
AI-Driven Prediction and Mapping of Soil Liquefaction Risks for Enhancing Earthquake Resilience in Smart Cities

Abstract
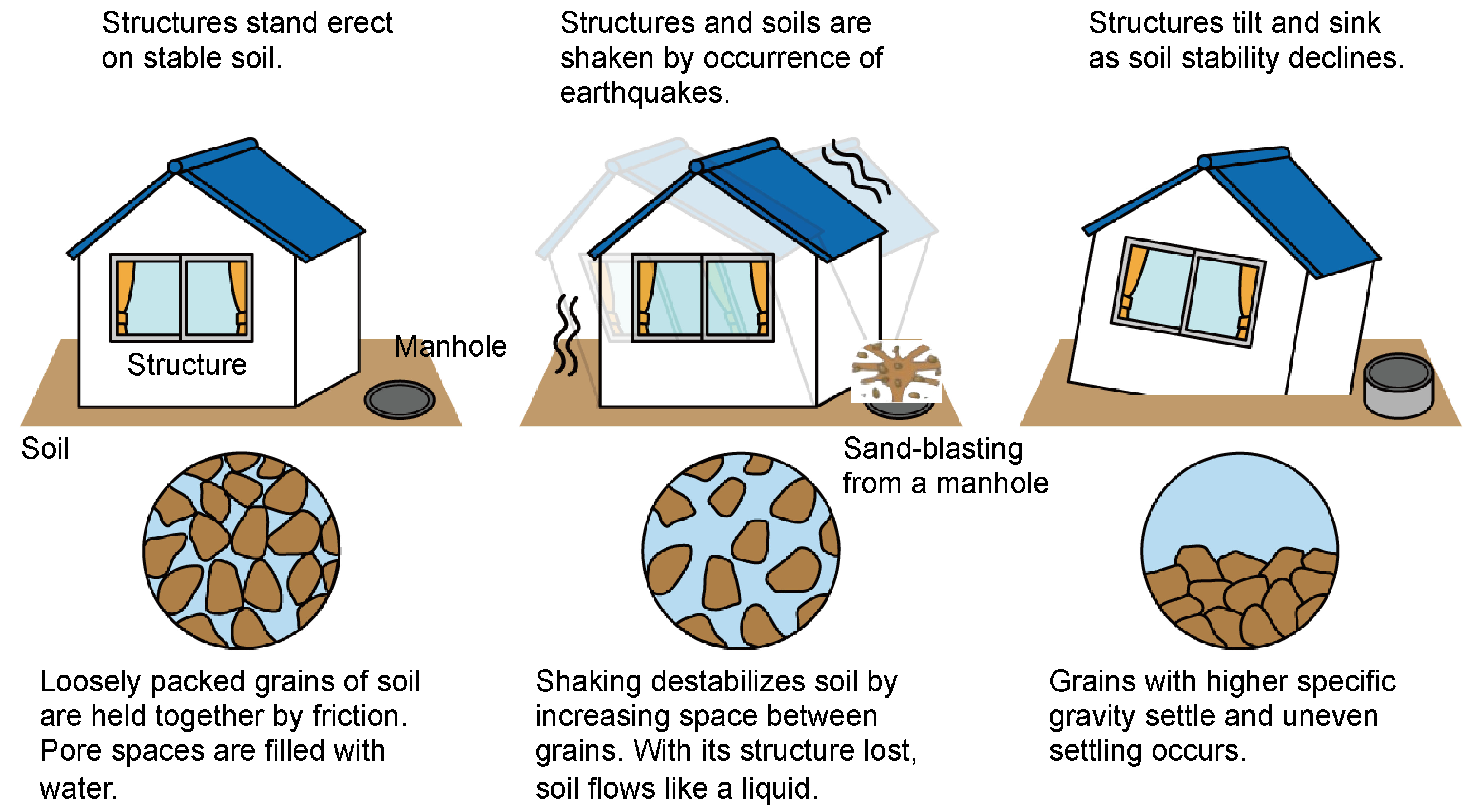
:1. Introduction
2. AI-Driven Predictive Models
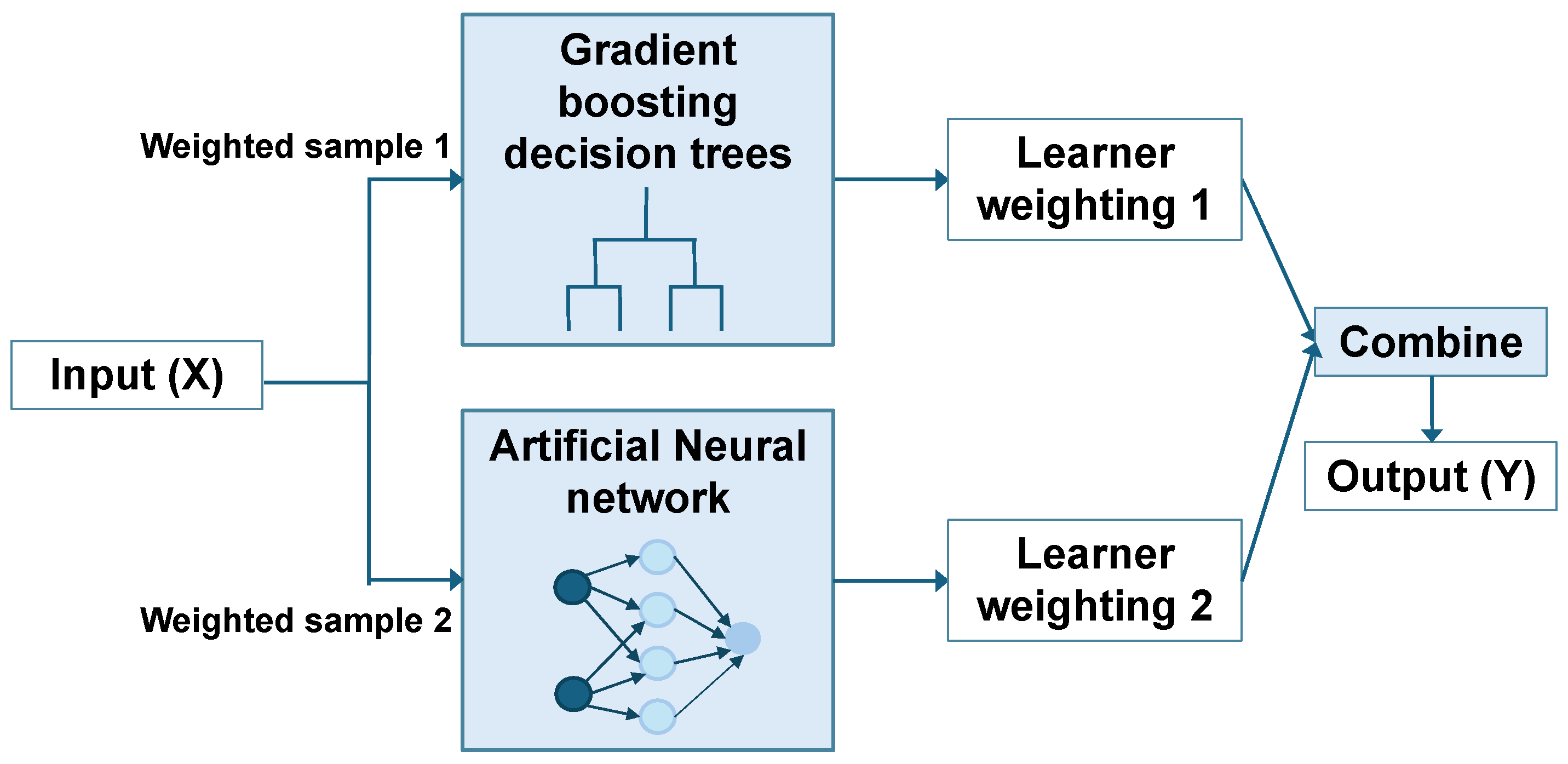
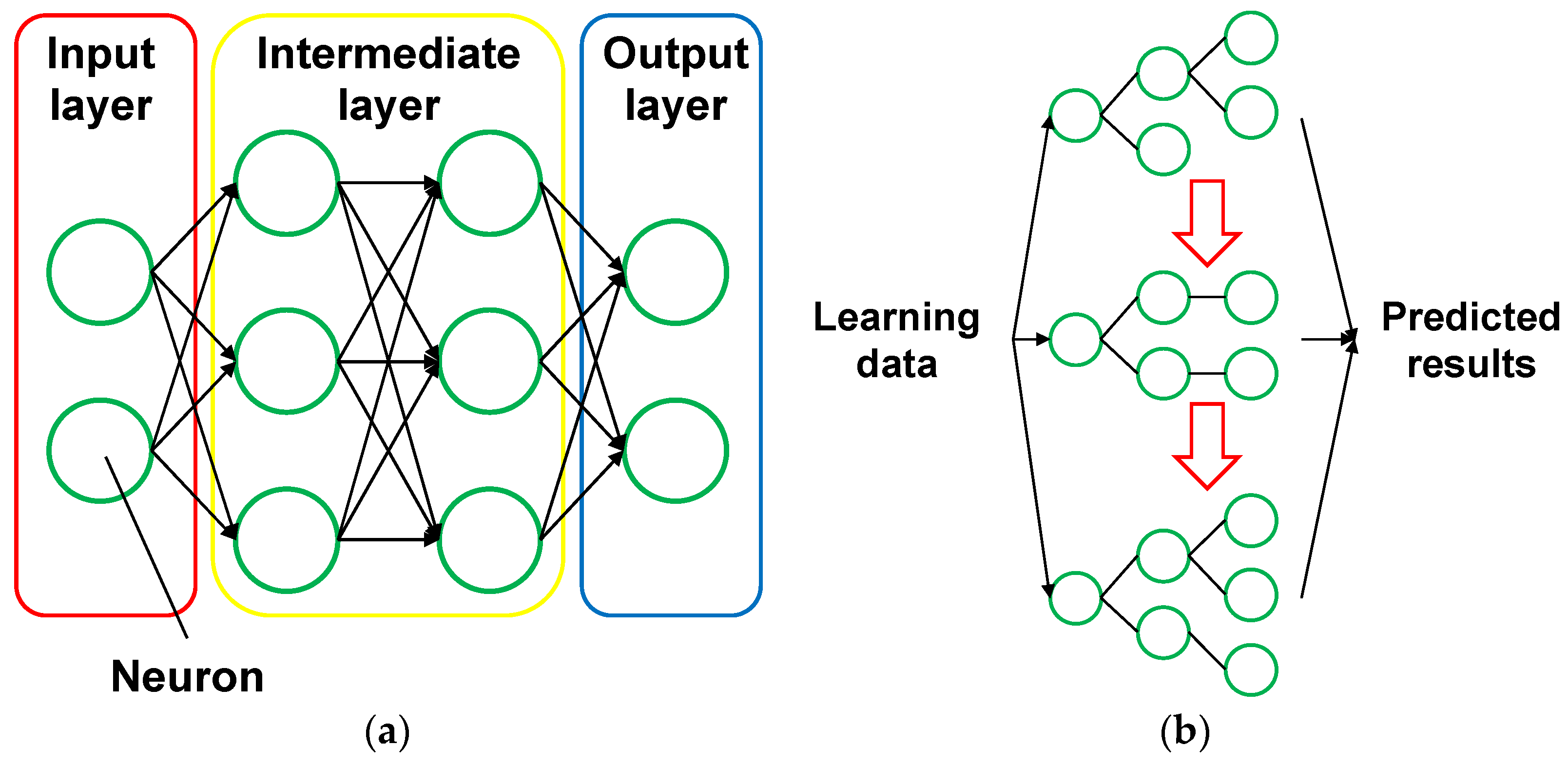
2.1. Ensemble Machine Learning
2.2. Reliability of Predictive Results by AI-Driven Predictive Model
3. Soil Liquefaction Risk Prediction with AI-Driven Predictive Model
3.1. Procedures on Soil Liquefaction Risk Prediction
- (1)
- The groundwater level must be within 10 m of the ground surface, and saturation must occur within 20 m of the ground surface.
- (2)
- The fine particle content (FC) must exceed 35%, with a plasticity index of 15 or less.
- (3)
- The average grain size (D50) must be 10 mm or less, and the 10% grain size (D10) must be 1 mm or less.
3.2. Assumed Earthquake Motions for Soil Liquefaction Risk Prediction
3.3. Soil Liquefaction Potential Index
4. Results and Discussion
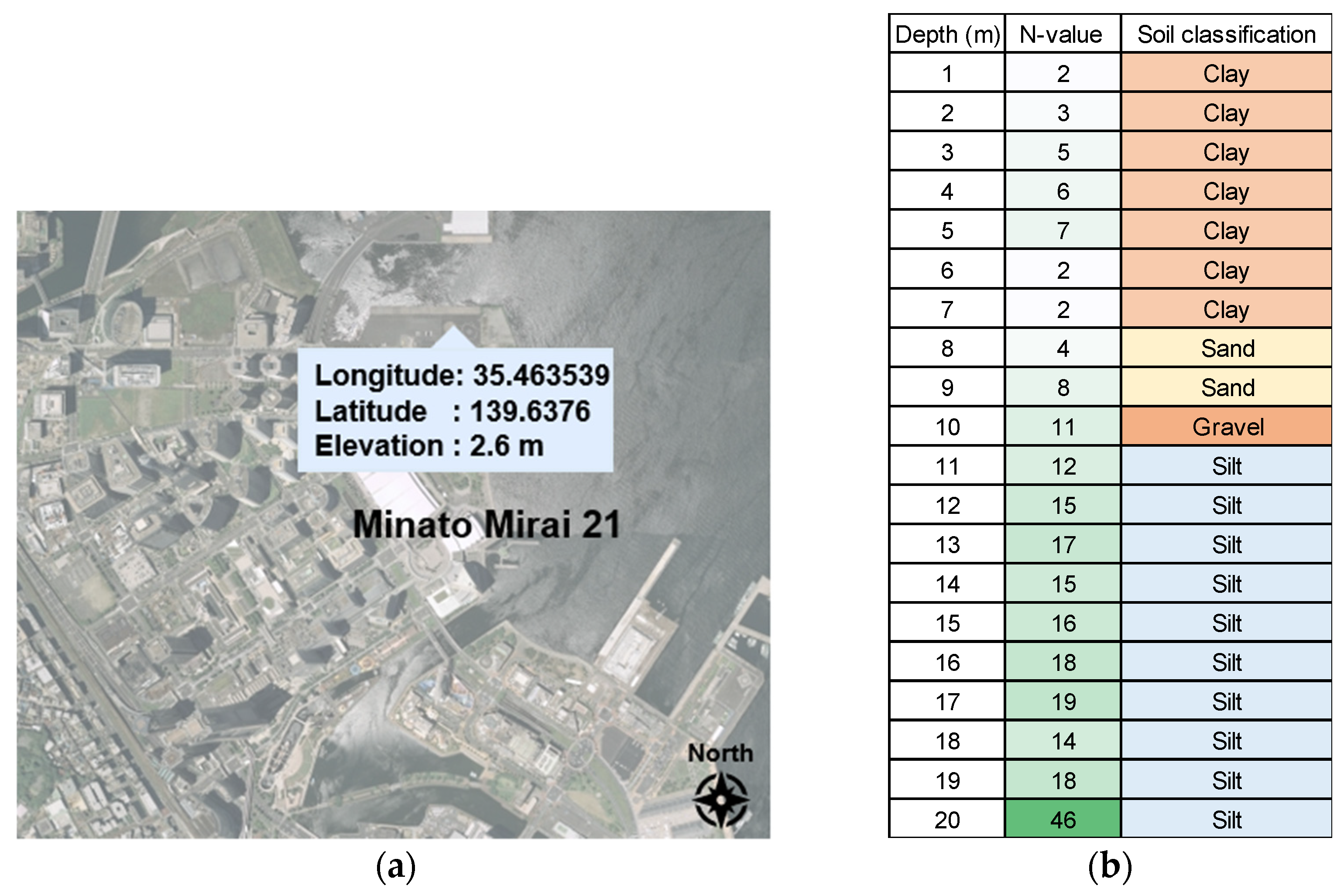
4.1. N-Values and Soil Classification Predictions
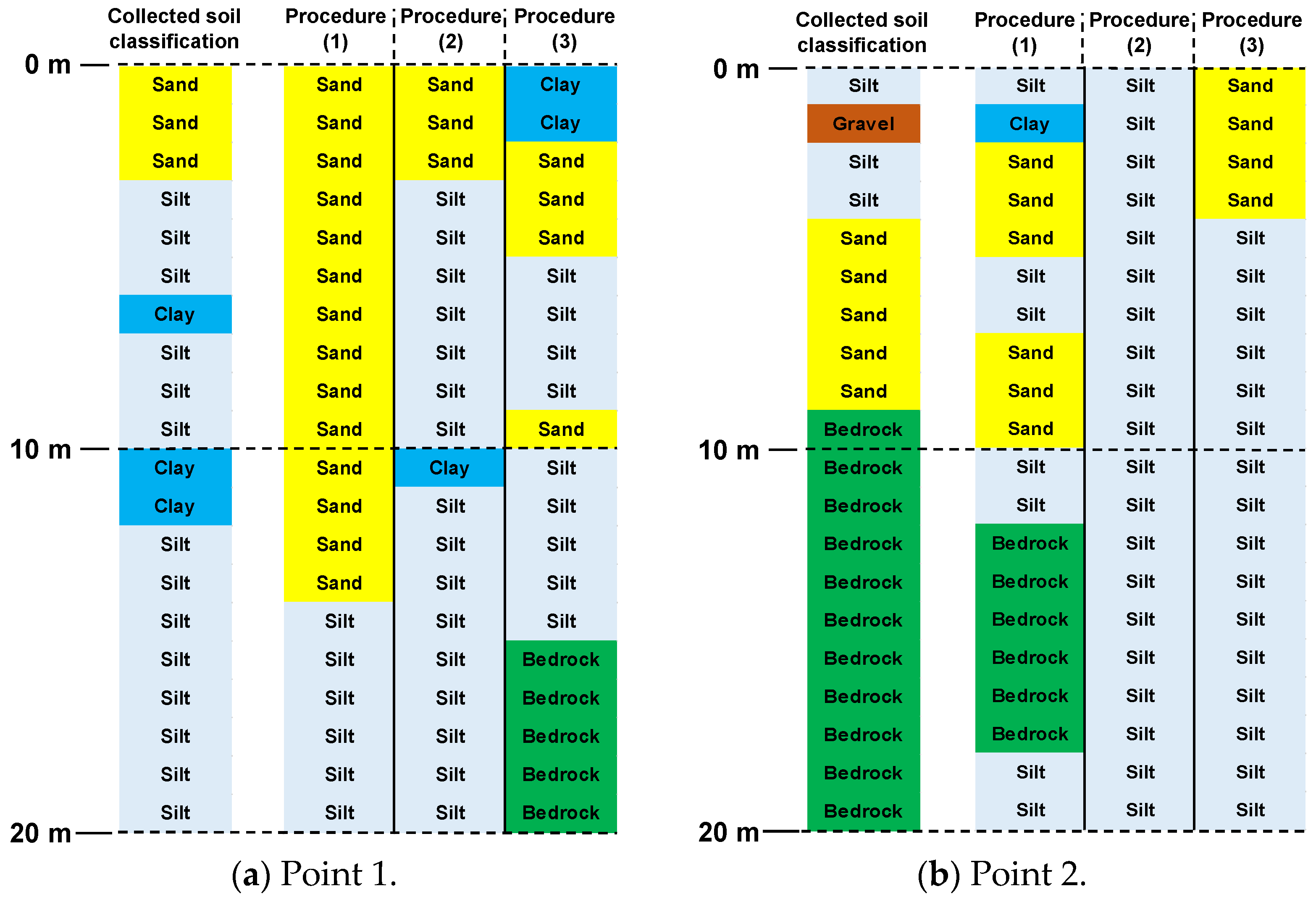
4.1.1. Case 1: Predictive Results for N-Value
- (1)
- A prediction procedure involving learning at every 1 m interval, without using the prediction results as data.
- (2)
- A prediction procedure that makes predictions at every 1 m interval from the ground surface to the subsurface, incorporating prediction results shallower than the predicted depth into the learning process.
- (3)
- A prediction procedure that makes predictions at every 1 m interval from 20 m below ground to the surface, incorporating prediction results deeper than the predicted depth into the learning process.
4.1.2. Case 2: Predictive Results of Soil Classification
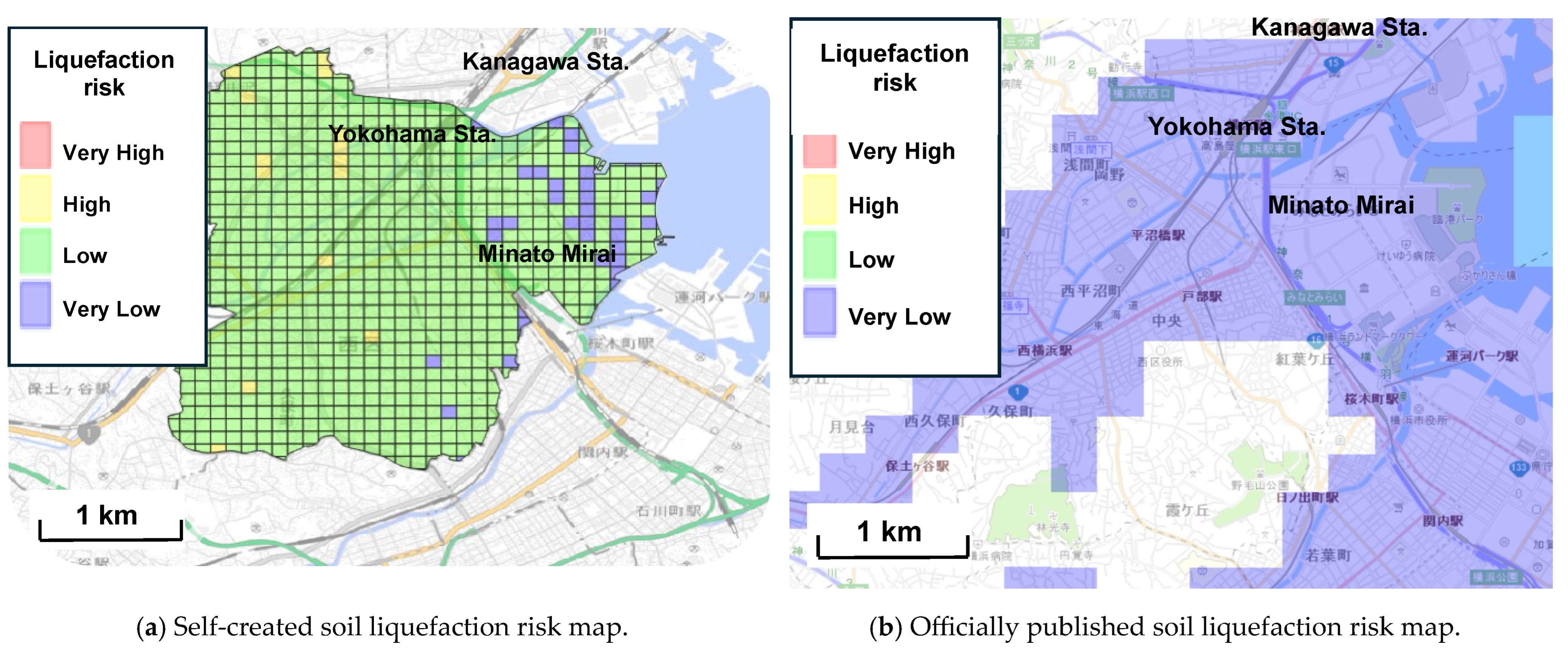
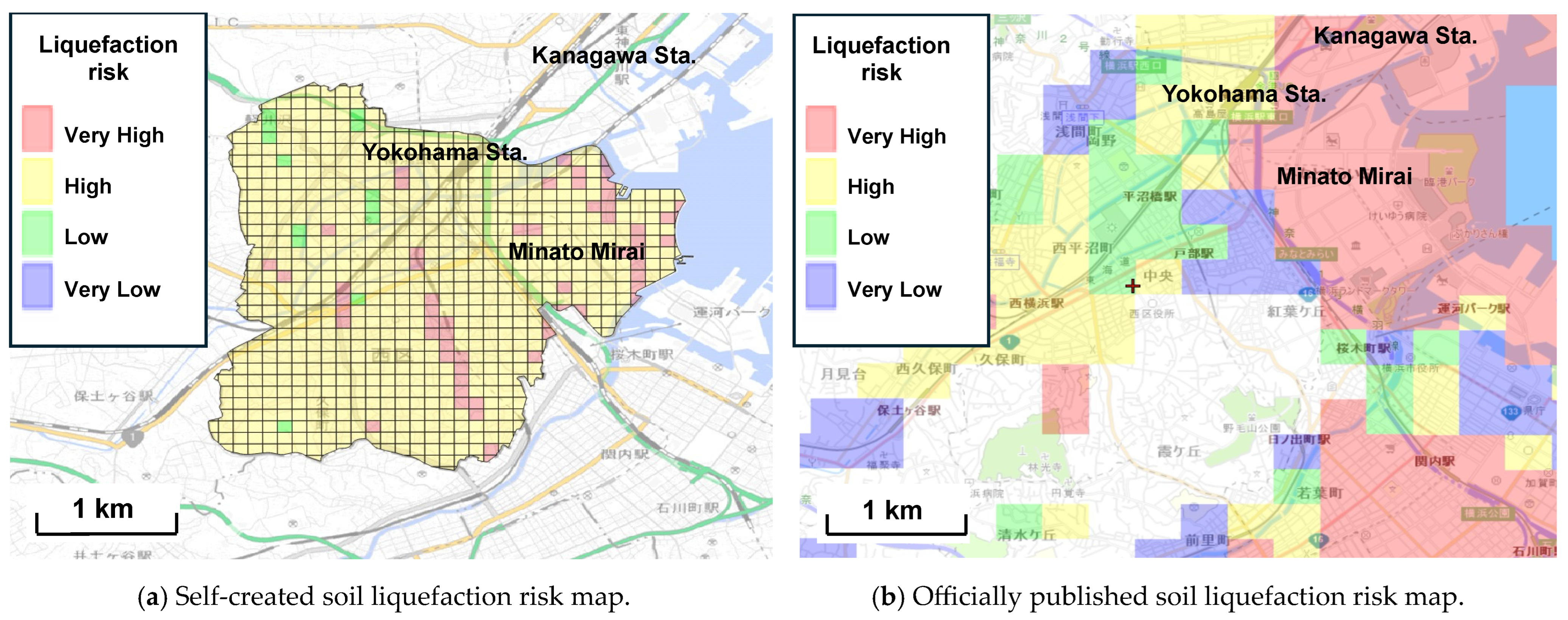
4.2. Creation of Soil Liquefaction Risk Mapping
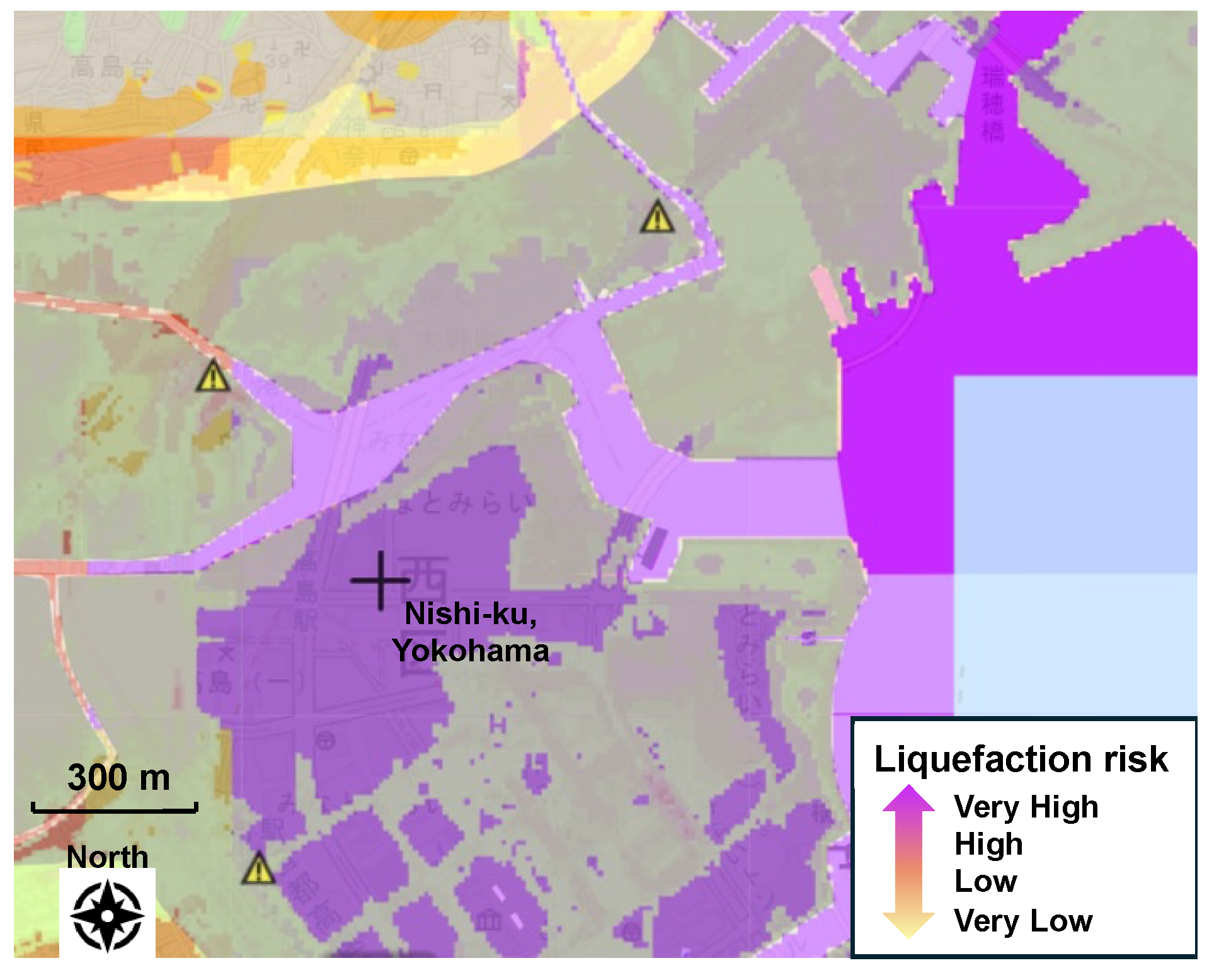
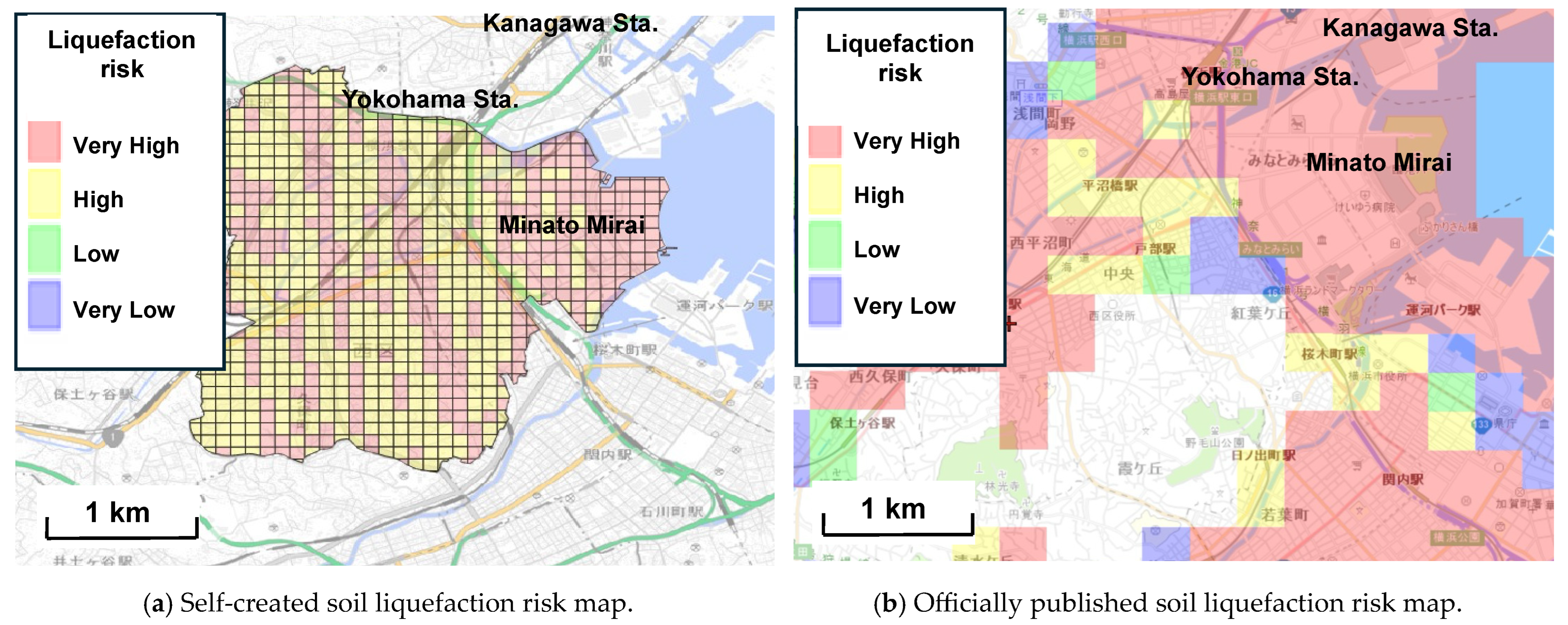
4.2.1. Comparison of Self-Created and Existing Soil Liquefaction Risk Maps
4.2.2. Advantage of Soil Liquefaction Risk Maps Created by AI-Driven Predictive Model
5. Conclusions
- (1)
- It was confirmed that the larger the training dataset used in the AI-driven predictive model, the higher the accuracy of the predictions.
- (2)
- The prediction procedure, which estimates the N-value and soil classification from 20 meters below ground to 1 meter above ground and incorporates learning from results deeper than the predicted depth, was found to be the most accurate.
- (3)
- The AI-driven predictive model provided more detailed soil liquefaction risk mapping for the seismic motion level compared to existing mappings.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Trindade, E.P.; Hinnig, M.P.F.; Costa, E.M.D.; Marques, J.S.; Bastos, R.C.; Yigitcanlar, T. Sustainable development of smart cities: A systematic review of the literature. J. Open Innov. Technol. Mark. Complex. 2017, 3, 1–14. [Google Scholar] [CrossRef]
- Sharifi, A.; Allam, Z.; Bibri, S.E.; Garmsir, A.R.K. Smart cities and sustainable development goals (SDGs): A systematic literature review of co-benefits and trade-offs. Cities 2024, 146, 104659. [Google Scholar] [CrossRef]
- Su, Y.; Fan, D. Smart cities and sustainable development. Reg. Stud. 2023, 57, 722–738. [Google Scholar] [CrossRef]
- Mishra, R.K.; Kumari, C.L.; Krishna, P.S.J.; Dubey, A. Smart cities for sustainable development: An overview. In Smart Cities for Sustainable Development; Springer: Singapore, 2022; pp. 1–12. [Google Scholar] [CrossRef]
- Ismagilova, E.; Hughes, L.; Dwivedi, Y.K.; Raman, K.R. Smart cities: Advances in research—An information systems perspective. Int. J. Inf. Manag. 2019, 47, 88–100. [Google Scholar] [CrossRef]
- Cugurullo, F.; Caprotti, F.; Cook, M.; Karvonen, A.; Guirk, P.M.; Marvin, S. The rise of AI urbanism in post-smart cities: A critical commentary on urban artificial intelligence. Urban Stud. 2024, 61, 1168–1182. [Google Scholar] [CrossRef]
- Cong, Y.; Inazumi, S. Integration of smart city technologies with advanced predictive analytics for geotechnical investigations. Smart Cities 2024, 7, 1089–1108. [Google Scholar] [CrossRef]
- Cong, Y.; Motohashi, T.; Nakao, K.; Inazumi, S. Machine learning predictive analysis of liquefaction resistance for sandy soils enhanced by chemical injection. Mach. Learn. Knowl. Extr. 2024, 6, 402–419. [Google Scholar] [CrossRef]
- Hazout, L.; Zitouni, Z.E.A.; Belkhatir, M.; Schanz, T. Evaluation of static liquefaction characteristics of saturated loose sand through the mean grain size and extreme grain sizes. Geotech. Geol. Eng. 2017, 35, 2079–2105. [Google Scholar] [CrossRef]
- Bao, X.; Ye, B.; Ye, G.; Zhang, F. Co-seismic and post-seismic behavior of a wall type breakwater on a natural ground composed of liquefiable layer. Nat. Hazards 2016, 83, 1799–1819. [Google Scholar] [CrossRef]
- Bao, X.; Jin, Z.; Cui, H.; Chen, X.; Xie, X. Soil liquefaction mitigation in geotechnical engineering: An overview of recently developed methods. Soil Dyn. Earthq. Eng. 2019, 120, 273–291. [Google Scholar] [CrossRef]
- Nakao, K.; Inazumi, S.; Takahashi, T.; Nontananandh, S. Numerical simulation of the liquefaction phenomenon by MPSM-DEM coupled CAEs. Sustainability 2022, 14, 7517. [Google Scholar] [CrossRef]
- Ishihara, K.; Araki, K.; Toshiyuki, K. Liquefaction in Tyoko Bay and Kano Regions in the 2011 Great East Japan Earthquake. Earthq. Geotech. Eng. Des. 2013, 28, 93–140. [Google Scholar]
- Wang, Z.Z.; Hu, Y.; Guo, X.F.; He, X.G.; Kek, H.; Ku, T.; Goh, S.H.; Leung, C.F. Predicting Geological Interfaces using Stacking Ensemble Learning with Multi-scale Features. Can. Geotech. J. 2022, 60, 1036–1054. [Google Scholar] [CrossRef]
- Kajihara, K.; Okuda, H.; Kiyota, T.; Konagai, K. Mapping of liquefaction risk on road network based on relationship between liquefaction potential and liquefaction-induced road subsidence. Soils Found. 2020, 60, 1202–1214. [Google Scholar] [CrossRef]
- Honda, K.; Takeyama, T.; Tachibana, S.; Iizuka, A. Liquefaction risk assessment in the 23 wards of Tyoko using elastoplastic analysis. Int. J. Geomate 2021, 21, 48–54. [Google Scholar] [CrossRef]
- Matsuoka, M.; Wakamatsu, K.; Hashimoto, M.; Midorikawa, S. Evaluation of liquefaction potential for large areas based on geomorphologic classification. Earthq. Spectra 2015, 31, 2375–2395. [Google Scholar] [CrossRef]
- Karimzadeh, S.; Matsuoka, M. A weighted overlay method for liquefaction-related urban damage detection: A case study of the 6 September 2018 Hokkaido eastern Iburi earthquake, Japan. Geosciences 2018, 8, 487. [Google Scholar] [CrossRef]
- Mishra, S.; Shaw, K.; Mishra, D.; Patil, S.; Kotecha, K.; Kumar, S.; Bajaj, S. Improving the accuracy of ensemble machine learning classification models using a novel bit-fusion algorithm for healthcare AI systems. Front. Public Health 2022, 10, 858282. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Z.L.; Li, X.W.; Zhang, J. Classifier selection and ensemble model for multi-class imbalance learning in education grants prediction. Appl. Artif. Intell. 2021, 35, 290–303. [Google Scholar] [CrossRef]
- Wu, H.; Levinson, D. The ensemble approach to forecasting: A review and synthesis. Transp. Res. Part C Emerg. Technol. 2022, 132, 103357. [Google Scholar] [CrossRef]
- Doroudi, S. The bias-variance tradeoff: How data science can inform educational debates. AERA Open 2020, 6, 4. [Google Scholar] [CrossRef]
- Ghosal, I.; Hooker, G. Boosting random forests to reduce bias; One-step boosted forest and its variance estimate. J. Comput. Graph. Stat. 2020, 30, 493–502. [Google Scholar] [CrossRef]
- Alelyani, S. Stable bagging feature selection on medical data. J. Big Data 2021, 8, 11. [Google Scholar] [CrossRef]
- Miemye, I.D.; Sun, Y. A Survey of ensemble learning: Concepts, algorithms, applications, and prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Ghnai, S.; Kumari, S.; Jaiswal, S.; Sawant, V.A. Comparative and parametric study of AI based models for risk assessment against soil liquefaction for high intensity earthquakes. Arab. J. Geosci. 2022, 15, 1262. [Google Scholar] [CrossRef]
- Zhong, L.; Guo, X.; Xu, Z.; Ding, M. Soil properties: Their prediction and feature extraction from the LUCAS spectral library using deep convolutional neural networks. Geoderma 2021, 402, 115366. [Google Scholar] [CrossRef]
- Pham, B.T.; Nguyen, M.D.; Ly, H.B.; Pham, T.A.; Hoang, V.; Le, V.H.; Le, T.T.; Nguyen, H.Q.; Bui, G.L. Development of artificial neural networks for prediction of compression coefficient of soft soil. In Proceedings of the 5th International Conference on Geotechnics 2020, Civil Engineering Works and Structures, Hanoi, Vietnam, 31 October–1 November 2019; Springer: Singapore, 2020; pp. 1167–1172. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide detection from an open satellite imagery and digital elevation model dataset using attention boosted convolutional neural networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Ghani, S.; Kumari, S. Liquefaction study of fine-grained soil using computational model. Innov. Infrastruct. Solut. 2021, 6, 58. [Google Scholar] [CrossRef]
- Ghani, S.; Kumari, S. Prediction of liquefaction using reliability-based regression analysis. In Advances in Geo-Science and Geo-Structures, Lecture Notes in Civil Engineering; Springer: Singapore, 2022; p. 154. [Google Scholar] [CrossRef]
- Zhang, Z.D.; Jung, C. GBDT-MO: Gradient-boosted decision trees for multiple outputs. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3156–3167. [Google Scholar] [CrossRef]
- Chekhaba, C.; Rebatchi, H.; ElBoussaidi, G.; Moha, N.; Kpodjedo, S. Coach: Classification-based architectural patterns detection in Android apps. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, Virtual Event, 22–26 March 2021; pp. 1429–1438. [Google Scholar] [CrossRef]
- Komolov, S.; Dlamini, G.; Megha, S.; Mazzara, M. Towards predicting architectural design patterns: A machine learning approach. Computers 2022, 11, 151. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ-Comput. Sci. 2021, 5, e623. [Google Scholar] [CrossRef] [PubMed]
- Shan, S.; Pei, X.; Zhan, W. Estimating deformation modulus and bearing capacity of deep soils from dynamic penetration test. Adv. Civ. Eng. 2021, 2021, 1082050. [Google Scholar] [CrossRef]
- Obara, H.; Maejima, Y.; Kohyaha, K.; Ohkura, T.; Takata, Y. Outline of the comprehensive soil classification system of Japan-first approximation. Jpn. Agric. Res. Quartely JARQ 2015, 49, 217–226. [Google Scholar] [CrossRef]
- Inazumi, S.; Intui, S.; Jotisankasa, A.; Chaiprakaikeow, S.; Kojima, K. Artificial intelligence system for supporting soil classification. Results Eng. 2020, 8, 100188. [Google Scholar] [CrossRef]
- Rahman, M.Z.; Siddiqua, S.; Kamal, A.S.M.M. Liquefaction hazard mapping by liquefaction potential index for Dhaka city, Bangladesh. Eng. Geol. 2015, 188, 137–147. [Google Scholar] [CrossRef]
- Wu, M.H.; Wang, J.P.; Wu, Y.J.; Chen, Z.B. Relationship between liquefaction potential index and liquefaction probability. J. GeoEngineering 2020, 15, 135–144. [Google Scholar] [CrossRef]
- Kajihara, K.; Pokhrel, R.M.; Kiyota, T.; Konagai, K. Liquefaction-induced ground subsidence extracted from digital surface models and its application to hazard map of Urayasu city, Japan. Soil Mech. Geotech. Eng. 2016, 2, 829–834. [Google Scholar] [CrossRef]
- Kiyota, T.; Ikeda, T.; Yokoyama, Y.; Kyokawa, H. Effect of in-situ sample quality on undrained cyclic strength and liquefaction assessment. Soils Found. 2016, 56, 691–703. [Google Scholar] [CrossRef]
- Imaide, K.; Nishimura, S.; Shibata, T.; Shuku, T.; Murakami, A.; Fujisawa, K. Evaluation of liquefaction probability of earth-fill dam over next 50 years using geostatistical method based on CPT. Soils Found. 2019, 59, 1758–1771. [Google Scholar] [CrossRef]
- Nakao, K.; Yamaguchi, H.; Hoshino, S.; Inazumi, S. Applicability of weighting method as measure for existing manholes against uplifting during liquefaction. Appl. Sci. 2022, 12, 3818. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coefficient and Variable Symbol | Explanation and Definition |
|---|---|
| Correction coefficient based on earthquake motion characteristics | |
| Liquefaction strength ratio | |
| N-value obtained from standard penetration test | |
| N-value converted to effective overburden pressure equivalent to 100 (kN/m2) | |
| Corrected N-value considering the effect of grain size | |
| Effective overburden pressure at depth from ground surface when performing standard penetration tests (kN/m2) | |
| Correction factor for N-value based on fine particle content | |
| Fine particle content (%) (Percentage of passing mass of soil particles with a particle size of 75 μm or less) | |
| 50% particle size (mm) | |
| Depth reduction factor of seismic shear stress ratio | |
| Design horizontal seismic intensity of the ground surface used to assess liquefaction (rounded to two decimal places) | |
| Regional correction factor (Yokohama is 1.0) | |
| Standard value of horizontal seismic intensity for design of ground surface used to judge liquefaction | |
| Total overburden pressure at depth x from ground surface (kN/m2) | |
| Effective overburden pressure at depth x from ground surface (kN/m2) | |
| Depth from ground surface (m) |
| Type of Site | Level 1 Earthquake Motion | Level 2 Earthquake Motion | |
|---|---|---|---|
| Type I | Type II | ||
| Site I | 0.12 | 0.5 | 0.8 |
| Site II | 0.15 | 0.45 | 0.7 |
| Site III | 0.18 | 0.4 | 0.6 |
| Soil Classification | Unit Weight of Soil Below Groundwater Table (kN/m3) | Unit Weight of Soil Above Groundwater Table (kN/m3) | FC (%) |
|---|---|---|---|
| Clay | 13 | 15 | 80 |
| Silt | 15.5 | 17.5 | 75 |
| Sand | 18 | 20 | 10 |
| Gravel | 19 | 21 | 0 |
| Bedrock | 20 | 20 | 5 |
| 0 < LPI < 5 | 0 < LPI < 15 | 15 < LPI < 30 | LPI > 30 | |
|---|---|---|---|---|
| Liquefaction risk | Very low | Low | High | Very high |
| (a) Model 1. | (b) Model 2. | ||||
|---|---|---|---|---|---|
| Depth (m) | Coefficient of Determination (R2) | Root Mean Square Error (RMSE) | Depth (m) | Coefficient of Determination (R2) | Root Mean Square Error (RMSE) |
| 1 | 0.0114 | 7.32 | 1 | 0.0720 | 6.38 |
| 2 | 0.0487 | 6.22 | 2 | 0.0695 | 7.67 |
| 3 | 0.0254 | 8.82 | 3 | 0.4005 | 8.65 |
| 4 | 0.2626 | 6.61 | 4 | 0.7248 | 6.18 |
| 5 | 0.2086 | 8.15 | 5 | 0.7445 | 7.00 |
| 6 | 0.4704 | 8.31 | 6 | 0.4879 | 11.13 |
| 7 | 0.2557 | 8.92 | 7 | 0.5324 | 12.09 |
| 8 | 0.6190 | 8.39 | 8 | 0.8231 | 8.23 |
| 9 | 0.7429 | 8.52 | 9 | 0.8096 | 9.21 |
| 10 | 0.6894 | 9.90 | 10 | 0.5211 | 15.14 |
| 11 | 0.6581 | 11.14 | 11 | 0.8628 | 8.29 |
| 12 | 0.9339 | 5.44 | 12 | 0.9112 | 6.80 |
| 13 | 0.9097 | 6.71 | 13 | 0.9518 | 5.72 |
| 14 | 0.9030 | 7.04 | 14 | 0.8981 | 7.46 |
| 15 | 0.9085 | 7.21 | 15 | 0.9314 | 6.18 |
| 16 | 0.8915 | 7.91 | 16 | 0.9763 | 3.63 |
| 17 | 0.9458 | 5.63 | 17 | 0.9379 | 5.90 |
| 18 | 0.8969 | 7.74 | 18 | 0.9130 | 6.87 |
| 19 | 0.8924 | 7.89 | 19 | 0.9168 | 6.73 |
| 20 | 0.8083 | 10.52 | 20 | 0.9063 | 7.11 |
| (a) Model 1. | (b) Model 2. | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Depth (m) | Accuracy (%) | Average Precision (%) | Average Recall (%) | F-Measure (%) | Depth (m) | Accuracy | Average Precision (%) | Average Recall (%) | F-Measure (%) |
| 1 | 90.10 | 77.38 | 55.65 | 75.19 | 1 | 79.34 | 77.61 | 61.77 | 79.34 |
| 2 | 87.13 | 84.49 | 53.85 | 72.65 | 2 | 81.13 | 81.62 | 62.59 | 82.32 |
| 3 | 85.15 | 80.69 | 60.98 | 80.65 | 3 | 79.44 | 79.53 | 49.67 | 81.03 |
| 4 | 88.89 | 91.97 | 77.7 | 82.91 | 4 | 86.45 | 85.92 | 66.89 | 84.22 |
| 5 | 84.16 | 81.9 | 80.06 | 80.8 | 5 | 84.91 | 82.12 | 78.82 | 79.6 |
| 6 | 86.14 | 87.34 | 82.8 | 84.65 | 6 | 85.92 | 82.86 | 67.55 | 83.57 |
| 7 | 84.00 | 79.43 | 79.66 | 79.50 | 7 | 82.71 | 60.26 | 62.21 | 76.51 |
| 8 | 86.00 | 76.32 | 70.86 | 71.89 | 8 | 84.58 | 80.01 | 64.47 | 79.93 |
| 9 | 86.00 | 76.32 | 70.86 | 71.89 | 9 | 84.51 | 78.93 | 65.76 | 79.75 |
| 10 | 75.25 | 74.73 | 59.96 | 61.92 | 10 | 85.51 | 78.17 | 75.29 | 75.99 |
| 11 | 87.13 | 81.13 | 71.12 | 73.64 | 11 | 93.46 | 92.19 | 88.94 | 90.35 |
| 12 | 85.15 | 82.01 | 75.21 | 77.56 | 12 | 88.79 | 85.85 | 84.88 | 84.9 |
| 13 | 93.07 | 87.65 | 80.89 | 82.62 | 13 | 88.79 | 93.64 | 97.12 | 69.8 |
| 14 | 93.00 | 94.84 | 79.84 | 83.64 | 14 | 94.34 | 92.05 | 80.54 | 84.13 |
| 15 | 93.94 | 95.96 | 75 | 77.92 | 15 | 94.84 | 97.29 | 76.71 | 82.83 |
| 16 | 91.00 | 93.47 | 56.27 | 77.47 | 16 | 95.33 | 86.63 | 71.23 | 87.76 |
| 17 | 94.74 | 91.03 | 91.63 | 91.25 | 17 | 94.31 | 85.97 | 82.56 | 83.92 |
| 18 | 84.16 | 67.23 | 52.86 | 72.31 | 18 | 94.37 | 91.73 | 76.38 | 93.48 |
| 19 | 88.12 | 93.91 | 60.61 | 64.81 | 19 | 96.26 | 96.25 | 95.46 | 95.81 |
| 20 | 87.13 | 86.35 | 60.08 | 64.26 | 20 | 95.79 | 95.94 | 92.95 | 94.33 |
| Advantage | Description |
|---|---|
| Dynamic Updates | The AI-driven predictive model can continuously update and refine predictions as new data become available, which is critical in rapidly changing urban areas. |
| Adaptability | The AI-driven predictive model adapts to changes in the urban landscape, such as construction and land use changes, maintaining the accuracy and relevance of risk maps. |
| Complex Data Analysis | The ability of the AI-driven predictive model to process large data sets enables the analysis of complex variables and interactions, providing more detailed and comprehensive risk assessments. |
| Emergency Preparedness | The AI-driven predictive model guides emergency planning and response efforts, improving resource allocation and response times during seismic events. |
| Proactive City Planning | Prediction of potential liquefaction zones helps to avoid building in high-risk areas or to implement special construction techniques to mitigate risk. |
| Support for Smart Cities | Integrates with smart city goals to improve sustainability, safety, and quality of life by applying advanced technology to urban planning. |
| Enhanced Urban Resilience | Improves resilience to earthquakes and seismic activity, contributing to safer and more sustainable urban environments. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Katsuumi, A.; Cong, Y.; Inazumi, S. AI-Driven Prediction and Mapping of Soil Liquefaction Risks for Enhancing Earthquake Resilience in Smart Cities. Smart Cities 2024, 7, 1836-1856. https://doi.org/10.3390/smartcities7040071
Katsuumi A, Cong Y, Inazumi S. AI-Driven Prediction and Mapping of Soil Liquefaction Risks for Enhancing Earthquake Resilience in Smart Cities. Smart Cities. 2024; 7(4):1836-1856. https://doi.org/10.3390/smartcities7040071
Chicago/Turabian StyleKatsuumi, Arisa, Yuxin Cong, and Shinya Inazumi. 2024. "AI-Driven Prediction and Mapping of Soil Liquefaction Risks for Enhancing Earthquake Resilience in Smart Cities" Smart Cities 7, no. 4: 1836-1856. https://doi.org/10.3390/smartcities7040071