
A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS



Abstract
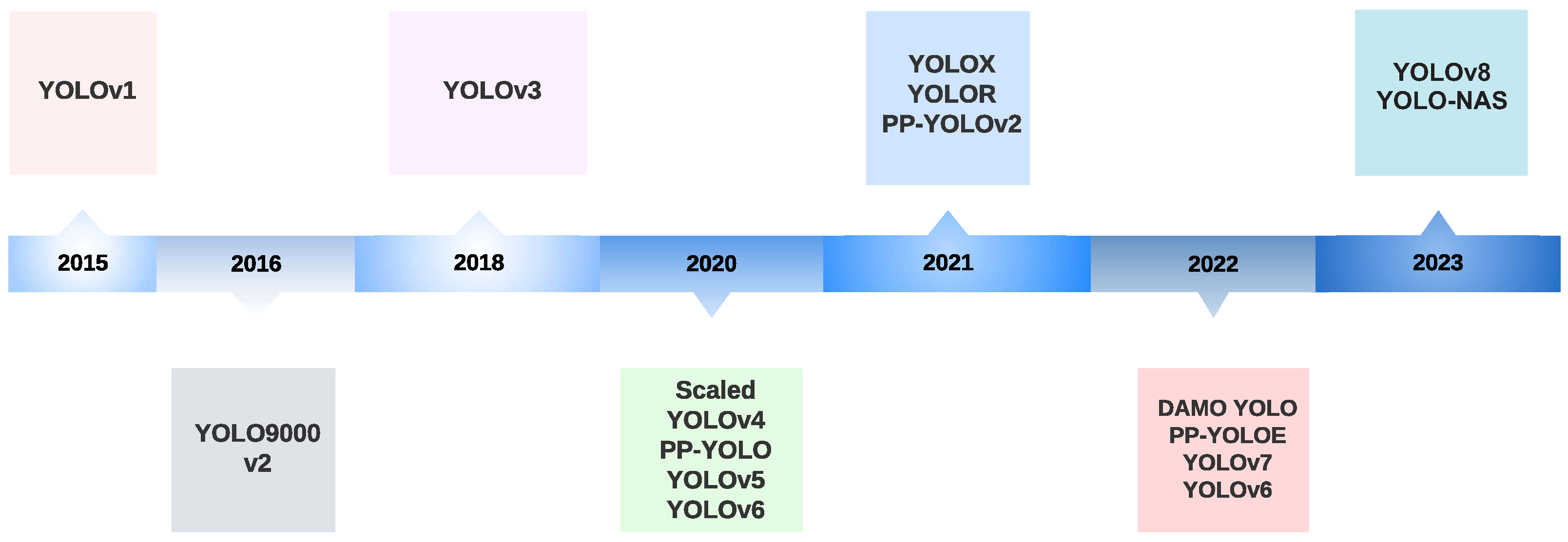
:1. Introduction
2. YOLO Applications across Diverse Fields
3. Object Detection Metrics and Non-Maximum Suppression (NMS)
3.1. How AP Works?
3.2. Computing AP
3.2.1. VOC Dataset
- For each category, calculate the precision–recall curve by varying the confidence threshold of the model’s predictions.
- Calculate each category’s average precision (AP) using an interpolated 11-point sampling of the precision–recall curve.
- Compute the final average precision (AP) by taking the mean of the APs across all 20 categories.
3.2.2. Microsoft COCO Dataset
- For each category, calculate the precision–recall curve by varying the confidence threshold of the model’s predictions.
- Compute each category’s average precision (AP) using 101 recall thresholds.
- Calculate AP at different Intersection over Union (IoU) thresholds, typically from 0.5 to 0.95 with a step size of 0.05. A higher IoU threshold requires a more accurate prediction to be considered a true positive.
- For each IoU threshold, take the mean of the APs across all 80 categories.
- Finally, compute the overall AP by averaging the AP values calculated at each IoU threshold.
3.3. Non-Maximum Suppression (NMS)
| Algorithm 1 Non-Maximum Suppression Algorithm |
|
4. YOLO: You Only Look Once
4.1. How Does YOLOv1 Work?
4.2. YOLOv1 Architecture
4.3. YOLOv1 Training
4.4. YOLOv1 Strengths and Limitations
- It could only detect at most two objects of the same class in the grid cell, limiting its ability to predict nearby objects.
- It struggled to predict objects with aspect ratios not seen in the training data.
- It learned from coarse object features due to the downsampling layers.
5. YOLOv2: Better, Faster, and Stronger
- Batch normalization on all convolutional layers improves convergence and acts as a regularizer to reduce overfitting.
- High-resolution classifier. Like YOLOv1, they pre-trained the model with ImageNet at . However, this time, they fine-tuned the model for ten epochs on ImageNet with a resolution of , improving the network performance on higher resolution input.
- Fully convolutional. They removed the dense layers and used a fully convolutional architecture.
- Use anchor boxes to predict bounding boxes. They use a set of prior boxes or anchor boxes, which are boxes with predefined shapes used to match prototypical shapes of objects as shown in Figure 7. Multiple anchor boxes are defined for each grid cell, and the system predicts the coordinates and the class for every anchor box. The size of the network output is proportional to the number of anchor boxes per grid cell.
- Dimension clusters. Picking good prior boxes helps the network learn to predict more accurate bounding boxes. The authors ran k-means clustering on the training bounding boxes to find good priors. They selected five prior boxes, providing a good tradeoff between recall and model complexity.
- Direct location prediction. Unlike other methods that predicted offsets [3], YOLOv2 followed the same philosophy and predicted location coordinates relative to the grid cell. The network predicts five bounding boxes for each cell, each with five values , , , , and , where is equivalent to from YOLOv1 and the final bounding box coordinates are obtained as shown in Figure 8.
- Finer-grained features. YOLOv2, compared with YOLOv1, removed one pooling layer to obtain an output feature map or grid of for input images of . YOLOv2 also uses a passthrough layer that takes the feature map and reorganizes it by stacking adjacent features into different channels instead of losing them via a spatial subsampling. This generates feature maps concatenated in the channel dimension with the lower resolution maps to obtain feature maps. See Table 2 for the architectural details.
- Multi-scale training. Since YOLOv2 does not use fully connected layers, the inputs can be of different sizes. To make YOLOv2 robust to different input sizes, the authors trained the model randomly, changing the input size—from up to —every ten batches.
5.1. YOLOv2 Architecture
5.2. YOLO9000 Is a Stronger YOLOv2
6. YOLOv3
- Bounding box prediction. Like YOLOv2, the network predicts four coordinates for each bounding box , , , and ; however, this time, YOLOv3 predicts an objectness score for each bounding box using logistic regression. This score is 1 for the anchor box with the highest overlap with the ground truth and 0 for the rest of the anchor boxes. YOLOv3, as opposed to Faster R-CNN [3], assigns only one anchor box to each ground truth object. Also, if no anchor box is assigned to an object, it only increases classification loss but not localization loss or confidence loss.
- Class Prediction. Instead of using a softmax for the classification, they used binary cross-entropy to train independent logistic classifiers and pose the problem as a multilabel classification. This change allows assigning multiple labels to the same box, which may occur on some complex datasets [56] with overlapping labels. For example, the same object can be a Person and a Man.
- New backbone. YOLOv3 features a larger feature extractor composed of 53 convolutional layers with residual connections. Section 6.1 describes the architecture in more detail.
- Spatial pyramid pooling (SPP) Although not mentioned in the paper, the authors also added to the backbone a modified SPP block [57] that concatenates multiple max pooling outputs without subsampling (stride = 1), each with different kernel sizes , where allowing a larger receptive field. This version is called YOLOv3-spp and was the best-performing version, improving the AP50 by 2.7%.
- Multi-scale Predictions. Similar to feature pyramid networks [58], YOLOv3 predicts three boxes at three different scales. Section 6.2 describes the multi-scale prediction mechanism in more detail.
- Bounding box priors. Like YOLOv2, the authors also use k-means to determine the bounding-box priors of anchor boxes. The difference is that in YOLOv2, they used a total of five prior boxes per cell, and in YOLOv3, they used three prior boxes for three different scales.
6.1. YOLOv3 Architecture
6.2. YOLOv3 Multi-Scale Predictions
6.3. YOLOv3 Results
7. Backbone, Neck, and Head
8. YOLOv4
- An Enhanced Architecture with Bag-of-Specials (BoS) Integration. The authors tried multiple architectures for the backbone, such as ResNeXt50 [68], EfficientNet-B3 [69], and Darknet-53. The best-performing architecture was a modification of Darknet-53 with cross-stage partial connections (CSPNet) [70], and Mish activation function [66] as the backbone (see Figure 12. For the neck, they used the modified version of spatial pyramid pooling (SPP) [57] from YOLOv3-spp and multi-scale predictions as in YOLOv3, but with a modified version of path aggregation network (PANet) [71] instead of FPN as well as a modified spatial attention module (SAM) [72]. Finally, for the detection head, they used anchors, as in YOLOv3. Therefore, the model was called CSPDarknet53-PANet-SPP. The cross-stage partial connections (CSP) added to the Darknet-53 help reduce the computation of the model while keeping the same accuracy. The SPP block, as in YOLOv3-spp, increases the receptive field without affecting the inference speed. The modified version of PANet concatenates the features instead of adding them as in the original PANet paper.
- Integrating Bag of Freebies (BoF) for an Advanced Training Approach. Apart from the regular augmentations such as random brightness, contrast, scaling, cropping, flipping, and rotation, the authors implemented mosaic augmentation that combines four images into a single one, allowing the detection of objects outside their usual context and also reducing the need for a large mini-batch size for batch normalization. For regularization, they used DropBlock [73], which works as a replacement for Dropout [74] but for convolutional neural networks as well as class label smoothing [75,76]. For the detector, they added CIoU loss [77] and cross-mini-batch normalization (CmBN) for collecting statistics from the entire batch instead of from single mini-batches as in regular batch normalization [78].
- Self-adversarial Training (SAT). To make the model more robust to perturbations, an adversarial attack is performed on the input image to create a deception that the ground-truth object is not in the image but keeps the original label to detect the correct object.
- Hyperparameter Optimization with Genetic Algorithms. To find the optimal hyperparameters used for training, they use genetic algorithms on the first 10% of periods and a cosine annealing scheduler [79] to alter the learning rate during training. It starts reducing the learning rate slowly, followed by a quick reduction halfway through the training process, ending with a slight reduction.
9. YOLOv5
YOLOv5 Architecture
10. Scaled-YOLOv4
11. YOLOR
12. YOLOX
- Anchor-free. Since YOLOv2, all subsequent YOLO versions were anchor-based detectors. YOLOX, inspired by anchor-free state-of-the-art object detectors, such as CornerNet [92], CenterNet [93], and FCOS [94], returned to an anchor-free architecture simplifying the training and decoding process. The anchor-free increased the AP by 0.9 points concerning the YOLOv3 baseline.
- Multi positives. To compensate for the large imbalances and the lack of anchors produced, the authors use center sampling [94] where they assigned the center area as positives. This approach increased AP by 2.1 points.
- Decoupled head. In [95,96], it was shown that there could be a misalignment between the classification confidence and localization accuracy. Due to this, YOLOX separates these two into two heads (as shown in Figure 14), one for classification tasks and the other for regression tasks, improving the AP by 1.1 points and speeding up the model convergence.
- Advanced label assignment. In [97], it was shown that the ground-truth label assignment could have ambiguities when the boxes of multiple objects overlap and formulate the assigning procedure as an Optimal Transport (OT) problem. YOLOX, inspired by this work, proposed a simplified version called simOTA. This change increased AP by 2.3 points.
- Strong augmentations. YOLOX uses MixUP [86] and Mosaic augmentations. The authors found that ImageNet pretraining was no longer beneficial after using these augmentations. The strong augmentations increased AP by 2.4 points.
13. YOLOv6
- Label assignment using the Task alignment learning approach introduced in TOOD [101].
- A self-distillation strategy for the regression and classification tasks.
14. YOLOv7
- Extended efficient layer aggregation network (E-ELAN). ELAN [109] is a strategy that allows a deep model to learn and converge more efficiently by controlling the shortest longest gradient path. YOLOv7 proposed E-ELAN that works for models with unlimited stacked computational blocks. E-ELAN combines the features of different groups by shuffling and merging cardinality to enhance the network’s learning without destroying the original gradient path.
- Model scaling for concatenation-based models. Scaling generates models of different sizes by adjusting some model attributes. The architecture of YOLOv7 is a concatenation-based architecture in which standard scaling techniques, such as depth scaling, cause a ratio change between the input channel and the output channel of a transition layer, which, in turn, leads to a decrease in the hardware usage of the model. YOLOv7 proposed a new strategy for scaling concatenation-based models in which the depth and width of the block are scaled with the same factor to maintain the optimal structure of the model.
- Planned re-parameterized convolution. Like YOLOv6, the architecture of YOLOv7 is also inspired by re-parameterized convolutions (RepConv) [99]. However, they found that the identity connection in RepConv destroys the residual in ResNet [62] and the concatenation in DenseNet [110]. For this reason, they removed the identity connection and called it RepConvN.
- Coarse label assignment for auxiliary head and fine label assignment for the lead head. The lead head is responsible for the final output, while the auxiliary head assists with the training.
- Batch normalization in conv-bn-activation. This integrates the mean and variance of batch normalization into the bias and weight of the convolutional layer at the inference stage.
- Implicit knowledge inspired in YOLOR [90].
- Exponential moving average as the final inference model.
Comparison with YOLOv4 and YOLOR
15. DAMO-YOLO
- A neural architecture search (NAS). They used a method called MAE-NAS [112] developed by Alibaba to find an efficient architecture automatically.
- A small head. The authors found that a large neck and a small neck yield better performance, and they only left one linear layer for classification and one for regression. They called this approach ZeroHead.
- AlignedOTA label assignment. Dynamic label assignment methods, such as OTA [97] and TOOD [101], have gained popularity due to their significant improvements over static methods. However, the misalignment between classification and regression remains a problem, partly because of the imbalance between classification and regression losses. To address this issue, their AlignOTA method introduces focal loss [6] into the classification cost and uses the IoU of prediction and ground-truth box as the soft label, enabling the selection of aligned samples for each target and solving the problem from a global perspective.
- Knowledge distillation. Their proposed strategy consists of two stages: the teacher guiding the student in the first stage and the student fine-tuning independently in the second stage. Additionally, they incorporate two enhancements in the distillation approach: the Align Module, which adapts student features to the same resolution as the teacher’s, and Channel-wise Dynamic Temperature, which normalizes teacher and student features to reduce the impact of real value differences.
16. YOLOv8
YOLOv8 Architecture

17. PP-YOLO, PP-YOLOv2, and PP-YOLOE
- A ResNet50-vd backbone replacing the DarkNet-53 backbone with an architecture augmented with deformable convolutions [118] in the last stage and a distilled pre-trained model, which has a higher classification accuracy on ImageNet. This architecture is called ResNet5-vd-dcn.
- A larger batch size to improve training stability; they went from 64 to 192, along with an updated training schedule and learning rate.
- Maintained moving averages for the trained parameters, used instead of the final trained values.
- DropBlock is applied only to the FPN.
- An IoU loss is added in another branch along with the L1-loss for bounding-box regression.
- An IoU prediction branch is added to measure localization accuracy along with an IoU-aware loss. During inference, YOLOv3 multiplies the classification probability and objectiveness score to compute the final detection. PP-YOLO also multiplies the predicted IoU to consider the localization accuracy.
- Grid-sensitive approach similar to YOLOv4, it is used to improve the bounding-box center prediction at the grid boundary.
- Matrix NMS [119] is used, which can be run in parallel, making it faster than traditional NMS.
- CoordConv [120] is used for the convolution of the FPN and on the first convolution layer in the detection head. CoordConv allows the network to learn translational invariance, improving the detection localization.
- Spatial Pyramid Pooling is used only on the top feature map to increase the receptive field of the backbone.
17.1. PP-YOLO Augmentations and Preprocessing
- Mixup Training [86] with a weight sampled from distribution, where and .
- Random Color Distortion.
- Random Expand.
- Random Crop and Random Flip with a probability of 0.5.
- RGB channel z-score normalization with a mean of and a standard deviation of .
- Multiple image sizes evenly drawn from [320, 352, 384, 416, 448, 480, 512, 544, 576, 608].
17.2. PP-YOLOv2
- Backbone changed from ResNet50 to ResNet101.
- Path aggregation network (PAN) instead of FPN, similar to YOLOv4.
- Mish activation function. Unlike YOLOv4 and YOLOv5, they only applied the Mish activation function in the detection neck to keep the backbone unchanged with the ReLU.
- Larger input sizes help to increase performance on small objects. They expanded the largest input size from 608 to 768 and reduced the batch size from 24 to 12 images per GPU. The input sizes are evenly drawn from [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768].
- A modified IoU-aware branch. They modified the calculation of the IoU-aware loss calculation using a soft label format instead of a soft weight format.
17.3. PP-YOLOE
- New backbone and neck. Inspired by TreeNet [123], the authors modified the architecture of the backbone and neck with RepResBlocks, combining residual and dense connections.
- Task alignment learning (TAL). YOLOX was the first to bring up the problem of task misalignment, where the classification confidence and the location accuracy do not agree in all cases. To reduce this problem, PP-YOLOE implemented TAL as proposed in TOOD [101], which includes a dynamic label assignment combined with a task-alignment loss.
- Efficient task-aligned head (ET-head). Different from YOLOX, where the classification and locations heads were decoupled, PP-YOLOE instead used a single head based on TOOD to improve speed and accuracy.
- Varifocal (VFL) and distribution focal loss (DFL). VFL [102] weights loss of positive samples using target score, giving higher weight to those with high IoU. This prioritizes high-quality samples during training. Similarly, both use IoU-aware classification score (IACS) as the target, allowing for joint learning of classification and localization quality, leading to consistency between training and inference. On the other hand, DFL [115] extends focal loss from discrete to continuous labels, enabling successful optimization of improved representations that combine quality estimation and class prediction. This allows for an accurate depiction of flexible distribution in real data, eliminating the risk of inconsistency.

18. YOLO-NAS
- Quantization-aware modules [126], called QSP and QCI, that combine re-parameterization for 8-bit quantization to minimize the accuracy loss during post-training quantization.
- Automatic architecture design using AutoNAC, Deci’s proprietary NAS technology.
- Hybrid quantization method to selectively quantize certain parts of a model to balance latency and accuracy instead of standard quantization, where all the layers are affected.
- A pre-training regimen with automatically labeled data, self-distillation, and large datasets.
19. YOLO with Transformers
20. Discussion
- Anchors: The original YOLO model was relatively simple and did not employ anchors, while the state of the art relied on two-stage detectors with anchors. YOLOv2 incorporated anchors, leading to improvements in bounding-box prediction accuracy. This trend persisted for five years until YOLOX introduced an anchorless approach that achieved state-of-the-art results. Since then, subsequent YOLO versions have abandoned the use of anchors.
- Framework: Initially, YOLO was developed using the Darknet framework, with subsequent versions following suit. However, when Ultralytics ported YOLOv3 to PyTorch, the remaining YOLO versions were developed using PyTorch, leading to a surge in enhancements. Another deep learning language utilized is PaddlePaddle, an open-source framework initially developed by Baidu.
- Backbone: The backbone architectures of YOLO models have undergone significant changes over time. Starting with the Darknet architecture, which comprised simple convolutional and max pooling layers, later models incorporated cross-stage partial connections (CSP) in YOLOv4, reparameterization in YOLOv6 and YOLOv7, and neural architecture search in DAMO-YOLO and YOLO-NAS.
- Performance: While the performance of YOLO models has improved over time, it is worth noting that they often prioritize balancing speed and accuracy rather than solely focusing on accuracy. This tradeoff is essential to the YOLO framework, allowing for real-time object detection across various applications.
Tradeoff between Speed and Accuracy
21. The Future of YOLO
22. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Proceedings, Part I 14, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Bhavya Sree, B.; Yashwanth Bharadwaj, V.; Neelima, N. An Inter-Comparative Survey on State-of-the-Art Detectors—R-CNN, YOLO, and SSD. In Intelligent Manufacturing and Energy Sustainability: Proceedings of ICIMES 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 475–483. [Google Scholar]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Lan, W.; Dang, J.; Wang, Y.; Wang, S. Pedestrian detection based on YOLO network model. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 1547–1551. [Google Scholar]
- Hsu, W.Y.; Lin, W.Y. Adaptive fusion of multi-scale YOLO for pedestrian detection. IEEE Access 2021, 9, 110063–110073. [Google Scholar] [CrossRef]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv 2021, arXiv:2112.11798. [Google Scholar]
- Dazlee, N.M.A.A.; Khalil, S.A.; Abdul-Rahman, S.; Mutalib, S. Object detection for autonomous vehicles with sensor-based technology using yolo. Int. J. Intell. Syst. Appl. Eng. 2022, 10, 129–134. [Google Scholar] [CrossRef]
- Liang, S.; Wu, H.; Zhen, L.; Hua, Q.; Garg, S.; Kaddoum, G.; Hassan, M.M.; Yu, K. Edge YOLO: Real-time intelligent object detection system based on edge-cloud cooperation in autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25345–25360. [Google Scholar] [CrossRef]
- Li, Q.; Ding, X.; Wang, X.; Chen, L.; Son, J.; Song, J.Y. Detection and identification of moving objects at busy traffic road based on YOLO v4. J. Inst. Internet, Broadcast. Commun. 2021, 21, 141–148. [Google Scholar]
- Shinde, S.; Kothari, A.; Gupta, V. YOLO-based human action recognition and localization. Procedia Comput. Sci. 2018, 133, 831–838. [Google Scholar] [CrossRef]
- Ashraf, A.H.; Imran, M.; Qahtani, A.M.; Alsufyani, A.; Almutiry, O.; Mahmood, A.; Attique, M.; Habib, M. Weapons detection for security and video surveillance using CNN and YOLO-v5s. CMC-Comput. Mater. Contin. 2022, 70, 2761–2775. [Google Scholar]
- Zheng, Y.; Zhang, H. Video Analysis in Sports by Lightweight Object Detection Network under the Background of Sports Industry Development. Comput. Intell. Neurosci. 2022, 2022, 3844770. [Google Scholar] [CrossRef] [PubMed]
- Ma, H.; Celik, T.; Li, H. Fer-yolo: Detection and classification based on facial expressions. In Proceedings of the Image and Graphics: 11th International Conference, ICIG 2021, Proceedings, Part I 11, Haikou, China, 6–8 August 2021; pp. 28–39. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Lippi, M.; Bonucci, N.; Carpio, R.F.; Contarini, M.; Speranza, S.; Gasparri, A. A Yolo-based pest detection system for precision agriculture. In Proceedings of the 2021 29th Mediterranean Conference on Control and Automation (MED), Puglia, Italy, 22–25 June 2021; pp. 342–347. [Google Scholar]
- Wang, Y.; Zheng, J. Real-time face detection based on YOLO. In Proceedings of the 2018 1st IEEE International Conference on knowledge innovation and Invention (ICKII), Jeju, Republic of Korea, 23–27 July 2018; pp. 221–224. [Google Scholar]
- Chen, W.; Huang, H.; Peng, S.; Zhou, C.; Zhang, C. YOLO-face: A real-time face detector. Vis. Comput. 2021, 37, 805–813. [Google Scholar] [CrossRef]
- Al-Masni, M.A.; Al-Antari, M.A.; Park, J.M.; Gi, G.; Kim, T.Y.; Rivera, P.; Valarezo, E.; Choi, M.T.; Han, S.M.; Kim, T.S. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Programs Biomed. 2018, 157, 85–94. [Google Scholar] [CrossRef] [PubMed]
- Nie, Y.; Sommella, P.; O’Nils, M.; Liguori, C.; Lundgren, J. Automatic detection of melanoma with yolo deep convolutional neural networks. In Proceedings of the 2019 E-Health and Bioengineering Conference (EHB), Iasi, Romania, 21–23 November 2019; pp. 1–4. [Google Scholar]
- Ünver, H.M.; Ayan, E. Skin lesion segmentation in dermoscopic images with combination of YOLO and grabcut algorithm. Diagnostics 2019, 9, 72. [Google Scholar] [CrossRef] [PubMed]
- Tan, L.; Huangfu, T.; Wu, L.; Chen, W. Comparison of RetinaNet, SSD, and YOLO v3 for real-time pill identification. BMC Med. Inform. Decis. Mak. 2021, 21, 1–11. [Google Scholar] [CrossRef]
- Cheng, L.; Li, J.; Duan, P.; Wang, M. A small attentional YOLO model for landslide detection from satellite remote sensing images. Landslides 2021, 18, 2751–2765. [Google Scholar] [CrossRef]
- Pham, M.T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-stage detector of small objects under various backgrounds in remote sensing images. Remote Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Qing, Y.; Liu, W.; Feng, L.; Gao, W. Improved Yolo network for free-angle remote sensing target detection. Remote Sens. 2021, 13, 2171. [Google Scholar] [CrossRef]
- Zakria, Z.; Deng, J.; Kumar, R.; Khokhar, M.S.; Cai, J.; Kumar, J. Multiscale and direction target detecting in remote sensing images via modified YOLO-v4. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1039–1048. [Google Scholar] [CrossRef]
- Kumar, P.; Narasimha Swamy, S.; Kumar, P.; Purohit, G.; Raju, K.S. Real-Time, YOLO-Based Intelligent Surveillance and Monitoring System Using Jetson TX2. In Data Analytics and Management: Proceedings of ICDAM; Springer: Berlin/Heidelberg, Germany, 2021; pp. 461–471. [Google Scholar]
- Bhambani, K.; Jain, T.; Sultanpure, K.A. Real-time face mask and social distancing violation detection system using Yolo. In Proceedings of the 2020 IEEE Bangalore Humanitarian Technology Conference (B-HTC), Vijiyapur, India, 8–10 October 2020; pp. 1–6. [Google Scholar]
- Li, J.; Su, Z.; Geng, J.; Yin, Y. Real-time detection of steel strip surface defects based on improved yolo detection network. IFAC-PapersOnLine 2018, 51, 76–81. [Google Scholar] [CrossRef]
- Ukhwah, E.N.; Yuniarno, E.M.; Suprapto, Y.K. Asphalt pavement pothole detection using deep learning method based on YOLO neural network. In Proceedings of the 2019 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 28–29 August 2019; pp. 35–40. [Google Scholar]
- Du, Y.; Pan, N.; Xu, Z.; Deng, F.; Shen, Y.; Kang, H. Pavement distress detection and classification based on YOLO network. Int. J. Pavement Eng. 2021, 22, 1659–1672. [Google Scholar] [CrossRef]
- Chen, R.C. Automatic License Plate Recognition via sliding-window darknet-YOLO deep learning. Image Vis. Comput. 2019, 87, 47–56. [Google Scholar]
- Dewi, C.; Chen, R.C.; Jiang, X.; Yu, H. Deep convolutional neural network for enhancing traffic sign recognition developed on Yolo V4. Multimed. Tools Appl. 2022, 81, 37821–37845. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An efficient and robust computer vision-based accurate object localization model for automated endangered wildlife detection. Ecol. Inform. 2023, 75, 101919. [Google Scholar] [CrossRef]
- Kulik, S.; Shtanko, A. Experiments with neural net object detection system YOLO on small training datasets for intelligent robotics. In Advanced Technologies in Robotics and Intelligent Systems: Proceedings of ITR 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 157–162. [Google Scholar]
- Dos Reis, D.H.; Welfer, D.; De Souza Leite Cuadros, M.A.; Gamarra, D.F.T. Mobile robot navigation using an object recognition software with RGBD images and the YOLO algorithm. Appl. Artif. Intell. 2019, 33, 1290–1305. [Google Scholar] [CrossRef]
- Sahin, O.; Ozer, S. Yolodrone: Improved Yolo architecture for object detection in drone images. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 26–28 July 2021; pp. 361–365. [Google Scholar]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. YOLO-Based UAV Technology: A Review of the Research and Its Applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- VOSviewer. VOSviewer: Visualizing Scientific Landscapes. 2023. Available online: https://www.vosviewer.com/ (accessed on 11 November 2023).
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16 June 2013; Volume 30, p. 3. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large-scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Krasin, I.; Duerig, T.; Alldrin, N.; Ferrari, V.; Abu-El-Haija, S.; Kuznetsova, A.; Rom, H.; Uijlings, J.; Popov, S.; Veit, A.; et al. Openimages: A Public Dataset for Large-Scale Multi-Label and Multi-Class Image Classification. 2017, Volume 2, p. 18. Available online: https://github.com/openimages (accessed on 1 January 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Misra, D. Mish: A self-regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, Red Hook, NY, USA, 3 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 10750–10760. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Islam, M.A.; Naha, S.; Rochan, M.; Bruce, N.; Wang, Y. Label refinement network for coarse-to-fine semantic segmentation. arXiv 2017, arXiv:1703.00551. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Wang, S.; Zhao, J.; Ta, N.; Zhao, X.; Xiao, M.; Wei, H. A real-time deep learning forest fire monitoring algorithm based on an improved Pruned+ KD model. J.-Real-Time Image Process. 2021, 18, 2319–2329. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5 by Ultralytics. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 28 February 2023).
- Contributors, M. YOLOv5 by MMYOLO. 2023. Available online: https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5 (accessed on 13 May 2023).
- Ultralytics. Model Structure. 2023. Available online: https://docs.ultralytics.com/yolov5/tutorials/architecture_description/#1-model-structure (accessed on 14 May 2023).
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross-stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E.; et al. PP-YOLO: An effective and efficient implementation of object detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the sibling head in object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11563–11572. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking classification and localization for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10186–10195. [Google Scholar]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. Ota: Optimal transport assignment for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 303–312. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Contributors, M. YOLOv6 by MMYOLO. 2023. Available online: https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov6 (accessed on 13 May 2023).
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 658–666. [Google Scholar]
- Ding, X.; Chen, H.; Zhang, X.; Huang, K.; Han, J.; Ding, G. Re-parameterizing Your Optimizers rather than Architectures. arXiv 2022, arXiv:2205.15242. [Google Scholar]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 5311–5320. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Contributors, M. YOLOv7 by MMYOLO. 2023. Available online: https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov7 (accessed on 13 May 2023).
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. DAMO-YOLO: A Report on Real-Time Object Detection Design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Alibaba. TinyNAS. 2023. Available online: https://github.com/alibaba/lightweight-neural-architecture-search (accessed on 18 May 2023).
- Tan, Z.; Wang, J.; Sun, X.; Lin, M.; Li, H. Giraffedet: A heavy-neck paradigm for object detection. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 28 February 2023).
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Contributors, M. YOLOv8 by MMYOLO. 2023. Available online: https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov8 (accessed on 13 May 2023).
- Ma, Y.; Yu, D.; Wu, T.; Wang, H. PaddlePaddle: An open-source deep learning platform from industrial practice. Front. Data Domputing 2019, 1, 105–115. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. Solov2: Dynamic, faster and stronger. In Proceedings of the Thirty-Fourth Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Liu, R.; Lehman, J.; Molino, P.; Petroski Such, F.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the coordconv solution. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 9628–9639. [Google Scholar]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A practical object detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Rao, L. TreeNet: A lightweight One-Shot Aggregation Convolutional Network. arXiv 2021, arXiv:2109.12342. [Google Scholar]
- Contributors, M. PP-YOLOE by MMYOLO. 2023. Available online: https://github.com/open-mmlab/mmyolo/tree/main/configs/ppyoloe (accessed on 13 May 2023).
- Research Team. YOLO-NAS by Deci Achieves State-of-the-Art Performance on Object Detection Using Neural Architecture Search. 2023. Available online: https://deci.ai/blog/yolo-nas-object-detection-foundation-model/ (accessed on 12 May 2023).
- Chu, X.; Li, L.; Zhang, B. Make RepVGG Greater Again: A Quantization-aware Approach. arXiv 2022, arXiv:2212.01593. [Google Scholar]
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8430–8439. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Fang, Y.; Liao, B.; Wang, X.; Fang, J.; Qi, J.; Wu, R.; Niu, J.; Liu, W. You only look at one sequence: Rethinking transformer in vision through object detection. Adv. Neural Inf. Process. Syst. 2021, 34, 26183–26197. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-based YOLO for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. Msft-yolo: Improved yolov5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef]
- Liu, Y.; He, G.; Wang, Z.; Li, W.; Huang, H. NRT-YOLO: Improved YOLOv5 based on nested residual transformer for tiny remote sensing object detection. Sensors 2022, 22, 4953. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Wang, S.; Gao, S.; Zhou, L.; Liu, R.; Zhang, H.; Liu, J.; Jia, Y.; Qian, J. YOLO-SD: Small Ship Detection in SAR Images by Multi-Scale Convolution and Feature Transformer Module. Remote Sens. 2022, 14, 5268. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Ouyang, H. DEYO: DETR with YOLO for Step-by-Step Object Detection. arXiv 2022, arXiv:2211.06588. [Google Scholar]
- Ultralytics. YOLOv8—Ultralytics YOLOv8 Documentation. 2023. Available online: https://docs.ultralytics.com/models/yolov8/ (accessed on 11 November 2023).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Filters | Size/Stride | Output | |
|---|---|---|---|---|
| Conv | 64 | |||
| Max Pool | ||||
| Conv | 192 | |||
| Max Pool | ||||
| Conv | 128 | |||
| Conv | 256 | |||
| Conv | 256 | |||
| Conv | 512 | |||
| Max Pool | ||||
| Conv | 256 | |||
| Conv | 512 | |||
| Conv | 512 | |||
| Conv | 1024 | |||
| Max Pool | ||||
| Conv | 512 | |||
| Conv | 1024 | |||
| Conv | 1024 | |||
| Conv | 1024 | |||
| Conv | 1024 | |||
| Conv | 1024 | |||
| FC | 4096 | 4096 | ||
| Dropout 0.5 | 4096 | |||
| FC |
| Num | Type | Filters | Size/Stride | Output |
|---|---|---|---|---|
| 1 | Conv/BN | 32 | ||
| 2 | Max Pool | |||
| 3 | Conv/BN | 64 | ||
| 4 | Max Pool | |||
| 5 | Conv/BN | 128 | ||
| 6 | Conv/BN | 64 | ||
| 7 | Conv/BN | 128 | ||
| 8 | Max Pool | |||
| 9 | Conv/BN | 256 | ||
| 10 | Conv/BN | 128 | ||
| 11 | Conv/BN | 256 | ||
| 12 | Max Pool | |||
| 13 | Conv/BN | 512 | ||
| 14 | Conv/BN | 256 | ||
| 15 | Conv/BN | 512 | ||
| 16 | Conv/BN | 256 | ||
| 17 | Conv/BN | 512 | ||
| 18 | Max Pool | |||
| 19 | Conv/BN | 1024 | ||
| 20 | Conv/BN | 512 | ||
| 21 | Conv/BN | 1024 | ||
| 22 | Conv/BN | 512 | ||
| 23 | Conv/BN | 1024 | ||
| 24 | Conv/BN | 1024 | ||
| 25 | Conv/BN | 1024 | ||
| 26 | Reorg layer 17 | |||
| 27 | Concat 25 and 26 | |||
| 28 | Conv/BN | 1024 | ||
| 29 | Conv | 125 |
| Backbone | Detector |
|---|---|
| Bag of Freebies | Bag of Freebies |
| Data augmentation | Data augmentation |
| - Mosaic | - Mosaic |
| - CutMix | - Self-adversarial training |
| Regularization | CIoU loss |
| - DropBlock | Cross-mini-batch normalization (CmBN) |
| Class label smoothing | Eliminate grid sensitivity |
| Multiple anchors for a single ground truth | |
| Cosine annealing scheduler | |
| Optimal hyperparameters | |
| Random training shapes | |
| Bag of Specials | Bag of Specials |
| Mish activation | Mish activation |
| Cross-stage partial connections | Spatial pyramid pooling block |
| Multi-input weighted residual connections | Spatial attention module (SAM) |
| Path aggregation network (PAN) | |
| Distance-IoU non-maximum suppression |
| Version | Date | Anchor | Framework | Backbone | AP (%) |
|---|---|---|---|---|---|
| YOLO | 2015 | No | Darknet | Darknet24 | 63.4 |
| YOLOv2 | 2016 | Yes | Darknet | Darknet24 | 78.6 |
| YOLOv3 | 2018 | Yes | Darknet | Darknet53 | |
| YOLOv4 | 2020 | Yes | Darknet | CSPDarknet53 | |
| YOLOv5 | 2020 | Yes | Pytorch | YOLOv5CSPDarknet | |
| PP-YOLO | 2020 | Yes | PaddlePaddle | ResNet50-vd | |
| Scaled-YOLOv4 | 2021 | Yes | Pytorch | CSPDarknet | |
| PP-YOLOv2 | 2021 | Yes | PaddlePaddle | ResNet101-vd | |
| YOLOR | 2021 | Yes | Pytorch | CSPDarknet | |
| YOLOX | 2021 | No | Pytorch | YOLOXCSPDarknet | |
| PP-YOLOE | 2022 | No | PaddlePaddle | CSPRepResNet | |
| YOLOv6 | 2022 | No | Pytorch | EfficientRep | |
| YOLOv7 | 2022 | No | Pytorch | YOLOv7Backbone | |
| DAMO-YOLO | 2022 | No | Pytorch | MAE-NAS | |
| YOLOv8 | 2023 | No | Pytorch | YOLOv8CSPDarknet | |
| YOLO-NAS | 2023 | No | Pytorch | NAS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680-1716. https://doi.org/10.3390/make5040083
Terven J, Córdova-Esparza D-M, Romero-González J-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Machine Learning and Knowledge Extraction. 2023; 5(4):1680-1716. https://doi.org/10.3390/make5040083
Chicago/Turabian StyleTerven, Juan, Diana-Margarita Córdova-Esparza, and Julio-Alejandro Romero-González. 2023. "A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS" Machine Learning and Knowledge Extraction 5, no. 4: 1680-1716. https://doi.org/10.3390/make5040083
APA StyleTerven, J., Córdova-Esparza, D.-M., & Romero-González, J.-A. (2023). A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Machine Learning and Knowledge Extraction, 5(4), 1680-1716. https://doi.org/10.3390/make5040083