
Can Interpretable Reinforcement Learning Manage Prosperity Your Way?


Abstract
:1. Introduction
2. Related Work
3. Methodology
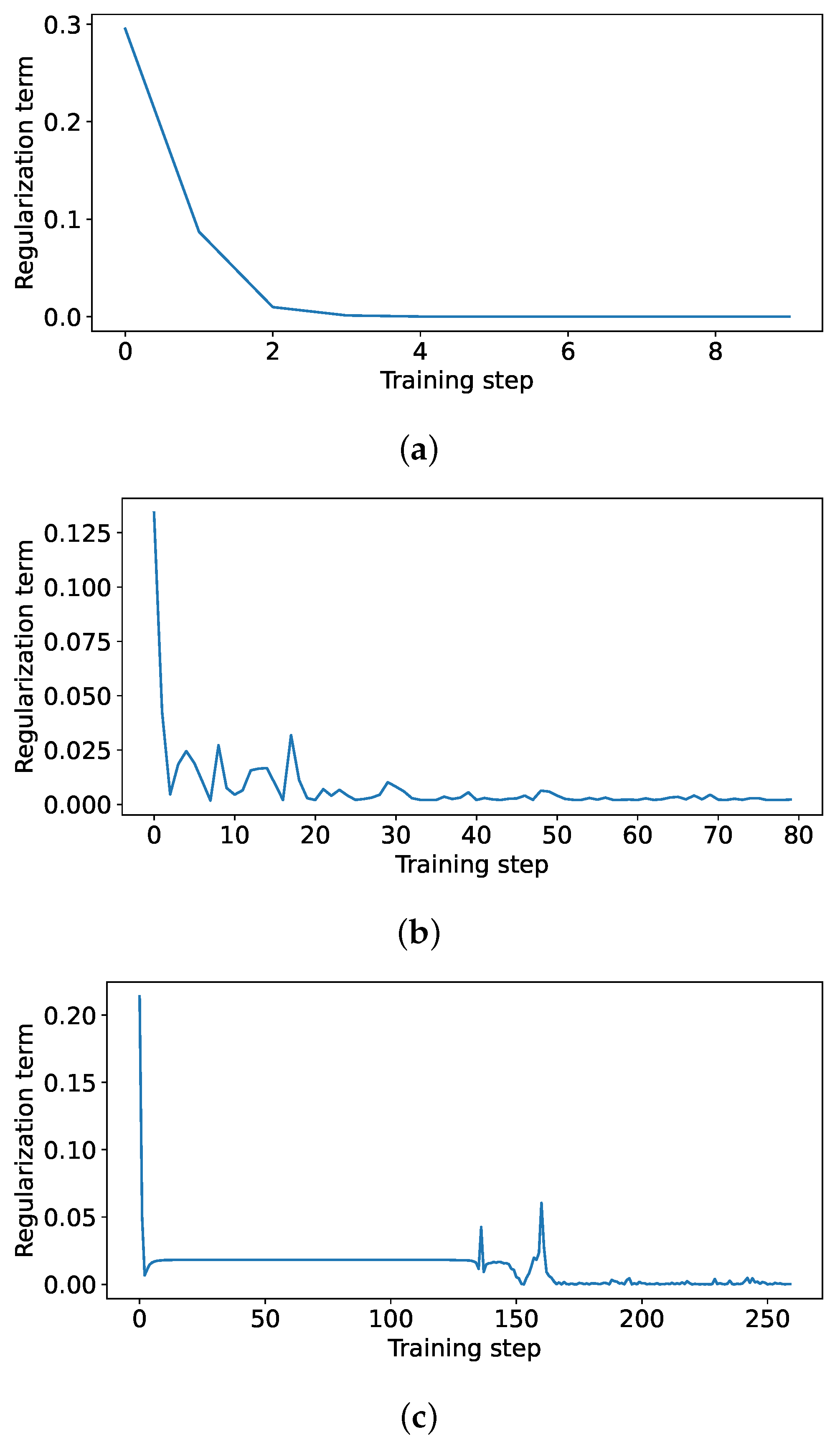
| Algorithm 1: Policy regularisation algorithm from [15]. |
|
3.1. Modelling Assumptions
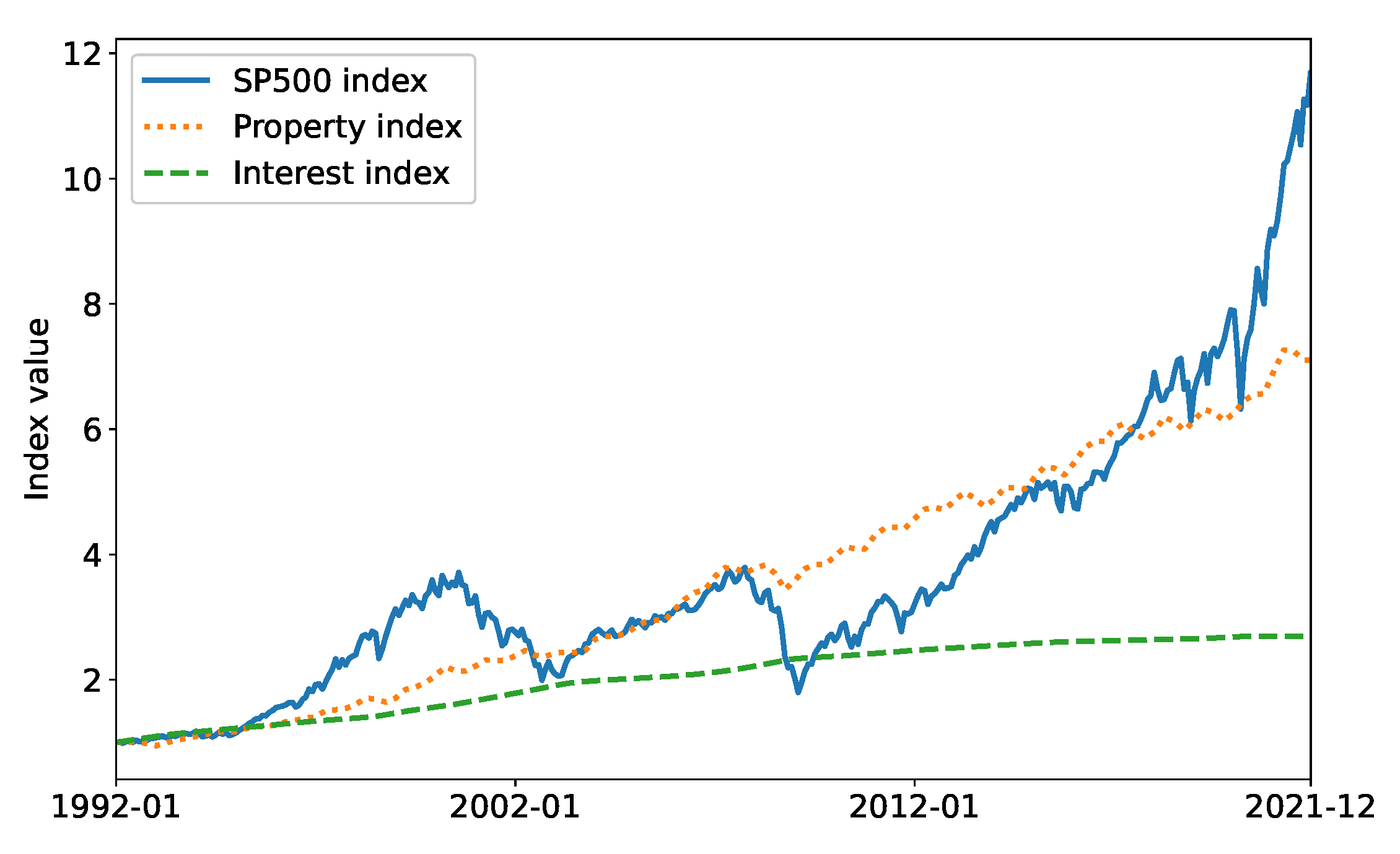
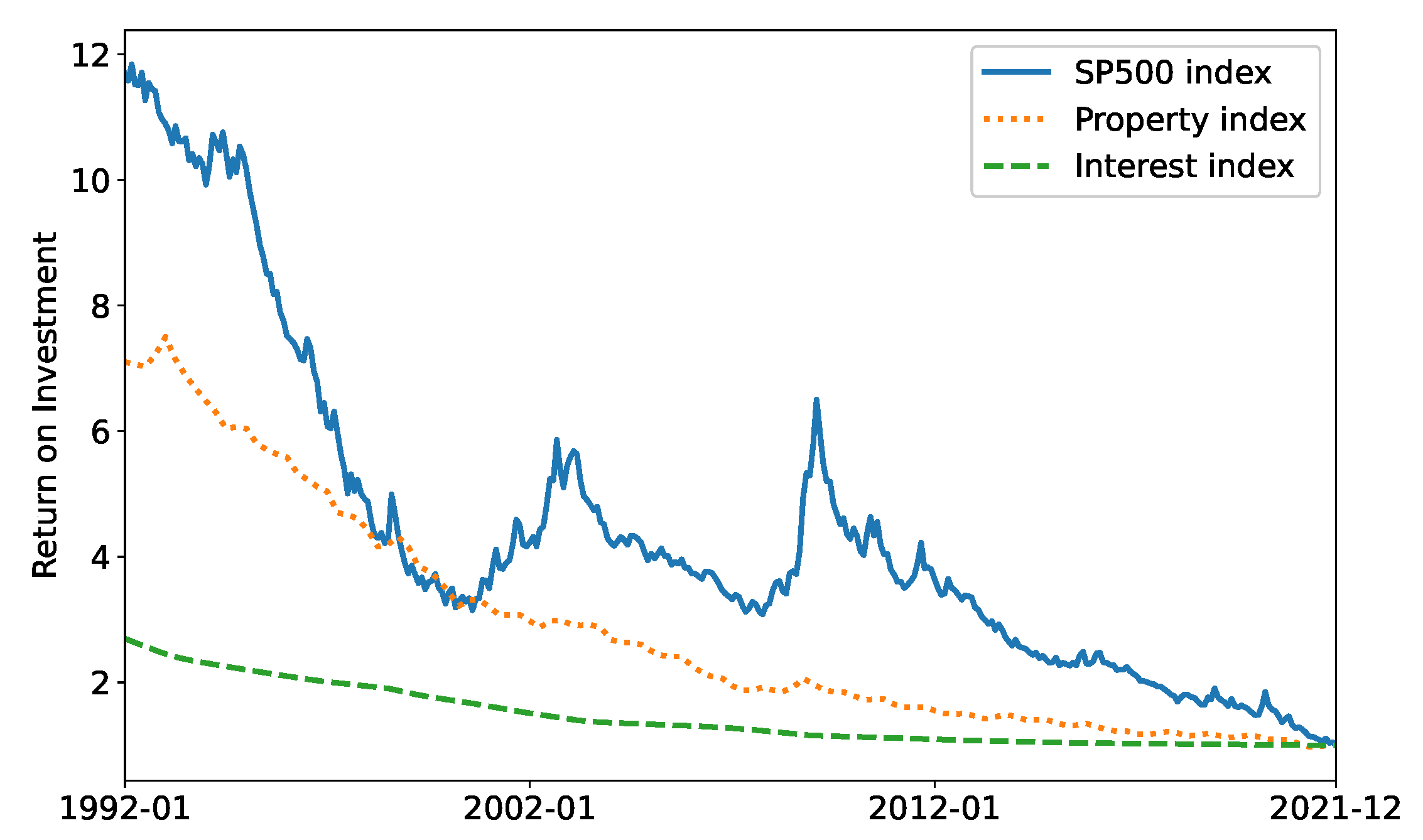
- States A set of 13 continuous values representing the customer age (between 30 and 60 years and normalized to a range of ), six values for the asset class holdings and total portfolio value (scaled by ), and two market indicators for each of the three indices, i.e., their mean asset convergence divergence (MACD) (the difference between the 26-month and the 12-month exponential moving average of a trend) which predicts trend reversals and relative strength index ( where and are the average positive and negative changes to the index values respectively, for x periods) which corrects for potential false predictions by MACD. The time horizon is 30 years.
- Reward The changes in portfolio values between time steps.
- Actions The continuous distribution of funds across the five asset classes.
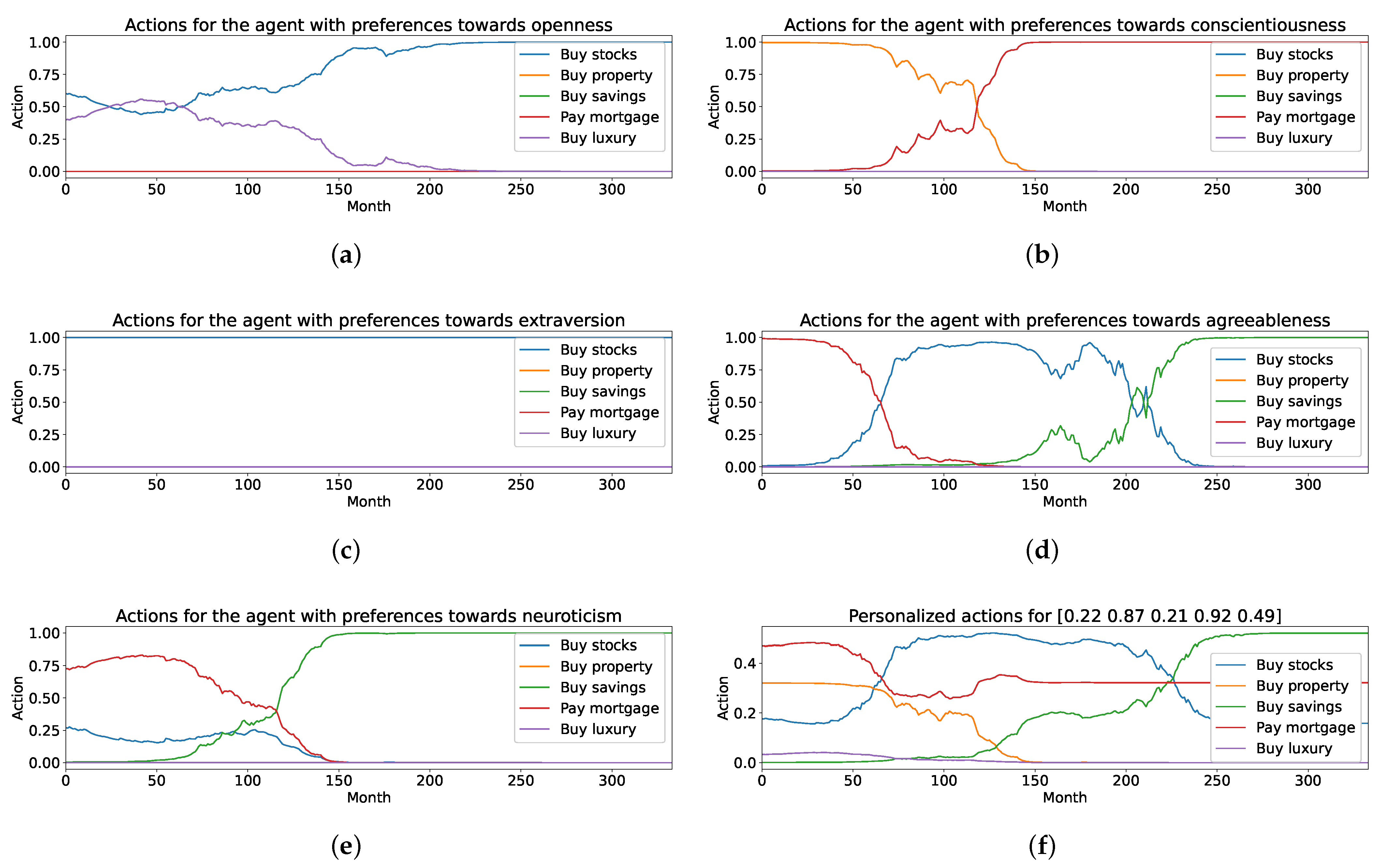
3.2. Agents
4. Results
5. Conclusions and Directions for Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stefanel, M.; Goyal, U. Artificial Intelligence & Financial Services: Cutting through the Noise; Technical Report; APIS Partners: London, UK, 2019. [Google Scholar]
- Jaiwant, S.V. Artificial Intelligence and Personalized Banking. In Handbook of Research on Innovative Management Using AI in Industry 5.0; Vikas, G., Goel, R., Eds.; IGI Global: Bengaluru, India, 2022; pp. 74–87. [Google Scholar]
- van der Burgt, J. General Principles for the Use of Artificial Intelligence in the Financial Sector; Technical Report; De Nederlandsche Bank: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Oyebode, O.; Orji, R. A hybrid recommender system for product sales in a banking environment. J. Bank. Financ. Technol. 2020, 4, 15–25. [Google Scholar] [CrossRef]
- Bhatore, S.; Mohan, L.; Reddy, R. Machine learning techniques for credit risk evaluation: A systematic literature review. J. Bank. Financ. Technol. 2020, 4, 111–138. [Google Scholar] [CrossRef]
- Desai, D. Hyper-Personalization: An AI-Enabled Personalization for Customer-Centric Marketing. In Adoption and Implementation of AI in Customer Relationship Management; Singh, S., Ed.; IGI Global: Maharashtra, India, 2022; pp. 40–53. [Google Scholar]
- Jothimani, D.; Yadav, S. Stock trading decisions using ensemble-based forecasting models: A study of the Indian stock market. J. Bank. Financ. Technol. 2019, 3, 113–129. [Google Scholar] [CrossRef]
- Zhang, Q.; Yan, W.; Kankanhalli, M. Overview of currency recognition using deep learning. J. Bank. Financ. Technol. 2019, 3, 59–69. [Google Scholar] [CrossRef]
- Hsu, T.Y. Machine learning applied to stock index performance enhancement. J. Bank. Financ. Technol. 2021, 5, 21–33. [Google Scholar] [CrossRef]
- Kolm, P.; Ritter, G. Modern Perspectives on Reinforcement Learning in Finance. SSRN Electron. J. 2019, 1, 1–28. [Google Scholar] [CrossRef]
- Fischer, T.G. Reinforcement Learning in Financial Markets—A Survey; Technical Report; Friedrich-Alexander University Erlangen-Nuremberg, Institute for Economics: Erlangen, Germany, 2018. [Google Scholar]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Cao, L. AI in Finance: Challenges, Techniques and Opportunities. Bank. Insur. eJournal 2021, 14, 1–40. [Google Scholar] [CrossRef]
- Maree, C.; Modal, J.E.; Omlin, C.W. Towards Responsible AI for Financial Transactions. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 16–21. [Google Scholar]
- Maree, C.; Omlin, C. Reinforcement Learning Your Way: Agent Characterization through Policy Regularization. AI 2022, 3, 15. [Google Scholar] [CrossRef]
- Tasse, G.N.; James, S.; Rosman, B. A Boolean Task Algebra for Reinforcement Learning. In Proceedings of the Neural Information Processing Systems, Online, 6–12 December 2020; Volume 34, pp. 1–11. [Google Scholar]
- Gladstone, J.; Matz, S.; Lemaire, A. Can Psychological Traits Be Inferred From Spending? Evidence From Transaction Data. Psychol. Sci. 2019, 30, 1087–1096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Matz, S.C.; Gladstone, J.J.; Stillwell, D. Money Buys Happiness When Spending Fits Our Personality. Psychol. Sci. 2016, 27, 715–725. [Google Scholar] [CrossRef] [PubMed]
- Maree, C.; Omlin, C.W. Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021; pp. 1–5. [Google Scholar]
- Maree, C.; Omlin, C.W. Understanding Spending Behavior: Recurrent Neural Network Explanation and Interpretation. In Proceedings of the IEEE Computational Intelligence for Financial Engineering and Economics, Helsinki, Finland, 4–5 May 2022; pp. 1–7, in print. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2019, arXiv:1509.02971. [Google Scholar]
- Bartram, S.M.; Branke, J.; Rossi, G.D.; Motahari, M. Machine Learning for Active Portfolio Management. J. Financ. Data Sci. 2021, 3, 9–30. [Google Scholar] [CrossRef]
- Jurczenko, E. Machine Learning for Asset Management: New Developments and Financial Applications; Wiley-ISTE: London, UK, 2020; pp. 1–460. [Google Scholar]
- Lim, Q.; Cao, Q.; Quek, C. Dynamic portfolio rebalancing through reinforcement learning. Neural Comput. Appl. 2021, 33, 1–15. [Google Scholar] [CrossRef]
- Pinelis, M.; Ruppert, D. Machine learning portfolio allocation. J. Financ. Data Sci. 2022, 8, 35–54. [Google Scholar] [CrossRef]
- Millea, A. Deep reinforcement learning for trading—A critical survey. Data 2021, 6, 119. [Google Scholar] [CrossRef]
- Maree, C.; Omlin, C.W. Balancing Profit, Risk, and Sustainability for Portfolio Management. In Proceedings of the IEEE Computational Intelligence for Financial Engineering and Economics, Helsinki, Finland, 4–5 May 2022; pp. 1–8, in print. [Google Scholar]
- Heuillet, A.; Couthouis, F.; Díaz-Rodríguez, N. Explainability in deep reinforcement learning. Knowl.-Based Syst. 2021, 214, 106685. [Google Scholar] [CrossRef]
- Wells, L.; Bednarz, T. Explainable AI and Reinforcement Learning: A Systematic Review of Current Approaches and Trends. Front. Artif. Intell. 2021, 4, 550030. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Singal, G.; Garg, D. Deep Reinforcement Learning Techniques in Diversified Domains: A Survey. Arch. Comput. Methods Eng. 2021, 28, 4715–4754. [Google Scholar] [CrossRef]
- Ziebart, B.D. Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy. Ph.D. Thesis, Machine Learning Department, Carnegie Mellon University, Pittsburgh, PA, USA, 2010. [Google Scholar]
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement Learning with Deep Energy-Based Policies. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Knight Frank Company. Knight Frank Luxury Investment Index. 2022. Available online: https://www.knightfrank.com/wealthreport/luxury-investment-trends-predictions/ (accessed on 27 May 2022).
- Yahoo Finance. Historical Data for S&P500 Stock Index. 2022. Available online: https://finance.yahoo.com/quote/%5EGSPC/history?p=%5EGSPC, (accessed on 30 January 2022).
- Statistics Norway. Table 07221—Price Index for Existing Dwellings. 2022. Available online: https://www.ssb.no/en/statbank/table/07221/ (accessed on 30 January 2022).
- Norges Bank. Interest Rates. 2022. Available online: https://app.norges-bank.no/query/#/en/interest (accessed on 30 January 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Asset Class Property | Savings | Property | Stocks | Luxury | Mortgage |
|---|---|---|---|---|---|
| High expected long term returns | 0.25 | 0.67 | 1.00 | 0.05 | 0.50 |
| Low expected long term risk | 1.00 | 0.32 | 0.10 | 0.05 | 1.00 |
| High asset liquidity | 1.00 | 0.25 | 0.80 | 0.10 | 0.05 |
| Low minimum investment | 0.80 | 0.25 | 1.00 | 0.50 | 1.00 |
| High perceived novelty | 0.10 | 0.25 | 0.75 | 1.00 | 0.10 |
| Asset Class Property | O | C | E | A | N |
|---|---|---|---|---|---|
| High expected long term returns | 1 | 1 | 2 | 1 | 1 |
| Low expected long term risk | −1 | 2 | −1 | 1 | 2 |
| High asset liquidity | 2 | −1 | 2 | 1 | 2 |
| Low minimum investment | 0 | −1 | 1 | 1 | 1 |
| High perceived novelty | 2 | 0 | 2 | 0 | −1 |
| Investment | O | C | E | A | N |
|---|---|---|---|---|---|
| Savings | −0.11 | 0.08 | −0.15 | 0.51 | 0.68 |
| Property | −0.15 | 0.32 | −0.22 | −0.36 | −0.24 |
| Stocks | 0.82 | −0.61 | 0.95 | 0.42 | 0.12 |
| Luxury | 0.16 | −0.51 | −0.07 | −0.80 | −0.81 |
| Mortgage | −0.72 | 0.72 | −0.52 | 0.23 | 0.25 |
| Investment | |||||
|---|---|---|---|---|---|
| Savings | 0.00 | 0.07 | 0.00 | 0.44 | 0.64 |
| Property | 0.00 | 0.28 | 0.00 | 0.00 | 0.00 |
| Stocks | 0.84 | 0.00 | 1.00 | 0.36 | 0.12 |
| Luxury | 0.16 | 0.00 | 0.00 | 0.00 | 0.00 |
| Mortgage | 0.00 | 0.65 | 0.00 | 0.02 | 0.24 |
| Policy | Final Portfolio Value (NOK 1M) |
|---|---|
| Openness | 22.4 |
| Conscientiousness | 18.8 |
| Extraversion * | 27.7 |
| Agreeableness | 20.5 |
| Neuroticism | 16.4 |
| Personal agent | 20.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maree, C.; Omlin, C.W. Can Interpretable Reinforcement Learning Manage Prosperity Your Way? AI 2022, 3, 526-537. https://doi.org/10.3390/ai3020030
Maree C, Omlin CW. Can Interpretable Reinforcement Learning Manage Prosperity Your Way? AI. 2022; 3(2):526-537. https://doi.org/10.3390/ai3020030
Chicago/Turabian StyleMaree, Charl, and Christian W. Omlin. 2022. "Can Interpretable Reinforcement Learning Manage Prosperity Your Way?" AI 3, no. 2: 526-537. https://doi.org/10.3390/ai3020030
APA StyleMaree, C., & Omlin, C. W. (2022). Can Interpretable Reinforcement Learning Manage Prosperity Your Way? AI, 3(2), 526-537. https://doi.org/10.3390/ai3020030