
Rule-Enhanced Active Learning for Semi-Automated Weak Supervision

 ,
,
Abstract
:1. Introduction
2. Preliminaries
2.1. Problem Formulation
2.2. Challenges
2.2.1. Label Noise
2.2.2. Label Incompleteness
2.2.3. Annotator Effort
2.3. Objectives
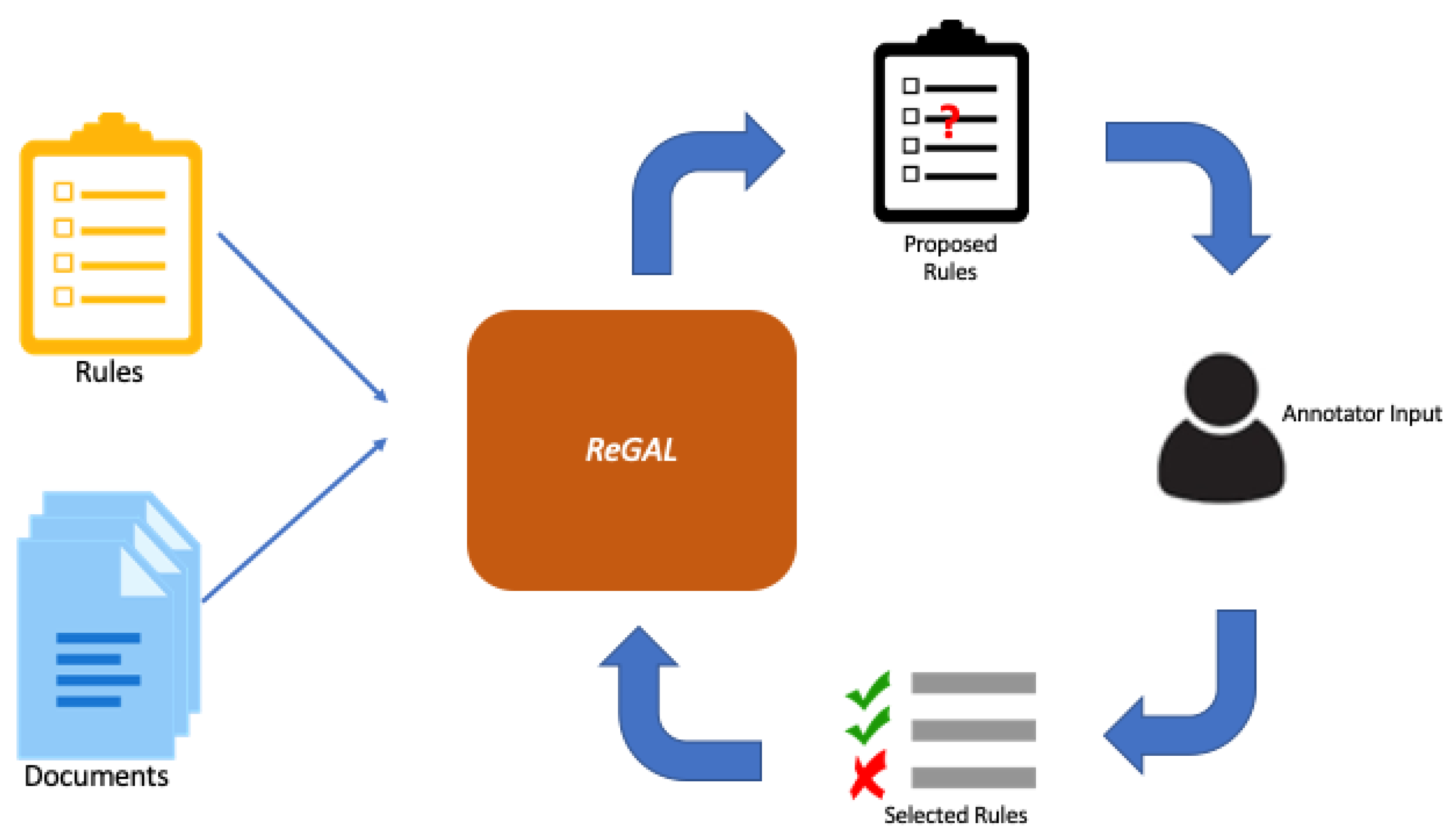
3. Methods
- (1)
- TextEncoder: Encodes semantically meaningful information about each token and document into contextualized token embeddings.
- (2)
- SnippetSelector: Extracts relevant phrases for document classification.
- (3)
- RuleProposer: Generates candidate labeling functions from extracted snippets.
- (4)
- RuleDenoiser: Produces probabilistic labels for all documents using labeling functions and document embeddings.
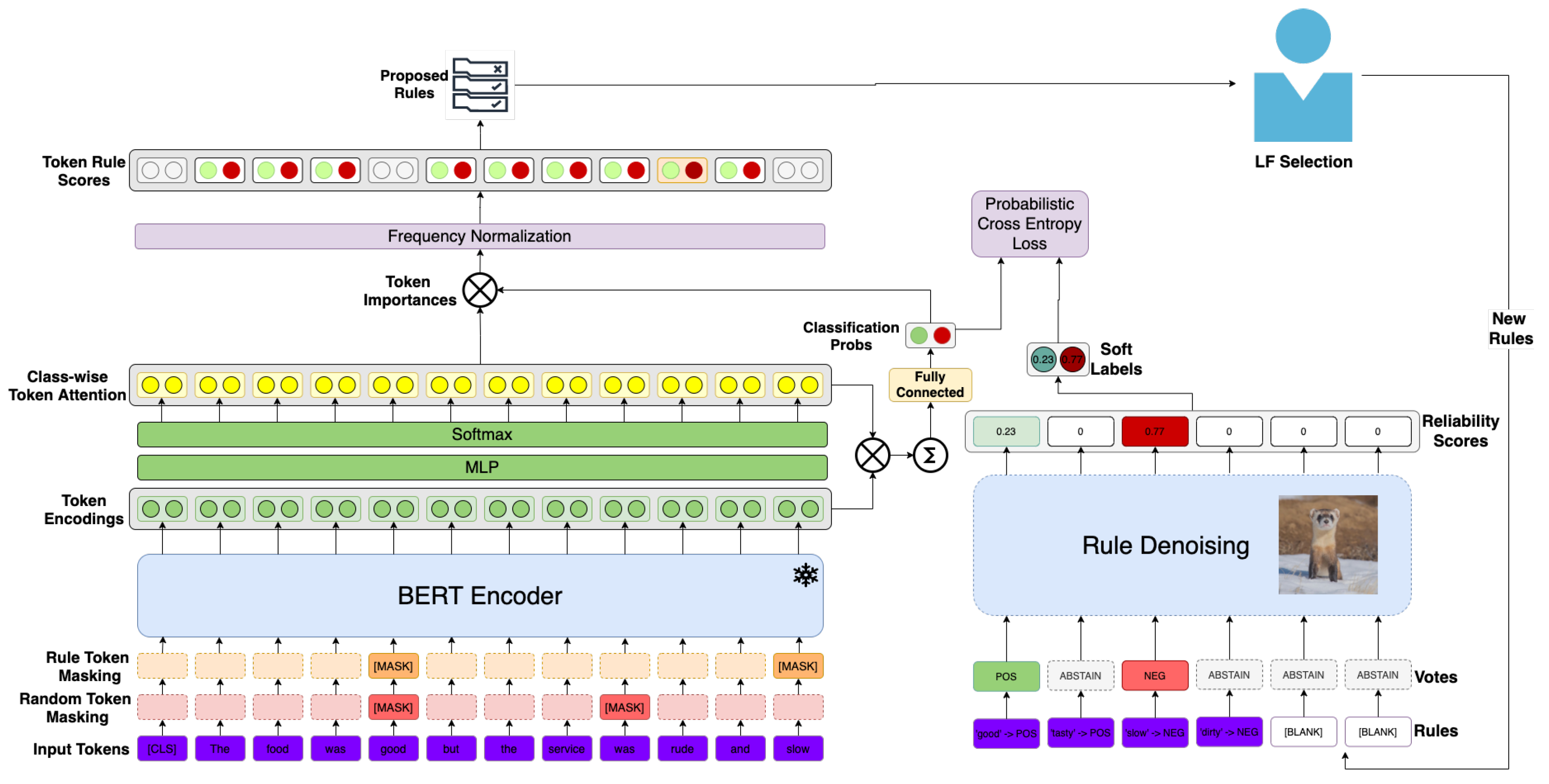
3.1. Text Encoder
3.2. Snippet Selector
3.3. Rule Proposal Network
3.4. Rule Denoiser
3.5. Model Optimization
4. Experiments and Discussion
4.1. Datasets
- Yelp is a collection of Yelp restaurant reviews classified according to their sentiment;
- IMDB is a set of movie reviews classified according to sentiment [26];
- AGnews is a news corpus for topic classification with four classes: sports, technology, politics, and business [27];
- BiasBios is a set of biographies of individuals with classes based on profession. We use the binary classification subsets utilized in [28]: (1) Professor vs. Physician, (2) Professor vs. Teacher, (3) Journalist vs. Photographer, and (4) Painter vs. Architect.
4.2. Baseline Models
4.2.1. Snuba or Reef
4.2.2. Interactive Weak Supervision
4.2.3. Fully Supervised BERT Model (FS BERT)
4.3. Training Setup
4.4. Rule Extraction
4.5. Qualitative LF Evaluation
5. Related Work
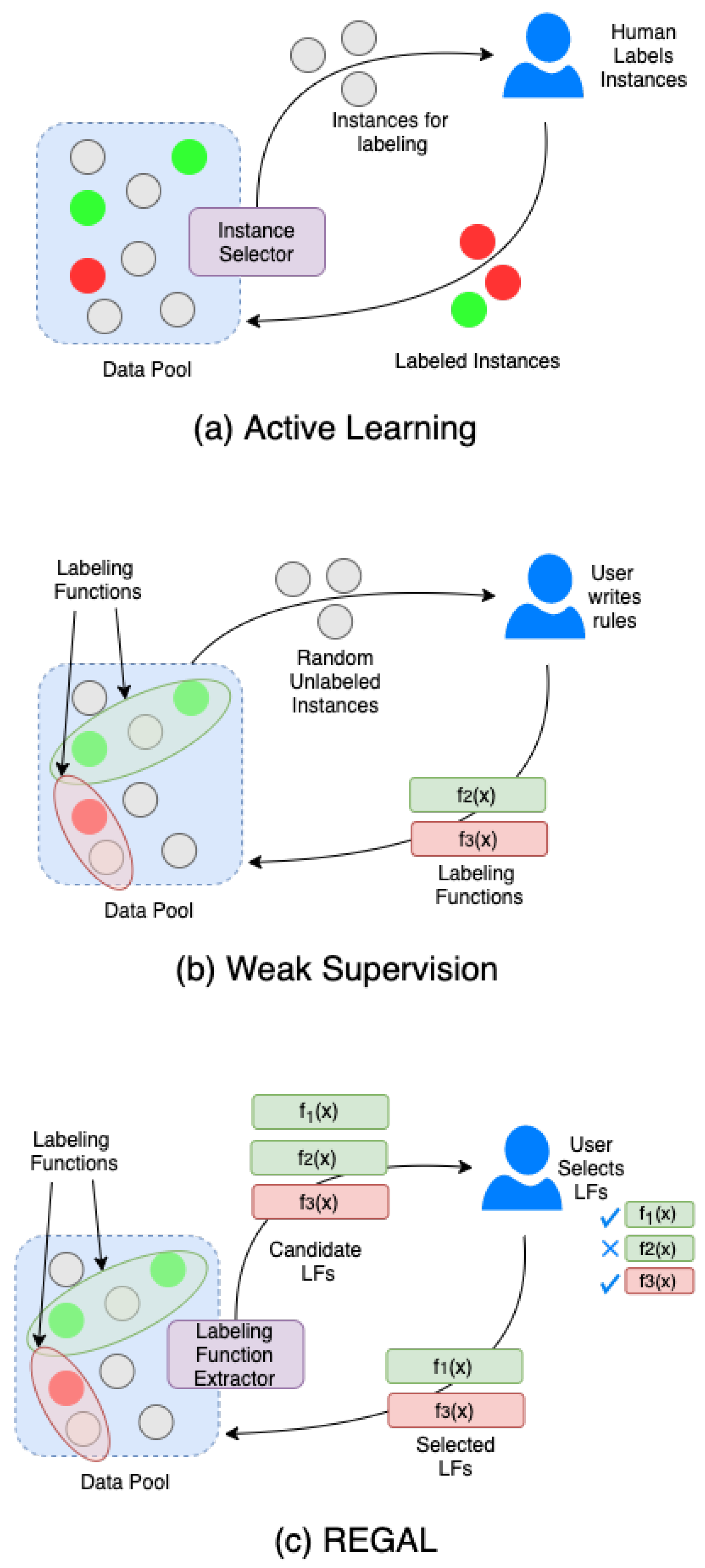
5.1. Active Learning
5.2. Weakly Supervised Learning
5.3. Combined Active Learning with Interactive Weak Supervision
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LF | Labeling Function |
| LM | Label Model |
| AUC | Area Under the Curve |
| IWS | Interactive Weak Supervision |
| REGAL | Rule-Enhanced Generative Active Learning |
Appendix A. Datasets and Preprocessing
Appendix B. Seed Labeling Rules
- Yelp LFs:
- Positive: ‘best’, ‘excellent’, ‘awesome’
- Negative: ‘worst’, ‘awful’, ‘nasty’
- Professor/Physician LFs:
- Professor: ‘professor’, ‘science’, ‘published’
- Teacher: ‘medical’, ‘practice’, ‘physician’
- Journalist/Photographer LFs:
- Journalist: ‘journalism’, ‘writing’, ‘news’
- Photographer: ‘photographer’, ‘studio’, ‘fashion’
- Professor/Teacher LFs:
- Professor: ‘professor’, ‘research’, ‘published’
- Teacher: ‘elementary’, ‘children’, ‘teacher’
- Painter/Architect LFs:
- Painter: ‘painting’, ‘art’, ‘gallery’
- Architect: ‘building’, ‘architect’, ‘residential’
- IMDB LFs:
- Positive: ‘masterpiece’, ‘excellent’, ‘wonderful’
- Negative: ‘worst’, ‘awful’, ‘garbage’

{kind=link}
{kind=link}
{kind=link}
| Dataset | Class | Length 2 Rules |
|---|---|---|
| AG News | Sports | ‘2006 world’, ‘93 -’, ‘- star’, ‘half goals’, ‘world short’, ‘1 draw’ |
| Science/Tech | ‘worm that’, ‘os x’, ‘/ l’, ‘data -’, ‘a flaw’, ‘chart )’ | |
| Politics | ‘labour party’, ‘labor party’, ‘s party’, ‘al -’, ‘bush ”, ‘pro -’ | |
| Business | ‘- wall’, ‘$ 46’, ‘up 0’, ‘$ 85’, ‘$ 43’, ‘a &’ | |
| IMDB | Positive | ‘kelly and’, ‘claire danes’, ‘george burns’, ‘jack lemmon’, ‘michael jackson’, ‘hong kong’ |
| Negative | ‘just really’, ‘plain stupid’, ‘maybe if’, ‘avoid it’, ‘so stupid’, ‘stupid the’ | |
| Journalist/ Photographer | Photographer | - |
| Journalist | ‘see less’, ‘twitter:’ | |
| Painter/ Architect | Painter | ‘attended the’, ‘public collections’, ‘collections including’ |
| Architect | - | |
| Professor/ Physician | Professor | ‘of financial’, ‘see less’, ‘film and’, ‘and society’, ‘fiction and’, ‘_ b’ |
| Physician | ‘oh and’, ‘va and’, ‘la and’, ‘tn and’, ‘ca and’, ‘ok and’ | |
| Professor/ Teacher | Teacher | ‘childhood education’, ‘early childhood’, ‘primary school’, ‘of 4’, ‘special education’, ‘rating at’ |
| Professor | ‘modeling and’, ‘and computational’, ‘climate change’, ‘and organizational’, ‘of government’, ‘nsf career’ | |
| Yelp | Positive | ‘affordable and’, ‘food good’, ‘highly recommended’, ‘highly recommend’, ‘top notch’, ‘definitely recommend’ |
| Negative | ‘never again’, ‘never recommend’, ‘ever again’, ‘very bad’, ‘never going’, ‘my card’ |
Appendix C. Additional Training Details
Appendix D. Generated Rules
Appendix E. Mann–Whitney-Wilcoxon Test
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: New York, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the NAACL, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: Pretrained Language Model for Scientific Text. arXiv 2019, arXiv:1903.10676. [Google Scholar]
- Ein-Dor, L.; Halfon, A.; Gera, A.; Shnarch, E.; Dankin, L.; Choshen, L.; Danilevsky, M.; Aharonov, R.; Katz, Y.; Slonim, N. Active Learning for BERT: An Empirical Study. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 7949–7962. [Google Scholar]
- Rühling Cachay, S.; Boecking, B.; Dubrawski, A. End-to-End Weak Supervision. Adv. Neural Inf. Process. Syst. 2021, 34. Available online: https://proceedings.neurips.cc/paper/2021/hash/0e674a918ebca3f78bfe02e2f387689d-Abstract.html (accessed on 16 December 2021).
- Yu, Y.; Zuo, S.; Jiang, H.; Ren, W.; Zhao, T.; Zhang, C. Fine-Tuning Pre-trained Language Model with Weak Supervision: A Contrastive-Regularized Self-Training Approach. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 6–11 June 2021; pp. 1063–1077. [Google Scholar]
- Ren, W.; Li, Y.; Su, H.; Kartchner, D.; Mitchell, C.; Zhang, C. Denoising Multi-Source Weak Supervision for Neural Text Classification. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 739–3754. [Google Scholar]
- Ratner, A.; Bach, S.H.; Ehrenberg, H.; Fries, J.; Wu, S.; Ré, C. Snorkel. Proc. VLDB Endow. 2017, 11, 269–282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dawid, A.P.; Skene, A.M. Maximum likelihood estimation of observer error-rates using the EM algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 20–28. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; 2009. [Google Scholar]
- Nodet, P.; Lemaire, V.; Bondu, A.; Cornuéjols, A.; Ouorou, A. From Weakly Supervised Learning to Biquality Learning: An Introduction. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Ratner, A.; Hancock, B.; Dunnmon, J.; Sala, F.; Pandey, S.; Ré, C. Training complex models with multi-task weak supervision. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4763–4771. [Google Scholar]
- Meng, Y.; Shen, J.; Zhang, C.; Han, J. Weakly-supervised neural text classification. In Proceedings of the International Conference on Information and Knowledge Management, Proceedings, Turin, Italy, 22–26 October 2018; pp. 983–992. [Google Scholar] [CrossRef] [Green Version]
- Awasthi, A.; Ghosh, S.; Goyal, R.; Sarawagi, S. Learning from Rules Generalizing Labeled Exemplars. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Cohen-Wang, B.; Mussmann, S.; Ratner, A.; Ré, C. Interactive programmatic labeling for weak supervision. In Proceedings of the KDD DCCL Workshop, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Zhou, W.; Lin, H.; Lin, B.Y.; Wang, Z.; Du, J.; Neves, L.; Ren, X. Nero: A neural rule grounding framework for label-efficient relation extraction. In Proceedings of the Web Conference 2020, Taipei Taiwan, 20–24 April 2020; pp. 2166–2176. [Google Scholar]
- Varma, P.; Ré, C. Snuba: Automating weak supervision to label training data. In Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases, Rio de Janeiro, Brazil, 12 August 2018; Volume 12, p. 223. [Google Scholar]
- Qu, M.; Ren, X.; Zhang, Y.; Han, J. Weakly-supervised Relation Extraction by Pattern-enhanced Embedding Learning. In Proceedings of the 2018 World Wide Web Conference on World Wide Web—WWW ’18, Florence, Italy, 18–22 May 2018; Association for Computing Machinery (ACM): New York, NY, USA, 2018; pp. 1257–1266. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, A.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 2017, 5999–6009. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Association for Computational Linguistics, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Varma, P.; Sala, F.; He, A.; Ratner, A.; Re, C. Learning Dependency Structures for Weak Supervision Models. In Proceedings of the Machine Learning Research, Vancouver, BC, Canada, 8–14 December 2019; Volume 97, pp. 6418–6427. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies—Volume 1, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, NIPS 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Boecking, B.; Neiswanger, W.; Xing, E.; Dubrawski, A. Interactive Weak Supervision: Learning Useful Heuristics for Data Labeling. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4–8 May 2021. [Google Scholar]
- Bryan, B.; Schneider, J.; Nichol, R.; Miller, C.J.; Genovese, C.R.; Wasserman, L. Active Learning for Identifying Function Threshold Boundaries; 2005; pp. 163–170. Available online: https://proceedings.neurips.cc/paper/2005/hash/8e930496927757aac0dbd2438cb3f4f6-Abstract.html (accessed on 16 December 2021).
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? China National Conference on Chinese Computational Linguistics; Springer: Kunming, China, 2019; pp. 194–206. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]
- Gissin, D.; Shalev-Shwartz, S. Discriminative active learning. arXiv 2019, arXiv:1907.06347. [Google Scholar]
- Sener, O.; Savarese, S. Active learning for convolutional neural networks: A core-set approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Lewis, D.D.; Gale, W.A. A Sequential Algorithm for Training Text Classifiers; SIGIR’94; Springer: London, UK, 1994; pp. 3–12. [Google Scholar]
- Huang, J.; Child, R.; Rao, V.; Liu, H.; Satheesh, S.; Coates, A. Active learning for speech recognition: The power of gradients. arXiv 2016, arXiv:1612.03226. [Google Scholar]
- Li, Y.; Shetty, P.; Liu, L.; Zhang, C.; Song, L. BERTifying the Hidden Markov Model for Multi-Source Weakly Supervised Named Entity Recognition. arXiv 2021, arXiv:2105.12848. [Google Scholar]
- Lison, P.; Hubin, A.; Barnes, J.; Touileb, S. Named entity recognition without labelled data: A weak supervision approach. arXiv 2020, arXiv:2004.14723. [Google Scholar]
- Saab, K.; Dunnmon, J.; Ré, C.; Rubin, D.; Lee-Messer, C. Weak supervision as an efficient approach for automated seizure detection in electroencephalography. NPJ Digit. Med. 2020, 3, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Hooper, S.; Wornow, M.; Seah, Y.H.; Kellman, P.; Xue, H.; Sala, F.; Langlotz, C.; Re, C. Cut out the annotator, keep the cutout: Better segmentation with weak supervision. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Karamanolakis, G.; Mukherjee, S.S.; Zheng, G.; Awadallah, A.H. Self-Training with Weak Supervision. In Proceedings of the 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT 2021), Mexico City, Mexico, 6–11 June 2021. [Google Scholar]
- Chen, M.F.; Fu, D.Y.; Sala, F.; Wu, S.; Mullapudi, R.T.; Poms, F.; Fatahalian, K.; Ré, C. Train and You’ll Miss It: Interactive Model Iteration with Weak Supervision and Pre-Trained Embeddings. arXiv 2020, arXiv:2006.15168. [Google Scholar]
- Wilcoxon, F. Individual comparisons by ranking methods. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 196–202. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]

| Dataset | # Train | # Valid | # Test | # Classes | Coverage | Bal. Coverage |
|---|---|---|---|---|---|---|
| Yelp | 30,400 | 3800 | 3800 | 2 | 0.2239 | 0.1042 |
| IMDB | 24,500 | 500 | 25,000 | 2 | 0.1798 | 0.1663 |
| AG News | 96,000 | 12,000 | 12,000 | 4 | 0.0963 | 0.0144 |
| Journalist/Photographer | 15,629 | 500 | 16,129 | 2 | 0.3211 | 0.2364 |
| Professor/Physician | 26,738 | 500 | 27,238 | 2 | 0.5149 | 0.3772 |
| Professor/Teacher | 11,794 | 500 | 12,294 | 2 | 0.5195 | 0.3574 |
| Painter/Architect | 5618 | 500 | 6118 | 2 | 0.4516 | 0.2650 |
| Dataset | Model | # LFs | LF Acc | Coverage | LM Acc | LM AUC |
|---|---|---|---|---|---|---|
| AG News | IWS | - | - | - | - | - |
| REEF/Snuba | - | - | - | - | - | |
| REGAL | 280 | 0.912 | 0.007 | 0.856 | - | |
| FS BERT * | - | - | - | 0.952 | - | |
| IMDB | IWS | 35 | 0.807 | 0.065 | 0.811 | 0.883 |
| REEF/Snuba | 50 | 0.729 | 0.068 | 0.722 | 0.787 | |
| REGAL | 193 | 0.787 | 0.017 | 0.510 | 0.757 | |
| FS BERT | - | - | - | 0.914 | 0.974 | |
| Journalist/ Photographer | IWS | 110 | 0.877 | 0.033 | 0.898 | 0.958 |
| REEF/Snuba | 23 | 0.894 | 0.142 | 0.910 | 0.944 | |
| REGAL | 265 | 0.840 | 0.030 | 0.733 | 0.890 | |
| FS BERT | - | - | - | 0.954 | 0.990 | |
| Painter/ Architect | IWS | 157 | 0.883 | 0.032 | 0.893 | 0.966 |
| REEF/Snuba | 23 | 0.893 | 0.140 | 0.874 | 0.947 | |
| REGAL | 373 | 0.876 | 0.034 | 0.897 | 0.977 | |
| FS BERT | - | - | - | 0.968 | 0.995 | |
| Professor/ Physician | IWS | 238 | 0.860 | 0.042 | 0.892 | 0.957 |
| REEF/Snuba | 26 | 0.917 | 0.184 | 0.882 | 0.935 | |
| REGAL | 249 | 0.876 | 0.041 | 0.794 | 0.871 | |
| FS BERT | - | - | - | 0.951 | 0.994 | |
| Professor/ Teacher | IWS | 218 | 0.785 | 0.030 | 0.760 | 0.928 |
| REEF/Snuba | 12 | 0.562 | 0.619 | 0.782 | 0.839 | |
| REGAL | 211 | 0.824 | 0.029 | 0.813 | 0.877 | |
| FS BERT | - | - | - | 0.938 | 0.982 | |
| Yelp | IWS | 87 | 0.799 | 0.047 | 0.747 | 0.830 |
| REEF/Snuba | 38 | 0.833 | 0.071 | 0.830 | 0.887 | |
| REGAL | 155 | 0.803 | 0.018 | 0.770 | 0.837 | |
| FS BERT | - | - | - | 0.960 | 0.992 | |
| macro-average | IWS | 140.833 | 0.835 | 0.041 | 0.833 | 0.920 |
| REEF/Snuba | 28.667 | 0.805 | 0.204 | 0.833 | 0.890 | |
| REGAL ** | 241 | 0.834 | 0.028 | 0.753 | 0.868 | |
| FS BERT ** | - | - | - | 0.9475 | 0.988 |
| Dataset | Higher Med. Acc. | MWW p-val. |
|---|---|---|
| Yelp | REGAL | 0.3438 |
| IMDB | IWS | 0.1926 |
| Journalist/Photographer | IWS * | 0.0066 * |
| Professor/Teacher | REGAL | 0.2086 |
| Professor/Physician | REGAL ** | 0.0010 ** |
| Painter/Architect | IWS | 0.1438 |
| Dataset | Model | Accuracy | AUC | MV Acc | MV AUC | Coverage | Imbalance Ratio |
|---|---|---|---|---|---|---|---|
| AG News | REGAL | 0.011 | − | −0.034 | − | −0.154 | 2.245 |
| IMDB | IWS | −0.002 | −0.014 | 0.008 | 0.001 | −0.107 | 1.896 |
| REEF/Snuba | 0.002 | 0.000 | 0.000 | 0.000 | −0.002 | 1.053 | |
| REGAL | 0.066 | −0.068 | 0.083 | −0.008 | −0.165 | 3.573 | |
| Journalist/ Photographer | IWS | −0.001 | −0.013 | −0.012 | 0.001 | −0.112 | 2.492 |
| REEF/Snuba | −0.003 | −0.004 | −0.004 | 0.000 | −0.006 | 1.493 | |
| REGAL | −0.014 | 0.004 | 0.025 | −0.012 | −0.001 | 1.319 | |
| Painter/ Architect | IWS | 0.033 | −0.014 | 0.022 | 0.007 | −0.136 | 3.969 |
| REEF/Snuba | 0.001 | 0.000 | −0.003 | −0.003 | −0.004 | 1.340 | |
| REGAL | −0.011 | −0.006 | 0.015 | −0.004 | −0.001 | 1.238 | |
| Professor/ Physician | IWS | −0.010 | −0.008 | 0.006 | −0.001 | −0.002 | 1.170 |
| REEF/Snuba | −0.004 | 0.001 | −0.007 | −0.002 | 0.000 | 1.499 | |
| REGAL | −0.026 | −0.024 | 0.024 | −0.009 | 0.000 | 1.380 | |
| Professor/ Teacher | IWS | 0.120 | −0.033 | 0.146 | 0.075 | −0.253 | 7.109 |
| REEF/Snuba | 0.008 | 0.000 | 0.000 | −0.008 | 0.000 | 1.012 | |
| REGAL | −0.001 | −0.013 | 0.000 | −0.003 | 0.000 | 1.121 | |
| Yelp | IWS | 0.085 | 0.061 | 0.060 | −0.007 | −0.140 | 3.285 |
| REEF/Snuba | 0.003 | 0.002 | 0.001 | 0.000 | −0.008 | 1.226 | |
| REGAL | 0.010 | 0.012 | 0.021 | −0.019 | −0.036 | 1.642 |
| Dataset | Class | Iter. 1 | Iter. 2 | Iter. 3 |
|---|---|---|---|---|
| AG News | Sports | ‘ioc’, ‘olympic’, ‘knicks’, ‘nba’, ‘ncaa’, ‘medal’ | ‘mls’, ‘mvp’, ‘fc’, ‘sport’, ‘cowboys’, ‘golf’ | ‘102’, ‘35th’, ‘vs’, ‘2012’, ‘700th’, ‘ruud’ |
| Science/Tech | ‘microprocessors’, ‘microprocessor’, ‘antivirus’, ‘workstations’, ‘passwords’, ‘mainframe’ | ‘xp’, ‘os’, ‘x86’, ‘sp2’, ‘worms’, ‘worm’ | ‘hd’, ‘666666’, ‘src’, ‘sd’, ‘br’, ‘200301151450’ | |
| Politics | ‘allawi’, ‘prime’, ‘ayad’, ‘iyad’, ‘kofi’, ‘sadr’ | ‘plo’, ‘holy’, ‘roh’, ‘troops’, ‘troop’, ‘mp’ | - | |
| Business | ‘futures’, ‘indexes’, ‘trading’, ‘investors’, ‘traders’, ‘shares’ | ‘http’, ‘www’, ‘output’, ‘bp’, ‘dow’, ‘bhp’ | ‘ob’ | |
| IMDB | Positive | ‘enchanting’, ‘errol’, ‘astaire’, ‘matthau’, ‘witherspoon’, ‘mclaglen’ | ‘garcia’, ‘ruby’, ‘1939’, ‘emily’, ‘myrna’, ‘poem’ | ‘delight’, ‘stellar’, ‘vivid’, ‘voight’, ‘burns’, ‘dandy’ |
| Negative | ‘dumbest’, ‘manos’, ‘lame’, ‘whiny’, ‘laughable’, ‘camcorder’ | ‘pointless’, ‘inept’, ‘inane’, ‘implausible’, ‘abysmal’, ‘cheap’ | ‘vomit’, ‘joke’, ‘morons’, ‘ugh’, ‘snakes’, ‘avoid’ | |
| Journalist/ Photographer | Photographer | ‘35mm’, ‘shoots’, ‘polaroid’, ‘headshots’, ‘captures’, ‘portraiture’ | ‘exposures’, ‘kodak’, ‘nudes’, ‘viewer’, ‘imagery’, ‘colors’ | ‘shadows’, ‘macro’, ‘canvas’, ‘skill’, ‘poses’, ‘hobby’ |
| Journalist | ‘corruption’, ‘government’, ‘cnn’, ‘previously’, ‘policy’, ‘stints’ | ‘governance’, ‘anchor’, ‘pbs’, ‘npr’, ‘democracy’, ‘bureau’ | ‘arabic’, ‘programme’, ‘elsewhere’, ‘economy’, ‘crisis’, ‘prior’ | |
| Painter/ Architect | Painter | ‘galleries’, ‘collections’, ‘residencies’, ‘acrylic’, ‘plein’, ‘pastels’ | ‘impressionist’, ‘textures’, ‘strokes’, ‘flowers’, ‘figurative’, ‘brush’ | ‘palette’, ‘feelings’, ‘realism’, ‘emotion’, ‘realistic’, ‘filled’ |
| Architect | ‘soa’, ‘enterprise’, ‘bim’, ‘server’, ‘scalable’, ‘solutions’ | ‘infrastructure’, ‘methodologies’, ‘certifications’, ‘intelligence’, ‘teams’, ‘developer’ | ‘automation’, ‘computing’, ‘delivery’, ‘healthcare’, ‘initiatives’, ‘processing’ | |
| Professor/ Physician | Professor | ‘banking’, ‘democratization’, ‘verification’, ‘cooperation’, ‘governance’, ‘b’ | ‘security’, ‘finance’, ‘macroeconomics’, ‘microeconomics’, ‘political’, ‘law’ | ‘acm’, ‘optimization’, ‘mechanical’, ‘metaphysics’, ‘computational’, ‘visualization’ |
| Physician | ‘specializes’, ‘alaska’, ‘takes’, ‘accepts’, ‘norfolk’, ‘ky’ | ‘speaks’, ‘aurora’, ‘carolinas’, ‘menorah’, ‘novant’, ‘affiliated’ | ‘vidant’, ‘anthonys’, ‘southside’, ‘fluent’, ‘hindi’, ‘osf’ | |
| Professor/ Teacher | Teacher | ‘grades’, ‘ages’, ‘eighth’, ‘aged’, ‘graders’, ‘grade’ | ‘ratings’, ‘sixth’, ‘fifth’, ‘fun’, ‘fourth’, ‘tutoring’ | ‘pupils’, ‘favorite’, ‘cooking’, ‘volunteering’, ‘comparing’, ‘friends’ |
| Professor | ‘governance’, ‘constitutional’, ‘cooperation’, ‘regulation’, ‘democracy’, ‘finance’ | ‘econometrics’, ‘banking’, ‘economy’, ‘markets’, ‘entrepreneurship’, ‘economic’ | ‘globalization’, ‘optimization’, ‘firms’, ‘statistical’, ‘conflict’, ‘tax’ | |
| Yelp | Positive | ‘phenomenal’, ‘yummy’, ‘delectable’, ‘favorite’, ‘amazing’, ‘atmosphere’ | ‘terrific’, ‘heavenly’, ‘notch’, ‘hearty’, ‘chic’, ‘stylish’ | ‘handmade’, ‘kale’, ‘cozy’, ‘carpaccio’, ‘tender’, ‘fave’ |
| Negative | ‘refund’, ‘pharmacy’, ‘disrespectful’, ‘refunded’, ‘warranty’, ‘rudest’ | ‘cancel’, ‘scam’, ‘confirmed’, ‘dealership’, ‘driver’, ‘appt’ | ‘receipt’, ‘confirm’, ‘reply’, ‘cox’, ‘clerk’, ‘policy’ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kartchner, D.; Nakajima An, D.; Ren, W.; Zhang, C.; Mitchell, C.S. Rule-Enhanced Active Learning for Semi-Automated Weak Supervision. AI 2022, 3, 211-228. https://doi.org/10.3390/ai3010013
Kartchner D, Nakajima An D, Ren W, Zhang C, Mitchell CS. Rule-Enhanced Active Learning for Semi-Automated Weak Supervision. AI. 2022; 3(1):211-228. https://doi.org/10.3390/ai3010013
Chicago/Turabian StyleKartchner, David, Davi Nakajima An, Wendi Ren, Chao Zhang, and Cassie S. Mitchell. 2022. "Rule-Enhanced Active Learning for Semi-Automated Weak Supervision" AI 3, no. 1: 211-228. https://doi.org/10.3390/ai3010013
APA StyleKartchner, D., Nakajima An, D., Ren, W., Zhang, C., & Mitchell, C. S. (2022). Rule-Enhanced Active Learning for Semi-Automated Weak Supervision. AI, 3(1), 211-228. https://doi.org/10.3390/ai3010013