
A Lightweight Real-Time Infrared Object Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles

Abstract
:1. Introduction
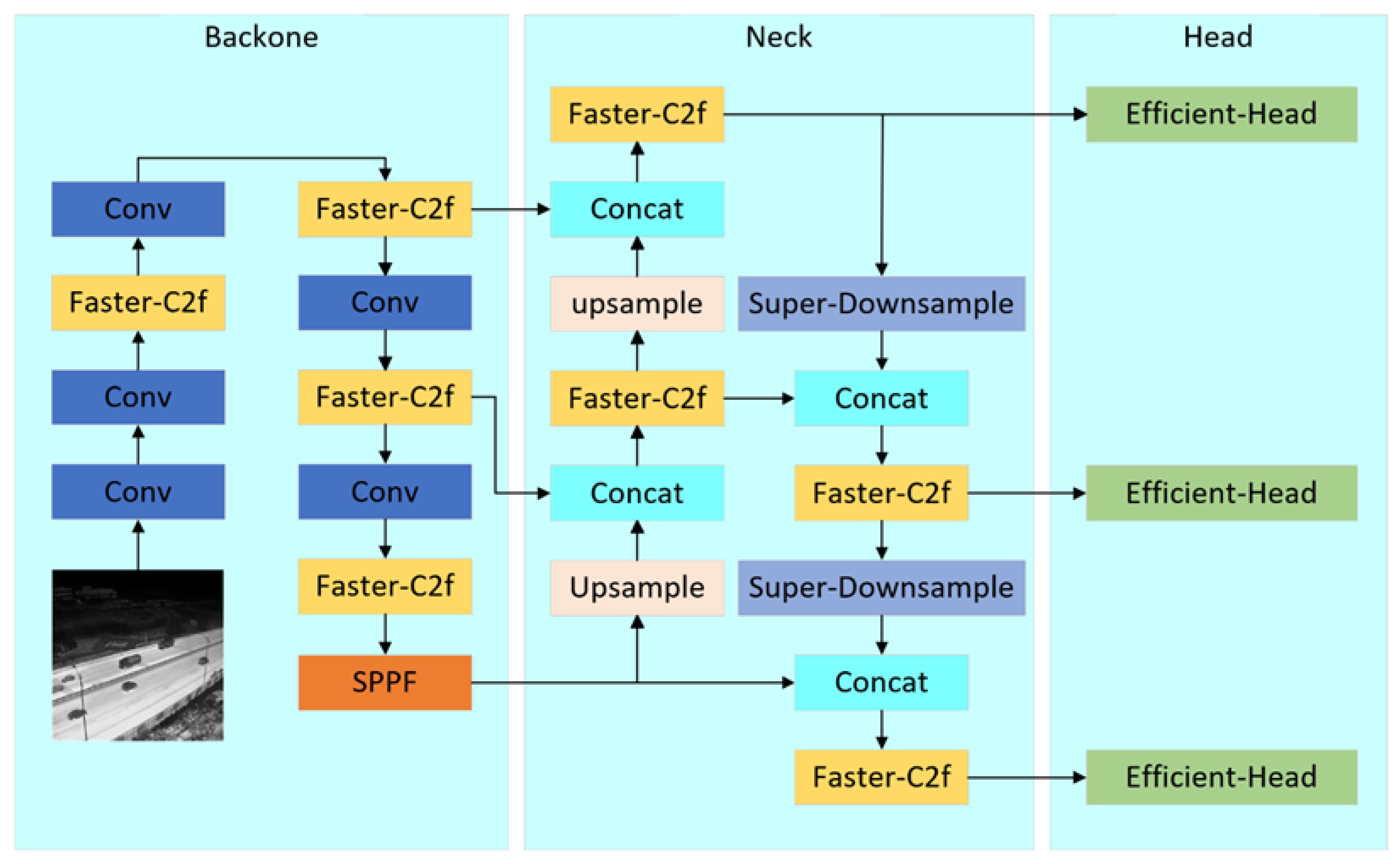
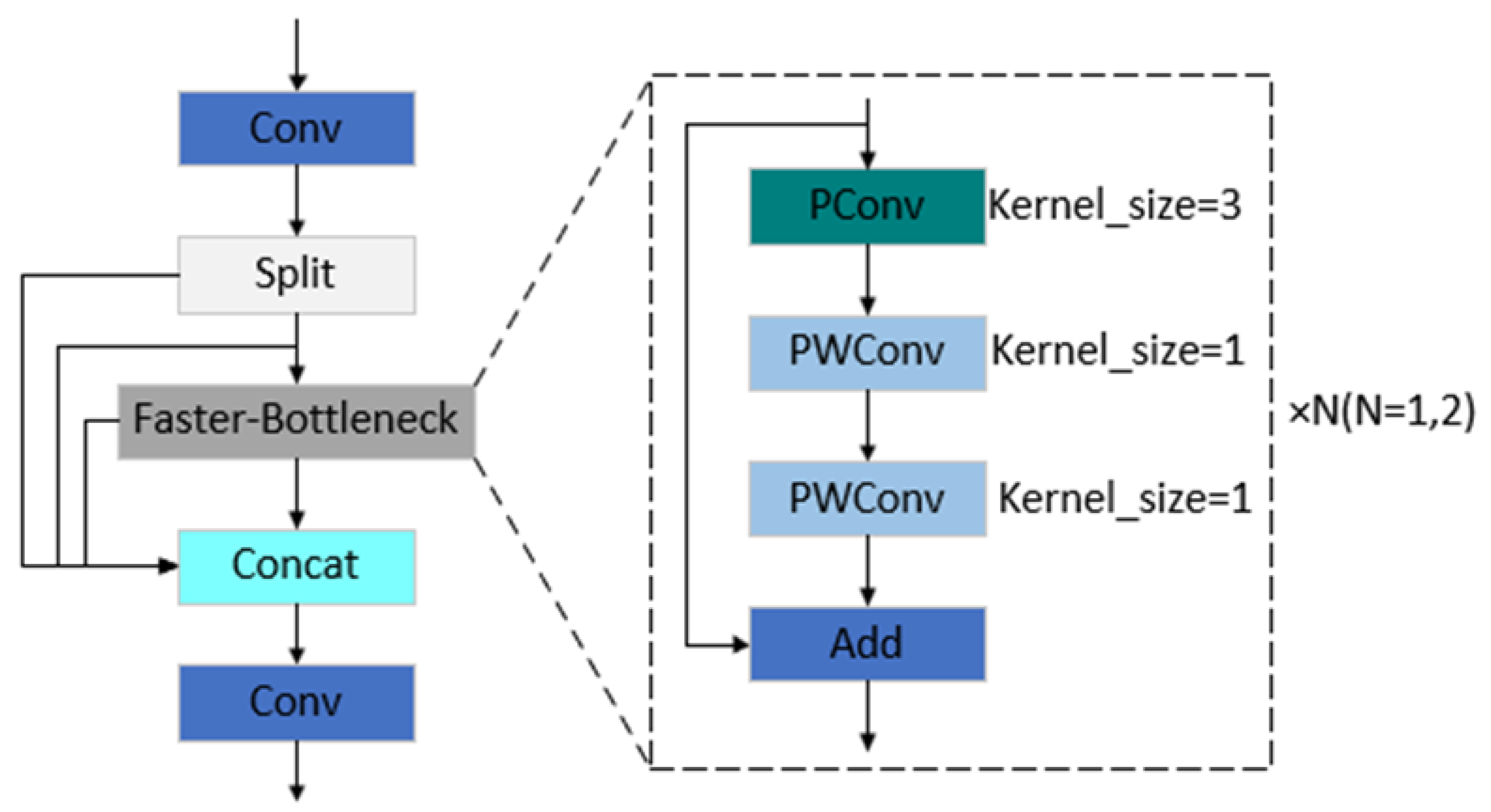
- This paper introduces a new lightweight module, Faster-C2f, which mainly uses Partial Convolution and Pointwise Convolution to improve the Bottleneck structure in C2f. By significantly decreasing both the model’s parameters and computational complexity, this method enhances detection performance.
- A new downsampling module, Super-Downsample, is utilized in the neck network. This module combines the advantages of ordinary convolution and max pooling, retaining multi-scale features to the maximum extent during the feature fusion stage.
- The decoupled detection head is redesigned using highly efficient Group Convolution instead of ordinary convolution, increasing the model’s detection speed. Given the prevalence of easy samples and the relative sparsity of difficult samples in object detection datasets, we introduce EMASlideLoss to replace the original BCELoss, improving the ability of the model to concentrate on difficult samples and smoothing the loss function.
- Considering the limited computational power of edge devices like UAVs, this research introduces a lightweight network for infrared target detection, LRI-YOLO. Compared to other state-of-the-art methods, LRI-YOLO demonstrates excellent performance on the HIT-UAV dataset.
2. Related Work
3. Materials and Methods
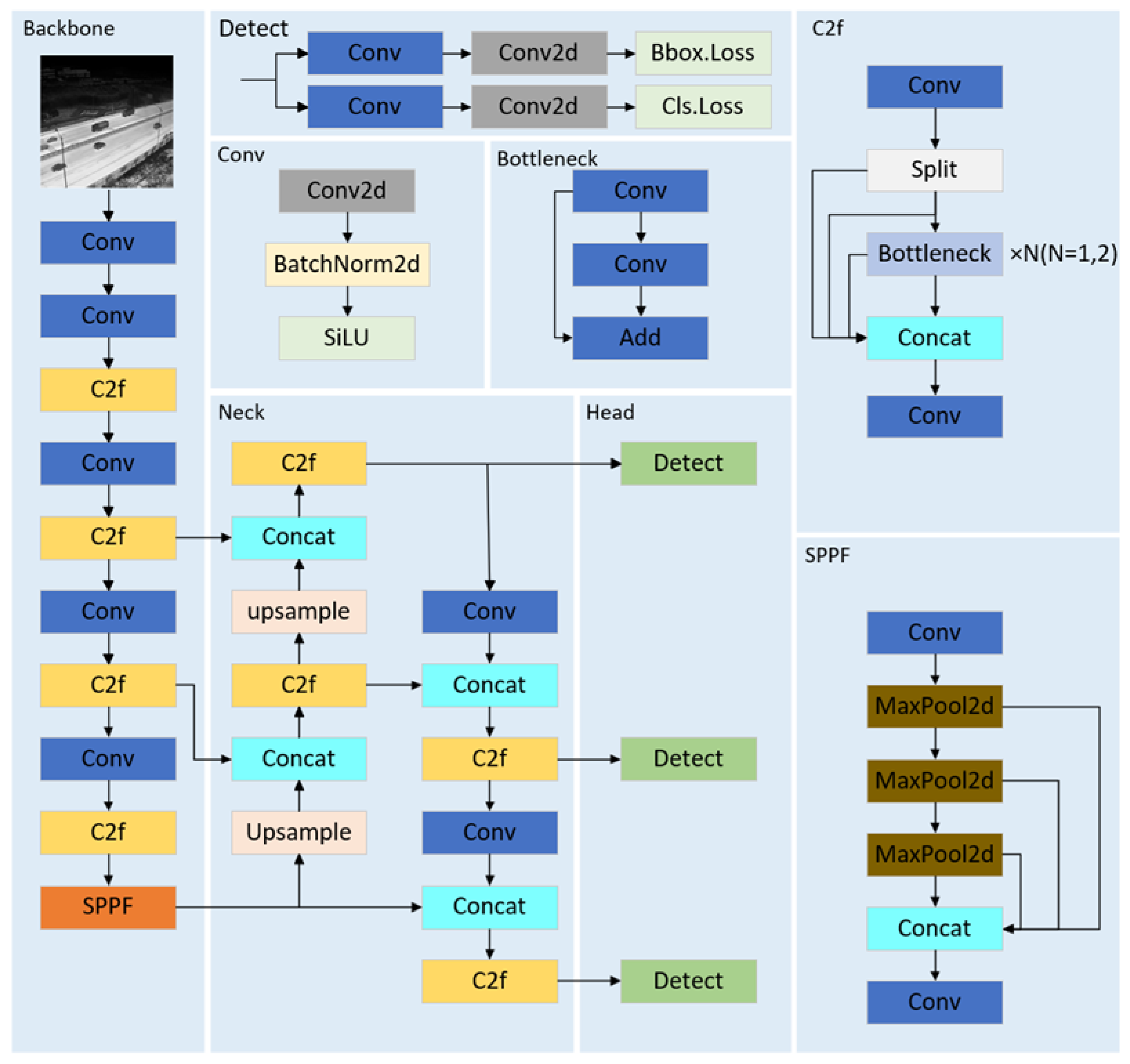
3.1. YOLOv8
3.2. LRI-YOLO
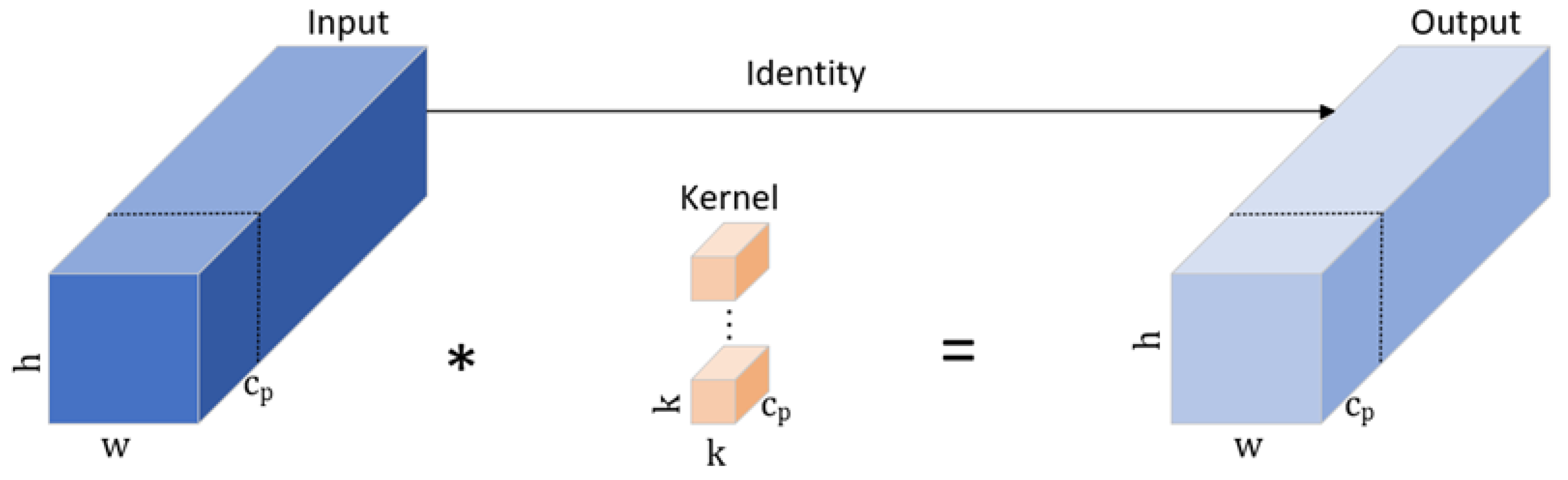
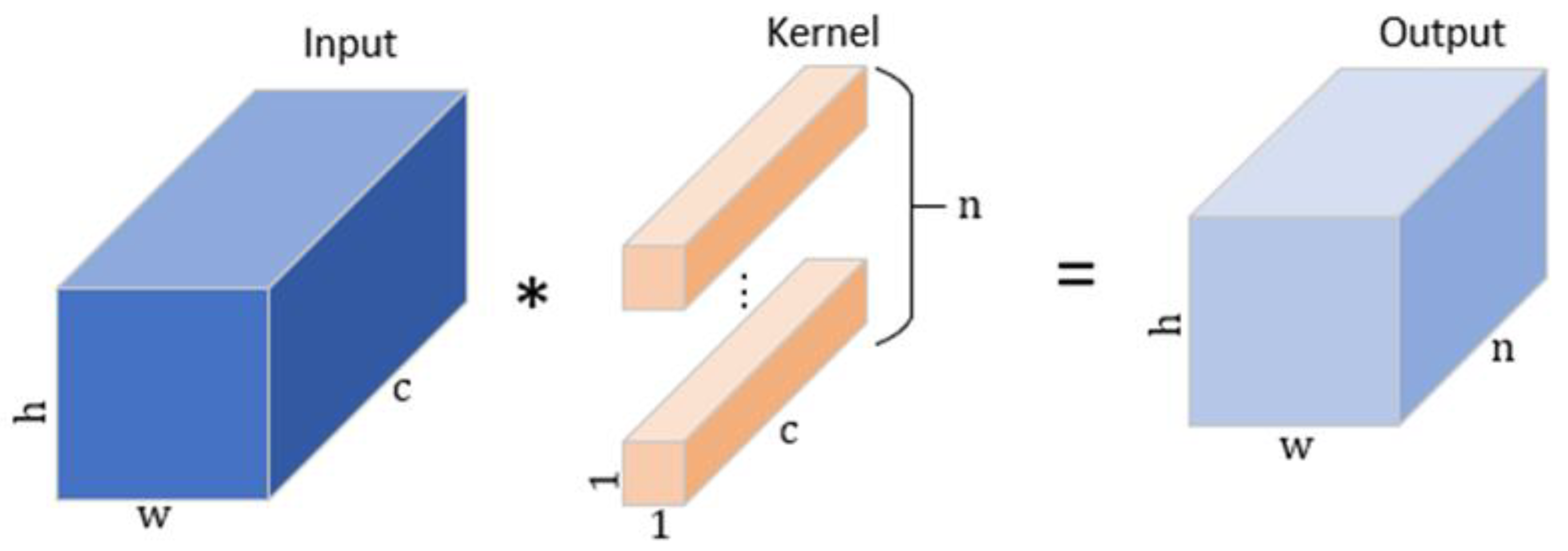
3.2.1. The Faster-C2f Module Based on Partial Convolution
3.2.2. The Super-Downsample Module Based on Max Pooling and Convolution
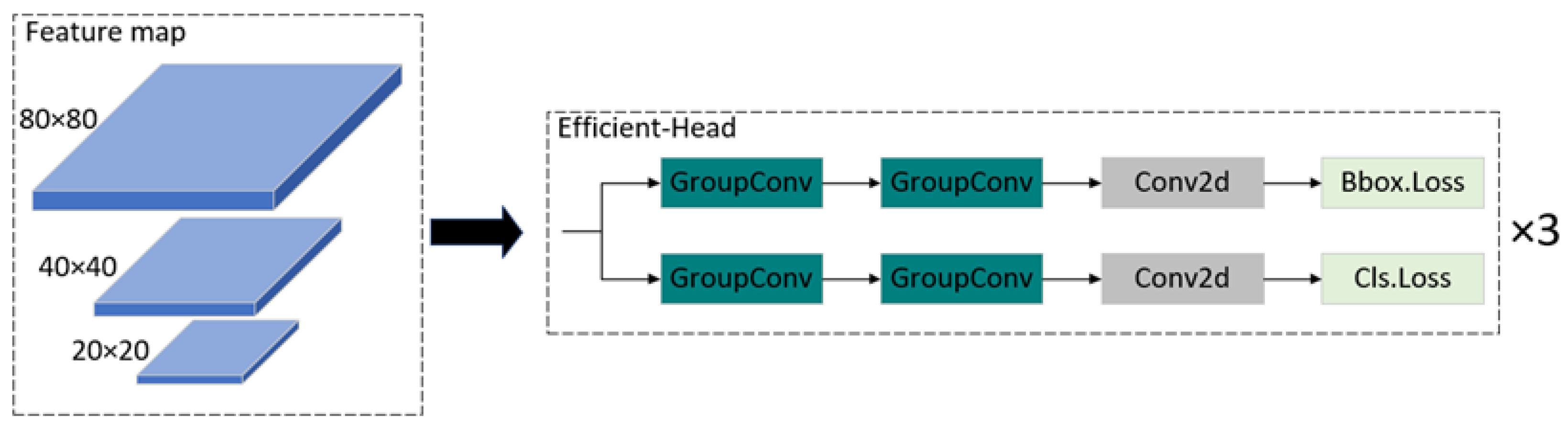
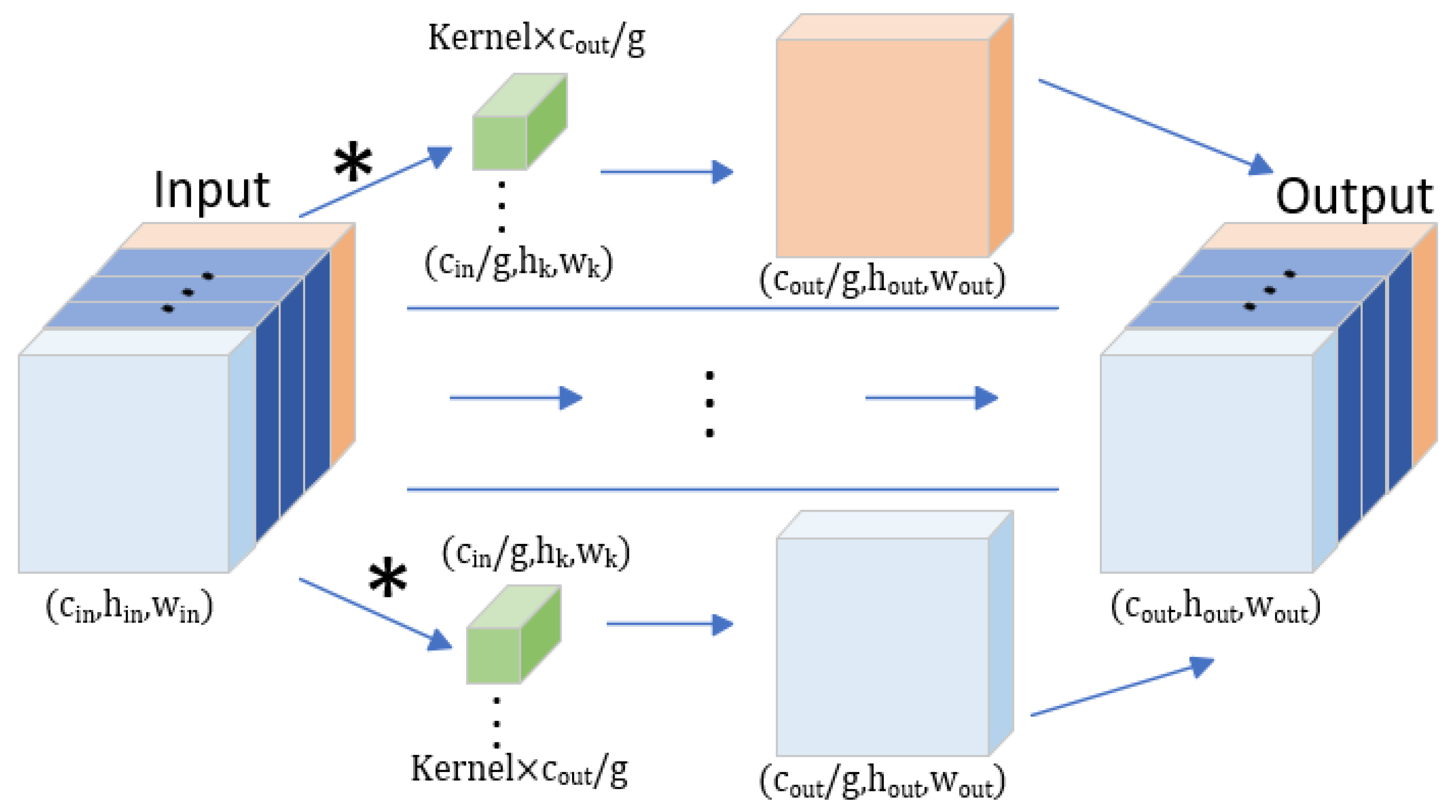
3.2.3. The Efficient-Head Module Based on Group Convolution
3.2.4. The EMASlideLoss Based on SlideLoss and Exponential Moving Average Concept
3.3. Experimental Dataset
3.4. Evaluation Indicators
4. Experimental Results
4.1. Experimental Platform and Parameter Settings
4.2. The Efficient-Head Hyperparameter Experiment
4.3. Ablation Experiments
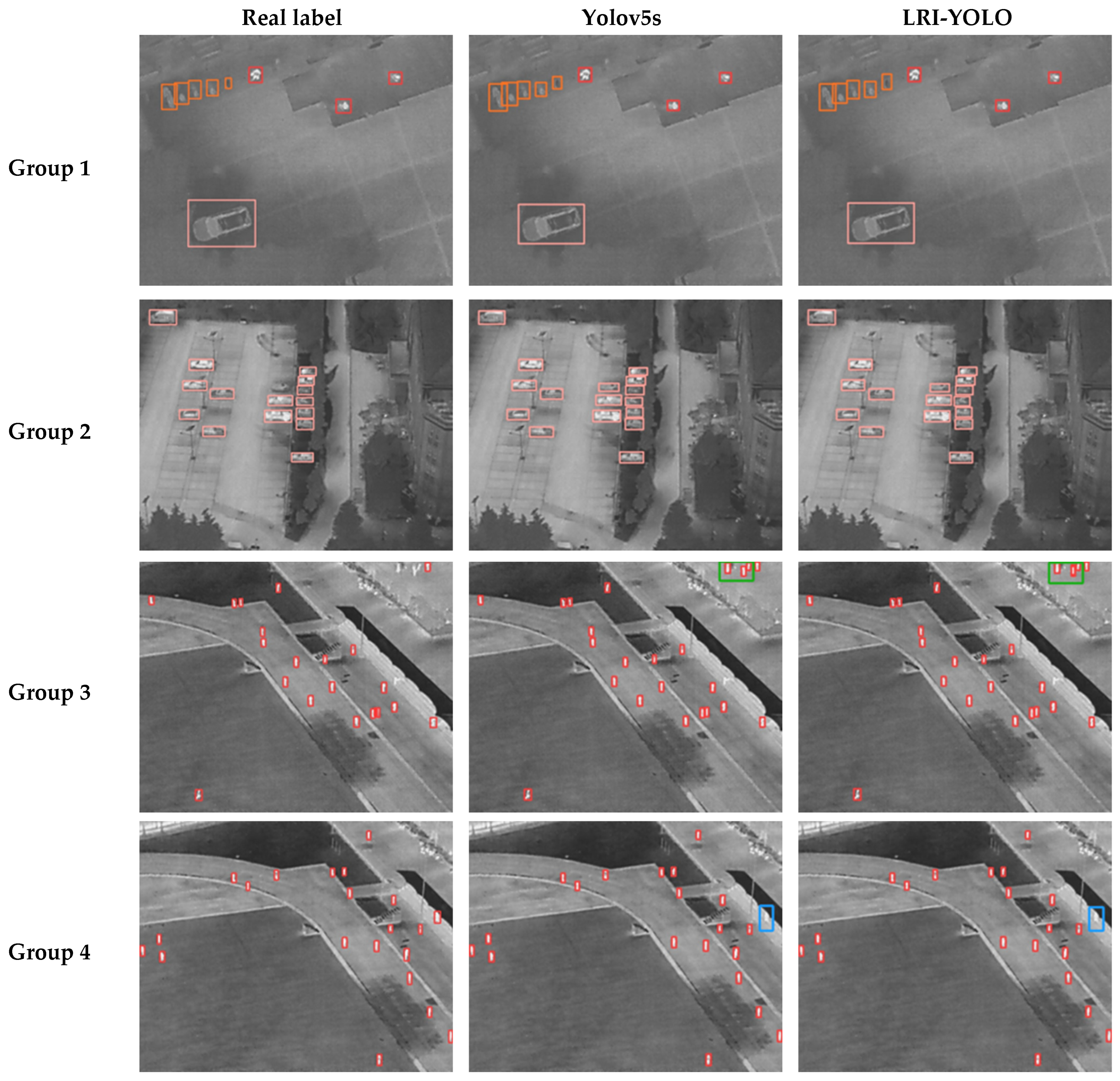
4.4. Contrast Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep Learning for Unmanned Aerial Vehicle-Based Object Detection and Tracking: A Survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 91–124. [Google Scholar] [CrossRef]
- Yue, M.; Zhang, L.; Huang, J.; Zhang, H. Lightweight and Efficient Tiny-Object Detection Based on Improved YOLOv8n for UAV Aerial Images. Drones 2024, 8, 276. [Google Scholar] [CrossRef]
- Cao, S.; Deng, J.; Luo, J.; Li, Z.; Hu, J.; Peng, Z. Local Convergence Index-Based Infrared Small Target Detection against Complex Scenes. Remote Sens. 2023, 15, 1464. [Google Scholar] [CrossRef]
- Fan, X.; Li, H.; Chen, Y.; Dong, D. UAV Swarm Search Path Planning Method Based on Probability of Containment. Drones 2024, 8, 132. [Google Scholar] [CrossRef]
- Oh, D.; Han, J. Smart Search System of Autonomous Flight UAVs for Disaster Rescue. Sensors 2021, 21, 6810. [Google Scholar] [CrossRef]
- Qiu, Z.; Bai, H.; Chen, T. Special Vehicle Detection from UAV Perspective via YOLO-GNS Based Deep Learning Network. Drones 2023, 7, 117. [Google Scholar] [CrossRef]
- Niu, C.; Song, Y.; Zhao, X. SE-Lightweight YOLO: Higher Accuracy in YOLO Detection for Vehicle Inspection. Appl. Sci. 2023, 13, 13052. [Google Scholar] [CrossRef]
- Shokouhifar, M.; Hasanvand, M.; Moharamkhani, E.; Werner, F. Ensemble Heuristic–Metaheuristic Feature Fusion Learning for Heart Disease Diagnosis Using Tabular Data. Algorithms 2024, 17, 34. [Google Scholar] [CrossRef]
- Patel, T.; Guo, B.H.W.; van der Walt, J.D.; Zou, Y. Effective Motion Sensors and Deep Learning Techniques for Unmanned Ground Vehicle (UGV)-Based Automated Pavement Layer Change Detection in Road Construction. Buildings 2023, 13, 5. [Google Scholar] [CrossRef]
- Seth, A.; James, A.; Kuantama, E.; Mukhopadhyay, S.; Han, R. Drone High-Rise Aerial Delivery with Vertical Grid Screening. Drones 2023, 7, 300. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, F. Infrared and Visible Image Fusion Based on Non-subsampled Shearlet Transform, Regional Energy, and Co-occurrence Filtering. Electron. Lett. 2020, 56, 761–764. [Google Scholar] [CrossRef]
- Fan, Y.; Qiu, Q.; Hou, S.; Li, Y.; Xie, J.; Qin, M.; Chu, F. Application of Improved YOLOv5 in Aerial Photographing Infrared Vehicle Detection. Electronics 2022, 11, 2344. [Google Scholar] [CrossRef]
- Yang, L.; Xie, T.; Liu, M.; Zhang, M.; Qi, S.; Yang, J. Infrared Small-Target Detection under a Complex Background Based on a Local Gradient Contrast Method. Int. J. Appl. Math. Comput. Sci. 2023, 33, 7–70. [Google Scholar] [CrossRef]
- Pan, L.; Liu, T.; Cheng, J.; Cheng, B.; Cai, Y. AIMED-Net: An Enhancing Infrared Small Target Detection Net in UAVs with Multi-Layer Feature Enhancement for Edge Computing. Remote Sens. 2024, 16, 1776. [Google Scholar] [CrossRef]
- Feng, H.; Mu, G.; Zhong, S.; Zhang, P.; Yuan, T. Benchmark Analysis of YOLO Performance on Edge Intelligence Devices. Cryptography 2022, 6, 16. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. ISBN 978-3-319-10601-4. [Google Scholar]
- Wang, Y.; Tian, Y.; Liu, J.; Xu, Y. Multi-Stage Multi-Scale Local Feature Fusion for Infrared Small Target Detection. Remote Sens. 2023, 15, 4506. [Google Scholar] [CrossRef]
- Chang, Y.; Li, D.; Gao, Y.; Su, Y.; Jia, X. An Improved YOLO Model for UAV Fuzzy Small Target Image Detection. Appl. Sci. 2023, 13, 5409. [Google Scholar] [CrossRef]
- Wu, A.; Deng, C. TIB: Detecting Unknown Objects via Two-Stream Information Bottleneck. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 611–625. [Google Scholar] [CrossRef]
- Wu, A.; Deng, C.; Liu, W. Unsupervised Out-of-Distribution Object Detection via PCA-Driven Dynamic Prototype Enhancement. IEEE Trans. Image Process. 2024, 33, 2431–2446. [Google Scholar] [CrossRef]
- Wu, A.; Deng, C. Single-Domain Generalized Object Detection in Urban Scene via Cyclic-Disentangled Self-Distillation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 837–846. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. arXiv 2014, arXiv:1311.2524. pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2015; Volume 28. [Google Scholar]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. Uav-Yolo: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Hong, D.; Ghamisi, P.; Li, W.; Tao, R. MsRi-CCF: Multi-Scale and Rotation-Insensitive Convolutional Channel Features for Geospatial Object Detection. Remote Sens. 2018, 10, 1990. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2023, arXiv:2207.02696. pp. 7464–7475. [Google Scholar]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2024, arXiv:2305.09972. [Google Scholar]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. YOLO-Based UAV Technology: A Review of the Research and Its Applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- Liang, S.; Wu, H.; Zhen, L.; Hua, Q.; Garg, S.; Kaddoum, G.; Hassan, M.M.; Yu, K. Edge YOLO: Real-Time Intelligent Object Detection System Based on Edge-Cloud Cooperation in Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25345–25360. [Google Scholar] [CrossRef]
- Wu, H.; Zhu, Y.; Li, S. CDYL for Infrared and Visible Light Image Dense Small Object Detection. Sci. Rep. 2024, 14, 3510. [Google Scholar] [CrossRef]
- Jiang, C.; Ren, H.; Ye, X.; Zhu, J.; Zeng, H.; Nan, Y.; Sun, M.; Ren, X.; Huo, H. Object Detection from UAV Thermal Infrared Images and Videos Using YOLO Models. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102912. [Google Scholar] [CrossRef]
- Zhao, X.; Xia, Y.; Zhang, W.; Zheng, C.; Zhang, Z. YOLO-ViT-Based Method for Unmanned Aerial Vehicle Infrared Vehicle Target Detection. Remote Sens. 2023, 15, 3778. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, W.; Zhang, H.; Zheng, C.; Ma, J.; Zhang, Z. ITD-YOLOv8: An Infrared Target Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones 2024, 8, 161. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. arXiv 2018, arXiv:1803.01534. pp. 8759–8768. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates: New York, NY, USA, 2012; Volume 25. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. arXiv 2023, arXiv:2303.03667. pp. 12021–12031. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. FractalNet: Ultra-Deep Neural Networks without Residuals. arXiv 2016, arXiv:1605.07648. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss V2: Learning Reliable Localization Quality Estimation for Dense Object Detection. arXiv 2021, arXiv:2011.12885. pp. 11632–11641. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. YOLO-FaceV2: A Scale and Occlusion Aware Face Detector. Pattern Recognit. 2024, 155, 110714. [Google Scholar] [CrossRef]
- Suo, J.; Wang, T.; Zhang, X.; Chen, H.; Zhou, W.; Shi, W. HIT-UAV: A High-Altitude Infrared Thermal Dataset for Unmanned Aerial Vehicle-Based Object Detection. Sci. Data 2023, 10, 227. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2010, arXiv:2010.04159. [Google Scholar] [CrossRef]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised Pre-Training for Object Detection with Transformers. arXiv 2021, arXiv:2011.09094. pp. 1601–1610. [Google Scholar]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic DETR: End-to-End Object Detection with Dynamic Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 2988–2997. [Google Scholar]
- Lv, W.; Zhao, Y.; Xu, S.; Wei, J.; Wang, G.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. DETRs Beat YOLOs on Real-Time Object Detection. arXiv 2023, arXiv:2304.08069. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Small | Medium | Large | |
|---|---|---|---|
| HIT-UAV | 17,118 | 7249 | 268 |
| Training set | 12,045 | 5205 | 268 |
| Validation set | 1742 | 665 | 46 |
| Test set | 3331 | 1379 | 70 |
| Names | Configurations |
|---|---|
| GPU | NVIDIA RTX 4090 |
| CPU | Intel(R) Xeon(R) Platinum 8352V |
| GPU memory size | 24 G |
| Operating system | Linux |
| Python version | Python3.10 |
| Deep learning framework | Pytorch2.1.2 |
| Parameters | Value |
|---|---|
| Optimizer | SGD |
| Initial learning rate | 0.01% |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Data augmentation | Mosaic |
| Batch size | 32 |
| Image size | 640 × 640 |
| Number of epochs | 300 |
| Model | P (%) | R (%) | Parameters (M) | FLOPs (G) | mAP50 (%) | Speed on GPU (FPS) | Speed on CPU (FPS) |
|---|---|---|---|---|---|---|---|
| Yolov8n | 91 | 89.4 | 3 | 8.1 | 93.8 | 229 | 30 |
| Yolov8n+Efficient-Head (g = 2) | 90.9 | 87.7 | 2.3 | 5.3 | 93.3 | 271 | 38 |
| Yolov8n+Efficient-Head (g = 4) | 91.1 | 88.3 | 2.3 | 5.3 | 93.3 | 270 | 39 |
| Yolov8n+Efficient-Head (g = 8) | 91.3 | 88.1 | 2.4 | 5.4 | 93.4 | 271 | 40 |
| Yolov8n+Efficient-Head (g = 16) | 91.5 | 89.3 | 2.4 | 5.6 | 93.6 | 274 | 39 |
| Yolov8n+Efficient-Head (g = 32) | 91.9 | 88.6 | 2.5 | 6 | 93.7 | 262 | 39 |
| Yolov8n+Efficient-Head (g = 64) | 91.7 | 88.5 | 2.8 | 6.9 | 93.2 | 260 | 37 |
| Yolov8 | A | B | C | D | P (%) | R (%) | Parameters (M) | FLOPs (G) | mAP0.5 (%) | Speed on GPU (FPS) | Speed on CPU (FPS) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| √ | 91.0 | 89.4 | 3 | 8.1 | 93.8 | 229 | 30 | ||||
| √ | √ | 91.4 (+0.4) | 89.3 (−0.1) | 2.39 (−0.61) | 6.3 (−1.8) | 94.0 (+0.2) | 232 (+3) | 37 (+7) | |||
| √ | √ | 91.5 (+0.5) | 89.3 (−0.1) | 2.4 (−0.6) | 5.6 (−2.5) | 93.6 (−0.2) | 274 (+45) | 39 (+9) | |||
| √ | √ | 91.2 (+0.2) | 89.4 (−0.0) | 2.9 (−0.1) | 8.0 (−0.1) | 94.0 (+0.2) | 235 (+6) | 33 (+3) | |||
| √ | √ | 91.9 (+0.9) | 88.7 (−0.7) | 3 (−0.0) | 8.1 (−0.0) | 93.8 (+0.0) | 229 (+0) | 30 (+0) | |||
| √ | √ | √ | 90.5 (−0.5) | 87.3 (−2.1) | 1.7 (−1.3) | 3.9 (−4.2) | 93.4 (−0.4) | 238 (+9) | 34 (+4) | ||
| √ | √ | √ | √ | 91.4 (+0.4) | 89.1 (−0.3) | 1.6 (−1.4) | 3.8 (−4.3) | 93.9 (+0.1) | 240 (+11) | 42 (+12) | |
| √ | √ | √ | √ | √ | 90.7 (−0.3) | 89.1 (−0.3) | 1.6 (−1.4) | 3.8 (−4.3) | 94.1 (+0.3) | 240 (+11) | 42 (+12) |
| Model | P (%) | R (%) | Parameters (M) | FLOPs (G) | mAP50 (%) | Speed on GPU (FPS) | Speed on CPU (FPS) |
|---|---|---|---|---|---|---|---|
| RTDETR-r18 | 89.4 | 88.8 | 19.9 | 56.9 | 93.1 | 64 | 8 |
| Yolov3-tiny | 86.8 | 80.4 | 12.1 | 18.9 | 87.6 | 300 | 32.8 |
| Yolov3 | 91.3 | 90.2 | 103.7 | 282.2 | 93.7 | 121.8 | 4.8 |
| Yolov5n | 91.4 | 88.7 | 2.5 | 7.1 | 93.7 | 234.3 | 37.3 |
| Yolov5s | 91.9 | 90.2 | 9.1 | 23.8 | 94.2 | 237.3 | 23.9 |
| Yolov5m | 91.0 | 91.0 | 25 | 64 | 94.1 | 187.7 | 12.4 |
| Yolov5l | 92.5 | 89.8 | 53.1 | 134.7 | 93.5 | 157.4 | 8 |
| Yolov6 | 90.3 | 87.4 | 4.2 | 11.8 | 92.6 | 285 | 38 |
| Yolov8n | 91.0 | 89.4 | 3 | 8.1 | 93.8 | 229 | 30 |
| Yolov8s | 91.4 | 89.9 | 11.1 | 28.4 | 94.1 | 228 | 22.1 |
| Yolov8m | 92.3 | 88.9 | 25.8 | 78.7 | 93.8 | 202.3 | 12.6 |
| Ours | 90.7 | 89.1 | 1.6 | 3.8 | 94.1 | 240 | 42 |
| Model | P (%) | R (%) | Parameters (M) | FLOPs (G) | mAP50 (%) | Speed on GPU (FPS) | Speed on CPU (FPS) |
|---|---|---|---|---|---|---|---|
| RT-DETR-r18 | 85.1 | 82.9 | 19.9 | 56.9 | 87.5 | 63 | 7 |
| Yolov3-tiny | 83.7 | 78.6 | 12.1 | 18.9 | 83.7 | 280 | 17 |
| Yolov5n | 84.5 | 80.0 | 2.5 | 7.1 | 86.4 | 213 | 27 |
| Yolov5s | 86.2 | 84.7 | 9.1 | 23.8 | 89.8 | 211 | 15 |
| Yolov6 | 82.7 | 75.9 | 4.2 | 11.8 | 82.2 | 262 | 35 |
| Yolov7-tiny | 85.0 | 80.2 | 6.02 | 13.2 | 86.2 | 203 | 26 |
| Yolov8n | 83.9 | 80.6 | 3 | 8.1 | 86.6 | 220 | 28 |
| Yolov8s | 85.9 | 85.5 | 11.1 | 28.4 | 90.0 | 210 | 14 |
| Ours | 83.6 | 81.0 | 1.6 | 3.8 | 86.7 | 231 | 38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, B.; Zhang, Y.; Ma, S. A Lightweight Real-Time Infrared Object Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones 2024, 8, 479. https://doi.org/10.3390/drones8090479
Ding B, Zhang Y, Ma S. A Lightweight Real-Time Infrared Object Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles. Drones. 2024; 8(9):479. https://doi.org/10.3390/drones8090479
Chicago/Turabian StyleDing, Baolong, Yihong Zhang, and Shuai Ma. 2024. "A Lightweight Real-Time Infrared Object Detection Model Based on YOLOv8 for Unmanned Aerial Vehicles" Drones 8, no. 9: 479. https://doi.org/10.3390/drones8090479