
A Performance Comparison and Enhancement of Animal Species Detection in Images with Various R-CNN Models


Abstract
:1. Introduction
2. Related Work in Detection
2.1. Object Detection
2.2. Animal Species Detection
3. Overview of CNN
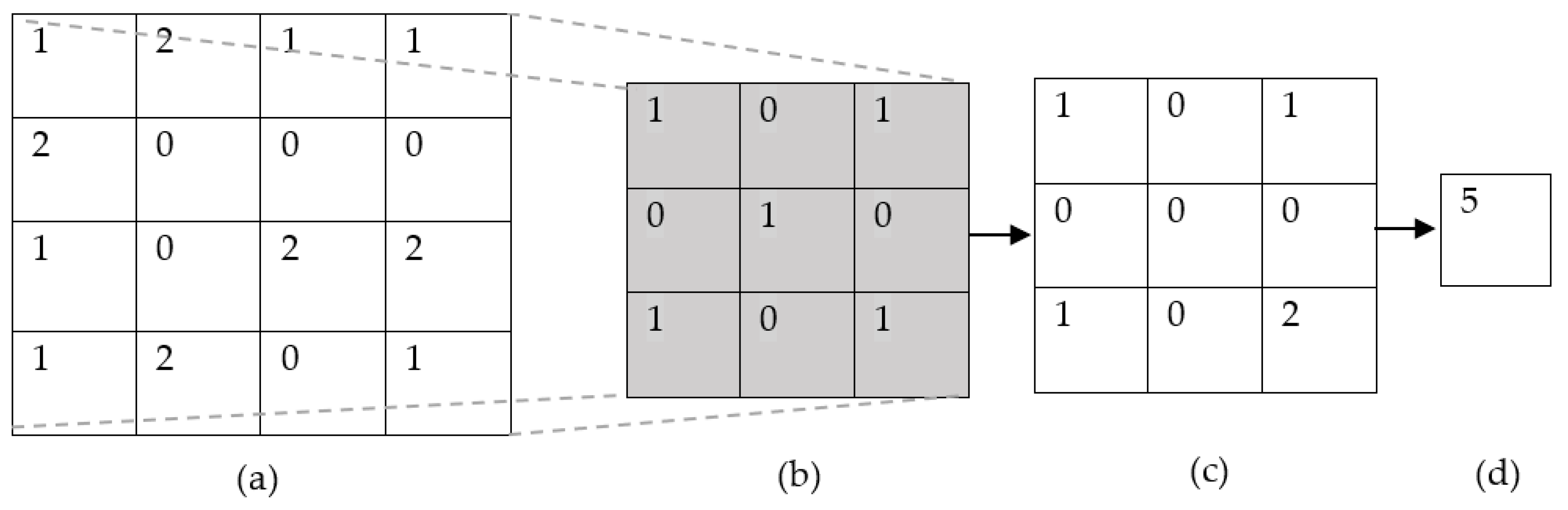
3.1. Regular CNN
3.2. D-CNN
4. R-CNN Models
4.1. R-CNN
- Network processing is expensive and slow due to the use of selective search algorithm, where hundreds to thousands of region proposals need to be classified for each image.
- R-CNN sometimes generates bad candidate region proposals as the selective search is a fixed algorithm which has no learning capabilities.
4.2. Fast R-CNN
4.3. Faster R-CNN
4.4. Mask R-CNN
5. Animal Datasets
5.1. Datasets Used in Our Study
5.2. Limitations of Datasets
6. Methodology of Animal Species Detection
6.1. Features Enhancement
6.2. Training
7. Experimental Results of Animal Species Detection
7.1. Performance Evaluation Metrics
7.2. Comparison Results and Discussion
- Three datasets of different characteristics have been used for training and testing.
- Deformable convolutional layers have been added to the R-CNN detectors, which have a great effect on enhancing the extracted features, which in turn improve the performance of animal species detection.
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 7 January 1998; pp. 555–562. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: A Backbone network for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, L.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In European Conference on Computer Vision; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2014; Volume 8689 LNCS, pp. 818–833. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Schneider, S.; Taylor, G.W.; Kremer, S. Deep Learning Object Detection Methods for Ecological Camera Trap Data. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 321–328. [Google Scholar]
- Swinnen, K.; Reijniers, J.; Breno, M.; Leirs, H. A Novel Method to Reduce Time Investment When Processing Videos from Camera Trap Studies. PLoS ONE 2014, 9, e98881. [Google Scholar] [CrossRef] [Green Version]
- Figueroa, K.; Camarena-Ibarrola, A.; Garcia, J.; Villela, H.T. Fast Automatic Detection of Wildlife in Images from Trap Cameras. Hybrid Learn. 2014, 8827, 940–947. [Google Scholar]
- Yu, X.; Wang, J.; Kays, R.; Jansen, P.; Wang, T.; Huang, T. Automated identification of animal species in camera trap images. EURASIP J. Image Video Process. 2013, 2013, 52. [Google Scholar] [CrossRef] [Green Version]
- Kwan, C.; Gribben, D.; Tran, T. Multiple Human Objects Tracking and Classification Directly in Compressive Measurement Domain for Long Range Infrared Videos. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 0469–0475. [Google Scholar]
- Uddin, M.S.; Hoque, R.; Islam, K.A.; Kwan, C.; Gribben, D.; Li, J. Converting Optical Videos to Infrared Videos Using Attention GAN and Its Impact on Target Detection and Classification Performance. Remote Sens. 2021, 13, 3257. [Google Scholar] [CrossRef]
- Chen, G.; Han, T.X.; He, Z.; Kays, R.; Forrester, T. Deep convolutional neural network based species recognition for wild animal monitoring. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 858–862. [Google Scholar]
- Villa, A.G.; Salazar, A.; Vargas, F. Towards automatic wild animal monitoring: Identification of animal species in camera-trap images using very deep convolutional neural networks. Ecol. Inform. 2017, 41, 24–32. [Google Scholar] [CrossRef] [Green Version]
- Willi, M.; Pitman, R.T.; Cardoso, A.W.; Locke, C.; Swanson, A.; Boyer, A.; Veldthuis, M.; Fortson, L. Identifying animal species in camera trap images using deep learning and citizen science. Methods Ecol. Evol. 2019, 10, 80–91. [Google Scholar] [CrossRef] [Green Version]
- Norouzzadeh, M.S.; Morris, D.; Beery, S.; Joshi, N.; Jojic, N.; Clune, J. A deep active learning system for species identification and counting in camera trap images. Methods Ecol. Evol. 2021, 12, 150–161. [Google Scholar] [CrossRef]
- Norouzzadeh, M.S.; Nguyen, A.; Kosmala, M.; Swanson, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Natl. Acad. Sci. USA 2018, 115, E5716–E5725. [Google Scholar] [CrossRef] [Green Version]
- Parham, J.; Stewart, C. Detecting plains and Grevy’s Zebras in the realworld. In Proceedings of the 2016 IEEE Winter Applications of Computer Vision Workshops (WACVW), Lake Placid, NY, USA, 10 March 2016. [Google Scholar]
- Zhang, Z.; He, Z.; Cao, G.; Cao, W. Animal Detection from Highly Cluttered Natural Scenes Using Spatiotemporal Object Region Proposals and Patch Verification. IEEE Trans. Multimed. 2016, 18, 2079–2092. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Falzon, G.; Kwan, P.; Guo, L.; Chen, G.; Tait, A.; Schneider, D. Automated cattle counting using Mask R-CNN in quadcopter vision system. Comput. Electron. Agric. 2020, 171, 105300. [Google Scholar] [CrossRef]
- Gupta, S.; Chand, D.; Kavati, I. Computer Vision based Animal Collision Avoidance Framework for Autonomous Vehicles. Inf. Process. Manag. Uncertain. Knowl.-Based Syst. 2021, 1378, 237–248. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and Transferring Mid-level Image Representations Using Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar] [CrossRef] [Green Version]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Weakly supervised object recognition with convolutional neural networks. HAL 2014. Available online: https://hal.inria.fr/hal-01015140v1.
- Kavukcuoglu, K.; Ranzato, M.; Fergus, R.; LeCun, Y. Learning invariant features through topographic filter maps. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1605–1612. [Google Scholar]
- Goodfellow, I.; Bengio, Y.B.; Courville, A. Adaptive Computation and Machine Learning Series (Deep Learning); The MIT Press: Cambridge, MA, USA, 2016; Available online: Academia.edu (accessed on 15 August 2020).
- Bishop, C.M. Pattern Recognition, and Machine Learning; Springer: New York, NY, USA, 2006; Volume 128, pp. 1–58. Available online: Academia.edu (accessed on 15 August 2020).
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Ding, S.; Zhang, X.; An, Y.; Xue, Y. Weighted linear loss multiple birth support vector machine based on information granulation for multi-class classification. Pattern Recognit. 2017, 67, 32–46. [Google Scholar] [CrossRef]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding Box Regression With Uncertainty for Accurate Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2019; pp. 2883–2892. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Convolutional feature masking for joint object and stuff segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2015; pp. 3992–4000. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Prokudin, S.; Kappler, D.; Nowozin, S.; Gehler, P. Learning to Filter Object Detections. In Transactions on Computational Science XI; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2017; Volume 10496, pp. 52–62. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Instance-Aware Semantic Segmentation via Multi-task Network Cascades. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2016; pp. 3150–3158. [Google Scholar]
- Arnab, A.; Torr, P.H.S. Pixelwise Instance Segmentation with a Dynamically Instantiated Network. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 879–888. [Google Scholar]
- Wu, H.; Siebert, J.P.; Xu, X. Fully Convolutional Networks for automatically generating image masks to train Mask R-CNN. arXiv 2020, arXiv:2003.01383v1. [Google Scholar]
- Labeled Information Library of Alexandria: Biology and Conservation (LILA BC). [Snapshot Serengeti]. Available online: http://lila.science/datasets/snapshot-serengeti (accessed on 27 August 2020).
- Snapshot Wisconsin, A Volunteer-Based Project for Wildlife Monitoring. [Snapshot Wisconsin]. Available online: https://dnr.wisconsin.gov/topic/research/projects/snapshot (accessed on 1 May 2020).
- Fan, Q.; Brown, L.; Smith, J. A closer look at Faster R-CNN for vehicle detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gotenburg, Sweden, 19–22 June 2016; Volume 1, pp. 124–129. [Google Scholar]
- MATLAB. Available online: https://www.mathworks.com/help/vision/ug/get-started-with-the-image-labeler.html (accessed on 15 January 2020).
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Henderson, P.; Ferrari, V. End-to-End Training of Object Class Detectors for Mean Average Precision. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 198–213. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Gupta, D.K.; Singh, S. An Animal Detection and Collision Avoidance System Using Deep Learning. Adv. Graph. Commun. Packag. Technol. Mater. 2021, 668, 1069–1084. [Google Scholar] [CrossRef]
- Yilmaz, A.; Uzun, G.N.; Gurbuz, M.Z.; Kivrak, O. Detection and Breed Classification of Cattle Using YOLO v4 Algorithm. In Proceedings of the 2021 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Kocaeli, Turkey, 25–27 August 2021; pp. 1–4. [Google Scholar]
- Sato, D.; Zanella, A.J.; Costa, E.X. Computational classification of animals for a highway detection system. Braz. J. Veter-Res. Anim. Sci. 2021, 58, e174951. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pre-Trained Models | Accuracy of Animal Identification |
|---|---|
| AlexNet | 93.1% |
| GoogleNet | 95.9% |
| VGG-16 | 96.8% |
| VGG-19 | 96.3% |
| ResNet-18 | 96.8% |
| ResNet-50 | 97.1% |
| ResNet-101 | 97.6% |
| References | Year | Dataset | Performance | Technique |
|---|---|---|---|---|
| Parham et al. [39] | 2016 | 2500 images of Plain and Grevy zebras | mAP of zebra detection: 55.6% for Plain and 56.6% for Grevy | YOLOv1 detector |
| Norouzzadeh et al. [37] | 2019 | Snapshot Serengeti | Accuracy of animal species detection 92.9% | Deep active learning |
| Xu et al. [41] | 2020 | 750 images of cattles | Accuracy of cattle detection: 94% | Mask R-CNN |
| Gupta et al. [42] | 2020 | MS COCO dataset [15] | AP of detection: 79.47% for cows, and 81.09% for dogs | Mask R-CNN |
| Saxena et al. [64] | 2021 | 31,774 images of various animals | mAP of animal species detection: 82.11% | Faster R-CNN |
| Yılmaz et al. [65] | 2021 | 1500 images of cattle | Accuracy of cattle detection: 92.85% | YOLOv4 |
| Sato et al. [66] | 2021 | 2000 images of donkeys and horses | Accuracy of donkeys and horses: detection: 84.87% | YOLOv4 |
| Our work | 2021 | Snapshot Serengeti, BCMOTI, and Snapshot Wisconsin | Accuracy and mAP of animal species detection, respectively: 98.4% and 89.2% in Snapshot Serengeti, 93.3% and 82.9% in BCMOTI, 97.6% and 87.6% in Snapshot Wisconsin | Deformable Mask R-CNN |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibraheam, M.; Li, K.F.; Gebali, F.; Sielecki, L.E. A Performance Comparison and Enhancement of Animal Species Detection in Images with Various R-CNN Models. AI 2021, 2, 552-577. https://doi.org/10.3390/ai2040034
Ibraheam M, Li KF, Gebali F, Sielecki LE. A Performance Comparison and Enhancement of Animal Species Detection in Images with Various R-CNN Models. AI. 2021; 2(4):552-577. https://doi.org/10.3390/ai2040034
Chicago/Turabian StyleIbraheam, Mai, Kin Fun Li, Fayez Gebali, and Leonard E. Sielecki. 2021. "A Performance Comparison and Enhancement of Animal Species Detection in Images with Various R-CNN Models" AI 2, no. 4: 552-577. https://doi.org/10.3390/ai2040034
APA StyleIbraheam, M., Li, K. F., Gebali, F., & Sielecki, L. E. (2021). A Performance Comparison and Enhancement of Animal Species Detection in Images with Various R-CNN Models. AI, 2(4), 552-577. https://doi.org/10.3390/ai2040034