Remaining Useful Life Prediction Using Temporal Convolution with Attention



Abstract
:1. Introduction
Related Work
2. Materials
2.1. Data Set
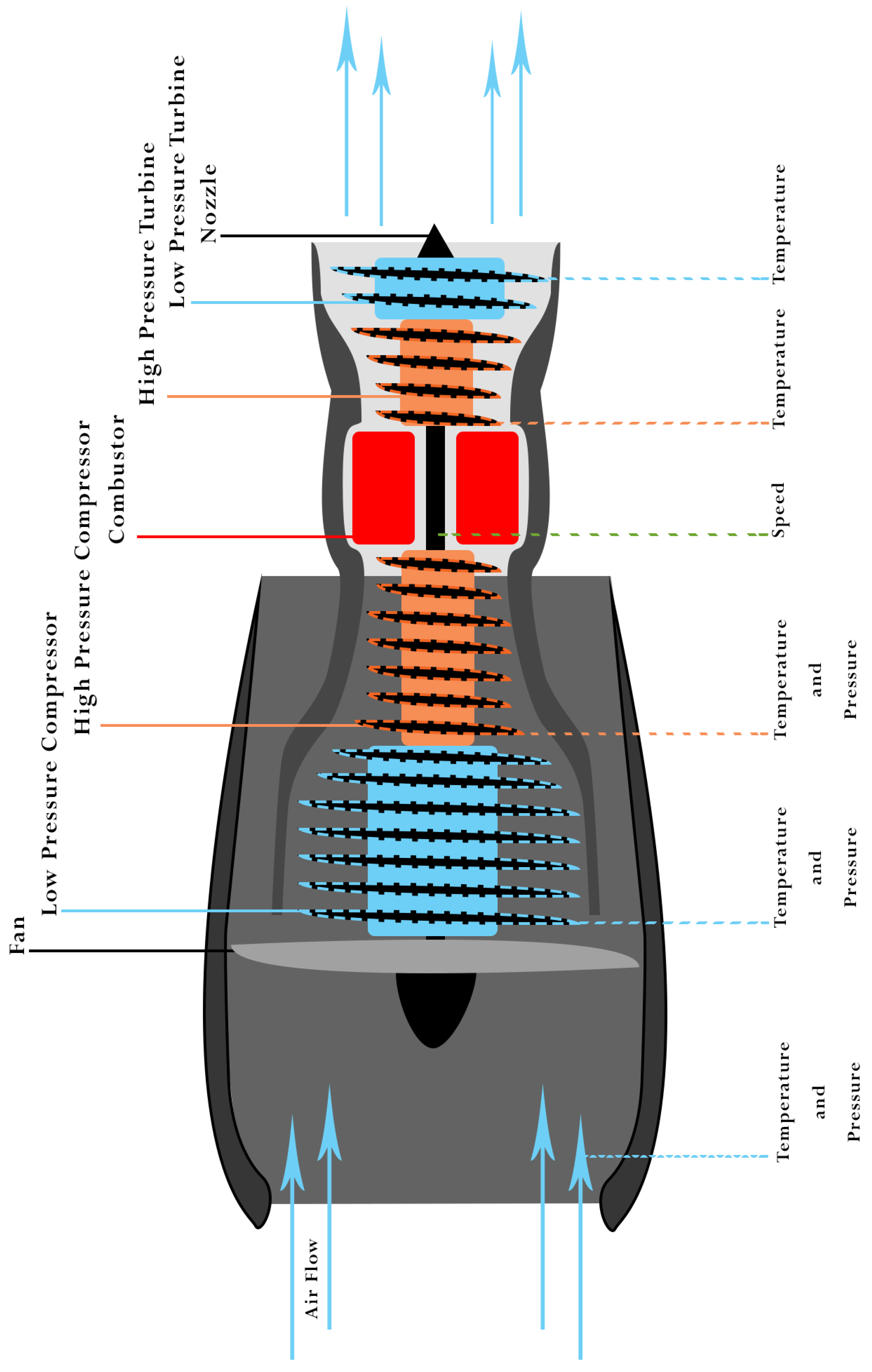
NASA C-MAPSS
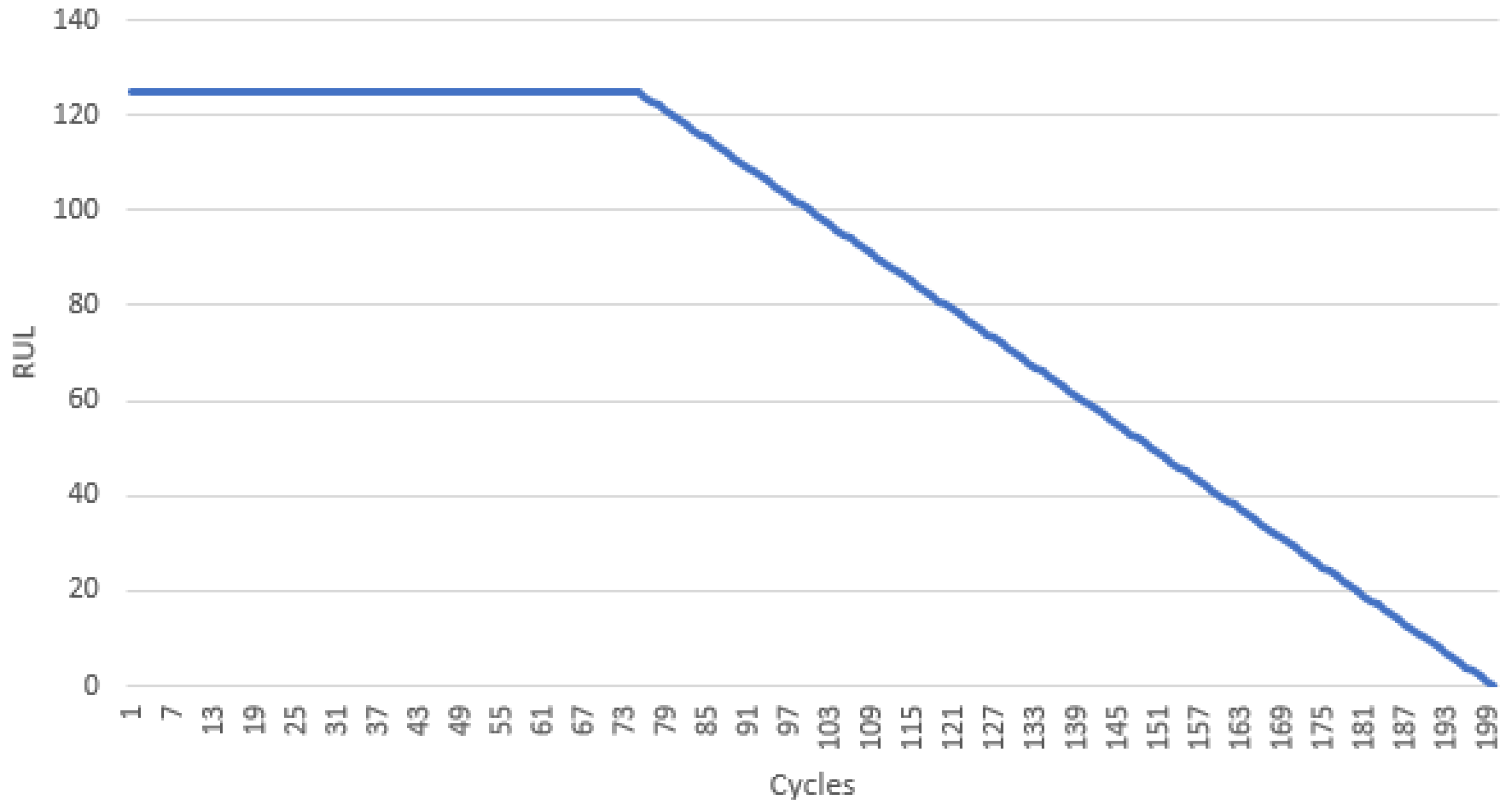
2.2. RUL Estimation
2.3. Metric
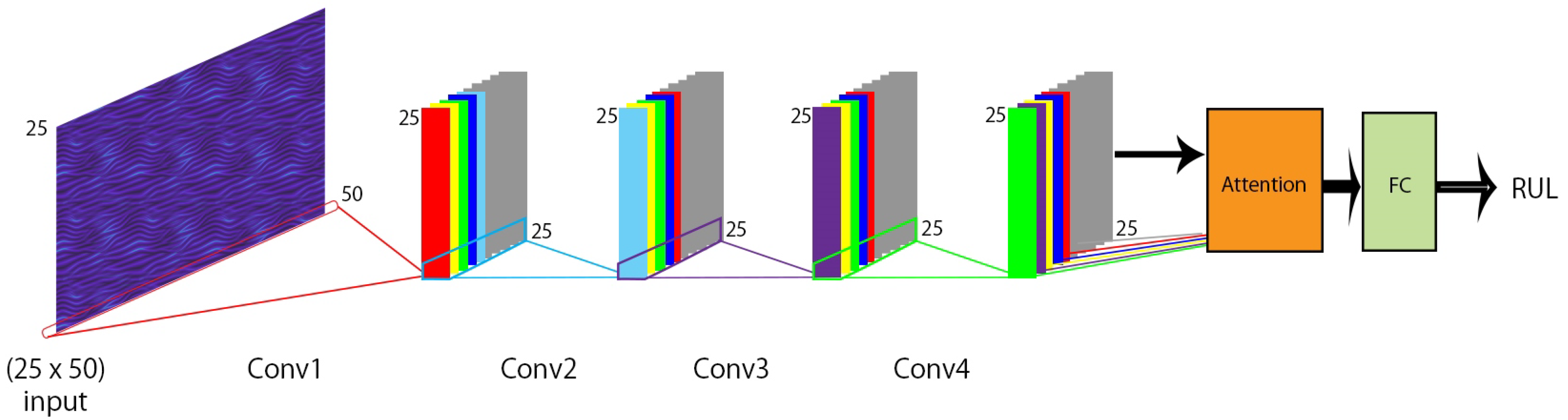
2.4. Proposed Architecture
2.4.1. Convolution Neural Network
2.4.2. Proposed Convolution
2.4.3. Attention Mechanism
- Calculating alignment scores;
- Calculating weighted average attention vector;
- Calculating the context vector.
2.4.4. Proposed Attention
2.4.5. Proposed Network Structure
3. Results and Discussion
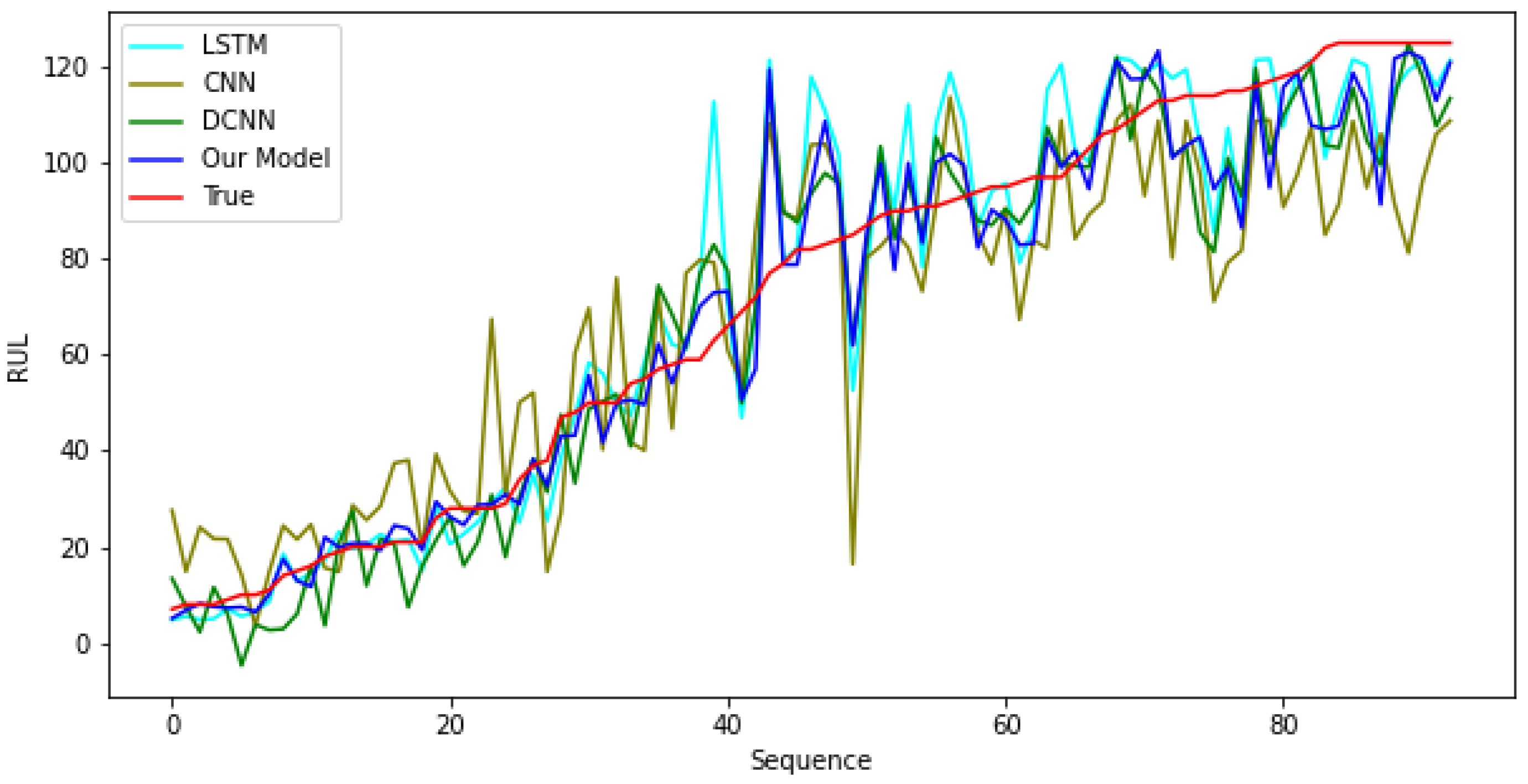
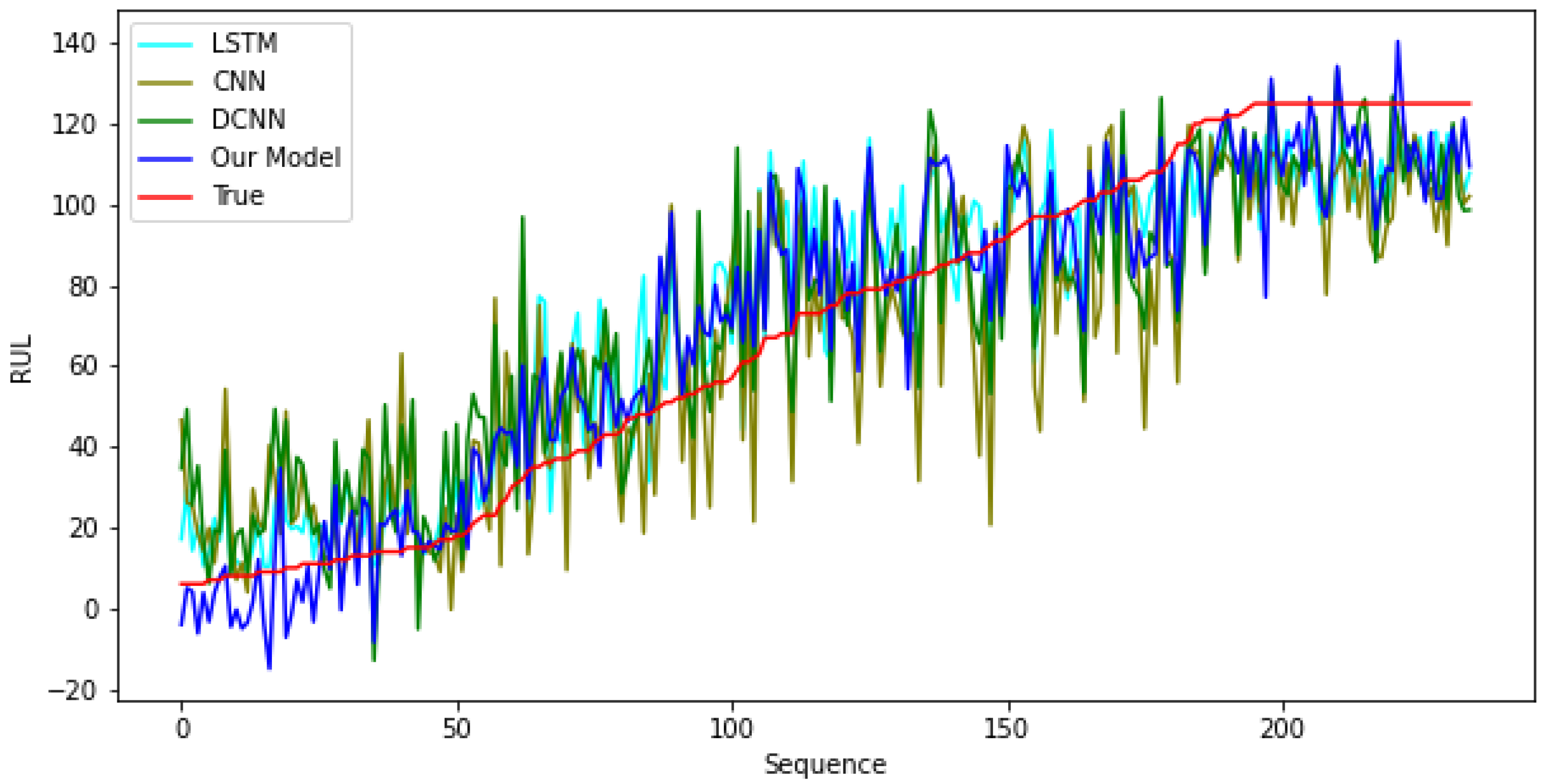
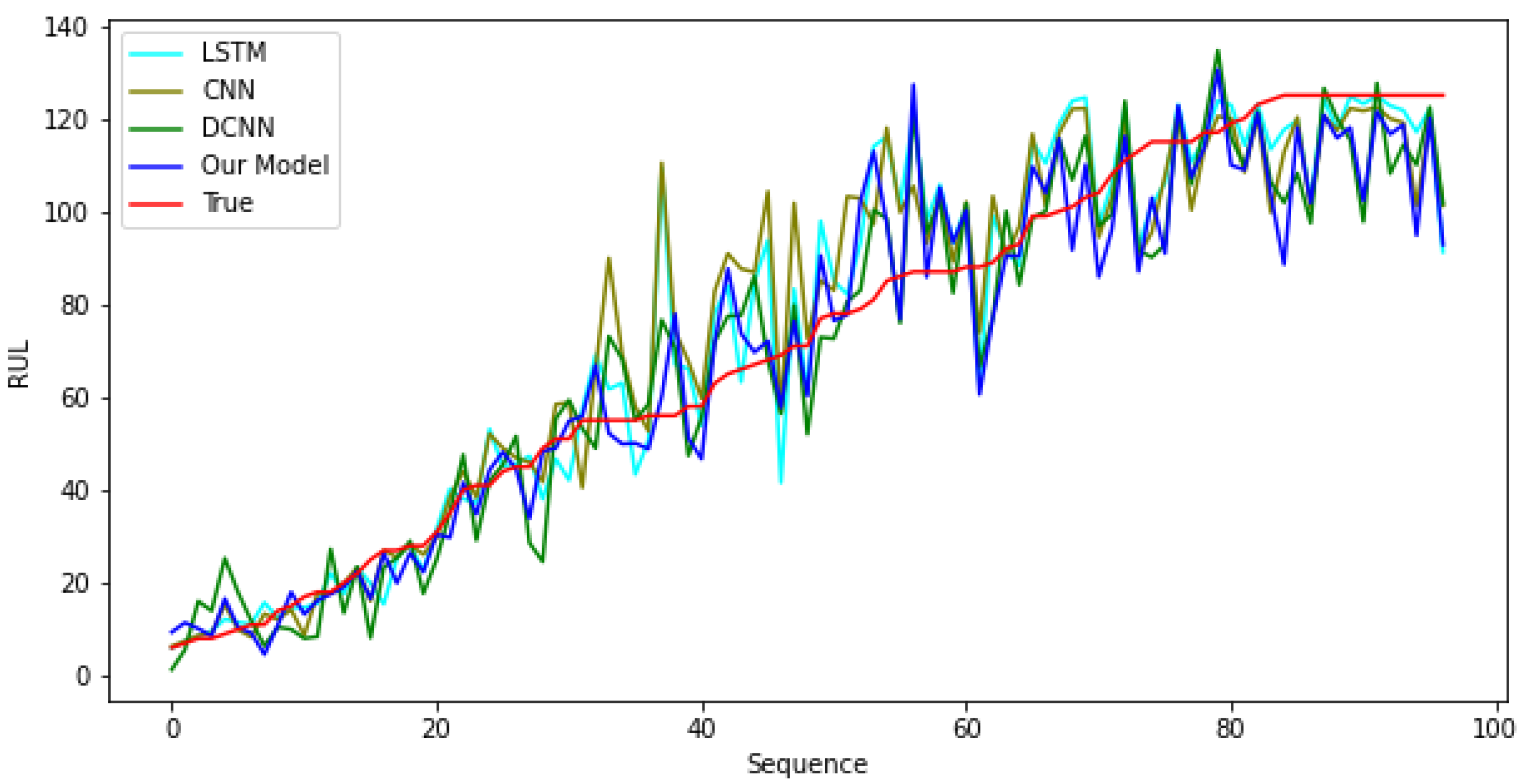
3.1. Analysis
3.1.1. Optimal Model
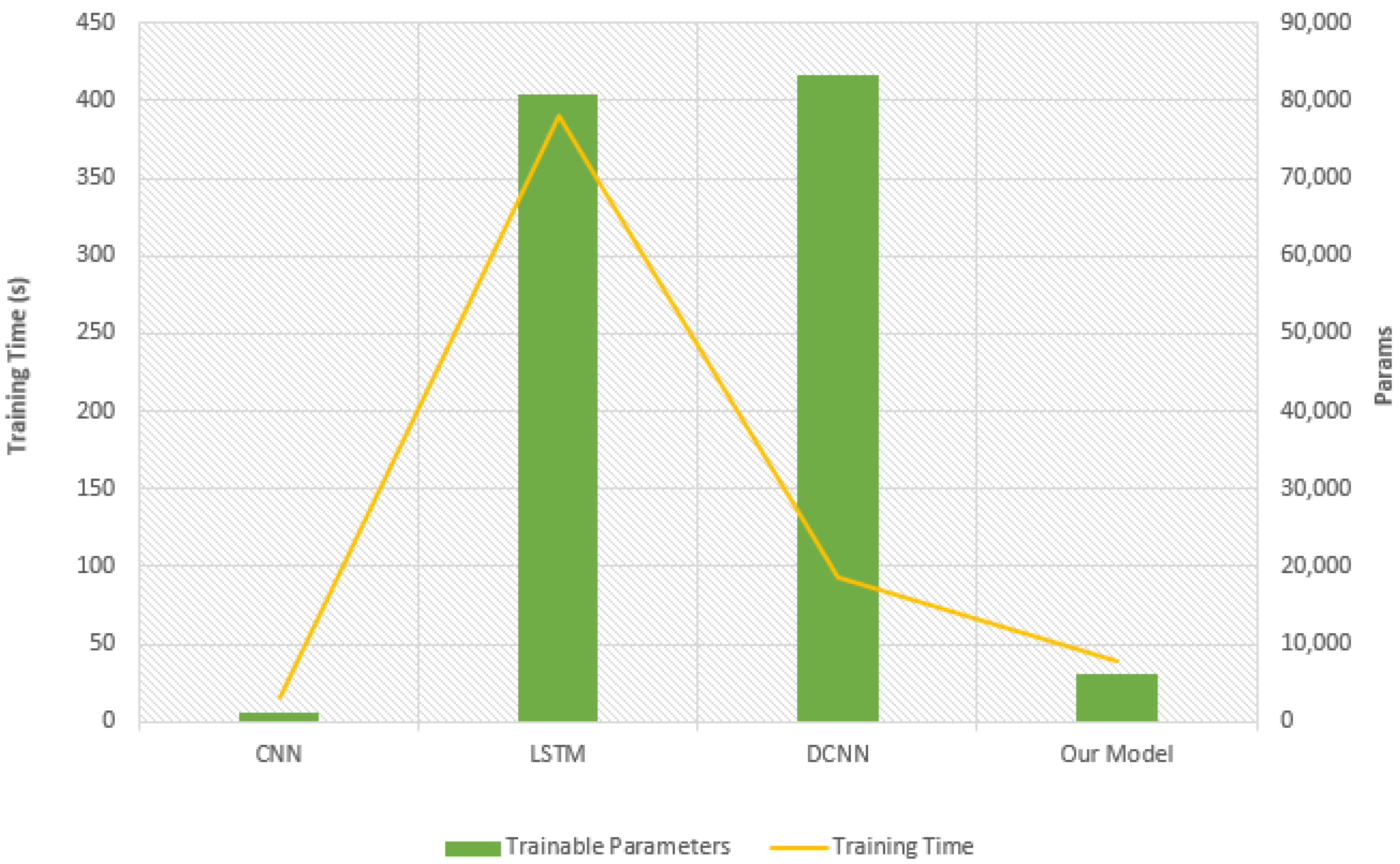
- Adapted CNN [17]A simple two layer convolution network that is adopted from [17]. This network, similar to the proposed model, uses one dimensional convolutions. They also use pooling layers that drastically reduce the data after every layer. It is trained with stochastic gradient descent. It should be noted that the convolutions for this model span across each time step and crosses multiple time steps at once, thus learning relations between close proximity time steps. This model is chosen as it out performed many of the traditional methods like Support Vector Regressor (SVR) and the MLP. It also shared some similarity to the proposed model that would make it a more relevant comparison. Reference [17] achieves its performance using a sequence length of 15 and a piece-wise cut off limit of 130. The deployment of the network attempts to follow the literature as closely as possible, using same number of layers and convolution parameters.
- LSTMThe LSTM RNN model used to benchmark is a vanilla 2 stack LSTM. Each LSTM layer has a 0.2 dropout rate and hidden nodes of 100 and 50 for each respective layer. LSTMs are a rather reliable variant of the traditional RNN. They are more capable of learning long term dependencies and suffer less from the well known issues in RNN like vanishing gradients. Not only have LSTMs proven themselves to possess a strong aptitude in learning temporal patterns, it is for this very reason that they are often compared to models with attention applied. There are also many literature that uses some form of the LSTM. Hence, a simplified version of it was deployed, the size of the model was specifically chosen to be more similar in size to the Deep Convolutional Neural Network (DCNN) model next, however they tend to be very large due to its recursive nature.
- Adapted DCNN [24]This model adapted from [24] was one of the first to achieve very good performance on the data set, close to the recent works metrics. It performs a two dimensional convolution on the data set. There are five layers of convolution, each of 10 filters producing a three dimensional output every time. As a result, it extracts more detail and as such learns better than its predecessors. The literature uses varying w for each subset of data and a fixed of 125. The model was deployed with only 14 sensors that were deemed useful. This model shows reliable success on this prognostics data set and would be a good benchmark to the proposed model. This was recreated as closely as possible to the literature aside from choice of some parameters such as .
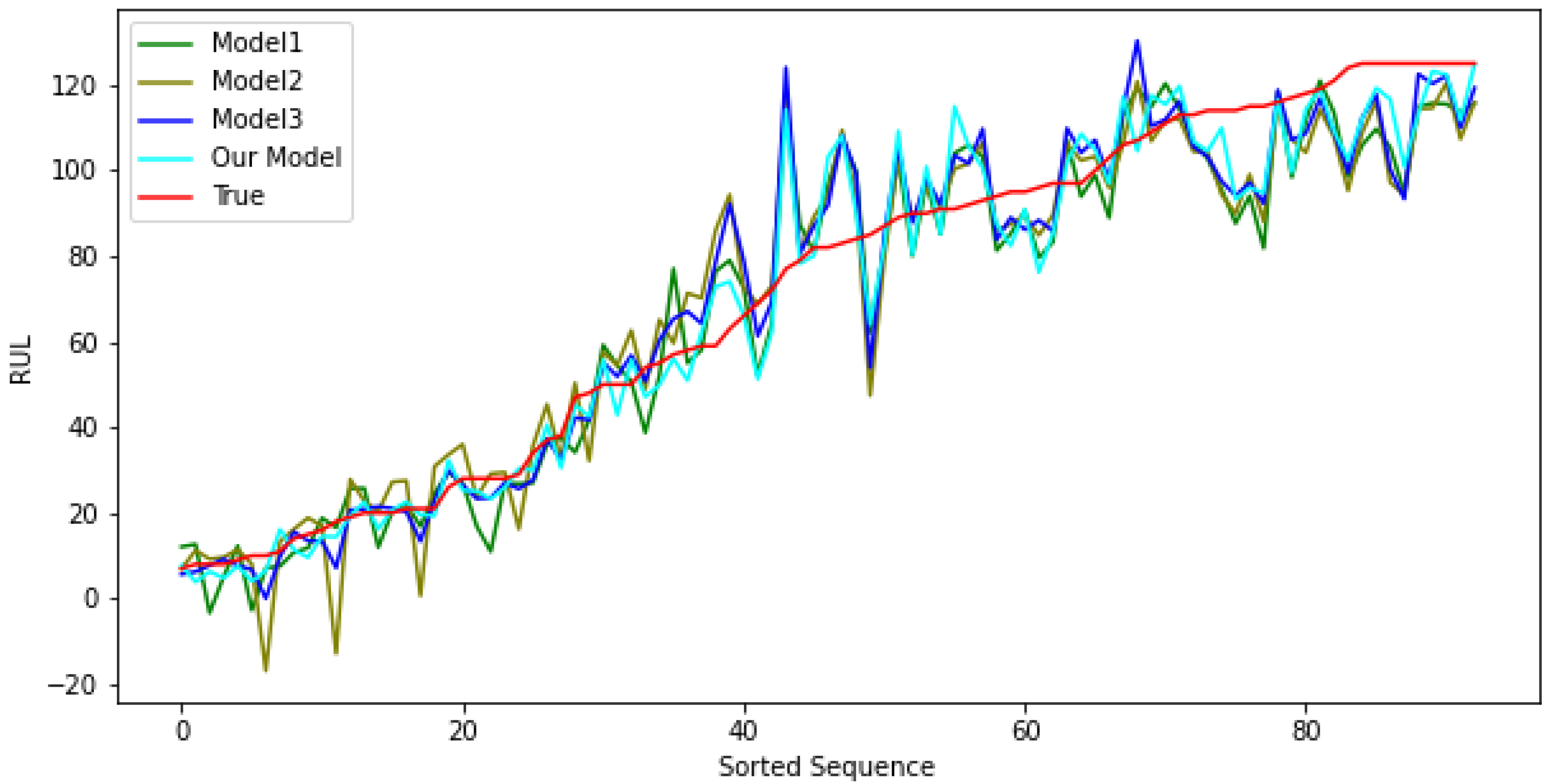
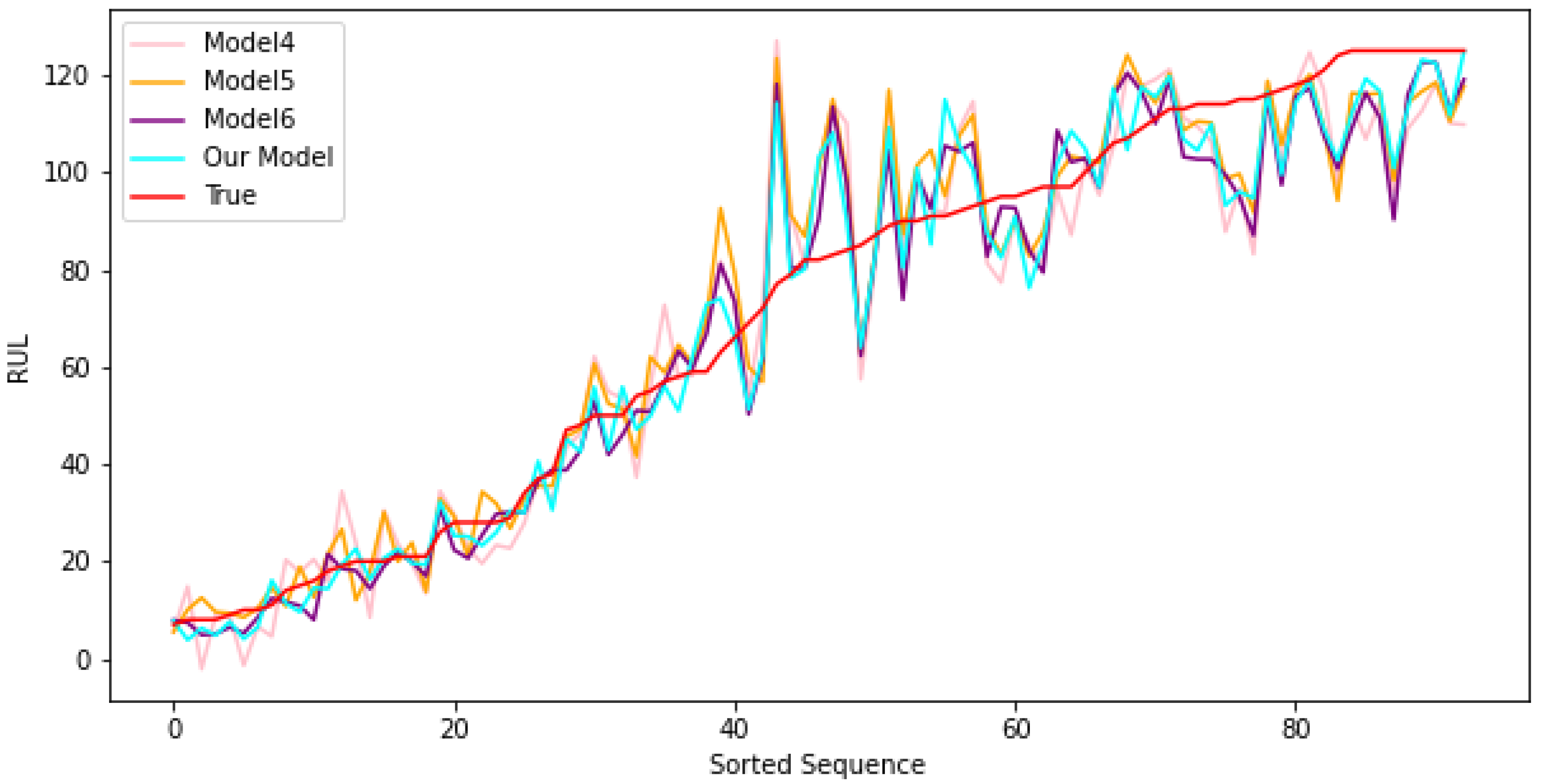
3.1.2. Impact of Proposed Structures
- Model 1 removes the proposed attention mechanism from the model and attempts to measure the aptitude of the convolution layers only.
- Model 2 experiments with the convolution by changing the axis of the filters. While Model 1 convolves over each time series, Model 2 takes a more popular approach by convolving over time steps and learning relations between sensor inputs per time step similar to [17].
- Model 3 introduces the attention mechanism back into the alternative convolution Model 2. This is to observe the effects of the attention in the different setting and might provide insight into the model.
- The last entry is the proposed model and it is used as a reference for the other models that are under review.
- Model 4 sees the attention mechanism attending to the rows of the convolution output instead of the columns. It would thus be focusing between the sensor series instead of amongst the convolution filters.
- Model 5 uses the original Softmax function to generate the attention weights instead of the Sigmoid that is used on top of the alternate attention axis used in Model 4.
- Model 6 uses the proposed model and changes only the Sigmoid to the original Softmax to visualize the difference that the Sigmoid makes.
3.2. Hardware Performance
4. Methods
Network Setup
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural Network |
| DCNN | Deep Convolutional Neural Network |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| LSTM | Long Short-Term Memory |
| SVM | Support Vector Machine |
| ML | Machine Learning |
| MAE | Mean Absolute Error |
| MLP | Multi Layer Perceptron |
| ELM | Extreme Learning Machine |
| DBN | Deep Belief Network |
| MODBNE | Multiobjective Deep Belief Networks Ensemble |
| MTS | Multi-variable Time Series |
| NLP | Natural Language Processing |
| DBN | Deep Belief Network |
| RMSE | Root Mean Square Error |
| RNN | Recurrent Neural Network |
| R2 | R-square correlation |
| RUL | Remaining Useful Life |
| DAG | Directed Acyclic Graph |
| DSM | Deep Survival Model |
| SoC | System on Chip |
| SVR | Support Vector Regressor |
| TCN | Temporal Convolution Network |
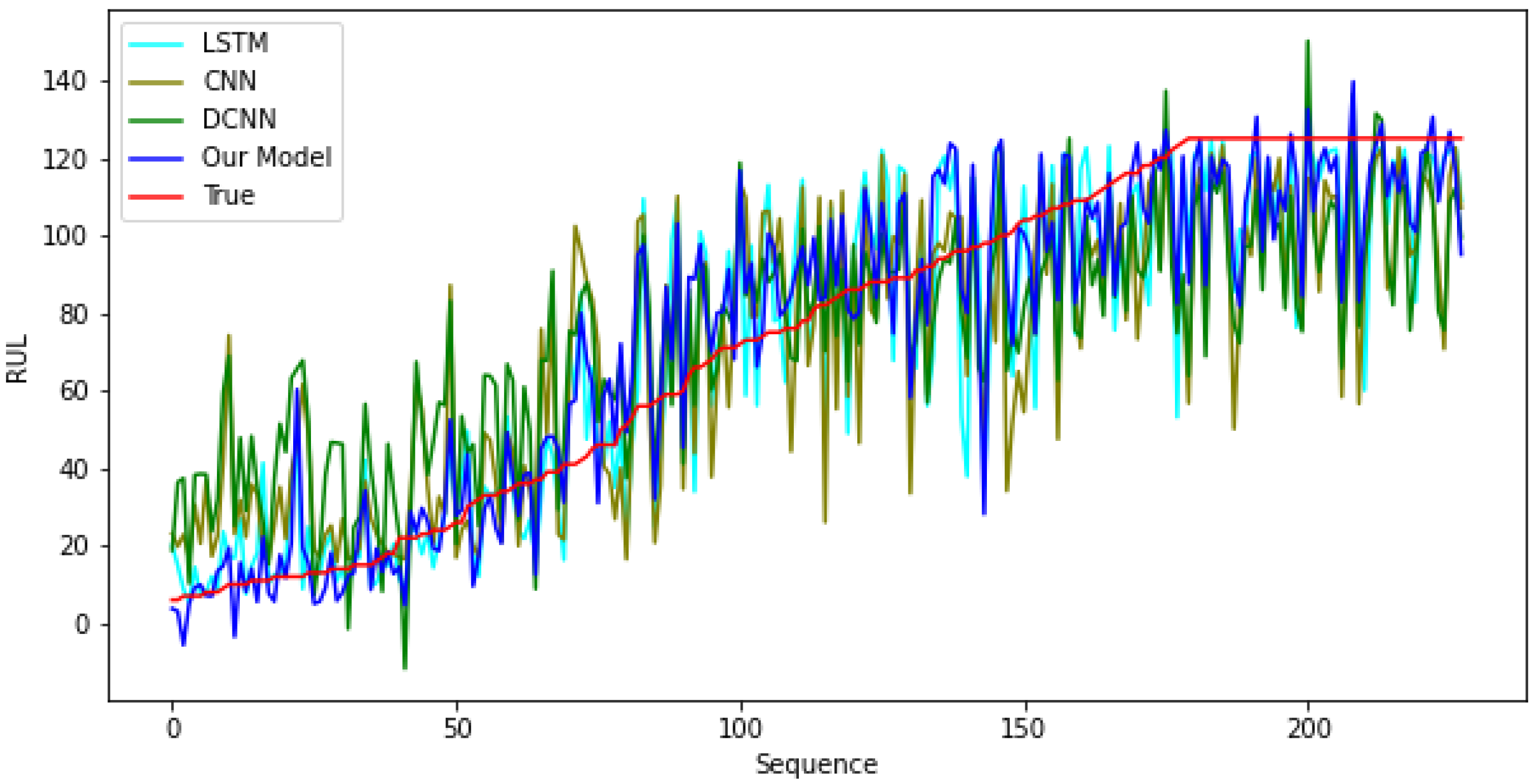
Appendix A. Further Analysis on Results





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cycles | Metric | Model | ||||
|---|---|---|---|---|---|---|
| CNN | LSTM | DCNN | Our Model | |||
| FD001 | RMSE | 10.80 | 2.59 | 7.72 | 2.83 | |
| MAE | 9.41 | 2.29 | 6.29 | 2.26 | ||
| Mean Score | 1.99 | 0.20 | 0.78 | 0.20 | ||
| RMSE | 13.87 | 4.33 | 7.15 | 3.32 | ||
| MAE | 10.83 | 3.35 | 5.71 | 2.70 | ||
| Mean Score | 4.31 | 0.37 | 0.73 | 0.28 | ||
| RMSE | 17.32 | 13.31 | 11.40 | 9.84 | ||
| MAE | 13.49 | 8.86 | 8.53 | 6.52 | ||
| Mean Score | 7.18 | 4.42 | 2.52 | 2.16 | ||
| FD002 | RMSE | 15.43 | 11.28 | 22.33 | 11.33 | |
| MAE | 12.1 | 8.71 | 17.73 | 8.91 | ||
| Mean Score | 5.85 | 2.25 | 14.46 | 1.55 | ||
| RMSE | 16.87 | 16.54 | 21.12 | 12.50 | ||
| MAE | 12.83 | 12.19 | 16.94 | 9.85 | ||
| Mean Score | 8.13 | 10.08 | 15.53 | 2.69 | ||
| RMSE | 21.06 | 19.89 | 21.29 | 14.95 | ||
| MAE | 16.37 | 15.28 | 17.05 | 11.69 | ||
| Mean Score | 10.36 | 13.36 | 14.77 | 4.38 | ||
| FD003 | RMSE | 11.75 | 2.31 | 8.40 | 3.48 | |
| MAE | 10.11 | 1.70 | 7.42 | 2.78 | ||
| Mean Score | 2.26 | 0.183 | 1.23 | 0.34 | ||
| RMSE | 17.87 | 4.75 | 11.38 | 4.19 | ||
| MAE | 13.86 | 3.41 | 8.94 | 3.33 | ||
| Mean Score | 7.31 | 0.41 | 2.39 | 0.35 | ||
| RMSE | 23.41 | 13.15 | 15.19 | 10.31 | ||
| MAE | 18.90 | 9.16 | 11.68 | 7.07 | ||
| Mean Score | 23.48 | 4.38 | 6.43 | 2.11 | ||
| FD004 | RMSE | 23.83 | 7.30 | 30.59 | 5.63 | |
| MAE | 20.27 | 5.64 | 26.97 | 4.49 | ||
| Mean Score | 29.91 | 0.97 | 45.01 | 0.53 | ||
| RMSE | 22.76 | 10.98 | 29.28 | 12.12 | ||
| MAE | 17.52 | 7.56 | 25.70 | 8.84 | ||
| Mean Score | 27.99 | 2.44 | 36.27 | 3.22 | ||
| RMSE | 24.29 | 17.83 | 24.96 | 16.82 | ||
| MAE | 19.41 | 12.96 | 20.82 | 12.49 | ||
| Mean Score | 22.16 | 7.49 | 22.91 | 7.13 | ||
Appendix B. Further Details about the NASA C-MAPSS Data Set

| Symbol | Description | Units |
|---|---|---|
| T2 | Total temperature at fan inlet | R |
| T24 | Total temperature at LPC outlet | R |
| T30 | Total temperature at HPC outlet | R |
| T50 | Total temperature at LPT outlet | R |
| P2 | Pressure at fan inlet | psia |
| P15 | Total pressure in bypass-duct | psia |
| P30 | Total pressure at HPC outlet | psia |
| Nf | Physical fan speed | rpm |
| Nc | Physical core speed | rpm |
| epr | Engine pressure ratio (P50/P2) | – |
| Ps30 | Static pressure at HPC outlet | psia |
| phi | Ratio of fuel flow to Ps30 | pps/psi |
| NRf | Corrected fan speed | rpm |
| NRc | Corrected core speed | rpm |
| BPR | Bypass Ratio | – |
| farB | Burner fuel-air ratio | – |
| htBleed | Bleed Enthalpy | – |
| Nf | Demanded fan speed | rpm |
| PCNFR | Demanded corrected fan speed | rpm |
| W31 | HPT coolant bleed | lbm/s |
| W32 | LPT coolant bleed | lbm/s |
References
- Azadeh, A.; Asadzadeh, S.; Salehi, N.; Firoozi, M. Condition-based maintenance effectiveness for series-parallel power generation system—A combined Markovian simulation model. Reliab. Eng. Syst. Saf. 2015, 142. [Google Scholar] [CrossRef]
- Pecht, M.; Gu, J. Physics-of-failure-based prognostics for electronic products. Trans. Inst. Meas. Control 2009, 31. [Google Scholar] [CrossRef]
- Heimes, F. Recurrent Neural Networks for Remaining Useful Life Estimation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–6. [Google Scholar] [CrossRef]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.W.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Song, H.; Rajan, D.; Thiagarajan, J.J.; Spanias, A. Attend and Diagnose: Clinical Time Series Analysis using Attention Models. arXiv 2017, arXiv:1711.03905. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient flow in recurrent nets: The difficulty of learning long-term dependencies. In A Field Guide to Dynamical Recurrent Neural Networks; Kremer, S.C., Kolen, J.F., Eds.; IEEE Press: Piscataway, NJ, USA, 2001. [Google Scholar]
- Shen, C.H.; Hsu, T.J. Research on Vehicle Trajectory Prediction and Warning Based on Mixed Neural Networks. Appl. Sci. 2020, 11, 7. [Google Scholar] [CrossRef]
- Bai, M.; Liu, J.; Ma, Y.; Zhao, X.; Long, Z.; Yu, D. Long Short-Term Memory Network-Based Normal Pattern Group for Fault Detection of Three-Shaft Marine Gas Turbine. Energies 2020, 14, 13. [Google Scholar] [CrossRef]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dehghani, M.; Gouws, S.; Vinyals, O.; Uszkoreit, J.; Łukasz, K. Universal Transformers. arXiv 2018, arXiv:1807.03819. [Google Scholar]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks. arXiv 2017, arXiv:1703.07015. [Google Scholar]
- Shih, S.Y.; Sun, F.K.; Lee, H. Temporal Pattern Attention for Multivariate Time Series Forecasting. arXiv 2018, arXiv:1809.04206. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Xi, L.; Li, X.; Liu, C.; Qiu, H.; Lee, J. Residual life predictions for ball bearings based on self-organizing map and back propagation neural network methods. Mech. Syst. Signal Process. 2007, 21, 193–207. [Google Scholar] [CrossRef]
- Tian, Z. An artificial neural network approach for remaining useful life prediction of equipments subject to condition monitoring. In Proceedings of the 2009 8th International Conference on Reliability, Maintainability and Safety, Chengdu, China, 20–24 July 2009; pp. 143–148. [Google Scholar]
- Babu, G.; Zhao, P.; Li, X. Deep Convolutional Neural Network Based Regression Approach for Estimation of Remaining Useful Life. In Proceedings of the International Conference on Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016; pp. 214–228. [Google Scholar] [CrossRef]
- Javed, K.; Gouriveau, R.; Zerhouni, N. A New Multivariate Approach for Prognostics Based on Extreme Learning Machine and Fuzzy Clustering. IEEE Trans. Cybern. 2015, 45, 2626–2639. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Lim, P.; Qin, A.K.; Tan, K.C. Multiobjective Deep Belief Networks Ensemble for Remaining Useful Life Estimation in Prognostics. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2306–2318. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining Useful Life Estimation of Engineered Systems using vanilla LSTM Neural Networks. Neurocomputing 2017, 275. [Google Scholar] [CrossRef]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long Short-Term Memory Network for Remaining Useful Life estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; pp. 88–95. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, P.; Yan, R.; Gao, R. Long short-term memory for machine remaining life prediction. J. Manuf. Syst. 2018. [Google Scholar] [CrossRef]
- Wang, J.; Wen, G.; Yang, S.; Liu, Y. Remaining Useful Life Estimation in Prognostics Using Deep Bidirectional LSTM Neural Network. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 1037–1042. [Google Scholar] [CrossRef]
- Li, X.; Ding, Q.; Sun, J.Q. Remaining Useful Life Estimation in Prognostics Using Deep Convolution Neural Networks. Reliab. Eng. Syst. Saf. 2017, 172. [Google Scholar] [CrossRef] [Green Version]
- Jayasinghe, L.; Samarasinghe, T.; Yuenv, C.; Low, J.C.N.; Ge, S.S. Temporal Convolutional Memory Networks for Remaining Useful Life Estimation of Industrial Machinery. In Proceedings of the 2019 IEEE International Conference on Industrial Technology (ICIT), Melbourne, Australia, 13–15 February 2019; pp. 915–920. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Su, H.; Zhao, W.l.; Liu, B. Predicting the Remaining Useful Life of an Aircraft Engine Using a Stacked Sparse Autoencoder with Multilayer Self-Learning. Complexity 2018, 2018, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Li, X.; He, D. A Directed Acyclic Graph Network Combined With CNN and LSTM for Remaining Useful Life Prediction. IEEE Access 2019, 7, 75464–75475. [Google Scholar] [CrossRef]
- Chu, C.H.; Lee, C.J.; Yeh, H.Y. Developing Deep Survival Model for Remaining Useful Life Estimation Based on Convolutional and Long Short-Term Memory Neural Networks. Wirel. Commun. Mob. Comput. 2020, 2020, 8814658. [Google Scholar] [CrossRef]
- Ellefsen, A.; Bjorlykhaug, E.; Æsøy, V.; Ushakov, S.; Zhang, H. Remaining Useful Life Predictions for Turbofan Engine Degradation Using Semi-Supervised Deep Architecture. Reliab. Eng. Syst. Saf. 2018, 183. [Google Scholar] [CrossRef]
- Hou, G.; Xu, S.; Zhou, N.; Yang, L.; Fu, Q. Remaining Useful Life Estimation Using Deep Convolutional Generative Adversarial Networks Based on an Autoencoder Scheme. Comput. Intell. Neurosci. 2020, 2020, 9601389. [Google Scholar] [CrossRef]
- Wang, Z.; Dong, Y.; Liu, W.; Ma, Z. A Novel Fault Diagnosis Approach for Chillers Based on 1-D Convolutional Neural Network and Gated Recurrent Unit. Sensors 2020, 20, 2458. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Teo, T.H.; Tan, W.M.; Tan, Y.S. Tumour detection using Convolutional Neural Network on a lightweight multi-core device. In Proceedings of the 2019 IEEE 13th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (IEEE MCSoC 2019), Singapore, 1–4 October 2019; pp. 87–92. [Google Scholar]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–9. [Google Scholar]
- Saxena, A.; Goebel, K. Turbofan Engine Degradation Simulation Data Set. 2008. Available online: https://ti.arc.nasa.gov/c/6/ (accessed on 10 February 2021).
- Peel, L. Data driven prognostics using a Kalman filter ensemble of neural network models. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–6. [Google Scholar]
- Ramasso, E. Investigating computational geometry for failure prognostics. Int. J. Progn. Health Manag. 2014, 5, 1–18. [Google Scholar]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 1–98. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Cui, Z.; Chen, W.; Chen, Y. Multi-Scale Convolutional Neural Networks for Time Series Classification. arXiv 2016, arXiv:1603.06995. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Min, M.R.; Ge, Y.; Kadav, A. A Context-aware Attention Network for Interactive Question Answering. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]





| Data Set | NASA C-MAPSS | |||
|---|---|---|---|---|
| FD001 | FD002 | FD003 | FD004 | |
| Train sets | 100 | 260 | 100 | 249 |
| Test sets | 100 | 259 | 100 | 248 |
| Operating conditions | 1 | 6 | 1 | 6 |
| Fault conditions | 1 | 1 | 2 | 2 |
| Train Samples | 17,731 | 48,819 | 21,820 | 57,522 |
| Min/Max cycles for Train set | 128/362 | 128/378 | 145/525 | 128/543 |
| Min/Max cycles for Test set | 31/303 | 21/367 | 38/475 | 19/486 |
| Method | FD001 | FD002 | FD003 | FD004 | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | Score | RMSE | Score | RMSE | Score | RMSE | Score | |
| MLP [17] | 37.56 | 18,000 | 80.03 | 7,800,000 | 37.39 | 17,400 | 77.37 | 5,620,000 |
| SVR [17] | 20.96 | 1380 | 42.0 | 590,000 | 21.05 | 1600 | 45.35 | 371,000 |
| RVR [17] | 23.80 | 1500 | 31.30 | 17,400 | 22.37 | 1430 | 34.34 | 26,500 |
| CNN [17] | 18.45 | 1290 | 30.29 | 13,600 | 19.82 | 1600 | 29.16 | 7890 |
| ELM [18] | 17.27 | 523 | 37.28 | 498,000 | 18.47 | 574 | 30.96 | 121,000 |
| LSTM [21] | 16.14 | 338 | 24.49 | 4450 | 16.18 | 852 | 28.17 | 5550 |
| DBN [19] | 15.21 | 418 | 27.12 | 9030 | 14.71 | 442 | 29.88 | 7950 |
| MODBNE [19] | 15.04 | 334 | 25.05 | 5590 | 12.51 | 422 | 28.66 | 6560 |
| RNN [24] | 13.44 | 339 | 24.03 | 14,300 | 13.36 | 347 | 24.02 | 14,300 |
| DCNN [24] | 12.61 | 274 | 22.36 | 10,400 | 12.64 | 284 | 23.31 | 12,500 |
| BiLSTM [23] | 13.65 | 295 | 23.18 | 4130 | 13.74 | 317 | 24.86 | 5430 |
| DAG [27] | 11.96 | 229 | 20.34 | 2730 | 12.46 | 535 | 22.43 | 3370 |
| DSM (Regression) [28] | 14.04 | 310 | 15.15 | 1080 | 14.62 | 325 | 21.92 | 2260 |
| Semi-Supervised [29] | 12.56 | 231 | 22.73 | 3366 | 12.10 | 251 | 22.66 | 2840 |
| DCGAN + AE [30] | 10.71 | 174 | 19.49 | 2982 | 11.48 | 273 | 19.71 | 3874 |
| Proposed Model (CNN+ATT) | 11.48 | 198 | 17.25 | 1144 | 12.31 | 251 | 20.58 | 2072 |
| Data | Metric | Model | |||
|---|---|---|---|---|---|
| CNN1 | LSTM | DCNN2 | CNN + ATT | ||
| FD001 | RMSE | 21.61 ± 8.33 | 12.10 ± 0.69 | 12.64 ± 1.00 | 9.19 ± 0.31 |
| MAE | 16.51 ± 7.11 | 8.76 ± 0.58 | 9.84 ± 0.92 | 6.52 ± 0.25 | |
| FD002 | RMSE | 30.58 ± 7.79 | 16.88 ± 2.53 | 16.92 ± 0.32 | 15.41 ± 0.44 |
| MAE | 24.50 ± 8.19 | 12.78 ± 2.28 | 13.10 ± 0.24 | 11.98 ± 0.41 | |
| FD003 | RMSE | 22.80 ± 0.95 | 10.64 ± 1.30 | 13.96 ± 0.88 | 9.13 ± 0.43 |
| MAE | 17.39 ± 0.61 | 6.98 ± 1.06 | 10.78 ± 0.72 | 6.50 ± 0.33 | |
| FD004 | RMSE | 34.48 ± 7.63 | 17.00 ± 2.18 | 17.02 ± 0.33 | 16.89 ± 0.55 |
| MAE | 28.51 ± 9.20 | 12.25 ± 1.94 | 13.15 ± 0.32 | 12.31 ± 0.38 | |
| Data | Metric | Model | |||
|---|---|---|---|---|---|
| CNN1 | LSTM | DCNN2 | CNN + ATT | ||
| FD001 | RMSE | 18.86 | 14.28 | 12.24 | 10.60 |
| MAE | 14.73 | 10.04 | 9.39 | 7.55 | |
| R2 | 0.78 | 0.87 | 0.90 | 0.93 | |
| FD002 | RMSE | 23.02 | 18.37 | 21.02 | 14.55 |
| MAE | 16.54 | 13.93 | 17.32 | 12.45 | |
| R2 | 0.70 | 0.80 | 0.75 | 0.88 | |
| FD003 | RMSE | 21.16 | 12.79 | 13.71 | 11.71 |
| MAE | 15.99 | 9.60 | 11.03 | 8.88 | |
| R2 | 0.70 | 0.89 | 0.87 | 0.91 | |
| FD004 | RMSE | 25.69 | 19.65 | 26.77 | 17.23 |
| MAE | 22.32 | 14.13 | 22.28 | 12.83 | |
| R2 | 0.63 | 0.79 | 0.60 | 0.83 | |
| Metric | Model | ||||||
|---|---|---|---|---|---|---|---|
| Model 1 a | Model 2 a | Model 3 a | Model 4 b | Model 5 b | Model 6 b | Proposed Model | |
| RMSE | 12.39 | 13.49 | 12.15 | 13.51 | 11.91 | 11.36 | 10.60 |
| MAE | 9.70 | 9.95 | 8.50 | 10.12 | 8.60 | 8.29 | 7.55 |
| R2 | 0.90 | 0.88 | 0.90 | 0.88 | 0.91 | 0.92 | 0.93 |
| Score | 205.50 | 256.30 | 263.75 | 313.50 | 272.45 | 183.50 | 183.20 |
| Data | Units: ms | |||
|---|---|---|---|---|
| CNN1 | LSTM | DCNN2 | CNN + ATT | |
| FD001 | 0.3705 | 9.2114 | 22.9548 | 0.5976 |
| Parameter | Description | Value |
|---|---|---|
| - | Batch size | 200 |
| s | Input sequences | 25 |
| Sequence length used in benchmarking | 30/20/30/15 | |
| Sequence length used in investigations | 50 | |
| k | Conv filters | 25 |
| c | No. conv layers in | 4 |
| - | Conv layer activation | |
| - | Dropout after Attention | 0.2 |
| - | Nodes in dense | 64 |
| RUL constant | 125 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, W.M.; Teo, T.H. Remaining Useful Life Prediction Using Temporal Convolution with Attention. AI 2021, 2, 48-70. https://doi.org/10.3390/ai2010005
Tan WM, Teo TH. Remaining Useful Life Prediction Using Temporal Convolution with Attention. AI. 2021; 2(1):48-70. https://doi.org/10.3390/ai2010005
Chicago/Turabian StyleTan, Wei Ming, and T. Hui Teo. 2021. "Remaining Useful Life Prediction Using Temporal Convolution with Attention" AI 2, no. 1: 48-70. https://doi.org/10.3390/ai2010005
APA StyleTan, W. M., & Teo, T. H. (2021). Remaining Useful Life Prediction Using Temporal Convolution with Attention. AI, 2(1), 48-70. https://doi.org/10.3390/ai2010005