
Effective Data Reduction Using Discriminative Feature Selection Based on Principal Component Analysis



Abstract
1. Introduction
2. Literature Review
3. Study Background
3.1. Brief Overview of the Datasets
Datasets
- i.
- The Arrhythmia Dataset: This dataset was generated to predict the presence or absence of cardiac arrhythmia and classify the cardiac arrhythmia within the 16 classes of the dataset [19].
- ii.
- The Madelon Dataset: The Madelon Dataset was generated as AI data that contains data points that are grouped into 32 clusters that are placed on the vertices of hypercubes with five dimensions and are labeled randomly as +1 or −1. These five dimensions represent features with information, while 15 additional linear combinations of the informative features were added to make this number 20, with the 15 being redundant. The goal of the experiment is to classify the 20 features into +1 and −1. Probe features were added to the dataset as distractions, with them holding no prediction power. They served as distractions to test the power of the algorithm [20].
- iii.
- The Gissette Dataset: This is one of the five datasets that was used in the NIPS 2003 challenge for feature selection. The dataset is made up of a fixed-sized dimensional image of 28 × 28 containing digits that are size-normalized and that are placed at the center of the image. The images contain pixel features that were sampled randomly at the middle–top of the features that contain the necessary information to identify four from nine, and higher dimensional features were created from these features to cast the challenge to a higher dimensional feature space. Features that serve as a distraction were added, with them being called probes and having no power in prediction [21].
- iv.
- The Ionosphere Dataset: This is a radar dataset with targets as free electrons present in the ionosphere. The class is such that ‘good’ radar should return some evidence that contains a specific kind of structure in the ionosphere, while ‘bad’ radar does not return such structural evidence [22].
- v.
- The IoT Intrusion Data: This is a large proprietary IoT dataset, with intrusions having 115 features. A fraction was used due to volume and computing speed constraints, giving a subset of 80,037 samples and 115 features.
3.2. Principal Component Analysis (PCA)
- View—The perspective (angle of sight) through which the data points are viewed (observed).
- Dimension—The columns in a dataset. This is the same as the feature.
- Projections—This is the perpendicular distance that exists between the data points and the principal components.
- Principal Components—These are the new variables that are constructed as linear combinations or mixtures of the supplied initial variables.
3.3. Singular Value Decomposition (SVD)
3.4. Problem Statement
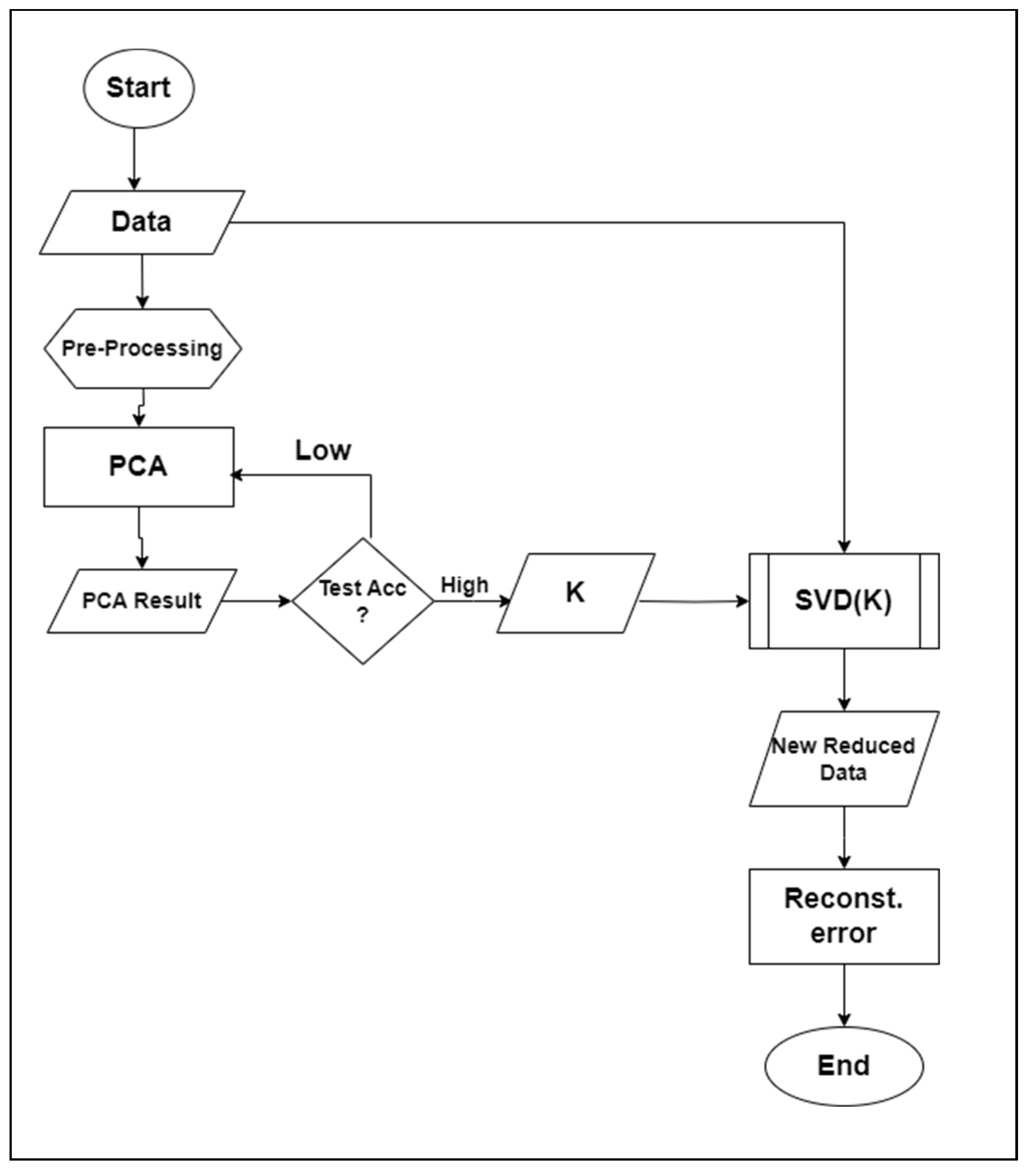
4. Proposed Methodology
Algorithm
- Data exploration—explore the data to check their features and balance.
- Data preprocessing—perform data cleaning and train/test set division.
- PCA implementation—perform PCA transformation, selecting N-components such that the dataset An,m >> Xk,m.
- Test the accuracy with a model and repeat until the best N-components (top-K features) are realized.
- Implement SVD using the chosen N-component numbers.
- A new dataset is produced.
- Test the new dataset with a model to test the accuracy.
- Calculate the reconstruction error.
5. Performance Evaluation, Results, and Discussion
5.1. Performance Evaluation
5.2. Result
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kavitha, R.; Kannan, E. An efficient framework for heart disease classification using feature extraction and feature selection technique in data mining. In Proceedings of the 2016 International Conference on Emerging Trends in Engineering, Technology and Science (ICETETS), Pudukkottai, India, 24–26 February 2016; pp. 1–5. [Google Scholar]
- Kale, A.P.; Sonavane, S. PF-FELM: A Robust PCA Feature Selection for Fuzzy Extreme Learning Machine. IEEE J. Sel. Top. Signal Process. 2018, 12, 1303–1312. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Cui, Y.; Fang, Y. Research on PCA Data Dimension Reduction Algorithm Based on Entropy Weight Method. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 392–396. [Google Scholar]
- Ibrahim, M.F.I.; Al-Jumaily, A.A. PCA indexing based feature learning and feature selection. In Proceedings of the 2016 8th Cairo International Biomedical Engineering Conference (CIBEC), Cairo, Egypt, 15–17 December 2016; pp. 68–71. [Google Scholar]
- Kane, A.; Shiri, N. Selecting the Top-K Discriminative Feature Using Principal Component Analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops, Barcelona, Spain, 12–15 December 2016; pp. 639–646. [Google Scholar]
- Chandak, T.; Ghorpade, C.; Shukla, S. Effective Analysis of Feature Selection Algorithms for Network based Intrusion Detection System. In Proceedings of the 2019 IEEE Bombay Section Signature Conference (IBSSC), Mumbai, India, 26–28 July 2019. [Google Scholar]
- Shah, H.; Verma, K. Voltage stability monitoring by different ANN architectures using PCA based feature selection. In Proceedings of the 2016 IEEE 7th Power India International Conference (PIICON), Bikaner, India, 25–27 November 2016; pp. 1–6. [Google Scholar]
- Ahmadi, S.S.; Rashad, S.; Elgazzar, H. Efficient Feature Selection for Intrusion Detection Systems. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019. [Google Scholar]
- Sagar, S.; Shrivastava, A.; Gupta, C. Feature Reduction and Selection Based Optimization for Hybrid Intrusion Detection System Using PGO followed by SVM. In Proceedings of the 2018 International Conference on Advanced Computation and Telecommunication (ICACAT), Bhopal, India, 28–29 December 2018. [Google Scholar]
- Khonde, S.R.; Ulagamuthalvi, D.V. Ensemble and Feature Selection-Based Intrusion Detection System for Multi-attack Environment. In Proceedings of the 2020 5th International Conference on Computing, Communication and Security (ICCCS), Patna, India, 14–16 October 2020. [Google Scholar]
- Nkiama, H.; Said, S.Z.M.; Saidu, M. A Subset Feature Elimination Mechanism for Intrusion Detection System. (IJACSA) Int. J. Adv. Comput. Sci. Appl. 2016, 7, 148–157. [Google Scholar] [CrossRef]
- Hakim, L.; Fatma, R.; Novriandi. Influence Analysis for Feature Selection to Network Intrusion Detection System Performance Using NSL-KDD Dataset. In Proceedings of the 2019 International Conference on Computer Science, Information Technology, and Electrical Engineering (ICOMITEE), Jember, Indonesia, 16–17 October 2019. [Google Scholar]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the myopia of inductive learning algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- Li, Y.; Shi, K.; Qiao, F.; Luo, H. A Feature Subset Selection Method Based on the Combination of PCA and Improved GA. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 191–194. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Wiley Online Library: Hoboken, NJ, USA, 2014. [Google Scholar]
- Patil, G.V.; Pachghare, K.V.; Kshirsagar, D.D. Feature Reduction in Flow Based Intrusion Detection System. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT-2018), Bangalore, India, 18–19 May 2018; pp. 1356–1362. [Google Scholar]
- Divekar, A.; Parekh, M.; Savla, V.; Mishra, R. Benchmarking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives. In Proceedings of the 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Kathmandu, Nepal, 25–27 October 2018. [Google Scholar]
- UCI Machine Learning Repository. Arrhythmia Data Set. Available online: https://archive.ics.uci.edu/dataset/5/arrhythmia (accessed on 14 March 2024).
- UCI Machine Learning Repository. Madelon Data Set. Available online: https://archive.ics.uci.edu/dataset/171/madelon (accessed on 14 March 2024).
- UCI Machine Learning Repository. Gisette Data Set. Available online: https://archive.ics.uci.edu/dataset/170/gisette (accessed on 14 March 2024).
- UCI Machine Learning Repository. Ionosphere Data Set. Available online: https://archive.ics.uci.edu/dataset/52/ionosphere (accessed on 14 March 2024).
- Simplilearn. What Is Data Standardization? Available online: https://www.simplilearn.com/what-is-data-standardization-article#:~:text=Data%20standardization%20is%20converting%20data,YYYY%2DMM%2DDD (accessed on 14 March 2024).
- Choudhary, A. Understanding the Covariance Matrix. DataScience+. Available online: https://datascienceplus.com/understanding-the-covariance-matrix/ (accessed on 14 March 2024).
- Wikipedia. Singular Value Decomposition. Available online: https://en.wikipedia.org/wiki/Singular_value_decomposition (accessed on 14 March 2024).
- Guruswami, V. Chapter 4: Error-Correcting Codes. Carnegie Mellon University. Available online: https://www.cs.cmu.edu/~venkatg/teaching/CStheory-infoage/book-chapter-4.pdf (accessed on 14 March 2024).
- Megantara, A.A.; Ahmad, T. Feature Importance Ranking for Increasing Performance of Intrusion Detection System. In Proceedings of the 2020 3rd International Conference on Computer and Information Engineering (IC2IE), Beijing, China, 14–16 August 2020; pp. 37–42. [Google Scholar]
- Ekici, B.; Tarhan, A.; Ozsoy, A. Data Cleaning for Process Mining with Smart Contract. In Proceedings of the (UBMK’19) 4th International Conference on Computer Science and Engineering-324, Samsun, Turkey, 11–15 September 2019. [Google Scholar]
- Jollife, I.T.; Cadima, J. Principal Component Analysis: A Review and Recent Developments. Philos. Trans. R. Soc. A 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Junaid, A. Metrics to Evaluate Your Machine Learning Algorithm. Towards Data Science. Available online: https://towardsdatascience.com/metrics-to-evaluate-your-machine-learning-algorithm-f10ba6e38234 (accessed on 14 March 2024).







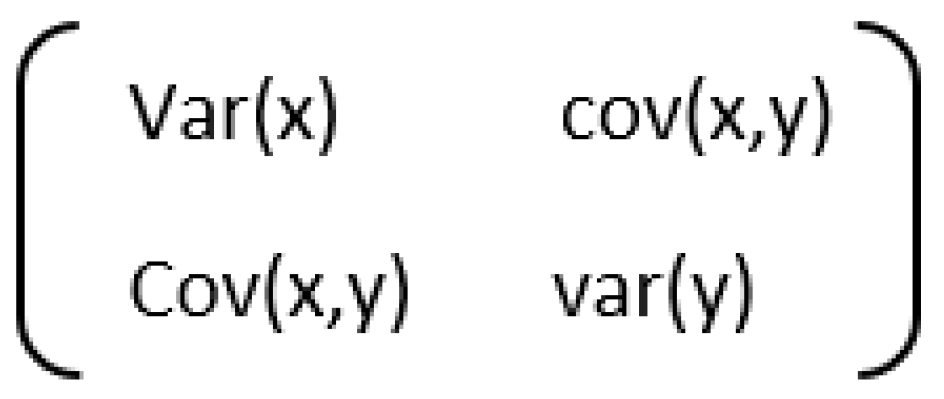{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | N_Samples | N_Features | Class |
|---|---|---|---|
| Arrhythmia | 452 | 279 | 16 |
| Ionosphere | 351 | 34 | 2 |
| Madelon | 2000 | 502 | 2 |
| Gissette | 5999 | 5000 | 2 |
| IoT Intrusion | 80,037 | 115 | 5 |
| Dataset | SVD Reconstruction Error | Test Accuracy | Inference_Time (s) | N_Samples | N_Features | Top-k Components |
|---|---|---|---|---|---|---|
| Arrhythmia | 0.715595 | 0.604396 | 0.012478 | 452 | 279 | 13 |
| Ionosphere | 0.364809 | 0.971831 | 0.013278 | 351 | 34 | 15 |
| Madelon | 0.978347 | 0.785000 | 0.020385 | 2000 | 502 | 5 |
| Gissette | 0.828217 | 0.971972 | 0.035977 | 5999 | 5000 | 89 |
| IoT Intrusion | 0.068727 | 0.974825 | 0.671137 | 80037 | 115 | 29 |
| Dataset | SVD Reconstruction Error | Test Accuracy | N_Features | Top-k Components | Ratio of SVD Selected Features to Original Features |
|---|---|---|---|---|---|
| Arrhythmia | 0.715595 | 0.604396 | 279 | 13 | 0.0466 |
| Ionosphere | 0.364809 | 0.971831 | 34 | 15 | 0.4412 |
| Madelon | 0.978347 | 0.785000 | 502 | 5 | 0.0100 |
| Gissette | 0.828217 | 0.971972 | 5000 | 89 | 0.0178 |
| IoT Intrusion | 0.068727 | 0.974825 | 115 | 29 | 0.2522 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nwokoma, F.; Foreman, J.; Akujuobi, C.M. Effective Data Reduction Using Discriminative Feature Selection Based on Principal Component Analysis. Mach. Learn. Knowl. Extr. 2024, 6, 789-799. https://doi.org/10.3390/make6020037
Nwokoma F, Foreman J, Akujuobi CM. Effective Data Reduction Using Discriminative Feature Selection Based on Principal Component Analysis. Machine Learning and Knowledge Extraction. 2024; 6(2):789-799. https://doi.org/10.3390/make6020037
Chicago/Turabian StyleNwokoma, Faith, Justin Foreman, and Cajetan M. Akujuobi. 2024. "Effective Data Reduction Using Discriminative Feature Selection Based on Principal Component Analysis" Machine Learning and Knowledge Extraction 6, no. 2: 789-799. https://doi.org/10.3390/make6020037
APA StyleNwokoma, F., Foreman, J., & Akujuobi, C. M. (2024). Effective Data Reduction Using Discriminative Feature Selection Based on Principal Component Analysis. Machine Learning and Knowledge Extraction, 6(2), 789-799. https://doi.org/10.3390/make6020037