
Military Image Captioning for Low-Altitude UAV or UGV Perspectives


Abstract
1. Introduction
- Dataset scarcity: There is no established benchmark dataset in the field of MilitIC. The datasets from military target detection and camouflaged detection are not readily applicable to this field.
- Deficiency of a specific method: there is a scarcity of methods specifically proposed for MilitIC tasks that can effectively highlight military semantics in caption generation.
- We created the first open-access MilitIC benchmark dataset, which was named the Military Objects Dataset in Real Combat (MOCO) and not only includes real and complex military scenes but also provides a vast number of rich captions. MOCO is available at https://github.com/Panlizhi/MOCO (accessed on 1 August 2024).
- We propose a novel encoder–augmentation–decoder architecture, MAE-MilitIC, to leverage image–text modalities to guide caption generation, and introduce the MAE mechanism to augment the image embeddings with explicit military text in the semantic subspace.
- Extensive qualitative and quantitative experiments on two challenging datasets demonstrated that the proposed MAE-MilitIC outperformed existing state-of-the-art image-captioning models.
2. Related Works
2.1. Image Captioning
2.2. Military Image Captioning (MilitIC)
2.3. Military Image Dataset
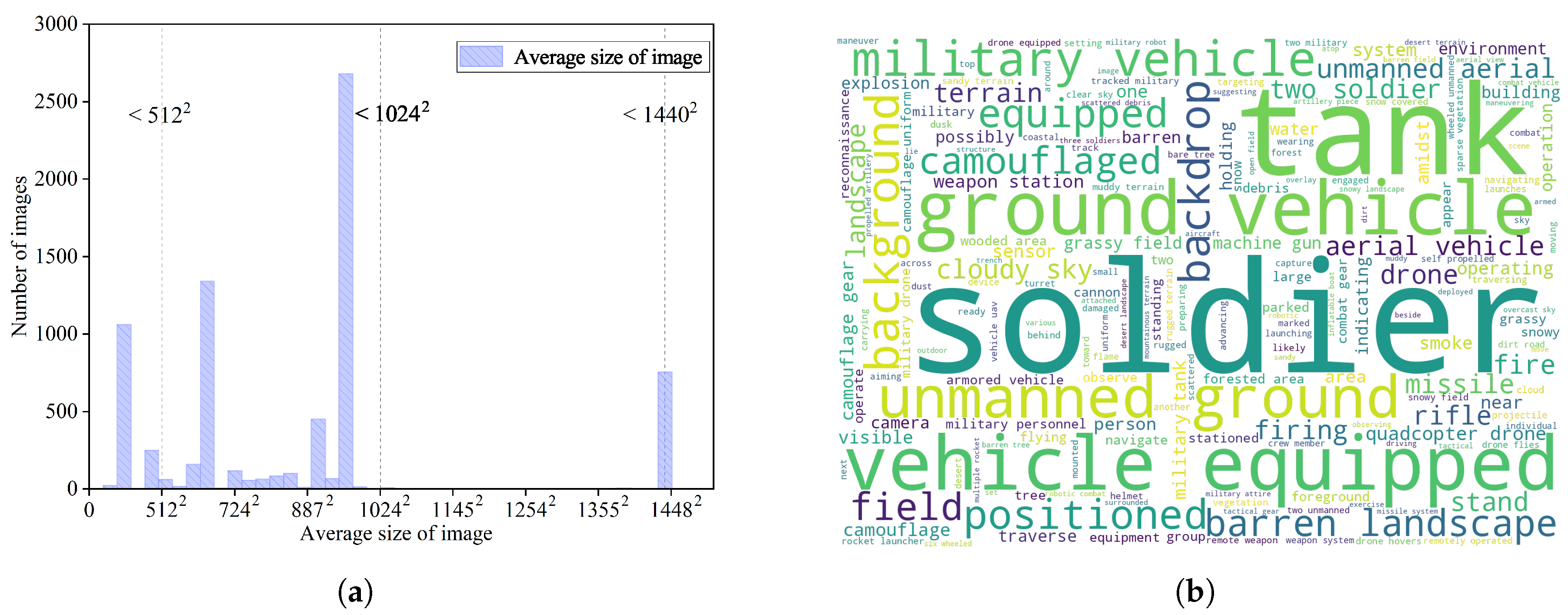
3. MOCO: A Military Objects Dataset in Real Combat for Military Image Captioning
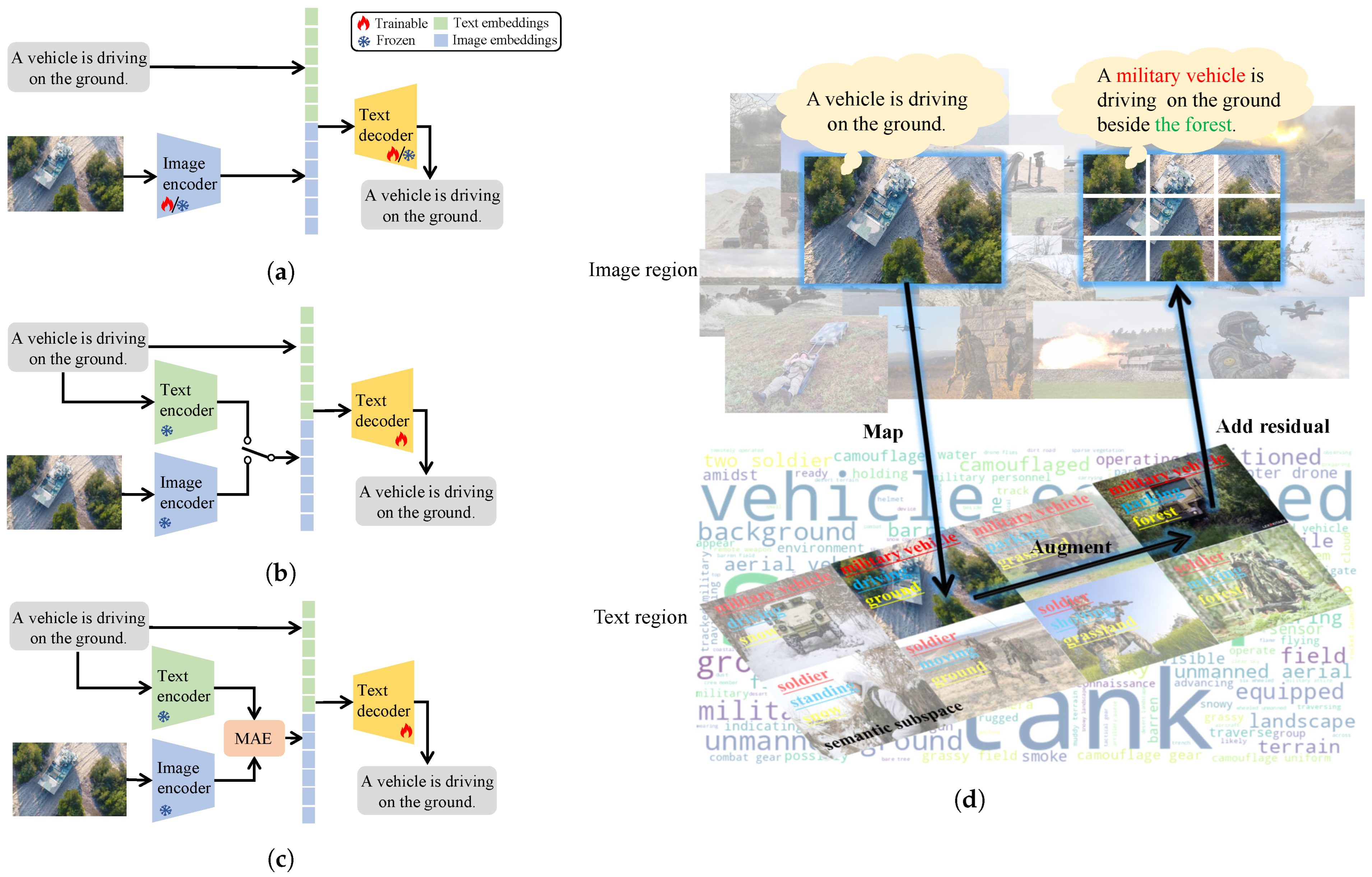
4. MAE-MilitIC: Map Augmentation Embedding to Enhance Semantics for Military Image Captioning
4.1. Backbone of MAE-MilitIC
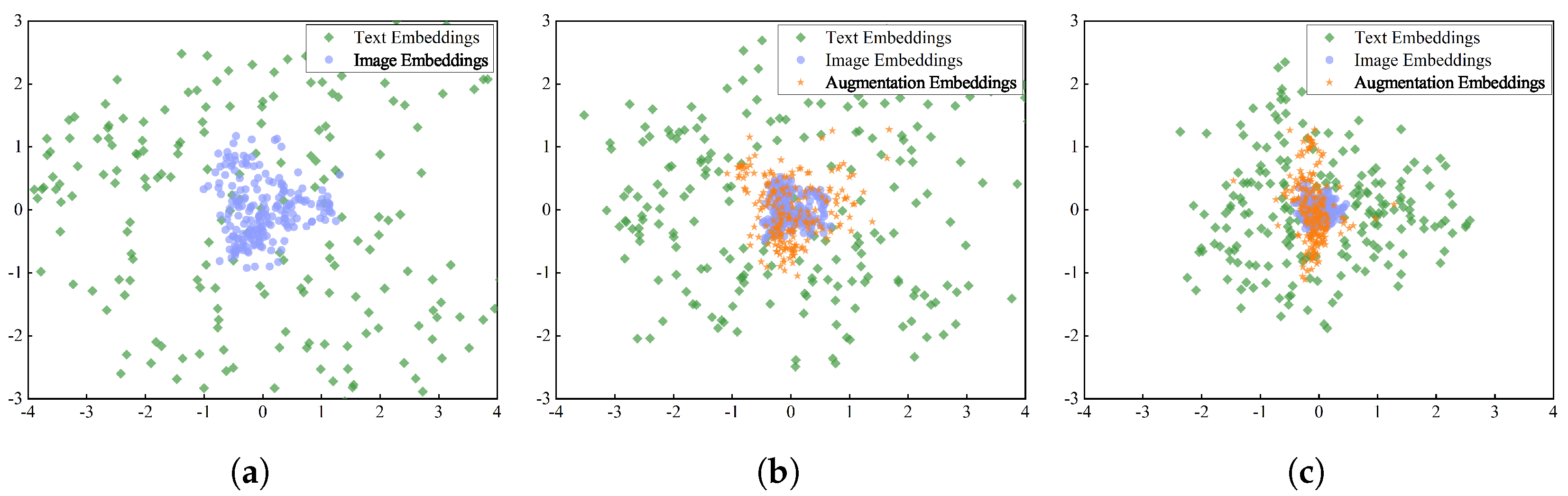
4.2. Map Augmentation Embedding (MAE)
4.2.1. Semantic Subspace
4.2.2. Mapping Step
4.2.3. Augmentation Step
5. Experiments and Results
5.1. Evaluation Metrics
5.2. Dataset Settings
5.3. Experimental Settings
5.4. Experimental Results
5.5. Ablation Studies
5.5.1. Parameter Optimization
5.5.2. Ablation of MAE-MilitIC
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
DURC Statement
Conflicts of Interest
Appendix A

References
- Peng, H.; Zhang, Y.; Yang, S.; Song, B. Battlefield image situational awareness application based on deep learning. IEEE Intell. Syst. 2019, 35, 36–43. [Google Scholar] [CrossRef]
- Monteiro, J.; Kitamoto, A.; Martins, B. Situational awareness from social media photographs using automated image captioning. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 19–21 October 2017; IEEE: Piscataway Township, NJ, USA, 2017; pp. 203–211. [Google Scholar]
- Robertson, J. Integrity of a common operating picture in military situational awareness. In Proceedings of the 2014 Information Security for South Africa, Johannesburg, South Africa, 13–14 August 2014; IEEE: Piscataway Township, NJ, USA, 2014; pp. 1–7. [Google Scholar]
- Schwartz, P.J.; O’Neill, D.V.; Bentz, M.E.; Brown, A.; Doyle, B.S.; Liepa, O.C.; Lawrence, R.; Hull, R.D. AI-enabled wargaming in the military decision making process. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications II. SPIE, Online, 27 April–8 May 2020; Volume 11413, pp. 118–134. [Google Scholar]
- Yu, J.; Li, J.; Yu, Z.; Huang, Q. Multimodal transformer with multi-view visual representation for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4467–4480. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, X.; Luo, Y.; Ji, J.; Zhou, Y.; Wu, Y.; Huang, F.; Ji, R. Rstnet: Captioning with adaptive attention on visual and non-visual words. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15465–15474. [Google Scholar]
- Fang, Z.; Wang, J.; Hu, X.; Liang, L.; Gan, Z.; Wang, L.; Yang, Y.; Liu, Z. Injecting semantic concepts into end-to-end image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18009–18019. [Google Scholar]
- Wang, Y.; Xu, J.; Sun, Y. End-to-end transformer based model for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 2585–2594. [Google Scholar]
- Tewel, Y.; Shalev, Y.; Schwartz, I.; Wolf, L. Zerocap: Zero-shot image-to-text generation for visual-semantic arithmetic. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17918–17928. [Google Scholar]
- Su, Y.; Lan, T.; Liu, Y.; Liu, F.; Yogatama, D.; Wang, Y.; Kong, L.; Collier, N. Language models can see: Plugging visual controls in text generation. arXiv 2022, arXiv:2205.02655. [Google Scholar]
- Nukrai, D.; Mokady, R.; Globerson, A. Text-Only Training for Image Captioning using Noise-Injected CLIP. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Online, 7–11 December 2022; pp. 4055–4063. [Google Scholar]
- Li, W.; Zhu, L.; Wen, L.; Yang, Y. Decap: Decoding clip latents for zero-shot captioning via text-only training. arXiv 2023, arXiv:2303.03032. [Google Scholar]
- Gu, S.; Clark, C.; Kembhavi, A. I Can’t Believe There’s No Images! Learning Visual Tasks Using only Language Supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 2672–2683. [Google Scholar]
- Zeng, Z.; Xie, Y.; Zhang, H.; Chen, C.; Wang, Z.; Chen, B. MeaCap: Memory-Augmented Zero-shot Image Captioning. arXiv 2024, arXiv:2403.03715. [Google Scholar]
- Das, S.; Jain, L.; Das, A. Deep learning for military image captioning. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; IEEE: Piscataway Township, NJ, USA, 2018; pp. 2165–2171. [Google Scholar]
- Ghataoura, D.; Ogbonnaya, S. Application of image captioning and retrieval to support military decision making. In Proceedings of the 2021 International Conference on Military Communication and Information Systems (ICMCIS), Hague, The Netherlands, 4–5 May 2021; IEEE: Piscataway Township, NJ, USA, 2021; pp. 1–8. [Google Scholar]
- Lee, C.E.; Baek, J.; Son, J.; Ha, Y.G. Deep AI military staff: Cooperative battlefield situation awareness for commander’s decision making. J. Supercomput. 2023, 79, 6040–6069. [Google Scholar] [CrossRef]
- Pan, J.Y.; Yang, H.J.; Duygulu, P.; Faloutsos, C. Automatic image captioning. In Proceedings of the 2004 IEEE International Conference on Multimedia and Expo (ICME)(IEEE Cat. No. 04TH8763), Taipei, Taiwan, 27–30 June 2004; IEEE: Piscataway Township, NJ, USA, 2004; Volume 3, pp. 1987–1990. [Google Scholar]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every picture tells a story: Generating sentences from images. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part IV 11. Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–29. [Google Scholar]
- Ordonez, V.; Kulkarni, G.; Berg, T. Im2text: Describing images using 1 million captioned photographs. Adv. Neural Inf. Process. Syst. 2011, 24, 1143–1151. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. Adv. Neural Inf. Process. Syst. 2013, 26, 2121–2129. [Google Scholar]
- Karpathy, A.; Joulin, A.; Li, F. Deep fragment embeddings for bidirectional image sentence mapping. In Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2, Valencia, Spain, 2–4 May 2014; pp. 1889–1897. [Google Scholar]
- Yao, B.; Yang, X.; Lin, L.; Lee, M.; Zhu, S.C. I2T: Image parsing to text description. Proc. IEEE 2010, 98, 1485–1508. [Google Scholar] [CrossRef]
- Aker, A.; Gaizauskas, R. Generating image descriptions using dependency relational patterns. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 1250–1258. [Google Scholar]
- Yang, Y.; Teo, C.; Daume III, H.; Aloimonos, Y. Corpusguided sentence generation of natural images. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, Scotland, UK, 27–31 July 2011; pp. 444–454. [Google Scholar]
- Li, S.; Kulkarni, G.; Berg, T.; Berg, A.; Choi, Y. Composing simple image descriptions using webscale ngrams. In Proceedings of the 5th Conference on Computational Natural Language Learning, Portland, OR, USA, 23–24 June 2011; pp. 220–228. [Google Scholar]
- Gupta, A.; Verma, Y.; Jawahar, C. Choosing linguistics over vision to describe images. In Proceedings of the 26th AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 606–612. [Google Scholar]
- Mitchell, M.; Grishman, R. Midge: Generating image descriptions from computer vision detections. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; pp. 747–756. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. BabyTalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef]
- Kuznetsova, P.; Ordonez, V.; Berg, T.; Choi, Y. TreeTalk: Composition and compression of trees for image descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 351–362. [Google Scholar] [CrossRef]
- Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Huang, Z.; Yuille, A. Deep captioning with multimodal recurrent neural networks (m-rnn). arXiv 2014, arXiv:1412.6632. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning PMLR, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Wang, Z.; Yu, J.; Yu, A.W.; Dai, Z.; Tsvetkov, Y.; Cao, Y. Simvlm: Simple visual language model pretraining with weak supervision. arXiv 2021, arXiv:2108.10904. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Mokady, R.; Hertz, A.; Bermano, A.H. Clipcap: Clip prefix for image captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar]
- Fei, J.; Wang, T.; Zhang, J.; He, Z.; Wang, C.; Zheng, F. Transferable decoding with visual entities for zero-shot image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3136–3146. [Google Scholar]
- Ramos, R.; Martins, B.; Elliott, D.; Kementchedjhieva, Y. Smallcap: Lightweight image captioning prompted with retrieval augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2840–2849. [Google Scholar]
- Li, G.; Ye, H.; Qi, Y.; Wang, S.; Qing, L.; Huang, Q.; Yang, M.H. Learning Hierarchical Modular Networks for Video Captioning. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1049–1064. [Google Scholar] [CrossRef]
- Tian, M.; Li, G.; Qi, Y.; Wang, S.; Sheng, Q.Z.; Huang, Q. Rethink video retrieval representation for video captioning. Pattern Recognit. 2024, 156, 110744. [Google Scholar] [CrossRef]
- Hodosh, M.; Young, P.; Hockenmaier, J. Framing image description as a ranking task: Data, models and evaluation metrics. J. Artif. Intell. Res. 2013, 47, 853–899. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Shingare, S.; Haribhakta, Y.; Rajmane, D. Video Captioning using Deep Learning and NLP to Detect Suspicious Activities. In Proceedings of the 2022 International Conference on Signal and Information Processing (IConSIP), Pune, India, 26–27 August 2022; IEEE: Piscataway Township, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Brochier, R.; Guille, A.; Velcin, J. Global vectors for node representations. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13 May 2019; pp. 2587–2593. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Meng, F.j.; Li, Y.q.; Shao, F.m.; Yuan, G.h.; Dai, J.y. Visual-simulation region proposal and generative adversarial network based ground military target recognition. Def. Technol. 2022, 18, 2083–2096. [Google Scholar] [CrossRef]
- Ma, J.; Yakimenko, O.A. The concept of sUAS/DL-based system for detecting and classifying abandoned small firearms. Def. Technol. 2023, 30, 23–31. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, C.q.; Zhou, Y.j. Camouflaged people detection based on a semi-supervised search identification network. Def. Technol. 2023, 21, 176–183. [Google Scholar] [CrossRef]
- Liu, M.; Di, X. Extraordinary MHNet: Military High-level camouflage object detection Network and Dataset. Neurocomputing 2023, 549, 126466. [Google Scholar] [CrossRef]
- Nakamura, T. Military Aircraft Detection Dataset. 2021. Available online: https://www.kaggle.com/datasets/a2015003713/militaryaircraftdetectiondataset/code (accessed on 19 May 2024).
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.; Gao, J. Unified vision-language pre-training for image captioning and vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13041–13049. [Google Scholar]
- Zhou, C.; Zhong, F.; Öztireli, C. CLIP-PAE: Projection-Augmentation Embedding to Extract Relevant Features for a Disentangled, Interpretable and Controllable Text-Guided Face Manipulation. In Proceedings of the ACM SIGGRAPH 2023 Conference Proceedings, Los Angeles, CA, USA, 6–10 August 2023; pp. 1–9. [Google Scholar]
- Wu, F.; Ma, Y.; Jin, H.; Jing, X.Y.; Jiang, G.P. MFECLIP: CLIP with Mapping-Fusion Embedding for Text-Guided Image Editing. IEEE Signal Process. Lett. 2023, 31, 116–120. [Google Scholar] [CrossRef]
- Wolff, M.; Brendel, W.; Wolff, S. The Independent Compositional Subspace Hypothesis for the Structure of CLIP’s Last Layer. In Proceedings of the ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models, Kigali, Rwanda, 4 May 2023. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches out, Barcelona, Spain, July 25–26 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Prague, Czech Republic, 23 June 2005; pp. 65–72. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part V 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 382–398. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 397–406. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Categories | Number of Captions | Task | Open Access |
|---|---|---|---|---|
| GMTD | Tank, transporter, and rocket launcher | 11,036 images, 20,132 targets | Object detection for ground equipment | - |
| SFD | Pistol and rifle | 3140 images, 3140 labels | Object detection for guns | - |
| COD10K+ | Person | 2592 images, 2592 labels | Object detection for camouflage | - |
| MHCD | Person, airplane, vehicle, and warship | 3000 images, 3000 labels | Object detection for camouflage | Yes |
| MADD | Aircraft | 14,088 images, 14,088 labels | Object detection for aircrafts | Yes |
| MOCO (ours) | Person, tank, rocket, fighter jet, helicopter, AV, UGV, boat, and defensive structure | 7449 images, 37,245 captions | Image captioning for real combat | Yes |
| Text Prompts | Main Elements | ||
|---|---|---|---|
| Military Personnel | Combat Equipment | Battlefield Environment | |
| Soldiers crossed the frontline under heavy fire. | Soldier | Fire | |
| Snipers positioned on rooftops monitored enemy movements. | Sniper | Rooftop | |
| Unmanned aerial drones conducted reconnaissance missions. | Unmanned aerial drones | ||
| UGVs transported supplies to forward positions. | UGV | ||
| Fighter jets engaged in combat maneuvers above the foggy mountains. | Fighter jet | Foggy mountains | |
| The jet conducted a reconnaissance mission under the cover of darkness. | Jet | Darkness | |
| The tank engaged enemy forces in the open plains. | Tank | Open plains | |
| The military vehicle traversed the muddy battlefield under a heavy downpour. | Military vehicle | Heavy downpour | |
| The soldiers that operated the anti-aircraft unit targeted enemy aircraft in the sky. | Soldier | Anti-aircraft unit | Sky |
| Armored vehicles deployed smoke screens to conceal troop movements. | Armored vehicle | Smoke screens | |
| The howitzer launched rounds into the night sky. | Howitzer | Night sky | |
| Cannons positioned on the coastal cliffs targeted ships at sea. | Cannon | Sea | |
| The combat engineers are setting up fences and trenches. | Combat engineer | Trench | |
| Engineering vehicles repaired damaged roadway. | Engineering vehicle | Roadway |
| Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | SPICE |
|---|---|---|---|---|---|---|---|
| ClipCap | 0.441 | 0.275 | 0.173 | 0.111 | 0.158 | 0.337 | 0.102 |
| CapDec | 0.363 | 0.184 | 0.086 | 0.041 | 0.111 | 0.264 | 0.059 |
| MAE-MilitICGSO | 0.494 | 0.322 | 0.212 | 0.141 | 0.163 | 0.353 | 0.113 |
| MAE-MilitICPCA | 0.460 | 0.290 | 0.181 | 0.112 | 0.158 | 0.336 | 0.102 |
| Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | SPICE |
|---|---|---|---|---|---|---|---|
| ClipCap | 0.547 | 0.443 | 0.369 | 0.271 | 0.230 | 0.576 | 0.437 |
| CapDec | 0.542 | 0.445 | 0.370 | 0.265 | 0.241 | 0.586 | 0.430 |
| MAE-MilitICGSO | 0.553 | 0.452 | 0.379 | 0.282 | 0.236 | 0.583 | 0.449 |
| MAE-MilitICPCA | 0.555 | 0.448 | 0.371 | 0.269 | 0.241 | 0.578 | 0.459 |
| Methods | Mapping | Augmentation | Residual | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGE-L | SPICE |
|---|---|---|---|---|---|---|---|---|---|---|
| MAE-MilitICGSO | ✓ | ✗ | ✗ | 0.335 | 0.183 | 0.102 | 0.057 | 0.115 | 0.279 | 0.068 |
| ✗ | ✓ | ✗ | 0.440 | 0.276 | 0.174 | 0.112 | 0.160 | 0.331 | 0.106 | |
| ✓ | ✓ | ✗ | 0.475 | 0.303 | 0.193 | 0.124 | 0.156 | 0.346 | 0.107 | |
| ✓ | ✓ | ✓ | 0.494 | 0.322 | 0.212 | 0.141 | 0.163 | 0.353 | 0.113 | |
| MAE-MilitICPCA | ✓ | ✗ | ✗ | 0.396 | 0.220 | 0.123 | 0.073 | 0.127 | 0.299 | 0.076 |
| ✗ | ✓ | ✗ | 0.440 | 0.276 | 0.174 | 0.112 | 0.160 | 0.331 | 0.106 | |
| ✓ | ✓ | ✗ | 0.453 | 0.278 | 0.172 | 0.105 | 0.150 | 0.325 | 0.100 | |
| ✓ | ✓ | ✓ | 0.460 | 0.290 | 0.181 | 0.112 | 0.158 | 0.336 | 0.102 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, L.; Song, C.; Gan, X.; Xu, K.; Xie, Y. Military Image Captioning for Low-Altitude UAV or UGV Perspectives. Drones 2024, 8, 421. https://doi.org/10.3390/drones8090421
Pan L, Song C, Gan X, Xu K, Xie Y. Military Image Captioning for Low-Altitude UAV or UGV Perspectives. Drones. 2024; 8(9):421. https://doi.org/10.3390/drones8090421
Chicago/Turabian StylePan, Lizhi, Chengtian Song, Xiaozheng Gan, Keyu Xu, and Yue Xie. 2024. "Military Image Captioning for Low-Altitude UAV or UGV Perspectives" Drones 8, no. 9: 421. https://doi.org/10.3390/drones8090421
APA StylePan, L., Song, C., Gan, X., Xu, K., & Xie, Y. (2024). Military Image Captioning for Low-Altitude UAV or UGV Perspectives. Drones, 8(9), 421. https://doi.org/10.3390/drones8090421