3D Object Detection Using Frustums and Attention Modules for Images and Point Clouds


Abstract
:1. Introduction
- In the PointNet of Frustum ConvNet, we added the Convolutional Block Attention Module (CBAM) [7] attention module at the hidden layer of Multilayer Perceptron (MLP) to improve the detection accuracy. The CBAM attention module can improve the contrast between the object and the surrounding environment.
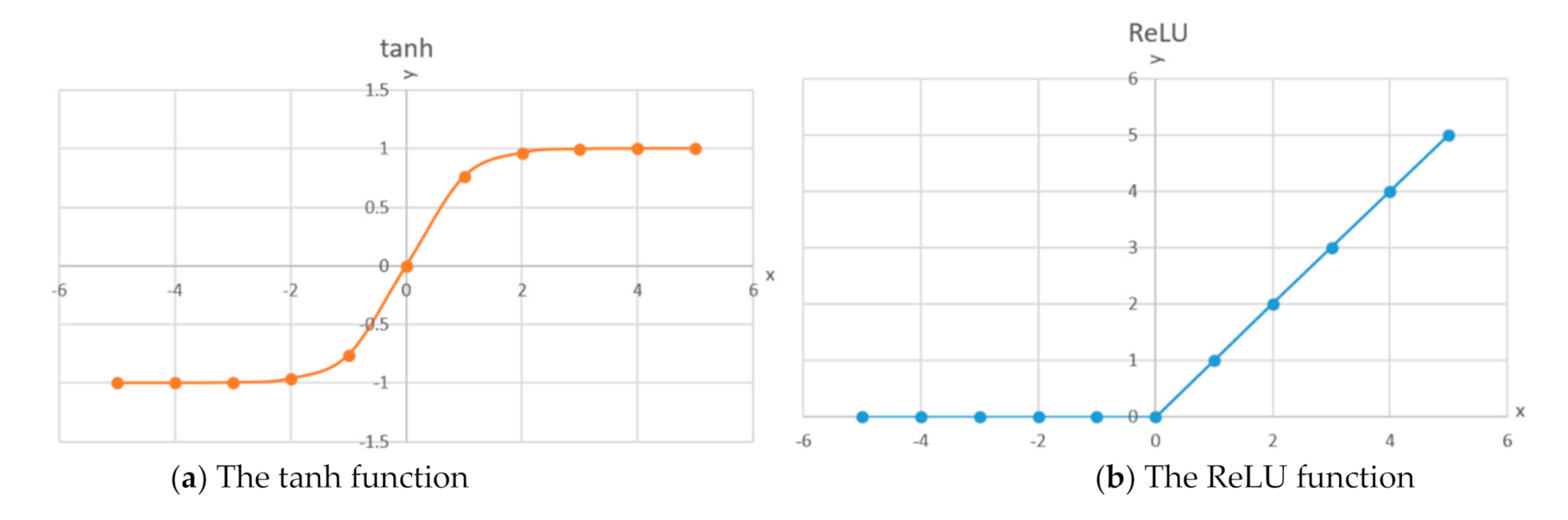
- We propose an improved attention module by adding Multilayer Perceptron (MLP) and using the tanh activation function. The tanh function is used for average-pooling and max-pooling layers to extract features. The mean of the tanh activation function is 0. Furthermore, the tanh function can cope with cases when the feature values have big differences. Finally, the feature information of the pooling layers is fused through the sigmoid function.
- We evaluated our approach on the KITTI [8] object detection benchmark. Compared with the state-of-the-art method, our method achieved competitive results, with an improvement of 0.21%, 0.27%, and 0.01% in Average Precision (AP) for 3D object detection in easy, moderate, and hard cases, respectively, and an improvement of 0.27%, 0.43%, and 0.36% in AP for Bird’s Eye View (BEV) object detection in easy, moderate, and hard cases, respectively, on KITTI detection benchmarks. Our method also obtains the best results in four cases in AP on the indoor SUN-RGBD [9] dataset for 3D object detection.
2. Related Works
2.1. Three-Dimensional (3D) Object Detection from Point Clouds
2.2. Attention Module in Object Detection
2.3. Activation Function in Neural Network
3. Frustum ConvNet with Attention (FCAM)
3.1. Frustum ConvNet
3.2. The Improved CBAM Attention Model for Point Cloud Detection
4. Experimental Results
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Z.; Jia, K. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. Computer Vision and Pattern Recognition (CVPR). arXiv 2019, arXiv:1903.01864. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Guo, W.; Xu, C.; Ma, S.; Xu, M. Visual attention based small object segmentation in natual images. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 1565–1568. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 15–20. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Xiang, Y.; Choi, W.; Lin, Y.; Savarese, S. Data-driven 3d voxel patterns for object category recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1903–1911. [Google Scholar]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Aggregate channel features for multi-view face detection. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–8. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Li, B. 3d fully convolutional network for vehicle detection in point cloud. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1513–1518. [Google Scholar]
- Song, S.; Xiao, J. Deep sliding shapes for amodal 3d object detection in rgb-d images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 808–816. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 22–24 June 2010. [Google Scholar]
- Zeiler, M.D.; Ranzato, M.; Monga, R.; Mao, M.; Yang, K.; Le, Q.V.; Hinton, G.E. On rectified linear units for speech processing. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3517–3521. [Google Scholar]
- Le, Q.V.; Jaitly, N.; Hinton, G.E. A simple way to initialize recurrent networks of rectified linear units. arXiv 2015, arXiv:1504.00941. [Google Scholar]
- Ang-bo, J.; Wei-wei, W. Research on optimization of ReLU activation function. Trans. Microsyst. Technol. 2018, 2. Available online: https://en.cnki.com.cn/Article_en/CJFDTotalCGQJ201802014.htm (accessed on 11 February 2021).
- Li, X.; Hu, Z.; Huang, X. Combine Relu with Tanh. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 51–55. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Ipod: Intensive point-based object detector for point cloud. Computer Vision and Pattern Recognition (CVPR). arXiv 2018, arXiv:1812.05276. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Shi, S.; Wang, X.; Wang, H. PointRCNN Li. 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 15–20. [Google Scholar]
- Ren, Z.; Sudderth, E.B. Three-dimensional object detection and layout prediction using clouds of oriented gradients. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1525–1533. [Google Scholar]
- Lahoud, J.; Ghanem, B. 2d-driven 3d object detection in rgbd images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4622–4630. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Ren, Z.; Sudderth, E.B. 3d object detection with latent support surfaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 937–946. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | T(s) | Easy | Moderate | Hard |
|---|---|---|---|---|
| Frustum ConvNet [1] | 0.002 | 90.23 | 88.79 | 86.84 |
| Frustum ConvNet [1] + CBAM [7] | 0.003 | 90.35 | 89.06 | 86.88 |
| Frustum ConvNet [1] + Improved CBAM | 0.004 | 90.44 | 89.06 | 86.85 |
| Method | T(s) | Easy | Moderate | Hard |
|---|---|---|---|---|
| Frustum ConvNet [1] | 0.002 | 89.02 | 78.80 | 77.09 |
| Frustum ConvNet [1] + CBAM [7] | 0.003 | 89.35 | 79.08 | 77.32 |
| Frustum ConvNet [1] + Improved CBAM | 0.004 | 89.29 | 79.23 | 77.45 |
| Method | Easy | Moderate | Hard |
|---|---|---|---|
| MV3D [12] | 86.55 | 78.10 | 76.67 |
| VoxelNet [15] | 89.60 | 84.81 | 78.57 |
| F-PointNet [2] | 88.16 | 84.92 | 76.44 |
| IPOD [26] | 88.3 | 86.4 | 84.6 |
| Frustum ConvNet [1] | 90.23 | 88.79 | 86.84 |
| FCAM (Ours) | 90.44 | 89.06 | 86.85 |
| Method | Easy | Moderate | Hard |
|---|---|---|---|
| MV3D [12] | 71.29 | 62.68 | 56.56 |
| VoxelNet [15] | 81.97 | 65.46 | 62.85 |
| F-PointNet [2] | 83.76 | 70.92 | 63.65 |
| IPOD [26] | 84.1 | 76.4 | 75.3 |
| AVOD-FPN [27] | 84.41 | 74.44 | 68.65 |
| PointRCNN [28] | 88.88 | 78.63 | 77.38 |
| Frustum ConvNet [1] | 89.02 | 78.80 | 77.09 |
| FCAM (Ours) | 89.29 | 79.23 | 77.45 |
| Method | Bathtub | Bed | Bookshelf | Chair | Desk | Dresser | Nightstand | Sofa | Table | Toilet | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSS [14] | 44.2 | 78.8 | 11.9 | 61.2 | 20.5 | 6.4 | 15.4 | 53.5 | 50.3 | 78.9 | 42.1 |
| COG [29] | 58.26 | 63.67 | 31.80 | 62.17 | 45.19 | 15.47 | 27.36 | 51.02 | 51.29 | 70.07 | 47.63 |
| 2Ddriven3D [30] | 43.45 | 64.48 | 31.40 | 48.27 | 27.93 | 25.92 | 41.92 | 50.39 | 37.02 | 80.40 | 45.12 |
| PointFusion [31] | 37.26 | 68.57 | 37.69 | 55.09 | 17.16 | 23.95 | 32.33 | 53.83 | 31.03 | 83.80 | 45.38 |
| Ren et al. [32] | 76.2 | 73.2 | 32.9 | 60.5 | 34.5 | 13.5 | 30.4 | 60.4 | 55.4 | 73.7 | 51.0 |
| F-PointNet [2] | 43.3 | 81.1 | 33.3 | 64.2 | 24.7 | 32.0 | 58.1 | 61.1 | 51.1 | 90.9 | 54.0 |
| Frustum ConvNet [1] | 61.32 | 83.19 | 36.46 | 64.4 | 29.67 | 35.10 | 58.42 | 66.61 | 53.34 | 86.99 | 57.55 |
| FCAM (Ours) | 57.18 | 84.86 | 36.04 | 65.32 | 32.40 | 36.51 | 57.62 | 66.91 | 54.87 | 88.36 | 58.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Xie, H.; Shin, H. 3D Object Detection Using Frustums and Attention Modules for Images and Point Clouds. Signals 2021, 2, 98-107. https://doi.org/10.3390/signals2010009
Li Y, Xie H, Shin H. 3D Object Detection Using Frustums and Attention Modules for Images and Point Clouds. Signals. 2021; 2(1):98-107. https://doi.org/10.3390/signals2010009
Chicago/Turabian StyleLi, Yiran, Han Xie, and Hyunchul Shin. 2021. "3D Object Detection Using Frustums and Attention Modules for Images and Point Clouds" Signals 2, no. 1: 98-107. https://doi.org/10.3390/signals2010009
APA StyleLi, Y., Xie, H., & Shin, H. (2021). 3D Object Detection Using Frustums and Attention Modules for Images and Point Clouds. Signals, 2(1), 98-107. https://doi.org/10.3390/signals2010009