
Attention-Enhanced Contrastive BiLSTM for UAV Intention Recognition Under Information Uncertainty


Abstract
1. Introduction
- This paper provides a systematic summary of intention recognition research in combat scenarios. The methods are categorized into three distinct classes, and a comparative analysis of their respective advantages and disadvantages is conducted;
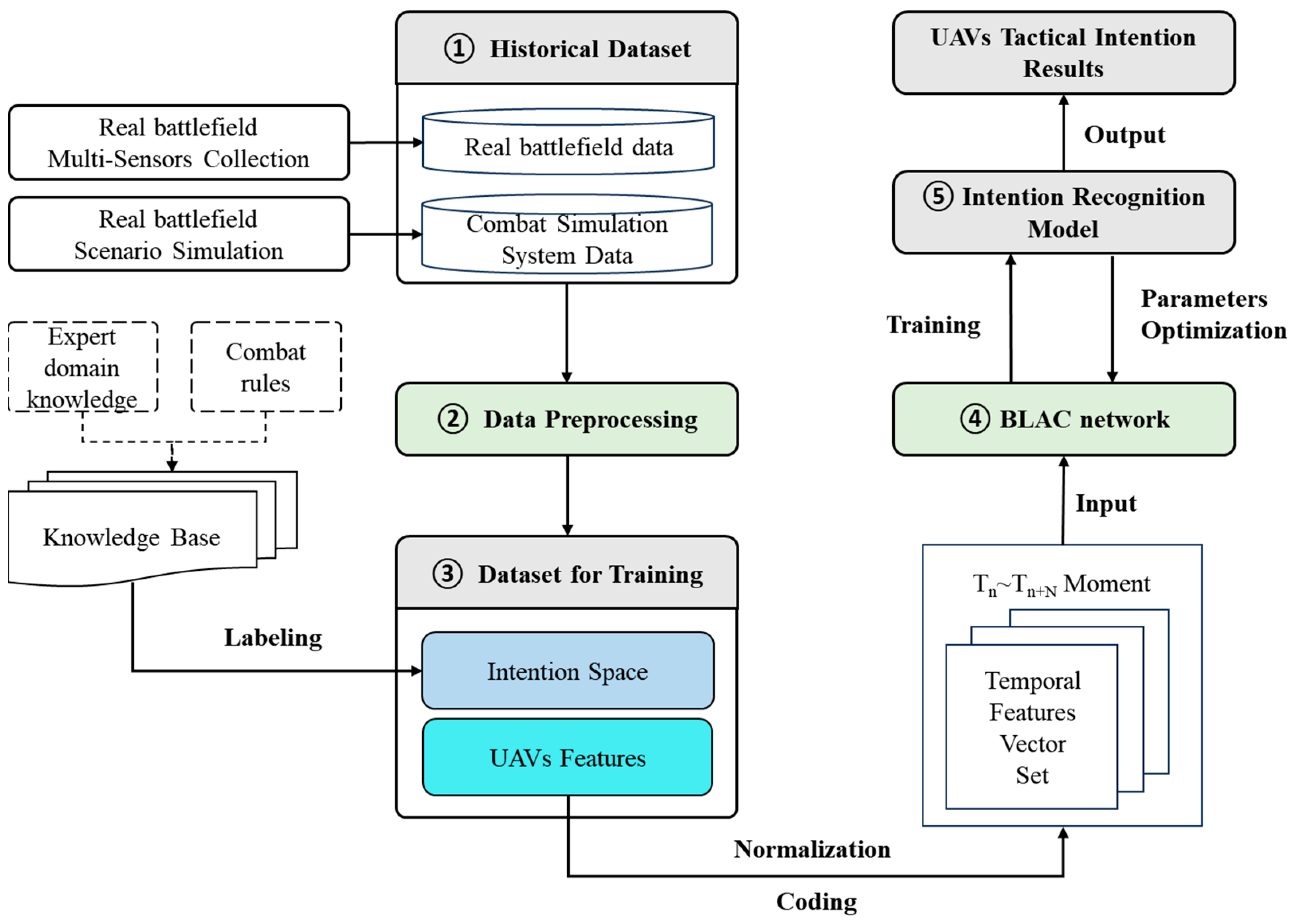
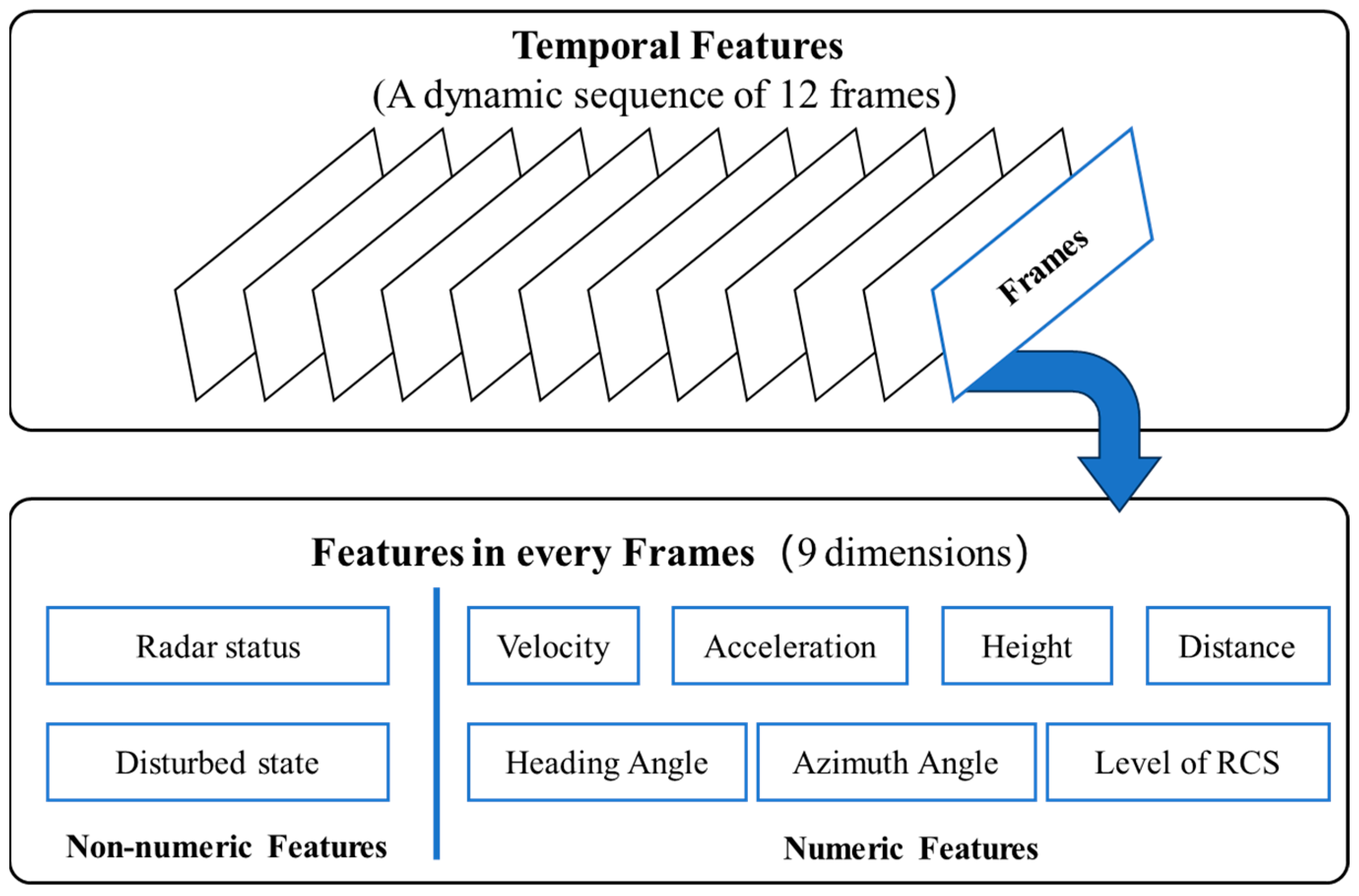
- The problem of UAV intention recognition in air combat is formally defined. A basic intention space and a feature set for intention recognition are constructed. A hierarchical strategy is employed to select a 9-dimensional target feature set. To capture the dynamic and temporal attributes of the target, data from 12 consecutive time steps are collected for feature extraction. The target features are normalized and uniformly encoded, while the decision-maker’s cognitive experience is encapsulated as intention labels;
- A novel data patching method is proposed to address uncertain information in air combat. The feature set is divided into numerical and non-numerical types. For numerical features, a cubic spline interpolation method is applied, while close filling is used for non-numerical features.
- An LSTM network is designed to implicitly map the intention feature set to the intention space. On the basis of LSTM, we add the bidirectional mechanism to integrate historical and future information, enabling robust temporal analysis. This approach captures time-dependent relationships and enhances the model’s capacity 82 to learn complex temporal patterns;
- A cross-attention mechanism is innovatively integrated into the model to emphasize the importance of data at different time steps. This mechanism comprises the following two components:
- Temporal attention mechanism: focuses on key temporal actions;
- Feature attention mechanism: evaluates the importance of different feature categories, filtering out the most influential features;
- Contrastive learning is introduced to improve feature discrimination. By minimizing intra-class distances and maximizing inter-class distances, recognition accuracy is improved under uncertainty.
2. Related Works
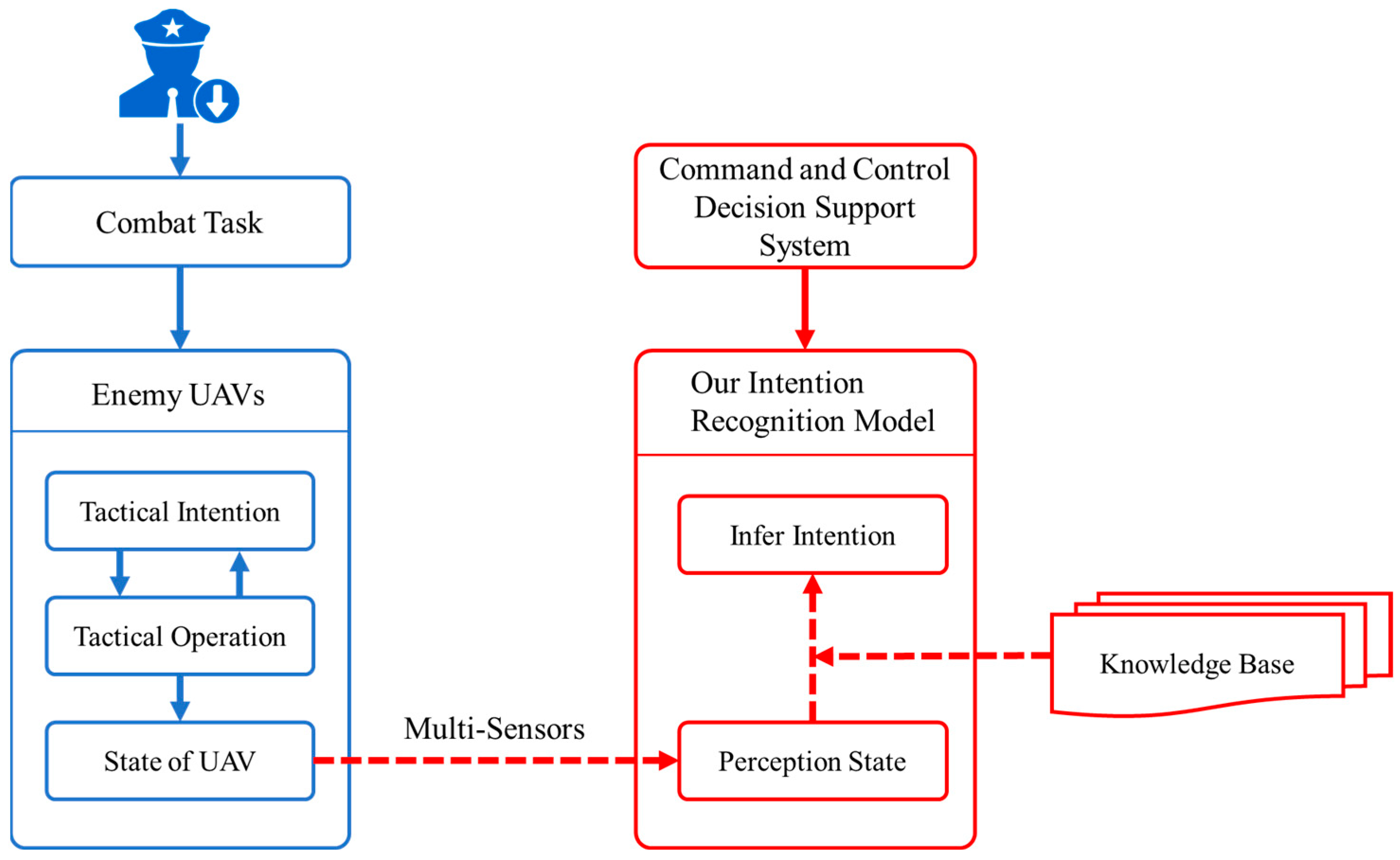
3. UAV Intention Recognition Problem Description
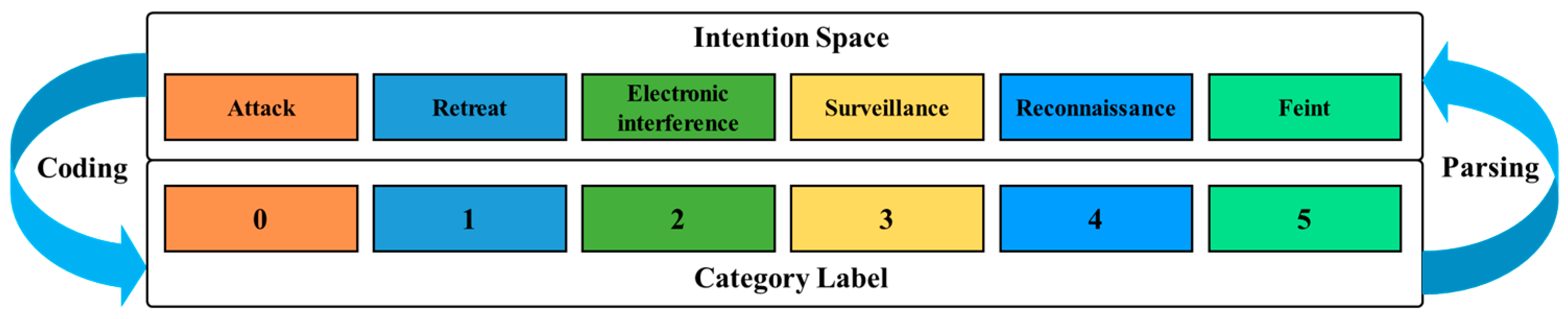
3.1. Intention Space
3.2. Target Features
4. Model Description
4.1. Data Patching
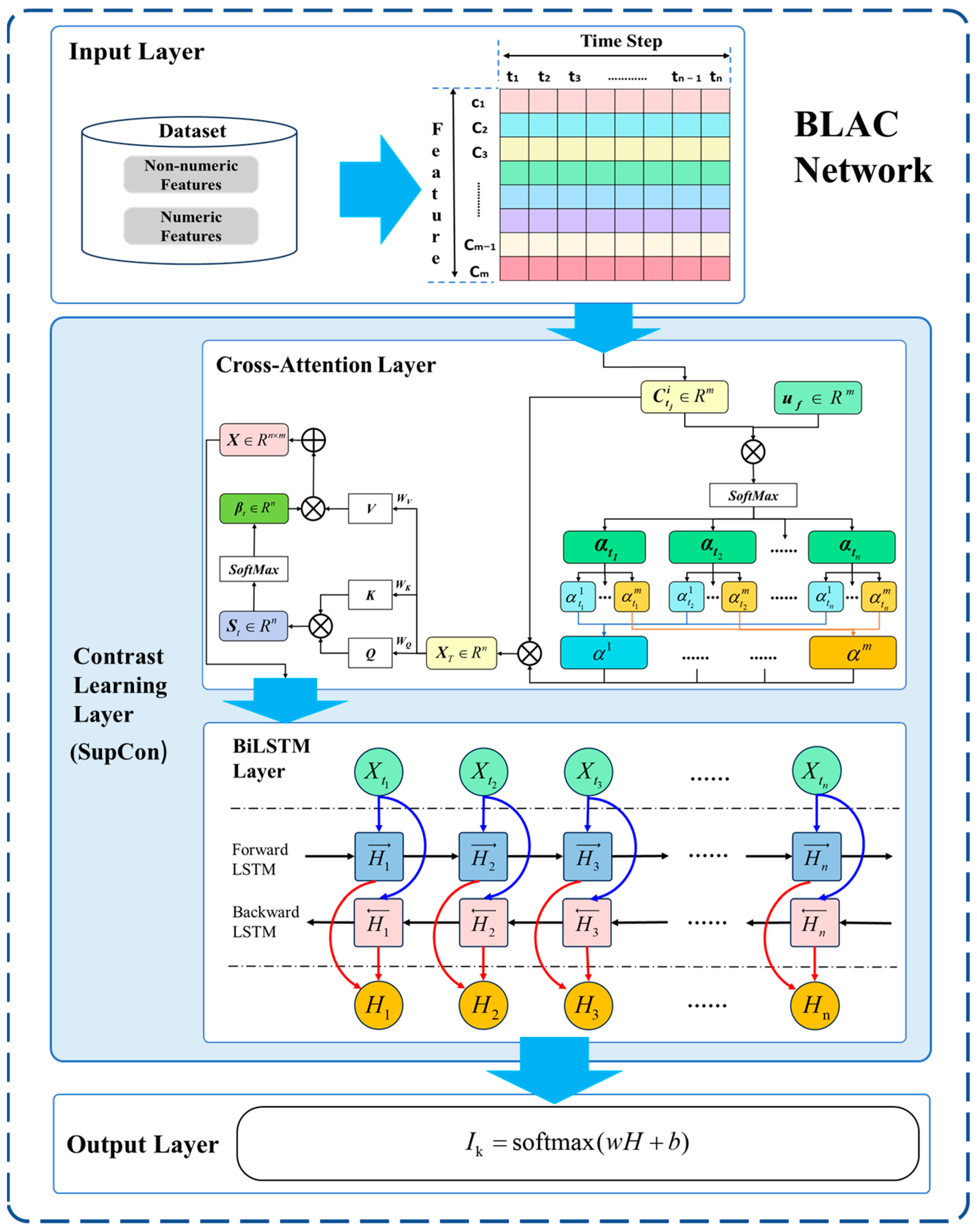
4.2. BLAC Network
4.2.1. Input Layer
4.2.2. Cross-Attention Layer
4.2.3. BiLSTM Layer
4.2.4. Contrast Learning Layer
4.2.5. Output Layer
5. Experimental Analysis
5.1. Experimental Data and Environment
5.2. Evaluation Metric
- 1
- Accuracy, which represents the proportion of samples correctly predicted by the model out of the total number of samples, as follows:
- 2
- Precision, which represents the proportion of samples that are actually positive among all the samples predicted as positive by the model, as follows:
- 3
- Recall, which represents the proportion of actual positive samples that are correctly predicted as positive by the model, as follows:
- 4
- F1 score, which represents the harmonic mean of precision and recall, serving as a comprehensive metric that balances both measures. It is particularly important in scenarios with imbalanced class distributions. The F1 score is calculated as follows:
- 5
- Loss—the cross-entropy loss quantifies the discrepancy between the predicted probability distribution and the true label distribution, and is formulated as follows:
5.3. Parameter Tuning
5.4. Results and Analysis
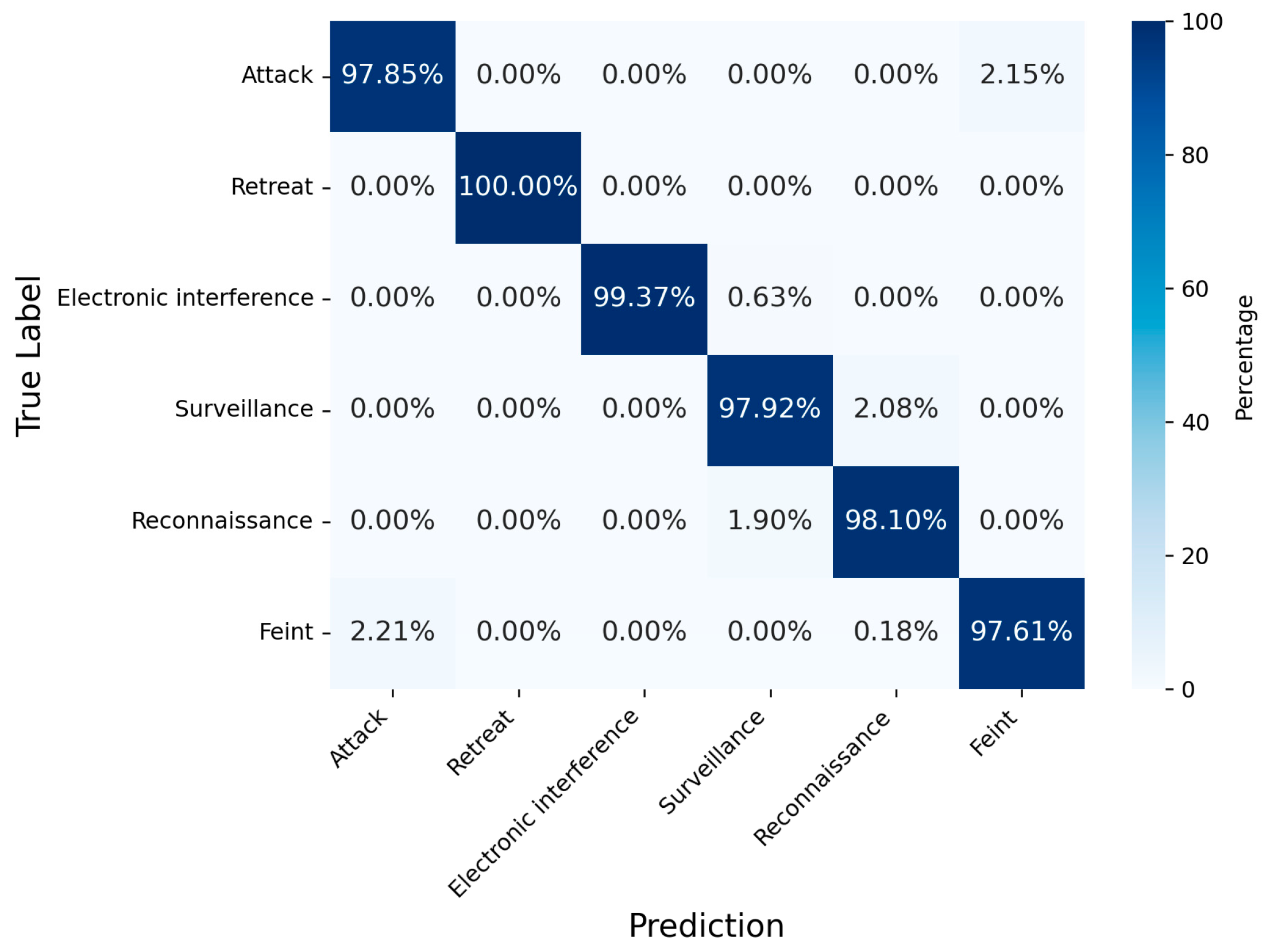
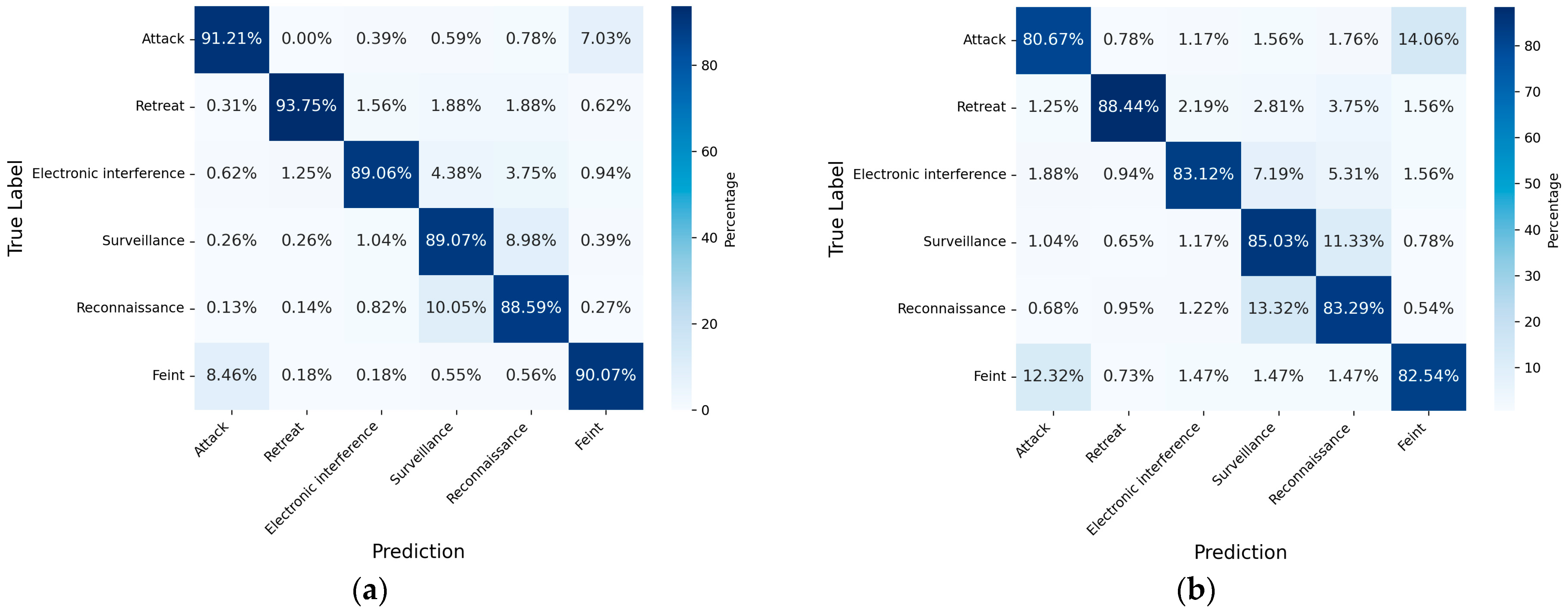
5.4.1. Intention Recognition Result Analysis of BLAC
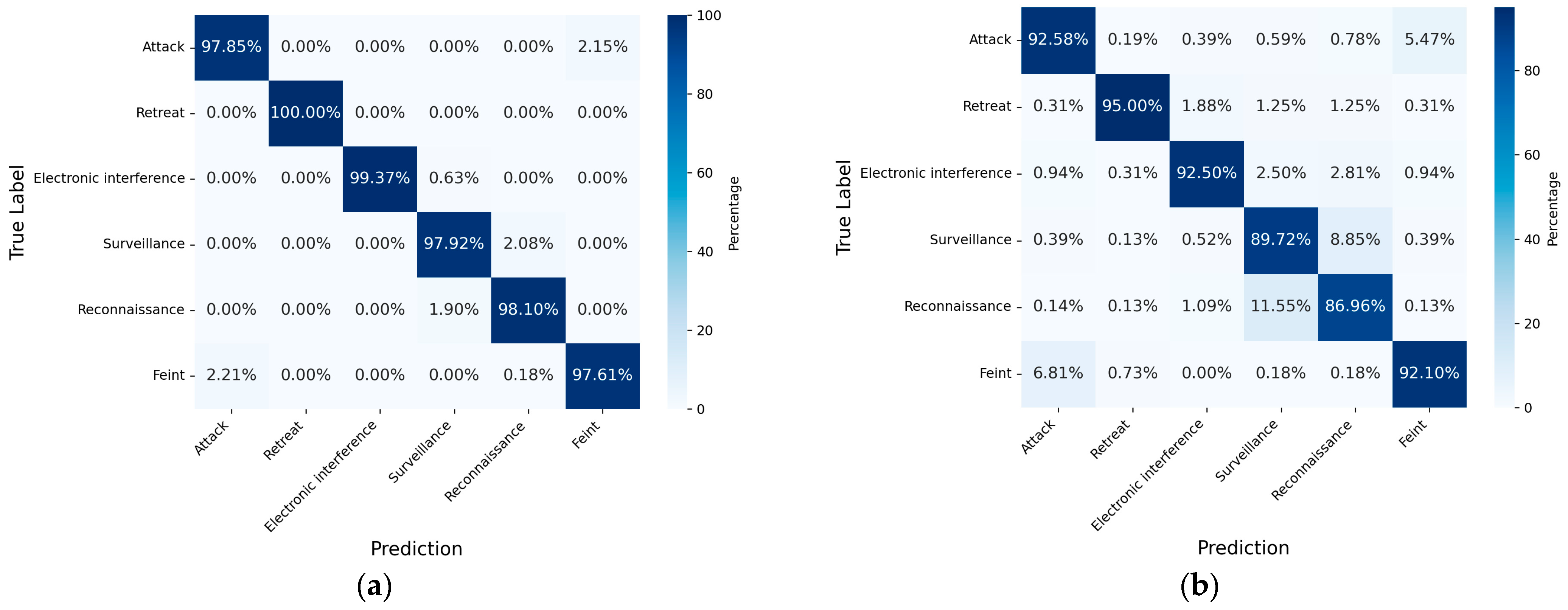
5.4.2. Comparative Analysis of Intention Recognition Methods
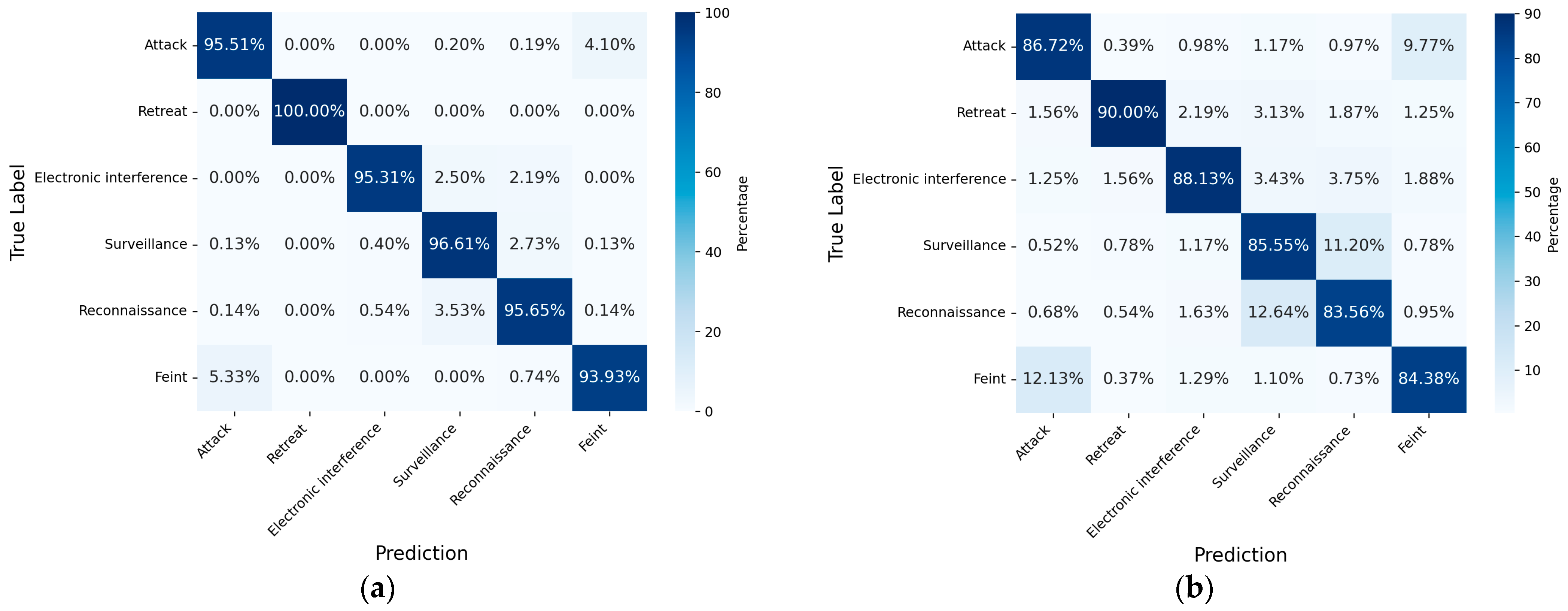
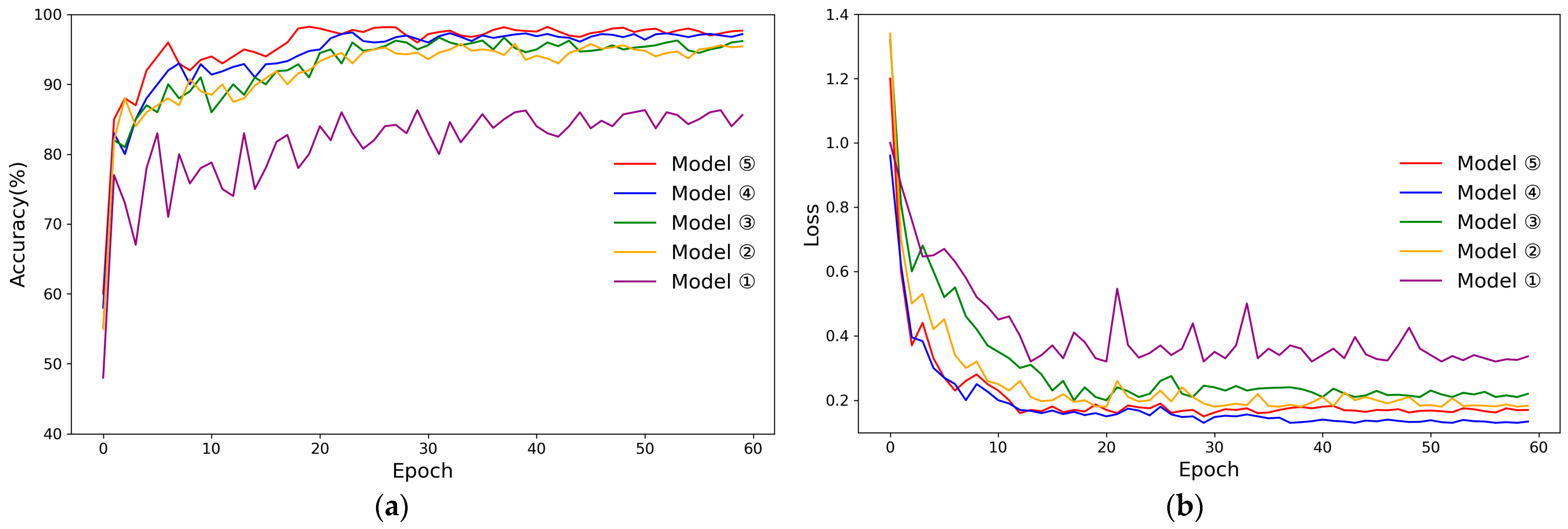
5.4.3. Ablation Experiment
6. Conclusions
Author Contributions
Funding
Data Availability Statement
DURC Statement
Conflicts of Interest
Abbreviations
| UAV | Unmanned aerial vehicle |
| BiGRU | Bidirectional gated recurrent unit |
| LSTM | Long short-term memory networks |
| TCN | Temporal convolutional network |
| PCLSTM | Panoramic convolutional long short-term memory networks |
| BiLSTM | Bidirectional long short-term memory networks |
References
- Zhang, C.; Yan, Z.; Cai, Y.; Guo, J. A Review of Air Target Operational Intention Recognition Research. Mod. Def. Technol. 2024, 52, 1–15. [Google Scholar]
- Yin, J.; Guo, X. Aero space situation evolving and predicting methods. In Proceedings of the 19th CCSSTA 2018, College Park, MD, USA, 10–14 August 2018; pp. 303–306. [Google Scholar]
- He, S.; Qian, J. Application research of expert system in data fusion technology. Fire Control Radar Technol. 2003, 32, 67–74+80. [Google Scholar]
- Azarewicz, J.; Fala, G.; Heithecker, C. Template-based multi-agent plan recognition for tactical situation assessment. In Proceedings of the Fifth Conference on Artificial Intelligence Applications, Miami, FL, USA, 6–10 March 1989; pp. 247–248. [Google Scholar]
- Floyd, M.W.; Karneeb, J.; Aha, D.W. Case-based team recognition using learned opponent models. In Proceedings of the Case-Based Reasoning Research and Development: 25th International Conference, ICCBR 2017; Trondheim, Norway, 26–28 June 2017, Springer: Berlin/Heidelberg, Germany, 2017; pp. 123–138. [Google Scholar]
- Huang, J.; Liu, W.; Zhao, Y. Intuitionistic cloud reasoning and its application in aerial target intention analysis. Oper. Res. Fuzziol. 2014, 4, 60–69. [Google Scholar] [CrossRef]
- Wang, X.; Xia, M.; Lin, Q.; Wang, Z.; Kong, F. Combat intent forecast based on DS evidence theory before contacting the enemy. Fire Control Command Control 2016, 41, 185–188. [Google Scholar]
- Zhang, S.; Cheng, Q.; Xie, Y.; Gang, Y. Intention recognition method under uncertain air situation information. J. Air Force Eng. Univ. (Nat. Sci.) 2008, 9, 50–53. [Google Scholar]
- Niu, X.; Zhao, H.; Zhang, Y. Warship intent recognition in naval battle field based on decision tree. Mil. Ind. Autom. 2010, 29, 44–46+53. [Google Scholar]
- Zhang, Y.; Deng, X.; Li, M.; Li, X.; Jiang, W. Air target intention recognition based on evidence network causal analysis. Acta Aeronaut. 2022, 43, 143–156. [Google Scholar]
- Cao, S.; Liu, Y.; Xue, S. Target tactical intention recognition method of improved high-dimensional data similarity. Sens. Microsyst. 2017, 36, 25–28. [Google Scholar]
- Dai, G.; Chen, W.; Liu, Z.; Bai, Z.; Chen, H. Aircraft tactical intention recognition method based on interval grey correlation degree. Pract. Underst. Math. 2014, 44, 198–207. [Google Scholar]
- Yang, C.; Song, S.; Fan, P. A target intention recognition method based on cost-sensitive and multi-class three-branch decision. J. Ordnance Equip. Eng. 2023, 44, 132–136. [Google Scholar]
- Li, J.; Zhang, P.; Hao, R. Unmanned Aerial Vehicle Tactical Intention Recognition Method Based on Dynamic Series Bayesian Network. In Proceedings of the 2023 IEEE International Conference on Unmanned Systems (ICUS), Hefei, China, 13–15 October 2023; pp. 427–432. [Google Scholar]
- Yang, R.; Yang, J.; Liu, X.; Zhang, Y.; Yan, Y. Air-ground cooperative operations intention recognition based on Dynamic Series Bayesian Network. Command Control Simul. 2024, 46, 75–85. [Google Scholar]
- Hu, Z.; Liu, H.; Gong, S.; Peng, C. Target intention recognition based on random forest. Mod. Electron. Tech. 2022, 45, 1–8. [Google Scholar]
- Zhang, P.; Zhang, Y.; Li, J.; Zhang, P.; Wei, X. Research on Air Target Intention Recognition Method Based on RL-LSTM. Fire Control Command Control 2024, 49, 75–81. [Google Scholar]
- Zhou, D.; Sun, G.; Zhang, Z.; Wu, L. On Deep Recurrent Reinforcement Learning for Active Visual Tracking of Space Noncooperative Objects. IEEE Robot. Autom. Lett. 2023, 8, 4418–4425. [Google Scholar] [CrossRef]
- Feng, Z.; Xiaofeng, H.; Lin, W. Simulation Method of Battlefields Situation Senior Comprehension Based on Deep Learning. Fire Control Command Control 2018, 43, 25–30. [Google Scholar]
- Wu, G.; Shi, H.; Qiu, C. Intention Recognition Method of Air Target Based on SSA-SVM. Ship Electron. Eng. 2022, 42, 29–34. [Google Scholar]
- Yang, S.; Zhang, D.; Xiong, W.; Ren, Z.; Tang, S. Decision-making method for air combat maneuver based on explainable reinforcement learning. Acta Aeronaut. Astronaut. Sin. 2024, 45, 257–274. [Google Scholar]
- Bai, L.; Xiao, Y.; Qi, J. Adversarial Intention Recognition Based on Reinforcement Learning. J. Command Control 2024, 10, 112–116. [Google Scholar]
- Zhou, T.; Chen, M.; Wang, Y.; He, J.; Yang, C. Information entropy-based intention prediction of aerial targets under uncertain and incomplete information. Entropy 2020, 22, 279. [Google Scholar] [CrossRef]
- Teng, F.; Liu, S.; Song, Y. BiLSTM-Attention: An Air Target Tactical Intention Recognition Model. Aero Weapon. 2021, 28, 24–32. [Google Scholar]
- Zhou, K.; Wei, R.; Xu, Z.; Zhang, Q.; Lu, H.; Zhang, G. An air combat decision learning system based on a brain-like cognitive mechanism. Cogn. Comput. 2020, 12, 128–139. [Google Scholar] [CrossRef]
- Zhu, B.; Fang, L.G.; Zhang, X.D. Intention Assessment to Aerial Target Based on Bayesian Network. J. Mod. Def. Technol. 2012, 40, 109–113. [Google Scholar]
- Xu, J.; Zhang, L.; Han, D. Air Target Intention recognition based on fuzzy inference. Command. Inf. Syst. Technol. 2020, 11, 44–48. [Google Scholar]
- Zhao, L.; Sun, P.; Zhang, Y. A fast aerial targets intention recognition method under imbalanced hard-sample. J. Air Force Eng. Univ. 2024, 25, 76–82. [Google Scholar]
- Liu, Z.; Chen, M.; Wu, Q.; Chen, S. Prediction of unmanned aerial vehicle target intention under incomplete information. Sci. Sin. Inf. 2020, 50, 704–717. [Google Scholar] [CrossRef]
- Xue, J.; Zhu, J.; Xiao, J.; Tong, S.; Huang, L. Panoramic convolutional long short-term memory networks for combat intension recognition of aerial targets. IEEE Access 2020, 8, 183312–183323. [Google Scholar] [CrossRef]
- Sun, L.; Yu, L.; Zou, D. Application of Dempster-Shafer Evidence Theory in Target Intention Prediction. Electron. Opt. Control. 2008, 15, 33–36. [Google Scholar]
- Zhang, Z.; Qu, Y.; Liu, H. Air target intention recognition based on further clustering and sample expansion. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 17–25 July 2018; pp. 3565–3569. [Google Scholar]
- Geng, Z.; Zhang, J. Research on Air Target Combat Intention Inference Based on Bayesian Networks. Mod. Def. Technol. 2008, 36, 40–44. [Google Scholar]
- Ou, W.; Liu, S.; He, X.; Guo, S. Tactical intention recognition algorithm based on encoded temporal features. Command Control Simul. 2016, 38, 36–41. [Google Scholar]
- Teng, F.; Song, Y.; Guo, X. Attention-TCN-BiGRU: An air target combat intention recognition model. Mathematics 2021, 9, 2412. [Google Scholar] [CrossRef]
- Ma, Y.; Sun, P.; Zhang, J..; Wang, P.; Yan, Y.; Zhao, L. Air group intention recognition method under imbalance samples. Syst. Eng. Electron. 2022, 44, 3747–3755. [Google Scholar]
- Wang, S.; Wang, G.; Fu, Q.; Song, Y.; Liu, J.; He, S. STABC-IR: An air target intention recognition method based on bidirectional gated recurrent unit and conditional random field with space-time attention mechanism. Chin. J. Aeronaut. 2023, 36, 316–334. [Google Scholar] [CrossRef]
- Zhang, H.; Yan, Y.; Li, S.; Hu, Y.; Liu, H. UAV behavior-intention estimation method based on 4-D flight-trajectory prediction. Sustainability 2021, 13, 12528. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Moradinasab, N.; Sharma, S.; Bar-Yoseph, R.; Radom-Aizik, S.; Bilchick, K.C.; Cooper, D.M.; Weltman, A.; Brown, D.E. Universal representation learning for multivariate time series using the instance-level and cluster-level supervised contrastive learning. Data Min. Knowl. Discov. 2024, 38, 1493–1519. [Google Scholar] [CrossRef]
- Teng, F.; Guo, X.; Song, Y.; Wang, G. An air target tactical intention recognition model based on bidirectional GRU with attention mechanism. IEEE Access 2021, 9, 169122–169134. [Google Scholar] [CrossRef]
- Ou, W.; Liu, S.; He, X.; Cao, Z. Study on intelligent recognition model of enemy target’s tactical intention on battlefield. Comput. Simul. 2017, 34, 10–14. [Google Scholar]
- Gou, X.T.; Wu, N.F. Air group situation recognition method based on GRU-attention neural network. Comput. Mod. 2019, 10, 11. [Google Scholar] [CrossRef]
- Li, L.; Yang, R.; Lv, M.; Wu, A.; Zhao, Z. From behavior to natural language: Generative approach for unmanned aerial vehicle intent recognition. IEEE Trans. Artif. Intell. 2024, 5, 6196–6209. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Intention Space | Qty. |
|---|---|---|
| [27] | Attack, penetration, retreat, and search | 4 |
| [13] | Attack, scout, penetration, electronic interference, and circumvention | 5 |
| [28] | Attack, electronic interference, retreat, surveillance, scout, and feint | 6 |
| [29] | Attack, scout, surveillance, feint, penetration, defense, and electronic interference | 7 |
| [30] | Penetration, attack, jamming, transportation, refueling, civil fight, AWACS, and scout | 8 |
| Intention | Description |
|---|---|
| Attack | UAVs launch bullets, bombs, or missiles to strike the strategic point to cause damage |
| Retreat | UAVs evacuate from the current battlefield area |
| Electronic interference | UAVs interfere with enemy radar and communication systems through electronic jamming equipment |
| Surveillance | Passive activities of UAVs to monitor an area |
| Reconnaissance | Active exploration activities of air targets to detect the situation |
| Feint | UAVs simulate an attack to deceive the enemy |
| References | Target Features | Qty. |
|---|---|---|
| [31] | Velocity, distance, and azimuth angle | 3 |
| [32] | Azimuth angle, distance, horizontal velocity, heading angle, and height | 5 |
| [33] | Heading, distance, identity, aircraft type, velocity, and height | 6 |
| [34] | Height, velocity, heading, repeated frequency, pulse width, carrier frequency, and level of RCS | 7 |
| [35] | Heading angle, azimuth angle, height, distance, velocity, acceleration, level of RCS, marine air-to-air radar status, and disturbed state | 9 |
| [28] | Azimuth angle, distance, heading angle, velocity, height, marine radar status, air-to-air radar status, disturbing state, disturbed state, and maneuver type | 10 |
| [36] | Velocity, acceleration, height, distance, heading angle, azimuth angle, level of RCS, maneuver type, disturbing state, air-to-air radar status, and marine radar status | 11 |
| [37] | Height, velocity, acceleration, heading angle, azimuth, distance, course short, 1D range profile, radar cross section, air-to-air radar status, air-to-ground radar state, and electronic interference state | 12 |
| Intention Label | Time Frame 1 | … | Time Frame 12 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Velocity | Acceleration | Height | Distance | Heading Angle | Azimuth Angle | Level of RCS | Radar Status | Disturbed State | … | … | |
| 0 | 240 | 20 | 480 | 50 | 90 | 0 | 0.3 | 1 | 0 | … | … |
| 1 | 220 | −5 | 702 | 200 | 270 | 180 | 1.2 | 0 | 0 | … | … |
| 2 | 50 | 5 | 520 | 40 | 45 | 90 | 3 | 1 | 1 | … | … |
| 3 | 70 | 3 | 1800 | 600 | 180 | 10 | 0.5 | 1 | 0 | … | … |
| 4 | 60 | 2 | 1300 | 400 | 90 | 180 | 0.3 | 1 | 1 | … | … |
| 5 | 150 | 12 | 800 | 100 | 270 | 90 | 4 | 1 | 1 | … | … |
| … | … | … | … | … | … | … | … | … | … | … | … |
| Intention Label | Intention Type | Total Samples | Training Samples | Test Samples |
|---|---|---|---|---|
| 0 | Attack | 2560 | 2048 | 512 |
| 1 | Retreat | 1600 | 1280 | 320 |
| 2 | Electronic interference | 1600 | 1280 | 320 |
| 3 | Surveillance | 3840 | 3072 | 768 |
| 4 | Reconnaissance | 3680 | 2944 | 736 |
| 5 | Feint | 2720 | 2176 | 544 |
| Parameter | Value |
|---|---|
| Batch size | [64, 128, 256, 512] |
| Number of hidden layer | [1, 2] |
| Number of hidden nodes | [64, 128, 256, 512] |
| Dropout | [0.1, 0.2, 0.3] |
| Learning rate | [0.0005, 0.001, 0.003] |
| Parameter | Accuracy (%) | ||||
|---|---|---|---|---|---|
| Batch Size | Hidden Layer | Hidden Nodes | Dropout | Learning Rate | |
| 64 | 2 | 128 | 0.1 | 0.003 | 98.104 |
| 64 | 2 | 128 | 0.2 | 0.003 | 98.043 |
| 64 | 2 | 256 | 0.3 | 0.0005 | 98.165 |
| 64 | 2 | 512 | 0.3 | 0.0005 | 98.104 |
| 128 | 1 | 64 | 0.2 | 0.003 | 98.250 |
| 128 | 2 | 64 | 0.3 | 0.001 | 98.043 |
| 128 | 2 | 256 | 0.3 | 0.003 | 98.165 |
| 256 | 2 | 128 | 0.2 | 0.0005 | 98.165 |
| 256 | 2 | 512 | 0.3 | 0.001 | 98.043 |
| 512 | 1 | 128 | 0.2 | 0.001 | 98.043 |
| 512 | 1 | 256 | 0.3 | 0.0005 | 98.043 |
| 512 | 2 | 256 | 0.2 | 0.0005 | 98.043 |
| 512 | 2 | 256 | 0.3 | 0.001 | 98.165 |
| Parameter | Value |
|---|---|
| Loss function | Categorical_Crossentropy |
| Optimizer | Adam |
| Activation function | ReLU |
| Hidden layer | 1 |
| Hidden nodes | 64 |
| Batch size | 128 |
| Epoch | 60 |
| Dropout | 0.2 |
| Learning rate | 0.003 |
| Data Missing | Accuracy (%) | Data Missing | Accuracy (%) |
|---|---|---|---|
| 0% | 98.25 | 40% | 86.51 |
| 10% | 96.82 | 50% | 73.27 |
| 20% | 93.33 | 60% | 60.83 |
| 30% | 91.57 | 70% | 45.60 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1 Score | Loss | Number of Parameters (K) | Computational Complexity (MFLOPs) |
|---|---|---|---|---|---|---|---|
| BLAC | 98.25 | 98.54 | 98.48 | 0.985 | 0.16 | 38.92 | 0.902 |
| BiGRU-Attention | 95.96 | 96.42 | 96.17 | 0.963 | 0.19 | 78.47 | 1.270 |
| LSTM-Attention | 90.74 | 91.85 | 91.47 | 0.916 | 0.17 | 21.37 | 0.504 |
| LSTM | 86.31 | 86.96 | 86.64 | 0.868 | 0.32 | 18.97 | 0.446 |
| GRU | 85.80 | 86.69 | 86.39 | 0.865 | 0.27 | 14.47 | 0.422 |
| TCN-Self-Attention | 89.93 | 91.05 | 90.29 | 0.906 | 0.22 | 26.54 | 0.649 |
| PCLSTM | 88.70 | 89.45 | 88.93 | 0.892 | 0.33 | 35.58 | 0.963 |
| TCN | 83.65 | 84.78 | 83.85 | 0.843 | 0.29 | 21.21 | 0.503 |
| Model | Model Composition Structure | Accuracy (%) | Loss | |||
|---|---|---|---|---|---|---|
| LSTM | Bidirectional | Cross Attention | Contrast Learning | |||
| ① | √ | 86.31 | 0.32 | |||
| ② | √ | √ | √ | 95.81 | 0.18 | |
| ③ | √ | √ | √ | 96.28 | 0.21 | |
| ④ | √ | √ | √ | 97.44 | 0.13 | |
| ⑤ | √ | √ | √ | √ | 98.25 | 0.16 |
| Index | Precision (%) | Recall (%) | F1 Score | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intention | ① | ② | ③ | ④ | ⑤ | ① | ② | ③ | ④ | ⑤ | ① | ② | ③ | ④ | ⑤ |
| Attack | 82.56 | 94.92 | 95.31 | 96.88 | 97.66 | 83.20 | 94.92 | 95.31 | 96.88 | 97.85 | 0.829 | 0.949 | 0.953 | 0.969 | 0.978 |
| Retreat | 92.54 | 100 | 100 | 100 | 100 | 96.88 | 100 | 100 | 100 | 100 | 0.947 | 1.000 | 1.000 | 1.000 | 1.000 |
| Electronic interference | 86.86 | 96.91 | 97.82 | 98.45 | 100 | 95.00 | 98.13 | 98.13 | 99.06 | 99.38 | 0.907 | 0.975 | 0.980 | 0.988 | 0.997 |
| Surveillance | 86.26 | 95.43 | 95.84 | 97.13 | 97.92 | 85.03 | 95.18 | 95.96 | 96.88 | 97.92 | 0.856 | 0.953 | 0.959 | 0.970 | 0.979 |
| Reconnaissance | 86.58 | 94.99 | 95.39 | 96.88 | 97.70 | 85.05 | 95.38 | 95.65 | 97.15 | 98.10 | 0.858 | 0.952 | 0.955 | 0.970 | 0.979 |
| Feint | 85.36 | 95.18 | 95.93 | 97.05 | 97.97 | 81.43 | 94.30 | 95.22 | 96.70 | 97.61 | 0.833 | 0.947 | 0.956 | 0.969 | 0.978 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, Q.; Zhang, L.; Ren, S.; Gao, W.; Wang, C. Attention-Enhanced Contrastive BiLSTM for UAV Intention Recognition Under Information Uncertainty. Drones 2025, 9, 319. https://doi.org/10.3390/drones9040319
Niu Q, Zhang L, Ren S, Gao W, Wang C. Attention-Enhanced Contrastive BiLSTM for UAV Intention Recognition Under Information Uncertainty. Drones. 2025; 9(4):319. https://doi.org/10.3390/drones9040319
Chicago/Turabian StyleNiu, Qianru, Luyuan Zhang, Shuangyin Ren, Wei Gao, and Chunjiang Wang. 2025. "Attention-Enhanced Contrastive BiLSTM for UAV Intention Recognition Under Information Uncertainty" Drones 9, no. 4: 319. https://doi.org/10.3390/drones9040319
APA StyleNiu, Q., Zhang, L., Ren, S., Gao, W., & Wang, C. (2025). Attention-Enhanced Contrastive BiLSTM for UAV Intention Recognition Under Information Uncertainty. Drones, 9(4), 319. https://doi.org/10.3390/drones9040319