
Knowledge Graphs and Their Reciprocal Relationship with Large Language Models


Abstract
1. Introduction
- RQ1: How are LLMs being used to construct KGs?
- RQ2: How are KGs being used to improve the output of LLMs?
- RQ3: What AI methodologies are used for LLM-based KG systems and KG-based LLMs?
2. Literature Review
3. Methods
3.1. Specific Research Questions
3.2. Data Sources and Search Strategy
3.3. Inclusion and Exclusion Criteria
3.4. Selection Process
3.5. Dimensions
- Domain: In the context of this research, this dimension largely refers to the domain or area of knowledge where the integration of LLMs and KGs is utilized to address challenges, solve problems, or drive innovations. While going through the dataset, we identified five major domains. These include computer science, education, finance, healthcare, and justice. The domain dimension is crucial for businesses as it helps identify industry-specific opportunities where LLM–KG can drive innovation, optimize operations, and enhance decision-making. By categorizing applications into areas like finance, healthcare, education, and justice, businesses can develop AI-driven solutions tailored to their sector, improving efficiency, customer experience, and competitive advantage. Understanding domain-specific applications allows companies to utilize AI not just for automation but as a strategic tool for growth, differentiation, and market leadership.
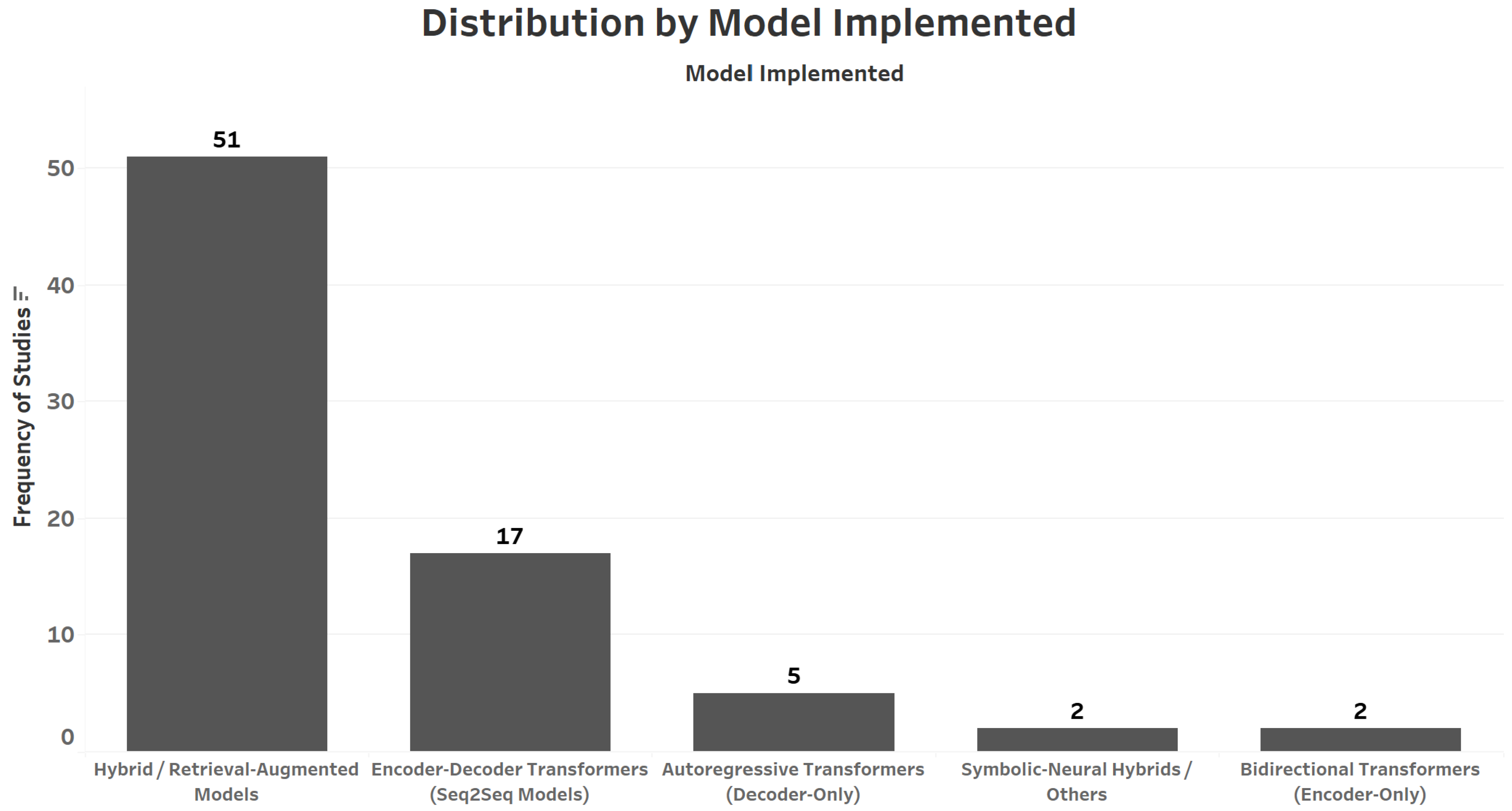
- Model Implemented: This dimension refers to the specific AI or computational model used to integrate LLM–KG. These models usually automate tasks essential for constructing and maintaining KGs, such as entity recognition, relationship extraction, and schema generation. Based on the studies, we were able to narrow down to five major models implemented, which are as follows:
- Autoregressive Transformers (Decoder-Only Models): These models, such as GPT-2, GPT-3, and GPT-4, predict the text token by token based on previous context. They are widely used in open-domain question answering, content generation, and dialogue systems.
- Bidirectional Transformers (Encoder-Only Models): These models, including BERT and RoBERTa, process input bidirectionally to capture contextual meaning, making them ideal for information retrieval, classification, and semantic understanding tasks.
- Encoder–Decoder Transformers (Seq2Seq Models): These models, such as T5 and BART, follow a sequence-to-sequence paradigm and are effective in translation, summarization, and generating structured outputs from textual or graph inputs.
- Hybrid/Retrieval-Augmented Models: This category includes architectures that integrate neural language models with retrieval mechanisms, symbolic tools, or external databases to improve factual grounding and reduce hallucinations. Examples include RAG, GraphRAG, and DRaM.
- Symbolic–Neural Hybrids/Other Non-Transformers: This group consists of models built with or around LSTM, GRU, CNNs, or logic-based rule systems, often in domain-specific or multimodal contexts. They are typically used in lower-resource or highly specialized applications.
- Applications: This dimension provides insights into how these solutions are used to solve real-world problems across various domains, including but not limited to building recommendation systems for providing personalized suggestions, developing classification systems for categorizing unstructured data into predefined groups, question answering systems and general NLP solutions for sentiment analysis and its applications.
- Input Type: This dimension investigates various types of input data used by the AI models in the studies finalized. Major types included in the finalized studies include text, images, and videos. It brings the focus to the ability of these models to incorporate unstructured and multimodal data to structured actionable insights.
3.6. Data Extraction, Data Analysis, and Synthesis
4. Results
4.1. RQ1: How Are LLMs Being Used to Construct KGs?
4.2. RQ2: How Are KGs Being Used to Improve the Output of LLMs?
- Medical KGs: Widely used in life sciences and pharmaceuticals, medical KGs improve LLM-based applications such as clinical decision-making, drug discovery, and patient management. For example, Wu et al. and Xu et al. demonstrate how medical KGs ground LLM responses in structured knowledge, reducing errors and improving reliability [75,92].
- Industrial KGs: Used in wirearchy management and immigration law, industrial KGs model organizational hierarchies and legal processes, improving the accuracy of LLM outputs in these domains [19,50]. Environmental sustainability KGs extend this by grounding ESG (Environmental, Social, Governance) queries in fact-based responses [47].
- Hybrid KGs: Combining multimodal data (textual, visual, audio, and numeric), hybrid KGs enhance LLM performance in domains like recommendation systems and robotics [23,42]. For example, frameworks like ManipMob-MMKG integrate scene-driven multimodal KGs to jointly process visual and textual inputs, supporting tasks like object identification and environment navigation [76]. In knowledge-based visual question answering (VQA), KGs improve multimodal reasoning by linking visual inputs to structured knowledge [85].
4.3. RQ3: What AI Methodologies Are Used for LLM-Based KG Systems and KG-Based LLMs?
- Symbolic AI—Symbolic AI is heavily implemented in LLM-based KG construction for the tasks requiring explicit rule-based reasoning and validation [55]. See some examples below:
- SPARQL Query Generation: LLMs generate SPARQL queries to validate KGs against predefined ontologies, ensuring compliance with knowledge representation standards [19]. Recent benchmarks like Spider4SPARQL is used to rigorously evaluate LLMs’ ability to handle complex query structures, while the subgraph extraction algorithms refine SPARQL generation by isolating contextually relevant graph segments [35].
- Logic-Based Inference: Frameworks like DRaM use symbolic reasoning to derive and validate relationships in KGs, improving interpretability and accuracy [97].
- Ontology Matching: Algorithms align LLM-generated entities with predefined taxonomies, ensuring semantic consistency in domains like scholarly KGs [87].
- While symbolic AI excels at rule-based reasoning and formal validation, machine learning methodologies take a more data-driven approach towards automating the discovery and extraction of knowledge from large unstructured datasets.
- 2.
- Machine Learning (ML)—ML supports the most LLM based methodologies to provide data driven approaches to extract and refine knowledge. See some examples below:
- Neural Network Techniques: Embedding-based models and GNN architectures like HybridGCN are used for link prediction and subgraph extraction from textual and relational data to build and refine KGs which further enables the automated discovery of relationships in KGs [23,42,90]. HybridGCN further scales KG reasoning by integrating graph neural networks with LLMs [90], while neural-symbolic frameworks like those by Liu et al. combine LLM embeddings with structured query generation for multi-hop reasoning [67].
- Prompt Engineering: Customized prompts guide the LLM in extracting domain-specific entities and relationships. By fine-tuning LLMs with custom prompts, machine learning facilitates domain-specific knowledge extraction [42,92]. Comparative studies by Schneider et al. demonstrate how prompt engineering aligns LLM outputs with KG structures, ensuring factual text generation [80].
- Multi-Level Knowledge Generation: Techniques like few-shot KG completion fill missing relationships with minimal labeled data, they enable LLMs to generate triples and attributes for KG completion reducing reliance on labelled datasets, as demonstrated by Li et al. in generating hierarchical attributes for sparse KGs [44].
- In contrast to both symbolic AI and machine learning, evolutionary computation focuses on optimizing and dynamically updating KGs to accommodate new information and maintain relevance over time.
- 3.
- Evolutionary Computation—The uncommon and less prevalent than machine learning and symbolic AI, evolutionary computation is being used occasionally to optimize tasks. For example,
5. Discussion
5.1. The Reciprocal Relationship
5.1.1. KGs as Input into LLMs
5.1.2. LLMs to Build KGs
5.2. Limitations
- Domain-Specific Challenges: LLMs often struggle with subtleties in specialized areas such as healthcare, finance and justice, leading to inaccuracies in entity recognition and relation extraction. This can compromise the quality of the resulting KGs and the outputs of LLM applications.
- Computational Intensity: The dynamic integration of KGs into LLM workflows demand significant computational resources, especially in real-time applications. This includes the cost of fine-tuning LLMs with domain-specific KG data or employing hybrid retrieval-augmented generation techniques.
- Explainability Concerns: While KGs enhance the interpretability of LLM outputs, the inherent opacity of LLMs’ reasoning processes remains a barrier. Even with advancements in XAI, ensuring trust and validation in sensitive domains like healthcare and governance is challenging, and this poses the risk of algorithmic discrimination.
- Data Governance and Compliance: Ensuring data governance, regulatory compliance and access control during KG and LLM integration is complex, especially in highly regulated industries. Failure to manage this concern can lead to data misuse or ethical concerns.
6. Gap Analysis
6.1. Gaps Across Analytical Dimensions
6.1.1. Domains
- Distribution of domains: A striking 76.6% (59 papers) of studies originate from the core domain of computer science, overshadowing other domains representing research in the field of AI and machine learning. The rest had applications in education (15.6%, 12 papers), healthcare (5.19%, 4 papers), finance (1.29%, 1 paper) and justice (1.29%, 1 paper).
- Lack of Interdisciplinary Synergy: Fewer than ten studies bridge insights from complementary domains, for instance, healthcare and education or environmental policy and economics, limiting the cross-domain applicability of LLM–KG frameworks. Studies originating from domains such as finance and justice are underrepresented. This shows that the application of LLM–KG frameworks can be investigated and then implemented in various domains.
6.1.2. Model Implementation
- Predominance of Hybrid/Retrieval-Augmented Models: Hybrid/Retrieval-Augmented Models (66.2%, 51 papers) dominate research, while specialized architectures like Bidirectional Transformers or Symbolic–Neural Hybrids (2.6%, 2 papers each) are underutilized.
- Scarce Decoder-based Autoregressive Transformer Adaptation: Only 6.4% (five papers) of studies employ fine-tuned LLMs (e.g., GPT variants) tailored to domain-specific challenges in healthcare or finance.
- Limited Hybrid Methodologies: Fewer than 5% of papers investigate synergies between disparate architectures, for example, integrating neural networks with symbolic reasoning systems.
6.1.3. Applications
- Bias Toward Language-Centric Tasks: Language modeling applications account for 63.6% (49 papers) of the studies, whereas recommendation systems (7.8%, 6 papers) and question answering (1.29%, 1 paper) receive minimal attention.
- Under deployment of Generative AI: Despite its versatility, ChatGPT is utilized in only 5.2% of studies (four papers), indicating its untapped potential in real-world applications where such Gen AI could assist adaptive education or customer service.
6.1.4. Input Modalities
- Text-Centric Paradigms: All the studies rely exclusively on textual inputs, neglecting other methods such as image or video data.
- Absence of Multimodal Integration: Fewer than 4% (three papers) of studies explore multimodal systems combining KGs with images and videos as multimodal inputs.
- Monolingual Limitations: No studies investigate multilingual KG–LLM systems, constraining their utility in linguistically diverse regions.
6.2. Gaps Aligned with the Research Questions
6.2.1. RQ1: LLMs in KG Construction
- Static Construction Paradigms: Most studies focus on static KG construction, with limited exploration of dynamic systems that update in real time. As knowledge is being created at such an immense rate and now recent advancements in computational AI are able to process big data real time, there are certain dataflow and workflows such as streaming data integration that could be explored to implement dynamic KGs with LLMs.
- Automation Deficits: Advanced techniques like automated schema generation or granular entity linking are addressed in few papers.
6.2.2. RQ2: KGs in Enhancing LLM Outputs
- Explainability Challenges: While KGs mitigate LLM hallucinations, only a few studies formalize explainability frameworks to trace outputs to KG nodes.
- Domain-Specific KG Underutilization: Critical sectors like healthcare employ domain-specific KGs in only some of the cases, despite their potential for precision.
- Sparse Multi-Hop Reasoning: Very few of the studies exploit KGs’ relational structures for complex reasoning tasks (e.g., causal inference).
6.2.3. RQ3: Methodological Diversity
- Isolated Methodological Approaches: Symbolic AI, machine learning, and evolutionary computation are rarely integrated, stifling innovation in hybrid problem-solving.
- Ethical Oversights: Methodologies addressing fairness, bias mitigation, or ethical governance are critically absent, particularly in high-stakes domains like healthcare.
6.3. Future Work and Strategic Recommendations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LLMs | Large Language Models |
| KGs | Knowledge Graphs |
| AI | Artificial Intelligence |
| XAI | Explainable AI |
| RAG | Retrieval Augmented Generation |
| PRISMA-ScR | Preferred Reporting Items for Systematic Reviews and Meta Analyses-Scoping Review |
| GPT | Generative Pre-Trained Transformer |
| BERT | Bidirectional Encoder Representations from Transformer |
| NLP | Natural Language Processing |
| RD-P | Retrieve-and-Discriminate Prompter |
| PRLLM | Patent Response Large Language Model |
| PPNet | Patent Precedents Knowledge Graphs |
| KARGEN | Knowledge-enhanced Automated Radiology Report Generation Using |
| Large Language Models | |
| MMKG | Multi-Modal Knowledge Graph |
| SPARQL | SPARQL Protocol and RDF Query Language |
| TKGs | Temporal Knowledge Graphs |
| VKGs | Virtual Knowledge Graphs |
| TFKGs | Traditional Folklore Knowledge Graphs |
| ORKG | Open Research Knowledge Graph |
| GNN | Graph Neural Network |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Research Study | Shortlisted? | |
|---|---|---|
| 1 | Title: “Breaking the Barrier: Utilizing Large Language Models for Industrial Recommendation Systems through an Inferential Knowledge Graph” Year: 2024 Library: ACM Reason for Inclusion: -Contains both “Large Language Models” and “Knowledge Graph” in the title. -Published in a peer-reviewed conference/journal (ACM). -Within the specified date range (2019–2024). | Yes |
| 2 | Title: “A fusion inference method for Large Language Models and Knowledge Graphs based on structured injection and causal inference” Year: 2024 Library: ACM Reason for Exclusion: -The title does not clearly focus on the integration of LLMs and Knowledge Graphs for the research aim. -While it mentions “Large Language Models” and “Knowledge Graphs,” it seems more aligned with general AI/ML methods rather than the specific research questions outlined. | No |
References
- Qin, C.; Zhang, A.; Zhang, Z.; Chen, J.; Yasunaga, M.; Yang, D. Is ChatGPT a General-Purpose Natural Language Processing Task Solver? arXiv 2023, arXiv:2302.06476. [Google Scholar]
- Danilevsky, M.; Qian, K.; Aharonov, R.; Katsis, Y.; Kawas, B.; Sen, P. A Survey of the State of Explainable AI for Natural Language Processing. arXiv 2020, arXiv:2010.00711. [Google Scholar]
- Pan, J.Z.; Razniewski, S.; Kalo, J.C.; Singhania, S.; Chen, J.; Dietze, S.; Jabeen, H.; Omeliyanenko, J.; Zhang, W.; Lissandrini, M.; et al. Large Language Models and Knowledge Graphs: Opportunities and Challenges. arXiv 2023, arXiv:2308.06374. [Google Scholar]
- Rajabi, E.; Etminani, K. Knowledge-graph-based explainable AI: A systematic review. J. Inf. Sci. 2024, 50, 1019–1029. [Google Scholar] [CrossRef]
- Ibrahim, N.; Aboulela, S.; Ibrahim, A.; Kashef, R. A survey on augmenting Knowledge Graphs (KGs) with large language models (LLMs): Models, evaluation metrics, benchmarks, and challenges. Discov. Artif. Intell. 2024, 4, 76. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; Arx, S.v.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the Opportunities and Risks of Foundation Models. arXiv 2022, arXiv:2108.07258. [Google Scholar]
- Li, D.; Xu, F. Synergizing Knowledge Graphs with Large Language Models: A Comprehensive Review and Future Prospects. arXiv 2024, arXiv:2407.18470. [Google Scholar]
- Zhu, Y.; Wang, X.; Chen, J.; Qiao, S.; Ou, Y.; Yao, Y.; Deng, S.; Chen, H.; Zhang, N. LLMs for Knowledge Graph construction and reasoning: Recent capabilities and future opportunities. World Wide Web 2024, 27, 58. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Adhikari, A.; Wenink, E.; van der Waa, J.; Bouter, C.; Tolios, I.; Raaijmakers, S. Towards FAIR Explainable AI: A standardized ontology for mapping XAI solutions to use cases, explanations, and AI systems. In Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments, New York, NY, USA, 29 June–1 July 2022; pp. 562–568. [Google Scholar] [CrossRef]
- Ananya, A.; Tiwari, S.; Mihindukulasooriya, N.; Soru, T.; Xu, Z.; Moussallem, D. Towards Harnessing Large Language Models as Autonomous Agents for Semantic Triple Extraction from Unstructured Text. 2024. Available online: https://ceur-ws.org/Vol-3747/text2kg_paper1.pdf (accessed on 1 March 2025).
- Saleh, A.O.M.; Tur, G.; Saygin, Y. SG-RAG: Multi-Hop Question Answering with Large Language Models Through Knowledge Graphs. In Proceedings of the 7th International Conference on Natural Language and Speech Processing (ICNLSP), Trento, NJ, USA, 19–20 October 2024; pp. 439–448. [Google Scholar]
- Trinh, T.; Dao, A.; Nhung, H.T.H.; Son, H.T. VieMedKG: Knowledge Graph and Benchmark for Traditional Vietnamese Medicine. bioRxiv 2024. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Z.; Liu, Y.; Wang, L.; Liu, L.; Zhou, L. KARGEN: Knowledge-enhanced Automated Radiology Report Generation Using Large Language Models. arXiv 2024, arXiv:2409.05370. [Google Scholar]
- Ren, X.; Tang, J.; Yin, D.; Chawla, N.; Huang, C. A Survey of Large Language Models for Graphs. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 6616–6626. [Google Scholar] [CrossRef]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic Mapping Studies in Software Engineering; BCS Learning & Development: Nicosia, Cyprus, 2008. [Google Scholar] [CrossRef]
- Dehal, R.S. Dataset—Reciprocal_Relationship_Of_KGs_And_LLMs. 2024. Available online: https://figshare.com/articles/dataset/Dataset_-_Reciprocal_Relationship_Of_KGs_And_LLMs/28468637/1?file=52560449 (accessed on 1 March 2025).
- Sun, Y.; Xin, H.; Sun, K.; Xu, Y.E.; Yang, X.; Dong, X.L.; Tang, N.; Chen, L. Are Large Language Models a Good Replacement of Taxonomies? Proc. VLDB Endow. 2024, 17, 2919–2932. [Google Scholar] [CrossRef]
- Venkatakrishnan, R.; Tanyildizi, E.; Canbaz, M.A. Semantic interlinking of Immigration Data using LLMs for Knowledge Graph Construction. In Proceedings of the Companion Proceedings of the ACM Web Conference 2024, Singapore, 13–17 May 2024; pp. 605–608. [Google Scholar] [CrossRef]
- Huang, Y.; Zeng, G. RD-P: A Trustworthy Retrieval-Augmented Prompter with Knowledge Graphs for LLMs. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, New York, NY, USA, 21–25 October 2024; pp. 942–952. [Google Scholar] [CrossRef]
- Colombo, A. Leveraging Knowledge Graphs and LLMs to Support and Monitor Legislative Systems. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024; pp. 5443–5446. [Google Scholar] [CrossRef]
- Chen, Z.; Mao, H.; Li, H.; Jin, W.; Wen, H.; Wei, X.; Wang, S.; Yin, D.; Fan, W.; Liu, H.; et al. Exploring the Potential of Large Language Models (LLMs)in Learning on Graphs. ACM SIGKDD Explor. Newsl. 2024, 25, 42–61. [Google Scholar] [CrossRef]
- Wei, W.; Ren, X.; Tang, J.; Wang, Q.; Su, L.; Cheng, S.; Wang, J.; Yin, D.; Huang, C. LLMRec: Large Language Models with Graph Augmentation for Recommendation. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Merida, Mexico, 4–8 March 2024; pp. 806–815. [Google Scholar] [CrossRef]
- Dong, X.L. Generations of Knowledge Graphs: The Crazy Ideas and the Business Impact. Proc. VLDB Endow. 2023, 16, 4130–4137. [Google Scholar] [CrossRef]
- Wu, Q.; Wang, Y. Research on Intelligent Question-Answering Systems Based on Large Language Models and Knowledge Graphs. In Proceedings of the 2023 16th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 16–17 December 2023; pp. 161–164. [Google Scholar] [CrossRef]
- Fieblinger, R.; Alam, M.T.; Rastogi, N. Actionable Cyber Threat Intelligence Using Knowledge Graphs and Large Language Models. In Proceedings of the 2024 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Vienna, Austria, 8–12 July 2024; pp. 100–111. [Google Scholar] [CrossRef]
- Vizcarra, J.; Haruta, S.; Kurokawa, M. Representing the Interaction between Users and Products via LLM-assisted Knowledge Graph Construction. In Proceedings of the 2024 IEEE 18th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 5–7 February 2024; pp. 231–232. [Google Scholar] [CrossRef]
- Kosten, C.; Cudré-Mauroux, P.; Stockinger, K. Spider4SPARQL: A Complex Benchmark for Evaluating Knowledge Graph Question Answering Systems. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 5272–5281. [Google Scholar] [CrossRef]
- Taffa, T.A.; Usbeck, R. Leveraging LLMs in Scholarly Knowledge Graph Question Answering. arXiv 2023, arXiv:2311.09841. [Google Scholar]
- Ding, Z.; Cai, H.; Wu, J.; Ma, Y.; Liao, R.; Xiong, B.; Tresp, V. zrLLM: Zero-Shot Relational Learning on Temporal Knowledge Graphs with Large Language Models. arXiv 2024, arXiv:2311.10112. [Google Scholar]
- Chen, L.; Xu, J.; Wu, T.; Liu, J. Information Extraction of Aviation Accident Causation Knowledge Graph: An LLM-Based Approach. Electronics 2024, 13, 3936. [Google Scholar] [CrossRef]
- Braşoveanu, A.M.P.; Nixon, L.J.B.; Weichselbraun, A.; Scharl, A. Framing Few-Shot Knowledge Graph Completion with Large Language Models. Electronics 2024, 13, 3936. [Google Scholar]
- Jiang, L.; Yan, X.; Usbeck, R. A Structure and Content Prompt-Based Method for Knowledge Graph Question Answering over Scholarly Data. 2023. Available online: https://ceur-ws.org/Vol-3592/paper3.pdf (accessed on 1 March 2025).
- Mohanty, A. EduEmbedd—A Knowledge Graph Embedding for Education. 2023. Available online: https://ceur-ws.org/Vol-3532/paper1.pdf (accessed on 1 March 2025).
- Pliukhin, D.; Radyush, D.; Kovriguina, L.; Mouromtsev, D. Improving Subgraph Extraction Algorithms for One-Shot SPARQL Query Generation with Large Language Models. 2024. Available online: https://ceur-ws.org/Vol-3592/paper6.pdf (accessed on 1 March 2025).
- Vasisht, K.; Ganesan, B.; Kumar, V.; Bhatnagar, V. Infusing Knowledge into Large Language Models with Contextual Prompts. In Proceedings of the 20th International Conference on Natural Language Processing (ICON), Goa, India, 14–17 December 2023; Pawar, J.D., Lalitha Devi, S., Eds.; Goa University: Goa, India, 2023; pp. 657–662. [Google Scholar]
- Schmidt, W.J.; Rincon-Yanez, D.; Kharlamov, E.; Paschke, A. Scaling Scientific Knowledge Discovery with Neuro-Symbolic AI and Large Language Models. 2024. Available online: https://publica.fraunhofer.de/entities/publication/a752f6fb-4cc0-46cc-9312-b6eff7f64334 (accessed on 1 March 2025).
- Liu, S.; Fang, Y. Use Large Language Models for Named Entity Disambiguation in Academic Knowledge Graphs; Atlantis Press: Amsterdam, The Netherlands, 2023; pp. 681–691. [Google Scholar] [CrossRef]
- Momii, Y.; Takiguchi, T.; Ariki, Y. Rule-based Fact Verification Utilizing Knowledge Graphs. 2023. Available online: https://www.jstage.jst.go.jp/article/jsaislud/99/0/99_51/_article/-char/en (accessed on 1 March 2025).
- de Paiva, V.; Gao, Q.; Kovalev, P.; Moss, L.S. Extracting Mathematical Concepts with Large Language Models. 2023. Available online: https://cicm-conference.org/2023/mathui/mathuiPubs/CICM_2023_paper_8826.pdf (accessed on 1 March 2025).
- Thießen, F.; D’Souza, J.; Stocker, M. Probing Large Language Models for Scientific Synonyms. 2023. Available online: https://ceur-ws.org/Vol-3510/paper_nlp_2.pdf (accessed on 1 March 2025).
- Wang, F.; Shi, D.; Aguilar, J.; Cui, X.; Jiang, J.; Shen, L.; Li, M. LLM-KGMQA: Large Language Model-Augmented Multi-Hop Question-Answering System Based on Knowledge Graph in Medical Field. 2024. ISSN: 2693-5015. Available online: https://www.researchsquare.com/article/rs-4721418/v1 (accessed on 1 March 2025). [CrossRef]
- Yang, J. Integrated Application of LLM Model and Knowledge Graph in Medical Text Mining and Knowledge Extraction. Soc. Med. Health Manag. 2024, 5, 56–62. [Google Scholar] [CrossRef]
- Li, Q.; Chen, Z.; Ji, C.; Jiang, S.; Li, J. LLM-based Multi-Level Knowledge Generation for Few-shot Knowledge Graph Completion. In Proceedings of the Thirty-ThirdInternational Joint Conference on Artificial Intelligence, Jeju, Republic of Korea, 3–9 August 2024; pp. 2135–2143. [Google Scholar] [CrossRef]
- Laurenzi, E.; Mathys, A.; Martin, A. An LLM-Aided Enterprise Knowledge Graph (EKG) Engineering Process. Proc. AAAI Symp. Ser. 2024, 3, 148–156. [Google Scholar] [CrossRef]
- Gillani, K.; Novak, E.; Kenda, K.; Mladenić, D. Knowledge Graph Extraction from Textual Data Using LLM. 2024. Available online: https://is.ijs.si/wp-content/uploads/2024/10/IS2024_-_SIKDD_2024_paper_15-1.pdf (accessed on 1 March 2025).
- Gupta, T.K.; Goel, T.; Verma, I.; Dey, L.; Bhardwaj, S. Knowledge Graph Aided LLM Based ESG Question-Answering from News. 2024. Available online: https://ceur-ws.org/Vol-3753/paper6.pdf (accessed on 1 March 2025).
- Ghanem, H.; Cruz, C. Fine-Tuning vs. Prompting: Evaluating the Knowledge Graph Construction with LLMs. 2024. Available online: https://hal.science/hal-04862235/ (accessed on 1 March 2025).
- Son, J.; Seonwoo, Y.; Yoon, S.; Thorne, J.; Oh, A. Multi-hop Database Reasoning with Virtual Knowledge Graph. In Proceedings of the 1st Workshop on Knowledge Graphs and Large Language Models (KaLLM 2024), Bangkok, Thailand, 15 August 2024; Biswas, R., Kaffee, L.A., Agarwal, O., Minervini, P., Singh, S., de Melo, G., Eds.; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 1–11. [Google Scholar] [CrossRef]
- Ventura de los Ojos, X. Application of LLM-Augmented Knowledge Graphs for Wirearchy Management; Universitat Oberta de Catalunya (UOC): Barcelona, Spain, 2024. [Google Scholar]
- Dernbach, S.; Agarwal, K.; Zuniga, A.; Henry, M.; Choudhury, S. GLaM: Fine-Tuning Large Language Models for Domain Knowledge Graph Alignment via Neighborhood Partitioning and Generative Subgraph Encoding. Proc. AAAI Symp. Ser. 2024, 3, 82–89. [Google Scholar] [CrossRef]
- Reitemeyer, B.; Fill, H.G. Leveraging LLMs in Semantic Mapping for Knowledge Graph-Based Automated Enterprise Model Generation; Gesellschaft für Informatik e.V.: Berlin, Germany, 2024. [Google Scholar] [CrossRef]
- Kollegger, A.B.; Erdl, A.; Hunger, M. Knowledge Graph Builder—Constructing a Graph from Arbitrary Text Using an LLM. In Proceedings of the 32nd International Symposium on Graph Drawing and Network Visualization (GD 2024), Vienna, Austria, 18–20 September 2024; Felsner, S., Klein, K., Eds.; Schloss Dagstuhl–Leibniz-Zentrum für Informatik: Dagstuhl, Germany, 2024; Volume 320, pp. 61:1–61:2. [Google Scholar] [CrossRef]
- Li, V.X.; Tan, Y. Dynamic Knowledge Graph Asset Pricing. 2024. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4841921 (accessed on 1 March 2025). [CrossRef]
- Tufek, N.; Saissre, A.; Just, V.P.; Ekaputra, F.J.; Sabou, M.; Hanbury, A. Validating Semantic Artifacts with Large Language Models. In European Semantic Web Conference; Springer Nature: Cham, Switzerland, 2024; pp. 92–101. [Google Scholar] [CrossRef]
- Gan, L.; Blum, M.; Dessí, D.; Mathiak, B.; Schenkel, R.; Dietze, S. Hidden Entity Detection from GitHub Leveraging Large Language Models. arXiv 2024, arXiv:2501.04455. [Google Scholar]
- Martin, A.; Witschel, H.F.; Mandl, M.; Stockhecke, M. Semantic Verification in Large Language Model-based Retrieval Augmented Generation. Proc. AAAI Symp. Ser. 2024, 3, 188–192. [Google Scholar] [CrossRef]
- Chu, J.M.; Lo, H.C.; Hsiang, J.; Cho, C.C. Patent Response System Optimised for Faithfulness: Procedural Knowledge Embodiment with Knowledge Graph and Retrieval Augmented Generation. In Proceedings of the 1st Workshop on Towards Knowledgeable Language Models (KnowLLM 2024), Bangkok, Thailand, 16 August 2024; Li, S., Li, M., Zhang, M.J., Choi, E., Geva, M., Hase, P., Ji, H., Eds.; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 146–155. [Google Scholar] [CrossRef]
- Dobriy, D. Employing RAG to Create a Conference Knowledge Graph from Text. 2024. Available online: https://ceur-ws.org/Vol-3747/text2kg_paper4.pdf (accessed on 1 March 2025).
- Seif, A.; Toh, S.; Lee, H.K. A Dynamic Jobs-Skills Knowledge Graph. 2024. Available online: https://recsyshr.aau.dk/wp-content/uploads/2024/10/RecSysHR2024-paper_1.pdf (accessed on 1 March 2025).
- Camboim de Sá, J.; Anastasiou, D.; Da Silveira, M.; Pruski, C. Socio-cultural adapted chatbots: Harnessing Knowledge Graphs and Large Language Models for enhanced context awarenes. In Proceedings of the 1st Worskhop on Towards Ethical and Inclusive Conversational AI: Language Attitudes, Linguistic Diversity, and Language Rights (TEICAI 2024), St. Julian’s, Malta, 22 March 2024; Hosseini-Kivanani, N., Höhn, S., Anastasiou, D., Migge, B., Soltan, A., Dippold, D., Kamlovskaya, E., Philippy, F., Eds.; Association for Computational Linguistics: St Julians, Malta, 2024; pp. 21–27. [Google Scholar]
- Daga, E.; Carvalho, J.; Morales Tirado, A. Extracting Licence Information from Web Resources with a Large Language Model, Heraklion, Greece. 2024. Available online: https://oro.open.ac.uk/97612/ (accessed on 1 March 2025).
- D’Souza, J.; Mihindukulasooriya, N. The State of the Art Large Language Models for Knowledge Graph Construction from Text: Techniques, Tools, and Challenges. 2024. Available online: https://research.ibm.com/publications/the-state-of-the-art-large-language-models-for-knowledge-graph-construction-from-text-techniques-tools-and-challenges (accessed on 1 March 2025).
- Iga, V.I.R.; Silaghi, G.C. LLMs for Knowledge-Graphs Enhanced Task-Oriented Dialogue Systems: Challenges and Opportunities. In Proceedings of the Advanced Information Systems Engineering Workshops, Limassol, Cyprus, 3–7 June 2024; Almeida, J.P.A., Di Ciccio, C., Kalloniatis, C., Eds.; Springer: Cham, Switzerland, 2024; pp. 168–179. [Google Scholar] [CrossRef]
- Zhao, Q.; Qian, H.; Liu, Z.; Zhang, G.D.; Gu, L. Breaking the Barrier: Utilizing Large Language Models for Industrial Recommendation Systems through an Inferential Knowledge Graph. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024; pp. 5086–5093. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Z.; Guo, L.; Xu, Y.; Zhang, W.; Chen, H. Making Large Language Models Perform Better in Knowledge Graph Completion. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024; pp. 233–242. [Google Scholar] [CrossRef]
- Liu, L.; Wang, Z.; Bai, J.; Song, Y.; Tong, H. New Frontiers of Knowledge Graph Reasoning: Recent Advances and Future Trends. In Proceedings of the Companion Proceedings of the ACM Web Conference 2024, Singapore, 13–17 May 2024; pp. 1294–1297. [Google Scholar] [CrossRef]
- Wu, L.I.; Su, Y.; Li, G. Zero-Shot Construction of Chinese Medical Knowledge Graph with GPT-3.5-turbo and GPT-4. ACM Trans. Manag. Inf. Syst. 2024, 16, 3657305. [Google Scholar] [CrossRef]
- Bui, T.; Tran, O.; Nguyen, P.; Ho, B.; Nguyen, L.; Bui, T.; Quan, T. Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A Case Study at HCMUT. In Proceedings of the 1st ACM Workshop on AI-Powered Q&A Systems for Multimedia, Phuket, Thailand, 14 June 2024; pp. 36–43. [Google Scholar] [CrossRef]
- Jiang, Y.; Yao, J.; Li, F.; Zhang, Y. Research on Engineering Management Question-answering System in the Communication Industry Based on Large Language Models and Knowledge Graphs. In Proceedings of the 2024 7th International Conference on Machine Vision and Applications, Singapore, 12–14 March 2024; pp. 100–105. [Google Scholar] [CrossRef]
- Le, D.; Zhao, K.; Wang, M.; Wu, Y. GraphLingo: Domain Knowledge Exploration by Synchronizing Knowledge Graphs and Large Language Models. In Proceedings of the 2024 IEEE 40th International Conference on Data Engineering (ICDE), Utrecht, The Netherlands, 13–16 May 2024; pp. 5477–5480. [Google Scholar] [CrossRef]
- Pan, S.; Luo, L.; Wang, Y.; Chen, C.; Wang, J.; Wu, X. Unifying Large Language Models and Knowledge Graphs: A Roadmap. IEEE Trans. Knowl. Data Eng. 2024, 36, 3580–3599. [Google Scholar] [CrossRef]
- Li, D.; Xu, F. The Deep Integration of Knowledge Graphs and Large Language Models: Advancements, Challenges, and Future Directions. In Proceedings of the 2024 IEEE 2nd International Conference on Sensors, Electronics and Computer Engineering (ICSECE), Jinzhou, China, 29–31 August 2024; pp. 157–162. [Google Scholar] [CrossRef]
- Abu-Rasheed, H.; Weber, C.; Fathi, M. Knowledge Graphs as Context Sources for LLM-Based Explanations of Learning Recommendations. In Proceedings of the 2024 IEEE Global Engineering Education Conference (EDUCON), Kos, Greece, 8–11 May 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, H.; Zhang, H.; Lu, J.; Xiao, G. ChatTf: A Knowledge Graph-Enhanced Intelligent Q&A System for Mitigating Factuality Hallucinations in Traditional Folklore. IEEE Access 2024, 12, 162638–162650. [Google Scholar] [CrossRef]
- Song, Y.; Sun, P.; Liu, H.; Li, Z.; Song, W.; Xiao, Y.; Zhou, X. Scene-Driven Multimodal Knowledge Graph Construction for Embodied AI. IEEE Trans. Knowl. Data Eng. 2024, 36, 6962–6976. [Google Scholar] [CrossRef]
- Jovanović, M.; Campbell, M. Connecting AI: Merging Large Language Models and Knowledge Graph. Computer 2023, 56, 103–108. [Google Scholar] [CrossRef]
- Knez, T.; Žitnik, S. Towards Using Automatically Enhanced Knowledge Graphs to Aid Temporal Relation Extraction. In Proceedings of the First Workshop on Patient-Oriented Language Processing (CL4Health) @ LREC-COLING 2024; Demner-Fushman, D., Ananiadou, S., Thompson, P., Ondov, B., Eds.; ELRA and ICCL: Torino, Italy, 2024; pp. 131–136. [Google Scholar]
- Cao, X.; Xu, W.; Zhao, J.; Duan, Y.; Yang, X. Research on Large Language Model for Coal Mine Equipment Maintenance Based on Multi-Source Text. Appl. Sci. 2024, 14, 2946. [Google Scholar] [CrossRef]
- Schneider, P.; Klettner, M.; Simperl, E.; Matthes, F. A Comparative Analysis of Conversational Large Language Models in Knowledge-Based Text Generation. arXiv 2024, arXiv:2402.01495. [Google Scholar]
- Xu, S.; Chen, M.; Chen, S. Enhancing Retrieval-Augmented Generation Models with Knowledge Graphs: Innovative Practices Through a Dual-Pathway Approach. In Proceedings of the Advanced Intelligent Computing Technology and Applications, Tianjin, China, 5–8 August 2024; Huang, D.S., Si, Z., Chen, W., Eds.; Springer Nature: Singapore, 2024; pp. 398–409. [Google Scholar] [CrossRef]
- Huang, Q.; Wan, Z.; Xing, Z.; Wang, C.; Chen, J.; Xu, X.; Lu, Q. Let’s Chat to Find the APIs: Connecting Human, LLM and Knowledge Graph through AI Chain. In Proceedings of the 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE), Luxembourg, 11–15 September 2023; pp. 471–483. [Google Scholar] [CrossRef]
- Sequeda, J.; Allemang, D.; Jacob, B. A Benchmark to Understand the Role of Knowledge Graphs on Large Language Model’s Accuracy for Question Answering on Enterprise SQL Databases. In Proceedings of the 7th Joint Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA), Santiago, Chile, 14 June 2024; pp. 1–12. [Google Scholar] [CrossRef]
- Fu, L.; Guan, H.; Du, K.; Lin, J.; Xia, W.; Zhang, W.; Tang, R.; Wang, Y.; Yu, Y. SINKT: A Structure-Aware Inductive Knowledge Tracing Model with Large Language Model. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, Boise, ID, USA, 21–25 October 2024; pp. 632–642. [Google Scholar] [CrossRef]
- Hu, Z.; Yang, P.; Liu, F.; Meng, Y.; Liu, X. Prompting Large Language Models with Knowledge-Injection for Knowledge-Based Visual Question Answering. Big Data Min. Anal. 2024, 7, 843–857. [Google Scholar] [CrossRef]
- Agrawal, G.; Pal, K.; Deng, Y.; Liu, H.; Chen, Y.C. CyberQ: Generating Questions and Answers for Cybersecurity Education Using Knowledge Graph-Augmented LLMs. Proc. AAAI Conf. Artif. Intell. 2024, 38, 23164–23172. [Google Scholar] [CrossRef]
- Hertling, S.; Paulheim, H. OLaLa: Ontology Matching with Large Language Models. In Proceedings of the 12th Knowledge Capture Conference 2023, Pensacola, FL, USA, 5–7 December 2023; pp. 131–139. [Google Scholar] [CrossRef]
- Cadeddu, A.; Chessa, A.; De Leo, V.; Fenu, G.; Motta, E.; Osborne, F.; Reforgiato Recupero, D.; Salatino, A.; Secchi, L. Optimizing Tourism Accommodation Offers by Integrating Language Models and Knowledge Graph Technologies. Information 2024, 15, 398. [Google Scholar] [CrossRef]
- Hello, N.; Di Lorenzo, P.; Strinati, E.C. Semantic Communication Enhanced by Knowledge Graph Representation Learning. In Proceedings of the 2024 IEEE 25th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Lucca, Italy, 10–13 September 2024; pp. 876–880. [Google Scholar] [CrossRef]
- Nguyen, D.A.K.; Kha, S.; Le, T.V. HybridGCN: An Integrative Model for Scalable Recommender Systems with Knowledge Graph and Graph Neural Networks. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 1327. [Google Scholar] [CrossRef]
- Zhao, J.; Ma, Z.; Zhao, H.; Zhang, X.; Liu, Q.; Zhang, C. Self-consistency, Extract and Rectify: Knowledge Graph Enhance Large Language Model for Electric Power Question Answering. In Proceedings of the Advanced Intelligent Computing Technology and Applications, Tianjin, China, 5–8 August 2024; Huang, D.S., Pan, Y., Guo, J., Eds.; Springer Nature: Singapore, 2024; pp. 493–504. [Google Scholar] [CrossRef]
- Wu, L.I.; Li, G. Zero-Shot Construction of Chinese Medical Knowledge Graph with ChatGPT. In Proceedings of the 2023 IEEE International Conference on Medical Artificial Intelligence (MedAI), Beijing, China, 18–19 November 2023; pp. 278–283. [Google Scholar] [CrossRef]
- Procko, T.T.; Ochoa, O. Graph Retrieval-Augmented Generation for Large Language Models: A Survey. In Proceedings of the 2024 Conference on AI, Science, Engineering, and Technology (AIxSET), Laguna Hills, CA, USA, 30 September–2 October 2024; pp. 166–169. [Google Scholar] [CrossRef]
- Su, Y.; Liao, D.; Xing, Z.; Huang, Q.; Xie, M.; Lu, Q.; Xu, X. Enhancing Exploratory Testing by Large Language Model and Knowledge Graph. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, Lisbon, Portugal, 14–20 April 2024; pp. 1–12. [Google Scholar] [CrossRef]
- Jin, B.; Liu, G.; Han, C.; Jiang, M.; Ji, H.; Han, J. Large Language Models on Graphs: A Comprehensive Survey. IEEE Trans. Knowl. Data Eng. 2024, 36, 8622–8642. [Google Scholar] [CrossRef]
- Procko, T.T.; Elvira, T.; Ochoa, O. GPT-4: A Stochastic Parrot or Ontological Craftsman? Discovering Implicit Knowledge Structures in Large Language Models. In Proceedings of the 2023 Fifth International Conference on Transdisciplinary AI (TransAI), Laguna Hills, CA, USA, 25–27 September 2023; pp. 147–154. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, W.; Liu, Y. The Application of Constructing Knowledge Graph of Oral Historical Archives Resources Based on LLM-RAG. In Proceedings of the 2024 8th International Conference on Information System and Data Mining, New York, NY, USA, 24–26 June 2024; pp. 142–149. [Google Scholar] [CrossRef]
- Chen, Y.; Cui, S.; Huang, K.; Wang, S.; Tang, C.; Liu, T.; Fang, B. Improving Adaptive Knowledge Graph Construction via Large Language Models with Multiple Views. In Proceedings of the Knowledge Graph and Semantic Computing: Knowledge Graph Empowers Artificial General Intelligence, Shenyang, China, 24–27 August 2023; Wang, H., Han, X., Liu, M., Cheng, G., Liu, Y., Zhang, N., Eds.; Springer Nature: Singapore, 2023; pp. 273–284. [Google Scholar] [CrossRef]
- Khorashadizadeh, H.; Amara, F.Z.; Ezzabady, M.; Ieng, F.; Tiwari, S.; Mihindukulasooriya, N.; Groppe, J.; Sahri, S.; Benamara, F.; Groppe, S. Research Trends for the Interplay between Large Language Models and Knowledge Graphs. arXiv 2024, arXiv:2406.08223. [Google Scholar]
- Dehal, R.S.; Sharma, M.; de Souza Santos, R. Exposing Algorithmic Discrimination and Its Consequences in Modern Society: Insights from a Scoping Study. In Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Society, New York, NY, USA, 14–20 April 2024; pp. 69–73. [Google Scholar] [CrossRef]
- Peng, B.; Zhu, Y.; Liu, Y.; Bo, X.; Shi, H.; Hong, C.; Zhang, Y.; Tang, S. Graph Retrieval-Augmented Generation: A Survey. arXiv 2024, arXiv:2408.08921. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. GraphCodeBERT: Pre-training Code Representations with Data Flow. arXiv 2021, arXiv:2009.08366. [Google Scholar]
- Andrus, B.R.; Nasiri, Y.; Cui, S.; Cullen, B.; Fulda, N. Enhanced Story Comprehension for Large Language Models through Dynamic Document-Based Knowledge Graphs. Proc. Aaai Conf. Artif. Intell. 2022, 36, 10436–10444. [Google Scholar] [CrossRef]

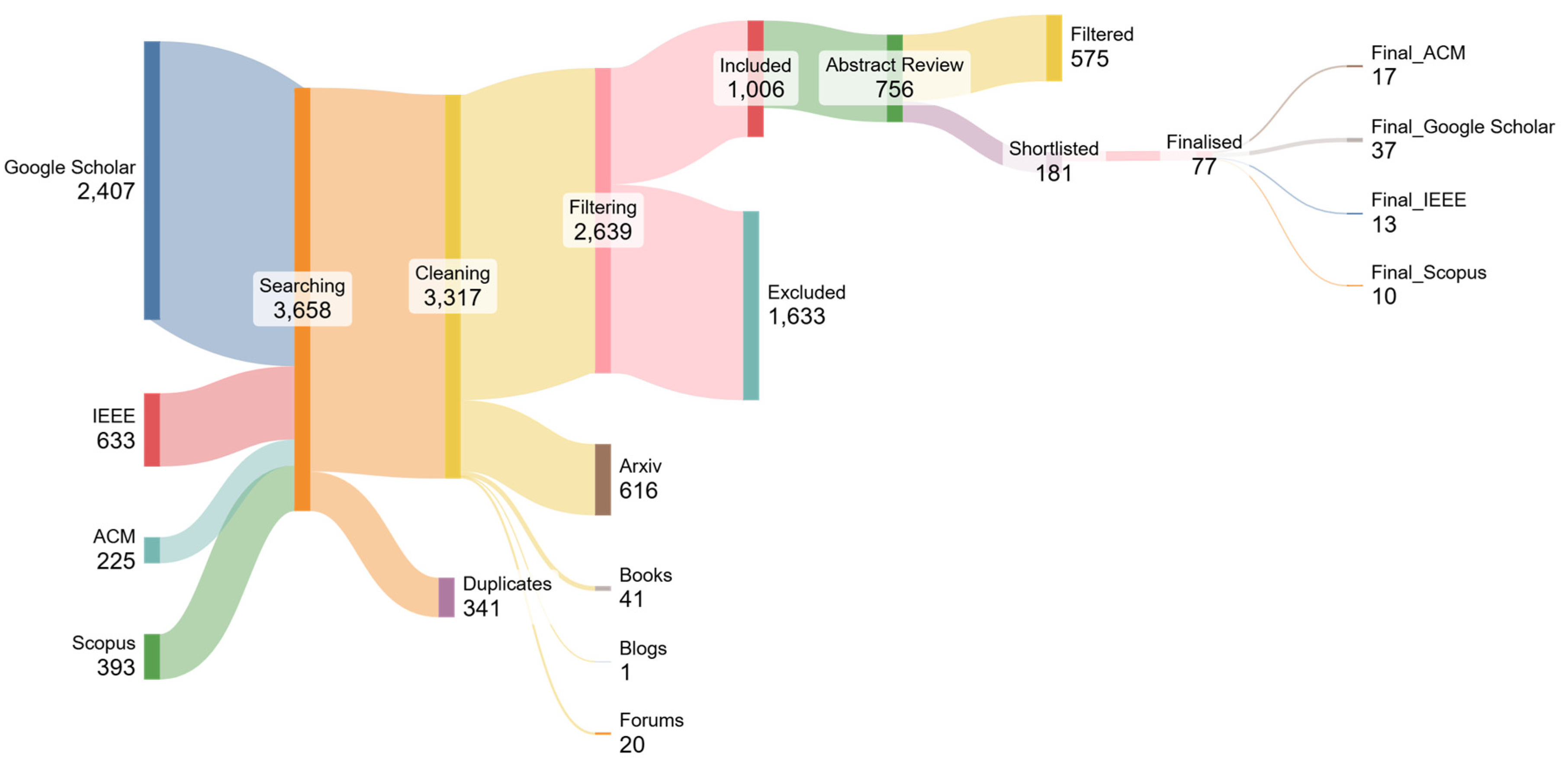
| Include Papers That Are | Exclude Papers That Are | ||
|---|---|---|---|
| IC-1 | Written in English | EC-1 | Published on blogs, forums, pages, or unofficial sites (e.g., not in conferences or journals) |
| IC-2 | Published in an official conference or journal (peer-reviewed) | EC-2 | Published in books or in ArXiv (not peer-reviewed in a conference or journal yet) |
| IC-3 | Discusses KGs, LLMs, or Semantic graphs and explore their workings | EC-3 | Primarily focused on AI/ML (determined by reviewing the title, introduction, and conclusion) |
| IC-4 | Published between 2019-2024 | EC-4 | Mentions Knowledge Graphs but is not focused on them |
| Model Implemented | Theme | Papers |
|---|---|---|
| Hybrid/Retrieval-Augmented Models | Combines LLMs with external retrieval, symbolic reasoning, or structured knowledge to enhance factual accuracy and context. | [11,12,13,14,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64] |
| Encoder–Decoder Transformers (Seq2Seq Models) | Transforms input sequences into structured or translated outputs, ideal for summarization, translation, and KG-to-text tasks. | [65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81] |
| Autoregressive Transformers (Decoder-Only) | A family of autoregressive language models, designed to generate coherent and contextually relevant text. | [82,83,84,85,86] |
| Bidirectional Transformers (Encoder-Only) | A transformer-based model pre-trained for understanding the context of words in both directions. | [87,88] |
| Symbolic–Neural Hybrids/Others | Integrates neural networks with rule-based or symbolic components, often used in domain-specific or low-resource applications. | [89,90] |
| Facets | Knowledge Graph → LLM | LLM → Knowledge Graph |
|---|---|---|
| Purpose | To enrich LLM’s output accuracy and data governance, providing factual grounding and regulatory compliance. | To automate or augment KG construction, expanding or updating the KG. |
| Input Format | Structured data (triples, graphs) | Unstructured data (text, documents) |
| Output | Improved text generation, reasoning, or prediction | Structured data such as nodes, edges, and triples |
| Key Processes | Grounding, reasoning, and contextualization | Entity extraction, relation identification |
| Example | Using a KG to answer, “Who is the CFO of Twitter?” accurately | Extracting “CFO of Twitter is Mr.X” from text to populate KG |
| Applications | Factual chatbots, personalized assistants | Dynamic KG updates, domain-specific KGs |
| Challenges | Handling incomplete or sparse KGs | Risk of introducing errors or biases |
| Research Question | Gap | Description |
|---|---|---|
| RQ1 (LLMs in KG Construction) | Static Construction Paradigms | Current focus is on static KGs, neglecting real-time dynamic updates. |
| Automation Deficits | Need to address automated schema generation or entity linking. | |
| RQ2 (KGs in Enhancing LLMs) | Explainability Challenges | Traceability between LLM outputs and KG nodes. |
| Sparse Multi-Hop Reasoning | Leveraging KGs for complex reasoning (e.g., causal inference). | |
| RQ3 (Methodological Diversity) | Ethical Oversights | Few studies address fairness, bias mitigation, or ethical governance. |
| Focus Area | Recommendation | Alignment with Gaps |
|---|---|---|
| Cross-Disciplinary Research | Prioritize underrepresented domains (e.g., finance, cultural heritage). | Addresses disciplinary imbalance and interdisciplinary gaps. |
| Multimodal Integration | Develop frameworks for combining KGs with visual, auditory, or sensor data. | Mitigates text-centric and multimodal input gaps. |
| Domain-Specific Models | Fine-tune LLMs and build specialized KGs for healthcare, finance, etc. | Reduces reliance on general-purpose models. |
| Explainability | Embed XAI frameworks to map LLM outputs to KG nodes. | Resolves explainability and traceability deficits. |
| Hybrid Methodologies | Integrate symbolic AI with machine learning for dynamic KG construction. | Addresses automation and methodological silos. |
| Ethical Governance | Institutionalize fairness audits and bias mitigation in methodologies. | Mitigates ethical oversights in sensitive domains. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dehal, R.S.; Sharma, M.; Rajabi, E. Knowledge Graphs and Their Reciprocal Relationship with Large Language Models. Mach. Learn. Knowl. Extr. 2025, 7, 38. https://doi.org/10.3390/make7020038
Dehal RS, Sharma M, Rajabi E. Knowledge Graphs and Their Reciprocal Relationship with Large Language Models. Machine Learning and Knowledge Extraction. 2025; 7(2):38. https://doi.org/10.3390/make7020038
Chicago/Turabian StyleDehal, Ramandeep Singh, Mehak Sharma, and Enayat Rajabi. 2025. "Knowledge Graphs and Their Reciprocal Relationship with Large Language Models" Machine Learning and Knowledge Extraction 7, no. 2: 38. https://doi.org/10.3390/make7020038
APA StyleDehal, R. S., Sharma, M., & Rajabi, E. (2025). Knowledge Graphs and Their Reciprocal Relationship with Large Language Models. Machine Learning and Knowledge Extraction, 7(2), 38. https://doi.org/10.3390/make7020038