
PIDQA—Question Answering on Piping and Instrumentation Diagrams


Abstract
1. Introduction
- A detailed framework for digitizing images of P&IDs into machine-readable graph data structures.
- A novel question–answer pairs dataset, PIDQA, consisting of 64,000 questions for 500 P&ID sheets in Dataset-P&ID covering 4 types of questions: (I) simple counting, (II) spatial counting, (III) spatial connections, and (IV) value-based queries. A representative sample is shown in Table 1. This study makes available the corresponding syntactically correct Cypher query translation for each question in PIDQA. To the best of our knowledge, there exist no publicly available datasets for question–answer pairs and text-to-Cypher queries for P&IDs. This dataset can also be used for training and evaluation of conventional Visual Question Answering (VQA) models like BLIP [26] or GIT [27] (The PIDQA dataset is publicly available at: https://github.com/mgupta70/PIDQA, accessed on 11 April 2025).
- A comprehensive evaluation of grounding techniques for the LLM to generate accurate and coherent responses while minimizing sensitivity to linguistic variations in user queries.
2. Literature Review
2.1. P&ID Digitization
2.2. Visual Question Answering
3. Methods
3.1. P&ID Dataset and Generation of Question–Answer Pairs
- I.
- Simple counting: This question type is related to counting tasks while generating material takeoffs (MTOs). For instance, [49] highlights that in the absence of digital P&IDs, engineers spend hours manually reviewing documents and generating MTOs.
- II.
- Spatial counting: This question type focuses on quickly searching spatial relationships for defined design property patterns in large and dense P&ID datasets. For example, in gravity flow systems, pumps are typically provided with strainers on their upstream side to prevent debris from damaging the pump [50]. With access to the proposed information retrieval system, an engineer can simply ask a question like, “Count the number of instances where strainers are not provided upstream of pumps?” for a quick design review.
- III.
- Spatial connections: This question type centers on determining whether a specific component exists between two other components, often serving as a safety check. For instance, as per OISD-129, in oil refineries, petroleum tanks are typically equipped with an automatic valve followed by a manual valve in succession to ensure fire safety compliance. A query like “Is there an automatic valve between an oil tank and a manual valve?” verifies adherence to this safety standard. This question requires traversing through intermediate nodes in a P&ID graph, making it a multi-hop operation.
- IV.
- Value-based queries: This question type simplifies the process of locating objects of interest across multiple P&ID drawings. They can also assist in identifying potential CAD drafting errors. For example, a rule such as “All Butterfly Valve tags must start with ’BV’, else provide details of violation” can return a list of drawings and specific locations where this naming policy is violated, ensuring consistency and aiding in error detection.
3.2. Making P&ID Queryable with Natural Language
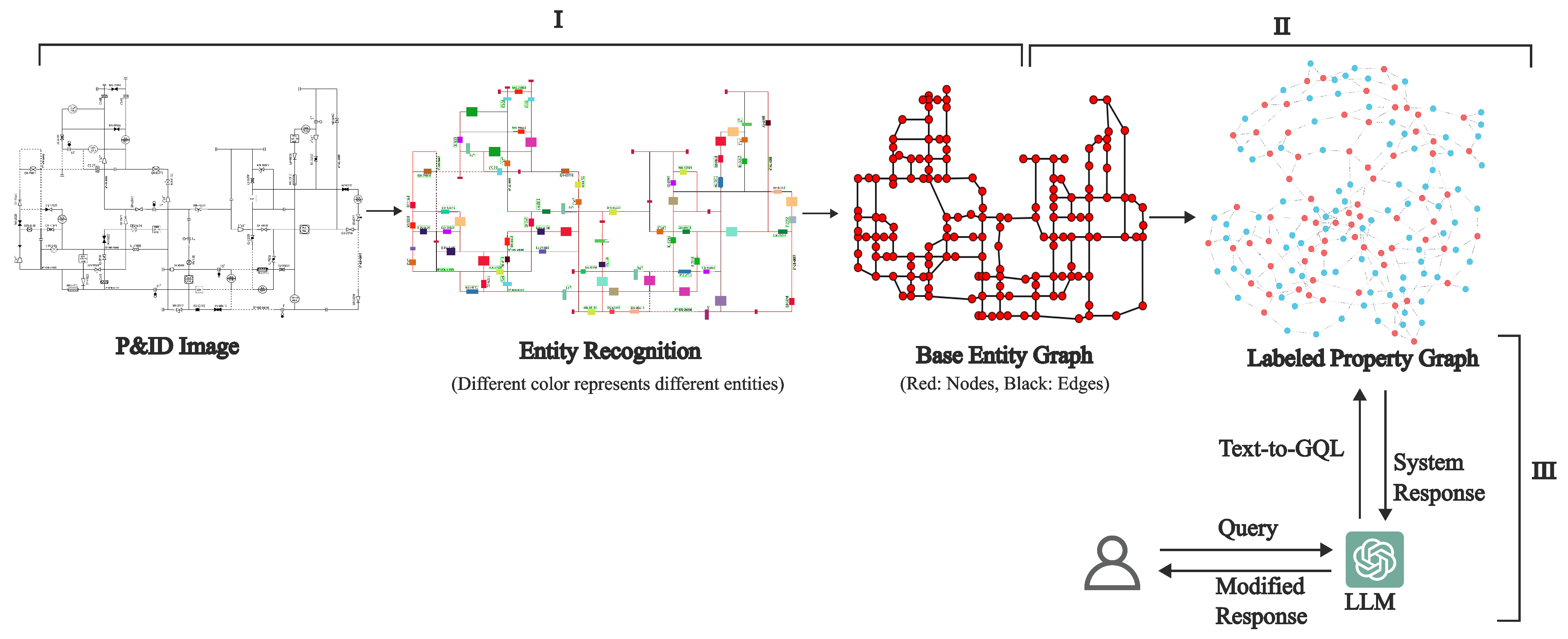
3.2.1. P&ID Sheet to a Base Entity Graph (Step-I)
- Text: Text in a P&ID is detected using a KerasOCR [54] model fine-tuned on the training set of Dataset-P&ID using the image-tiling approach.
- Lines: These are recognized with a custom method combining Probabilistic Hough Transform (PHT) and a post-processing, step merging duplicate lines effectively. Moreover, the hyperparameters for PHT are programmatically selected, obviating the need for any manual tuning. The details are shown graphically in Figure 5A–G.
3.2.2. Base Entity Graph to Labeled Property Graph (Step II)
3.2.3. Information Retrieval System (Step III)
4. Results and Discussion
4.1. Entity Recognition
4.2. Creation of Graph Structure
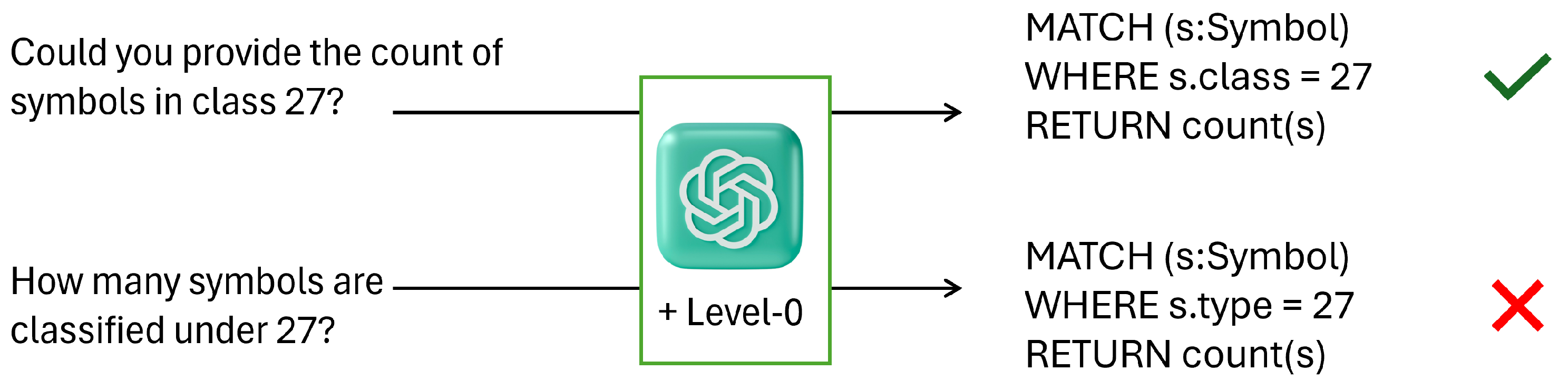
4.3. Information Retrieval System
5. Limitations
6. Conclusions and Future Study
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Court, A.; Ullman, D.; Culley, S. A Comparison Between the Provision of Information to Engineering Designers in the UK and the USA. Int. J. Inf. Manag. 1998, 18, 409–425. [Google Scholar] [CrossRef]
- Kasimov, D.R.; Kuchuganov, A.V.; Kuchuganov, V.N. Individual strategies in the tasks of graphical retrieval of technical drawings. J. Vis. Lang. Comput. 2015, 28, 134–146. [Google Scholar] [CrossRef]
- Hofer-Alfeis, J.; Maderlechner, G. Automated Conversion of Mechanical Engineering Drawings to CAD Models: Too many Problems? In Proceedings of the IAPR International Workshop on Machine Vision Applications, Tokyo, Japan,, 12–14 October 1988. [Google Scholar]
- Azzam, S.; Mohamed, S.; ELDASH, K. Outsourcing Engineering Tasks by Construction Firms: State-of-the-Art. Eng. Res. J. (Shoubra) 2023, 52, 157–168. [Google Scholar] [CrossRef]
- Joy, J.; Mounsef, J. Automation of Material Takeoff using Computer Vision. In Proceedings of the 2021 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), Bandung, Indonesia, 27–28 July 2021; pp. 196–200. [Google Scholar] [CrossRef]
- Li, Z.; Victor, R.; Karthik, R. A Methodology of Engineering Ontology Development for Information Retrieval. Proceedings of ICED 2007, the 16th International Conference on Engineering Design (ICED), Paris, France, 28–31 July 2007. [Google Scholar]
- Aliakbar Heidari, Y.P.; Amanzadegan, M. A systematic review of the BIM in construction: From smart building management to interoperability of BIM & AI. Archit. Sci. Rev. 2024, 67, 237–254. [Google Scholar] [CrossRef]
- Li, N.; Li, Q.; Liu, Y.S.; Lu, W.; Wang, W. BIMSeek++: Retrieving BIM components using similarity measurement of attributes. Comput. Ind. 2020, 116, 103186. [Google Scholar] [CrossRef]
- Hertzum, M.; Pejtersen, A.M. The information-seeking practices of engineers: Searching for documents as well as for people. Inf. Process. Manag. 2000, 36, 761–778. [Google Scholar] [CrossRef]
- Ranasinghe, U.; Tang, L.M.; Harris, C.; Li, W.; Montayre, J.; de Almeida Neto, A.; Antoniou, M. A systematic review on workplace health and safety of ageing construction workers. Saf. Sci. 2023, 167, 106276. [Google Scholar] [CrossRef]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 2011; Lin, D., Matsumoto, Y., Mihalcea, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 541–550. [Google Scholar]
- Bordes, A.; Weston, J.; Usunier, N. Open Question Answering with Weakly Supervised Embedding Models. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Nancy, France, 15–19 September 2014; Calders, T., Esposito, F., Hüllermeier, E., Meo, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 165–180. [Google Scholar]
- Heck, L.; Hakkani-Tür, D.Z.; Tür, G. Leveraging knowledge graphs for web-scale unsupervised semantic parsing. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013. [Google Scholar]
- Hakimov, S.; Oto, S.A.; Dogdu, E. Named entity recognition and disambiguation using linked data and graph-based centrality scoring. In Proceedings of the 4th International Workshop on Semantic Web Information Management, New York, NY, USA, 20 May 2012. SWIM’12. [Google Scholar] [CrossRef]
- Yüksel, K.E.; Üsküdarli, S. Incorporating Knowledge Graph Embeddings into Graph Neural Networks for Sequential Recommender Systems. In Proceedings of the 2024 9th International Conference on Computer Science and Engineering (UBMK), Antalya, Turkiye, 26–28 October 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Purohit, S.; Van, N.; Chin, G. Semantic Property Graph for Scalable Knowledge Graph Analytics. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 2672–2677. [Google Scholar] [CrossRef]
- Elyan, E.; Garcia, C.M.; Jayne, C. Symbols Classification in Engineering Drawings. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Dzhusupova, R.; Banotra, R.; Bosch, J.; Olsson, H.H. Using artificial intelligence to find design errors in the engineering drawings. J. Software: Evol. Process 2023, 35, e2543. [Google Scholar] [CrossRef]
- Kim, H.; Lee, W.; Kim, M.; Moon, Y.; Lee, T.; Cho, M.; Mun, D. Deep-learning-based recognition of symbols and texts at an industrially applicable level from images of high-density piping and instrumentation diagrams. Expert Syst. Appl. 2021, 183, 115337. [Google Scholar] [CrossRef]
- Tan, W.C.; Chen, I.M.; Tan, H.K. Automated identification of components in raster piping and instrumentation diagram with minimal pre-processing. In Proceedings of the 2016 IEEE International Conference on Automation Science and Engineering (CASE), Fort Worth, TX, USA, 21–25 August 2016; pp. 1301–1306. [Google Scholar] [CrossRef]
- Xie, L.; Lu, Y.; Furuhata, T.; Yamakawa, S.; Zhang, W.; Regmi, A.; Kara, L.; Shimada, K. Graph neural network-enabled manufacturing method classification from engineering drawings. Comput. Ind. 2022, 142, 103697. [Google Scholar] [CrossRef]
- Moreno-García, C.F.; Elyan, E.; Jayne, C. New trends on digitisation of complex engineering drawings. Neural Comput. Appl. 2019, 31, 1695–1712. [Google Scholar] [CrossRef]
- Gupta, M.; Wei, C.; Czerniawski, T. Semi-supervised symbol detection for piping and instrumentation drawings. Autom. Constr. 2024, 159, 105260. [Google Scholar] [CrossRef]
- Paliwal, S.; Jain, A.; Sharma, M.; Vig, L. Digitize-PID: Automatic Digitization of Piping and Instrumentation Diagrams. In Proceedings of the Trends and Applications in Knowledge Discovery and Data Mining; Gupta, M., Ramakrishnan, G., Eds.; Springer: Cham, Switzerland, 2021; pp. 168–180. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. In Proceedings of the ICML, New York, NY, USA, 18–21 February 2022. [Google Scholar]
- Wang, J.; Yang, Z.; Hu, X.; Li, L.; Lin, K.; Gan, Z.; Liu, Z.; Liu, C.; Wang, L. GIT: A Generative Image-to-text Transformer for Vision and Language. arXiv 2022, arXiv:2205.14100. [Google Scholar]
- Kim, B.C.; Kim, H.; Moon, Y.; Lee, G.; Mun, D. End-to-end digitization of image format piping and instrumentation diagrams at an industrially applicable level. J. Comput. Des. Eng. 2022, 9, 1298–1326. [Google Scholar] [CrossRef]
- Yu, E.S.; Cha, J.M.; Lee, T.; Kim, J.; Mun, D. Features Recognition from Piping and Instrumentation Diagrams in Image Format Using a Deep Learning Network. Energies 2019, 12, 4425. [Google Scholar] [CrossRef]
- Moon, Y.; Lee, J.; Mun, D.; Lim, S. Deep Learning-Based Method to Recognize Line Objects and Flow Arrows from Image-Format Piping and Instrumentation Diagrams for Digitization. Appl. Sci. 2021, 11, 10054. [Google Scholar] [CrossRef]
- Rahul, R.; Paliwal, S.; Sharma, M.; Vig, L. Automatic Information Extraction from Piping and Instrumentation Diagrams. arXiv 2019, arXiv:1901.11383. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 22 September 2024).
- Smith, R. An Overview of the Tesseract OCR Engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; Volume 2, pp. 629–633. [Google Scholar] [CrossRef]
- Vedhaviyassh, D.; Sudhan, R.; Saranya, G.; Safa, M.; Arun, D. Comparative Analysis of EasyOCR and TesseractOCR for Automatic License Plate Recognition using Deep Learning Algorithm. In Proceedings of the 2022 6th International Conference on Electronics, Communication and Aerospace Technology, Coimbatore, India, 1–3 December 2022; pp. 966–971. [Google Scholar] [CrossRef]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character Region Awareness for Text Detection. arXiv 2019, arXiv:1904.01941. [Google Scholar] [CrossRef]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Kafle, K.; Kanan, C. An Analysis of Visual Question Answering Algorithms. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1983–1991. [Google Scholar] [CrossRef]
- Masry, A.; Do, X.L.; Tan, J.Q.; Joty, S.; Hoque, E. ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2263–2279. [Google Scholar] [CrossRef]
- Babkin, P.; Watson, W.; Ma, Z.; Cecchi, L.; Raman, N.; Nourbakhsh, A.; Shah, S. BizGraphQA: A Dataset for Image-based Inference over Graph-structured Diagrams from Business Domains. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 23–27 July 2023; SIGIR ’23. pp. 2691–2700. [Google Scholar] [CrossRef]
- Lu, P.; Mishra, S.; Xia, T.; Qiu, L.; Chang, K.W.; Zhu, S.C.; Tafjord, O.; Clark, P.; Kalyan, A. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. NIPS ’22.. [Google Scholar]
- Kunlamai, T.; Yamane, T.; Suganuma, M.; Chun, P.J.; Okatani, T. Improving visual question answering for bridge inspection by pre-training with external data of image–text pairs. Comput.-Aided Civ. Infrastruct. Eng. 2024, 39, 345–361. [Google Scholar] [CrossRef]
- Ding, Y.; Liu, M.; Luo, X. Safety compliance checking of construction behaviors using visual question answering. Autom. Constr. 2022, 144, 104580. [Google Scholar] [CrossRef]
- Wen, S.; Park, M.; Tran, D.Q.; Lee, S.; Park, S. Automated construction safety reporting system integrating deep learning-based real-time advanced detection and visual question answering. Adv. Eng. Softw. 2024, 198, 103779. [Google Scholar] [CrossRef]
- Shi, X.; Lee, S. Benchmarking Out-of-Distribution Detection in Visual Question Answering. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 5473–5483. [Google Scholar] [CrossRef]
- Zhang, M.; Maidment, T.; Diab, A.; Kovashka, A.; Hwa, R. Domain-robust VQA with diverse datasets and methods but no target labels. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7042–7052. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, X.; Li, H. Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts. In Proceedings of the International Conference on Machine Learning, Shenzhen, China, 26 February–1 March 2021. [Google Scholar]
- Artificial Intelligence for the Automatic Generation of Material Take offs from Piping and Instrumentation Diagrams, Vol. Day 3 Wed, 4 October 2023, Abu Dhabi International Petroleum Exhibition and Conference. 2023. Available online: https://onepetro.org/SPEADIP/proceedings-pdf/23ADIP/3-23ADIP/D031S117R002/3281517/spe-216815-ms.pdf (accessed on 3 January 2025). [CrossRef]
- Park, Y.C.; Ryu, J.S. Design and Test of ASME Strainer for Primary Cooling System in HANARO. In Proceedings of the Sixth Asian Symposium on Research Reactors, Mito, Japan, 29-31 March 1999; pp. 130–135. [Google Scholar]
- Mehta, R.; Singh, B.; Varma, V.; Gupta, M. CircuitVQA: A Visual Question Answering Dataset for Electrical Circuit Images. In Proceedings of the Machine Learning and Knowledge Discovery in Databases. Research Track; Bifet, A., Davis, J., Krilavičius, T., Kull, M., Ntoutsi, E., Žliobaitė, I., Eds.; Springer: Cham, Switzerland, 2024; pp. 440–460. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Akyon, F.C.; Onur Altinuc, S.; Temizel, A. Slicing Aided Hyper Inference and Fine-Tuning for Small Object Detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 966–970. [Google Scholar] [CrossRef]
- Tarawneh, A.S.; Hassanat, A.B.; Chetverikov, D.; Lendak, I.; Verma, C. Invoice Classification Using Deep Features and Machine Learning Techniques. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019; pp. 855–859. [Google Scholar] [CrossRef]
- Hagberg, A.; Swart, P.J.; Schult, D.A. Exploring Network Structure, Dynamics, and Function Using NetworkX; Los Alamos National Laboratory (LANL): Los Alamos, NM, USA, 2008. [Google Scholar]
- Miller, J.J. Graph Database Applications and Concepts with Neo4j. In Proceedings of the southern association for information systems conference, Atlanta, GA, USA, 8–9 March 2013; Volume 2324, no. 36. pp. 141–147. [Google Scholar]
- Özsoy, M.G.; Messallem, L.; Besga, J.; Minneci, G. Text2Cypher: Bridging Natural Language and Graph Databases. arXiv 2024, arXiv:2412.10064. [Google Scholar]
- Zhang, S.; Dong, L.; Li, X.; Zhang, S.; Sun, X.; Wang, S.; Li, J.; Hu, R.; Zhang, T.; Wu, F.; et al. Instruction Tuning for Large Language Models: A Survey. arXiv 2023, arXiv:2308.10792. [Google Scholar] [CrossRef]
- Yu, X.; Huang, Q.; Wang, Z.; Feng, Y.; Zhao, D. Towards Context-Aware Code Comment Generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3938–3947. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Ma, J.; Li, R.; Xia, H.; Xu, J.; Wu, Z.; Chang, B.; et al. A Survey on In-context Learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 1107–1128. [Google Scholar] [CrossRef]
- Paul, D.G.; Zhu, H.; Bayley, I. Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review. In Proceedings of the 2024 IEEE International Conference on Artificial Intelligence Testing (AITest), Shanghai, China, 15–18 July 2024; pp. 87–94. [Google Scholar] [CrossRef]
- Gan, Y.; Chen, X.; Huang, Q.; Purver, M.; Woodward, J.R.; Xie, J.; Huang, P. Towards Robustness of Text-to-SQL Models against Synonym Substitution. arXiv 2021, arXiv:2106.01065. [Google Scholar]
- Deng, X.; Awadallah, A.H.; Meek, C.; Polozov, O.; Sun, H.; Richardson, M. Structure-Grounded Pretraining for Text-to-SQL. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tur, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1337–1350. [Google Scholar] [CrossRef]
- Gu, Z.; Fan, J.; Tang, N.; Cao, L.; Jia, B.; Madden, S.; Du, X. Few-shot Text-to-SQL Translation using Structure and Content Prompt Learning. Proc. ACM Manag. Data 2023, 1, 1–28. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Question Type | Question | Answer |
|---|---|---|
| Simple counting | How many symbols of class 1 are present? | 2 |
| Spatial counting | How many symbols with class 28 are linked directly to symbols with class 32? | 1 |
| Spatial connections | Is there a symbol in class 17 that is connected to class 21 on one side and class 25 on the other? | True |
| Value | Give me all class 31 symbols whose tag starts with ZLO. | [ZLO 433] |
| Question Type | Number of Questions | |
|---|---|---|
| 1 Sheet | 500 Sheets | |
| Simple counting | 32 | 16,000 |
| Spatial counting | 32 | 16,000 |
| Spatial connections | 32 | 16,000 |
| Value | 32 | 16,000 |
| Total | 128 | 64,000 |
| Entity | Model | Recall | Precision | F1 Score |
|---|---|---|---|---|
| Symbols | YOLOv11 | 0.999 | 0.997 | 0.998 |
| Text | KerasOCR | 0.997 | 0.992 | 0.994 |
| Lines | PHT + line refinement | 0.999 | 0.996 | 0.997 |
| Task | Accuracy with Context | |||
|---|---|---|---|---|
| Level 0 | Level 1 | Level 2 | Level 3 | |
| Simple counting | 0.127 | 0.866 | 0.871 | 0.995 |
| Spatial counting | 0.571 | 0.713 | 0.88 | 0.986 |
| Spatial connections | 0.135 | 0.29 | 0.54 | 0.975 |
| Value | 0.172 | 0.565 | 0.762 | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gupta, M.; Wei, C.; Czerniawski, T.; Eiris, R. PIDQA—Question Answering on Piping and Instrumentation Diagrams. Mach. Learn. Knowl. Extr. 2025, 7, 39. https://doi.org/10.3390/make7020039
Gupta M, Wei C, Czerniawski T, Eiris R. PIDQA—Question Answering on Piping and Instrumentation Diagrams. Machine Learning and Knowledge Extraction. 2025; 7(2):39. https://doi.org/10.3390/make7020039
Chicago/Turabian StyleGupta, Mohit, Chialing Wei, Thomas Czerniawski, and Ricardo Eiris. 2025. "PIDQA—Question Answering on Piping and Instrumentation Diagrams" Machine Learning and Knowledge Extraction 7, no. 2: 39. https://doi.org/10.3390/make7020039
APA StyleGupta, M., Wei, C., Czerniawski, T., & Eiris, R. (2025). PIDQA—Question Answering on Piping and Instrumentation Diagrams. Machine Learning and Knowledge Extraction, 7(2), 39. https://doi.org/10.3390/make7020039