




AI 2025, 6(12), 323; https://doi.org/10.3390/ai6120323 - 9 Dec 2025
Abstract
Background: With the development of wireless communication technologies, the rapid advancement of 5G and 6G communication systems has spawned an urgent demand for low latency and high data rates. Orthogonal Frequency Division Multiplexing (OFDM) communication using high-order digital modulation has become a
[...] Read more.
Background: With the development of wireless communication technologies, the rapid advancement of 5G and 6G communication systems has spawned an urgent demand for low latency and high data rates. Orthogonal Frequency Division Multiplexing (OFDM) communication using high-order digital modulation has become a key technology due to its characteristics, such as high reliability, high data rate, and low latency, and has been widely applied in various fields. As a component of cognitive radios, automatic modulation classification (AMC) plays an important role in remote sensing and electromagnetic spectrum sensing. However, under current complex channel conditions, there are issues such as low signal-to-noise ratio (SNR), Doppler frequency shift, and multipath propagation. Methods: Coupled with the inherent problem of indistinct characteristics in high-order modulation, these currently make it difficult for AMC to focus on OFDM and high-order digital modulation. Existing methods are mainly based on a single model-driven approach or data-driven approach. The Adaptive Wavelet Mamba Network (AWMN) proposed in this paper attempts to combine model-driven adaptive wavelet transform feature extraction with the Mamba deep learning architecture. A module based on the lifting wavelet scheme effectively captures discriminative time–frequency features using learnable operations. Meanwhile, a Mamba network constructed based on the State Space Model (SSM) can capture long-term temporal dependencies. This network realizes a combination of model-driven and data-driven methods. Results: Tests conducted on public datasets and a custom-built real-time received OFDM dataset show that the proposed AWMN achieves a performance reaching higher accuracies of 62.39%, 64.50%, and 74.95% on the public Rml2016(a) and Rml2016(b) datasets and our formulated EVAS dataset, while maintaining a compact parameter size of 0.44M. Conclusions: These results highlight its potential for improving the automatic modulation classification of high-order OFDM modulation in 5G/6G systems.
Full article
(This article belongs to the Topic AI-Driven Wireless Channel Modeling and Signal Processing)





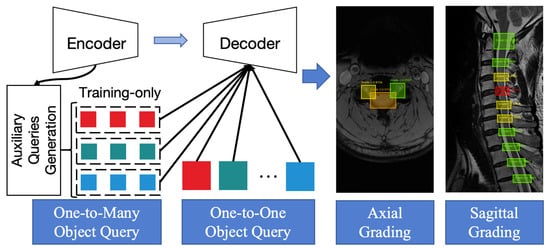









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}