Statistical Validation of Energy Efficiency Improvements through Analysis of Experimental Field Data: A Guide to Good Practice



Abstract
:1. Introduction
1.1. Aim and Research Questions
- Does Method A provide better results than Method B according to a certain routing criterion? As such criterion, the vehicle’s energy consumption is considered in our use case. Thus, in other words, we would like to study whether the average energy consumption of a vehicle following the same routing method A is statistically lower than the consumption of the same vehicle following routing method B.
- Is Method A better at a γ% percentage compared to Method B, on the basis of the adopted routing criterion? In other words, we would like to examine whether the average energy savings percentage of a vehicle following routing method A is at least γ% compared to the energy consumption of the same vehicle following routing method B.
1.2. Related Work
2. Methodology-Statistical Hypothesis Testing Process
- i.
- μ = μ0, σ2 = ω0 (simple hypothesis)
- ii.
- μ = μ0, σ2 > ω0 (composite hypothesis)
- iii.
- μ = μ0 (simple hypothesis)
- i.
- HA: μ > μ0 (right-tailed, directional)
- ii.
- HA: μ < μ0 (left-tailed, directional)
- iii.
- HA: μ ≠ μ0 (two-tailed, non-directional)
- Type I error: Rejection of hypothesis H0 while the latter is true
- Type II error: Acceptance (or no rejection) of H0 when the latter is false
- Probability of type I error = P (rejection of H0 | H0 is true) = α
- Probability of type II error = P (acceptance of H0 | HA is true) = β
- Identification of the population distribution and determination of the parameters of interest (e.g., mean value), which will be the subject of hypothesis testing. Identification of the null hypothesis H0 as well as of the form of the alternative hypothesis HA.
- Selection of a suitable test statistic.
- Identification of the critical region.
- Calculation of the observed value of the test statistic.
3. Experimental Process and Results
3.1. Description of the Experiment and the Collected Dataset
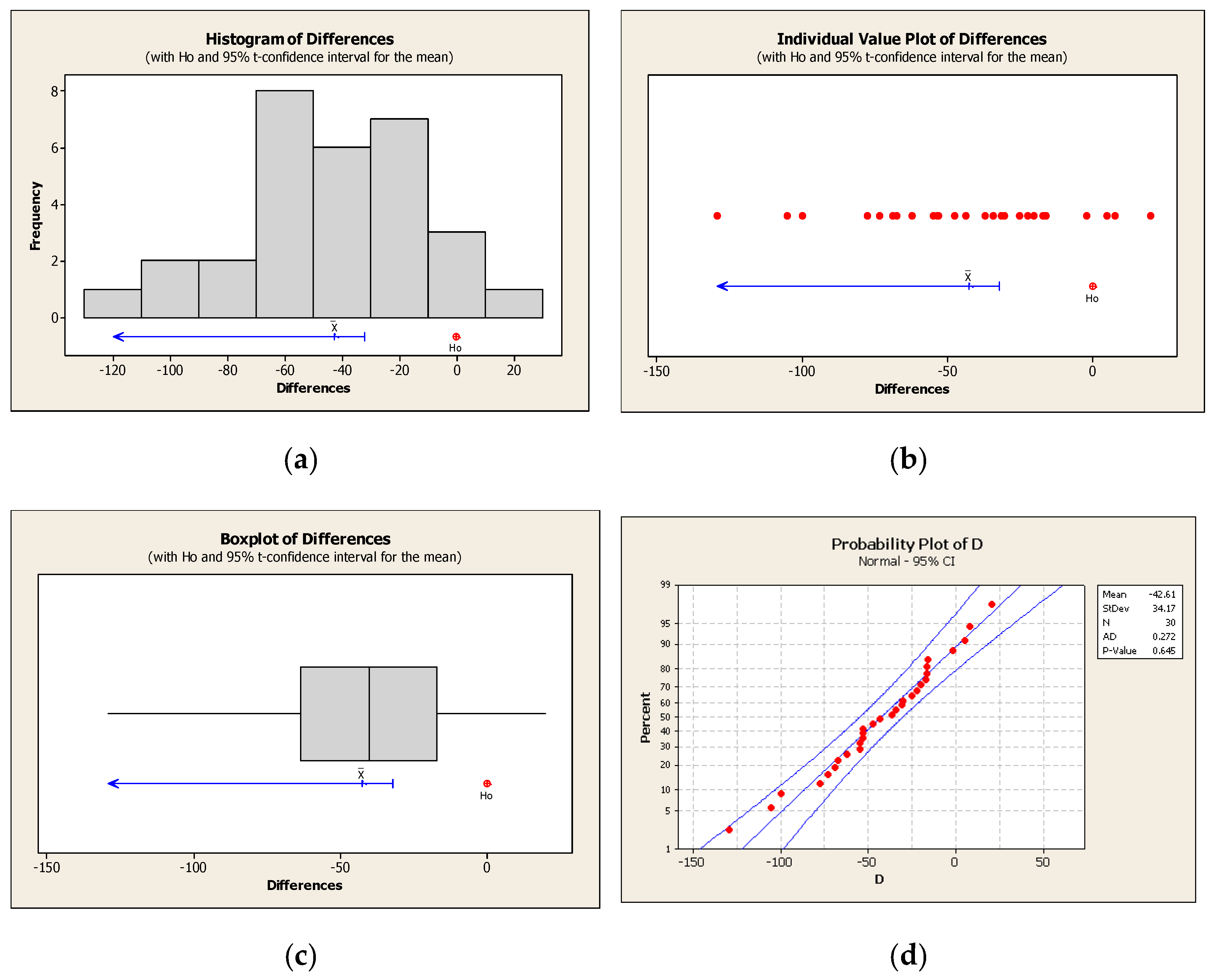
3.2. Paired Sample Tests
- Concerning the pairs: For each i (where ), the random pair has a two-dimensional normal distribution with parameters such that:and that the random pairs are random vectors independent from one another.
- Concerning the differences : The differences , where:comprise a random sample out of a normal population with mean value . Thus, we assume that the random variables constitute a random sample of a normal population with mean value equal to the difference of the average values of each pair’s observations [24].
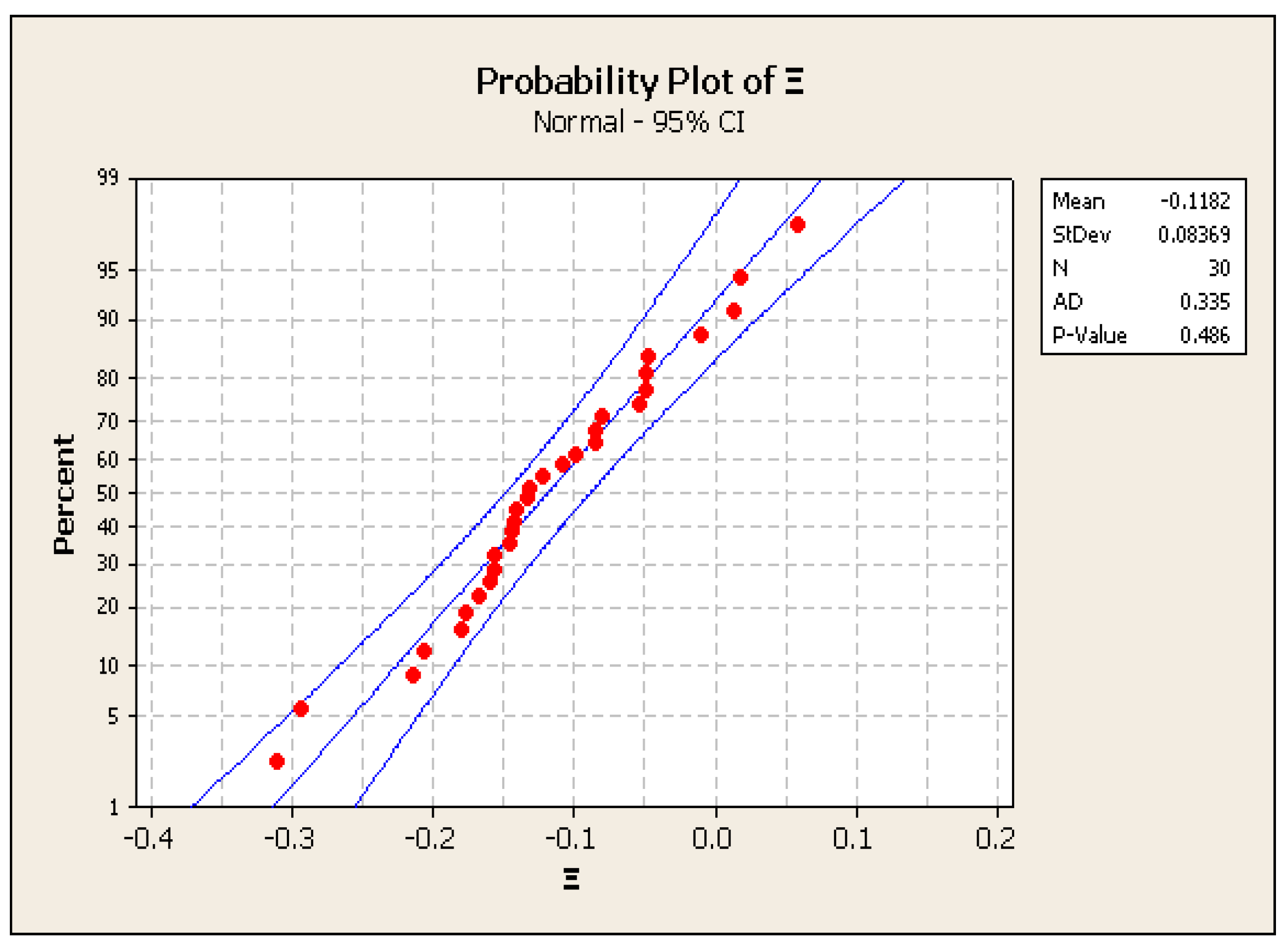
3.3. Statistical Testing of the Mean Value in a Normal Population (with Unknown Variance)
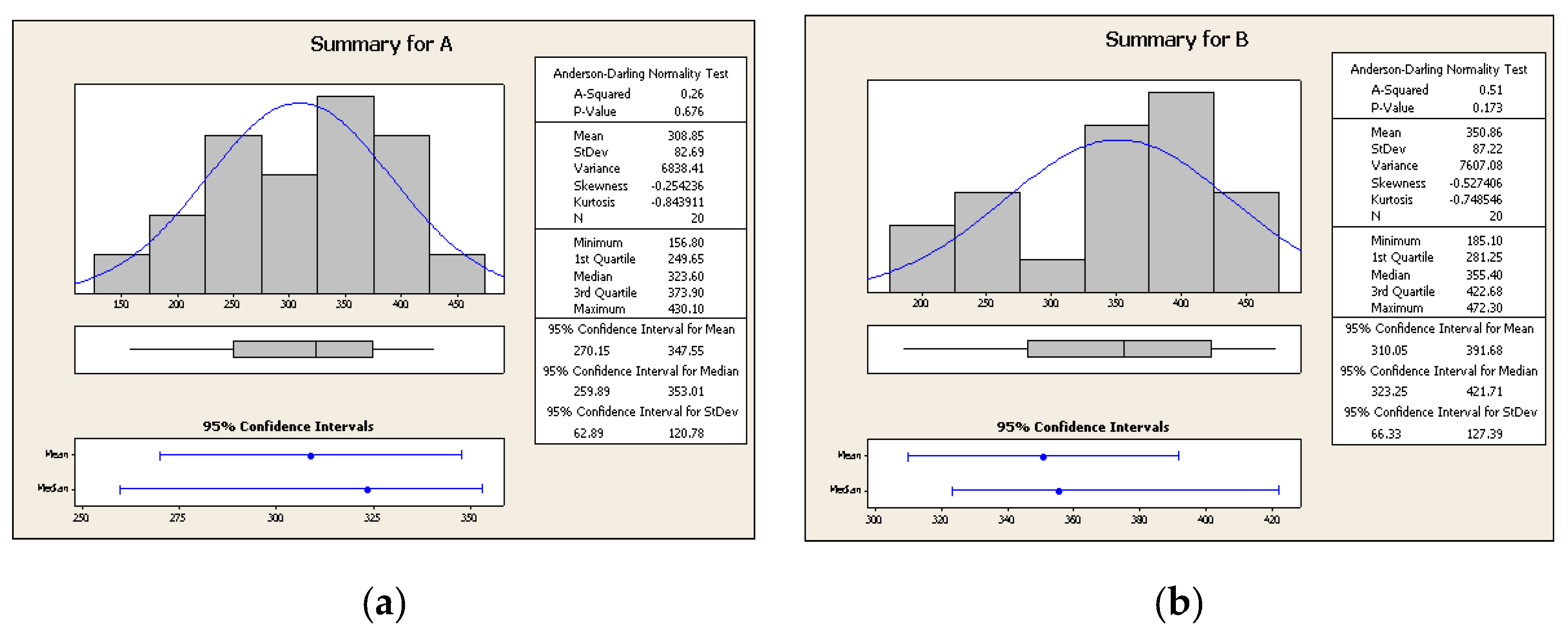
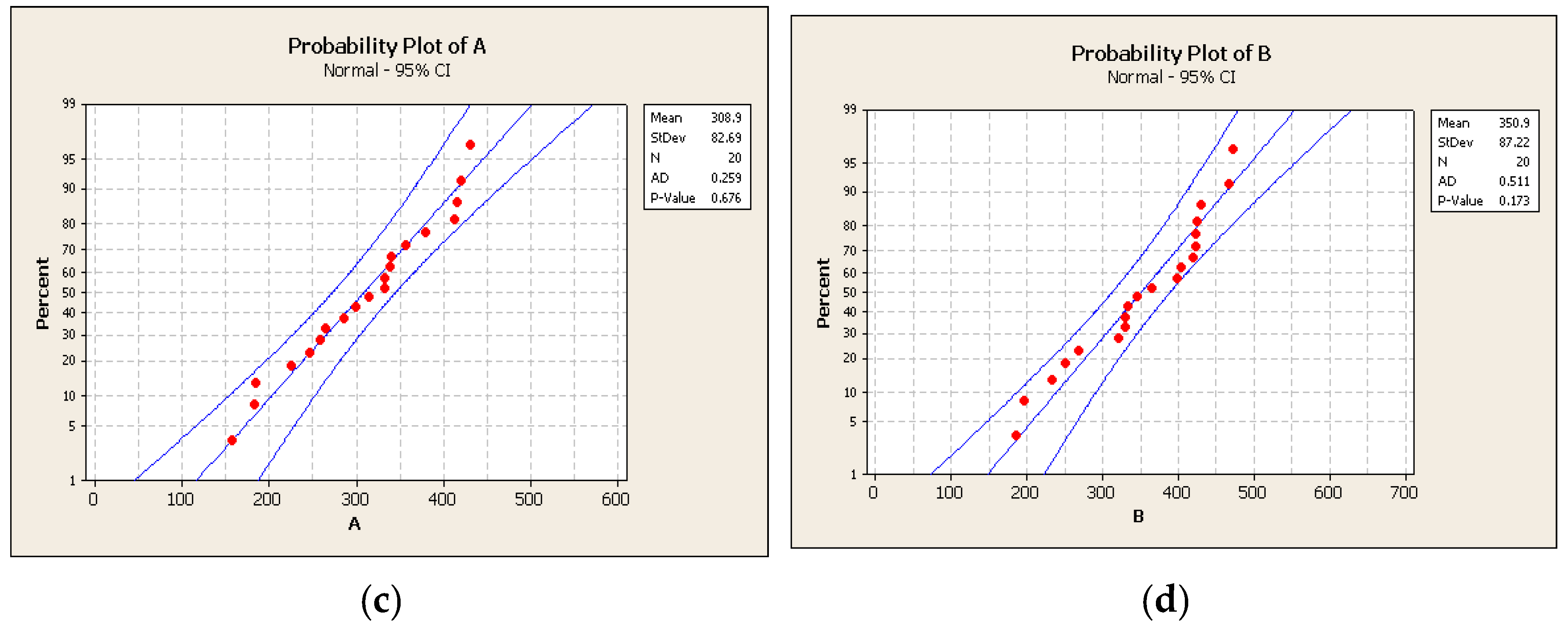
3.4. Statistical Testing of the Difference of the Mean Values of Two Populations with Independent Samples
3.5. Discussion and Guidelines
- The mean difference in the two cases is similar, i.e., in the first case (paired samples test) and (measured in Watt-hours) in the second (two-sample test);
- On the other hand, as opposed to the paired samples, the two-sample experimentation has not provided substantial evidence that Method A achieves on average better results than Method B.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kamal, M.A.S.; Mukai, M.; Murata, J.; Kawabe, T. Model Predictive Control of Vehicles on Urban Roads for Improved Fuel Economy. IEEE Trans. Control Syst. Technol. 2013, 21, 831–841. [Google Scholar] [CrossRef]
- d’Orey, P.M.; Ferreira, M. ITS for Sustainable Mobility: A Survey on Applications and Impact Assessment Tools. IEEE Trans. Intell. Transp. Syst. 2014, 15, 477–493. [Google Scholar] [CrossRef]
- Jiang, J.; Charles, J.; Demestichas, K. ECOGEM: A European Framework-7 Project. IEEE Veh. Technol. Mag. 2011, 6, 22–26. [Google Scholar] [CrossRef]
- Saint Pierre, G.; Brouwer, R.; Hogema, J.; Kuiper, O.; Seewald, P.; Mejuto, P.; Garc, E.; Toffetti, A.; Borgarello, L.; Capano, P. D43. 1: Eco Driving in the Real-world: Behavioural, Environmental and Safety Impacts. 2016. Available online: https://hal.archives-ouvertes.fr/hal-02194519/file/D43.1%20Annexes%20A-B-C-D-E-F-G_final.pdf (accessed on 28 August 2020).
- Matysiak, A.; Niezgoda, M. EMERALD—Deliverable D5.1—Initial Trials Results and Analysis. 2005. Available online: https://cordis.europa.eu/docs/projects/cnect/1/314151/080/deliverables/001-EMERALDD51v07InitialTrialsResultsandAnalysis.pdf (accessed on 28 August 2020).
- Pandazis, J.-C. eCoMove—Deploying the Cooperative Mindset. Available online: http://www.ecomove-project.eu/assets/Uploads/Publications/eCoMoveBrochuresecured.pdf (accessed on 6 August 2020).
- Samaras, Z.; Ntziachristos, L.; Toffolo, S.; Magra, G.; Garcia-Castro, A.; Valdes, C.; Vock, C.; Maier, W. Quantification of the Effect of ITS on CO2 Emissions from Road Transportation. Transp. Res. Procedia 2016, 14, 3139–3148. [Google Scholar] [CrossRef] [Green Version]
- Hao, P.; Wu, G.; Boriboonsomsin, K.; Barth, M.J. Developing a framework of Eco-Approach and Departure application for actuated signal control. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 796–801. [Google Scholar]
- Guo, L.; Huang, S.; Sadek, A.W. An Evaluation of Environmental Benefits of Time-Dependent Green Routing in the Greater Buffalo–Niagara Region. J. Intell. Transp. Syst. 2013, 17, 18–30. [Google Scholar] [CrossRef]
- Ayyildiz, K.; Cavallaro, F.; Nocera, S.; Willenbrock, R. Reducing fuel consumption and carbon emissions through eco-drive training. Transp. Res. Part F Traffic Psychol. Behav. 2017, 46, 96–110. [Google Scholar] [CrossRef]
- Demir, E.; Bektaş, T.; Laporte, G. A review of recent research on green road freight transportation. Eur. J. Oper. Res. 2014, 237, 775–793. [Google Scholar] [CrossRef] [Green Version]
- Chalkias, C.; Lasaridi, K. A GIS based model for the optimisation of municipal solid waste collection: The case study of Nikea, Athens, Greece. Technology 2009, 1, 11–15. [Google Scholar]
- Ando, N.; Taniguchi, E. Travel Time Reliability in Vehicle Routing and Scheduling with Time Windows. Netw. Spat. Econ. 2006, 6, 293–311. [Google Scholar] [CrossRef]
- Bandeira, J.; Carvalho, D.O.; Khattak, A.J.; Rouphail, N.M.; Coelho, M.C. A comparative empirical analysis of eco-friendly routes during peak and off-peak hours. In Proceedings of the Transportation Research Board 91st Annual Meeting, Washington, DC, USA, 22–26 January 2012. [Google Scholar]
- Paksoy, T.; Özceylan, E. Environmentally conscious optimization of supply chain networks. J. Oper. Res. Soc. 2014, 65, 855–872. [Google Scholar] [CrossRef]
- Perez-Prada, F.; Monzon, A.; Valdes, C. Managing Traffic Flows for Cleaner Cities: The Role of Green Navigation Systems. Energies 2017, 10, 791. [Google Scholar] [CrossRef] [Green Version]
- Ericsson, E.; Larsson, H.; Brundell-Freij, K. Optimizing route choice for lowest fuel consumption—Potential effects of a new driver support tool. Transp. Res. Part C Emerg. Technol. 2006, 14, 369–383. [Google Scholar] [CrossRef]
- Elbery, A.; Rakha, H.; Elnainay, M.; Drira, W.; Filali, F. Eco-Routing Using V2I Communication: System Evaluation. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Las Palmas de Gran Canaria, Spain, 15–18 September 2015; pp. 71–76. [Google Scholar]
- Dahlinger, A.; Tiefenbeck, V.; Ryder, B.; Gahr, B.; Fleisch, E.; Wortmann, F. The impact of numerical vs. symbolic eco-driving feedback on fuel consumption—A randomized control field trial. Transp. Res. Part Transp. Environ. 2018, 65, 375–386. [Google Scholar] [CrossRef]
- Tulusan, J.; Staake, T.; Fleisch, E. Providing eco-driving feedback to corporate car drivers: What impact does a smartphone application have on their fuel efficiency? In Proceedings of the Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 12–16 September 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 212–215. [Google Scholar]
- Barth, M.; Mandava, S.; Boriboonsomsin, K.; Xia, H. Dynamic ECO-driving for arterial corridors. In Proceedings of the 2011 IEEE Forum on Integrated and Sustainable Transportation Systems, Vienna, Austria, 29 June–1 July 2011; pp. 182–188. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference; Duxbury: Pacific Grove, CA, USA, 2002; Volume 2. [Google Scholar]
- Wasserman, L. All of Statistics: A Concise Course in Statistical Inference; Springer Science & Business Media: Berlin, Germany, 2013; ISBN 0-387-21736-3. [Google Scholar]
- Koutrouvelis, I. Probabilities and Statistics II; Hellenic Open University: Patras, Greece, 2008; Volume B. [Google Scholar]
- Macdonald, R.R. Simple V Composite Tests. In Encyclopedia of Statistics in Behavioral Science; American Cancer Society: Atlanta, GA, USA, 2005; ISBN 978-0-470-01319-9. [Google Scholar]
- Wu, J.-D.; Liu, J.-C. A forecasting system for car fuel consumption using a radial basis function neural network. Expert Syst. Appl. 2012, 39, 1883–1888. [Google Scholar] [CrossRef]
- Masikos, M.; Demestichas, K.; Adamopoulou, E.; Theologou, M. Energy-efficient routing based on vehicular consumption predictions of a mesoscopic learning model. Appl. Soft Comput. 2015, 28, 114–124. [Google Scholar] [CrossRef]
- Masikos, M.; Demestichas, K.; Adamopoulou, E.; Theologou, M. Mesoscopic forecasting of vehicular consumption using neural networks. Soft Comput. 2015, 19, 145–156. [Google Scholar] [CrossRef]
- Ross, S.M. Introductory Statistics; Academic Press: Cambridge, MA, USA, 2017; ISBN 0-12-804361-X. [Google Scholar]
- Stephens, M.A. EDF Statistics for Goodness of Fit and Some Comparisons. J. Am. Stat. Assoc. 1974, 69, 730–737. [Google Scholar] [CrossRef]
- Shafer, D.S.; Zhang, Z. Introductory Statistics; Saylor Foundation: Washington, DC, USA, 2013; ISBN 1-4533-4487-X. [Google Scholar]
- Tests with Two Independent Samples, Continuous Outcome. Available online: https://sphweb.bumc.bu.edu/otlt/MPH-Modules/BS/BS704_HypothesisTest-Means-Proportions/BS704_HypothesisTest-Means-Proportions6.html (accessed on 28 August 2020).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision | Real Situation | |
|---|---|---|
| H0 Is true or HA Is False | H0 Is False or HA Is True | |
| Rejection of H0 | Rejection of H0 while it is true (Type I error) | Rejection of H0 while HA is true |
| Acceptance of H0 | No rejection of H0 while it is true | Acceptance of H0 while HA is true (Type II error) |
| Method A | Method B | Method A vs. Method B [Ratio = (A − B)/B] | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Test | Length (m) | Energy (Wh) | Time (s) | Links | Length (m) | Energy (Wh) | Time (s) | Links | Length (Ratio %) | Energy (Ratio) | Time (Ratio %) |
| 1 | 3037 | 402.6 | 293 | 36 | 3040 | 422.8 | 256 | 35 | −0.10% | −0.047781 | 14% |
| 2 | 2349 | 275.0 | 181 | 27 | 2100 | 300.2 | 164 | 31 | 11.85% | −0.083814 | 10% |
| 3 | 2175 | 311.8 | 194 | 35 | 3014 | 441.0 | 167 | 37 | −27.84% | −0.293006 | 16% |
| 4 | 2098 | 234.4 | 154 | 16 | 2496 | 339.6 | 188 | 31 | −15.95% | −0.309695 | −18% |
| 5 | 2101 | 328.3 | 274 | 36 | 2112 | 345.3 | 257 | 37 | −0.52% | −0.049346 | 7% |
| 6 | 2244 | 324.8 | 298 | 42 | 2086 | 341.3 | 252 | 40 | 7.57% | −0.048488 | 18% |
| 7 | 2660 | 196.8 | 198 | 21 | 2682 | 213.9 | 162 | 22 | −0.82% | −0.079729 | 22% |
| 8 | 2772 | 343.0 | 346 | 33 | 3112 | 416.2 | 334 | 32 | −10.95% | −0.175933 | 4% |
| 9 | 2732 | 342.4 | 313 | 30 | 3026 | 411.3 | 321 | 31 | −9.72% | −0.167596 | −3% |
| 10 | 3128 | 365.9 | 319 | 30 | 3903 | 465.6 | 313 | 30 | −19.87% | −0.214217 | 2% |
| 11 | 2376 | 311.8 | 275 | 26 | 2721 | 365.0 | 283 | 27 | −12.66% | −0.145646 | −3% |
| 12 | 2695 | 353.4 | 336 | 34 | 3040 | 406.4 | 313 | 35 | −11.33% | −0.130481 | 7% |
| … | … | … | … | … | … | … | … | … | … | … | … |
| 30 | … | … | … | … | … | … | … | … | … | … | … |
| Paired T for A–B | ||||
|---|---|---|---|---|
| N | Mean | StDev | SE Mean | |
| A | 30 | 308.4 | 79.3 | 14.5 |
| B | 30 | 351.0 | 88.6 | 16.2 |
| Difference | 30 | −42.6 | 34.17 | 6.24 |
| 95% upper bound for mean difference: −32.01 | ||||
| t-Test of mean difference = 0 (vs. <0): T-Value = −6.83 p-Value = 0.000 | ||||
| Test of μΞ = −0.1 vs. > −0.1 | |||||||
|---|---|---|---|---|---|---|---|
| Variable | N | Mean | StDev | SE Mean | 95% Lower Bound | T | p |
| Ξ | 30 | −0.1182 | 0.0837 | 0.0153 | −0.1442 | −1.19 | 0.878 |
| HA | Critical Region |
|---|---|
| μA − μB < δ0 | |
| μA − μB > δ0 | |
| μA − μB ≠ δ0 | ∪ |
| Test and Cl for Two Variances: A; B | ||||
|---|---|---|---|---|
| Method | ||||
| Null hypothesis | Sigma (A)/Sigma (B) = 1 | |||
| Alternative hypothesis | Sigma (A)/Sigma (B) not = 1 | |||
| Significance level | Alpha = 0.05 | |||
| Statistics | ||||
| Variable | N | StDev | Variance | |
| A | 20 | 82.695 | 6838.408 | |
| B | 20 | 87.219 | 7607.082 | |
| Ratio of standard deviations = 0.948 | ||||
| Ratio of variances = 0.899 | ||||
| 95% Confidence Intervals | ||||
| Distribution of Data | CI for StDev | CI for Variance Ratio | ||
| Normal | (0.597; 1.507) | (0.356; 2.271) | ||
| Continuous | (0.583; 1.471) | (0.340; 2.165) | ||
| Test Method | DF1 | DF2 | Test | |
| Statistic | p-Value | |||
| F Test (normal) | 19 | 19 | 0.90 | 0.819 |
| Levene’s Test | ||||
| (any continuous) | 1 | 38 | 0.09 | 0.762 |
| Two-Sample T for A vs. B | ||||
|---|---|---|---|---|
| SE | ||||
| N | Mean | StDev | Mean | |
| A | 20 | 308.9 | 82.7 | 18 |
| B | 20 | 350.9 | 87.2 | 20 |
| Difference = μA − μΒ | ||||
| Estimate for difference: −42.0 | ||||
| 95% upper bound for difference: 3.3 | ||||
| t-Test of difference = 0 (vs. <): T-Value = −1.56 | p-Value = 0.063 | DF = 38 | ||
| Both use Pooled StDev = 84.9867 | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Demestichas, K.; Adamopoulou, E. Statistical Validation of Energy Efficiency Improvements through Analysis of Experimental Field Data: A Guide to Good Practice. Vehicles 2020, 2, 542-558. https://doi.org/10.3390/vehicles2030030
Demestichas K, Adamopoulou E. Statistical Validation of Energy Efficiency Improvements through Analysis of Experimental Field Data: A Guide to Good Practice. Vehicles. 2020; 2(3):542-558. https://doi.org/10.3390/vehicles2030030
Chicago/Turabian StyleDemestichas, Konstantinos, and Evgenia Adamopoulou. 2020. "Statistical Validation of Energy Efficiency Improvements through Analysis of Experimental Field Data: A Guide to Good Practice" Vehicles 2, no. 3: 542-558. https://doi.org/10.3390/vehicles2030030
APA StyleDemestichas, K., & Adamopoulou, E. (2020). Statistical Validation of Energy Efficiency Improvements through Analysis of Experimental Field Data: A Guide to Good Practice. Vehicles, 2(3), 542-558. https://doi.org/10.3390/vehicles2030030