
A New Method to Compare the Interpretability of Rule-Based Algorithms


Abstract
:
1. Introduction
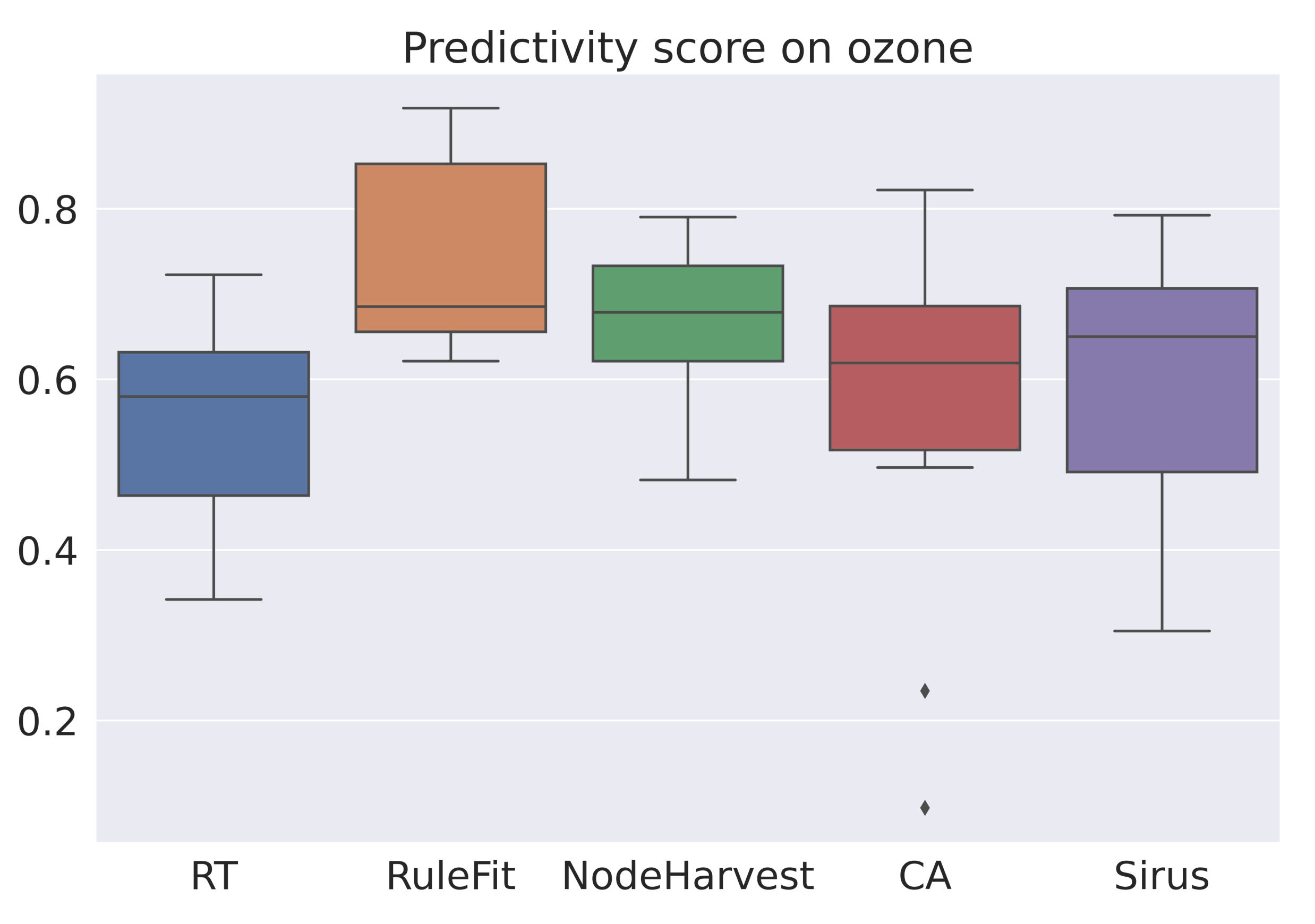
2. Predictivity Score
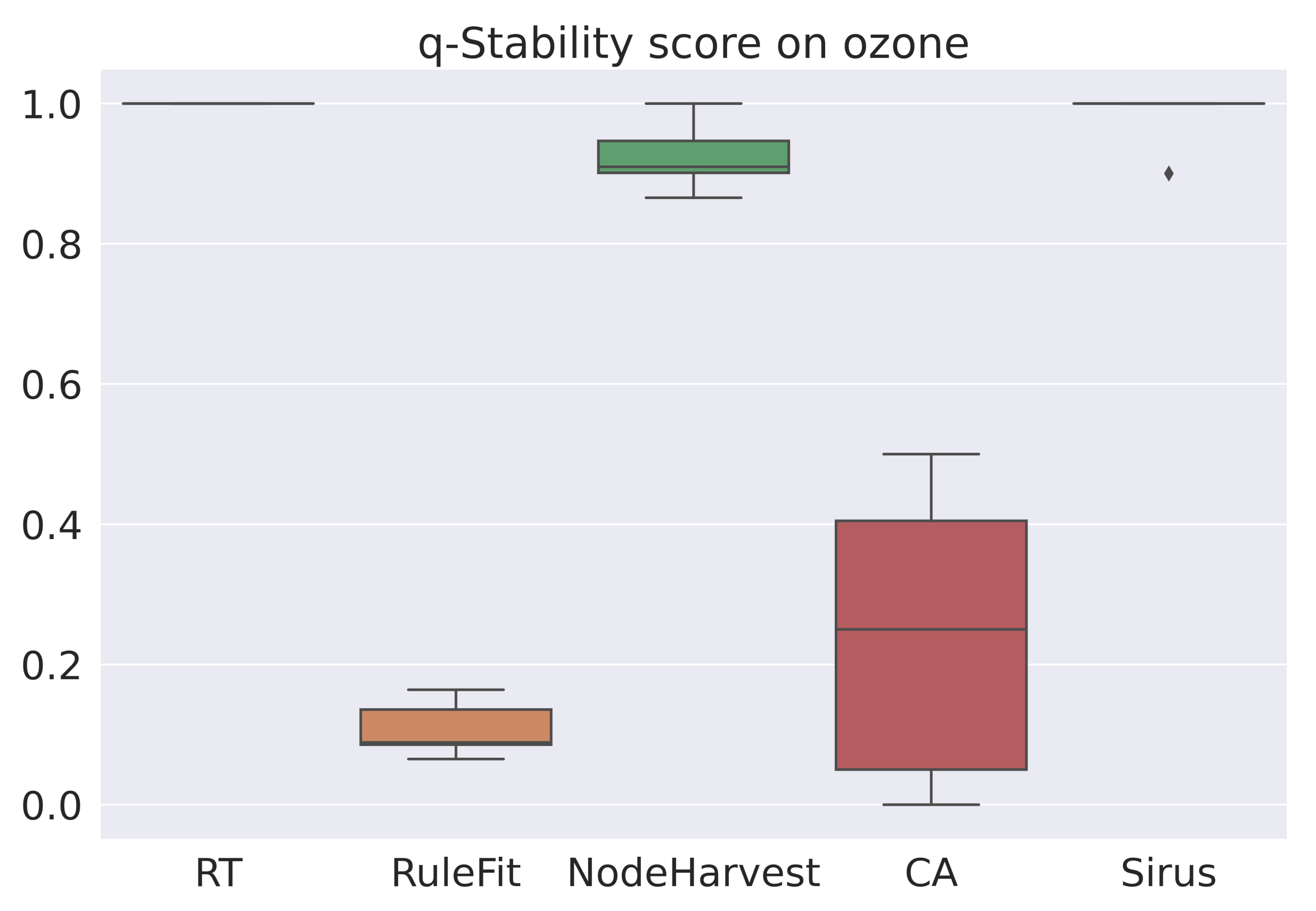
3. q-Stability Score
“A rule learning algorithm is stable if two independent estimations based on two independent samples, drawn from the same distribution , result in two similar lists of rules.”
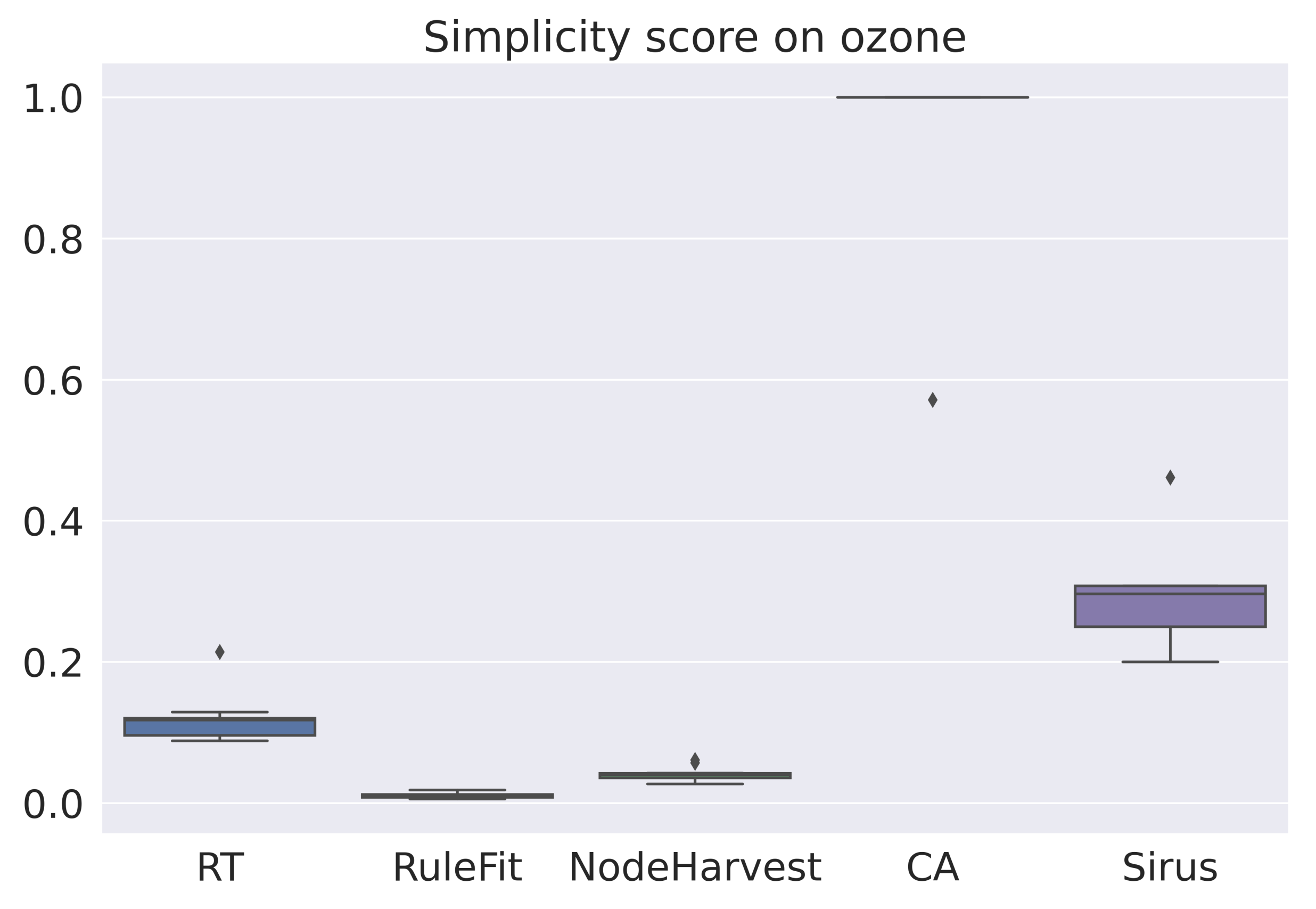
4. Simplicity Score
5. Interpretability Score
“the ability to explain or present to a person in an understandable form”
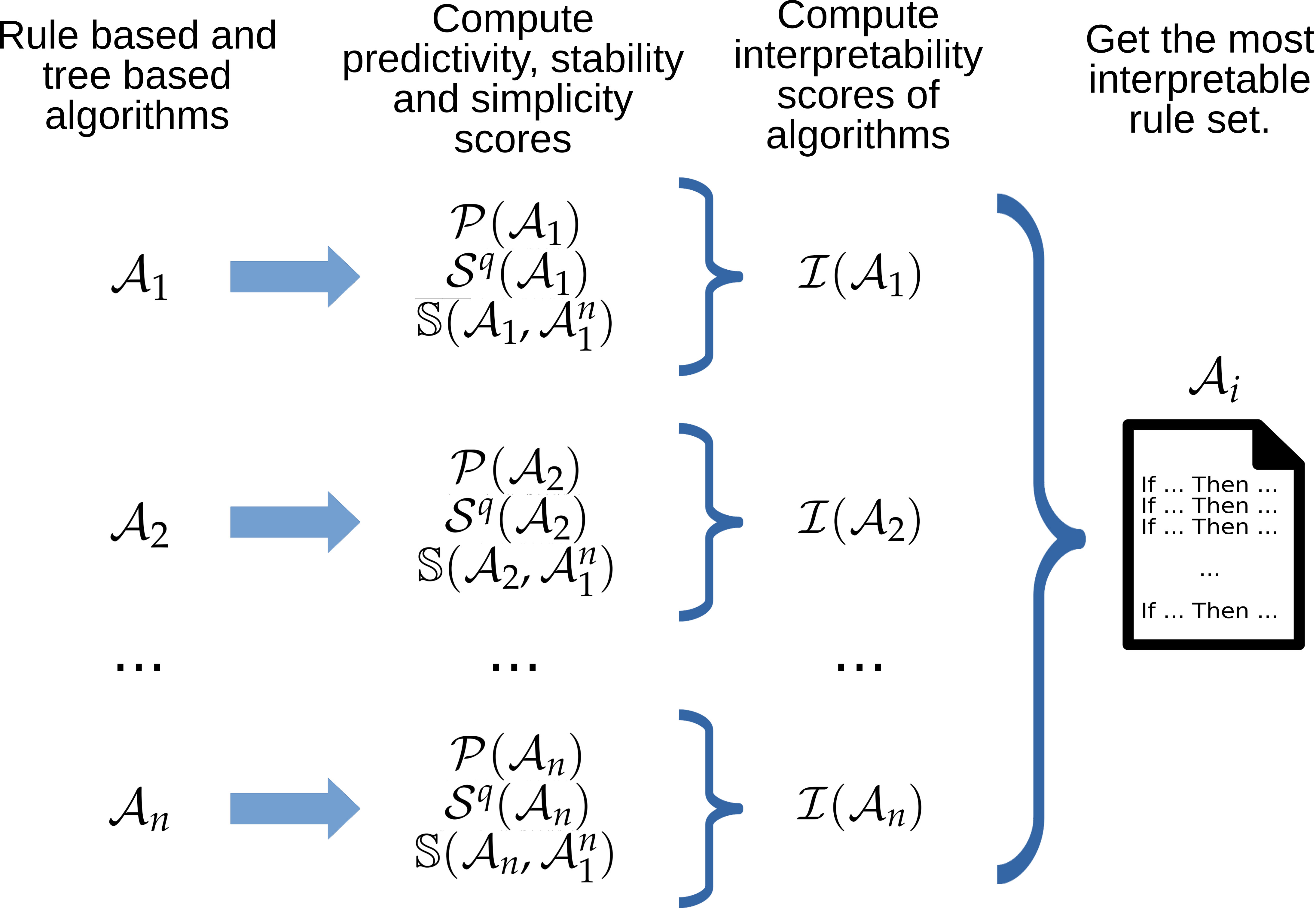
6. Application
6.1. Brief Overview of the Selected Algorithms
6.2. Datasets
6.3. Execution
6.4. Results for Regression
6.5. Results for Classification
7. Conclusions and Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Molnar, C. Interpretable Machine Learning. 2020. Available online: https://www.lulu.com (accessed on 25 May 2021).
- Molnar, C.; Casalicchio, G.; Bischl, B. Interpretable machine learning—A brief history, state-of-the-art and challenges. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Ghent, Belgium, 14–18 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 417–431. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. J. Comput. Graph. Stat. 2015, 24, 44–65. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you?: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4765–4774. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 1993. [Google Scholar]
- Wang, Y.; Witten, I.H. Inducing model trees for continuous classes. In Proceedings of the European Conference on Machine Learning, Prague, Czech Republic, 23–25 April 1997. [Google Scholar]
- Landwehr, N.; Hall, M.; Frank, E. Logistic model trees. Mach. Learn. 2005, 59, 161–205. [Google Scholar] [CrossRef] [Green Version]
- Cohen, W. Fast effective rule induction. In Machine Learning Proceedings; Elsevier: Amsterdam, The Netherlands, 1995; pp. 115–123. [Google Scholar]
- Karalič, A.; Bratko, I. First order regression. Mach. Learn. 1997, 26, 147–176. [Google Scholar] [CrossRef]
- Holmes, G.; Hall, M.; Prank, E. Generating rule sets from model trees. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Sydney, Australia, 6–10 December 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 1–12. [Google Scholar]
- Friedman, J.; Popescu, B. Predective learning via rule ensembles. Ann. Appl. Stat. 2008, 2, 916–954. [Google Scholar] [CrossRef]
- Dembczyński, K.; Kotłowski, W.; Słowiński, R. Solving regression by learning an ensemble of decision rules. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 22–26 June 2008; pp. 533–544. [Google Scholar]
- Meinshausen, N. Node harvest. Ann. Appl. Stat. 2010, 4, 2049–2072. [Google Scholar] [CrossRef] [Green Version]
- Bénard, C.; Biau, G.; Da Veiga, S.; Scornet, E. Sirus: Stable and interpretable rule set for classification. Electron. J. Stat. 2021, 15, 427–505. [Google Scholar] [CrossRef]
- Bénard, C.; Biau, G.; Veiga, S.; Scornet, E. Interpretable random forests via rule extraction. In Proceedings of the International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 13–15 April 2021; pp. 937–945. [Google Scholar]
- Margot, V.; Baudry, J.P.; Guilloux, F.; Wintenberger, O. Consistent regression using data-dependent coverings. Electron. J. Stat. 2021, 15, 1743–1782. [Google Scholar] [CrossRef]
- Lipton, Z.C. The mythos of model interpretability. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Yu, B.; Kumbier, K. Veridical data science. Proc. Natl. Acad. Sci. USA 2020, 117, 3920–3929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Interpretable machine learning: Definitions, methods, and applications. arXiv 2019, arXiv:1901.04592. [Google Scholar] [CrossRef] [Green Version]
- Hammer, P.L.; Kogan, A.; Simeone, B.; Szedmák, S. Pareto-optimal patterns in logical analysis of data. Discret. Appl. Math. 2004, 144, 79–102. [Google Scholar] [CrossRef] [Green Version]
- Alexe, G.; Alexe, S.; Hammer, P.L.; Kogan, A. Comprehensive vs. comprehensible classifiers in logical analysis of data. Discret. Appl. Math. 2008, 156, 870–882. [Google Scholar] [CrossRef] [Green Version]
- Alexe, G.; Alexe, S.; Bonates, T.O.; Kogan, A. Logical analysis of data—The vision of Peter L. Hammer. Ann. Math. Artif. Intell. 2007, 49, 265–312. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Bousquet, O.; Elisseeff, A. Stability and generalization. J. Mach. Learn. Res. 2002, 2, 499–526. [Google Scholar]
- Poggio, T.; Rifkin, R.; Mukherjee, S.; Niyogi, P. General conditions for predictivity in learning theory. Nature 2004, 428, 419–422. [Google Scholar] [CrossRef] [PubMed]
- Yu, B. Stability. Bernoulli 2013, 19, 1484–1500. [Google Scholar] [CrossRef] [Green Version]
- Letham, B.; Rudin, C.; McCormick, T.; Madigan, D. Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model. Ann. Appl. Stat. 2015, 9, 1350–1371. [Google Scholar] [CrossRef]
- Fayyad, U.M.; Irani, K.B. Multi-interval discretization of continuous-valued attributes for classification learning. In Proceedings of the 13th International Joint Conference on Artificial Intelligence, 28 August–3 September 1993; pp. 1022–1027. [Google Scholar]
- Margot, V.; Baudry, J.P.; Guilloux, F.; Wintenberger, O. Rule induction partitioning estimator. In Proceedings of the International Conference on Machine Learning and Data Mining in Pattern Recognition, New York, NY, USA, 15–19 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 288–301. [Google Scholar]
- Dougherty, J.; Kohavi, R.; Sahami, M. Supervised and unsupervised discretization of continuous features. In Machine Learning Proceedings; Elsevier: Amsterdam, The Netherlands, 1995; pp. 194–202. [Google Scholar]
- Luštrek, M.; Gams, M.; Martinčić-Ipšić, S. What makes classification trees comprehensible? Expert Syst. Appl. 2016, 6, 333–346. [Google Scholar]
- Fürnkranz, J.; Kliegr, T.; Paulheim, H. On cognitive preferences and the plausibility of rule-based models. Mach. Learn. 2020, 109, 853–898. [Google Scholar] [CrossRef] [Green Version]
- Frank, E.; Witten, I.H. Generating accurate rule sets without global optimization. In Proceedings of the Fifteenth International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 144–151. [Google Scholar]
- Hornik, K.; Buchta, C.; Zeileis, A. Open-source machine learning: R meets Weka. Comput. Stat. 2009, 24, 225–232. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Popescu, B. Importance sampled learning ensembles. J. Mach. Learn. Res. 2003, 94305, 1–32. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Fürnkranz, J.; Gamberger, D.; Lavrač, N. Foundations of Rule Learning; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Fürnkranz, J.; Kliegr, T. A brief overview of rule learning. In Proceedings of the International Symposium on Rules and Rule Markup Languages for the Semantic Web, Berlin, Germany, 3–5 August 2015; Springer: Berlin/Heidelberg, Germany; pp. 54–69. [Google Scholar]
- Dua, D.; Graff, C. Uci Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 25 May 2021).
- Hastie, T.; Friedman, J.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: Berlin, Germeny, 2001; Volume 1. [Google Scholar]
- Cortez, P.; Silva, A.M.G. Using data mining to predict secondary school student performance. In Proceedings of the 5th Future Business Technology Conference, Porto, Portugal, 9–11 April 2008. [Google Scholar]
- Harrison, D., Jr.; Rubinfeld, D.L. Hedonic housing prices and the demand for clean air. J. Environ. Econ. Manag. 1978, 5, 81–102. [Google Scholar] [CrossRef] [Green Version]
- Fokoue, E. UCI Machine Learning Repository. 2020. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 25 May 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | |
|---|---|---|
| Ozone | Prediction of atmospheric ozone concentration from daily meteorological measurements [50]. | |
| Machine | Prediction of published relative performance [49]. | |
| MPG | Prediction of city-cycle fuel consumption in miles per gallon [49]. | |
| Boston | Prediction of the median price of neighborhoods, [52]. | |
| Student | Prediction of the final grade of the student based on attributes collected by reports and questionnaires [51]. | |
| Abalone | Prediction of the age of abalone from physical measurements [49]. |
| Name | Description | |
|---|---|---|
| Wine | Classification of white wine quality from 0 to 10 [49]. | |
| Covertype | 581,012 × 54 | Classification of forest cover type based on cartographic variables [49]. |
| Speaker | Classification of accent, six possibilities, based on features extracted from the first reading of a word [53]. |
| Algorithm | Parameters |
|---|---|
| CART | . |
| RuleFit | , . |
| NodeHarvest | . |
| CA | , , , , , |
| SIRUS | , . |
| Dataset | |||||
| RT | RuleFit | NodeHarvest | CA | SIRUS | |
| Ozone | 0.55 | 0.74 | 0.66 | 0.56 | 0.6 |
| Machine | 0.79 | 0.95 | 0.73 | 0.59 | 0.46 |
| MPG | 0.75 | 0.85 | 0.78 | 0.59 | 0.74 |
| Boston | 0.61 | 0.74 | 0.67 | 0.26 | 0.57 |
| Student | 0.08 | 0.16 | 0.22 | 0.13 | 0.24 |
| Abalone | 0.4 | 0.55 | 0.37 | 0.39 | 0.3 |
| Dataset | |||||
| RT | RuleFit | NodeHarvest | CA | SIRUS | |
| Ozone | 1.0 | 0.11 | 0.92 | 0.24 | 0.99 |
| Machine | 0.63 | 0.27 | 0.91 | 0.17 | 1.0 |
| MPG | 1.0 | 0.14 | 0.87 | 0.25 | 1.0 |
| Boston | 0.85 | 0.15 | 0.81 | 0.26 | 0.97 |
| Student | 0.98 | 0.14 | 1.0 | 0.26 | 1.0 |
| Abalone | 1.0 | 0.21 | 0.86 | 0.25 | 0.99 |
| Dataset | |||||
| RT | RuleFit | NodeHarvest | CA | SIRUS | |
| Ozone | 0.12 | 0.01 | 0.04 | 0.96 | 0.29 |
| Machine | 0.14 | 0.02 | 0.04 | 0.9 | 0.25 |
| MPG | 0.15 | 0.01 | 0.05 | 0.98 | 0.34 |
| Boston | 0.26 | 0.01 | 0.07 | 1.0 | 0.52 |
| Student | 0.37 | 0.05 | 0.25 | 0.91 | 0.97 |
| Abalone | 0.58 | 0.02 | 0.13 | 0.66 | 1.0 |
| Dataset | |||||
| RT | RuleFit | NodeHarvest | CA | SIRUS | |
| Ozone | 0.56 | 0.29 | 0.54 | 0.59 | 0.63 |
| Machine | 0.52 | 0.41 | 0.56 | 0.55 | 0.57 |
| MPG | 0.63 | 0.33 | 0.57 | 0.61 | 0.69 |
| Boston | 0.57 | 0.3 | 0.52 | 0.5 | 0.69 |
| Student | 0.47 | 0.12 | 0.49 | 0.43 | 0.74 |
| Abalone | 0.66 | 0.26 | 0.45 | 0.43 | 0.76 |
| 1 | |||
| − | 1 | ||
| − | − | 1 |
| Dataset | |||
| CART | RIPPER | PART | |
| Wine | 0.13 | 0.12 | 0.01 |
| Covertype | 0.37 | 0.46 | 0.5 |
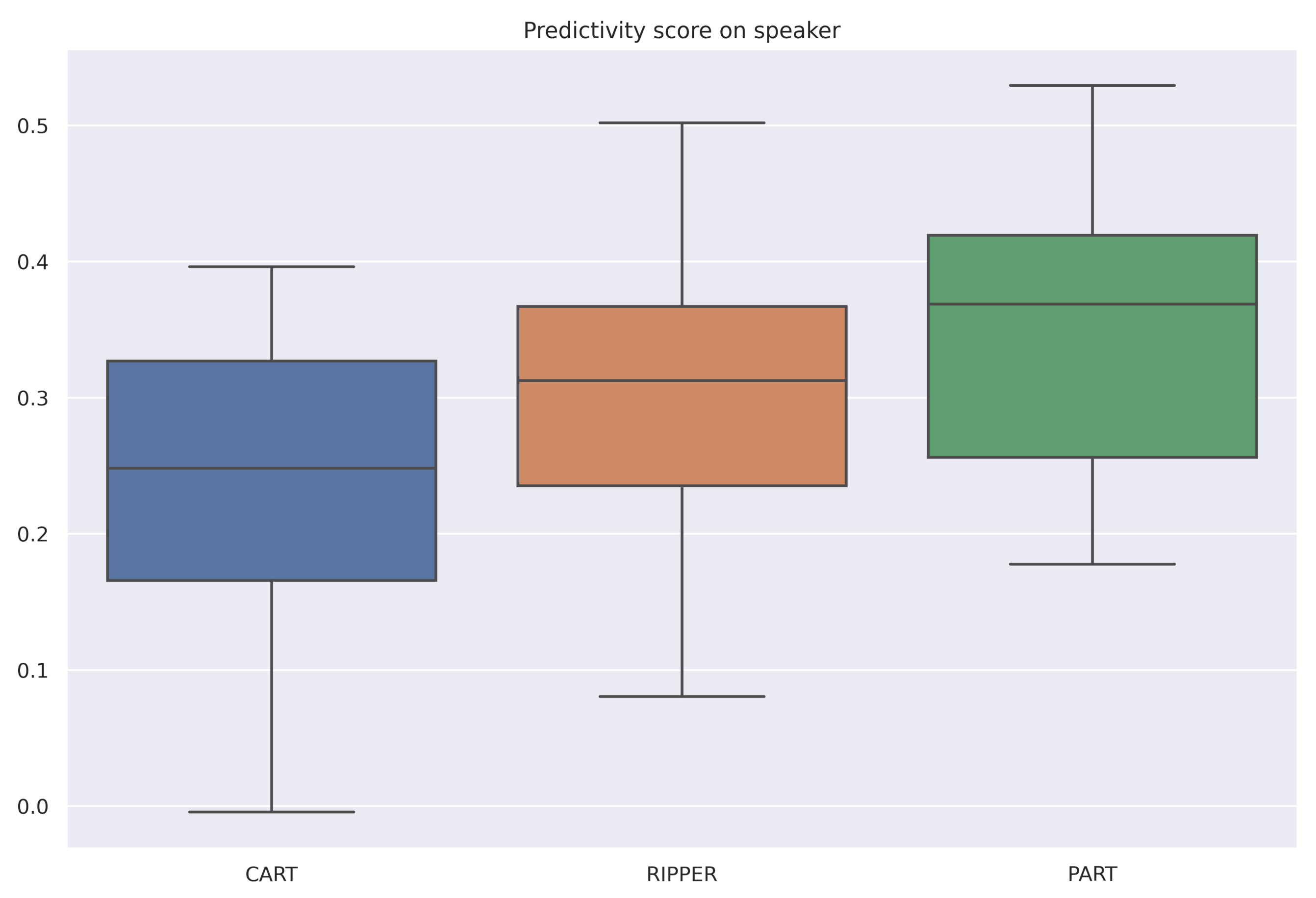
| Speaker | 0.24 | 0.31 | 0.35 |
| Dataset | |||
| CART | RIPPER | PART | |
| Wine | 1.0 | 1.0 | 1.0 |
| Covertype | 1.0 | 1.0 | 1.0 |
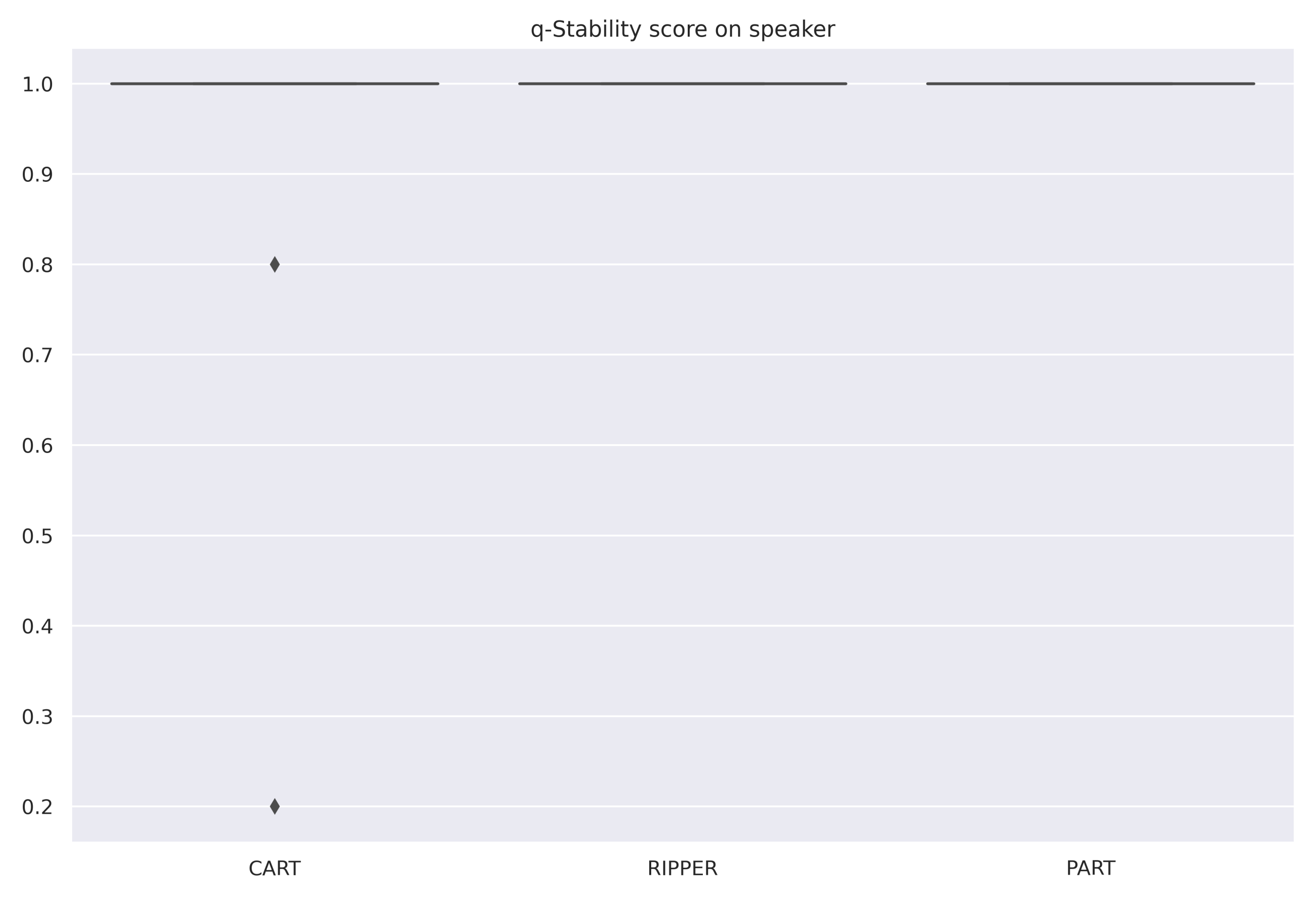
| Speaker | 0.95 | 1.0 | 1.0 |
| Dataset | |||
| CART | RIPPER | PART | |
| Wine | 0.99 | 0.64 | 0.01 |
| Covertype | 1.0 | 0.12 | 0.01 |
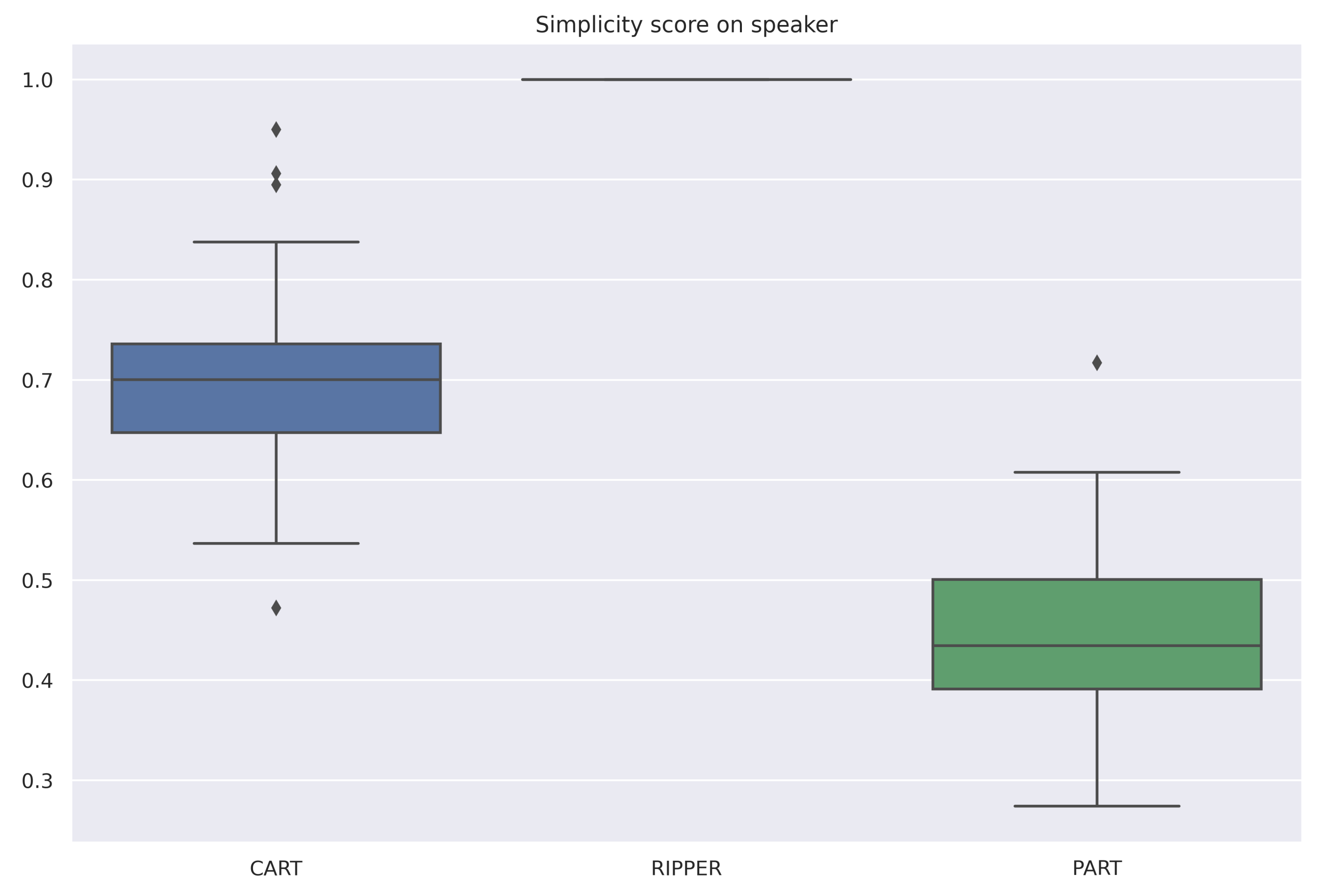
| Speaker | 0.71 | 1.0 | 0.45 |
| Dataset | |||
| CART | RIPPER | PART | |
| Wine | 0.71 | 0.59 | 0.34 |
| Covertype | 0.79 | 0.53 | 0.50 |
| Speaker | 0.63 | 0.77 | 0.6 |
| 1 | |||
| − | 1 | ||
| − | − | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Margot, V.; Luta, G. A New Method to Compare the Interpretability of Rule-Based Algorithms. AI 2021, 2, 621-635. https://doi.org/10.3390/ai2040037
Margot V, Luta G. A New Method to Compare the Interpretability of Rule-Based Algorithms. AI. 2021; 2(4):621-635. https://doi.org/10.3390/ai2040037
Chicago/Turabian StyleMargot, Vincent, and George Luta. 2021. "A New Method to Compare the Interpretability of Rule-Based Algorithms" AI 2, no. 4: 621-635. https://doi.org/10.3390/ai2040037
APA StyleMargot, V., & Luta, G. (2021). A New Method to Compare the Interpretability of Rule-Based Algorithms. AI, 2(4), 621-635. https://doi.org/10.3390/ai2040037