
Utilizing Deep Neural Networks for Chrysanthemum Leaf and Flower Feature Recognition




Abstract
:1. Introduction
2. Materials and Methods
2.1. Plant-Consuming Materials and Input Process
2.2. Data Processing
2.3. Extracted Features
2.3.1. Color Feature
2.3.2. Shape Feature
2.3.3. Texture Feature
2.4. SVM Input Vector and MLP Input Vector
2.4.1. SVM Input Vector
2.4.2. MLP Input Vector
2.5. Training and Prediction Model
2.6. AI Support Tools for Manuscript Construction
3. Results and Discussion
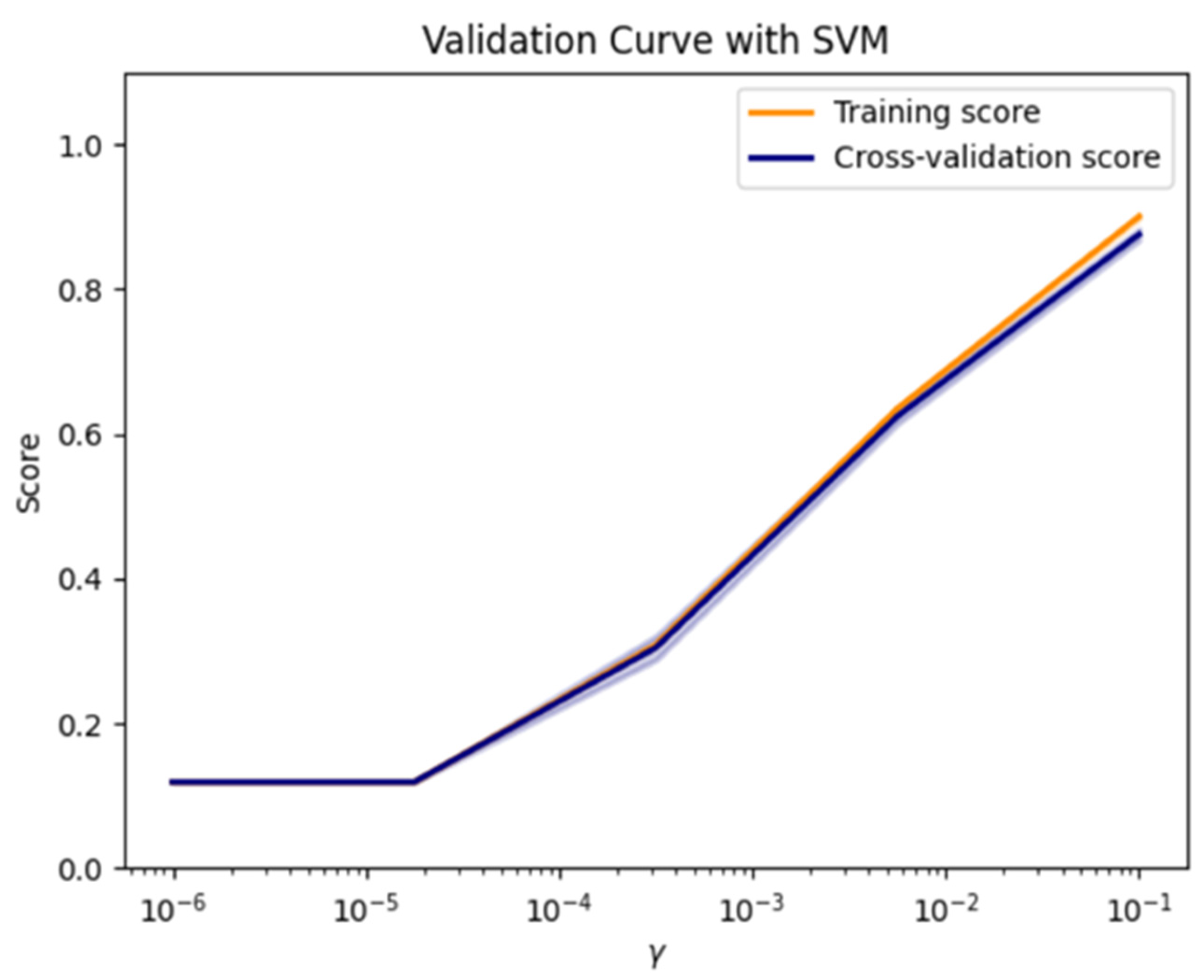
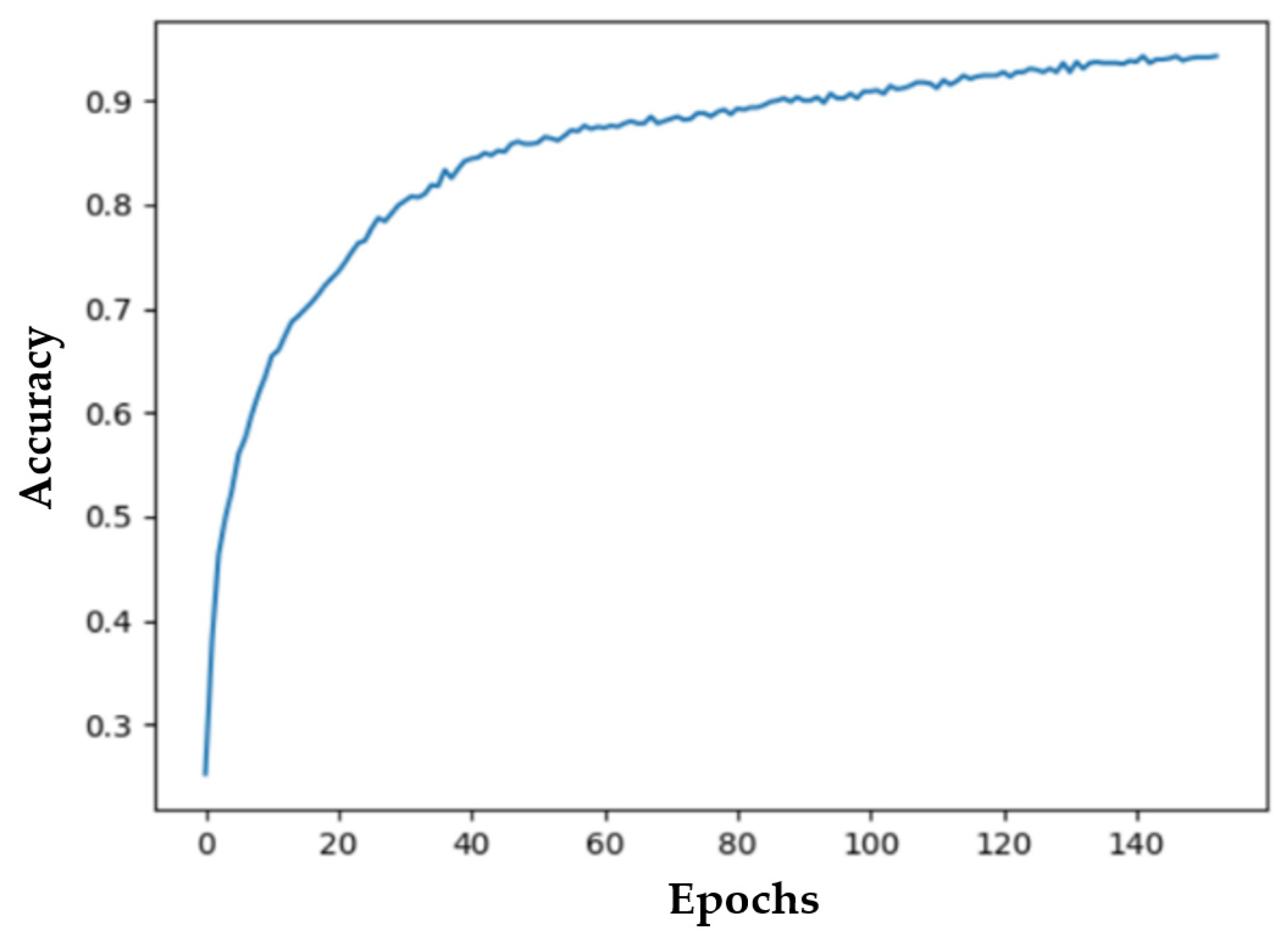
3.1. Training Results
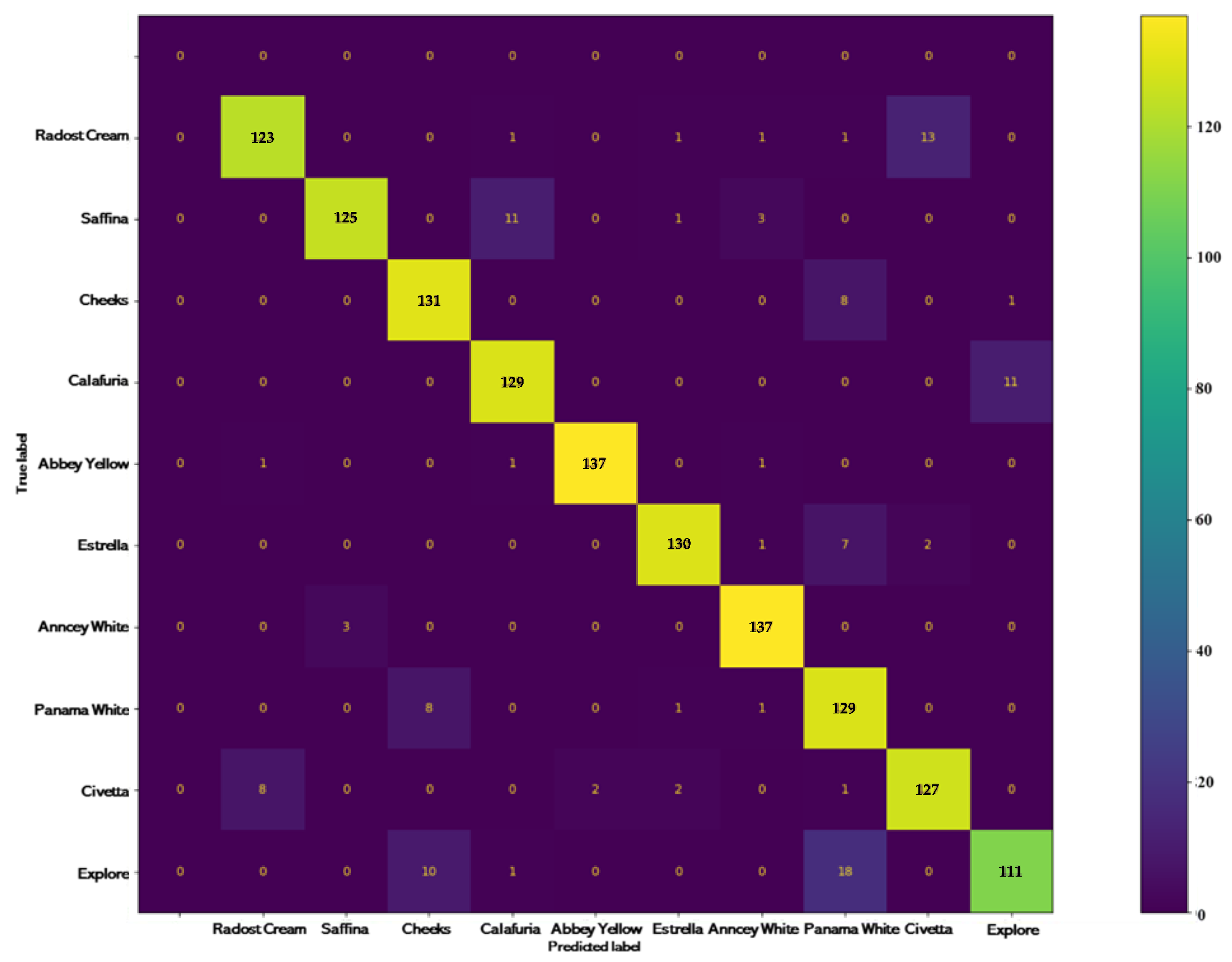
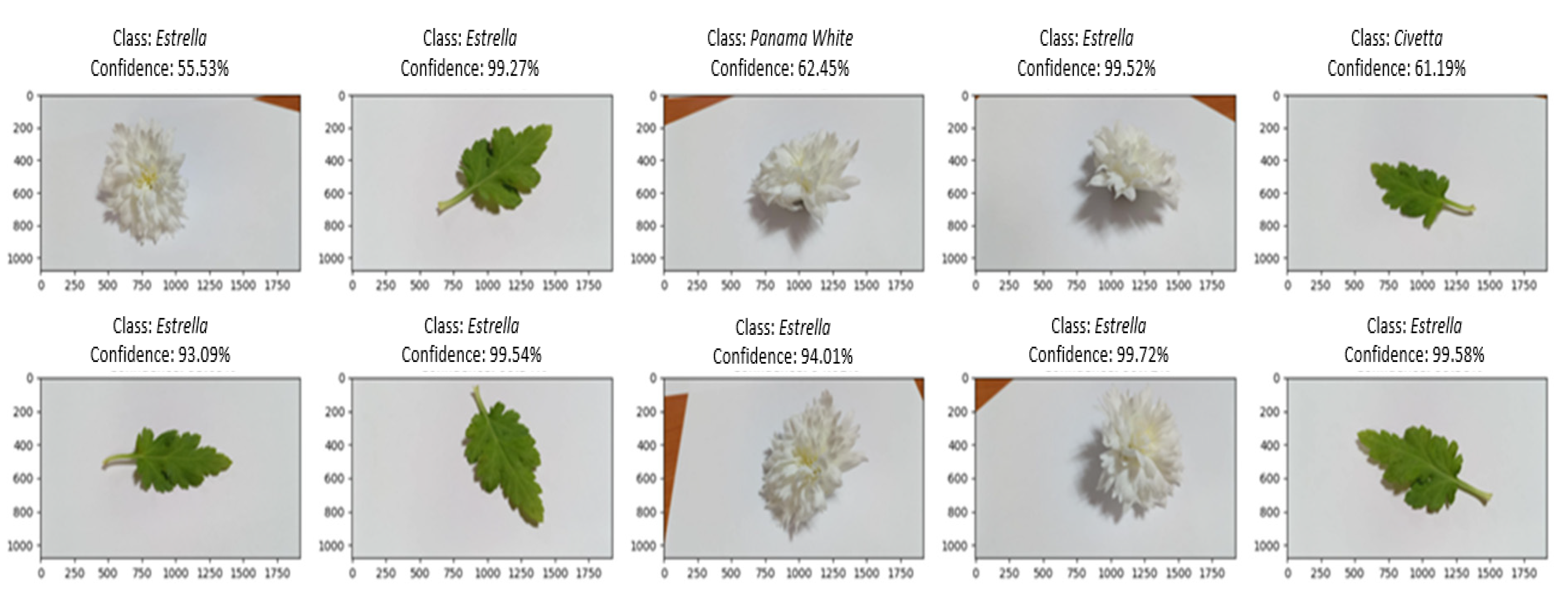
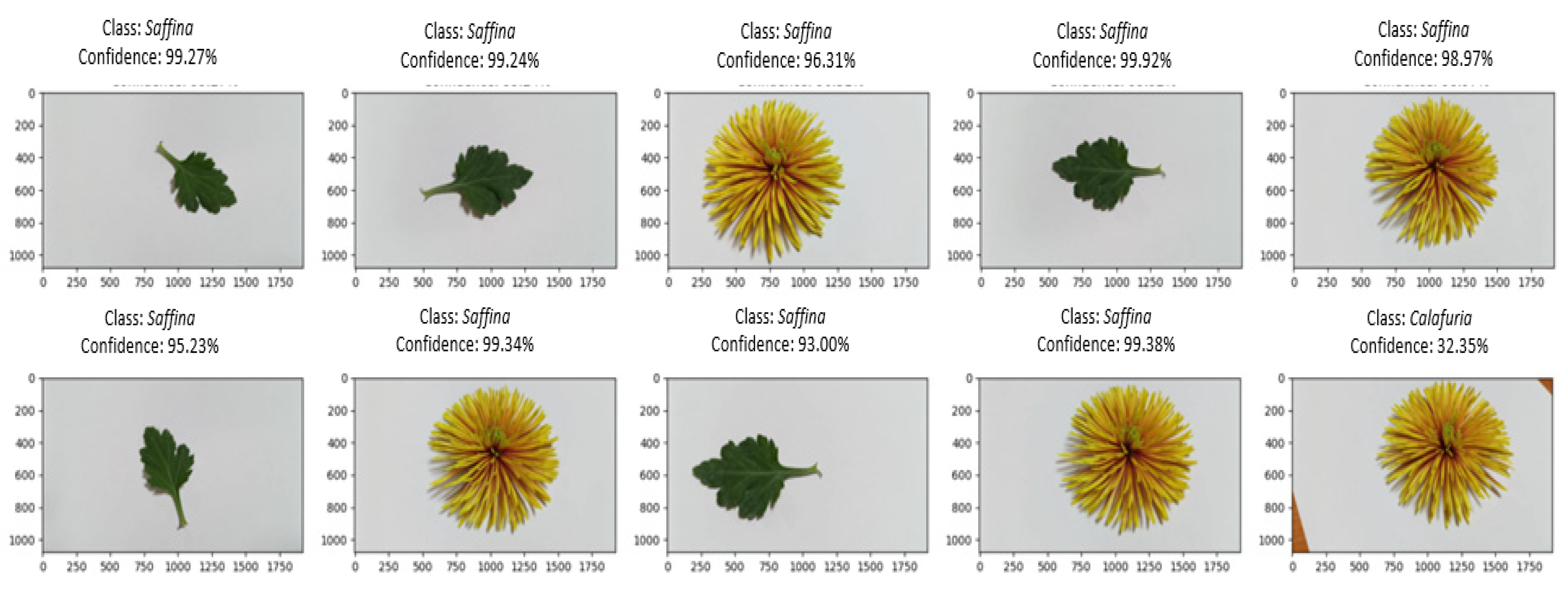
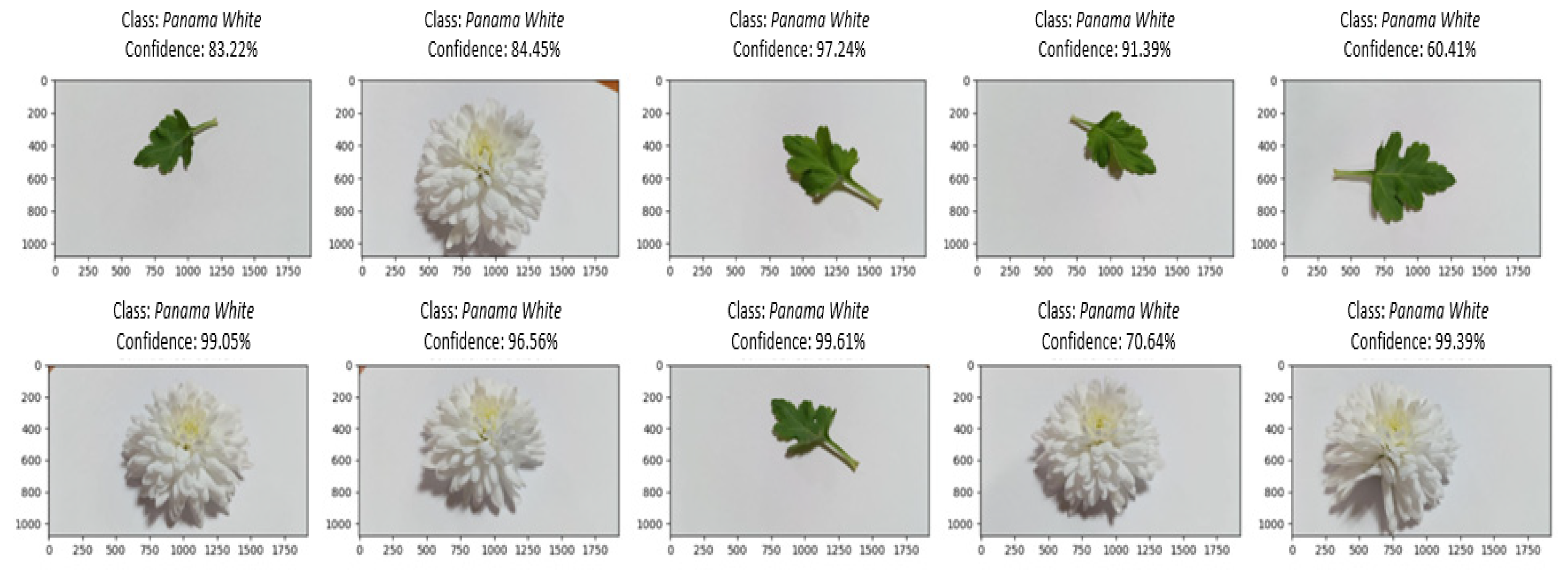
3.2. Testing Results
- Abbey Yellow and Anncey White: The model displayed outstanding performance with classification accuracy exceeding 97% for both Abbey Yellow and Anncey White cultivars in both leaf and flower recognition. Additionally, it demonstrated a high accuracy rate of 99% in identification only, underscoring its robustness in effectively discerning between the flower and leaf characteristics associated with these cultivars.
- Cheeks, Calafuria, Estrella, and Panama White: These cultivars also showed strong classification accuracy, with rates over 92% in the recognition of leaves and flowers. However, slight decreases in classification accuracy rates were noted up to 5% in the cultivars Calafuria (only leaves—decreasing 1.63%), Cheeks cultivar (only leaves—decreasing 5.55%), and Panama White (only leaves—decreasing 0.97%). Notably, in the case of Estrella, the accuracy rate for leaf identification in the leaves-only dataset is higher than both leaf and flower identification. This suggests that the model is proficient in discerning the distinctive traits of these cultivars, encompassing both leaf and flower characteristics.
- Civetta, Radost Cream, and Saffina: These cultivars displayed encouraging performance, with a classification accuracy of over 87% in leaves and flower identification. Especially when using only leaves for identification, these cultivars have high classification accuracy, followed by Civetta (increasing 0.65%), Radost Cream (increasing 2.26%), and Saffina (increasing 8.02%). While not as high as the top-performing cultivars, the model was still successful in distinguishing their features.
- Explore: The Explore cultivar yielded an acceptable rate with a classification accuracy of 71.18% within only leaves, and the accuracy classification increased up to 79.29% with both leaves and flowers recognition, indicating the model’s proficiency in acceptably categorizing both flowers and leaves.
3.3. Comparison with Other Models
4. Conclusions
- (i)
- The establishment of a well-defined criterion for constructing the repetitive system allows for network refinement until saturation is achieved, thus minimizing diminishing returns in performance gains. Additionally, strategies for effective training across a diverse spectrum of flower colors should be explored;
- (ii)
- The implementation of an expanded data collection approach to encompass the recognition of over twenty distinct cultivars. This extension of the dataset would facilitate more robust and comprehensive disease identification capabilities.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nguyen, T.K.; Dang, L.M.; Song, H.-K.; Moon, H.; Lee, S.J.; Lim, J.H. Wild chrysanthemums core collection: Studies on leaf identification. Horticulturae 2022, 8, 839. [Google Scholar] [CrossRef]
- Yan, W.; Li, J.H.; Jung, J.A.; Kim, W.H.; Lim, K.-B.; Cabahug, R.M.; Hwang, Y.-J. Analysis of ploidy levels of Korean wild Asteraceae species using chromosome counting. Flower Res. J. 2019, 27, 278–284. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, Z.; Li, T.; Chen, N.; Xu, W.; Liu, S. Surface-enhanced Raman scattering spectra revealing the inter-cultivar differences for Chinese ornamental Flos Chrysanthemum: A new promising method for plant taxonomy. Plant Methods 2017, 13, 92. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Luo, X.-Y.; Zhu, J.; Wang, C.; Hong, Y.; Lu, J.; Liu, Q.-Q.; Li, B.-Q.; Zhu, M.-L.; Wang, Z.-F. A classification study for chrysanthemum (Chrysanthemum × grandiflorum Tzvelv.) cultivars based on multivariate statistical analyses. J. Syst. Evol. 2014, 52, 612–628. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, M.-L.; Dai, S.-L. Analysis of karyotype diversity of 40 Chinese chrysanthemum cultivars. J. Syst. Evol. 2013, 51, 335–352. [Google Scholar] [CrossRef]
- Luo, C.; Chen, D.; Cheng, X.; Liu, H.; Li, Y.; Huang, C. SSR Analysis of genetic relationship and classification in chrysanthemum germplasm collection. Hortic. Plant J. 2018, 4, 73–82. [Google Scholar] [CrossRef]
- Dang, L.M.; Wang, H.; Li, Y.; Min, K.; Kwak, J.T.; Lee, O.N.; Park, H.; Moon, H. Fusarium wilt of radish detection using RGB and near infrared images from Unmanned Aerial Vehicles. Remote Sens. 2020, 12, 2863. [Google Scholar] [CrossRef]
- Nguyen, T.N.; Lee, S.; Nguyen-Xuan, H.; Lee, J. A novel analysis-prediction approach for geometrically nonlinear problems using group method of data handling. Comput. Methods Appl. Mech. Eng. 2019, 354, 506–526. [Google Scholar] [CrossRef]
- Rumpf, T.; Mahlein, A.K.; Steiner, U.; Oerke, E.C.; Dehne, H.W.; Plümer, L. Early detection and classification of plant diseases with Support Vector Machines based on hyperspectral reflectance. Comput. Electron. Agric. 2010, 74, 91–99. [Google Scholar] [CrossRef]
- He, X.; Chen, Y. Modifications of the Multi-Layer Perceptron for hyperspectral image classification. Remote Sens. 2021, 13, 3547. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Agarwal, R.; Verma, O.P. Image splicing detection using hybrid feature extraction. In Advances in Mechanical Engineering; Springer: Singapore, 2021; pp. 663–672. [Google Scholar]
- Humeau-Heurtier, A. Texture feature extraction methods: A survey. IEEE Access 2019, 7, 8975–9000. [Google Scholar] [CrossRef]
- Iqbal, N.; Mumtaz, R.; Shafi, U.; Zaidi, S.M.H. Gray level co-occurrence matrix (GLCM) texture based crop classification using low altitude remote sensing platforms. PeerJ Comput. Sci. 2021, 7, e536. [Google Scholar] [CrossRef] [PubMed]
- Bambil, D.; Pistori, H.; Bao, F.; Weber, V.; Alves, F.M.; Gonçalves, E.G.; de Alencar Figueiredo, L.F.; Abreu, U.G.P.; Arruda, R.; Bortolotto, I.M. Plant species identification using color learning resources, shape, texture, through machine learning and artificial neural networks. Environ. Syst. Decis. 2020, 40, 480–484. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Mika, S.; Burges, C.; Knirsch, P.; Muller, K.; Ratsch, G.; Smola, A. Input space versus feature space in kernel-based methods. IEEE Trans. Neural Netw. 1999, 10, 1000–1017. [Google Scholar]
- Burges, C.J.; Schölkopf, B. Improving the accuracy and speed of support vector machines. Adv. Neural Inf. Process. Syst. 1996, 9, 375–381. [Google Scholar]
- Schölkopf, B.; Burges, C.J.; Smola, A.J. Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Song, X.; Xu, Y.; Gao, K.; Fan, G.; Zhang, F.; Deng, C.; Dai, S.; Huang, H.; Xin, H.; Li, Y. High-density genetic map construction and identification of loci controlling flower-type traits in Chrysanthemum (Chrysanthemum × morifolium Ramat.). Hortic. Res. 2020, 7, 108. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.-P.; Zhao, L.; Zhang, W.-J.; Zhang, Y.-H.; Xing, X.; Duan, X.-X.; Hu, J.; Harris, A.; Liu, P.-L.; Dai, S.-L.; et al. Origins of cultivars of Chrysanthemum—Evidence from the chloroplast genome and nuclear LFY gene. J. Syst. Evol. 2020, 58, 925–944. [Google Scholar] [CrossRef]
- Gao, K.; Song, X.; Kong, D.; Dai, S. Genetic analysis of leaf traits in small-flower chrysanthemum (Chrysanthemum × morifolium Ramat.). Agronomy 2020, 10, 697. [Google Scholar] [CrossRef]
- Hodaei, M.; Rahimmalek, M.; Arzani, A. Variation in morphological characters, chemical composition, and anthocyanin content of different Chrysanthemum morifolium cultivars from Iran. Biochem. Syst. Ecol. 2017, 74, 1–10. [Google Scholar] [CrossRef]
- Song, X.; Gao, K.; Fan, G.; Zhao, X.; Liu, Z.; Dai, S. Quantitative classification of the morphological traits of ray florets in large-flowered chrysanthemum. HortScience 2018, 53, 1258–1265. [Google Scholar] [CrossRef]
- Fanourakis, D.; Kazakos, F.; Nektarios, P.A. Allometric individual leaf area estimation in chrysanthemum. Agronomy 2021, 11, 795. [Google Scholar] [CrossRef]
- Hoang, T.K.; Wang, Y.; Hwang, Y.-J.; Lim, J.-H. Analysis of the morphological characteristics and karyomorphology of wild Chrysanthemum species in Korea. Hortic. Environ. Biotechnol. 2020, 61, 359–369. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, F.-J.; Chen, F.-D.; Fang, W.-M.; Teng, N.-J. Identification of chrysanthemum (Chrysanthemum morifolium) self-incompatibility. Sci. World J. 2014, 2014, 625658. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Wang, J.; Tian, Y.; Dai, S. Deep learning for image-based large-flowered chrysanthemum cultivar recognition. Plant Methods 2019, 15, 146. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Lu, W.; Gao, B.; Kimura, H.; Li, Y.; Wang, J. Rapid identification of chrysanthemum teas by computer vision and deep learning. Food Sci. Nutr. 2020, 8, 1968–1977. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Brown, D.; Gao, Y.; Salle, J.L. Mobile plant leaf identification using smart-phones. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 4417–4421. [Google Scholar]
- Sun, Y.; Liu, Y.; Wang, G.; Zhang, H. Deep learning for plant identification in natural environment. Comput. Intell. Neurosci. 2017, 2017, 7361042. [Google Scholar] [CrossRef]
- Prasad, S.; Kumar, P.S.; Ghosh, D. An efficient low vision plant leaf shape identification system for smart phones. Multimed. Tools Appl. 2017, 76, 6915–6939. [Google Scholar] [CrossRef]
- Yuan, P.; Ren, S.; Xu, H.; Chen, J. Chrysanthemum abnormal petal type classification using random forest and over-sampling. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 275–278. [Google Scholar] [CrossRef]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of image classification algorithms based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Tian, Z.; Zhang, F. 2D and 3D object detection algorithms from images: A Survey. Array 2023, 19, 100305. [Google Scholar] [CrossRef]
- Huang, Z.; Su, L.; Wu, J.; Chen, Y. Rock image classification based on EfficientNet and Triplet Attention Mechanism. Appl. Sci. 2023, 13, 3180. [Google Scholar] [CrossRef]
- Chen, Y.; Sharifuzzaman, S.-A.-S.-M.; Wang, H.; Li, Y.; Dang, L.-M.; Song, H.-K.; Moon, H. Deep learning based underground sewer defect classification using a modified RegNet. Comput. Mater. Contin. 2023, 75, 5455–5473. [Google Scholar] [CrossRef]
- Liang, H.; Song, T. Lightweight marine biological target detection algorithm based on YOLOv5. Front. Mar. Sci. 2023, 10, 1219155. [Google Scholar] [CrossRef]
- Nergiz, M. Analysis of RepVGG on small sized Dandelion images dataset in terms of transfer learning, regularization, spatial attention as well as Squeeze and Excitation Blocks. In Proceedings of the 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 378–382. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cultivar | Flower Color | Flower Type |
|---|---|---|
| Abbey Yellow | Yellow | Double |
| Anncey White | White | Spider Anemonae |
| Calafuria | Orange | Spider Double |
| Cheeks | Pink | Pompon |
| Civetta | Green | Double |
| Estrella | White | Double |
| Explore | Red | Single |
| Panama White | White | Double |
| Radost Cream | Cream | Anemonae |
| Saffina | Yellow + Orange | Spider Double |
| Cultivar | Part | Training Set | Validation Set | Total |
|---|---|---|---|---|
| Abbey Yellow | Flower | 180 | 46 | 226 |
| Leaf | 192 | 48 | 240 | |
| Anncey White | Flower | 214 | 54 | 268 |
| Leaf | 181 | 46 | 227 | |
| Calafuria | Flower | 192 | 46 | 238 |
| Leaf | 206 | 52 | 258 | |
| Cheeks | Flower | 184 | 47 | 231 |
| Leaf | 188 | 48 | 236 | |
| Civetta | Flower | 223 | 56 | 279 |
| Leaf | 196 | 49 | 245 | |
| Estrella | Flower | 186 | 47 | 233 |
| Leaf | 176 | 45 | 221 | |
| Explore | Flower | 186 | 47 | 233 |
| Leaf | 184 | 46 | 230 | |
| Panama White | Flower | 194 | 49 | 243 |
| Leaf | 186 | 47 | 233 | |
| Radost Cream | Flower | 188 | 47 | 235 |
| Leaf | 196 | 50 | 246 | |
| Saffina | Flower | 197 | 50 | 247 |
| Leaf | 183 | 46 | 229 | |
| Total | Flower | 1944 | 489 | 2433 |
| Leaf | 1888 | 477 | 2365 |
| Cultivar | Classification Accuracy Rate | |
|---|---|---|
| Only Leaves | Leaves and Flowers | |
| Abbey Yellow | 99.91% | 97.86% |
| Anncey White | 99.89% | 97.86% |
| Calafuria | 90.51% | 92.14% |
| Cheeks | 88.02% | 93.57% |
| Civetta | 91.36% | 90.71% |
| Estrella | 95.76% | 92.86% |
| Explore | 71.18% | 79.29% |
| Panama White | 91.84% | 92.81% |
| Radost Cream | 90.12% | 87.86% |
| Saffina | 97.31% | 89.29% |
| Model | Accuracy | Precision | Recall |
|---|---|---|---|
| ANN [34] | 89.8% | 89.3% | 93.5% |
| PVT [35] | 87.5% | 85.2% | 89.6% |
| EfficientNet v2 [36] | 90.5% | 91.4% | 92.3% |
| GoogLeNet [37] | 91.4% | 92.6% | 92.2% |
| RepVGG [38,39] | 90.3% | 94.5% | 91.8% |
| SVM [1] | 92.1% | 94.2% | 93.5% |
| MLP [10] | 93.9% | 95.3% | 94.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.K.; Dang, M.; Doan, T.T.M.; Lim, J.H. Utilizing Deep Neural Networks for Chrysanthemum Leaf and Flower Feature Recognition. AgriEngineering 2024, 6, 1133-1149. https://doi.org/10.3390/agriengineering6020065
Nguyen TK, Dang M, Doan TTM, Lim JH. Utilizing Deep Neural Networks for Chrysanthemum Leaf and Flower Feature Recognition. AgriEngineering. 2024; 6(2):1133-1149. https://doi.org/10.3390/agriengineering6020065
Chicago/Turabian StyleNguyen, Toan Khac, Minh Dang, Tham Thi Mong Doan, and Jin Hee Lim. 2024. "Utilizing Deep Neural Networks for Chrysanthemum Leaf and Flower Feature Recognition" AgriEngineering 6, no. 2: 1133-1149. https://doi.org/10.3390/agriengineering6020065
APA StyleNguyen, T. K., Dang, M., Doan, T. T. M., & Lim, J. H. (2024). Utilizing Deep Neural Networks for Chrysanthemum Leaf and Flower Feature Recognition. AgriEngineering, 6(2), 1133-1149. https://doi.org/10.3390/agriengineering6020065