
SHapley Additive exPlanations (SHAP) for Efficient Feature Selection in Rolling Bearing Fault Diagnosis


Abstract
1. Introduction
2. Theoretical Background
2.1. Fault Detection and Diagnosis
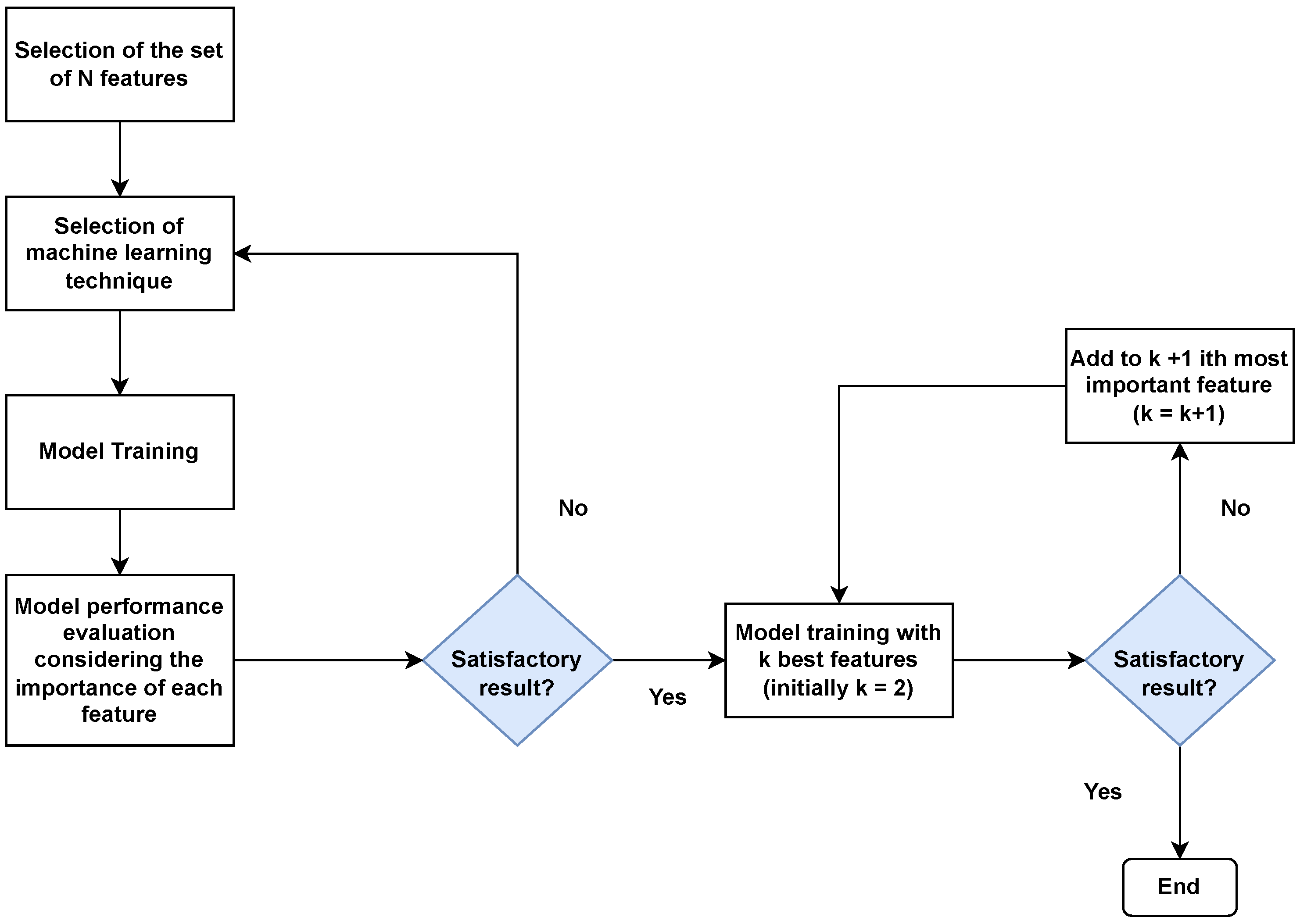
2.2. Feature Selection of ML Models
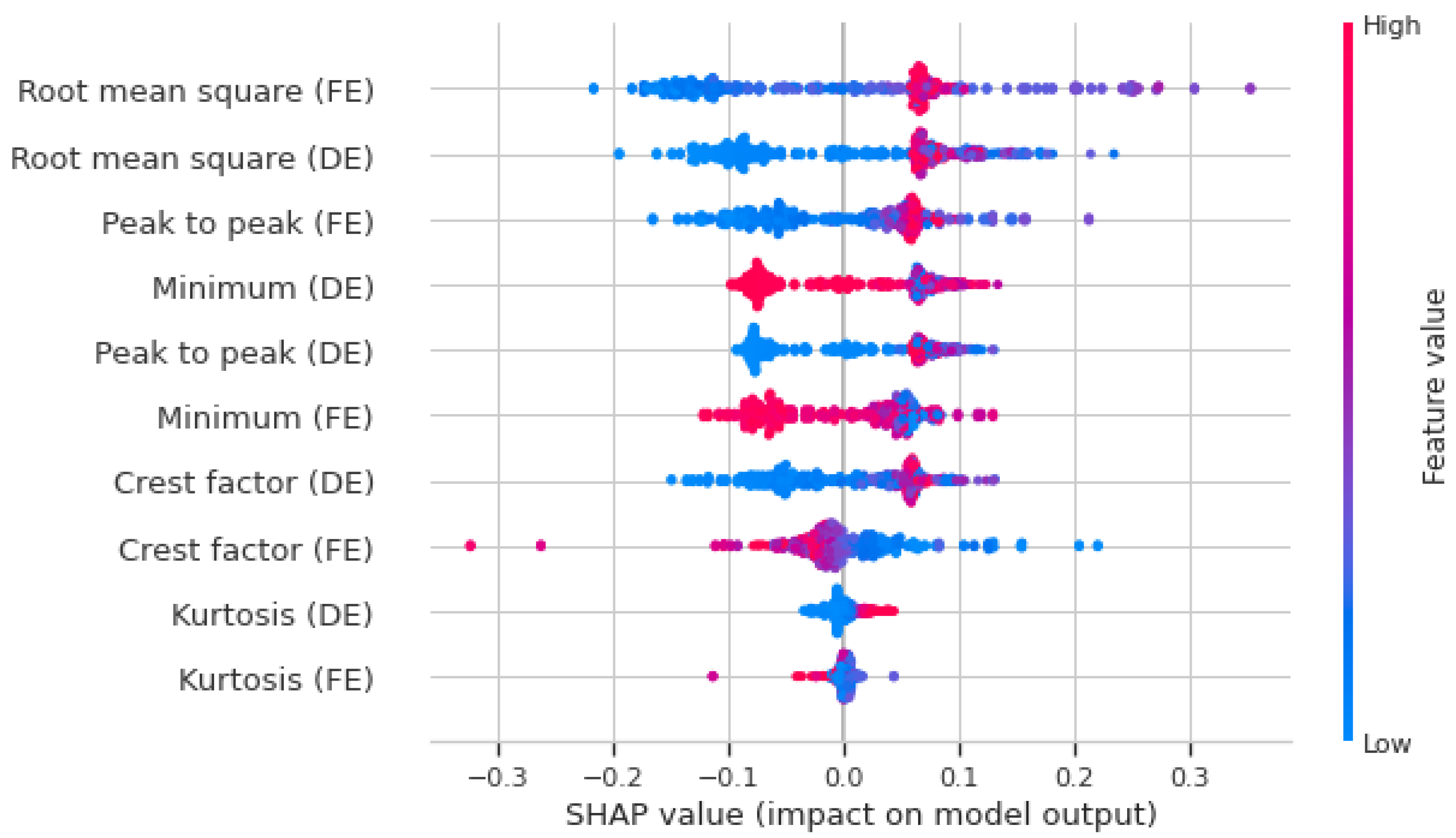
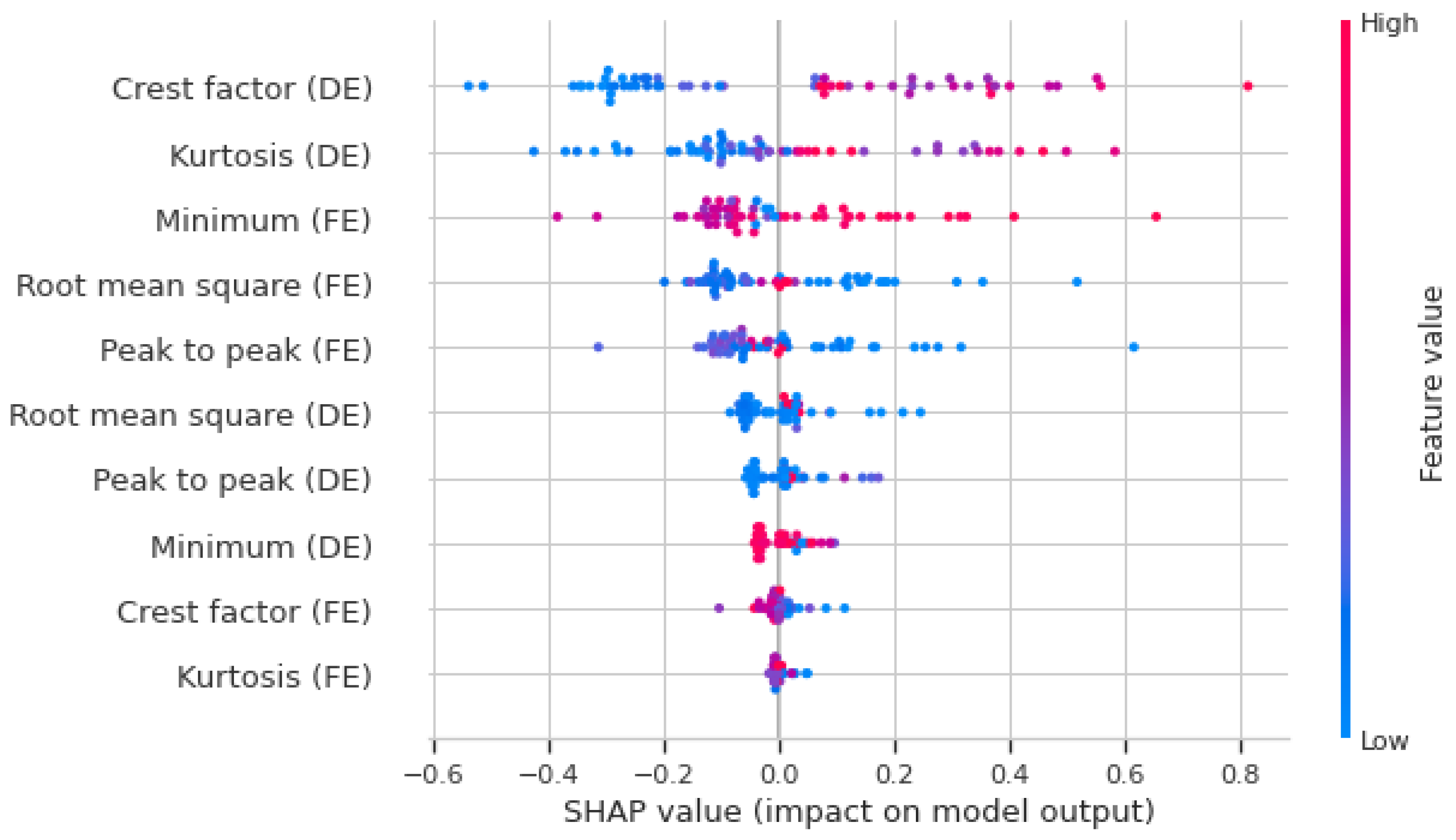
2.3. Explainable Artificial Intelligence (XAI)
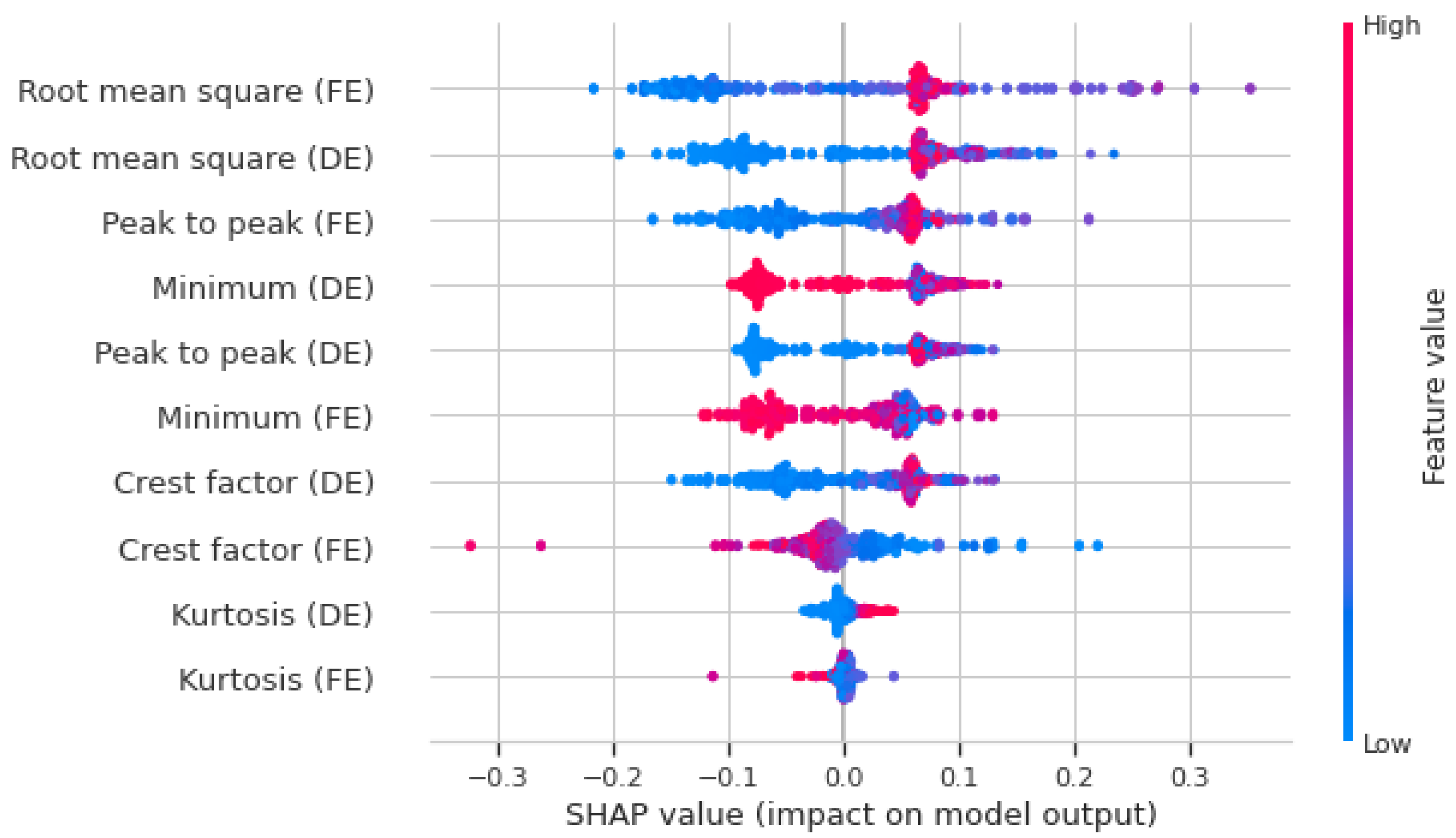
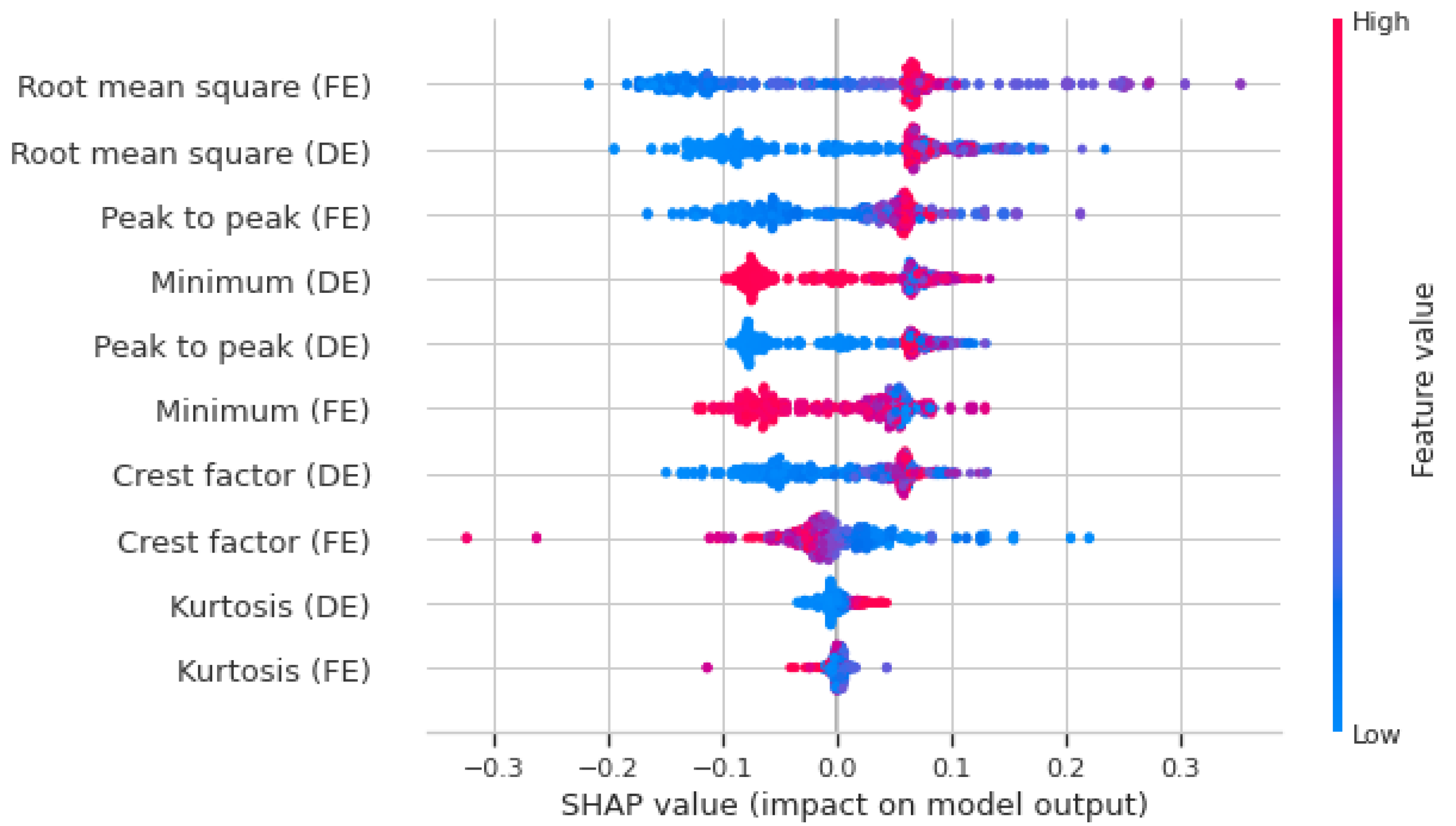
- The vertical position identifies the corresponding feature.
- The horizontal position indicates whether the value’s influence resulted in a higher or lower prediction.
- The color represents whether the data’s value is categorized as high or low.
3. Proposed FDD Approach
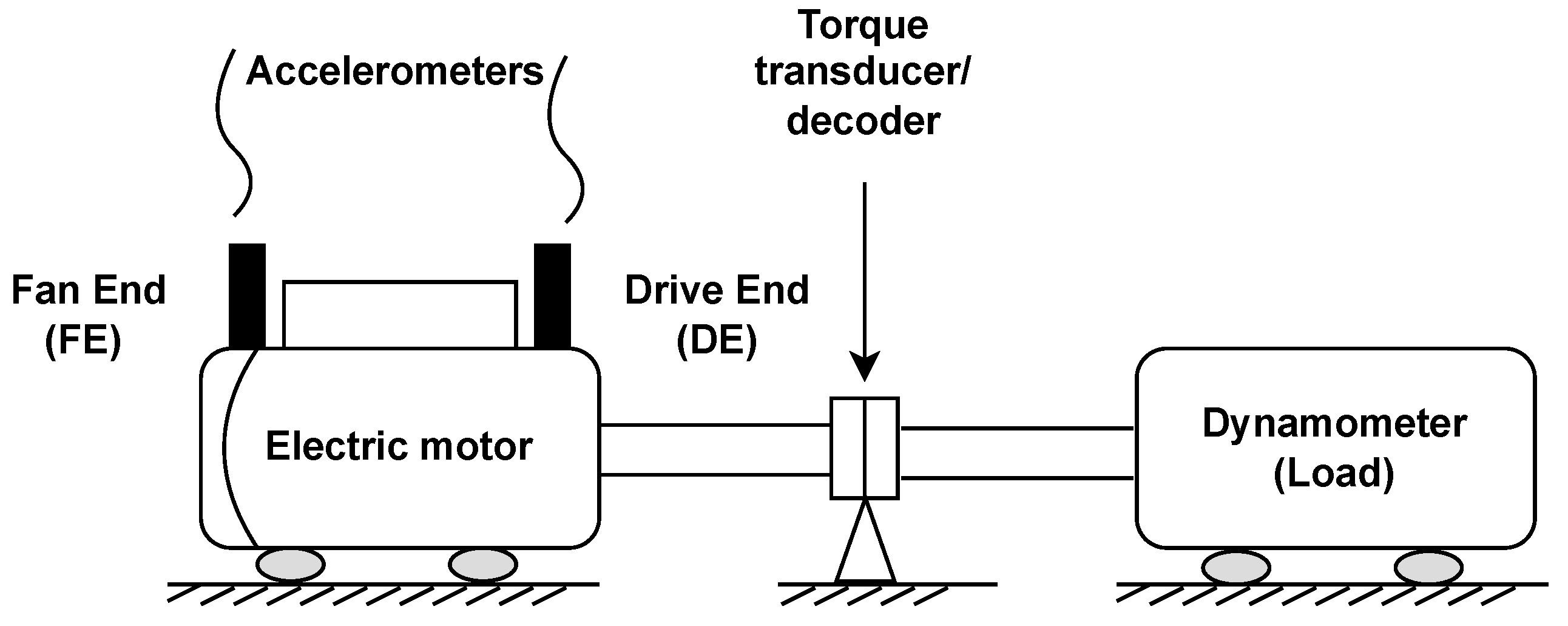
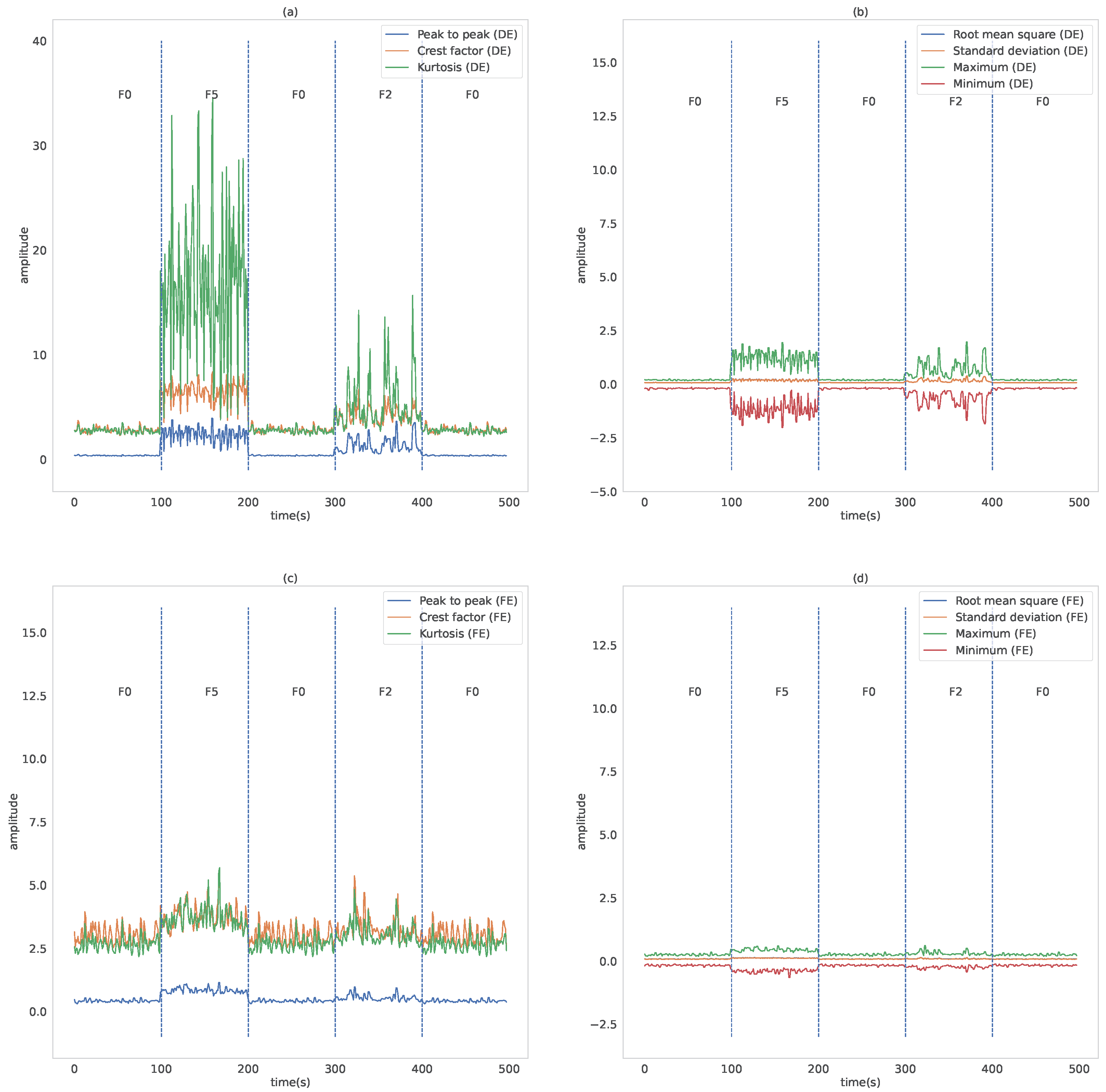
4. Case Study
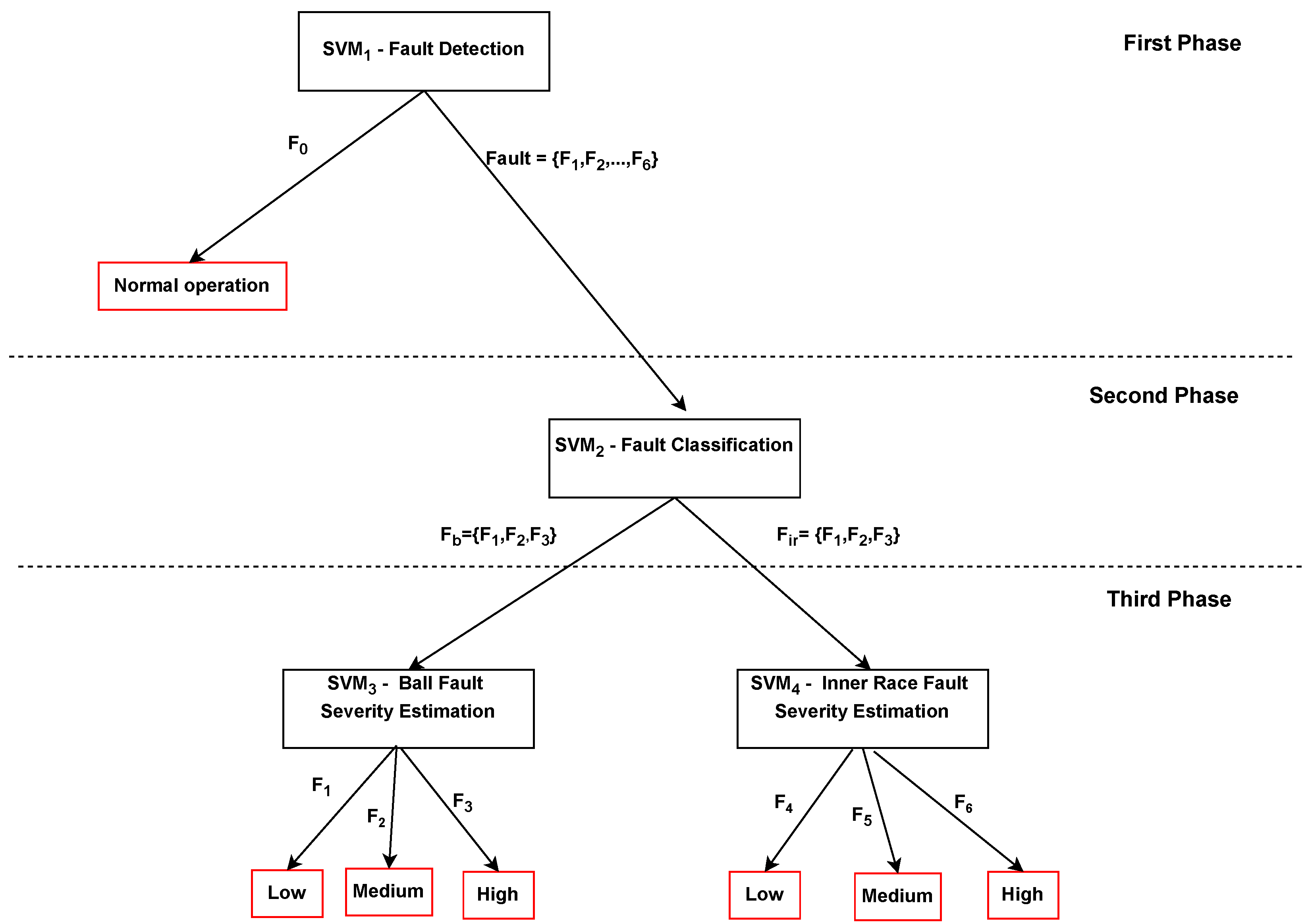
- First phase (fault detection): In this initial phase, a support vector machine (SVM1) is employed to perform fault detection. The SVM1 model is trained to distinguish between normal operation () and any form of fault (). The SVM1 effectively separates the instances of normal operation from those associated with various fault conditions.
- Second phase (fault classification): Building upon the results of the first phase, a second support vector machine (SVM2) is utilized for fault classification. This SVM2 model focuses on the specific fault types, particularly differentiating between Ball Faults (, , ) and Inner Race Faults (, , ). SVM2 discriminates instances belonging to Ball Faults and Inner Race Faults based on their unique characteristics.
- Third phase (fault severity estimation): The final phase encompasses two sub-phases, each dedicated to severity estimation for distinct fault types. For Ball Faults, a dedicated support vector machine (SVM3) is employed. SVM3 classifies the severity of Ball Faults into three levels: low, medium, and high. Similarly, for Inner Race Faults, a separate support vector machine (SVM4) is used for severity estimation. SVM4 divides the Inner Race Faults into three severity categories: low, medium, and high.
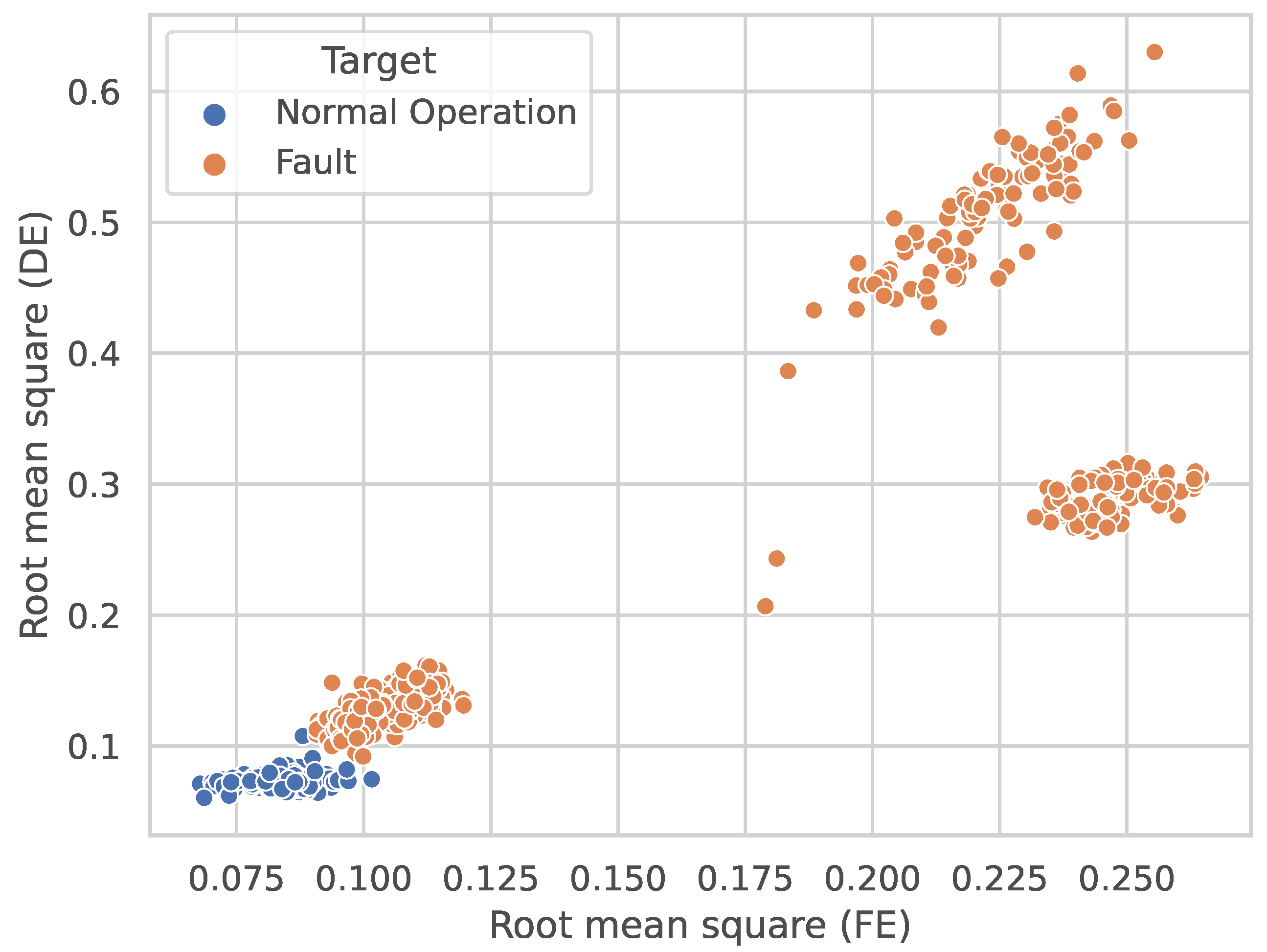
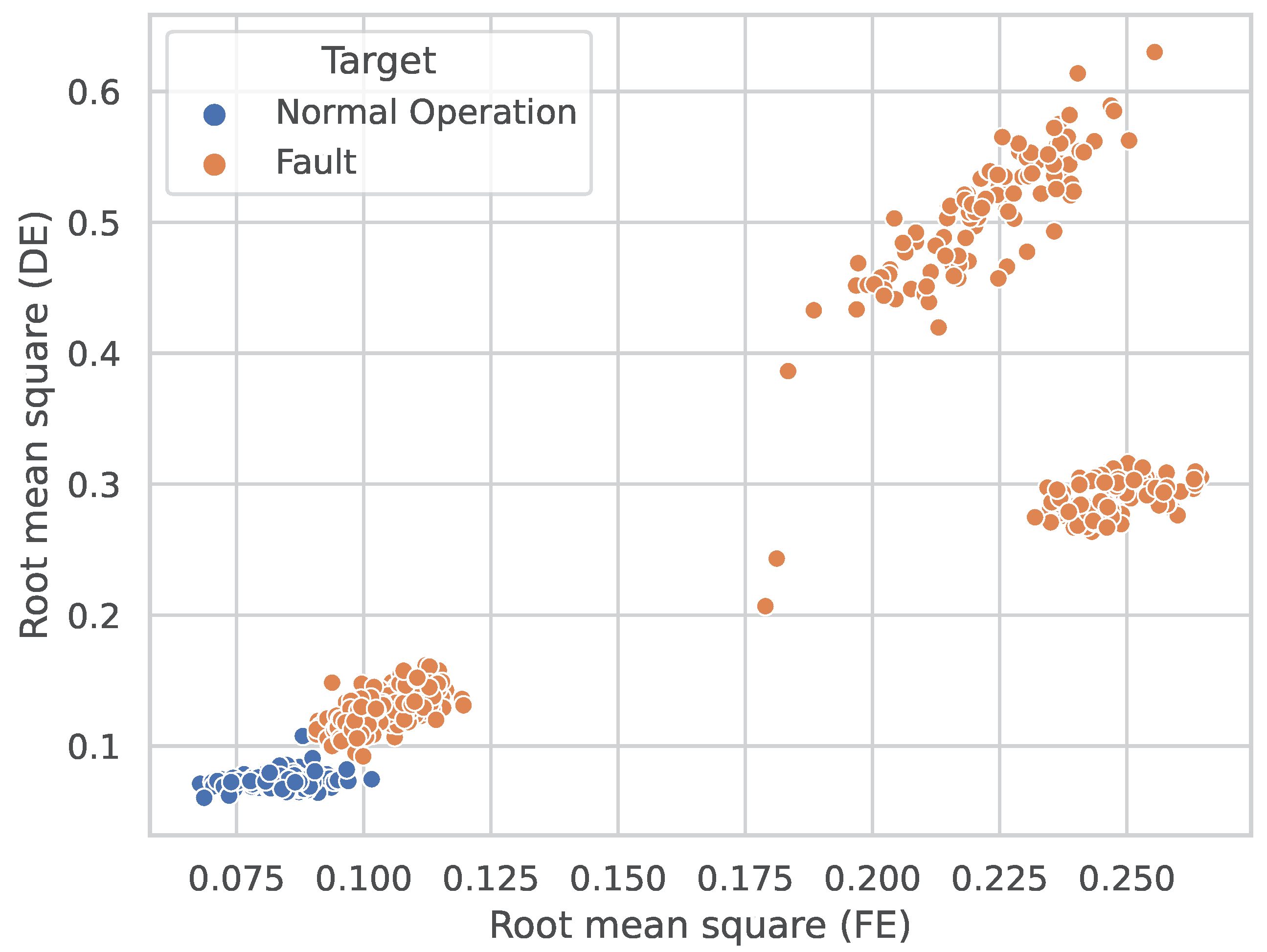
4.1. Fault Detection Phase
4.2. Fault Classification Phase
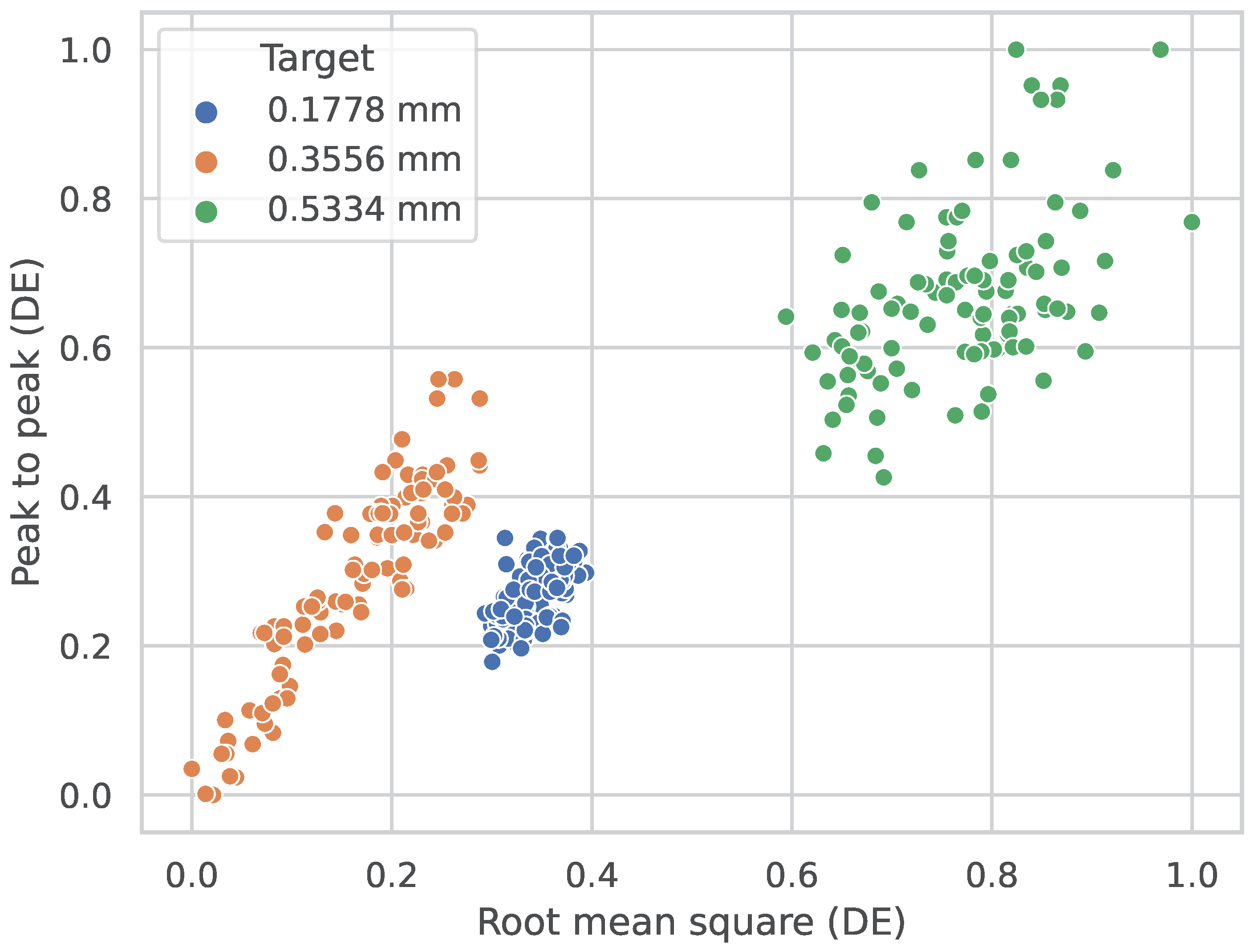
4.3. Fault Severity Estimation Phase
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mikić, D.; Desnica, E.; Ašonja, A.; Stojanovic, B.; Epifanić-Pajić, V. Reliability Analysis of Ball Bearing on the Crankshaft of Piston Compressors. J. Balk. Tribol. Assoc. 2016, 22, 5060–5070. [Google Scholar]
- Randall, R.B.; Antoni, J. Rolling element bearing diagnostics—A tutorial. Mech. Syst. Signal Process. 2011, 25, 485–520. [Google Scholar] [CrossRef]
- Desnica, E.; Ašonja, A.; Radovanović, L.; Palinkaš, I.; Kiss, I. Selection, Dimensioning and Maintenance of Roller Bearings. In Proceedings of the 31st International Conference on Organization and Technology of Maintenance (OTO 2022), Osijek, Croatia, 12 December 2022; Blažević, D., Ademović, N., Barić, T., Cumin, J., Desnica, E., Eds.; Springer: Cham, Switzerland, 2023; pp. 133–142. [Google Scholar]
- Santos, M.R.; Affonso Guedes, L. An Evolving Approach to Fault Detection of Rolling Element Bearings. In Proceedings of the 2021 International Conference on Control, Automation and Diagnosis (ICCAD), Grenoble, France, 3–5 November 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Sharma, A.; Patra, G.K.; Naidu, V. Bearing Fault Classification using Acoustic Features and Artificial Neural Network. In Proceedings of the 2022 4th International Conference on Circuits, Control, Communication and Computing (I4C), Bangalore, India, 21–23 December 2022; pp. 421–425. [Google Scholar] [CrossRef]
- Pastukhov, A.; Timashov, E.; Stanojević, D. Temperature Conditions and Diagnostics of Bearings. Appl. Eng. Lett. J. Eng. Appl. Sci. 2023, 8, 45–51. [Google Scholar] [CrossRef]
- Wakiru, J.; Pintelon, L.; Muchiri, P.; Chemweno, P. A data mining approach for lubricant-based fault diagnosis. J. Qual. Maint. Eng. 2020, 27, 264–291. [Google Scholar] [CrossRef]
- Cerrada, M.; Sánchez, R.V.; Li, C.; Pacheco, F.; Cabrera, D.; Valente de Oliveira, J.; Vásquez, R.E. A review on data-driven fault severity assessment in rolling bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Nelson, W.; Culp, C. FDD in Building Systems Based on Generalized Machine Learning Approaches. Energies 2023, 16, 1637. [Google Scholar] [CrossRef]
- Mohamad, T.H.; Nataraj, C. Fault identification and severity analysis of rolling element bearings using phase space topology. J. Vib. Control 2021, 27, 295–310. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Shenfield, A.; Howarth, M. A Novel Deep Learning Model for the Detection and Identification of Rolling Element-Bearing Faults. Sensors 2020, 20, 5112. [Google Scholar] [CrossRef]
- Han, H.; Gu, B.; Wang, T.; Li, Z. Important sensors for chiller fault detection and diagnosis (FDD) from the perspective of feature selection and machine learning. Int. J. Refrig. 2011, 34, 586–599. [Google Scholar] [CrossRef]
- Kim, M.Y.; Atakishiyev, S.; Babiker, H.K.B.; Farruque, N.; Goebel, R.; Zaïane, O.R.; Motallebi, M.H.; Rabelo, J.; Syed, T.; Yao, H.; et al. A Multi-Component Framework for the Analysis and Design of Explainable Artificial Intelligence. Mach. Learn. Knowl. Extr. 2021, 3, 900–921. [Google Scholar] [CrossRef]
- Hulsen, T. Explainable Artificial Intelligence (XAI): Concepts and Challenges in Healthcare. AI 2023, 4, 652–666. [Google Scholar] [CrossRef]
- Ghnemat, R.; Alodibat, S.; Abu Al-Haija, Q. Explainable Artificial Intelligence (XAI) for Deep Learning Based Medical Imaging Classification. J. Imaging 2023, 9, 177. [Google Scholar] [CrossRef]
- Clement, T.; Kemmerzell, N.; Abdelaal, M.; Amberg, M. XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process. Mach. Learn. Knowl. Extr. 2023, 5, 78–108. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4765–4774. [Google Scholar]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Bezerra, C.G.; Costa, B.S.J.; Guedes, L.A.; Angelov, P.P. An evolving approach to unsupervised and Real-Time fault detection in industrial processes. Expert Syst. Appl. 2016, 63, 134–144. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Yin, K.; Kavuri, S.N. A review of process fault detection and diagnosis: Part I: Quantitative model-based methods. Comput. Chem. Eng. 2003, 27, 293–311. [Google Scholar] [CrossRef]
- Wang, P.; Guo, C. Based on the coal mine’s essential safety management system of safety accident cause analysis. Am. J. Environ. Energy Power Res. 2013, 1, 62–68. [Google Scholar]
- Li, Z.; Wang, Y.; Wang, K.S. Intelligent predictive maintenance for fault diagnosis and prognosis in machine centers: Industry 4.0 scenario. Adv. Manuf. 2017, 5, 377–387. [Google Scholar] [CrossRef]
- Del Buono, F.; Calabrese, F.; Baraldi, A.; Paganelli, M.; Guerra, F. Novelty Detection with Autoencoders for System Health Monitoring in Industrial Environments. Appl. Sci. 2022, 12, 4931. [Google Scholar] [CrossRef]
- Jalayer, M.; Kaboli, A.; Orsenigo, C.; Vercellis, C. Fault Detection and Diagnosis with Imbalanced and Noisy Data: A Hybrid Framework for Rotating Machinery. Machines 2022, 10, 237. [Google Scholar] [CrossRef]
- Yin, L.; Wang, H.; Fan, W.; Kou, L.; Lin, T.; Xiao, Y. Incorporate active learning to semi-supervised industrial fault classification. J. Process Control 2019, 78, 88–97. [Google Scholar] [CrossRef]
- Sorsa, T.; Koivo, H.N.; Koivisto, H. Neural networks in process fault diagnosis. IEEE Trans. Syst. Man, Cybern. 1991, 21, 815–825. [Google Scholar] [CrossRef]
- Ayoubi, M. Nonlinear dynamic systems identification with dynamic neural networks for fault diagnosis in technical processes. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 2–5 October 1994; Volume 3, pp. 2120–2125. [Google Scholar]
- Khan, S.; Yairi, T. A review on the application of deep learning in system health management. Mech. Syst. Signal Process. 2018, 107, 241–265. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar] [CrossRef]
- Ganesh, S.; Beucler, T.; Tam, F.; Gomez, M.; Runge, J.; Gerhardus, A. Selecting robust features for machine-learning applications using multidata causal discovery. Environ. Data Sci. 2023, 2, e27. [Google Scholar] [CrossRef]
- Du, S.C.; Liu, T.; Huang, D.L.; Li, G.L. An Optimal Ensemble Empirical Mode Decomposition Method for Vibration Signal Decomposition. J. Vib. Acoust. 2017, 139, 031003. [Google Scholar] [CrossRef]
- Sreejith, B.; Verma, A.; Srividya, A. Fault diagnosis of rolling element bearing using time domain features and neural networks. In Proceedings of the 2008 IEEE Region 10 and the Third international Conference on Industrial and Information Systems, Kharagpur, India, 8–10 December 2008; pp. 1–6. [Google Scholar] [CrossRef]
- Yiakopoulos, C.; Gryllias, K.; Antoniadis, I. Rolling element bearing fault detection in industrial environments based on a K-means clustering approach. Expert Syst. Appl. 2011, 38, 2888–2911. [Google Scholar] [CrossRef]
- Dhamande, L.S.; Chaudhari, M.B. Compound gear-bearing fault feature extraction using statistical features based on time-frequency method. Measurement 2018, 125, 63–77. [Google Scholar] [CrossRef]
- Grover, C.; Turk, N. Optimal Statistical Feature Subset Selection for Bearing Fault Detection and Severity Estimation. Shock Vib. 2020, 2020, 5742053. [Google Scholar] [CrossRef]
- Nayana, B.R.; Geethanjali, P. Analysis of Statistical Time-Domain Features Effectiveness in Identification of Bearing Faults from Vibration Signal. IEEE Sens. J. 2017, 17, 5618–5625. [Google Scholar] [CrossRef]
- Zhan, L.; Ma, F.; Zhang, J.; Li, C.; Li, Z.; Wang, T. Fault Feature Extraction and Diagnosis of Rolling Bearings Based on Enhanced Complementary Empirical Mode Decomposition with Adaptive Noise and Statistical Time-Domain Features. Sensors 2019, 19, 4047. [Google Scholar] [CrossRef] [PubMed]
- Seryasat, O.; Aliyari shoorehdeli, M.; Honarvar, F.; Rahmani, A. Multi-fault diagnosis of Ball bearing using FFT, wavelet energy entropy mean and root mean square (RMS). In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 4295–4299. [Google Scholar] [CrossRef]
- Xiang, C.; Ren, Z.; Shi, P.; Zhao, H. Data-Driven Fault Diagnosis for Rolling Bearing Based on DIT-FFT and XGBoost. Complexity 2021, 2021, 4941966. [Google Scholar] [CrossRef]
- Cocconcelli, M.; Zimroz, R.; Rubini, R.; Bartelmus, W. STFT Based Approach for Ball Bearing Fault Detection in a Varying Speed Motor. In Condition Monitoring of Machinery in Non-Stationary Operations; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Gao, H.; Liang, L.; Chen, X.; Xu, G. Feature extraction and recognition for rolling element bearing fault utilizing short-time Fourier transform and non-negative matrix factorization. Chin. J. Mech. Eng. 2014, 28, 96–105. [Google Scholar] [CrossRef]
- Tao, H.; Wang, P.; Chen, Y.; Stojanovic, V.; Yang, H. An unsupervised fault diagnosis method for rolling bearing using STFT and generative neural networks. J. Frankl. Inst. 2020, 357, 7286–7307. [Google Scholar] [CrossRef]
- Kankar, P.; Sharma, S.C.; Harsha, S. Rolling element bearing fault diagnosis using autocorrelation and continuous wavelet transform. J. Vib. Control 2011, 17, 2081–2094. [Google Scholar] [CrossRef]
- Kankar, P.; Sharma, S.C.; Harsha, S. Rolling element bearing fault diagnosis using wavelet transform. Neurocomputing 2011, 74, 1638–1645. [Google Scholar] [CrossRef]
- Konar, P.; Chattopadhyay, P. Bearing fault detection of induction motor using wavelet and Support Vector Machines (SVMs). Appl. Soft Comput. 2011, 11, 4203–4211. [Google Scholar] [CrossRef]
- Patil, A.B.; Gaikwad, J.A.; Kulkarni, J.V. Bearing fault diagnosis using discrete Wavelet Transform and Artificial Neural Network. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bangalore, India, 21–23 July 2016; pp. 399–405. [Google Scholar] [CrossRef]
- Yang, D.M. The Detection of Motor Bearing Fault with Maximal Overlap Discrete Wavelet Packet Transform and Teager Energy Adaptive Spectral kurtosis. Sensors 2021, 21, 6895. [Google Scholar] [CrossRef]
- Anbu, S.; Thangavelu, A.; Ashok, S.D. Fuzzy C-Means Based Clustering and Rule Formation Approach for Classification of Bearing Faults Using Discrete Wavelet Transform. Computation 2019, 7, 54. [Google Scholar] [CrossRef]
- Liang, L.; Shan, L.; Liu, F.; Niu, B.; Xu, G. Sparse Envelope Spectra for Feature Extraction of Bearing Faults Based on NMF. Appl. Sci. 2019, 9, 755. [Google Scholar] [CrossRef]
- Liu, Y.; Qian, Q.; Liu, F.; Lu, S.; He, Q.; Zhao, J. Wayside Bearing Fault Diagnosis Based on Envelope Analysis Paved with Time-Domain Interpolation Resampling and Weighted-Correlation-Coefficient-Guided Stochastic Resonance. Shock Vib. 2017, 2017, 3189135. [Google Scholar] [CrossRef]
- Leite, V.C.M.N.; Borges da Silva, J.G.; Veloso, G.F.C.; Borges da Silva, L.E.; Lambert-Torres, G.; Bonaldi, E.L.; de Lacerda de Oliveira, L.E. Detection of Localized Bearing Faults in Induction Machines by Spectral kurtosis and Envelope Analysis of Stator Current. IEEE Trans. Ind. Electron. 2015, 62, 1855–1865. [Google Scholar] [CrossRef]
- Ben Ali, J.; Fnaiech, N.; Saidi, L.; Chebel-Morello, B.; Fnaiech, F. Application of empirical mode decomposition and artificial neural network for automatic bearing fault diagnosis based on vibration signals. Appl. Acoust. 2015, 89, 16–27. [Google Scholar] [CrossRef]
- Zhang, X.; Liang, Y.; Zhou, J.; Zang, Y. A novel bearing fault diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized SVM. Measurement 2015, 69, 164–179. [Google Scholar] [CrossRef]
- Mohanty, S.; Gupta, K.K.; Raju, K.S. Adaptive fault identification of bearing using empirical mode decomposition–principal component analysis-based average kurtosis technique. IET Sci. Meas. Technol. 2017, 11, 30–40. [Google Scholar] [CrossRef]
- Nishat Toma, R.; Kim, C.H.; Kim, J.M. Bearing Fault Classification Using Ensemble Empirical Mode Decomposition and Convolutional Neural Network. Electronics 2021, 10, 1248. [Google Scholar] [CrossRef]
- Peres, F.A.P.; Fogliatto, F.S. Variable selection methods in multivariate statistical process control: A systematic literature review. Comput. Ind. Eng. 2018, 115, 603–619. [Google Scholar] [CrossRef]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar] [CrossRef]
- Ali, S.; Abuhmed, T.; El-Sappagh, S.; Muhammad, K.; Alonso-Moral, J.M.; Confalonieri, R.; Guidotti, R.; Del Ser, J.; Díaz-Rodríguez, N.; Herrera, F. Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence. Inf. Fusion 2023, 99, 101805. [Google Scholar] [CrossRef]
- Machlev, R.; Heistrene, L.; Perl, M.; Levy, K.; Belikov, J.; Mannor, S.; Levron, Y. Explainable Artificial Intelligence (XAI) techniques for energy and power systems: Review, challenges and opportunities. Energy AI 2022, 9, 100169. [Google Scholar] [CrossRef]
- Longo, L.; Brcic, M.; Cabitza, F.; Choi, J.; Confalonieri, R.; Del Ser, J.; Guidotti, R.; Hayashi, Y.; Herrera, F.; Holzinger, A.; et al. Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions. arXiv 2023, arXiv:2310.19775. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Rodríguez-Pérez, R.; Bajorath, J. Interpretation of Compound Activity Predictions from Complex Machine Learning Models Using Local Approximations and Shapley Values. J. Med. Chem. 2019, 63, 8761–8777. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 2522–5839. [Google Scholar] [CrossRef] [PubMed]
- Delgado, M.; Cirrincione, G.; García, A.; Ortega, J.A.; Henao, H. Accurate bearing faults classification based on statistical-time features, curvilinear component analysis and neural networks. In Proceedings of the IECON 2012—38th Annual Conference on IEEE Industrial Electronics Society, Montreal, QC, Canada, 25–28 October 2012; pp. 3854–3861. [Google Scholar] [CrossRef]
- Neupane, D.; Seok, J. Bearing Fault Detection and Diagnosis Using Case Western Reserve University Dataset with Deep Learning Approaches: A Review. IEEE Access 2020, 8, 93155–93178. [Google Scholar] [CrossRef]
- Rácz, A.; Bajusz, D.; Héberger, K. Effect of Dataset Size and Train/Test Split Ratios in QSAR/QSPR Multiclass Classification. Molecules 2021, 26, 1111. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # Fault | Fault Type | Fault Severity Estimation (Diameter in Millimeters mm) |
|---|---|---|
| No Fault | 0.000 | |
| Ball Fault— | 0.1778 | |
| Ball Fault— | 0.3556 | |
| Ball Fault— | 0.5334 | |
| Inner Race— | 0.1778 | |
| Inner Race— | 0.3556 | |
| Inner Race— | 0.5334 |
| Number of Features (k) | Accuracy (%) |
|---|---|
| 2 | 97% |
| 3 | 97% |
| 4 | 95% |
| 5 | 95% |
| 6 | 97% |
| 7 | 97% |
| 8 | 95% |
| 9 | 95% |
| 10 | 96% |
| Number of Features (k) | Accuracy (%) |
|---|---|
| 2 | 100% |
| 3 | 100% |
| 4 | 100% |
| 5 | 100% |
| 6 | 100% |
| 7 | 100% |
| 8 | 100% |
| 9 | 100% |
| 10 | 100% |
| Number of Features (k) | Accuracy (%) |
|---|---|
| 2 | 93% |
| 3 | 93% |
| 4 | 95% |
| 5 | 96% |
| 6 | 96% |
| 7 | 96% |
| 8 | 88% |
| 9 | 95% |
| 10 | 88% |
| Number of Features (k) | Accuracy (%) |
|---|---|
| 2 | 50% |
| 3 | 70% |
| 4 | 83% |
| 5 | 73% |
| 6 | 75% |
| 7 | 77% |
| 8 | 77% |
| 9 | 75% |
| 10 | 75% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santos, M.R.; Guedes, A.; Sanchez-Gendriz, I. SHapley Additive exPlanations (SHAP) for Efficient Feature Selection in Rolling Bearing Fault Diagnosis. Mach. Learn. Knowl. Extr. 2024, 6, 316-341. https://doi.org/10.3390/make6010016
Santos MR, Guedes A, Sanchez-Gendriz I. SHapley Additive exPlanations (SHAP) for Efficient Feature Selection in Rolling Bearing Fault Diagnosis. Machine Learning and Knowledge Extraction. 2024; 6(1):316-341. https://doi.org/10.3390/make6010016
Chicago/Turabian StyleSantos, Mailson Ribeiro, Affonso Guedes, and Ignacio Sanchez-Gendriz. 2024. "SHapley Additive exPlanations (SHAP) for Efficient Feature Selection in Rolling Bearing Fault Diagnosis" Machine Learning and Knowledge Extraction 6, no. 1: 316-341. https://doi.org/10.3390/make6010016
APA StyleSantos, M. R., Guedes, A., & Sanchez-Gendriz, I. (2024). SHapley Additive exPlanations (SHAP) for Efficient Feature Selection in Rolling Bearing Fault Diagnosis. Machine Learning and Knowledge Extraction, 6(1), 316-341. https://doi.org/10.3390/make6010016