
Use of Yolo Detection for 3D Pose Tracking of Cardiac Catheters Using Bi-Plane Fluoroscopy

 ,
,  , , and
, , and 
Abstract
1. Introduction
- Improved accuracy by using the Yolo architecture for object detection;
- Deep learning-based bounding box pose estimation of the catheter, including four classes of landmark features, namely catheter tip, radio-opaque marker, bend, and entry, for future use in catheter tracking systems;
- A new diverse catheter dataset with a complete bounding box and representative pixel annotation.
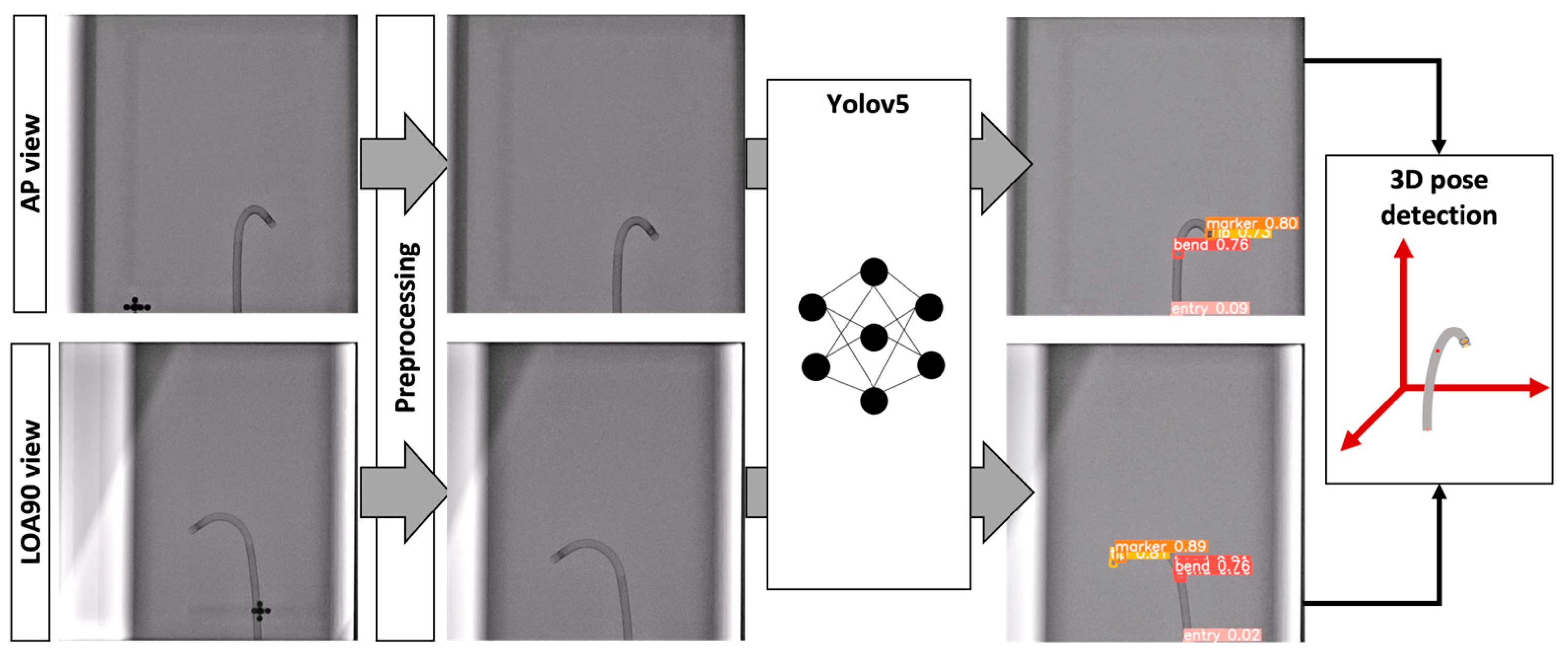
2. Materials and Methods
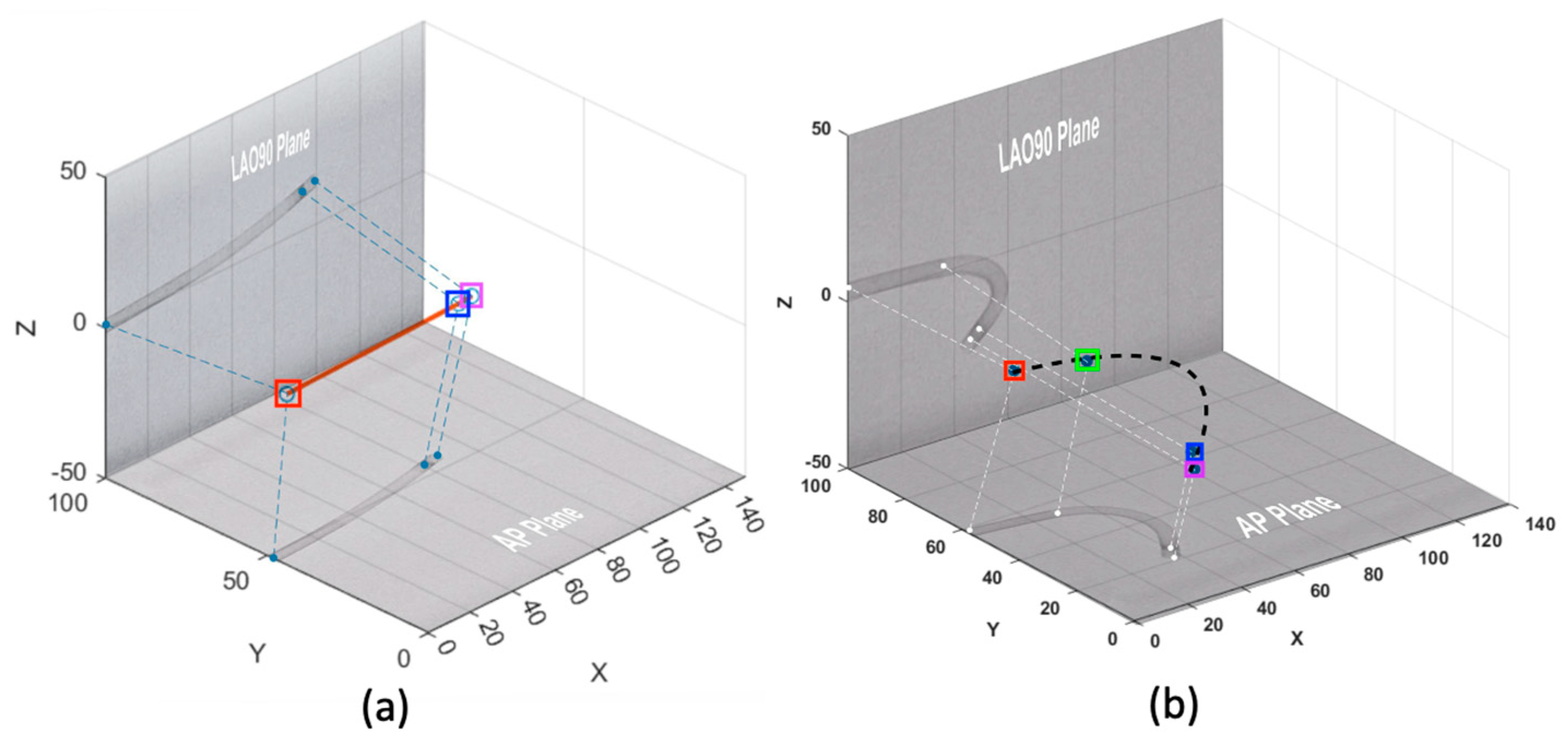
3. Results and Discussion
3.1. Experiment 1—Paired AP LAO90 Dataset
3.2. Experiment 2—Combinatory Dataset, Tested on a Combinatory Test Set
3.3. Experiment 3—Combinatory Dataset, Tested Only on the Paired Dataset
3.4. Result Analysis
3.5. Limitations
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fazlali, H.R.; Karimi, N.; Soroushmehr, S.M.R.; Shirani, S.; Nallamothu, B.K.; Ward, K.R.; Samavi, S.; Najarian, K. Vessel segmentation and catheter detection in X-ray angiograms using superpixels. Med. Biol. Eng. Comput. 2018, 56, 1515–1530. Available online: https://link.springer.com/article/10.1007/s11517-018-1793-4 (accessed on 6 May 2024). [CrossRef] [PubMed]
- Spenkelink, I.M.; Heidkam, J.; Fütterer, J.J.; Rovers, M.M. Image-guided procedures in the hybrid operating room: A systematic scoping review. PLoS ONE 2022, 17, e0266341. Available online: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0266341 (accessed on 6 May 2024). [CrossRef] [PubMed]
- Steinberg, Z.L.; Singh, H.S. How to plan and perform a diagnostic catheterisation in adult patients with congenital heart disease. Heart 2023, 109, 151–157. [Google Scholar] [CrossRef] [PubMed]
- Gurgitano, M.; Angileri, S.A.; Rodà, G.M.; Liguori, A.; Pandolfi, M.; Ierardi, A.M.; Wood, B.J.; Carrafiello, G. Interventional Radiology ex-machina: Impact of Artificial Intelligence on practice. La Radiol. Medica 2021, 126, 998–1006. Available online: https://link.springer.com/article/10.1007/s11547-021-01351-x (accessed on 6 May 2024). [CrossRef] [PubMed]
- Abdulhafiz, I.; Janabi-Sharifi, F. A Hybrid approach to 3D shape estimation of catheters using ultrasound images. IEEE Robot. Autom. Lett. 2023, 8, 1912–1919. Available online: https://ieeexplore.ieee.org/abstract/document/10042968 (accessed on 6 May 2024). [CrossRef]
- Greer, J.S.; Hussein, M.A.; Vamsee, R.; Arar, Y.; Krueger, S.; Weiss, S.; Dillenbeck, J.; Greil, G.; Veeram Reddy, S.R.; Hussain, T. Improved catheter tracking during cardiovascular magnetic resonance-guided cardiac catheterization using overlay visualization. J. Cardiovasc. Magn. Reson. 2022, 24, 32. Available online: https://link.springer.com/article/10.1186/s12968-022-00863-3 (accessed on 6 May 2024). [CrossRef] [PubMed]
- Kim, T.; Hedayat, M.; Vaitkus, V.V.; Belohlavek, M.; Krishnamurthy, V.; Borazjani, I. A learning-based, region of interest-tracking algorithm for catheter detection in echocardiography. Comput. Med. Imaging Graph. 2022, 100, 102106. Available online: https://www.sciencedirect.com/science/article/pii/S0895611122000787 (accessed on 6 May 2024). [CrossRef] [PubMed]
- Zar, H.A.; Goharimanesh, M.; Janabi-Sharifi, F. Mathematical Modeling and Machine Learning for Force Estimation on a Planar Catheter. In Proceedings of the Canadian Society for Mechanical Engineering International Congress, Edmonton, AB, Canada, 5–8 June 2022. [Google Scholar]
- Wu, D.; Ha, X.T.; Zhang, Y.; Ourak, M.; Borghesan, G.; Niu, K.; Trauzettel, F.; Dankelman, J.; Menciassi, A.; Poorten, E.V. Deep-learning-based compliant motion control of a pneumatically-driven robotic catheter. IEEE Robot. Autom. Lett. 2022, 7, 8853–8860. Available online: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9807375 (accessed on 6 May 2024). [CrossRef]
- Lawson, J.; Chitale, R.; Simaan, N. Model-Based pose estimation of steerable catheters under bi-Plane image feedback. arXiv 2023, arXiv:2304.12165. [Google Scholar]
- Manavi, S.; Renna, T.; Horvath, A.; Freund, S.; Zam, A.; Rauter, G.; Schade, W.; Cattin, P.C. Using supervised deep-learning to model edge-FBG shape sensors. In Proceedings of the Optical Sensors, Online, 19–30 April 2021; p. 11772. Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/11772/117720P/Using-supervised-deep-learning-to-model-edge-FBG-shape-sensors/10.1117/12.2589252.full (accessed on 6 May 2024).
- Eagleton, M.J. Updates in endovascular procedural navigation in Canadian Journal of Cardiology. Can. J. Cardiol. 2022, 38, 662–671. [Google Scholar] [CrossRef]
- Vernikouskaya, I.; Bertsche, D.; Rottbauer, W.; Rasche, V. Deep learning-based framework for motion-compensated image fusion in catheterization procedures. Comput. Med. Imaging Graph. 2022, 98, 102069. Available online: https://www.sciencedirect.com/science/article/pii/S0895611122000428 (accessed on 6 May 2024). [CrossRef] [PubMed]
- Ravigopal, S.R.; Sarma, A.; Brumfiel, T.A.; Desai, J.P. Real-time pose tracking for a continuum guidewire robot under fluoroscopic imaging. IEEE Trans. Med. Robot. Bionics 2023, 5, 230–241. [Google Scholar] [CrossRef] [PubMed]
- Ramadani, A.; Bui, M.; Wendler, T.; Schunkert, H.; Ewert, P.; Navab, N. Survey of catheter tracking concepts and methodologies. Med. Image Anal. 2022, 82, 102584. Available online: https://www.sciencedirect.com/science/article/pii/S1361841522002225 (accessed on 6 May 2024). [CrossRef] [PubMed]
- Aghasizade, M.; Kiyoumarsioskouei, A.; Hashemi, S.; Torabinia, M.; Caprio, A.; Rashid, M.; Xiang, Y.; Rangwala, H.; Ma, T.; Lee, B.; et al. A coordinate-regression-based deep learning model for catheter detection during structural heart interventions. Appl. Sci. 2023, 13, 7778. [Google Scholar] [CrossRef]
- Torabinia, M.; Caprio, A.; Jang, S.-J.; Ma, T.; Tran, H.; Mekki, L.; Chen, I.; Sabuncu, M.; Wong, S.C.; Mosadegh, B. Deep learning-driven catheter tracking from bi-plane X-ray fluoroscopy of 3D printed heart phantoms. Mini-Invasive Surg. 2021, 5, 32. [Google Scholar] [CrossRef]
- Liu, D.; Tupor, S.; Singh, J.; Chernoff, T.; Leong, N.; Sadikov, E.; Amjad, A.; Zilles, S. The challenges facing deep learning–based catheter localization for ultrasound guided high-dose-rate prostate brachytherapy. Med. Phys. 2022, 49, 2442–2451. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012; Available online: https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 6 May 2024).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1409–1556. Available online: https://arxiv.org/pdf/1409.1556.pdf (accessed on 6 May 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. Available online: https://arxiv.org/pdf/1512.03385.pdf (accessed on 6 May 2024).
- Munea, T.L.; Jembre, Y.Z.; Weldegebriel, H.T.; Chen, L.; Huang, C.; Yang, C. The progress of human pose estimation: A survey and taxonomy of models applied in 2D human pose estimation. IEEE Access 2020, 8, 133330–133348. [Google Scholar] [CrossRef]
- Jensen, A.J.; Flood, P.D.L.; Palm-Vlasak, L.S.; Burton, W.S.; Chevalier, A.; Rullkoetter, P.J.; Banks, S.A. Joint track machine learning: An autonomous method of measuring total knee arthroplasty kinematics from single-plane X-ray images. J. Arthroplast. 2023, 38, 2068–2074. Available online: https://www.sciencedirect.com/science/article/pii/S0883540323005521 (accessed on 6 May 2024). [CrossRef] [PubMed]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2017, arXiv:1602.07360. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. Available online: https://openaccess.thecvf.com/content_cvpr_2018/papers/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.pdf (accessed on 6 May 2024).
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31, pp. 4278–4284. Available online: http://www.cs.cmu.edu/~jeanoh/16-785/papers/szegedy-aaai2017-inception-v4.pdf (accessed on 6 May 2024).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar] [CrossRef] [PubMed]
- Baccouche, A.; Garcia-Zapirain, B.; Zheng, Y.; Elmaghraby, A.S. Early detection and classification of abnormality in prior mammograms using image-to-image translation and YOLO techniques. Comput. Methods Programs Biomed. 2022, 221, 106884. [Google Scholar] [CrossRef]
- Baccouche, A.; Garcia-Zapirain, B.; Olea, C.C.; Elmaghraby, A.S. Breast lesions detection and classification via YOLO-based fusion models. Comput. Mater. Contin. 2021, 69, 106884. Available online: https://www.sciencedirect.com/science/article/pii/S0169260722002668 (accessed on 6 May 2024). [CrossRef]
- George, J.; Skaria, S.; Varun, V. Using YOLO based deep learning network for real time detection and localization of lung nodules from low dose CT scans. In Proceedings of the SPIE 2018: Medical Imaging: Computer-Aided Diagnosis, Houston, TX, USA, 10–15 February 2018; Volume 10575, pp. 347–355. Available online: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/10575/2293699/Using-YOLO-based-deep-learning-network-for-real-time-detection/10.1117/12.2293699.full (accessed on 6 May 2024).
- Kavitha, A.R.; Palaniappan, K. Brain tumor segmentation using a deep Shuffled-YOLO network. Int. J. Imaging Syst. Technol. 2023, 33, 511–522. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1002/ima.22832 (accessed on 6 May 2024). [CrossRef]
- Amiri Tehrani Zade, A.; Jalili Aziz, M.; Majedi, H.; Mirbagheri, A.; Ahmadian, A. Spatiotemporal analysis of speckle dynamics to track invisible needle in ultrasound sequences using convolutional neural networks: A phantom study. Int. J. Comput. Assist. Radiol. Surg. 2023, 18, 1373–1382. Available online: https://pubmed.ncbi.nlm.nih.gov/36745339/ (accessed on 6 May 2024). [CrossRef] [PubMed]
- Krumb, H.J.; Dorweiler, B.; Mukhopadhyay, A. HEX: A safe research framework for hybrid EMT X-ray navigation. Int. J. Comput. Assist. Radiol. Surg. 2023, 18, 1175–1183. Available online: https://link.springer.com/article/10.1007/s11548-023-02917-y (accessed on 6 May 2024). [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Exp | Training Set | Test Set | Bi-Plane (Pixels) | 3D (Pixels) | 3D (mm) |
|---|---|---|---|---|---|---|
| Avg. Acc | Avg. Acc | Avg. Acc | ||||
| Tip | 1 | DS. 1 | DS. 1 | 1.171 ± 0.848 | 1.031 ± 0.482 | 0.296 ± 0.138 |
| 2 | DS. 1&2 | DS. 1&2 | 1.277 ± 0.816 | N/A | N/A | |
| 3 | DS. 1 | 1.208 ± 0.833 | 0.995 ± 0.498 | 0.285 ± 0.143 | ||
| Marker | 1 | DS. 1 | DS. 1 | 1.042 ± 0.675 | 0.924 ± 0.494 | 0.265 ± 0.142 |
| 2 | DS. 1&2 | DS. 1&2 | 1.009 ± 0.602 | N/A | N/A | |
| 3 | DS. 1 | 1.075 ± 0.660 | 0.909 ± 0.482 | 0.261 ± 0.138 | ||
| Bend | 1 | DS. 1 | DS. 1 | 2.496 ± 2.000 | 1.454 ± 1.130 | 0.417 ± 0.325 |
| 2 | DS. 1&2 | DS. 1&2 | 3.426 ± 3.511 | N/A | N/A | |
| 3 | DS. 1 | 2.512 ± 2.173 | 1.477 ± 1.258 | 0.424 ± 0.361 | ||
| Entry | 1 | DS. 1 | DS. 1 | 0.898 ± 0.489 | 0.851 ± 0.379 | 0.244 ± 0.109 |
| 2 | DS. 1&2 | DS. 1&2 | 1.063 ± 0.578 | N/A | N/A | |
| 3 | DS. 1 | 0.979 ± 0.443 | 0.819 ± 0.297 | 0.235 ± 0.085 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hashemi, S.; Annabestani, M.; Aghasizade, M.; Kiyoumarsioskouei, A.; Wong, S.C.; Mosadegh, B. Use of Yolo Detection for 3D Pose Tracking of Cardiac Catheters Using Bi-Plane Fluoroscopy. AI 2024, 5, 887-897. https://doi.org/10.3390/ai5020044
Hashemi S, Annabestani M, Aghasizade M, Kiyoumarsioskouei A, Wong SC, Mosadegh B. Use of Yolo Detection for 3D Pose Tracking of Cardiac Catheters Using Bi-Plane Fluoroscopy. AI. 2024; 5(2):887-897. https://doi.org/10.3390/ai5020044
Chicago/Turabian StyleHashemi, Sara, Mohsen Annabestani, Mahdie Aghasizade, Amir Kiyoumarsioskouei, S. Chiu Wong, and Bobak Mosadegh. 2024. "Use of Yolo Detection for 3D Pose Tracking of Cardiac Catheters Using Bi-Plane Fluoroscopy" AI 5, no. 2: 887-897. https://doi.org/10.3390/ai5020044
APA StyleHashemi, S., Annabestani, M., Aghasizade, M., Kiyoumarsioskouei, A., Wong, S. C., & Mosadegh, B. (2024). Use of Yolo Detection for 3D Pose Tracking of Cardiac Catheters Using Bi-Plane Fluoroscopy. AI, 5(2), 887-897. https://doi.org/10.3390/ai5020044