1. Introduction
The outbreak of a novel coronavirus, severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), started in Wuhan, China, in December 2019 [
1]. Afterwards, the aggressive human-to-human spread of the virus infected the entire world with a disease now widely referred to as COVID-19 (coronavirus disease 2019). The total number of reported cases is more than 110 million at the time of writing (22 February 2021) [
2]. Although governments are taking drastic measures to fight the transmission of the virus, emerging variants are threatening progress [
3].
Currently, there are two types of diagnostic tests used in the identification of COVID-19. These are molecular tests such as real-time reverse transcription-polymerase chain reaction (RT-PCR) that detect the virus’s genetic material and antigen tests that detect specific proteins from the virus. Although RT-PCR test is performed on patients showing clinical symptoms, the current tests have very high false-negative rates resulting in the lack of treatment of COVID-19 patients and consequently failing to prevent transmission of the virus to others by these patients [
4]. Therefore, as an alternative, medical doctors are utilizing chest imaging technologies such as Computed tomography (CT) and X-ray images for diagnosing COVID-19. X-ray images are a fast and cheap way to detect COVID-19 [
5,
6]. CT scans of lungs are found to be a sensitive and accurate test for COVID-19 diagnosis [
7,
8]. Chest CT scans have the further advantage of identifying patients who are at the very start of the symptoms and even identifying asymptomatic patients [
9]. X-ray images can catch inflammation in the lungs; however, CT scans are more effective for COVID-19 and pneumonia detection because they present a detailed picture of air sacs [
8]. Hence, in this study, we have selected CT scans of lungs for identifying COVID-19 and other pneumonia.
In addition to diagnosis challenges, the prevalence of the virus and the ever-growing number of confirmed cases created a high-level demand for healthcare workers. Healthcare providers are facing intense workloads due to the pandemic [
10]. There are studies that use meta-heuristic optimization algorithms [
11,
12] and anomaly detection methods [
13] to detect COVID-19 pneumonia. To relieve the overwhelming workload, AI systems are also being used to detect and identify COVID-19 using medical imaging technologies [
14,
15,
16,
17,
18,
19,
20,
21,
22]. Recent studies on radiology demonstrate promising results for COVID-19 pneumonia classification using chest CTs with the help of deep learning methodologies.
Although there are works proposing deep Convolutional Neural Networks (CNNs) without performing segmentation on CT slices [
14,
18], performing segmentation of CT slices is usually preferred as a preprocessing step before classification networks. The reason why segmentation before classification is commonly preferred is that lung regions in CT images can easily be extracted with segmentation networks, which are efficacious in removing redundant information and eliminating noise. In these related works, pre-trained well-known architectures such as U-Net [
23], U-Net++ [
24], and Deeplabv3 [
25] are used for the segmentation task. As for the classification, deep CNNs, ResNext [
26] based classifiers, and LSTMs are utilized. There are different class definition approaches in COVID-19 related studies, such as binary or multi-class. Binary classification is usually applied for COVID pneumonia and non-COVID pneumonia [
17,
22] or COVID-positive and COVID-negative [
19,
21]. Multiclass classification separates COVID-negative further into COVID pneumonia, non-COVID pneumonia and no pneumonia [
14,
15,
16,
18,
20]. For radiologists diagnosing hundreds of patients with COVID pneumonia and distinguishing COVID pneumonia and non-COVID pneumonia in a short time is challenging. Therefore, a multi-class classifier is beneficial to radiologists for making a fast diagnosis.
Another important difference in the methods applied among the related studies is the use of slice-based or patient-level labeling. While most COVID-19 classification studies exploit slice-based CT image labels [
15,
17,
18,
20,
21,
22] because of its convenience, it has a significant labor cost requiring manual labeling of slices by radiologists. Therefore, patient-level labeling has also been used [
14,
16,
19] instead of slice-based labeling, where slice-based features can be obtained with the help of deep learning methods. Notwithstanding, the studies making patient-level predictions apply restrictions on the input slice size of a single CT volume, causing information loss. These are done via random selection or interpolation.
At the beginning of the outbreak, most infected patients were diagnosed with pneumonia with unknown causes [
27]. The resemblance between the chest CT scans of patients with COVID-19 and non-COVID pneumonia made identification of the disease difficult. Therefore, it is crucial to distinguish between non-COVID pneumonia and pneumonia caused by COVID-19. To achieve this, we developed a multi-class deep learning model for diagnosing COVID-19 disease, which can identify COVID-19 pneumonia, non-COVID pneumonia, and healthy patients from chest CT scans. The main contributions of this work are as follows: (1) AI-assisted medical imaging detection of COVID-19 pneumonia and non-COVID-19 pneumonia for radiologists with high specificity and sensitivity (2) proposing an efficient model which can utilize inference task using moderate memory and computational power. (3) Implementation of our two-staged deep learning framework in selected Turkish hospitals. The dataset used in this study was provided by a Turkish hospital.
2. Materials and Methods
2.1. Dataset
The dataset used in this study consists of 26,935 CT images of 348 patients with varying numbers from 13 to 261 for each patient. For each CT slice image, the labels of the patients were used. The dataset was supplied by American Hospital and labeled by their expert radiologists. CT images were exported onto a local server from the CT machines via the picture archiving and communication systems (PACS) in DICOM format. All slices were converted to PNG format with adaptive histogram equalization.
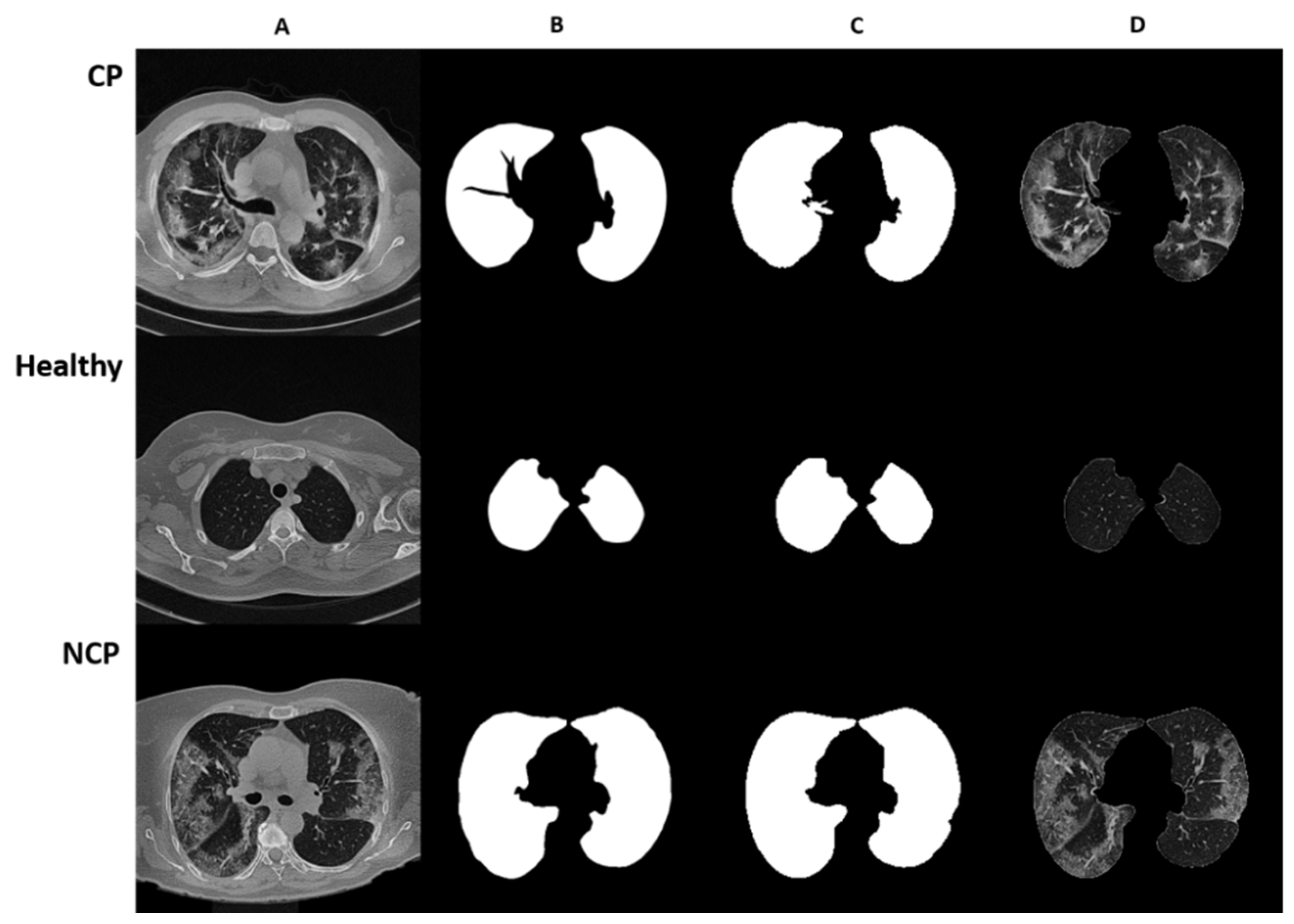
In this study, three subclasses, COVID Pneumonia (CP), Non-COVID Pneumonia (NCP), and healthy, were used. Out of 348 patients, 270 were assigned to the training set and 78 to the test set with these three subclasses. The distribution of the dataset is given in
Table 1. For each of the three subclasses, CT slice images are represented in
Figure 1 with original, manually segmented, AI-based segmented, and final merged format.
2.2. Preprocessing
The spatial resolution of the CT images is 512 pixels, and slice thicknesses are between 0.75 and 5.0 mm. In the image preprocessing step, CT images were scaled to 256 × 256 pixels. To eliminate redundant information in lung CT slices, CT slices were segmented, and the obtained masks were used to eliminate small lungs. The slices of each patient were grouped to have 50 slices in each group to feed the network.
2.2.1. Lung Segmentation
U-Net [
23] medical image segmentation architecture was used for CT slices segmentation. In this study, U-Net architecture was trained from scratch since it is not designed for CT images. The segmentation helped to reduce the background information and assisted the classifier model by focusing on the areas with pneumonia characteristics.
The segmentation model was trained with 301 manually annotated CT slice images. The validation set was assigned randomly from 10% of the annotated dataset. The model was trained for 30 epochs achieving 0.9681 Dice-Coefficient Index proving an accurate segmentation. The learning rate of the segmentation model was set to 2 × 10−5. For data augmentation, rotating, flipping, blurring, and brightening were used. The generalization of the model was increased by applying augmentation in a random range with a randomly selected augmentation type through a data generator.
2.2.2. Segmentation-Based Elimination
The areas containing no lung information were eliminated. CT slices having small lung regions were also eliminated since those were not supplying valuable information on pneumonia characteristics. The original CT slices were masked by the ratio obtained by the maximum CT lung area. Threshold values of 0.4 for the up-side of the lung and 0.9 for the down-side of the lung were used for masking. The segmentation mask was applied to those having a scaled CT lung area smaller than the defined thresholds.
2.2.3. Slice Grouping
In this study, we adopted patient-based labeling without imposing any restrictions on input size not to have any information loss. A patient-based labeled dataset requires the number of slices in a group, which has to be defined considering the number of occurrences of pneumonia characteristics. We grouped CT images since each slice can contribute to pneumonia characteristics. We set the group size to be 50 CT slices since an exact number of slices needs to be fed to the network. In the studied dataset, the number of slices ranges from 13 to 261, as mentioned in
Section 2.1. Therefore, in case the number of slices for a patient was not divisible by 50: when there were more than 25 slices remaining, the last group of slices was augmented with padding of black images, and when there were fewer than 25 slices remaining, then the number of slices in the last two groups were downsampled to 50 using interpolation.
2.3. Deep Learning Model
In this study, CNNs were used to obtain feature maps of CT slices, and bidirectional LSTMs were used for classification. This framework was applied to CT Volumes consisting of multiple CT slices for each patient. CT groups generated from CT slices for each patient were fed to the bidirectional LSTM. Then, segmented and eliminated CT groups of each patient were processed by the framework.
Two separate steps of training were performed in an end-to-end pipeline. Initially, the slices were fed to the proposed Convolutional Neural Network block for extracting spatial features. Once the spatial features were extracted from each slice, the feature maps were given to the bidirectional LSTM. The bidirectional LSTM makes the classification for the CT group by exploiting the axial dependency in the input slices and transforming the spatial features to axial features. Finally, label-based majority voting was performed for classification outputs of multiple CT groups for a particular patient. The proposed framework was motivated by the detection of violence in video frames by Hanson et al. [
28].
The proposed framework was trained on a machine with a 4 NVIDIA Tesla V100 GPU and implemented on the Python programming language using the Keras library with Tensorflow backend.
2.3.1. Convolutional Neural Network
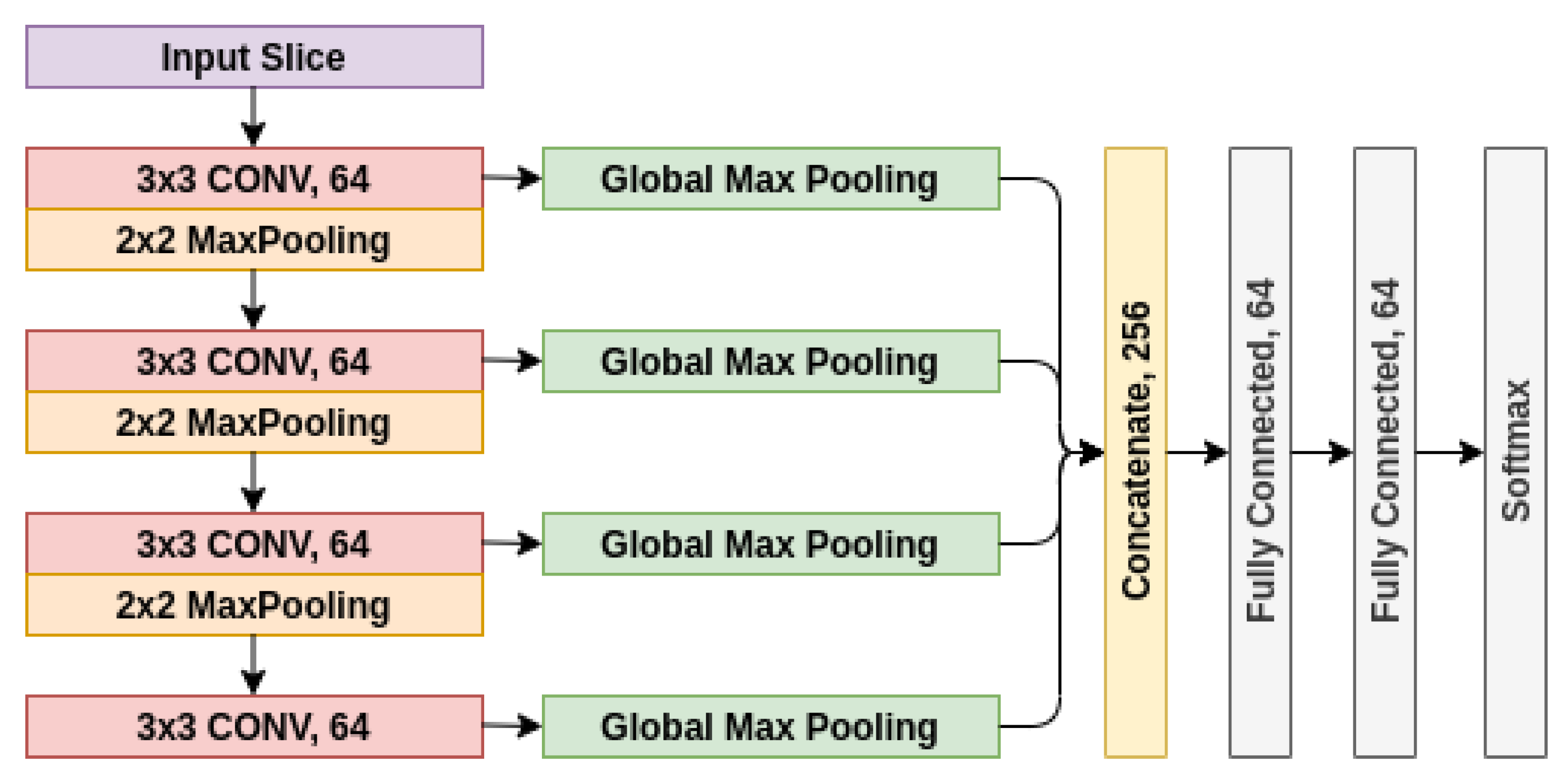
The proposed architecture was formed of 4 convolutional layers with ReLU activation function whose outputs were concatenated after applying Global Max Pooling operations. The architecture of the network is shown in
Figure 2. This concatenation ensures that features from all layers are used equally.
Most of the related studies use pre-trained classification models [
14,
15,
19,
29]; however, these architectures are not particularly designed for the classification of CT volumes. The architectures such as ResNet [
30] and Inception [
31] are designed for the ImageNet dataset [
32], where the images contain a wide variety of objects. For the ImageNet classification task, a large set of features must be learned for inference; hence, deeper networks need to be utilized. On the other hand, CT volumes can be inferred with smaller feature maps in comparison to ImageNet. The CNN encoder architecture is designed to be more efficient in terms of both memory and runtime inference.
The main purpose of training these CNN blocks is to obtain feature maps of ground glass opacities (GGO) which are prevalent in COVID pneumonia [
7,
33]. After training, the infection feature maps belonging to each slice were fed to the bidirectional LSTM to maintain the relationship between slices.
All layer weights were initialized randomly. The CNNs were trained for 100 epochs with an early stopping set to 25 epochs to avoid overfitting. The learning rate is set to 1e-4. The categorical cross-entropy loss function was used to calculate the loss between predictions and ground-truth labels. Rotating, flipping, blurring, and brightening were used as data augmentation techniques. A data generator augments data at each step in a random range with a randomly selected augmentation type to increase the generalization of the model.
2.3.2. Bidirectional LSTM Based Classifier
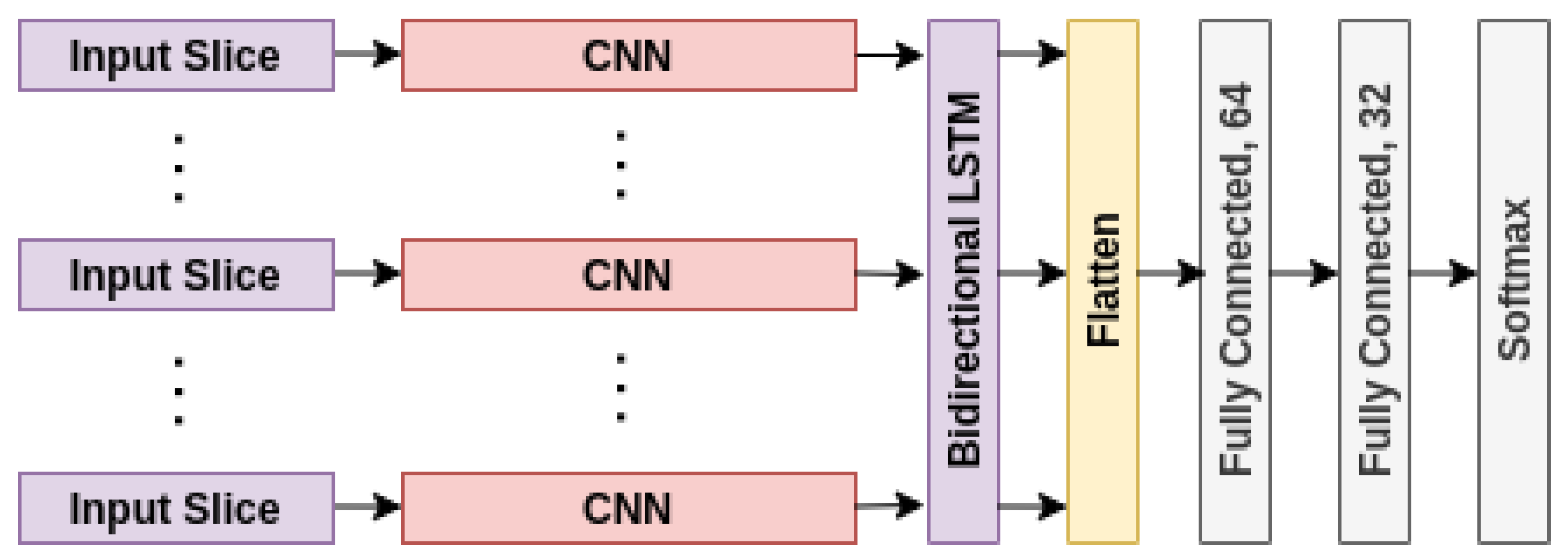
The concatenation of the output of CNN blocks for each CT slice was fed to bidirectional LSTM. The sequence model was used to emphasize the relationship between spatial feature maps of multiple and ordered CT slices. Since this relationship is both forward and backward, a bidirectional sequence model was used. The output of each bidirectional LSTM cell was preserved and flattened. It is assumed that each cell output has equal importance given the fact that spatial feature maps are agnostic in terms of the amount of infection in the lungs. The aggregated features obtained from bidirectional LSTM were then transferred to a dense layer with dropout. The obtained output of the final dense layer is a multi-class classifier of three classes for each CT group of a single patient. The architecture of the network is shown in
Figure 3.
CNN blocks (explained in detail in
Section 2.2.2) were initialized with the weights of feature extracting layers. CNN weights were frozen, and the rest were initialized randomly. The classifier was trained for 200 epochs with an early stopping set to 25 epochs to avoid overfitting. The same parameters used for the CNN were used for biLSTM (see
Section 2.3.2).
2.4. Performance and Assessment
In the case of patients having more than one CT group, label-based majority voting was applied. First, the label with the highest classification probability for each group was selected. Next, the label having the majority vote was assigned to the label of the patient. When the output was healthy, and the group was classified as NCP or CP, the probability of non-healthy class was checked further. When the probability was greater than the predefined threshold (0.9), the label changed in favor of the non-healthy class.
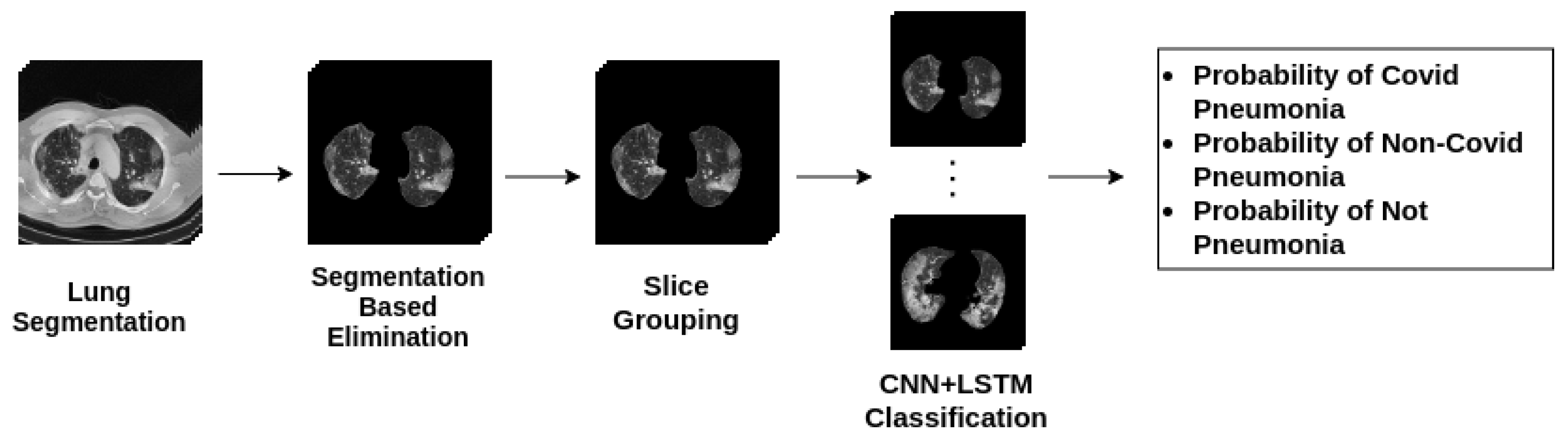
Accuracy, specificity, sensitivity, and f1-score were calculated from the label-based majority voting method outputs since pneumonia infections might not be apparent in all slices of a patient. The flowchart for the algorithm is illustrated in
Figure 4.
3. Results
CT images collected from the PACS server were preprocessed then fed to the CNN + biLSTM network. CNN blocks were used for obtaining feature maps of ground glass opacities (GGO), then feature maps were fed to the biLSTM network, which maintained the relationship between spatial feature maps of multiple and ordered CT slices. The framework was designed to be efficient in runtime inference. As a result of this approach, the average inference runtime for each CT group in our test set is 0.106 s with a single NVIDIA RTX 2060 GPU and 0.409 s with an Intel i7-9750H CPU. The proposed network performance was evaluated on an independent test set. Accuracy, specificity, sensitivity, and f1-score for each class were calculated and summarized in
Table 2.
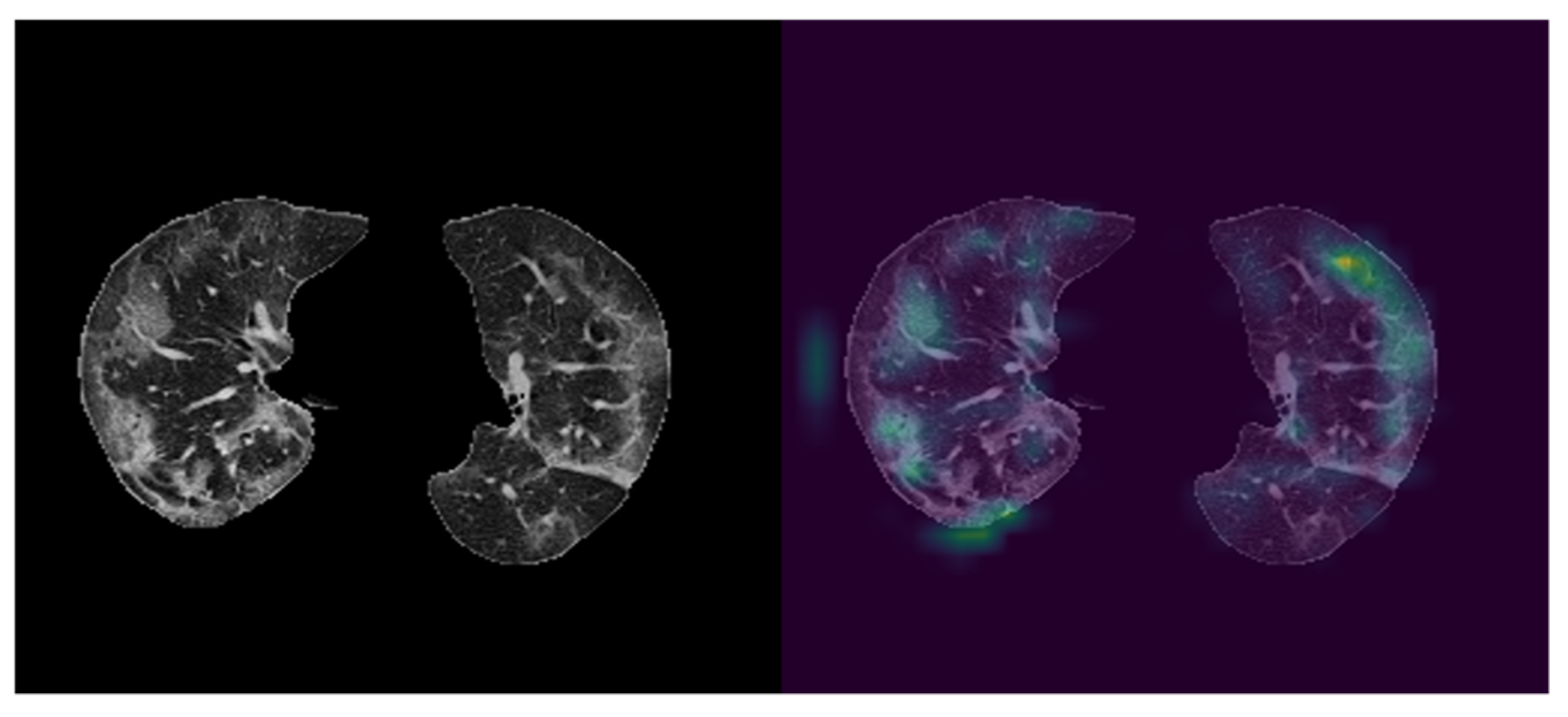
CNN blocks of the proposed network were utilized to obtain feature maps of ground glass opacities (GGO). To illustrate the effectiveness of the approach used in this study, the last class activation map (CAM) was visualized with the help of Grad-CAM (
Figure 5). As it can be seen from
Figure 5, features were primarily extracted from ground glass opacities.
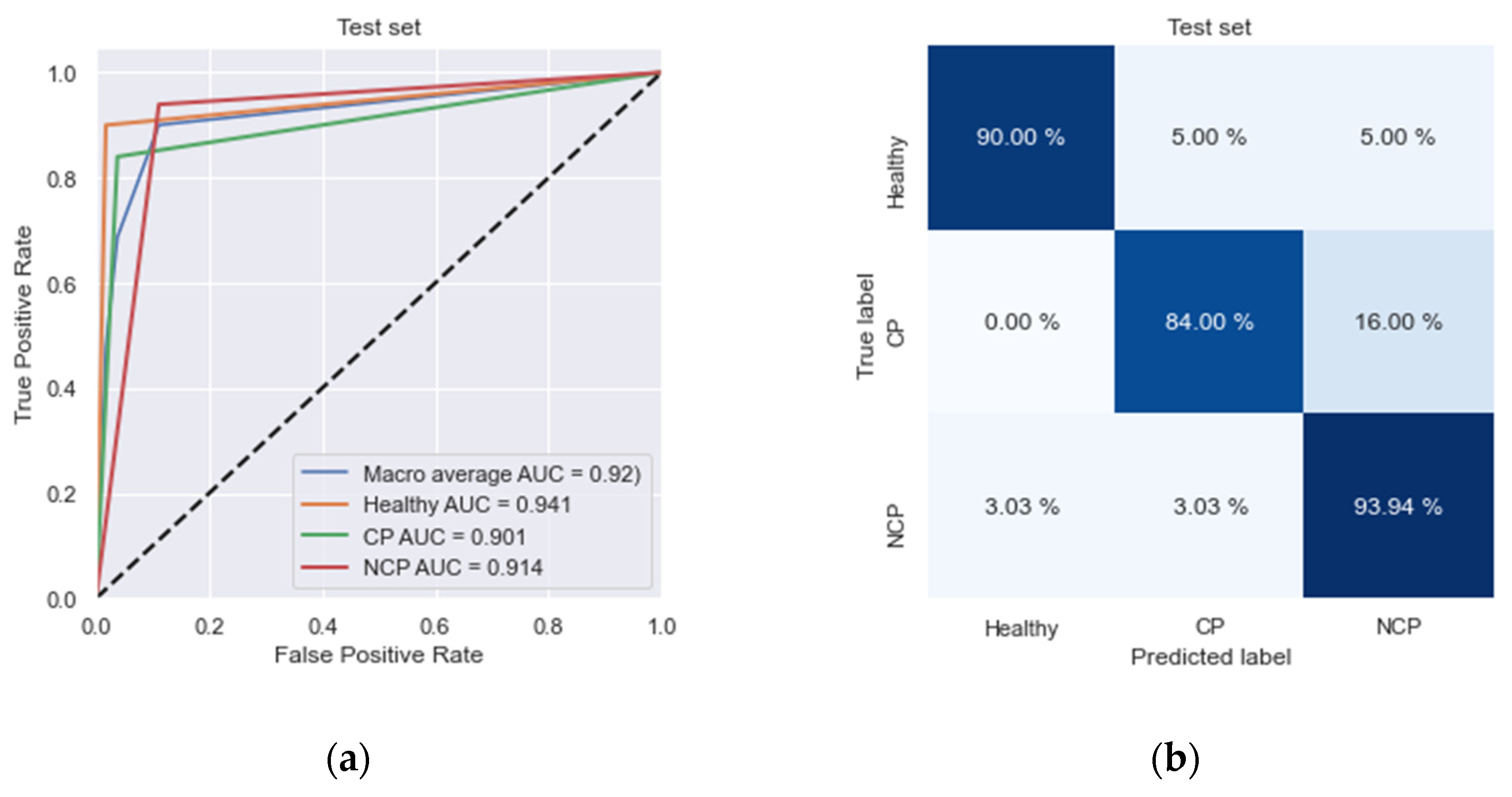
On an independent test dataset, we achieved high specificity (98.3%) and high sensitivity (84%) rates in the detection of COVID-19. Moreover, we obtained high specificity (96.2%) and high sensitivity (93.9%) rates in the detection of non-COVID-19 pneumonia as well (
Table 2). The areas under receiver operating characteristics for COVID-19 and non-COVID-19 pneumonia were 0.90 and 0.91, respectively (
Figure 6a).
The same algorithm (
Figure 4) was applied for each patient in the test set and represented. By comparing the patients’ ground-truth labels, ROC curves and confusion matrix are plotted as shown in
Figure 6. In the ROC curve, we obtained a macro average AUC value of 0.92.
Table 2 shows the classification results of the patients. Our network classifies NCP patients more accurately (93.9%) than other labels, and its overall accuracy is 89.7%.
Specificity and sensitivity are mostly used for evaluating diagnosis applications. Our model’s specificity value for CP patients is 98.3%, and for NCP patients, it is 96.2%. These values show that our model can classify pneumonia-affected patients efficiently.
4. Discussion
In this work, we designed and implemented a two-staged deep learning model for the diagnosis of COVID-19 disease from chest CT volumes. Our model was able to assist the radiologists with its performance of high specificity (CP: 98.3%, NCP: 96.2%) and high sensitivity (CP: 84%, NCP: 93.9%) rates in the detection of COVID-19 pneumonia and non-COVID-19 pneumonia. This study offers a solution with reduced time and effort for diagnosing CP and NCP, as well as distinguishing healthy patients. This work was especially motivated to be easily implemented and used in the COVID-19 pandemic to manage the overwhelming workload.
We were able to collect a large number of chest CT scans from American Hospital in Turkey. The dataset included a total of 26,935 CT scans belonging to 348 distinct patients. We used patient-based labeling due to its effectiveness both in cost and time. Although slice-based labeling is advantageous for deep learning methods, these slice-based features can be obtained via CNNs. The use of slice-based or patient-based labeling was among the differences in the model architectures used in the related studies (see
Table 3 for all compared features). We implemented a grouping method for the varying numbers of slices in the CT Volumes dataset. There are other methods like performing interpolations on CT Volumes or random selection of slices of a CT Volume; however, these cause information loss. Another advantage of the grouping method was exploiting every single slice of every patient. Since we grouped the CT slices of the patients, the evaluation of the class probabilities of groups was done by utilizing the majority-voting method.
In
Table 3, we report a summary of the previous works that are focusing on multi-class classification on chest CT scans distinguishing COVID-19 pneumonia from community-acquired pneumonia and healthy patients. The only exception is the study from El-bana et al. [
29], compartmentalizing community-acquired pneumonia by viral and bacterial. In this table, we compared the related studies with our work in terms of number and types of classes, sample size as well as architectures used for segmentation and feature extraction tasks. Furthermore, the use of pre-trained models was examined for both segmentation and feature extraction methods. The studies using sequence models to relate CT scans in a CT volume were also noted. Unlike other studies using prominent segmentation architectures, in this study, we trained on our dataset of chest CT scans since U-Net is not trained on chest CT scans.
We designed an efficient architecture to be readily used in every hospital. Since deeper architectures require high memory and high computing power, not every hospital has a suited infrastructure to fulfill those requirements. Our model utilizes inference tasks with moderate memory and computational power (0.409 s average runtime for each CT group on CPU). This work has several limitations. Foremost, we used a single dataset from a single hospital since this study was an immediate response to an urgent need. Correspondingly, this dataset is collected from a particular type of CT machine. It would be desirable to work with other datasets from other hospitals. Hence, we are in the process of collaborating with other hospitals. Nonetheless, we believe our study is a compatible and fast response to the hospitals in need. Our proposed framework can help relieve the burden on radiologists and reduce the time to diagnose COVID-19 pneumonia and non-COVID-19 pneumonia. In addition, our framework can decrease misdiagnosis of CP and NCP thanks to its high specificity and sensitivity rates.
Although explainability and interpretability are major concerns for deep learning models, there have been significant efforts in explaining the decisions of deep learning models used for medical diagnosis. Since the doctors are going to make decisions for patients relying on the AI system, it is useful to understand why the AI system makes one choice over another. There are many methods developed to explain deep learning methods trained on medical images [
34], such as Grad-CAM [
35]. With this in mind, we visualized the feature maps generated via Grad-CAM to provide insight into our framework.
We further evaluated Grad-CAM consistency by calculating the effect of different perturbations. We compared four perturbed states: clockwise rotated, counterclockwise rotated, 30 pixels x-axes and −15 pixels y-axes translated, and −20 pixels x-axes and 15 pixels y-axes translated (see
Figure S1). We used cosine similarity (CS) to measure the effect of perturbations applied on the feature map of the original image (
) and the perturbed one (
) (see
Supplementary Materials for the Equation). The average similarity between the feature map of the original image and the feature maps of the perturbed images was 0.98. The two vectorized maps are similar when CS is close to 1; therefore, calculated similarity indicates Grad-CAM consistency.
5. Conclusions
Fast and accurate diagnosis of COVID-19 forms a challenge for all countries. The available tests for fast diagnosis either have sensitivity or accuracy problems. In this regard, chest CT scans were found to be very effective in identifying COVID-19 patients. This method showed a superior practice over other methods by its power in identifying COVID-19 patients even who are at the very early stages of the disease or patients with no symptoms. In addition to this, there is a pronounced level of confirmed cases causing an additional demand for healthcare workers.
We built an AI system that can accurately differentiate COVID-19 pneumonia patients and non-COVID-19 pneumonia patients. The framework is implemented and ready for use to assist radiologists. Our two-staged deep learning classifier enables us to identify CP, NCP, and healthy patients from chest CT volumes. First, this framework is capable of learning pneumonic features in CT scans. Second, it can classify COVID-19 pneumonia and non-COVID-19 pneumonia with 84% and 93.9% accuracy. Our model achieves high specificity for CP: 98.3% and NCP: 96.2% and high sensitivity for CP: 84% and NCP: 93.9%. We have further analyzed the area under receiver operating characteristics curve (ROC-AUC) to demonstrate the effectiveness and efficiency of our proposed framework. We provide an AI system for automated, fast, and accurate diagnosis of COVID-19 using medical imaging technologies. Along with recent efforts in radiology, we demonstrate a promising COVID-19 pneumonia classification using chest CTs augmented with the help of deep learning methodologies. We showed that our system is assisting the radiologists. It is implemented in real-time in selected hospitals through a user interface.
As a next step, we showed that our framework is able to detect Ground Glass Opacities (GGO) in patients suffering from COVID-19 pneumonia via visualizations using Grad-CAM algorithm [
35]. Image pixel attributions can be visualized upon calculating the gradient from the output to a given deeper layer. Grad-CAM reconstructs maps as a weighted combination of forward neuron activation, with weights based on global average pooling and backpropagation outputs to a target layer. This way, COVID-19 patients can be distinguished from the others by providing a demonstration of the proposed models with pneumonia indicating top features. Note that this framework identifies not only CP but also NCP owing to its capability to generate two-dimensional feature maps. This can be easily further compartmentalized for additional pneumonia types according to the needs of the hospitals and healthcare workers. Overall, our work offers an easily adaptable framework that has already been implemented and is being used. As such, it offers implementation in numerous hospitals with low computing powers.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}