
A Multilevel Multiresolution Machine Learning Classification Approach: A Generalization Test on Chinese Heritage Architecture




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
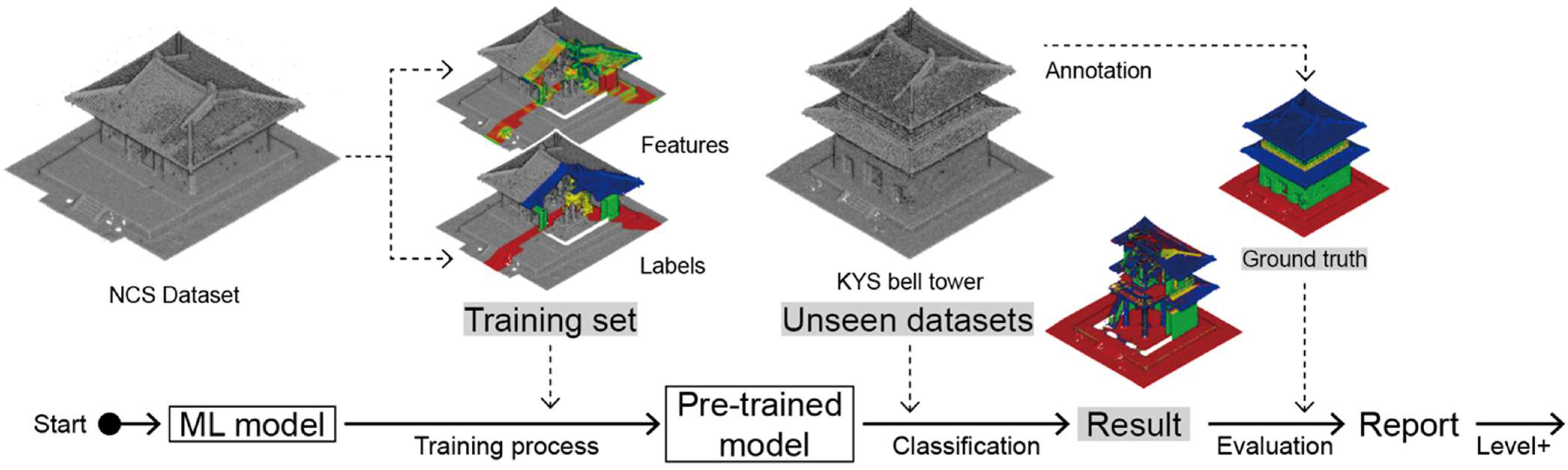
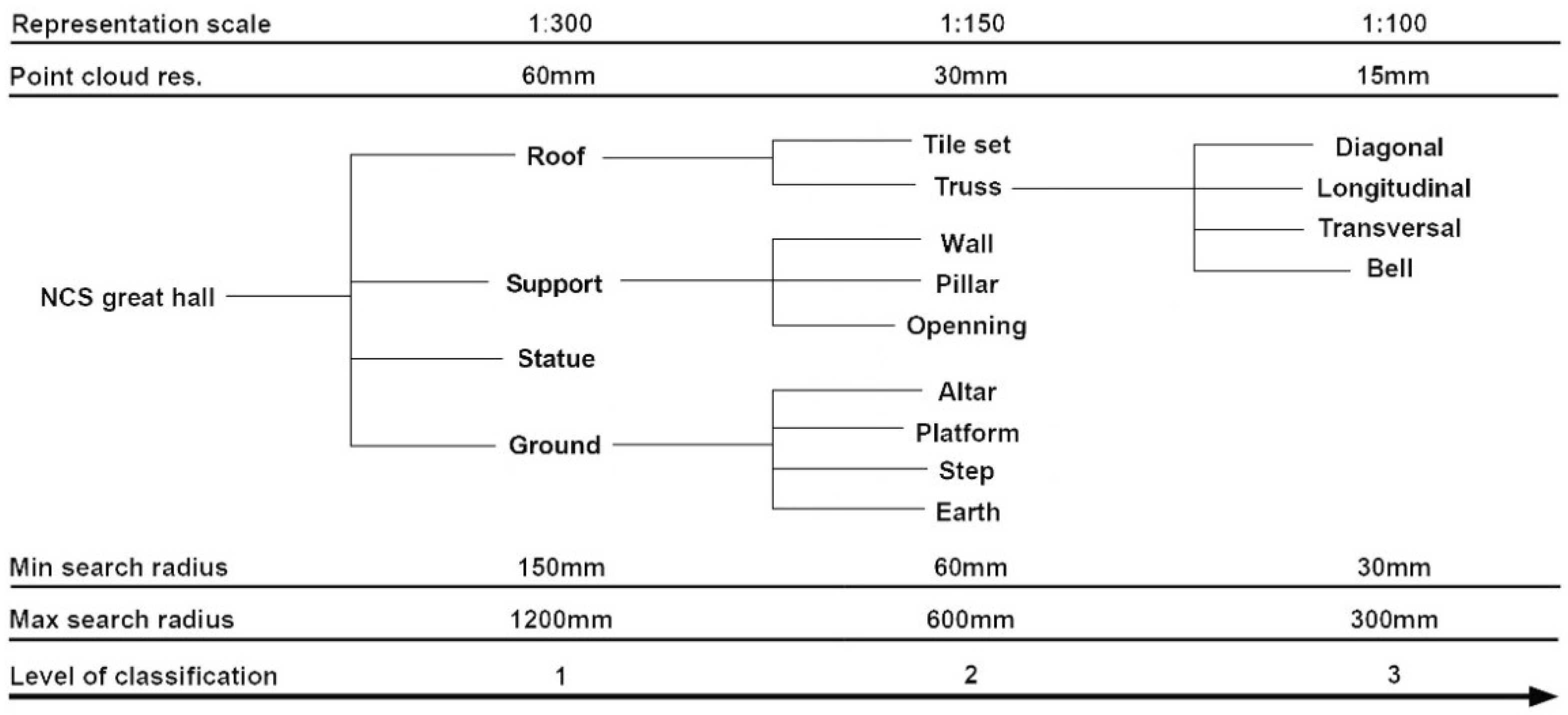
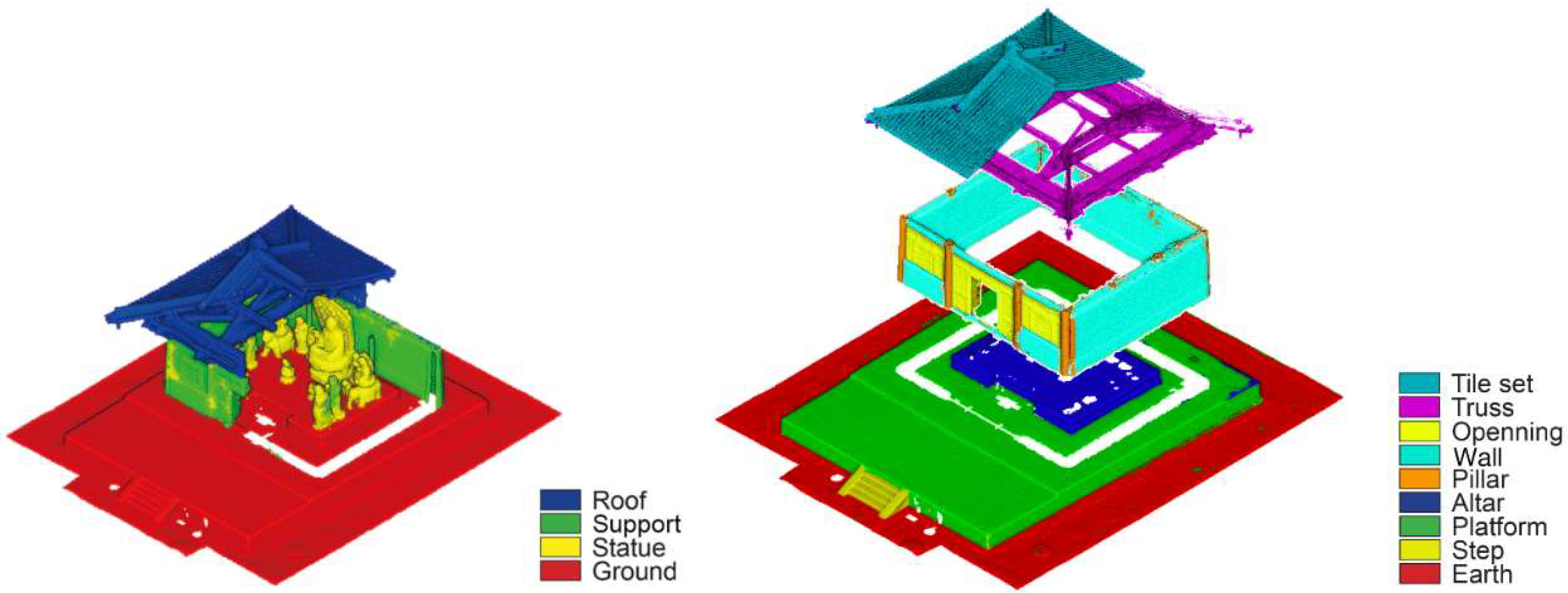
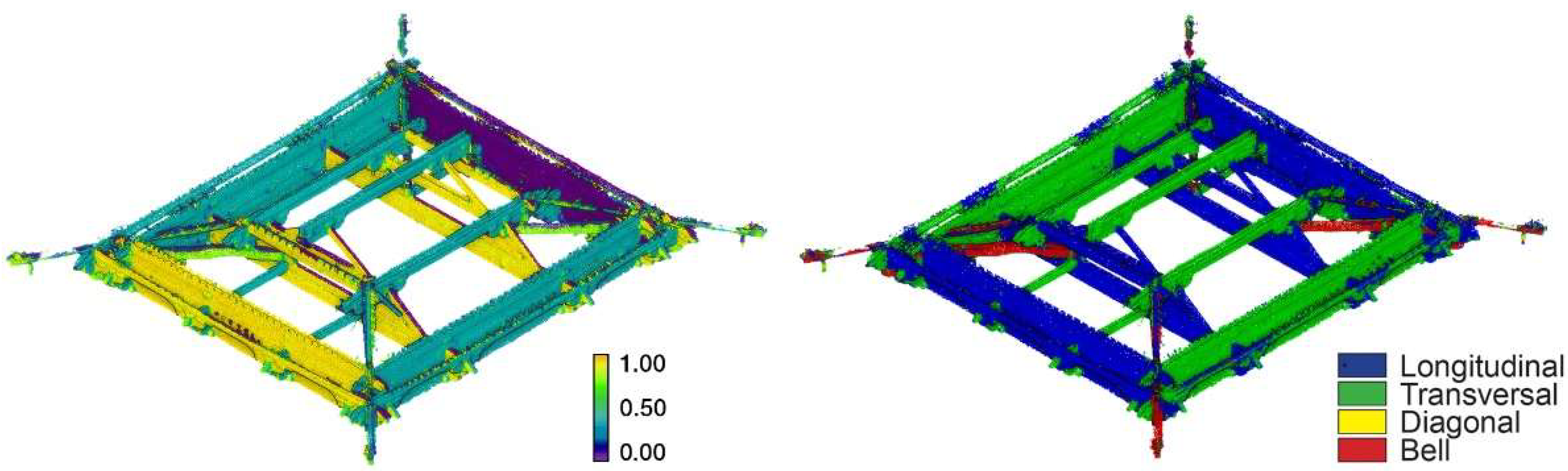
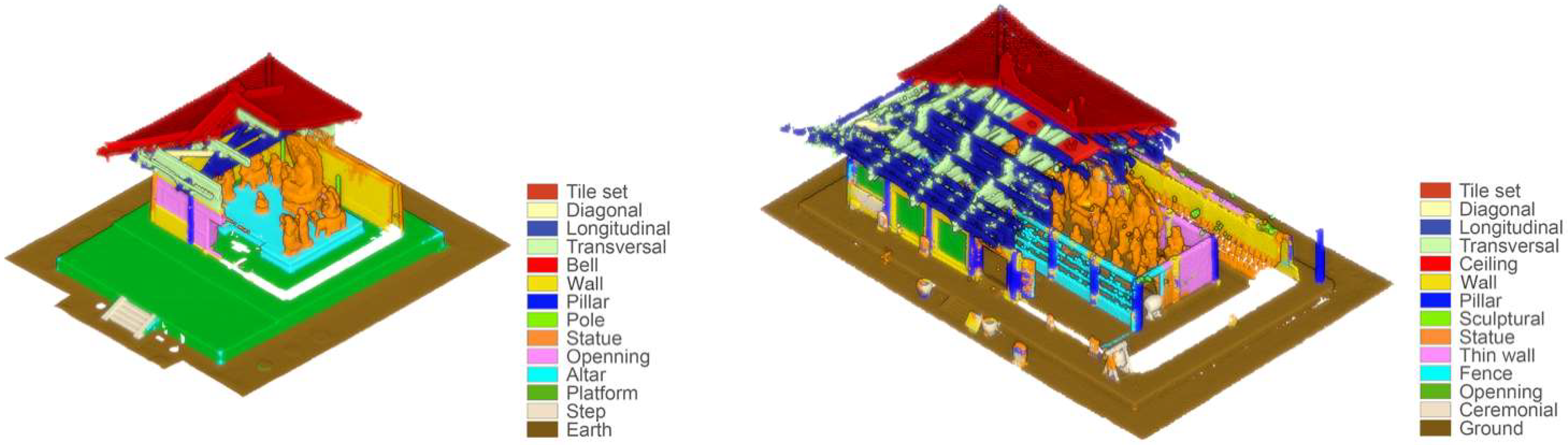
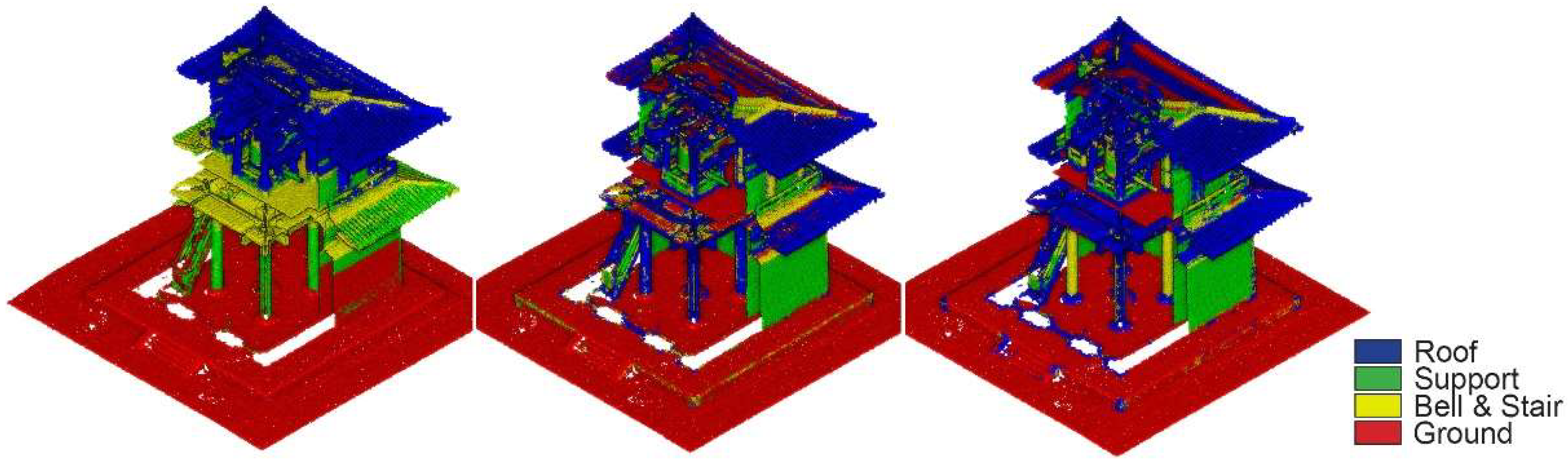
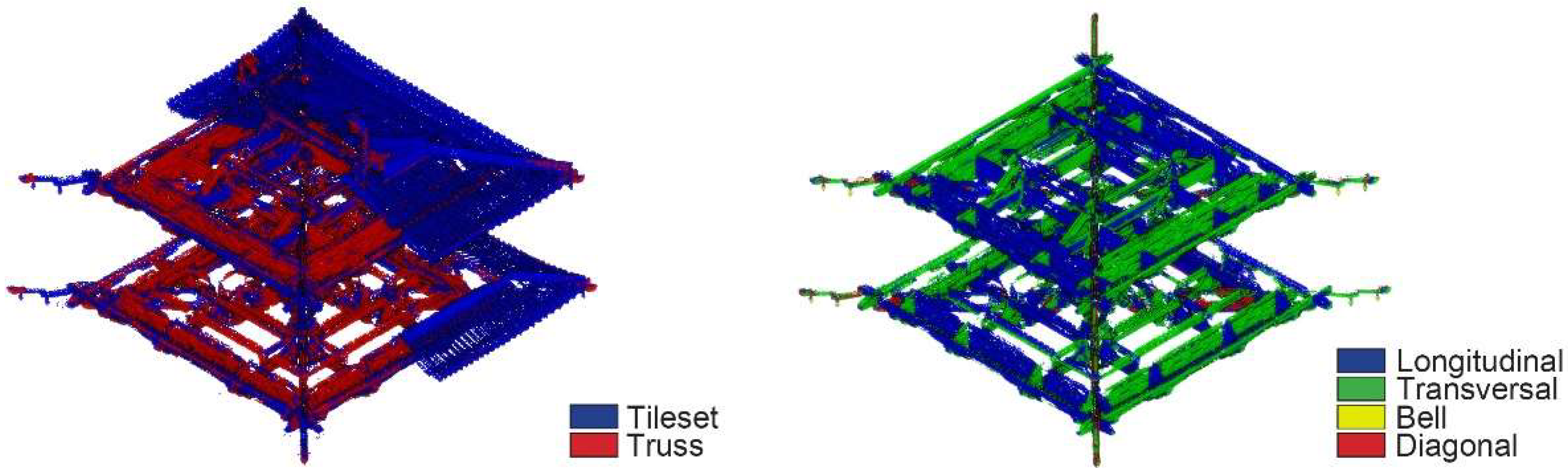
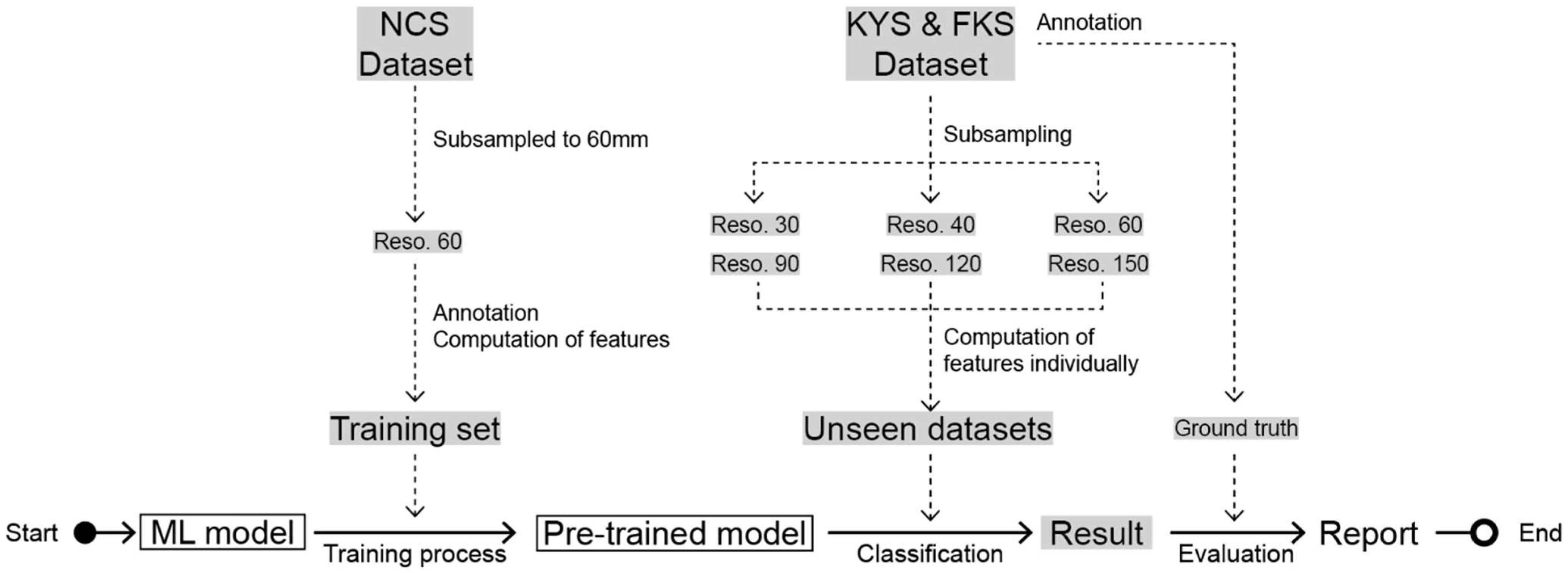
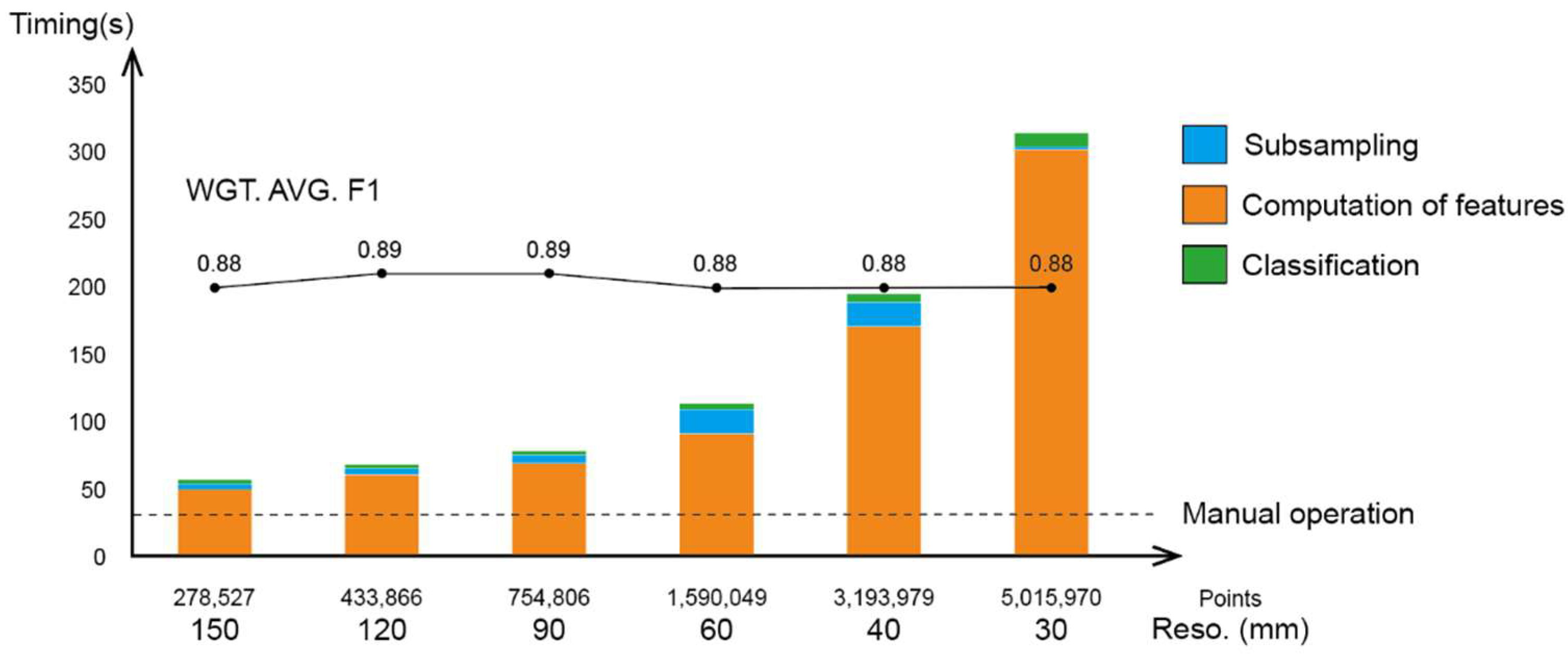
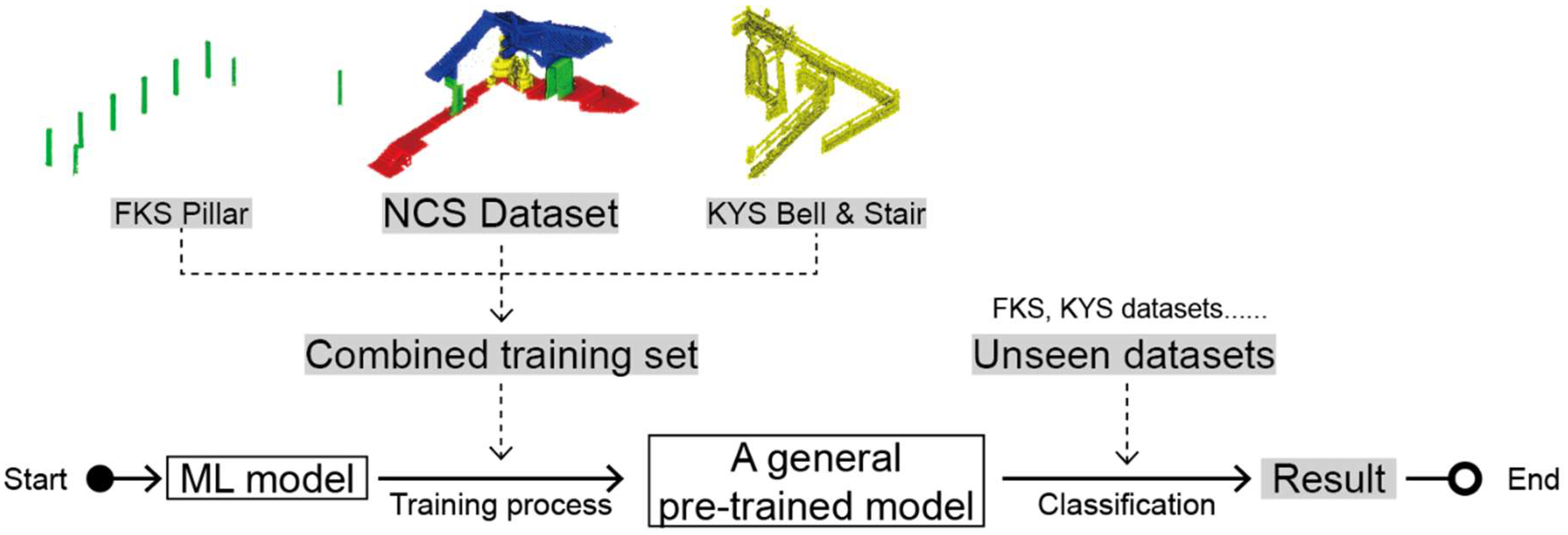
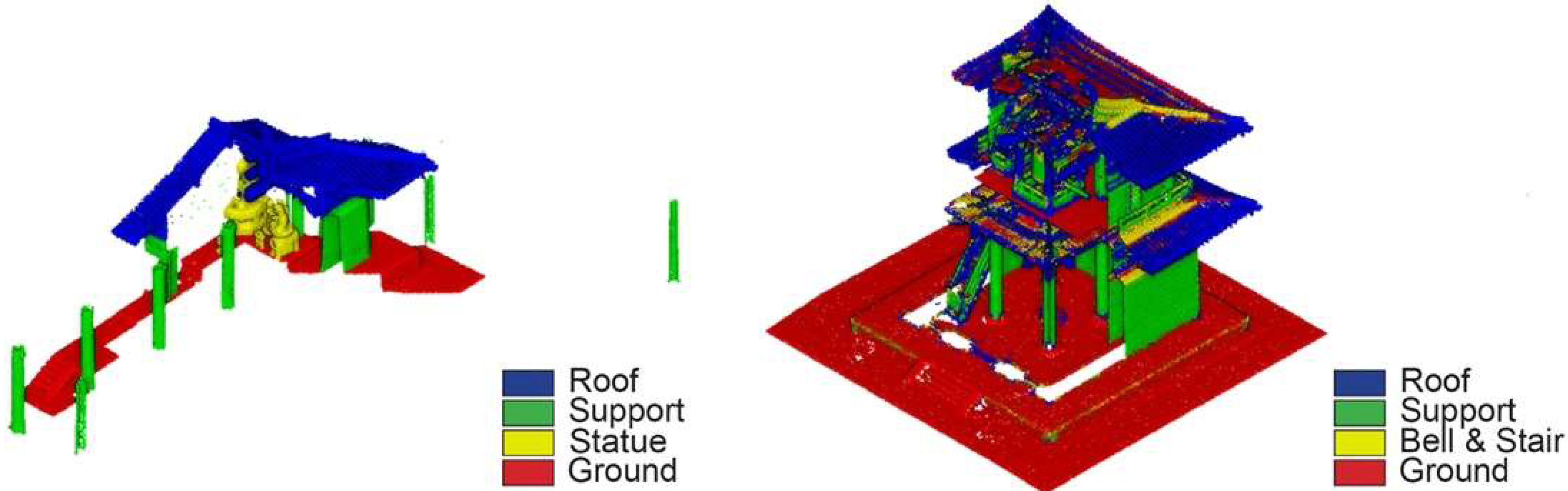
Abstract
Share and Cite
Zhang, K.; Teruggi, S.; Ding, Y.; Fassi, F. A Multilevel Multiresolution Machine Learning Classification Approach: A Generalization Test on Chinese Heritage Architecture. Heritage 2022, 5, 3970-3992. https://doi.org/10.3390/heritage5040204
Zhang K, Teruggi S, Ding Y, Fassi F. A Multilevel Multiresolution Machine Learning Classification Approach: A Generalization Test on Chinese Heritage Architecture. Heritage. 2022; 5(4):3970-3992. https://doi.org/10.3390/heritage5040204
Chicago/Turabian StyleZhang, Kai, Simone Teruggi, Yao Ding, and Francesco Fassi. 2022. "A Multilevel Multiresolution Machine Learning Classification Approach: A Generalization Test on Chinese Heritage Architecture" Heritage 5, no. 4: 3970-3992. https://doi.org/10.3390/heritage5040204
APA StyleZhang, K., Teruggi, S., Ding, Y., & Fassi, F. (2022). A Multilevel Multiresolution Machine Learning Classification Approach: A Generalization Test on Chinese Heritage Architecture. Heritage, 5(4), 3970-3992. https://doi.org/10.3390/heritage5040204