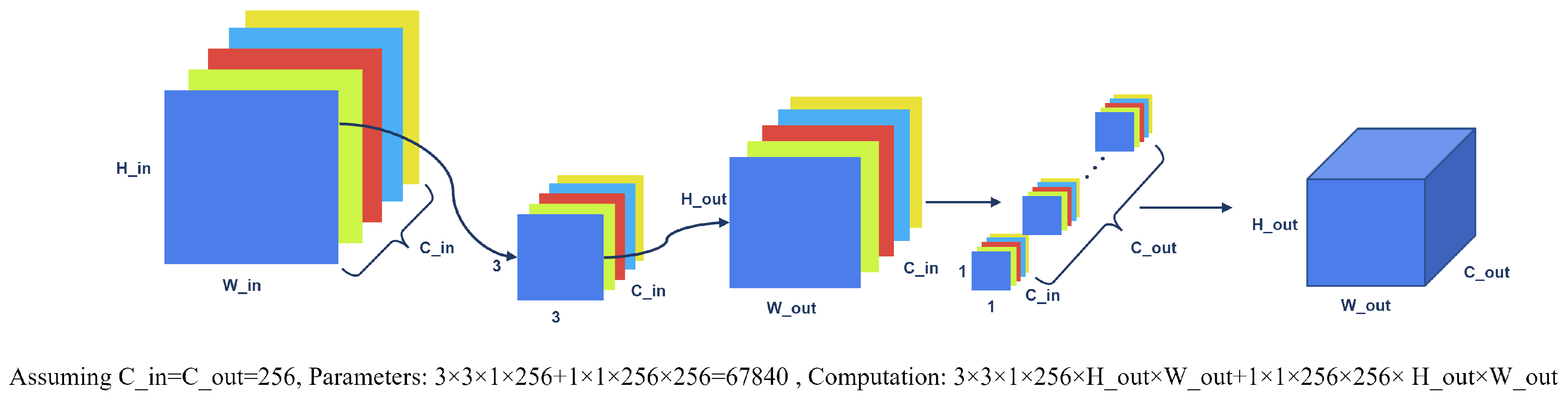
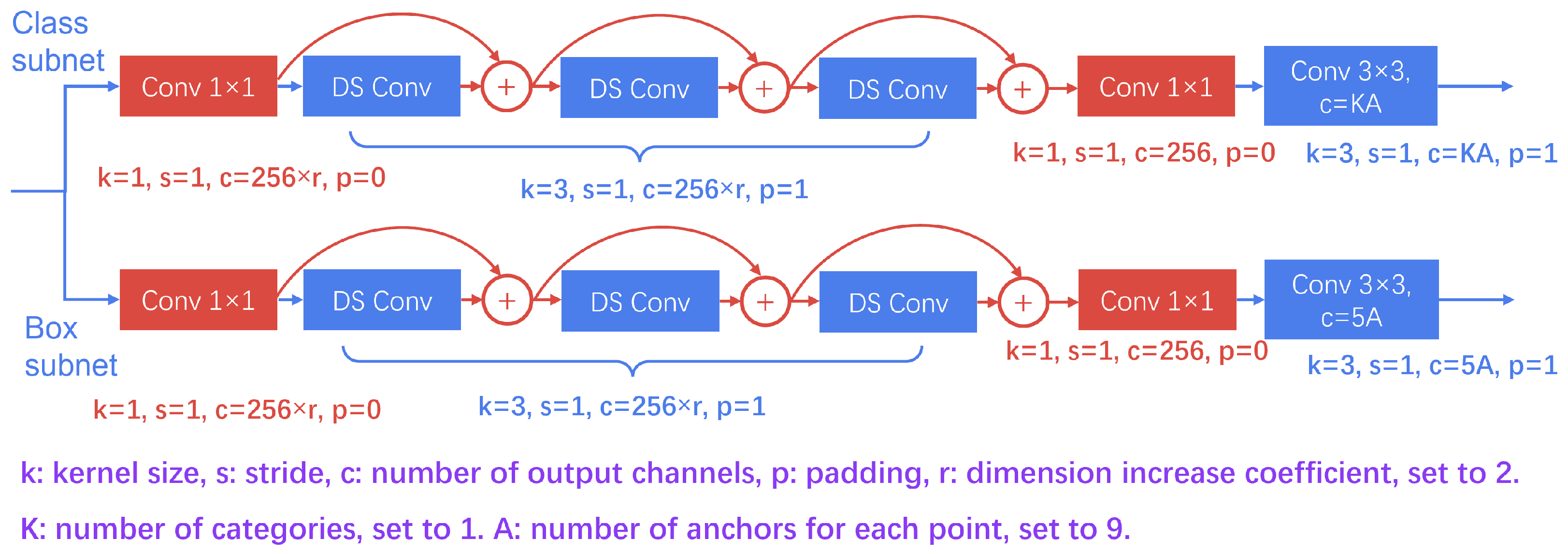
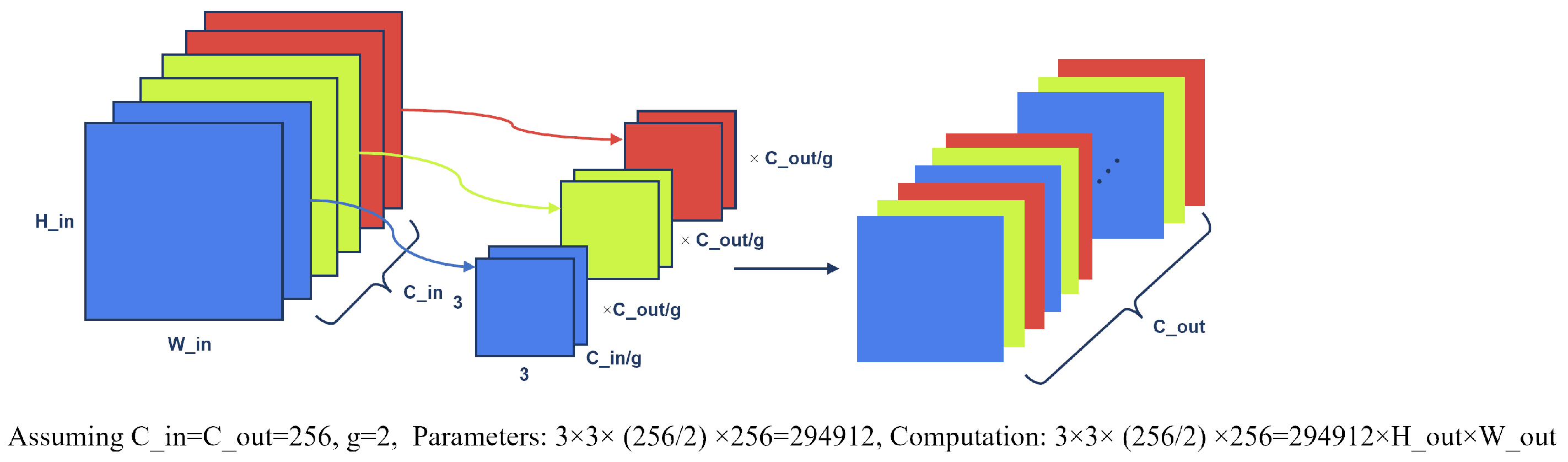
3.2.1. LIHead Based on Deep Separable Convolution
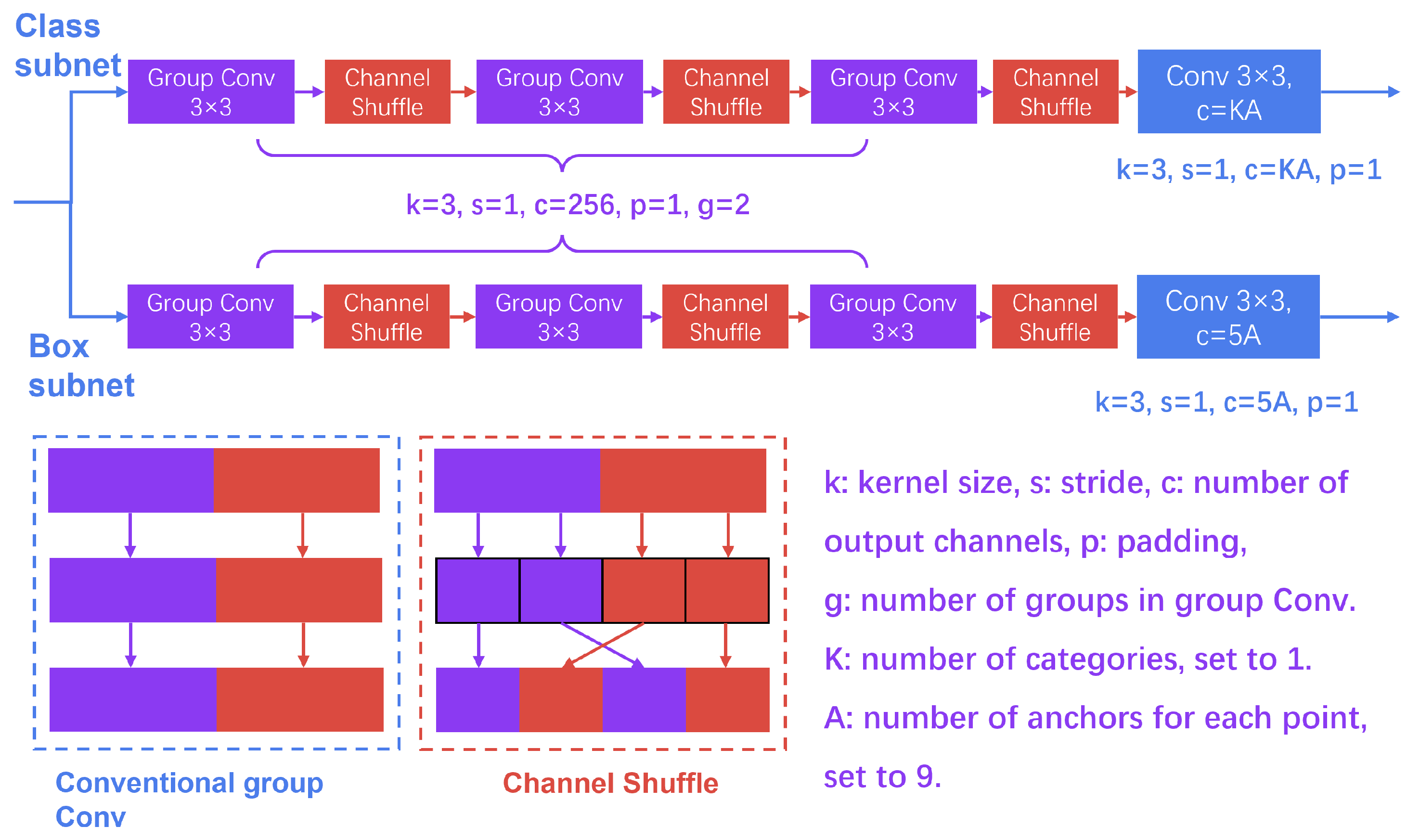
3.2.2. LIHead Based on Group Convolution
3.2.3. Comparison of Two LIHead Structures
3.3. Lightweight Backbone Selection
3.4. Edge Device Deployment and Model Acceleration
4. Experiments
4.1. Experimental Setup and Dataset
4.2. Evaluation Metrics
4.3. Ablation Study
4.3.1. LIFPN Experiment
4.3.2. LIHead Experiment
4.3.3. Backbone Experiment
4.3.4. All Ablation Experiments
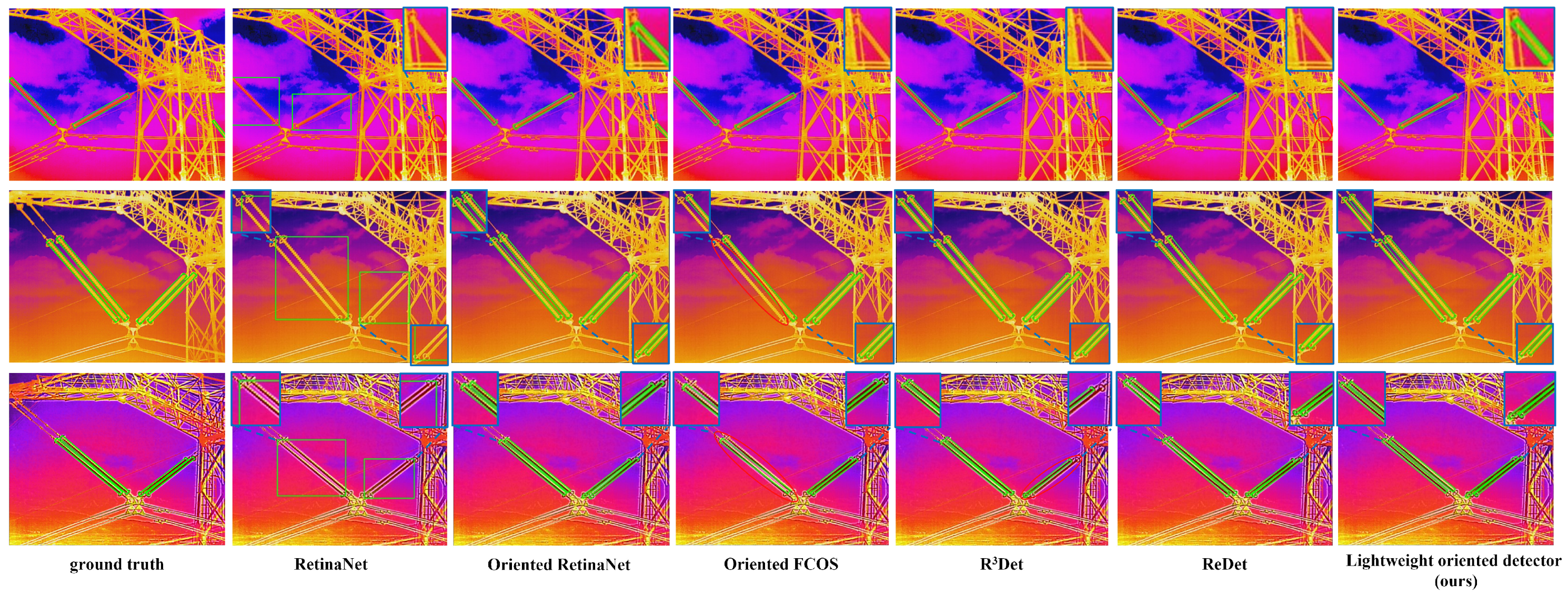
4.4. Comparative Experiment
4.5. Edge Device Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, J.; Wu, H.; Zhang, H.; Wang, Z.; Xu, W. Insulator-defect detection algorithm based on improved YOLOv7. Sensors 2022, 22, 8801. [Google Scholar] [CrossRef] [PubMed]
- Lu, Z.; Li, Y.; Shuang, F. MGFNet: A Progressive Multi-Granularity Learning Strategy-Based Insulator Defect Recognition Algorithm for UAV Images. Drones 2023, 7, 333. [Google Scholar] [CrossRef]
- Shuang, F.; Han, S.; Li, Y.; Lu, T. RSIn-dataset: An UAV-based insulator detection aerial images dataset and benchmark. Drones 2023, 7, 125. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, W.; Zhang, H.; Zheng, C.; Ma, J.; Zhang, Z. ITD-YOLOv8: An Infrared Target Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones 2024, 8, 161. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, Y.; Zhang, W.; Zhou, H.; Yu, H. SDWBF algorithm: A novel pedestrian detection algorithm in the aerial scene. Drones 2022, 6, 76. [Google Scholar] [CrossRef]
- Han, Y.; Guo, J.; Yang, H.; Guan, R.; Zhang, T. SSMA-YOLO: A Lightweight YOLO Model with Enhanced Feature Extraction and Fusion Capabilities for Drone-Aerial Ship Image Detection. Drones 2024, 8, 145. [Google Scholar] [CrossRef]
- Lu, G.; He, X.; Wang, Q.; Shao, F.; Wang, H.; Wang, J. A novel multi-scale transformer for object detection in aerial scenes. Drones 2022, 6, 188. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G. ReDet: A Rotation-equivariant Detector for Aerial Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 2785–2794. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the 2021 AAAI Conference on Artificial Intelligence (AAAI), Virtually, 2–9 February 2021; Volume 35, pp. 3163–3171. [Google Scholar]
- Zhai, Y.; Wang, D.; Zhang, M.; Wang, J.; Guo, F. Fault detection of insulator based on saliency and adaptive morphology. Multimed. Tools Appl. 2017, 76, 12051–12064. [Google Scholar] [CrossRef]
- Zhang, K.; Qian, S.; Zhou, J.; Xie, C.; Du, J.; Yin, T. ARFNet: Adaptive receptive field network for detecting insulator self-explosion defects. Signal Image Video Process. 2022, 16, 2211–2219. [Google Scholar] [CrossRef]
- Zhai, Y.; Chen, R.; Yang, Q.; Li, X.; Zhao, Z. Insulator fault detection based on spatial morphological features of aerial images. IEEE Access 2018, 6, 35316–35326. [Google Scholar] [CrossRef]
- Tao, X.; Zhang, D.; Wang, Z.; Liu, X.; Zhang, H.; Xu, D. Detection of power line insulator defects using aerial images analyzed with convolutional neural networks. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 1486–1498. [Google Scholar] [CrossRef]
- Yu, Z.; Lei, Y.; Shen, F.; Zhou, S.; Yuan, Y. Research on Identification and Detection of Transmission Line Insulator Defects Based on a Lightweight YOLOv5 Network. Remote Sens. 2023, 15, 4552. [Google Scholar] [CrossRef]
- Zheng, H.; Liu, Y.; Sun, Y.; Li, J.; Shi, Z.; Zhang, C.; Lai, C.S.; Lai, L.L. Arbitrary-Oriented Detection of Insulators in Thermal Imagery via Rotation Region Network. IEEE Trans. Ind. Inform. 2022, 18, 5242–5252. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 13–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the 2021 International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–11. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]
- Hou, L.; Lu, K.; Xue, J.; Li, Y. Shape-adaptive selection and measurement for oriented object detection. In Proceedings of the 2022 AAAI Conference on Artificial Intelligence (AAAI), Virtual, 22 February–1 March 2022; Volume 36, pp. 923–932. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Methods | Detection Accuracy | Detection Speed |
|---|---|---|
| [21] | Achieved an accuracy of 92% on a self-built dataset (100 aerial images). | Achieved 0.5 frames per second (FPS) on the computer |
| [22] | On a self-built dataset (2303 aerial images), the combination of ARFNet and YOLO v5 achieved an 84.4% average precision (AP). Note that this was the AP for the horizontal detection box. | No relevant data available. |
| [23] | Achieved a detection accuracy of 90.6% on a self-built dataset (74 aerial images). | Due to the use of multiple image-processing steps, the detection speed was slow, reaching only about 1.5 FPS on the computer. |
| [24] | Achieved 91% precision and 96% recall in detecting dropped string defects on a self-built dataset (1956 aerial images). | Due to the use of cascaded networks, the detection speed was slow and could only reach 2.79 FPS on the computer. |
| [25] | Achieved a 70.5% and 50.3% on a self-built dataset (1627 aerial images). Note that this was the AP for the horizontal detection box. | Related data mismatch. |
| [26] | Achieved 95.08% on a self-built dataset (2760 aerial images), with no relevant data available. | Due to the use of an oriented object detector, the detection speed was slow and could only reach 6.3 FPS on the computer. Note that this was the AP for the rotated detection box. |
| Neck | AP (%) | AP50 (%) | AP75 (%) | FLOPs (G) | Params (M) |
|---|---|---|---|---|---|
| FPN | 62.89 | 90.38 | 75.96 | 65.49 | 36.13 |
| LIFPN1 (Integrated feature fusion path) | 62.85 | 90.63 | 75.38 | 60.65 | 29.05 |
| LIFPN2 (Replace with transposed Conv) | 63.96 | 90.51 | 75.02 | 61.08 | 29.57 |
| LIFPN3 (Replace with dilation Conv) | 63.02 | 90.60 | 75.99 | 61.60 | 30.23 |
| LIFPN4 (Replace with transposed and dilation Conv) | 64.26 | 90.63 | 76.00 | 62.02 | 30.75 |
| LIFPN5 (Integrating the SimAM attention mechanism) | 64.66 | 90.68 | 76.53 | 62.02 | 30.75 |
| Head | AP (%) | AP50 (%) | AP75 (%) | FLOPs (G) | Params (M) |
|---|---|---|---|---|---|
| Baseline | 62.89 | 90.38 | 75.96 | 65.49 | 36.13 |
| LIHead (DSConv) | 0 | 0 | 0 | 37.04 | 31.95 |
| LIHead (DS Conv and shortcut) | 53.38 | 89.40 | 54.06 | 37.04 | 31.95 |
| LIHead (DS Conv and high-dimensional) | 60.34 | 90.25 | 66.76 | 47.88 | 33.54 |
| LIHead (group Conv and shuffle) | 62.84 | 90.40 | 76.19 | 45.37 | 33.18 |
| Backbone | AP (%) | AP50 (%) | AP75 (%) | FLOPs (G) | Params (M) |
|---|---|---|---|---|---|
| ResNet50 | 62.89 | 90.38 | 75.96 | 65.49 | 36.13 |
| Mobilenet v3 | 60.84 | 90.20 | 67.40 | 37.49 | 8.4 |
| ShuffleNetv2 | 59.49 | 90.05 | 65.44 | 38.36 | 9.74 |
| Mobilenet v2 | 60.72 | 90.58 | 67.54 | 39.53 | 12.74 |
| Mobilenet v2 | LIFPN | LIHead | AP (%) | AP50 (%) | AP75 (%) | FLOPs (G) | Params (M) |
|---|---|---|---|---|---|---|---|
| 62.89 | 90.38 | 75.96 | 65.49 | 36.13 | |||
| 🗸 | 60.72 | 90.58 | 67.54 | 39.53 | 12.74 | ||
| 🗸 | 64.43 | 90.60 | 74.91 | 62.02 | 30.75 | ||
| 🗸 | 62.84 | 90.40 | 76.19 | 45.37 | 33.18 | ||
| 🗸 | 🗸 | 🗸 | 62.48 | 90.39 | 75.38 | 16.38 | 6.19 |
| Detector | AP (%) | AP50 (%) | AP75 (%) | FLOPs (G) | Params (M) |
|---|---|---|---|---|---|
| RetinaNet [17] | 58.30 | 87.70 | 66.0 | 65.35 | 36.10 |
| Oriented RetinaNet | 62.89 | 90.38 | 75.96 | 65.49 | 36.13 |
| Oriented FCOS [41] | 64.06 | 90.68 | 77.72 | 64.44 | 31.89 |
| R3Det [20] | 62.81 | 90.63 | 78.47 | 139.94 | 47.04 |
| Oriented Reppoints [42] | 59.76 | 88.01 | 69.88 | 60.71 | 36.62 |
| ReDet [19] | 65.55 | 90.82 | 78.85 | 44.15 | 31.54 |
| SASM [43] | 64.01 | 86.70 | 77.30 | 60.70 | 36.60 |
| Lightweight oriented detector (ours) | 62.48 | 90.39 | 75.38 | 16.38 | 6.19 |
| Mobilenet v2 | LIFPN | LIHead | AP (%) | AP50 (%) | AP75 (%) | FPS 1 | FPS 2 |
|---|---|---|---|---|---|---|---|
| 62.887 | 90.381 | 75.965 | 11.43 | 33.37 | |||
| 🗸 | 60.720 | 90.586 | 67.544 | 11.88 | 38.23 | ||
| 🗸 | 64.266 | 90.604 | 74.911 | 12.12 | 39.52 | ||
| 🗸 | 62.836 | 90.403 | 76.187 | 12.06 | 38.71 | ||
| 🗸 | 🗸 | 🗸 | 62.477 | 90.393 | 75.380 | 13.65 | 41.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, F.; Lin, Y.; Tian, L.; Du, Q.; Wu, H.; Liao, W. Lightweight Oriented Detector for Insulators in Drone Aerial Images. Drones 2024, 8, 294. https://doi.org/10.3390/drones8070294
Qu F, Lin Y, Tian L, Du Q, Wu H, Liao W. Lightweight Oriented Detector for Insulators in Drone Aerial Images. Drones. 2024; 8(7):294. https://doi.org/10.3390/drones8070294
Chicago/Turabian StyleQu, Fengrui, Yu Lin, Lianfang Tian, Qiliang Du, Huangyuan Wu, and Wenzhi Liao. 2024. "Lightweight Oriented Detector for Insulators in Drone Aerial Images" Drones 8, no. 7: 294. https://doi.org/10.3390/drones8070294
APA StyleQu, F., Lin, Y., Tian, L., Du, Q., Wu, H., & Liao, W. (2024). Lightweight Oriented Detector for Insulators in Drone Aerial Images. Drones, 8(7), 294. https://doi.org/10.3390/drones8070294