

A Robustness Study on Early Fire Image Recognitions


Abstract
1. Introduction
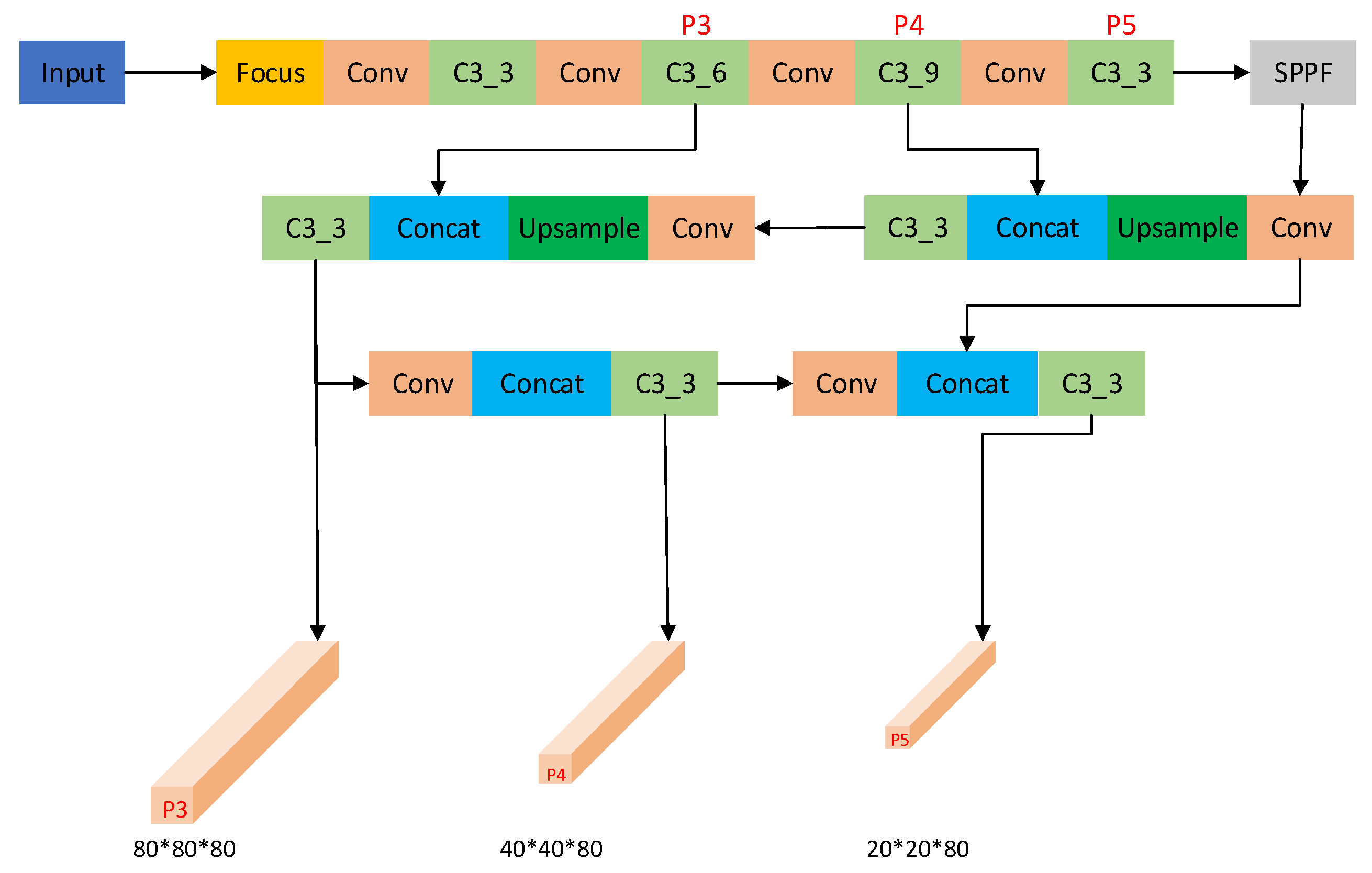
2. Improvements to YOLOv5
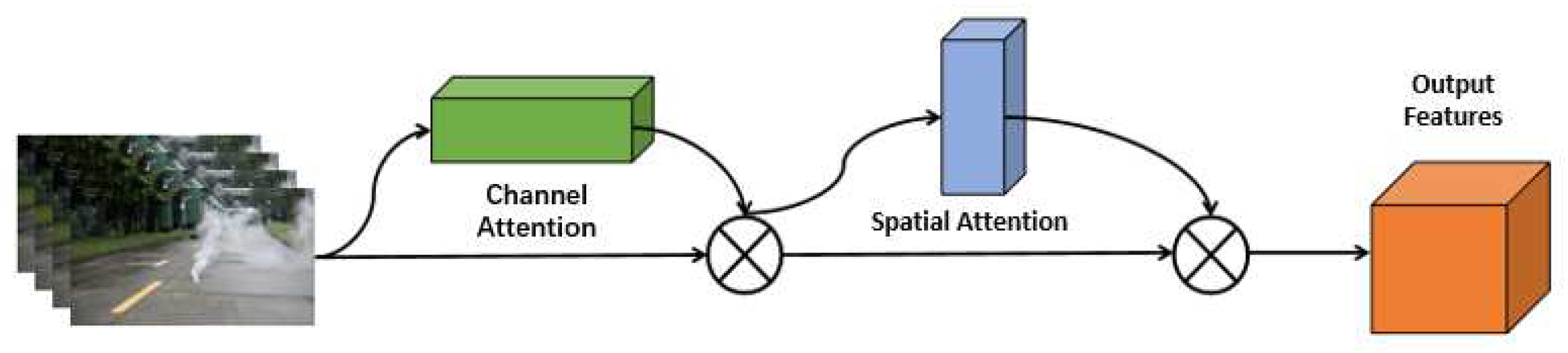
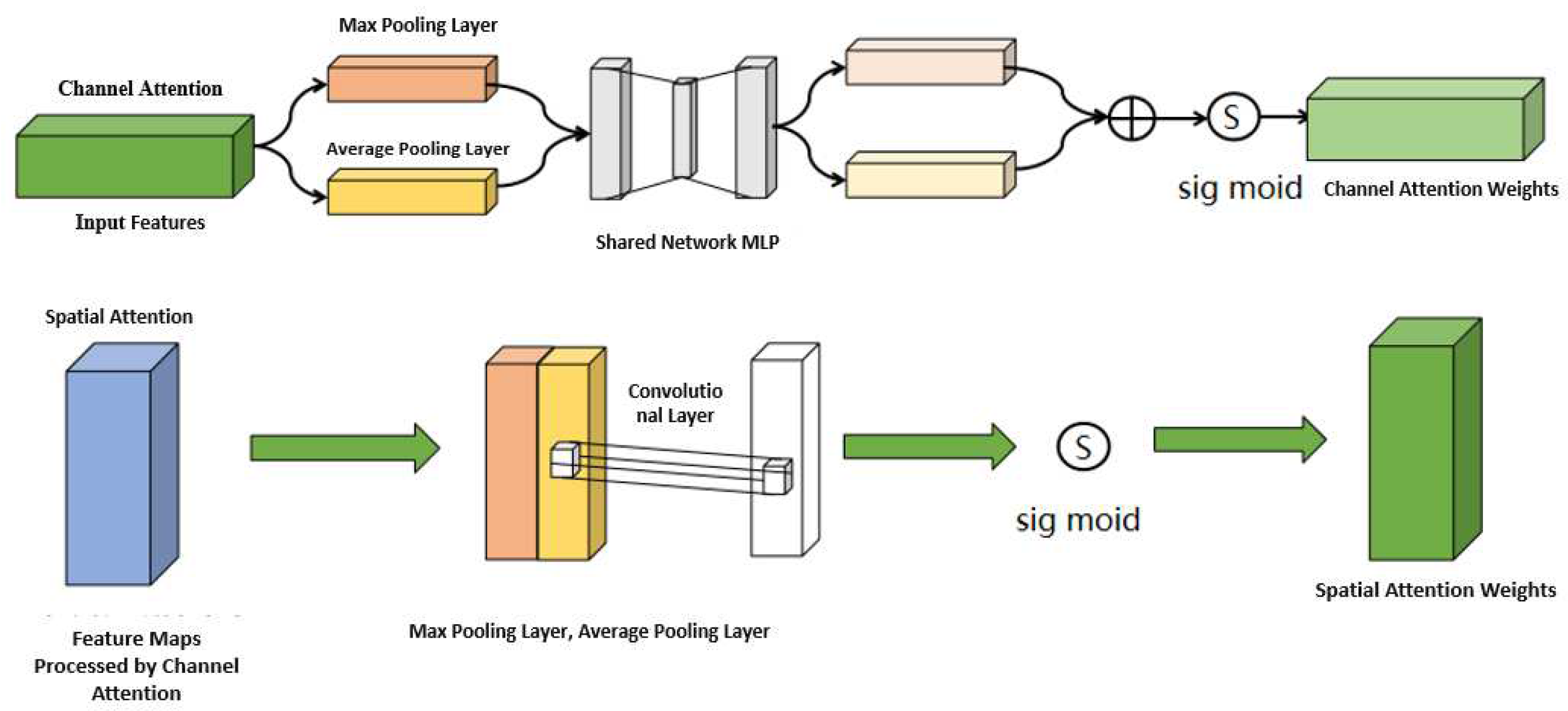
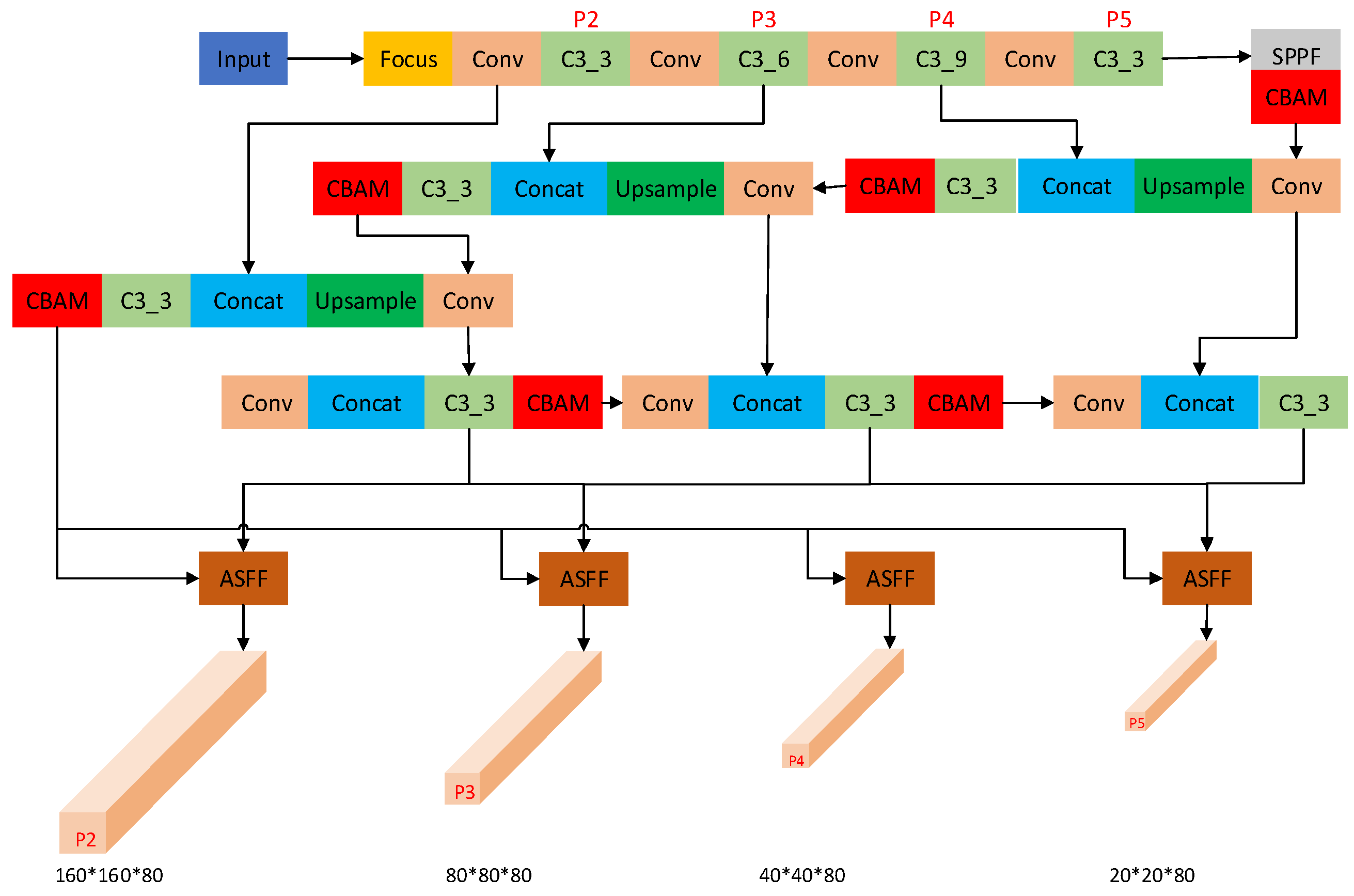
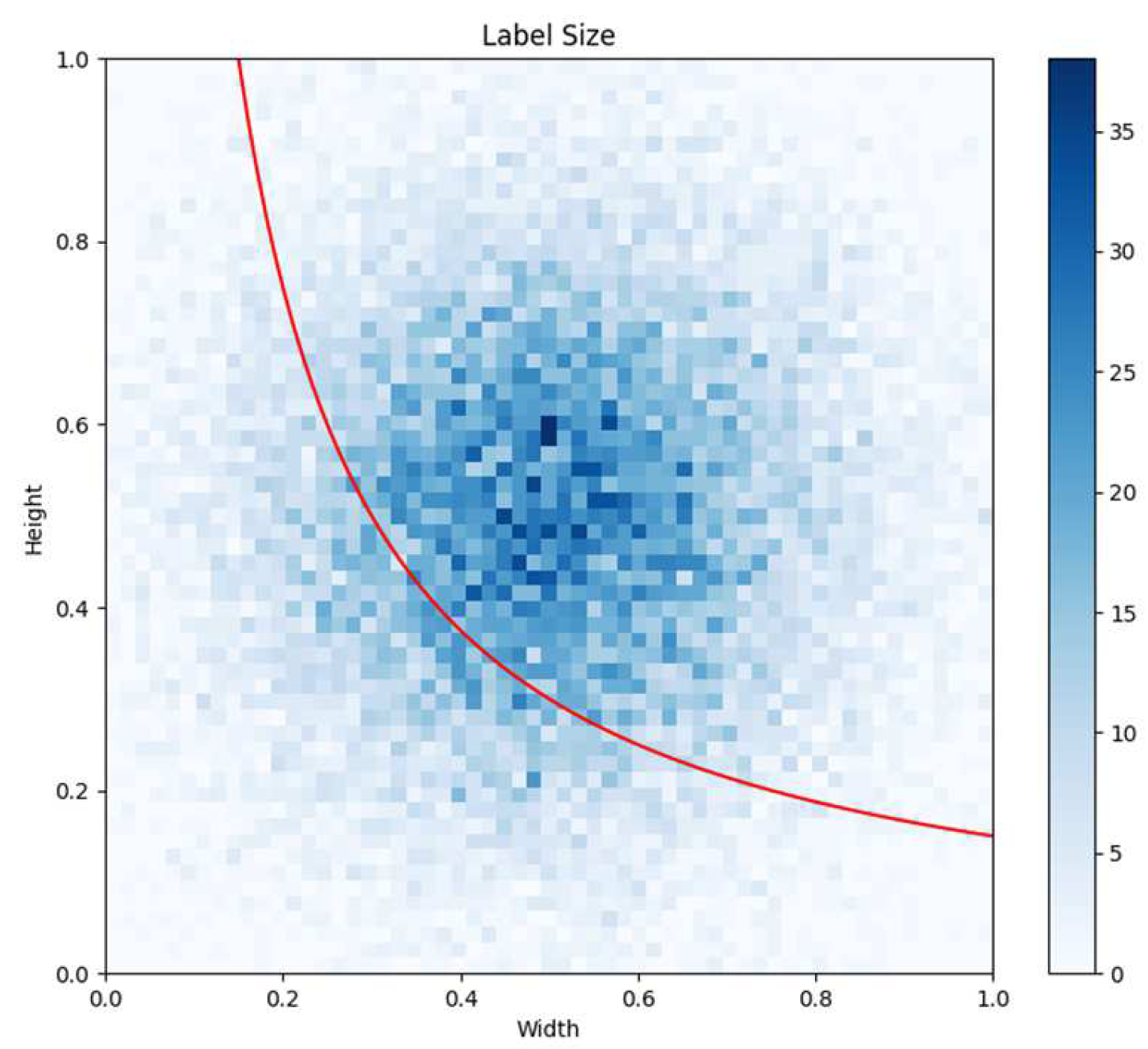
2.1. Incorporating Attention Mechanism
2.2. Adaptive Spatial Feature Fusion Module
2.3. Loss Function Improvement
2.4. Detection Head Improvement
3. Experiment and Analysis of Improved YOLOv5 Algorithm
3.1. Experiment Preparation
3.2. Experimental Evaluation Metrics
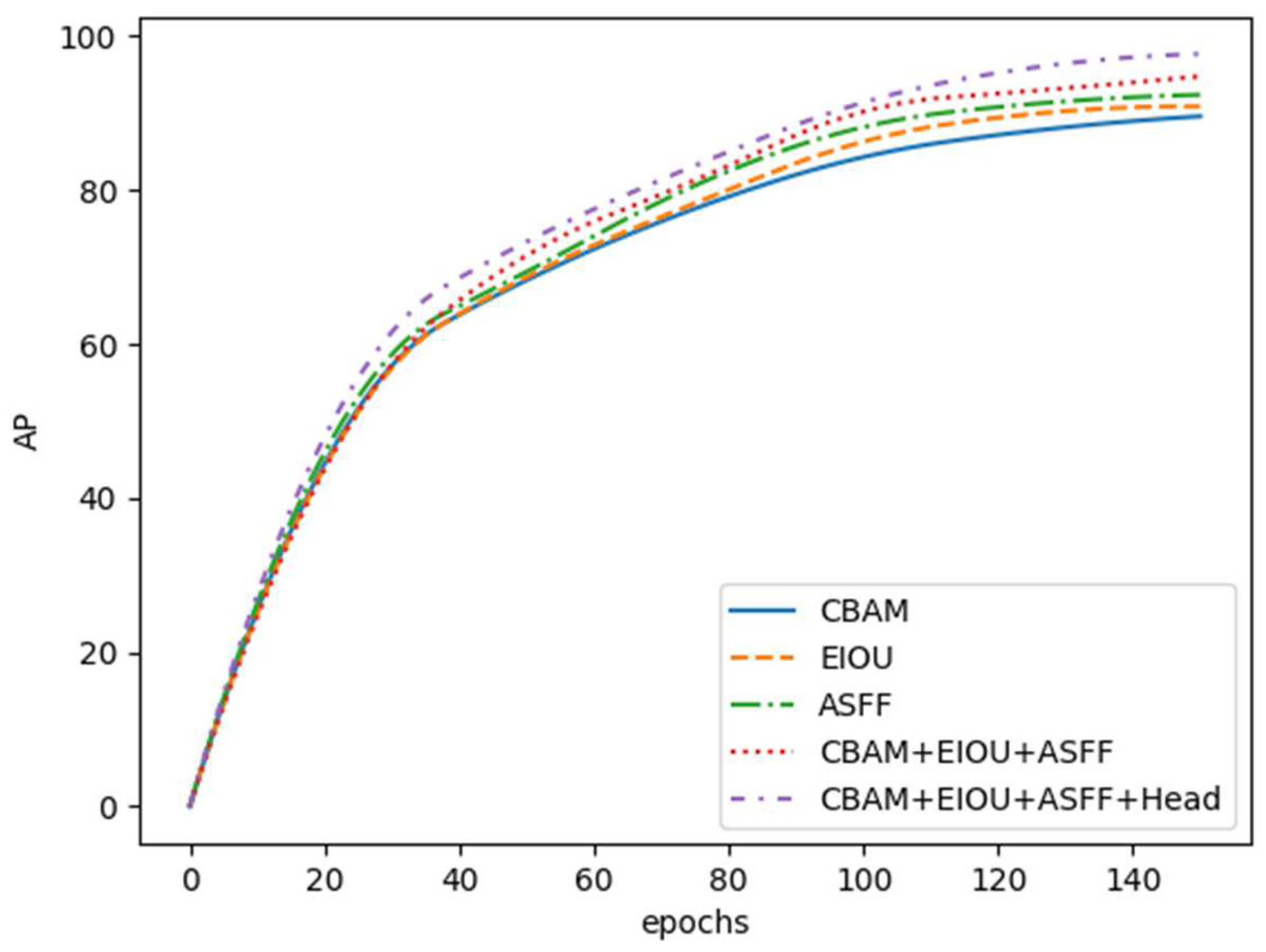
3.3. Ablation Study
3.4. Comparative Experiment
4. Feasibility Verification of Improved YOLOv5 Algorithm Deployment
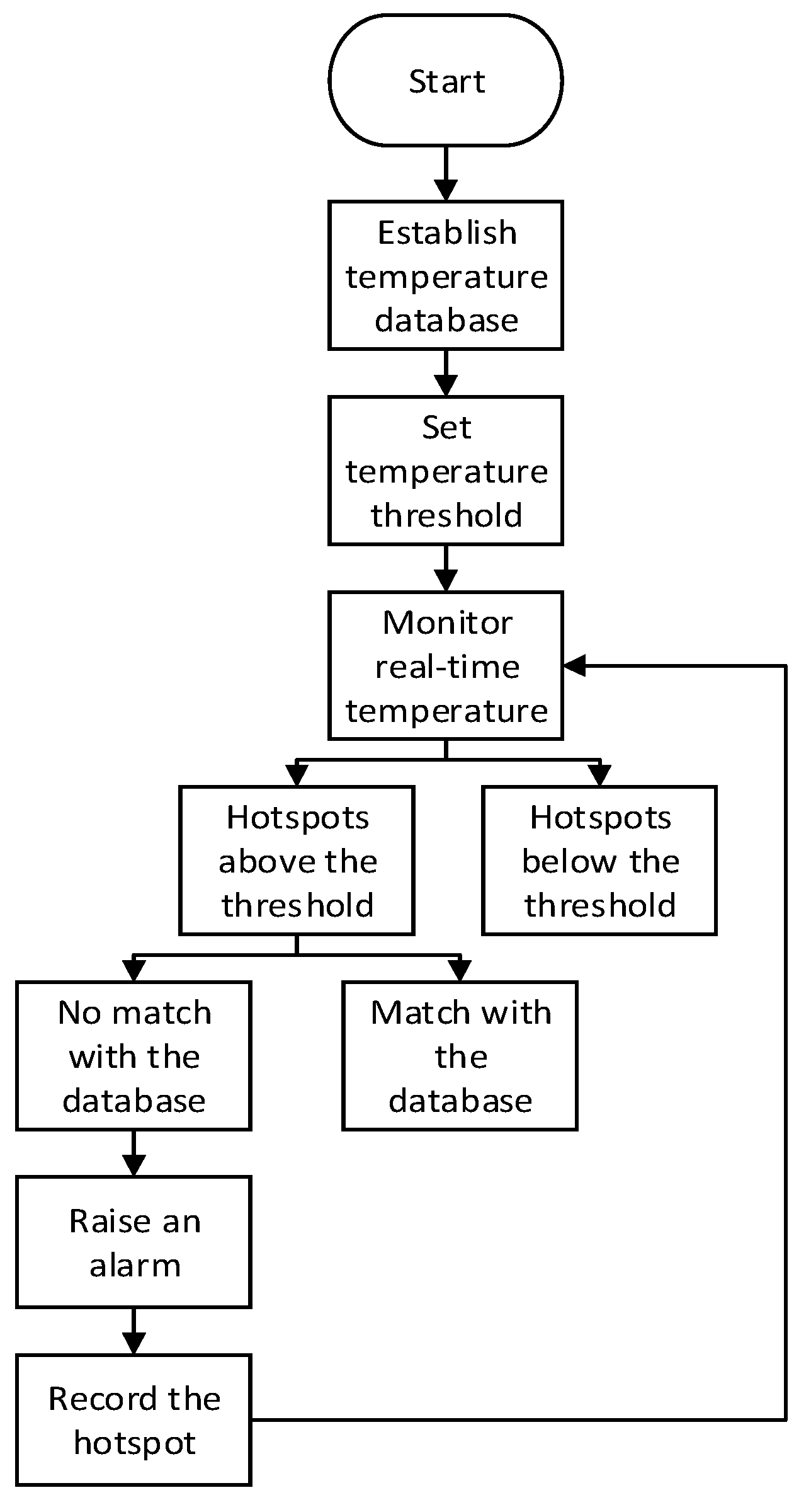
4.1. Temperature-Based Threshold Detection Algorithm
- Establish a local temperature database: Firstly, process the temperature data collected in the target area to establish a temperature model. Secondly, within a certain time period, record the coordinates, range, temperature, and other data of fire source points that appear above the threshold temperature.
- Analyze the established temperature model and set the threshold value according to specific requirements. The threshold is likely to vary depending on the scene.
- Compare the collected temperature data with the threshold: If the temperature is higher than the high-temperature threshold, it is marked as an abnormal hotspot.
- Compare the detected abnormal hotspots with the fire source points recorded in the database: If the coordinates, range, temperature, and other data of the abnormal hotspot match the data of existing fire source points within a certain time period, no alarm is issued, and the lifespan of the fire source point is updated. If the abnormal hotspot does not match successfully, an alarm is issued, and the new fire source point is recorded in the local temperature database. This ensures that the model does not continuously issue alarm messages for normal sources of fire, such as candles or oil lamps, and the lifespan concept also ensures the robustness of the algorithm.
- Update the local temperature database: Update all fire source points in the database and delete the information of fire source points with insufficient lifespan.
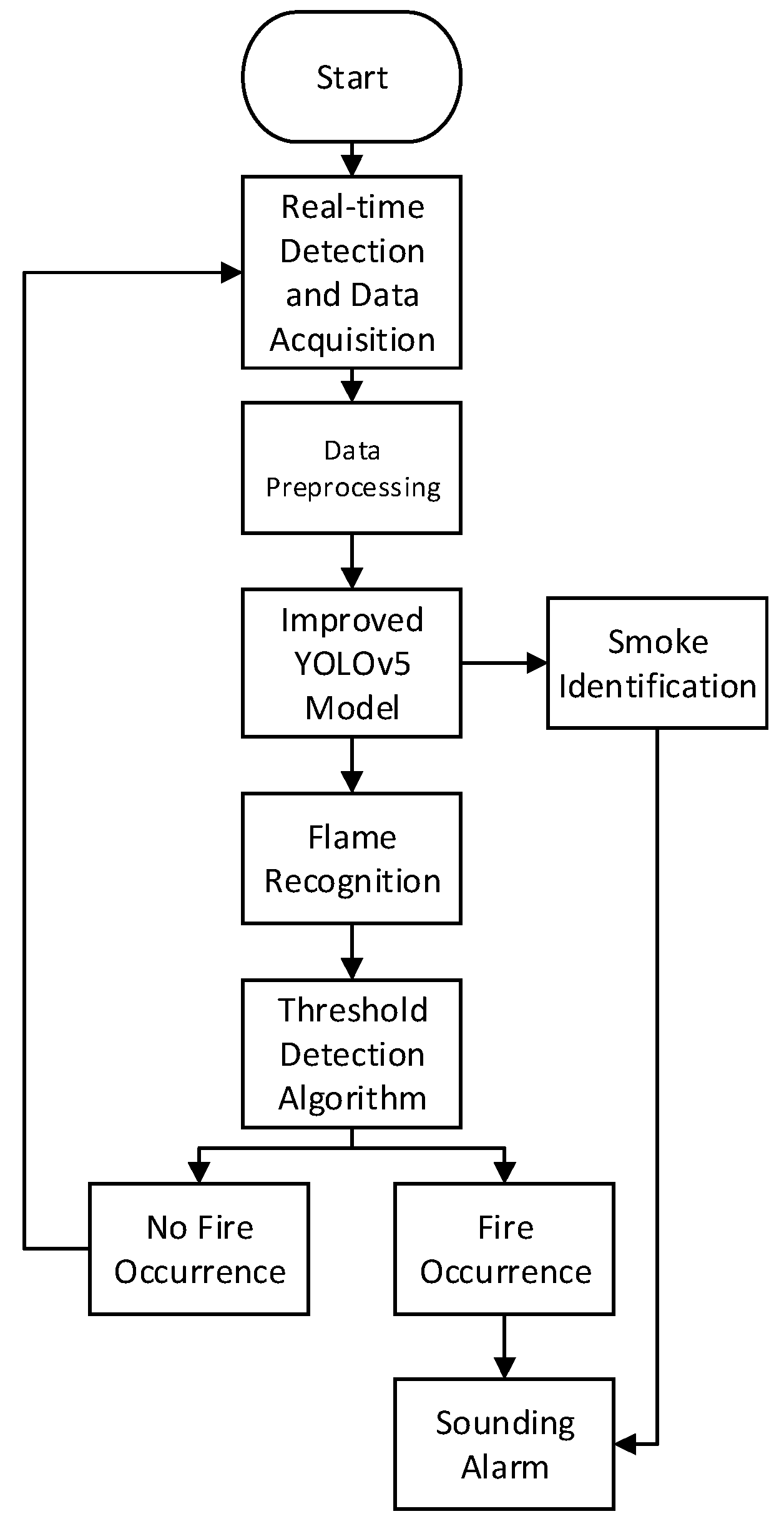
4.2. Algorithm Integration
- Real-time Data Collection from Cameras: Data within the experimental monitoring and collection scene are captured. By using a thermal surveillance camera, the target scene is monitored in real-time. This thermal surveillance camera efficiently captures temperature matrix data around the fire source while also collecting real-time video surveillance data.
- Real-time Data Decryption and Preprocessing: Since the collected fire videos may need to be decrypted, this step ensures the integrity of the data. This step involves decrypting the data and preprocessing the raw data to make them suitable for subsequent algorithmic inputs.
- Improved YOLOv5 Model: The decrypted and preprocessed data are transmitted to the improved YOLOv5 model for target detection. If smoke is identified, an alarm is directly triggered; if flame data is identified, to prevent false alarms, the algorithm continues execution.
- Threshold Detection Algorithm: This threshold detection algorithm judges whether there are hotspot anomalies based on preset thresholds. This step helps reduce false alarm rates and reduces interference from normal fire sources within the scene.
- Result Output: The results are returned, indicating the accurate positions of targets such as fire sources and smoke, along with judgments on the presence of fire sources. The output of this integrated system can be used for real-time fire monitoring, early warning, and taking corresponding response measures.
4.3. Feasibility Verification Experimental Results
5. Conclusions
- An investigation of the impact of attention mechanisms on smoke feature extraction accuracy was conducted. Through experimental comparisons, embedding the CBAM module into the C3_3 module of the SPPF module and the Neck network resulted in the most substantial improvement. It increased precision by 2% on the standard dataset and by 1.4% on the small target dataset.
- The traditional YOLOv5 network structure was improved by incorporating CBAM and ASFF modules, as well as enhancing loss functions and detection modules. These enhancements led to an 8.1% increase in Average Precision (AP) on the standard dataset DATA1 and an 8.6% increase on the small target dataset DATA2.
- The improved YOLOv5 algorithm was combined with a temperature-based threshold detection algorithm, achieving a frame rate of 57 frames per second during actual deployment. Such experimental results demonstrated high accuracy and reliability, both enhancing the precision of the algorithm and validating the feasibility of deployment.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Majid, S.; Alenezi, F.; Masood, S.; Ahmad, M.; Gündüz, E.S.; Polat, K. Attention Based Cnn Model for Fire Detection and Localization in Real-World Images. Expert Syst. Appl. 2022, 189, 116114. [Google Scholar] [CrossRef]
- Campbell, M.J.; Dennison, P.E.; Thompson, M.P.; Butler, B.W. Assessing Potential Safety Zone Suitability Using a New Online Mapping Tool. Fire 2022, 5, 5. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, M.; Ding, Y.; Bu, X. Ms-Frcnn: A Multi-Scale Faster Rcnn Model for Small Target Forest Fire Detection. Forests 2023, 14, 616. [Google Scholar] [CrossRef]
- Sun, B.; Wang, Y.; Wu, S. An Efficient Lightweight Cnn Model for Real-Time Fire Smoke Detection. J. Real-Time Image Process. 2023, 20, 74. [Google Scholar] [CrossRef]
- Almeida, J.S.; Jagatheesaperumal, S.K.; Nogueira, F.G.; de Albuquerque, V.H.C. Edgefiresmoke++: A Novel Lightweight Algorithm for Real-Time Forest Fire Detection and Visualization Using Internet of Things-Human Machine Interface. Expert Syst. Appl. 2023, 221, 119747. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An Improved Fire Detection Approach Based on Yolo-V8 for Smart Cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Kim, S.Y.; Muminov, A. Forest Fire Smoke Detection Based on Deep Learning Approaches and Unmanned Aerial Vehicle Images. Sensors 2023, 23, 5702. [Google Scholar] [CrossRef]
- Lin, J.; Lin, H.; Wang, F. A Semi-Supervised Method for Real-Time Forest Fire Detection Algorithm Based on Adaptively Spatial Feature Fusion. Forests 2023, 14, 361. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Huang, Q.; Li, X. A Gated Recurrent Network with Dual Classification Assistance for Smoke Semantic Segmentation. IEEE Trans. Image Process. 2021, 30, 4409–4422. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location Classification | Model | AP (%) | |
|---|---|---|---|
| DATA1 | DATA2 | ||
| YOLOv5 | YOLOv5 | 89.6 | 51.7 |
| 1 | YOLOv5 + CBAM1 | 91.1 | 52.3 |
| 2 | YOLOv5 + CBAM2 | 91.0 | 52.7 |
| 3 | YOLOv5 + CBAM3 | 91.6 | 53.1 |
| Methods | CBAM | EIOU | ASFF | Head | DATA1 | DATA2 | FPS | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| P% | R% | AP% | P% | R% | AP% | ||||||
| YOLOv5n | 91.1 | 89.5 | 89.6 | 49.6 | 52.1 | 51.7 | 102 | ||||
| A | √ | 90.3 | 89.2 | 91.6 | 51.6 | 52.2 | 53.1 | 101 | |||
| B | √ | 89.1 | 88.9 | 91.9 | 51.1 | 54.1 | 53.3 | 105 | |||
| C | √ | 90.1 | 91.7 | 92.4 | 54.7 | 55.2 | 56.3 | 77 | |||
| D | √ | √ | √ | 96.8 | 93.5 | 94.8 | 57.1 | 59.3 | 58.6 | 75 | |
| Improvements | √ | √ | √ | √ | 96.1 | 95.9 | 97.7 | 59.2 | 61.1 | 60.1 | 63 |
| Methods | DATA1 | DATA2 | ||||
|---|---|---|---|---|---|---|
| P/% | R/% | AP/% | P/% | R/% | AP/% | |
| YOLOv5n | 89.1 | 88.5 | 89.6 | 51.6 | 53.4 | 51.7 |
| Faster R-CNN | 97.6 | 95.3 | 97.1 | 52.3 | 54.2 | 53.2 |
| Retina Net | 93.2 | 92.2 | 92.4 | 49.3 | 51.8 | 47.2 |
| YOLOv7-tiny | 89.2 | 91.0 | 90.5 | 53.6 | 56.2 | 51.3 |
| YOLOv8n | 91.2 | 92.2 | 90.3 | 56.2 | 53.7 | 52.5 |
| Improvements | 96.1 | 97.9 | 97.7 | 61.3 | 62.9 | 60.1 |
| Method | False Positives | Accuracy/% | FPS |
|---|---|---|---|
| HK | 131 | 86.6 | 95 |
| HK-YOLO | 78 | 95.3 | 64 |
| HK-YOLO-TEMP | 17 | 98.5 | 57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Tu, Y.; Huo, Y.; Ren, J. A Robustness Study on Early Fire Image Recognitions. Fire 2024, 7, 241. https://doi.org/10.3390/fire7070241
Wang J, Tu Y, Huo Y, Ren J. A Robustness Study on Early Fire Image Recognitions. Fire. 2024; 7(7):241. https://doi.org/10.3390/fire7070241
Chicago/Turabian StyleWang, Jingwu, Yifeng Tu, Yinuo Huo, and Jingxia Ren. 2024. "A Robustness Study on Early Fire Image Recognitions" Fire 7, no. 7: 241. https://doi.org/10.3390/fire7070241
APA StyleWang, J., Tu, Y., Huo, Y., & Ren, J. (2024). A Robustness Study on Early Fire Image Recognitions. Fire, 7(7), 241. https://doi.org/10.3390/fire7070241