Smoke Detection Transformer: An Improved Real-Time Detection Transformer Smoke Detection Model for Early Fire Warning


Abstract
1. Introduction
2. Related Works
2.1. Overview of Methods for Smoke Detection
2.2. Transformer for Smoke Detection
3. Methods
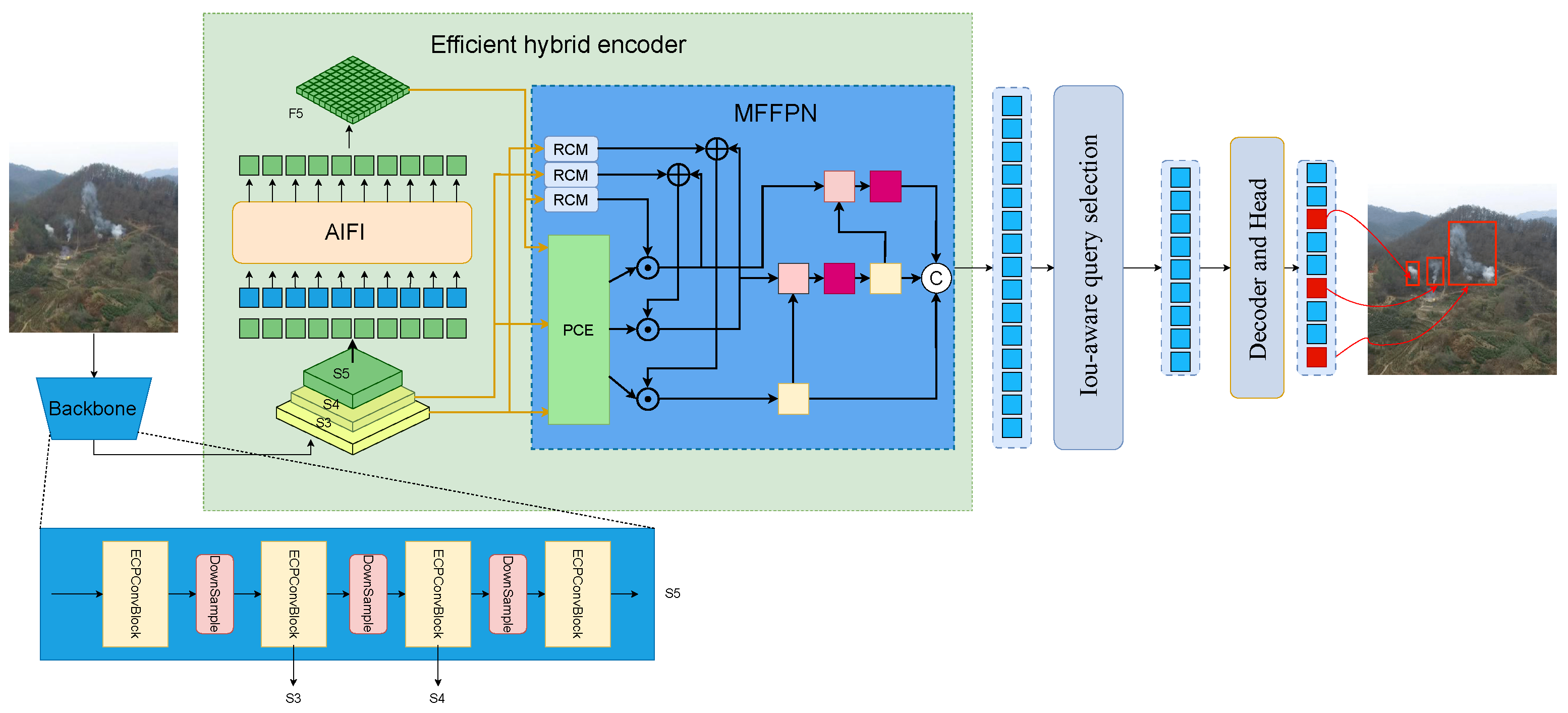
3.1. Overall Structure of Smoke-DETR
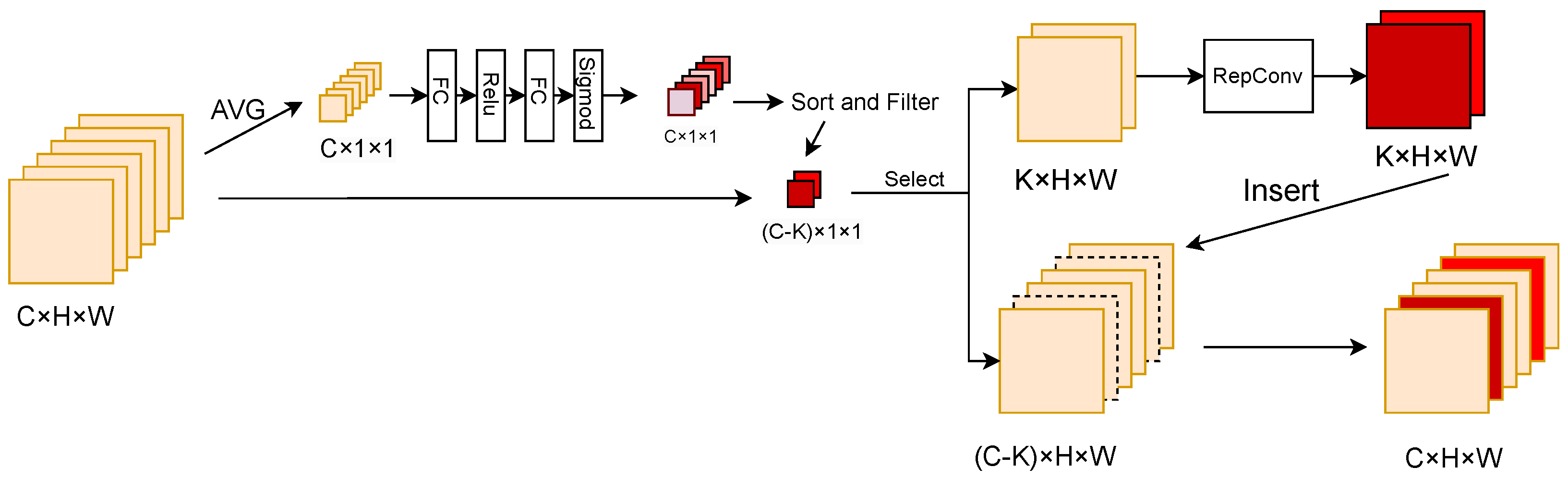
3.2. Enhanced Channel-Wise Partial Convolution
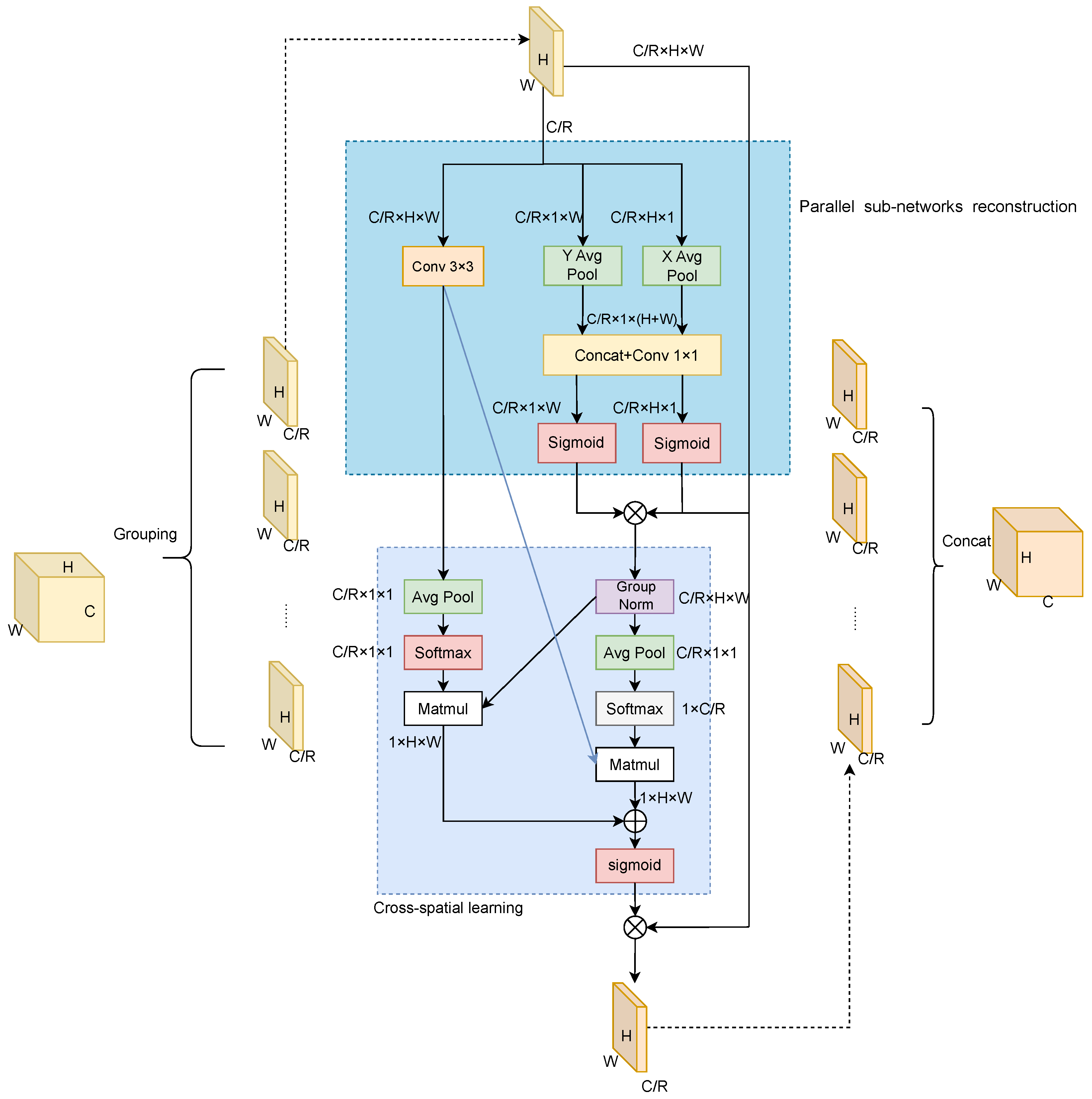
3.3. Efficient Multi-Scale Attention Module
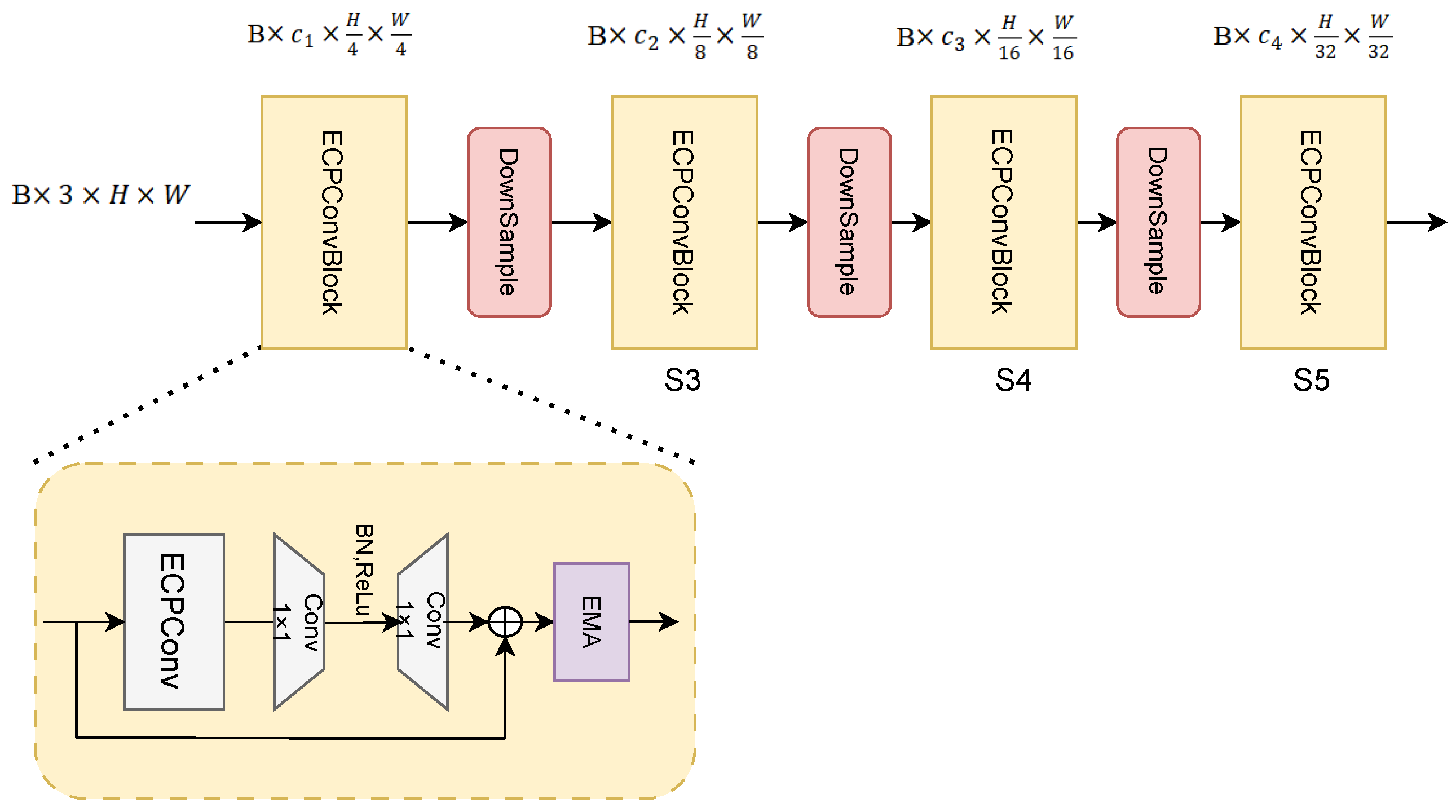
3.4. Improved Backbone Network Structure
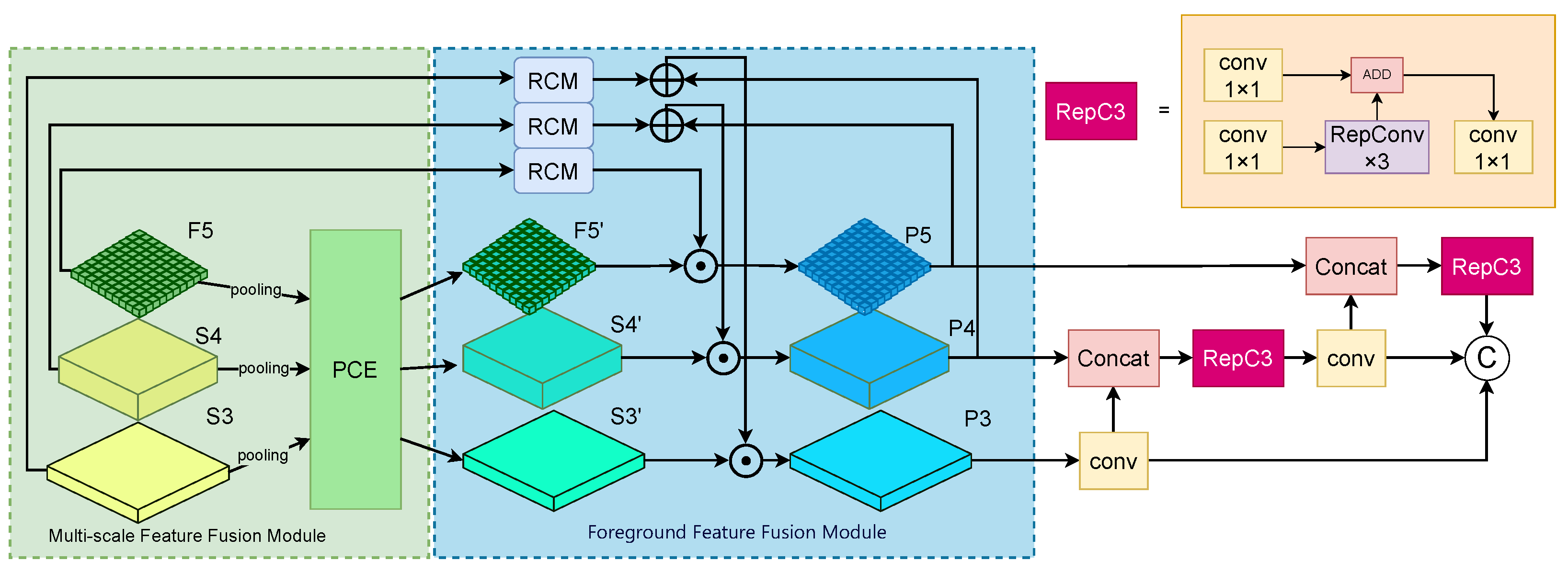
3.5. Multi-Scale Foreground-Focus Fusion Pyramid Network
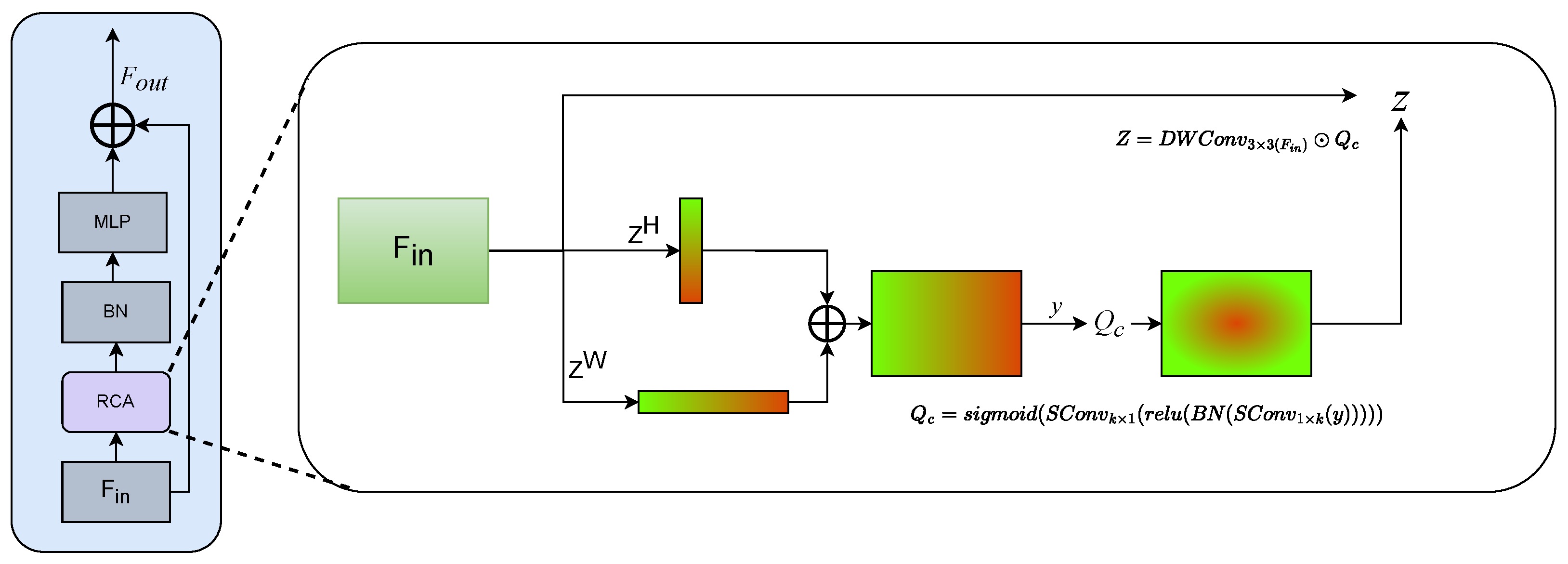
3.5.1. Rectangular Self-Calibration Module
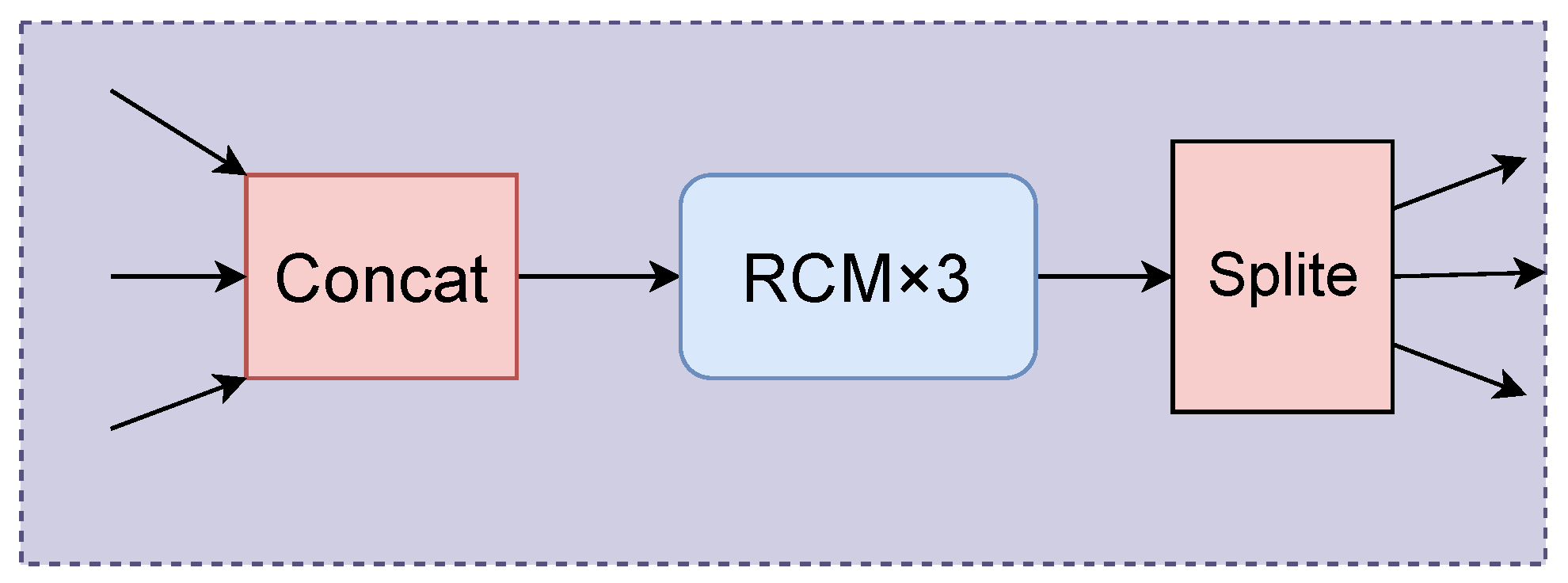
3.5.2. Multi-Scale Feature Foreground Enhancement
3.5.3. Foreground Feature Fusion Module
4. Experiments and Results
4.1. Experimental Equipment and Hyper-Parameter Settings
4.2. Dataset and Evaluation Metrics
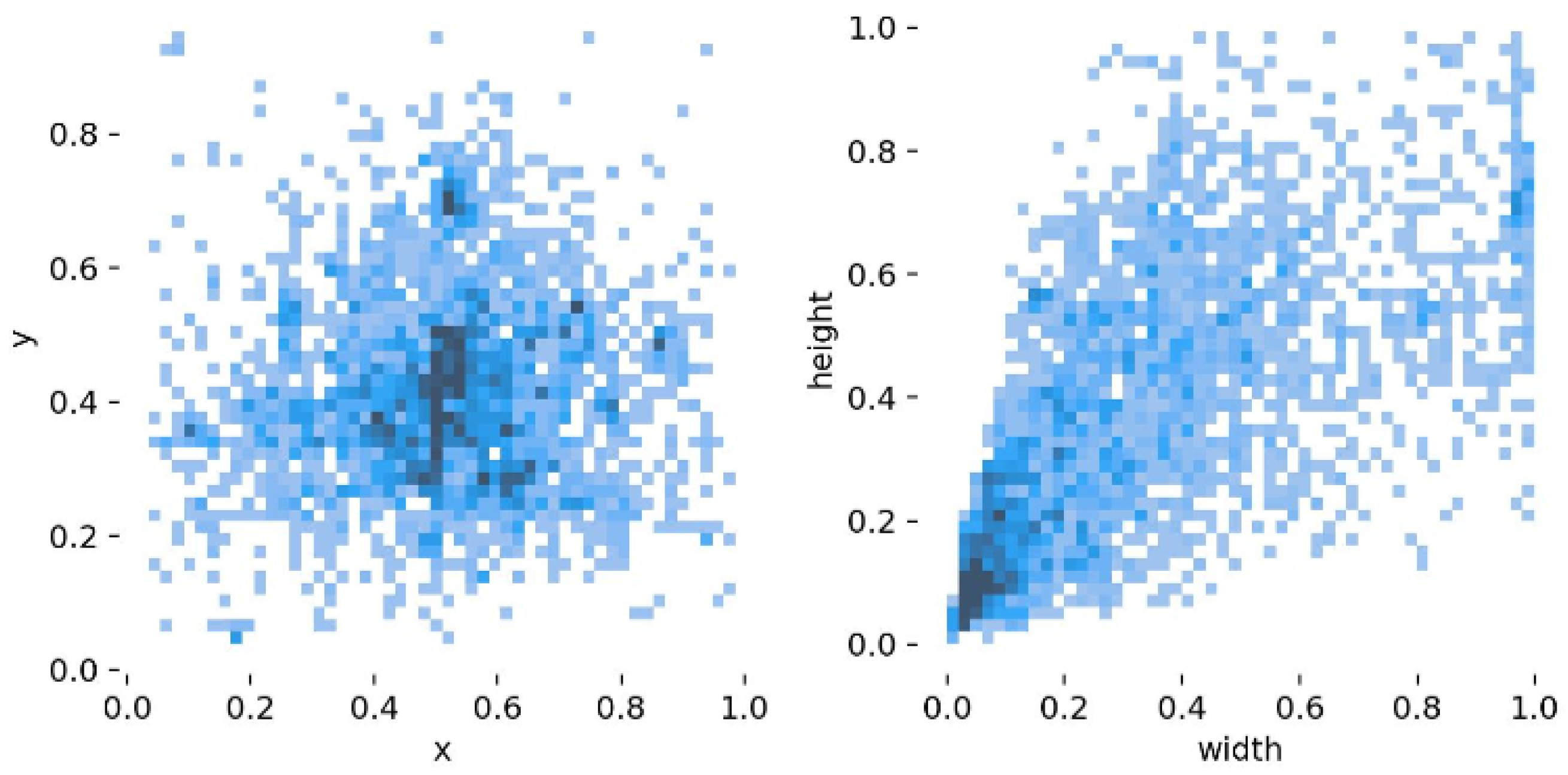
4.2.1. Smoke Detection Dataset
4.2.2. Evaluation Metrics
4.3. Comparative Experiments
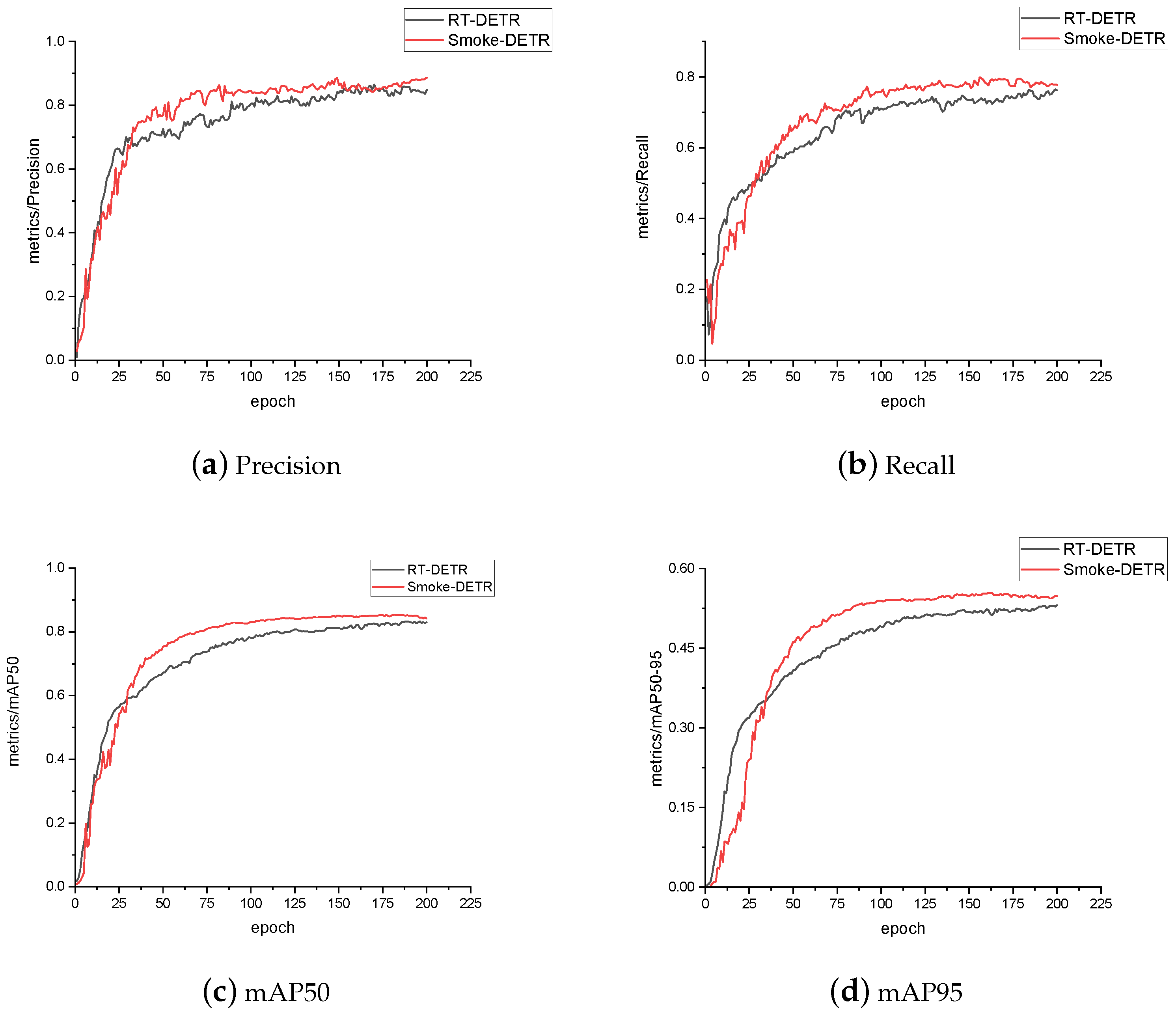
4.3.1. Evaluation in Comparison with a Number of Advanced Object Detection Algorithms
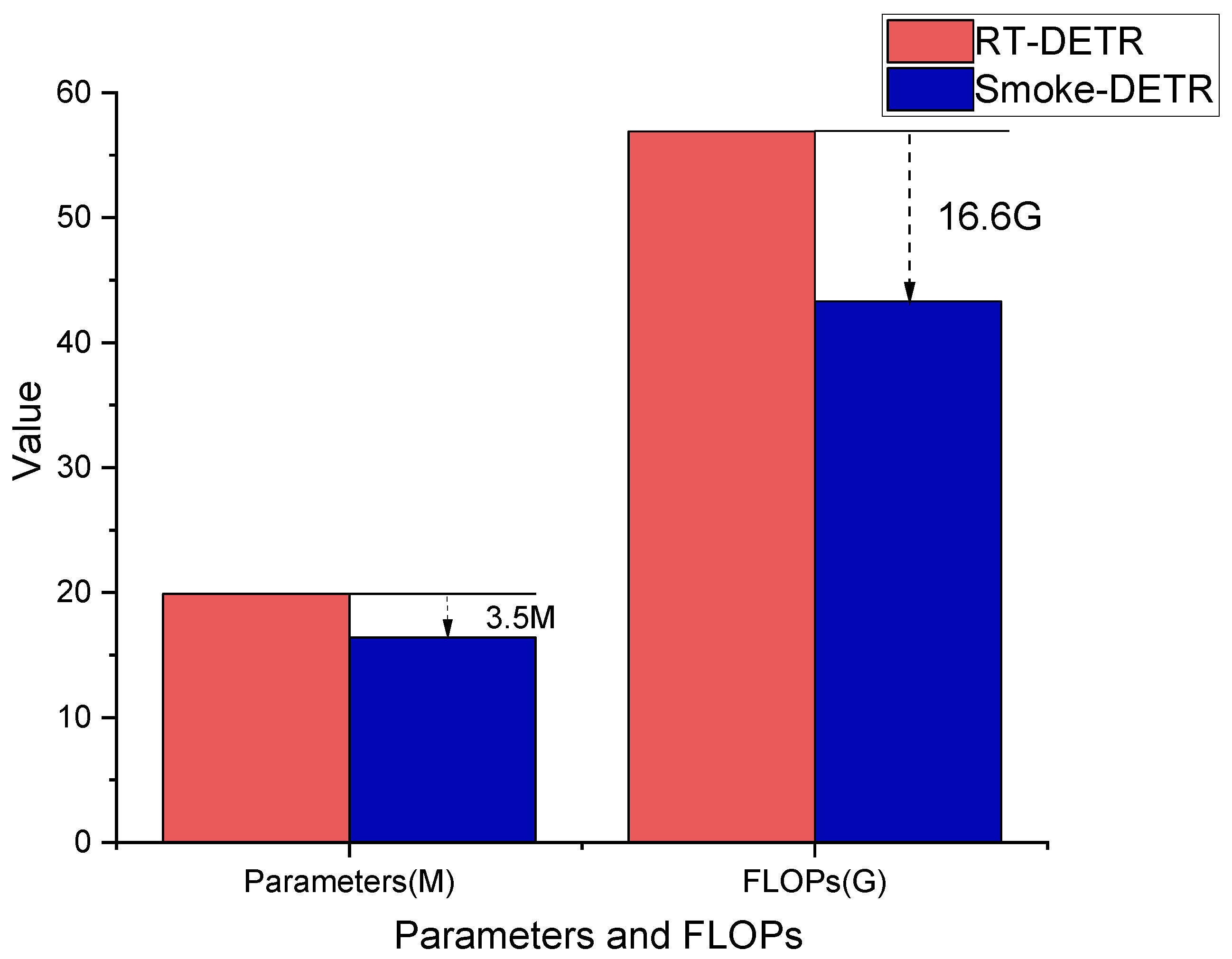
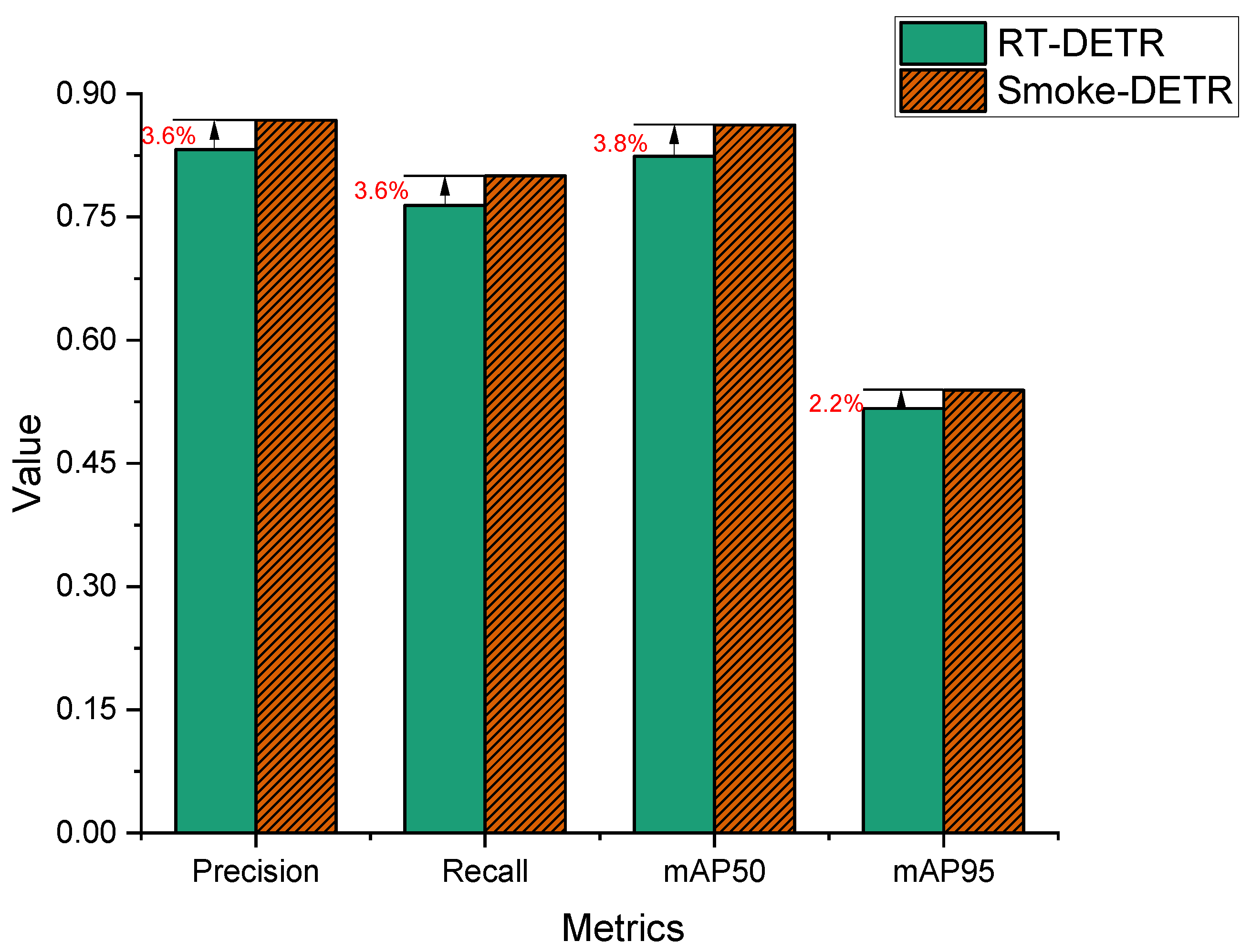
4.3.2. Comparison of the Baseline Model
4.4. Ablation Experiment
4.4.1. Experiments in the Feature Fusion Section
4.4.2. Experiments on the Backbone
4.4.3. Experiments with Different Iou Loss Function
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1 The Pseudocode of Enhanced Channel-wise Partial Convolution | |
| Input: | |
| Output: | |
| 1: Function ECPConv(X) | |
| 2: Y = [] | |
| 3: for x in X do | |
| 4: i = 0 | |
| 5: = | |
| 6: | |
| 7: end for | |
| 8: | |
| 9: sort Y by | |
| 10: Z = [] | |
| 11: for k in rang(0,) do | |
| 12: Z.add(X[Y[k]]) | |
| 13: | |
| 14: | |
| 15: end for | |
| 16: return X | |
| 17: end Function | |
References
- Yuan, F.; Shi, J.; Xia, X.; Zhang, L.; Li, S. Encoding pairwise Hamming distances of Local Binary Patterns for visual smoke recognition. Comput. Vis. Image Underst. 2019, 178, 43–53. [Google Scholar] [CrossRef]
- Yuan, F.; Shi, J.; Xia, X.; Fang, Y.; Fang, Z.; Mei, T. High-order local ternary patterns with locality preserving projection for smoke detection and image classification. Inf. Sci. 2016, 372, 225–240. [Google Scholar] [CrossRef]
- Natural Resources Canada National Wildland Fire Situation Report. 2023. Available online: https://cwfis.cfs.nrcan.gc.ca/report (accessed on 5 March 2023).
- Barbero, R.; Abatzoglou, J.T.; Larkin, N.K.; Kolden, C.A.; Stocks, B. Climate change presents increased potential for very large fires in the contiguous United States. Int. J. Wildland Fire 2015, 24, 892–899. [Google Scholar] [CrossRef]
- U.S. Fire Administration. Fire Deaths, Fire Death Rates, and Risk of Dying in a Fire. 2020. Available online: https://www.usfa.fema.gov/statistics/deaths-injuries/states.html (accessed on 1 July 2024).
- Chen, S.; Cao, Y.; Feng, X.; Lu, X. Global2Salient: Self-adaptive feature aggregation for remote sensing smoke detection. Neurocomputing 2021, 466, 202–220. [Google Scholar] [CrossRef]
- Asiri, N.; Bchir, O.; Ismail, M.M.B.; Zakariah, M.; Alotaibi, Y.A. Image-based smoke detection using feature mapping and discrimination. Soft Comput. 2021, 25, 3665–3674. [Google Scholar] [CrossRef]
- Carletti, V.; Greco, A.; Saggese, A.; Vento, B. A smart visual sensor for smoke detection based on deep neural networks. Sensors 2024, 24, 4519. [Google Scholar] [CrossRef]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.I. An improved wildfire smoke detection based on YOLOv8 and UAV images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 July 2023; pp. 12021–12031. [Google Scholar]
- Maruta, H.; Nakamura, A.; Kurokawa, F. A new approach for smoke detection with texture analysis and support vector machine. In Proceedings of the 2010 IEEE International Symposium on Industrial Electronics, Bari, Italy, 4–7 July 2010; pp. 1550–1555. [Google Scholar] [CrossRef]
- Tian, H.; Li, W.; Ogunbona, P.O.; Wang, L. Detection and Separation of Smoke from Single Image Frames. IEEE Trans. Image Process. 2018, 27, 1164–1177. [Google Scholar] [CrossRef]
- Jia, Y.; Yuan, J.; Wang, J.; Fang, J.; Zhang, Q.; Zhang, Y. A saliency-based method for early smoke detection in video sequences. Fire Technol. 2016, 52, 1271–1292. [Google Scholar] [CrossRef]
- Chunyu, Y.; Jun, F.; Jinjun, W.; Yongming, Z. Video fire smoke detection using motion and color features. Fire Technol. 2010, 46, 651–663. [Google Scholar] [CrossRef]
- Li, T.; Zhao, E.; Zhang, J.; Hu, C. Detection of Wildfire Smoke Images Based on a Densely Dilated Convolutional Network. Electronics 2019, 8, 1131. [Google Scholar] [CrossRef]
- Wang, G.; Yuan, F.; Li, H.; Fang, Z. A pyramid Gaussian pooling based CNN and transformer hybrid network for smoke segmentation. IET Image Process. 2024, 18, 3206–3217. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Huang, J.; Zhou, J.; Yang, H.; Liu, Y.; Liu, H. A small-target forest fire smoke detection model based on deformable transformer for end-to-end object detection. Forests 2023, 14, 162. [Google Scholar] [CrossRef]
- Liang, T.; Zeng, G. FSH-DETR: An Efficient End-to-End Fire Smoke and Human Detection Based on a Deformable DEtection TRansformer (DETR). Sensors 2024, 24, 4077. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–24 June 2024; pp. 16965–16974. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the EEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. Aˆ2-Nets: Double Attention Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Ni, Z.; Chen, X.; Zhai, Y.; Tang, Y.; Wang, Y. Context-Guided Spatial Feature Reconstruction for Efficient Semantic Segmentation. arXiv 2024, arXiv:2405.06228. [Google Scholar]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–16 June 2020; pp. 10781–10790. [Google Scholar]
- Xue, Y.; Ju, Z.; Li, Y.; Zhang, W. MAF-YOLO: Multi-modal attention fusion based YOLO for pedestrian detection. Infrared Phys. Technol. 2021, 118, 103906. [Google Scholar] [CrossRef]
- Ma, S.; Xu, Y. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S. Shape-iou: More accurate metric considering bounding box shape and scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | mAP50 (%) | mAP95 (%) | Parameters | Flops |
|---|---|---|---|---|---|---|
| Faster-Rcnn | 0.798 | 0.726 | 0.772 | 0.476 | 40 M | 207 G |
| Yolov8m | 0.813 | 0.784 | 0.826 | 0.527 | 25.8 M | 78.7 G |
| Yolov9m | 0.823 | 0.79 | 0.836 | 0.516 | 16.6 M | 60.0 G |
| Yolov11m | 0.819 | 0.765 | 0.829 | 0.533 | 20.1 M | 68.0 G |
| Rtmdet | 0.802 | 0.743 | 0.817 | 0.500 | 8.89 M | 14.8 G |
| DINO | 0.876 | 0.776 | 0.841 | 0.532 | 47 M | 279 G |
| RT-DETR | 0.832 | 0.764 | 0.824 | 0.517 | 19.9 M | 56.9 G |
| Smoke-DETR | 0.868 | 0.8 | 0.862 | 0.539 | 16.4 M | 43.3 G |
| Method | Precision (%) | Recall (%) | mAP50 (%) | mAP95 (%) | Parameters | Flops |
|---|---|---|---|---|---|---|
| Rtdetr-r18 | 0.832 | 0.764 | 0.824 | 0.517 | 19.9 M | 56.9 G |
| Rtdetr-r18 + MFFPN | 0.875 | 0.791 | 0.847 | 0.527 | 19.2 M | 48.2 G |
| Rtdetr-r18 + ECPConv | 0.842 | 0.793 | 0.840 | 0.522 | 16.8 M | 49.5 G |
| Rtdetr-r18 + EMA | 0.851 | 0.791 | 0.842 | 0.525 | 20.1 M | 58.1 G |
| Rtdetr-r18 + (MFFPN + ECPConv + EMA) | 0.868 | 0.800 | 0.862 | 0.539 | 16.3 M | 43.3 G |
| Method | Precision (%) | Recall (%) | mAP50 (%) | mAP95 (%) | Parameters | Flops |
|---|---|---|---|---|---|---|
| PANET (baseline) | 0.832 | 0.764 | 0.824 | 0.517 | 19.9 M | 56.9 G |
| MFFPN (ours) | 0.875 | 0.791 | 0.847 | 0.527 | 19.2 M | 48.2 G |
| MAFPN | 0.845 | 0.783 | 0.835 | 0.513 | 22.9 M | 56.3 G |
| BIFPN | 0.862 | 0.805 | 0.843 | 0.518 | 20.3 M | 64.3 G |
| Method | Precision (%) | Recall (%) | mAP50 (%) | mAP95 (%) | Parameters | Flops |
|---|---|---|---|---|---|---|
| Rtdetr-r18 (baseline) | 0.832 | 0.764 | 0.824 | 0.517 | 19.9 | 56.9 |
| PConv | 0.847 | 0.769 | 0.832 | 0.520 | 16.8 | 49.5 |
| ECPConv | 0.851 | 0.776 | 0.843 | 0.521 | 16.8 | 49.9 |
| ECPConv + EMA | 0.851 | 0.791 | 0.852 | 0.535 | 17.0 | 51.4 |
| Method | Precision (%) | Recall (%) | mAP50 (%) | mAP95 (%) |
|---|---|---|---|---|
| Smoke-DETR (GIou) | 0.868 | 0.800 | 0.862 | 0.539 |
| Smoke-DETR (MDPIou) | 0.875 | 0.781 | 0.850 | 0.534 |
| Smoke-DETR (EIou) | 0.849 | 0.801 | 0.841 | 0.536 |
| Smoke-DETR (Shape-Iou) | 0.851 | 0.776 | 0.843 | 0.521 |
| Smoke-DETR (NWDLoss) | 0.888 | 0.777 | 0.846 | 0.511 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, B.; Cheng, X. Smoke Detection Transformer: An Improved Real-Time Detection Transformer Smoke Detection Model for Early Fire Warning. Fire 2024, 7, 488. https://doi.org/10.3390/fire7120488
Sun B, Cheng X. Smoke Detection Transformer: An Improved Real-Time Detection Transformer Smoke Detection Model for Early Fire Warning. Fire. 2024; 7(12):488. https://doi.org/10.3390/fire7120488
Chicago/Turabian StyleSun, Baoshan, and Xin Cheng. 2024. "Smoke Detection Transformer: An Improved Real-Time Detection Transformer Smoke Detection Model for Early Fire Warning" Fire 7, no. 12: 488. https://doi.org/10.3390/fire7120488
APA StyleSun, B., & Cheng, X. (2024). Smoke Detection Transformer: An Improved Real-Time Detection Transformer Smoke Detection Model for Early Fire Warning. Fire, 7(12), 488. https://doi.org/10.3390/fire7120488