
Object Detection through Fires Using Violet Illumination Coupled with Deep Learning



Abstract
1. Introduction
- (1)
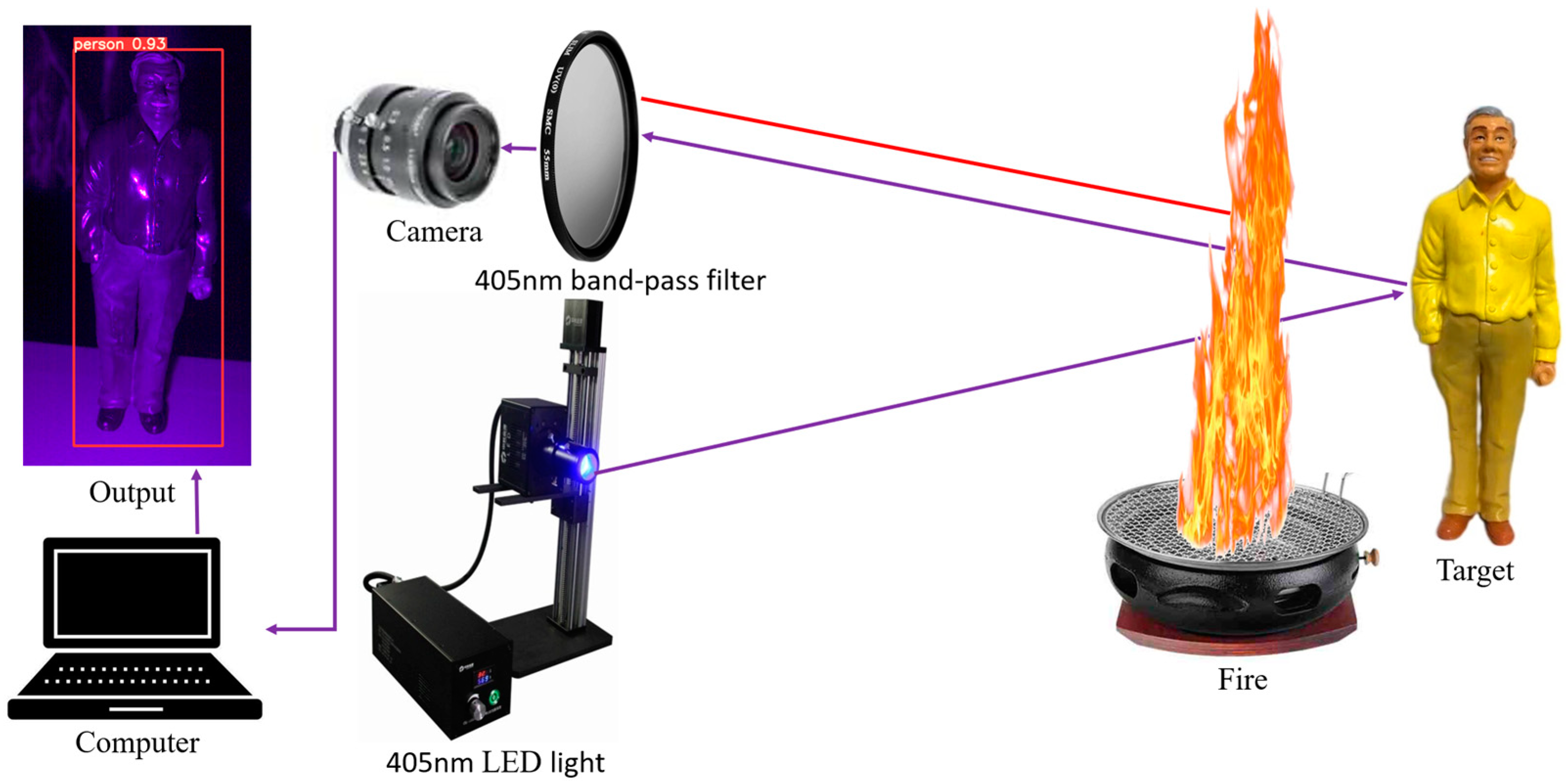
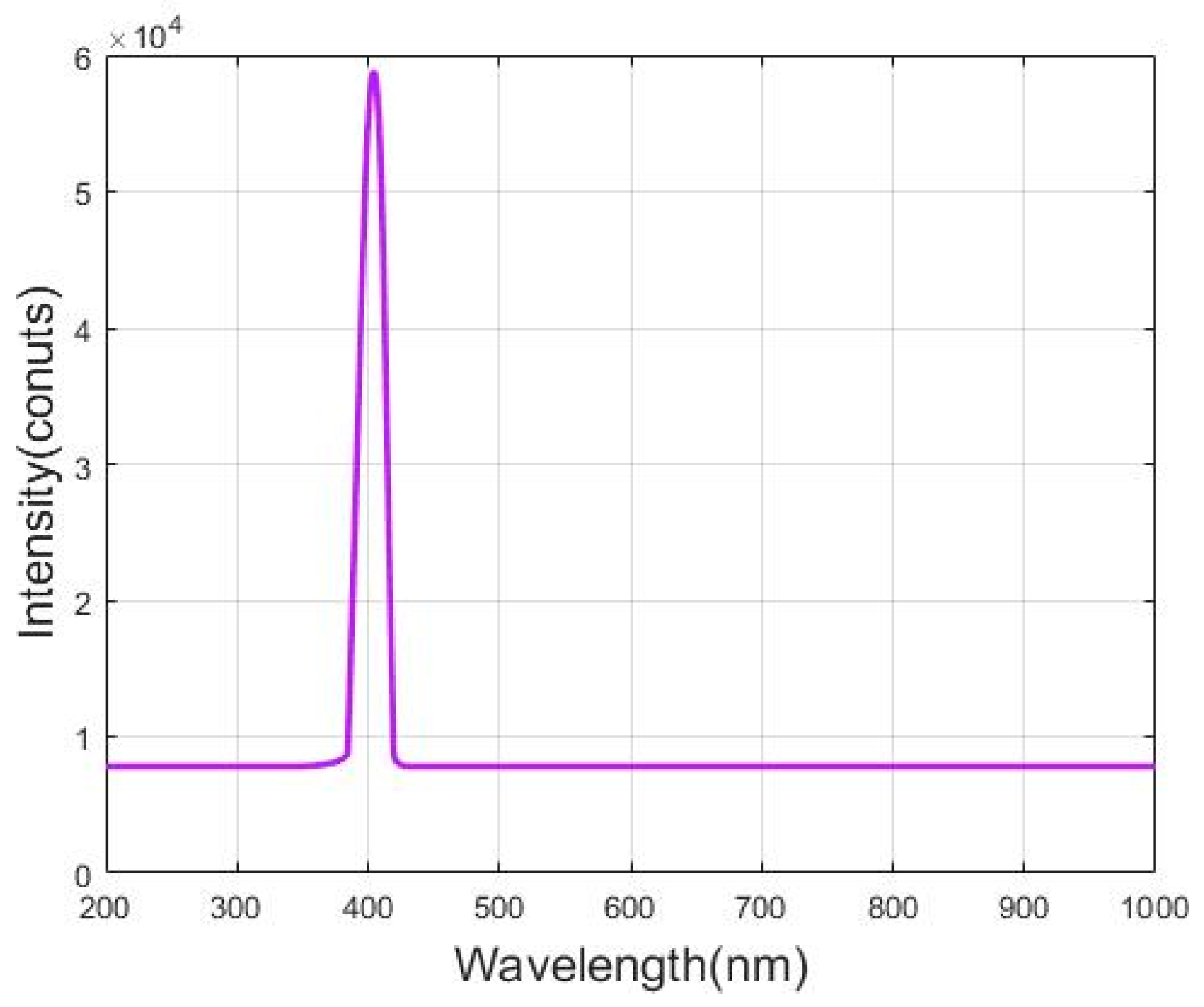
- The use of a 405 nm LED light source, a CMOS camera, and a matched band-pass optical filter to capture images of targets under different conditions of flames, thereby reducing the obstruction caused by flames and enhancing the signal-to-noise ratio;
- (2)
- The application of a dehazing algorithm in image processing; several dehazing algorithms are used to ameliorate the blocking effect of smoke and soot;
- (3)
- The application of the YOLOv5 object detection algorithm to detect the targets behind flames and to improve the detection accuracy by training the deep learning model with images collected from fire scenes.
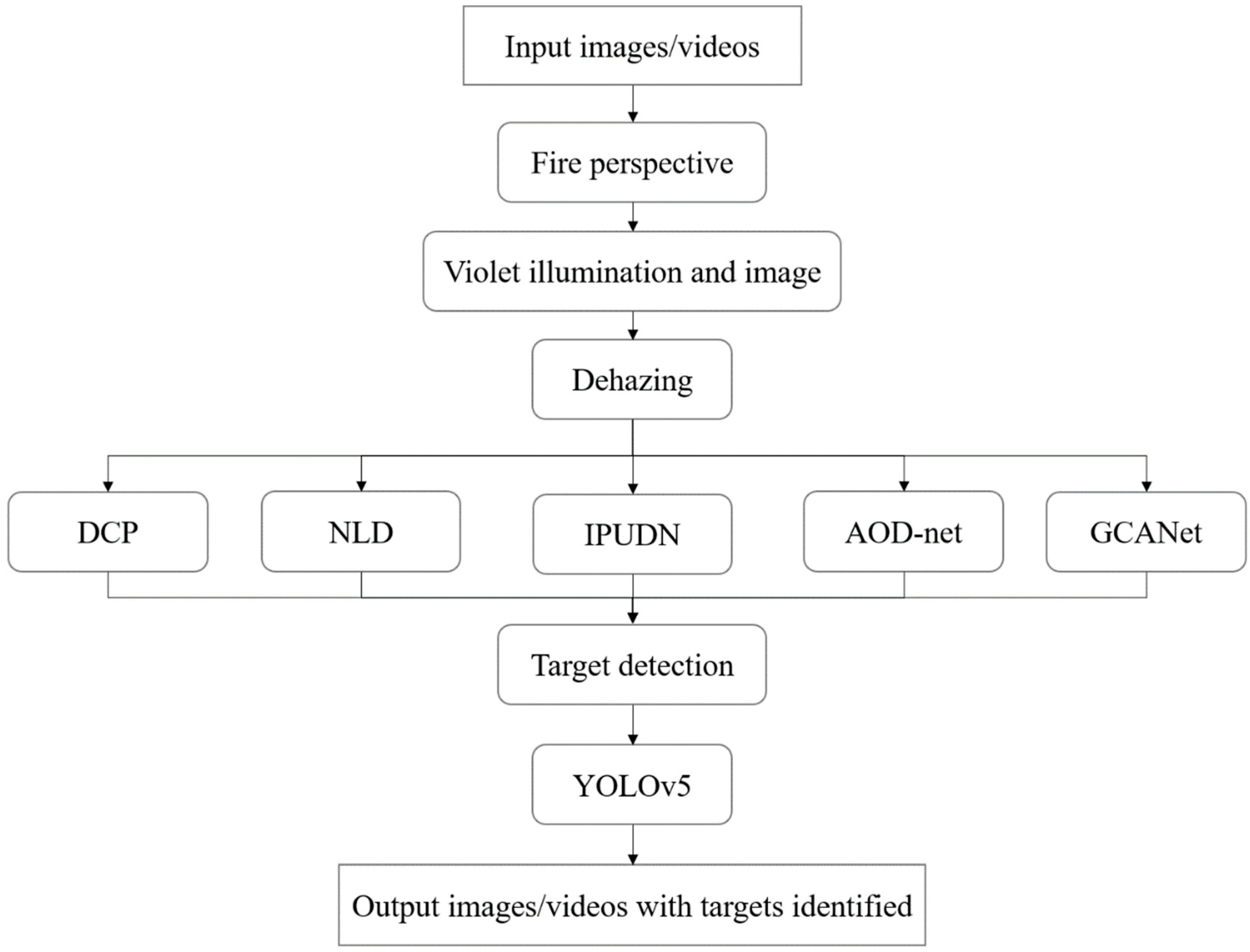
2. Methodology
2.1. Experimental Setup
2.2. Haze Removal Methods
2.2.1. Dark Channel Prior
2.2.2. Non-Local Image Dehazing
2.2.3. AOD-Net
2.2.4. IPUDN
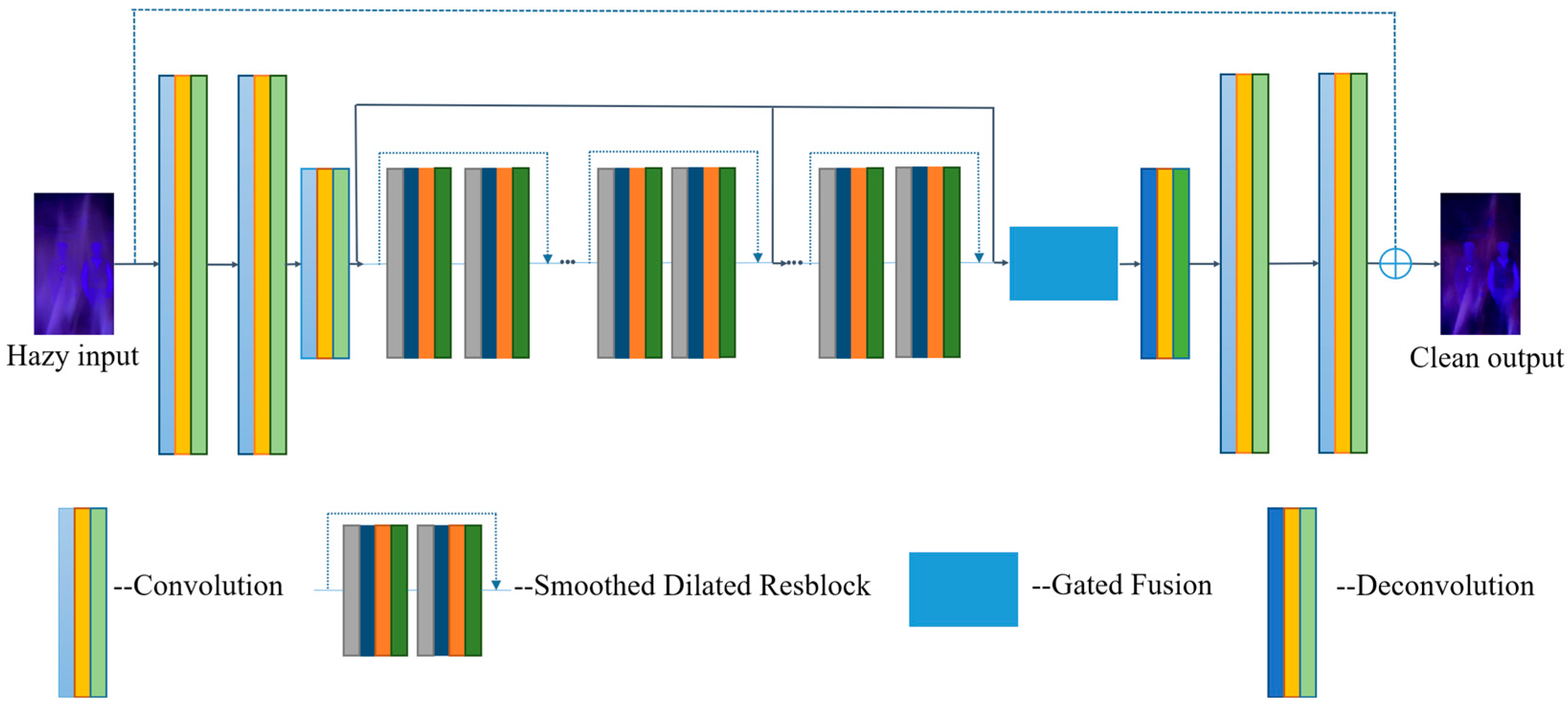
2.2.5. GCANet
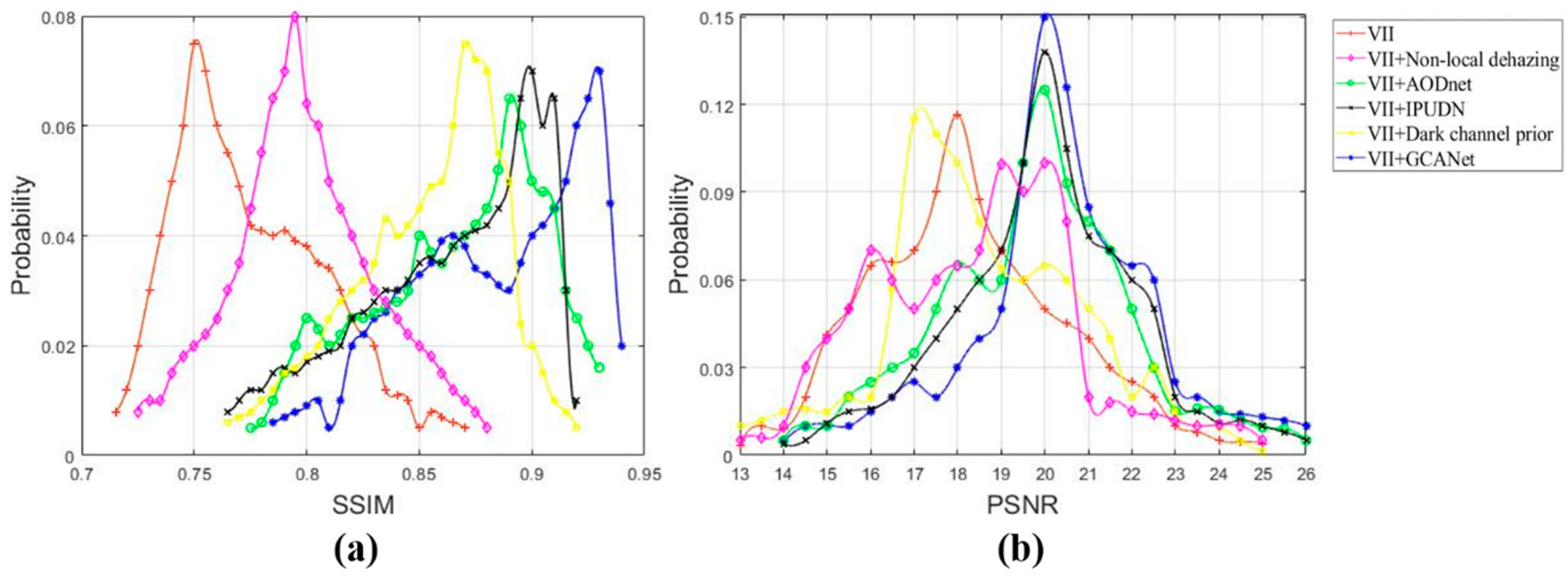
2.3. Evaluation Indices
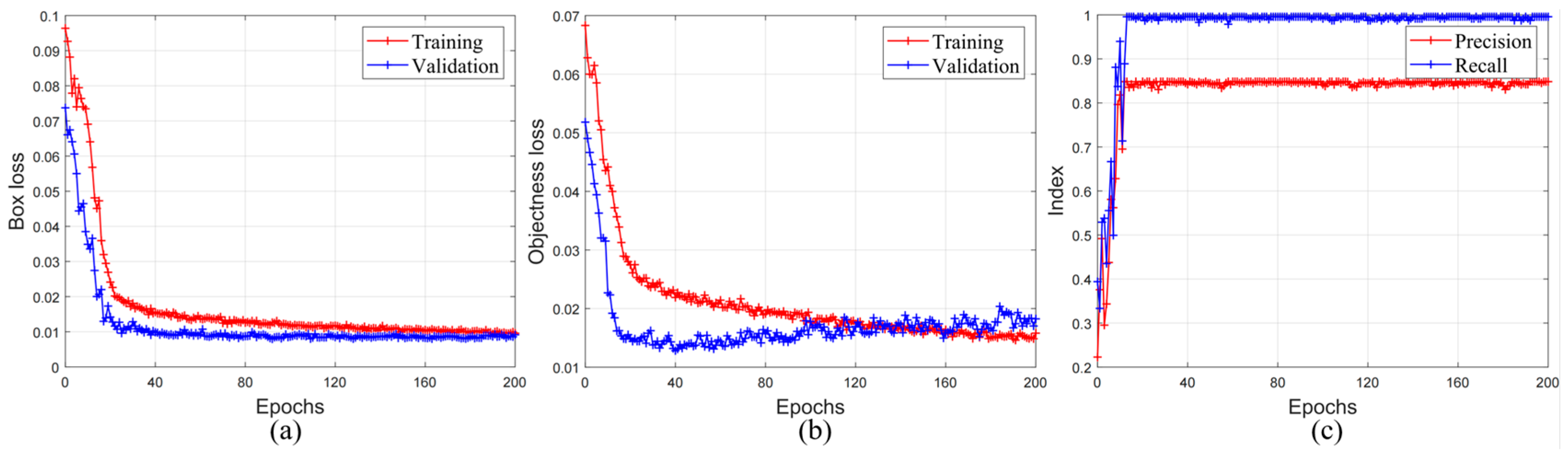
3. Object Detection Algorithms
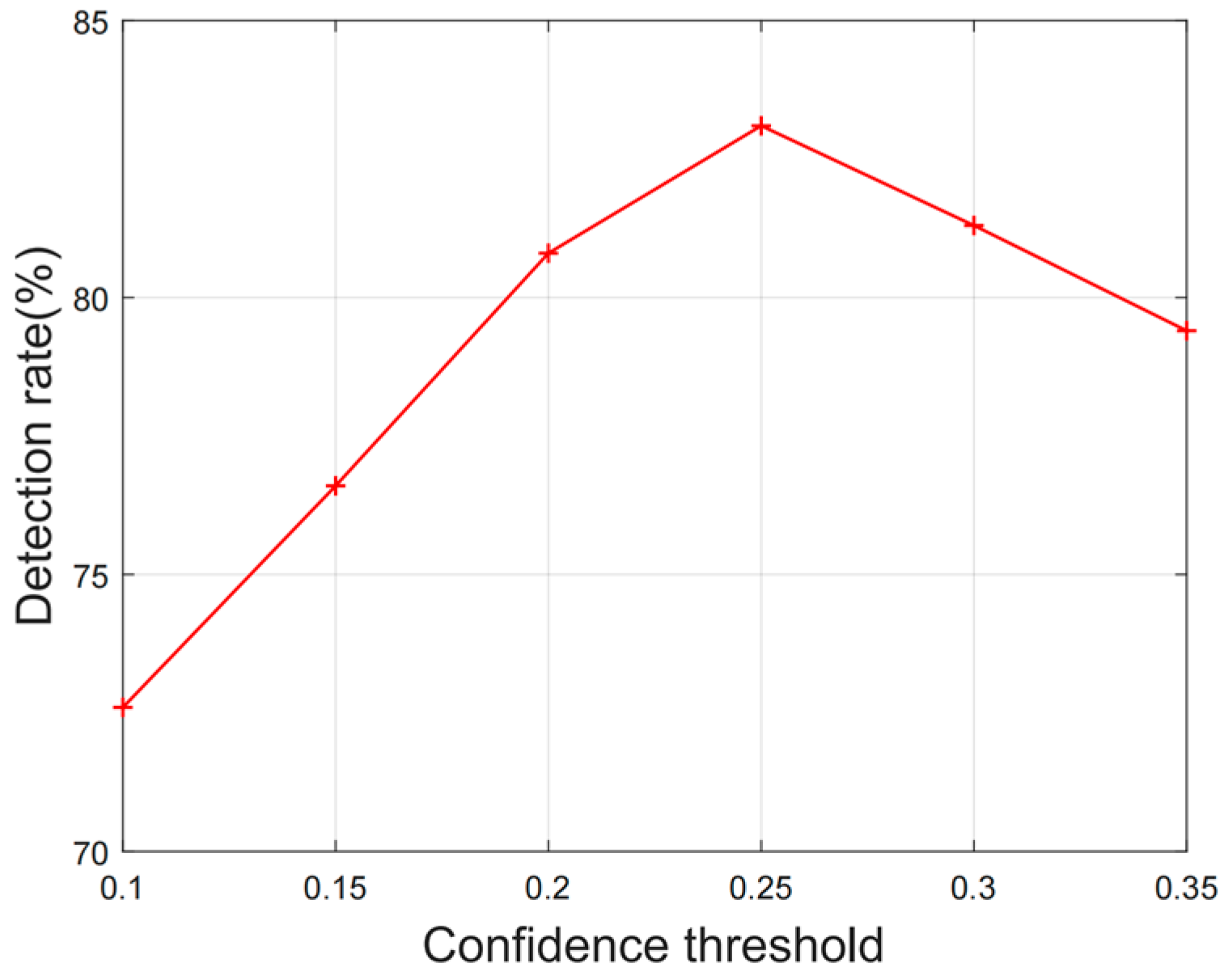
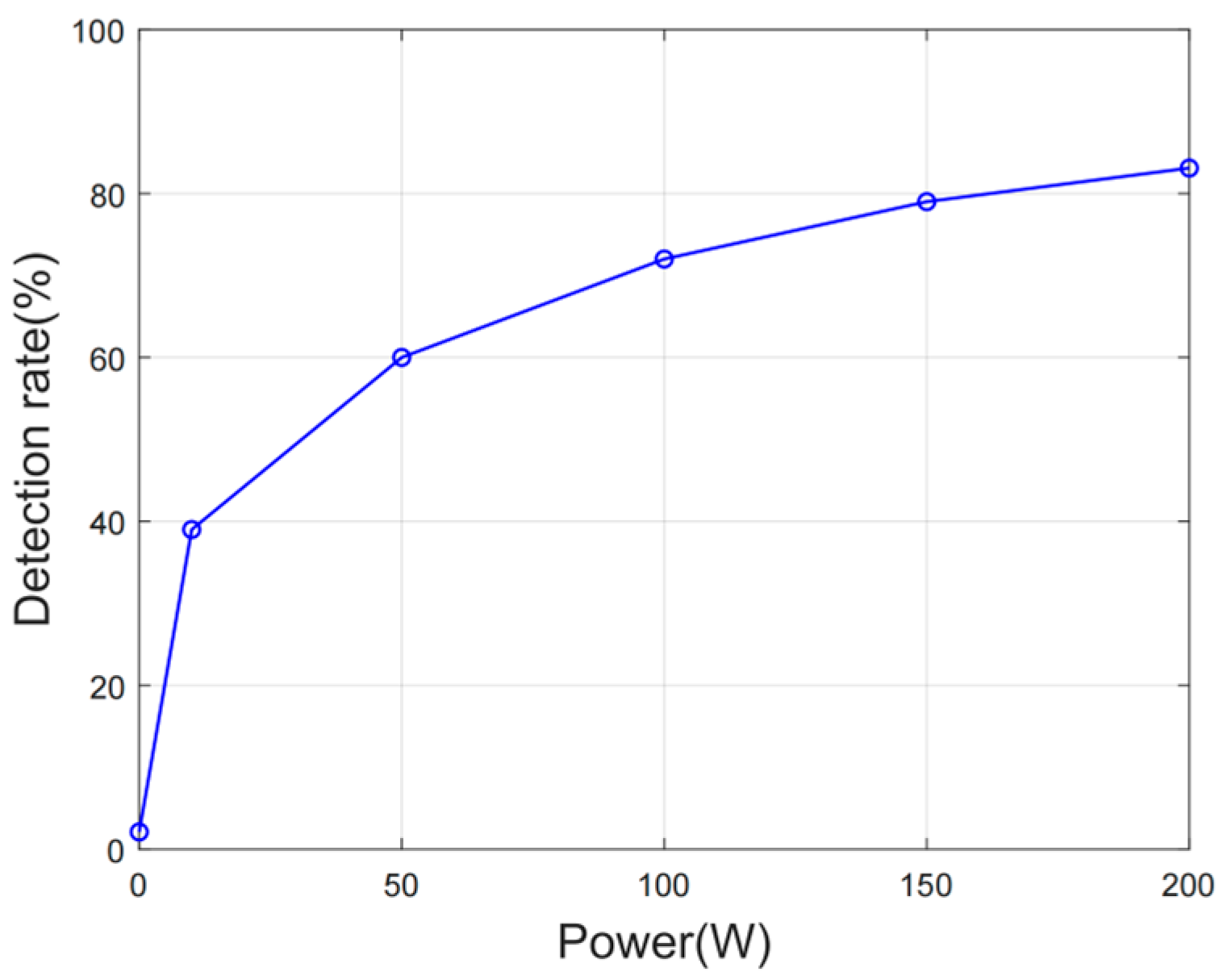
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Twigg, J.; Christie, N.; Haworth, J.; Osuteye, E.; Skarlatidou, A. Improved Methods for Fire Risk Assessment in Low-Income and Informal Settlements. Int. J. Environ. Res. Public Health 2017, 14, 139. [Google Scholar] [CrossRef] [PubMed]
- Cvetkovic, V.M.; Dragasevic, A.; Protic, D.; Jankovic, B.; Nikolic, N.; Milosevic, P. Fire safety behavior model for residential buildings: Implications for disaster risk reduction. Int. J. Disaster Risk Reduct. 2022, 76, 102981. [Google Scholar] [CrossRef]
- Hoehler, M.S.; Smith, C.M. Application of blue laser triangulation sensors for displacement measurement through fire. Meas. Sci. Technol. 2016, 27, 115201. [Google Scholar] [CrossRef] [PubMed]
- Smith, C.M.; Hoehler, M.S. Imaging Through Fire Using Narrow-Spectrum Illumination. Fire Technol. 2018, 54, 1705–1723. [Google Scholar] [CrossRef] [PubMed]
- Gatien, S.; Young, T.; Hoehler, M.S.; Gales, J. Application of narrow-spectrum illumination and image processing to measure surface char formation in lateral ignition and flame spread tests. Fire Mater. 2019, 43, 358–364. [Google Scholar] [CrossRef] [PubMed]
- Debnath, B.; Dharmadhikari, J.A.; Meena, M.S.; Ramachandran, H.; Dharmadhikari, A.K. Improved imaging through flame and smoke using blue LED and quadrature lock-in discrimination algorithm. Opt. Lasers Eng. 2022, 154, 107045. [Google Scholar] [CrossRef]
- Berman, D.; Treibitz, T.; Avidan, S. Non-Local Image Dehazing. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. In Proceedings of the IEEE-Computer-Society Conference on Computer Vision and Pattern Recognition Workshops, Miami Beach, FL, USA, 20–25 June 2009. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. An all-in-one network for dehazing and beyond. arXiv 2017, arXiv:1707.06543. [Google Scholar]
- Kar, A.; Dhara, S.K.; Sen, D.; Biswas, P.K. Transmission map and atmospheric light guided iterative updater network for single image Dehazing. arXiv 2020, arXiv:2008.01701. [Google Scholar]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated Context Aggregation Network for Image Dehazing and Deraining. In Proceedings of the 19th IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar]
- Guo, X.; Yang, Y.; Wang, C.; Ma, J. Image dehazing via enhancement, restoration, and fusion: A survey. Inf. Fusion 2022, 86–87, 146–170. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the ACM Conference on Multimedia (MM), Univ Cent Florida, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deepdriving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2722–2730. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yang, Z.; Nevatia, R. A Multi-Scale Cascade Fully Convolutional Network Face Detector. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Mexican Assoc Comp Vis Robot & Neural Comp, Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Bianco, V.; Mazzeo, P.L.; Paturzo, M.; Distante, C.; Ferraro, P. Deep learning assisted portable IR active imaging sensor spots and identifies live humans through fire. Opt. Lasers Eng. 2020, 124, 105818. [Google Scholar] [CrossRef]
- Sruthi, M.S.; Poovathingal, M.J.; Nandana, V.N.; Lakshmi, S.; Samshad, M.; Sudeesh, V.S. YOLOv5 based Open-Source UAV for Human Detection during Search And Rescue (SAR). In Proceedings of the 2021 International Conference on Advances in Computing and Communications (ICACC), Kakkanad, India, 21–23 October 2021; p. 6. [Google Scholar]
- Sumit, S.S.; Watada, J.; Roy, A.; Rambli, D. In object detection deep learning methods, YOLO shows supremum to Mask R-CNN. J. Phys. Conf. Ser. 2020, 1529, 042086. [Google Scholar] [CrossRef]
- Ivasic-Kos, M.; Kristo, M.; Pobar, M. Human Detection in Thermal Imaging Using YOLO. In Proceedings of the 5th International Conference on Computer and Technology Applications (ICCTA), Istanbul, Turkey, 16–17 April 2019. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Rate | Flame Image | VII | VII + NLD | VII + DCP | VII + AODNet | VII + IPUDN | VII + GCANet |
|---|---|---|---|---|---|---|---|
| Pre-trained YOLOv5s model (%) | 7.04 | 30.4 | 32.8 | 33.1 | 46.3 | 48.0 | 49.7 |
| Self-trained model (%) | 2.11 | 50.6 | 53.1 | 44.4 | 72.5 | 77.5 | 83.1 |
| Original Flame | VII | Dehazing Algorithm | Self-Trained YOLOv5 | Detection Rate (%) |
|---|---|---|---|---|
| √ | 7.04 | |||
| √ | √ | 30.4 | ||
| √ | √ | √ | 49.7 | |
| √ | √ | √ | 50.6 | |
| √ | √ | √ | √ | 83.1 |
| Dehazing Algorithm | NLD + YOLOv5 | DCP + YOLOv5 | AODNet + YOLOv5 | IPUDN + YOLOv5 | GCANet + YOLOv5 |
|---|---|---|---|---|---|
| Processing time (s) | 3.964 | 2.047 | 0.116 | 1.275 | 0.101 |
| Illumination Distance (m) | 3 | 6 | 9 | 12 | 15 |
|---|---|---|---|---|---|
| VII + GCANet + YOLOv5 |  |  |  |  |  |
| Number of images | 385 | 381 | 384 | 384 | 387 |
| Detection rate (%) | 80.8 | 71.7 | 61.2 | 53.1 | 40.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Dong, X.; Sun, Z. Object Detection through Fires Using Violet Illumination Coupled with Deep Learning. Fire 2023, 6, 222. https://doi.org/10.3390/fire6060222
Zhang H, Dong X, Sun Z. Object Detection through Fires Using Violet Illumination Coupled with Deep Learning. Fire. 2023; 6(6):222. https://doi.org/10.3390/fire6060222
Chicago/Turabian StyleZhang, Haojun, Xue Dong, and Zhiwei Sun. 2023. "Object Detection through Fires Using Violet Illumination Coupled with Deep Learning" Fire 6, no. 6: 222. https://doi.org/10.3390/fire6060222
APA StyleZhang, H., Dong, X., & Sun, Z. (2023). Object Detection through Fires Using Violet Illumination Coupled with Deep Learning. Fire, 6(6), 222. https://doi.org/10.3390/fire6060222