
Object Extraction-Based Comprehensive Ship Dataset Creation to Improve Ship Fire Detection



Abstract
1. Introduction
- Collection of ship and ship fire images from internet sources.
- Object-extracted blending of collected images with basic and advanced approaches. To note, our study will not cover all techniques of basic and advanced approaches.
- Open-source Gradio web application for data augmentation that we applied in our work. Application can be used for the creation of other limited datasets.
2. Related Work
2.1. Basic Image Manipulation
2.2. Generative Models for Data Synthesis
2.3. Style Transfer Approaches
3. Proposed Methods, Model Architecture
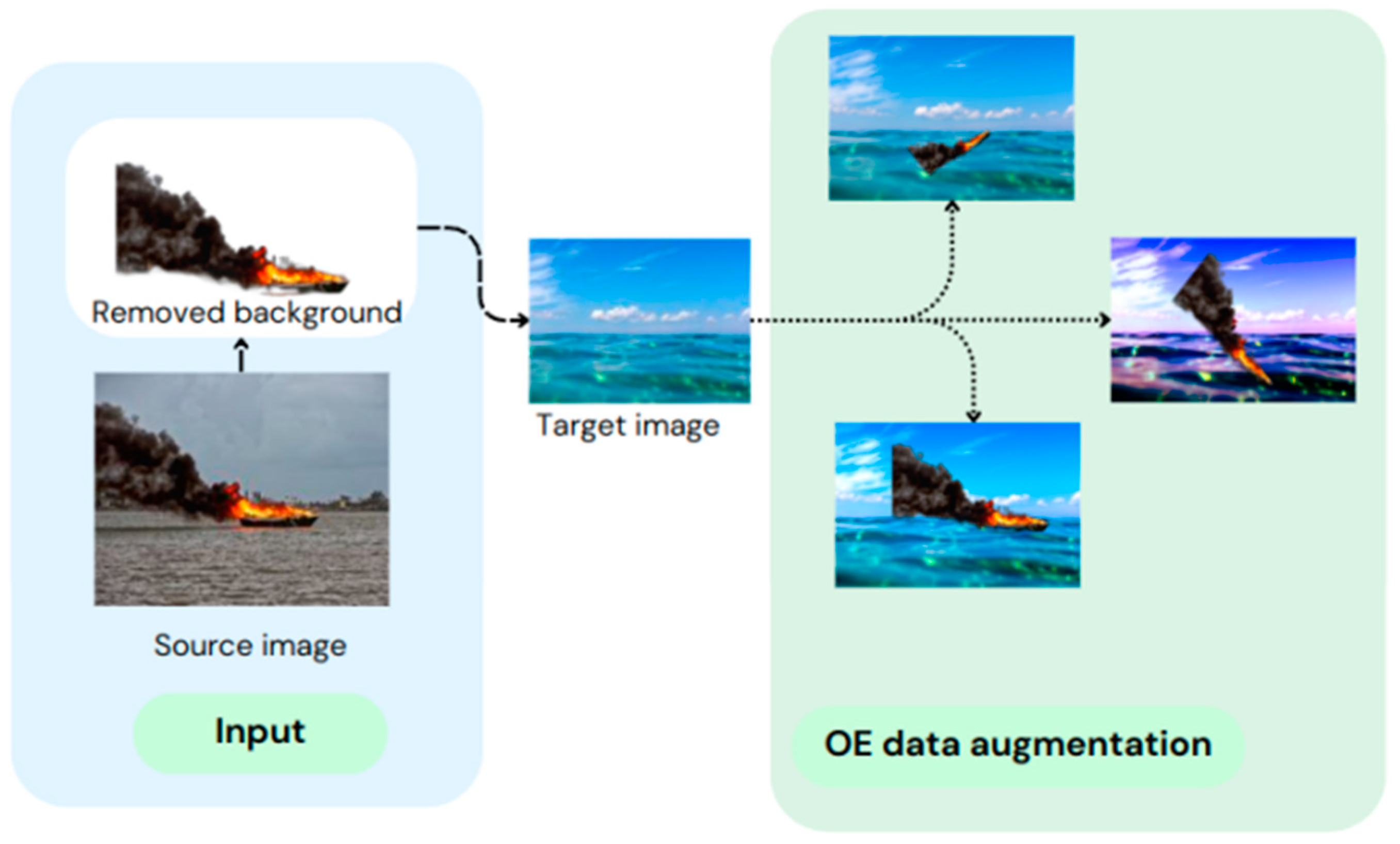
3.1. Background Removing
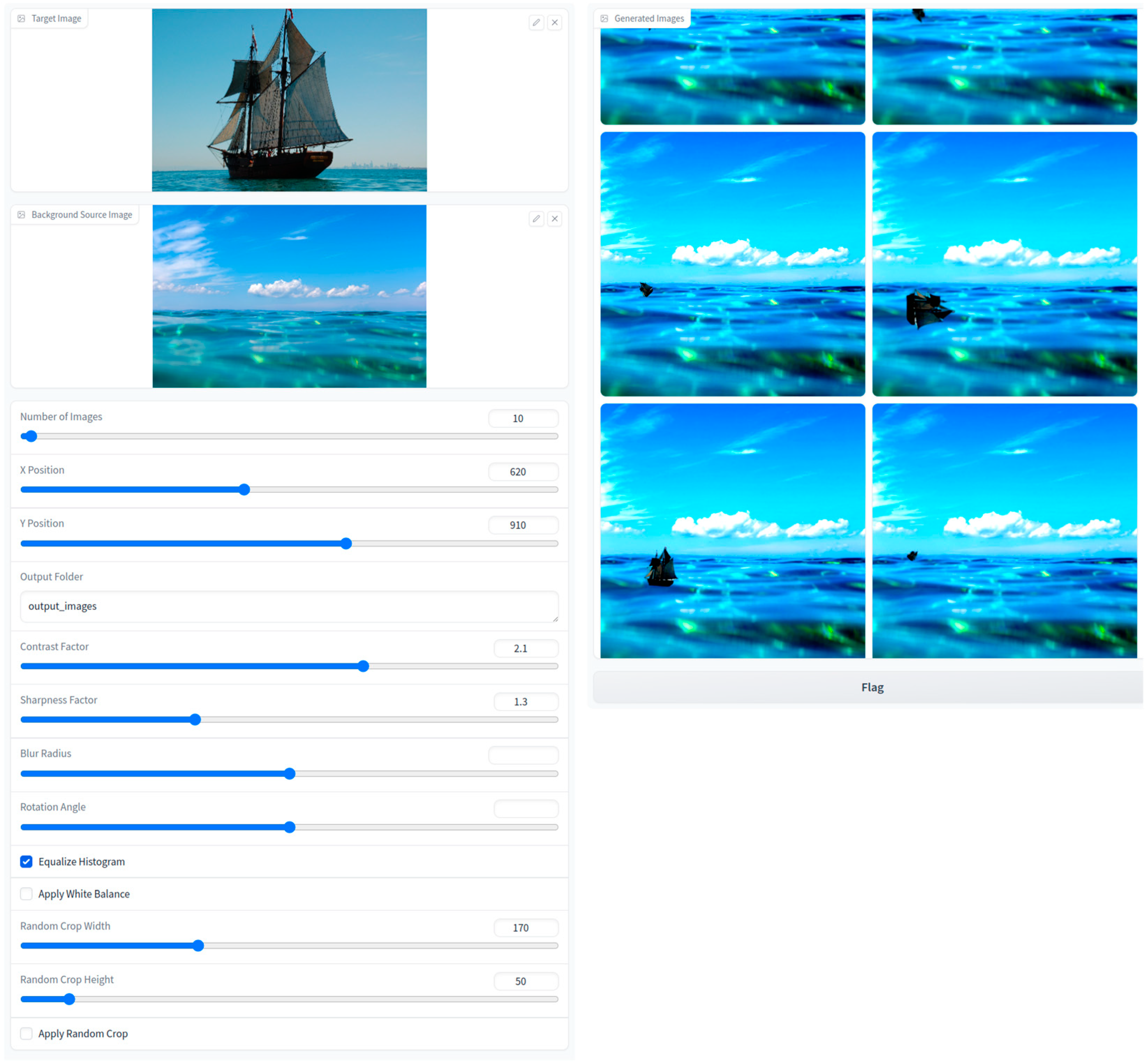
3.2. Image Resizing and Positioning
- -
- is the original pixel value at position .
- -
- is the resampled pixel value at the new position .
- -
- is the Lanczos kernel applied to the distance between the original and new pixel positions.
3.3. Random Flip, Rotation and Combination
3.4. Blur Effects
3.5. Change Color Channels and White Balance Adjustment
3.6. Change Contrast Button and Equalize Histogram
3.7. Change Sharpness Button
3.8. Random Crop Function
3.9. Dataset Collection
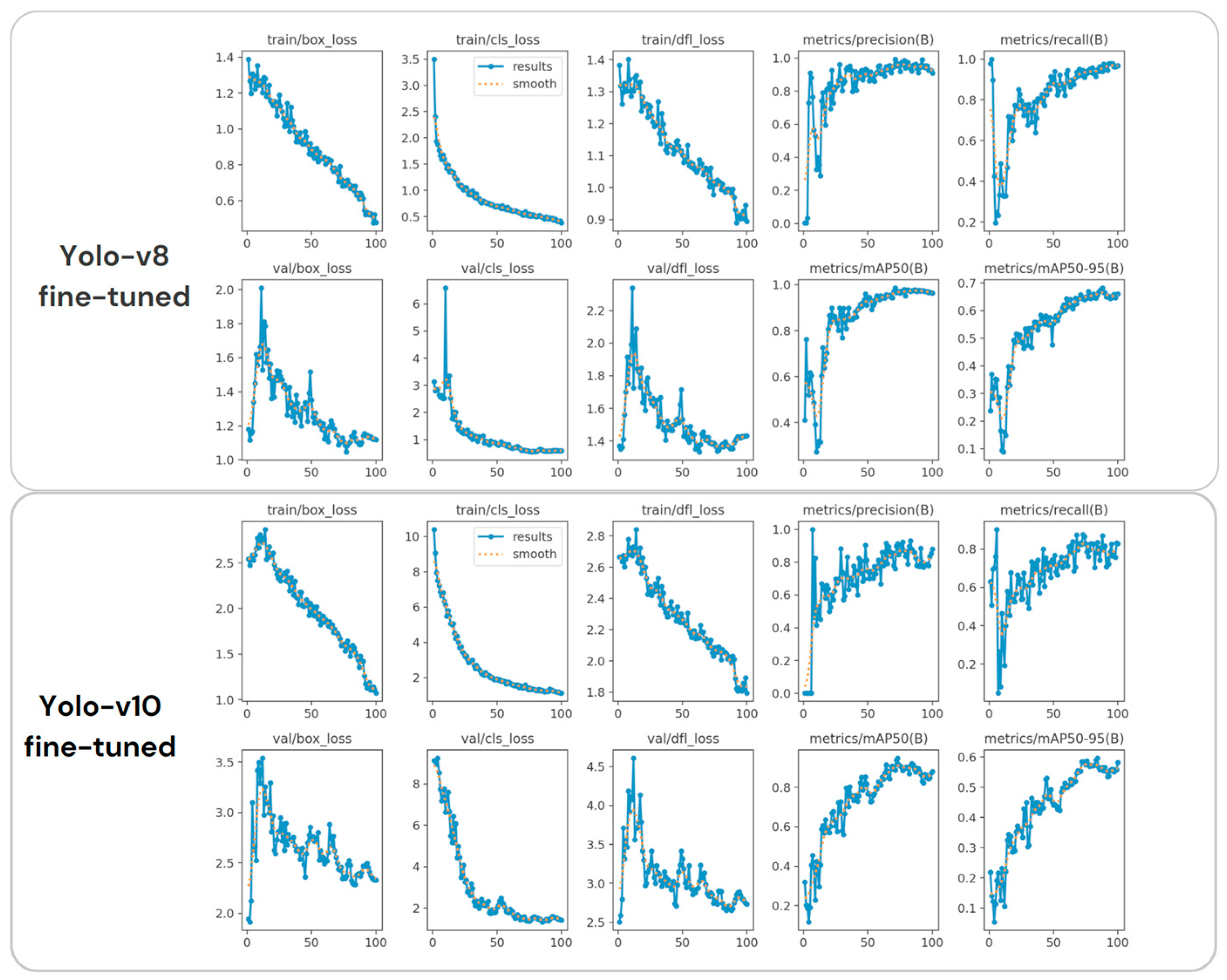
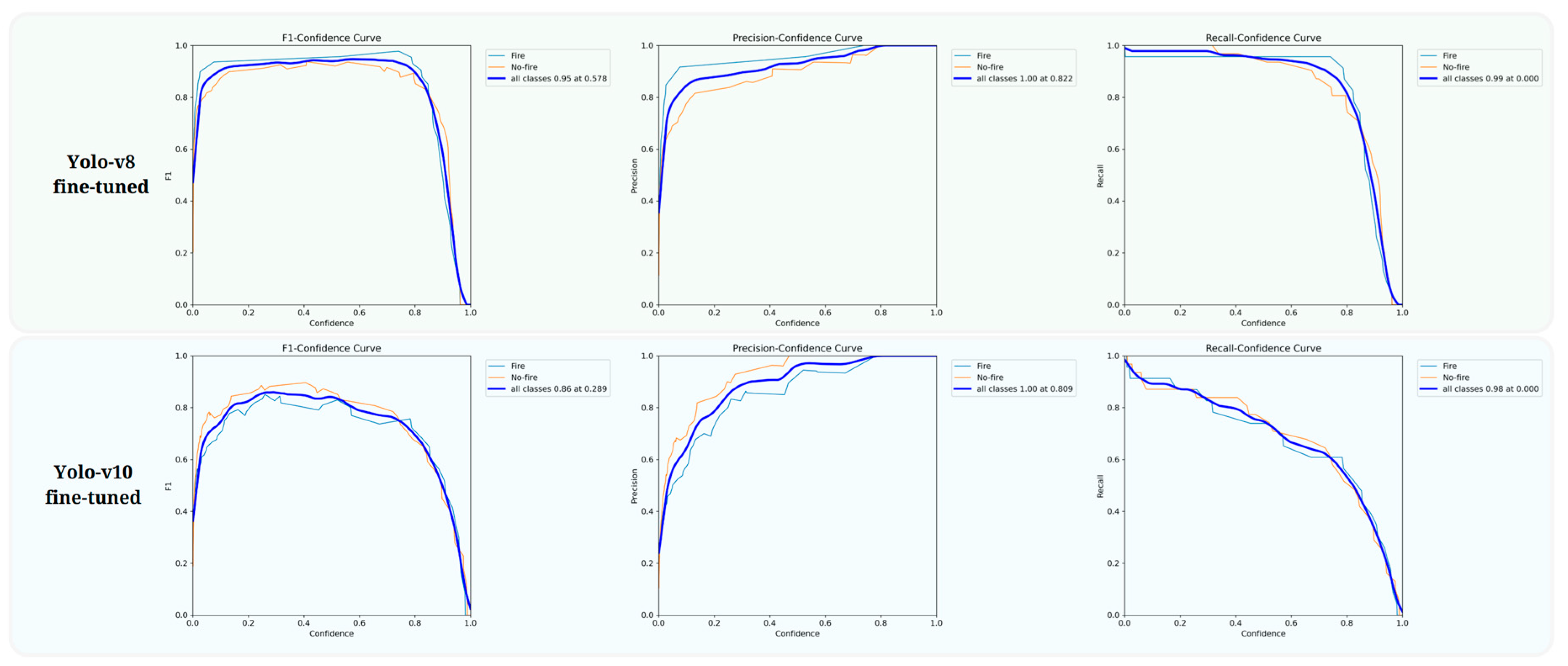
4. Experimental Results
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Available online: https://www.worldshipping.org/ (accessed on 12 June 2024).
- Halevy, A.; Norvig, P.; Pereira, F. The unreasonable effectiveness of data. IEEE Intell. Syst. 2009, 24, 8–12. [Google Scholar] [CrossRef]
- Chen, S.; Abhinav, S.; Saurabh, S.; Abhinav, G. Revisting Unreasonable Effectivness of Data in Deep Learning Era. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1106–1114. [Google Scholar] [CrossRef]
- Karen, S.; Andrew, Z. Very Deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Kaiming, H.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Christian, S.; Vincent, V.; Sergey, I.; Jon, S.; Zbigniew, W. Rethinking the inception architecture for computer vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Gao, H.; Zhuang, L.; Laurens, M.; Kilian, Q.W. Densely connected convolutional networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Moayed, H.; Mansoori, E.G. Skipout: An Adaptive Layer-Level Regularization Framework for Deep Neural Networks. IEEE Access 2022, 10, 62391–62401. [Google Scholar] [CrossRef]
- Bacciu, D.; Crecchi, F. Augmenting Recurrent Neural Networks Resilience by Dropout. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 345–351. [Google Scholar] [CrossRef]
- Qian, L.; Hu, L.; Zhao, L.; Wang, T.; Jiang, R. Sequence-Dropout Block for Reducing Overfitting Problem in Image Classification. IEEE Access 2020, 8, 62830–62840. [Google Scholar] [CrossRef]
- Fei, W.; Dai, W.; Li, C.; Zou, J.; Xiong, H. On Centralization and Unitization of Batch Normalization for Deep ReLU Neural Networks. IEEE Trans. Signal Process. 2024, 72, 2827–2841. [Google Scholar] [CrossRef]
- Zhijie, Y.; Lei, W.; Li, L.; Shiming, L.; Shasha, G.; Shuquan, W. Bactran: A Hardware Batch Normalization Implementation for CNN Training Engine. IEEE Embed. Syst. Lett. 2021, 13, 29–32. [Google Scholar] [CrossRef]
- Nie, L.; Li, C.; Marzani, F.; Wang, H.; Thibouw, F.; Grayeli, A.B. Classification of Wideband Tympanometry by Deep Transfer Learning With Data Augmentation for Automatic Diagnosis of Otosclerosis. IEEE J. Biomed. Health Inform. 2022, 26, 888–897. [Google Scholar] [CrossRef] [PubMed]
- Kuldashboy, A.; Umirzakova, S.; Allaberdiev, S.; Nasimov, R.; Abdusalomov, A.; Im Cho, Y. Efficient image classification through collaborative knowledge distillation: A novel AlexNet modification approach. Heliyon 2024, 10, e34376. [Google Scholar] [CrossRef]
- Zhang, R.; Yao, W.; Shi, Z.; Ai, X.; Tang, Y.; Wen, J. Towards Multi-Scenario Power System Stability Analysis: An Unsupervised Transfer Learning Method Combining DGAT and Data Augmentation. IEEE Trans. Power Syst. 2023, 38, 5367–5380. [Google Scholar] [CrossRef]
- Khujamatov, H.; Pitchai, M.; Shamsiev, A.; Mukhamadiyev, A.; Cho, J. Clustered Routing Using Chaotic Genetic Algorithm with Grey Wolf Optimization to Enhance Energy Efficiency in Sensor Networks. Sensors 2024, 24, 4406. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Huang, L.; Yuan, Y.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Interlaced sparse self-attention for semantic segmentation. arXiv 2019, arXiv:1907.12273. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Convolutional Deep Belief Networks on Cifar-10; University of Toronto: Toronto, ON, Canada, 2010; Volume 40, pp. 1–9. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. NIPS Workshop Deep. Learn. Unsupervised Feature Learn. 2011, 2011, 4. [Google Scholar]
- Francisco, J.M.-B.; Fiammetta, S.; Jose, M.J.; Daniel, U.; Leonardo, F. Forward Noise Adjustment Scheme for Data Augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018. [Google Scholar]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Tomohiko, K.; Michiaki, I. Icing on the cake: An easy and quick post-learning method you can try after deep learning. arXiv 2018, arXiv:1807.06540. [Google Scholar]
- Terrance, V.; Graham, W.T. Dataset Augmentation in Feature Space. In Proceedings of the International Conference on Machine Learning (ICML), Workshop Track, Sydney, Australia, 10–11 August 2017. [Google Scholar]
- Kwasigroch, A.; Mikołajczyk, A.; Grochowski, M. Deep Convolutional Neural Networks as a Decision Support Tool in Medical Problems–Malignant Melanoma case Study; Trends in Advanced Intelligent Control, Optimization and Automation. In Advances in Intelligent Systems and Computing, KKA 2017, Kraków, Poland, 18–21 June 2017; Mitkowski, W., Kacprzyk, J., Oprzędkiewicz, K., Skruch, P., Eds.; Springer: Cham, Switzerland, 2017; Volume 577, pp. 848–856. [Google Scholar]
- Kwasigroch, A.; Mikołajczyk, A.; Grochowski, M. Deep Neural Networks Approach to Skin Lesions Classification—A Comparative Analysis. In Proceedings of the 2017 22nd International Conference on Methods and Models in Automation and Robotics (MMAR), Miedzyzdroje, Poland, 28–31 August 2017; pp. 1069–1074. [Google Scholar]
- Wąsowicz, M.; Grochowski, M.; Kulka, M.; Mikołajczyk, A.; Ficek, M.; Karpieńko, K.; Cićkiewicz, M. Computed Aided System for Separation and Classification of the Abnormal Erythrocytes in Human Blood. In Proceedings of the Biophotonics—Riga, Riga, Latvia, 27–29 August 2017; Volume 10592, p. 105920A. [Google Scholar]
- Makhmudov, F.; Kultimuratov, A.; Cho, Y.-I. Enhancing Multimodal Emotion Recognition through Attention Mechanisms in BERT and CNN Architectures. Appl. Sci. 2024, 14, 4199. [Google Scholar] [CrossRef]
- Shijie, J.; Ping, W.; Peiyi, J.; Siping, H. Research on Data Augmentation for Image Classification Based on Convolution Neural Networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 4165–4170. [Google Scholar]
- Makhmudov, F.; Kutlimuratov, A.; Akhmedov, F.; Abdallah, M.S.; Cho, Y.-I. Modeling Speech Emotion Recognition via Attention-Oriented Parallel CNN Encoders. Electronics 2022, 11, 4047. [Google Scholar] [CrossRef]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic Data Augmentation Using Gan for Improved Liver Lesion Classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.-I. An Improved Wildfire Smoke Detection Based on YOLOv8 and UAV Images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef]
- Rasheed, Z.; Ma, Y.-K.; Ullah, I.; Ghadi, Y.Y.; Khan, M.Z.; Khan, M.A.; Abdusalomov, A.; Alqahtani, F.; Shehata, A.M. Brain Tumor Classification from MRI Using Image Enhancement and Convolutional Neural Network Techniques. Brain Sci. 2023, 13, 1320. [Google Scholar] [CrossRef]
- Agnieszka, M.; Michal, G. Data Augmentation for Improving Deep Learning in Image Classification Problem. In Proceedings of the IEEE 2018 international interdisciplinary Ph.D. Workshop, Swinoujscie, Poland, 9–12 May 2018. [Google Scholar]
- Fabio, P.; Christina, V.; Sandra, A.; Eduardo, V. Data Augmentation for Skin Lesion Analysis. In Proceedings of the ISIC Skin Image Analysis Workshop and Challenge, MICCAI 2018, Granada, Spain, 20 September 2018. [Google Scholar]
- Navneet, D.; Bill, T. Histograms of Oriented Gradients for Human Detection. In Proceedings of the CVPR, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Mingyang, G.; Kele, X.; Bo, D.; Huaimin, W.; Lei, Z. Learning data augmentation policies using augmented random search. arXiv 2018, arXiv:1811.04768. [Google Scholar]
- Akhmedov, F.; Nasimov, R.; Abdusalomov, A. Developing a Comprehensive Oil Spill Detection Model for Marine Environments. Remote Sens. 2024, 16, 3080. [Google Scholar] [CrossRef]
- Alexander, B.; Alex, P.; Eugene, K.; Vladimir, I.I.; Alexandr, A.K. Albumentations: Fast and flexible image augmentations. arXiv 2018, arXiv:1809.06839. [Google Scholar]
- Ren, W.; Shengen, Y.; Yi, S.; Qingqing, D.; Gang, S. Deep image: Scaling up image recognition. arXiv 2015, arXiv:1501.02876. [Google Scholar]
- Ken, C.; Karen, S.; Andrea, V.; Andrew, Z. Return of the Devil in the Details: Delving Deep into Convolutional Nets. In Proceedings of the BMVC, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the CVPR09, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Mark, E.; Luc, V.G.; Christopher, K.I.W.; John, W.; Andrew, Z. The Pascal Visual Object Classes (VOC) Challenge. 2008. Available online: http://www.pascal-network.org/challenges/VOC/voc2008/workshop/ (accessed on 12 July 2024).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the NIPS, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Akhmedov, F.; Nasimov, R.; Abdusalomov, A. Dehazing Algorithm Integration with YOLO-v10 for Ship Fire Detection. Fire 2024, 7, 332. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Zhang, J.; Chen, X.; Cai, Z.; Pan, L.; Zhao, H.; Yi, S.; Yeo, C.K.; Dai, B.; Loy, C.C. Unsupervised 3D Shape Completion through gan Inversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D. StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Abdusalomov, A.B.; Nasimov, R.; Nasimova, N.; Muminov, B.; Whangbo, T.K. Evaluating Synthetic Medical Images Using Artificial Intelligence with the GAN Algorithm. Sensors 2023, 23, 3440. [Google Scholar] [CrossRef] [PubMed]
- Umirzakova, S.; Ahmad, S.; Khan, L.U.; Whangbo, T. Medical image super-resolution for smart healthcare applications: A comprehensive survey. Inf. Fusion 2023, 103, 102075. [Google Scholar] [CrossRef]
- Umirzakova, S.; Mardieva, S.; Muksimova, S.; Ahmad, S.; Whangbo, T. Enhancing the Super-Resolution of Medical Images: Introducing the Deep Residual Feature Distillation Channel Attention Network for Optimized Performance and Efficiency. Bioengineering 2023, 10, 1332. [Google Scholar] [CrossRef] [PubMed]
- Swee, K.L.; Yi, L.; Ngoc-Trung, T.; Ngai-Man, C.; Gemma, R.; Yuval, E. DOPING: Generative data augmentation for unsupervised anomaly detection with GAN. arXiv 2018, arXiv:1808.07632. [Google Scholar]
- Alireza, M.; Jonathon, S.; Navdeep, J.; Ian, G.; Brendan, F. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Leon, A.G.; Alexander, S.E.; Matthias, B. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv 2018, arXiv:1811.12231. [Google Scholar]
- Chun, S.; Park, S. StyleAugment: Learning texture de-biased representations by style augmentation without pre-defined textures. arXiv 2021, arXiv:2108.10549. [Google Scholar]
- Hong, M.; Choi, J.; Kim, G. Stylemix: Separating Content and Style for Enhanced Data Augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14862–14870. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Philip, T.J.; Amir, A.A.; Stephen, B.; Toby, B.; Boguslaw, O. Style augmentation: Data augmentation via style randomization. arXiv 2018, arXiv:1809.05375. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of Stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Muksimova, S.; Umirzakova, S.; Mardieva, S.; Cho, Y.-I. Enhancing Medical Image Denoising with Innovative Teacher–Student Model-Based Approaches for Precision Diagnostics. Sensors 2023, 23, 9502. [Google Scholar] [CrossRef]
- Umirzakova, S.; Whangbo, T.K. Detailed feature extraction network-based fine-grained face segmentation. Knowl.-Based Syst. 2022, 250, 109036. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Rakhimov, M.; Karimberdiyev, J.; Belalova, G.; Cho, Y.I. Enhancing Automated Brain Tumor Detection Accuracy Using Artificial Intelligence Approaches for Healthcare Environments. Bioengineering 2024, 11, 627. [Google Scholar] [CrossRef] [PubMed]
- Ergasheva, A.; Akhmedov, F.; Abdusalomov, A.; Kim, W. Advancing Maritime Safety: Early Detection of Ship Fires through Computer Vision, Deep Learning Approaches, and Histogram Equalization Techniques. Fire 2024, 7, 84. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Kilichev, D.; Nasimov, R.; Rakhmatullayev, I.; Cho, Y.I. Optimizing Smart Home Intrusion Detection with Harmony-Enhanced Extra Trees. IEEE Access 2024, 12, 117761–117786. [Google Scholar] [CrossRef]
- Zhun, Z.; Liang, Z.; Guoliang, K.; Shaozi, L.; Yi, Y. Random erasing data augmentation. arXiv 2017, arXiv:1708.04896. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- ultralytics, YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 11 November 2023).
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Buriboev, A.S.; Rakhmanov, K.; Soqiyev, T.; Choi, A.J. Improving Fire Detection Accuracy through Enhanced Convolutional Neural Networks and Contour Techniques. Sensors 2024, 24, 5184. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model Name | Before Augmentation (%) | After Augmentation (%) | Accuracy Improvement by (%) |
|---|---|---|---|---|
| CIFAR-10 | DenseNet | 94.15 | 94.59 | 0.44 |
| Wide-ResNet | 93.34 | 93.67 | 1.33 | |
| Shake-ResNet | 93.7 | 94.84 | 1.11 | |
| CIFAR-100 | DenseNet | 74.98 | 75.93 | 0.95 |
| Wide-ResNet | 74.46 | 76.52 | 2.06 | |
| Shake-ResNet | 73.96 | 76.76 | 2.80 | |
| SVHN | DenseNet | 97.91 | 97.98 | 0.07 |
| Wide-ResNet | 98.23 | 98.31 | 0.80 | |
| Shake-ResNet | 98.37 | 98.40 | 0.30 |
| Model | MNIST | CIFAR-10 |
|---|---|---|
| Baseline | 1.093 ± 0.057 | 30.65 ± 0.27 |
| Baseline + input space affine transformations | 1.477 ± 0.068 | - |
| Baseline + input space extrapolation | 1.010 ± 0.065 | - |
| Baseline + feature space extrapolation | 0.950 ± 0.036 | 29.24 ± 0.27 |
| Input | background, ship_image, position |
| Output | blended_image |
| background | background.convert(“RGBA”) |
| mask | ship_image.split() [3] |
| background.paste(ship_image, position, mask) | |
| return background |
| Description | Values (Range) |
|---|---|
| Number of images | 1–1000 |
| Target image x—axis | 0–1500 |
| Target image y—axis | 0–1500 |
| Output folder | Specify |
| Contrast factor | 0.5–3 |
| Sharpness factor | 0.5–3 |
| Blur radius | 0–20 |
| Rotation angle | 0–360 |
| Equalize histogram | yes/no |
| Apply white balance | yes/no |
| Random crop width | 10–500 |
| Random crop height | 10–500 |
| Apply random crop | yes/no |
| Internet Source Images | Total | |
| Ship Fire | 9200 | |
| Ship No—Fire | 4100 | |
| Internet Source (Sample) | Augmented | |
| Ship fire | 90 | 11,440 |
| Background | 13 | |
| Models | Precision | Recall | F1 | mAP@0.50 |
|---|---|---|---|---|
| Yolo-v3-Tiny [70] | 0.797 | 0.821 | 0.81 | 0.745 |
| Yolo-v5s [71] | 0.901 | 0.855 | 0.88 | 0.814 |
| Yolo-v7-tiny [72] | 0.857 | 0.7921 | 0.82 | 0.758 |
| Yolo-v8n (custom data) | 0.866 | 0.912 | 0.888 | 0.910 |
| Yolo-v10n (custom data) | 0.913 | 0.937 | 0.925 | 0.937 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akhmedov, F.; Mukhamadiev, S.; Abdusalomov, A.; Cho, Y.-I. Object Extraction-Based Comprehensive Ship Dataset Creation to Improve Ship Fire Detection. Fire 2024, 7, 345. https://doi.org/10.3390/fire7100345
Akhmedov F, Mukhamadiev S, Abdusalomov A, Cho Y-I. Object Extraction-Based Comprehensive Ship Dataset Creation to Improve Ship Fire Detection. Fire. 2024; 7(10):345. https://doi.org/10.3390/fire7100345
Chicago/Turabian StyleAkhmedov, Farkhod, Sanjar Mukhamadiev, Akmalbek Abdusalomov, and Young-Im Cho. 2024. "Object Extraction-Based Comprehensive Ship Dataset Creation to Improve Ship Fire Detection" Fire 7, no. 10: 345. https://doi.org/10.3390/fire7100345
APA StyleAkhmedov, F., Mukhamadiev, S., Abdusalomov, A., & Cho, Y.-I. (2024). Object Extraction-Based Comprehensive Ship Dataset Creation to Improve Ship Fire Detection. Fire, 7(10), 345. https://doi.org/10.3390/fire7100345