
IndShaker: A Knowledge-Based Approach to Enhance Multi-Perspective System Dynamics Analysis


Abstract
1. Introduction
2. Related Work
3. Background Concepts
- Multi-criteria Analysis. The target system intrinsically addresses scenarios that require more than one criterion to perform a reasonable analysis. Typical examples are, among others, situations characterized by complexity [21], wickedness [22], as well as soft systems [23]. Complexity may refer to many different contexts but it is, in general, associated with unpredictable behaviors—i.e., people behavior. Wicked problems present a significant resistance to solution and are, indeed, often considered impossible to solve because of requirements (normally incomplete, contradictory and constantly changing) and of complex dependencies, which may generate trade-off and other issues. Soft problems are usually real-world problems whose formulation is problematic, normally because they can be perceived in a different way depending on the point of view. MCDA is a classic and consolidated approach [24] that has evolved in the context of different application domains [25].
- Evidence-based approach. The analysis strategy assumes measurable input (indicators) to establish an evidence-based approach to decision making [26].
- Multi-perspective interpretation. Interpretation is another key factor for the target analysis as any complex scenario is somehow likely to be understood and perceived in a different way by different individuals or stakeholders. It affects above all the decision-making process (e.g., ref. [27]).
- Heterogeneity. The information adopted to model a system that presents a certain complexity is very likely to present a certain heterogeneity that is normally requested whenever the target analysis aims to reflect or consider multiple aspects. Properly dealing with heterogeneity (e.g., ref. [28]) becomes a critical factor to create a focused analysis framework and avoid entropic or excessively biased environments.
- Quantitative/qualitative metrics. Qualitative (e.g., ref. [29]) and quantitative (e.g., ref. [30]) methods are available for decision making. The analysis framework is based in the concept of quantitative measures. However, such a quantitative approach is integrated with qualitative aspects to enforce more contextual analysis.
- Adaptive mechanisms. Adaptive decision making [31] is a well-known need for a generic approach, as frameworks need to adapt somehow to specific situations and contexts. The proposed solution adopts an adaptive algorithm that systematically tunes computational parameters to limit bias that may come from strong numerical differences in heterogeneous environments. A transparent view of tuning parameter contributes to avoid a “black-box” approach.
- Dynamic analysis model. In order to assure a model of analysis that takes into account the evolution of a given system, the framework works assuming an observation interval and looks at the evolution of the system from .
- Semantics associated with data. The analysis is performed by combining numerical indicators that are semantically enriched (e.g., ref. [32]) to describe contextual and situation-specific interpretations. In the approach proposed, semantics are understood at different levels and, in general terms, may be dynamically specified or extended to reflect the analysis context.
- Uncertainty management via transparency. Uncertainty is somehow an intrinsic factor in system analysis and decision making. It evidently applies also to MCDA [33,34]. In the context of the proposed framework, uncertainty is mostly related to the relevance associated with the different criteria and to the adaptive mechanisms, as well as to missing data. The metrics provided to estimate uncertainty contribute to a more transparent analysis environment on one side and, on the other side, may be used as a driver factor to select input data in case of multiple available choices.
4. Framework Overview
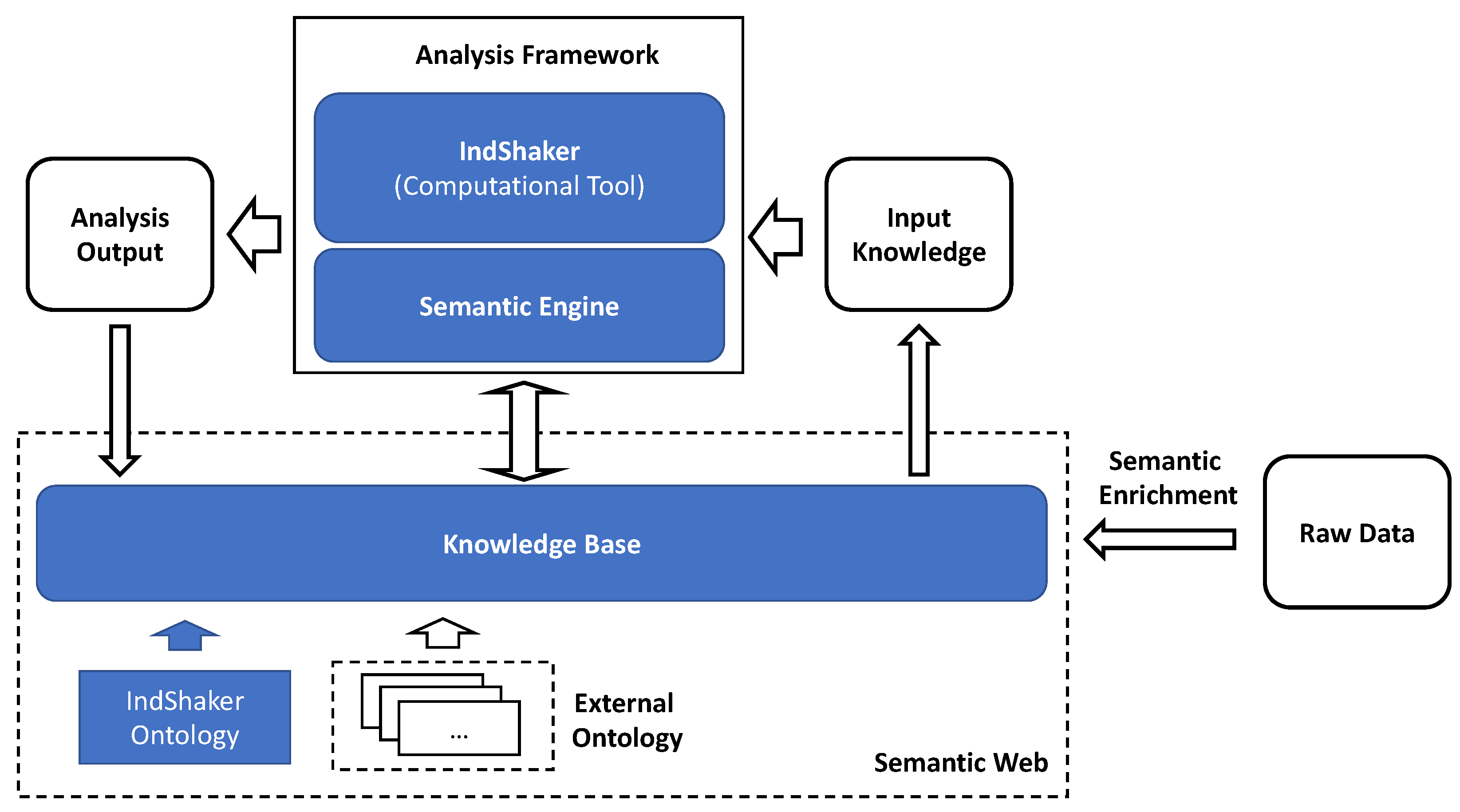
4.1. Reference Architecture
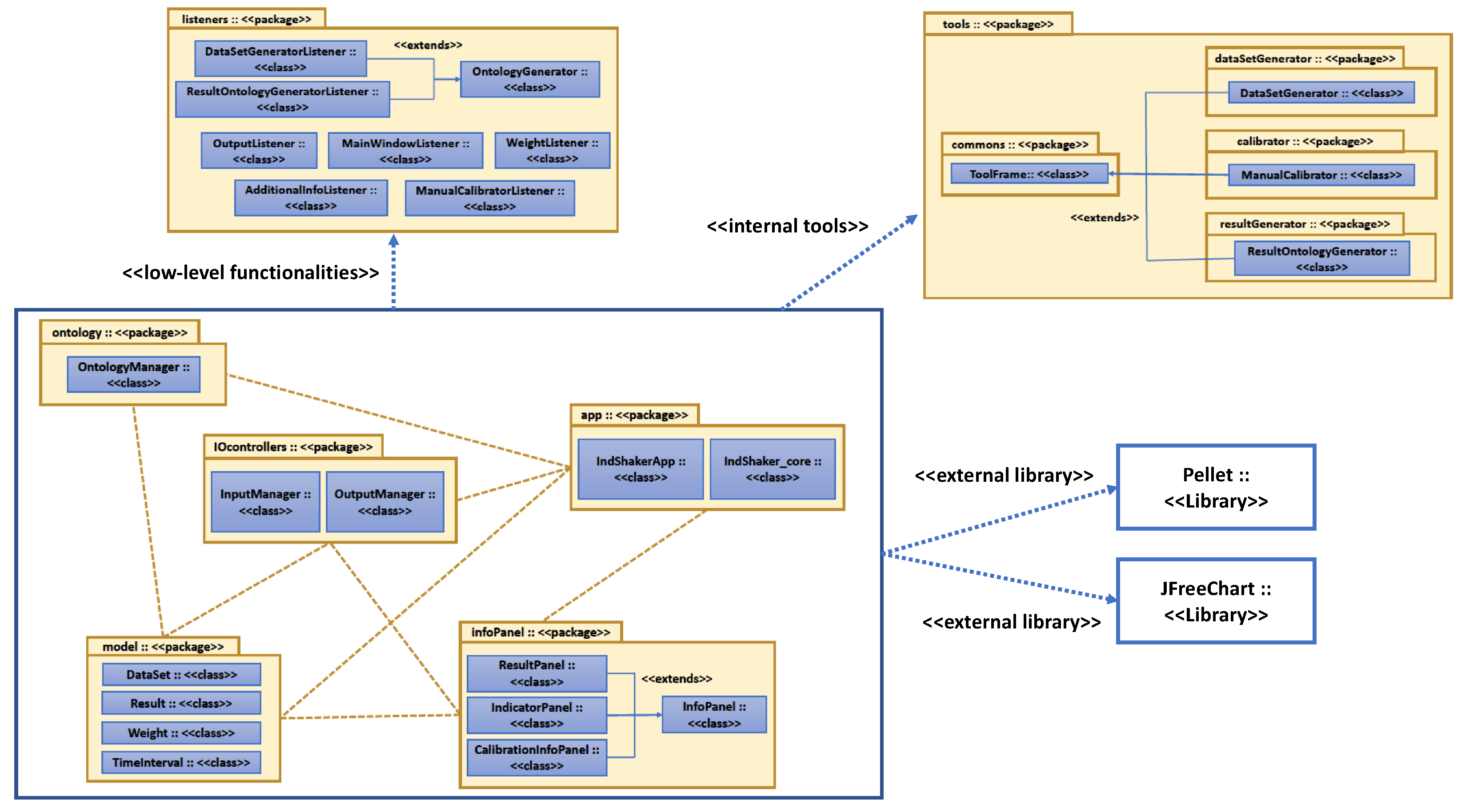
4.2. IndShaker V1.0
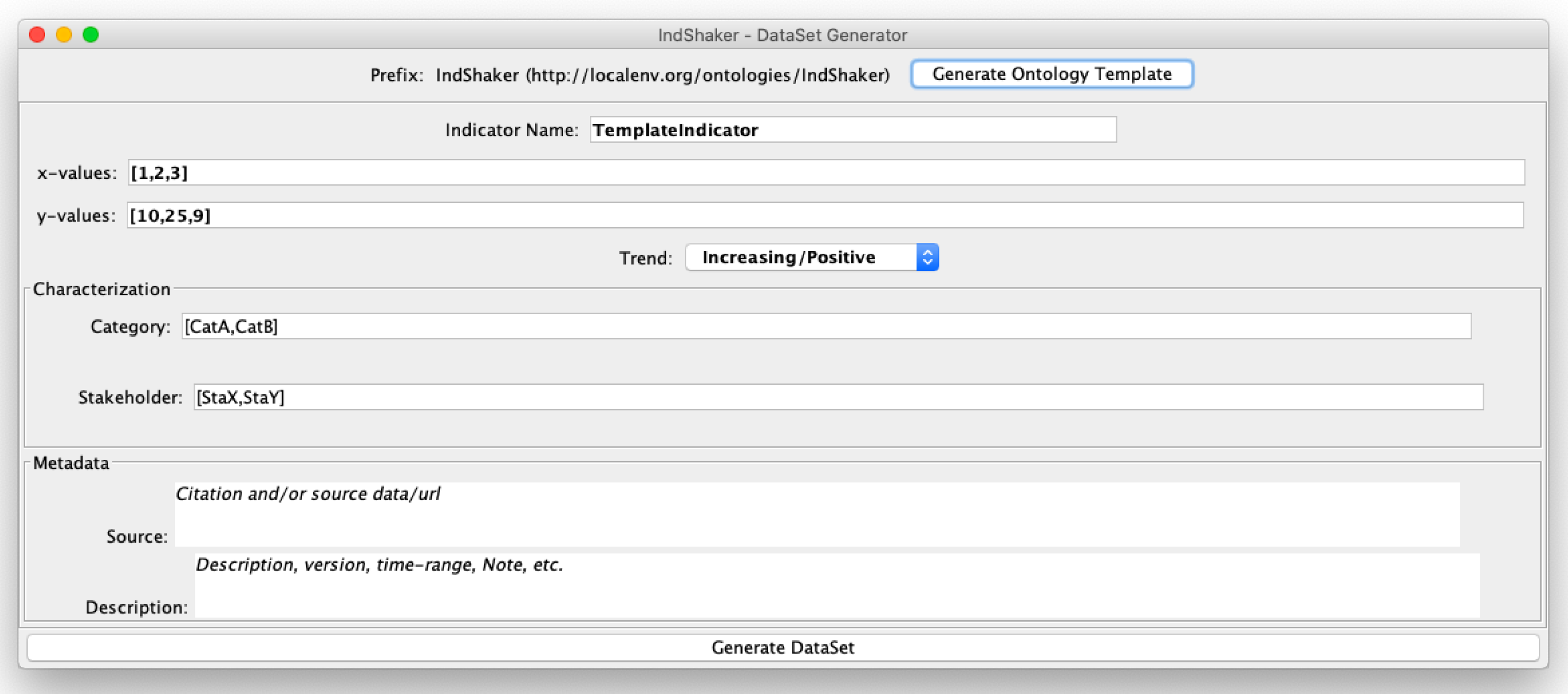
4.2.1. Open-Source Software Tool
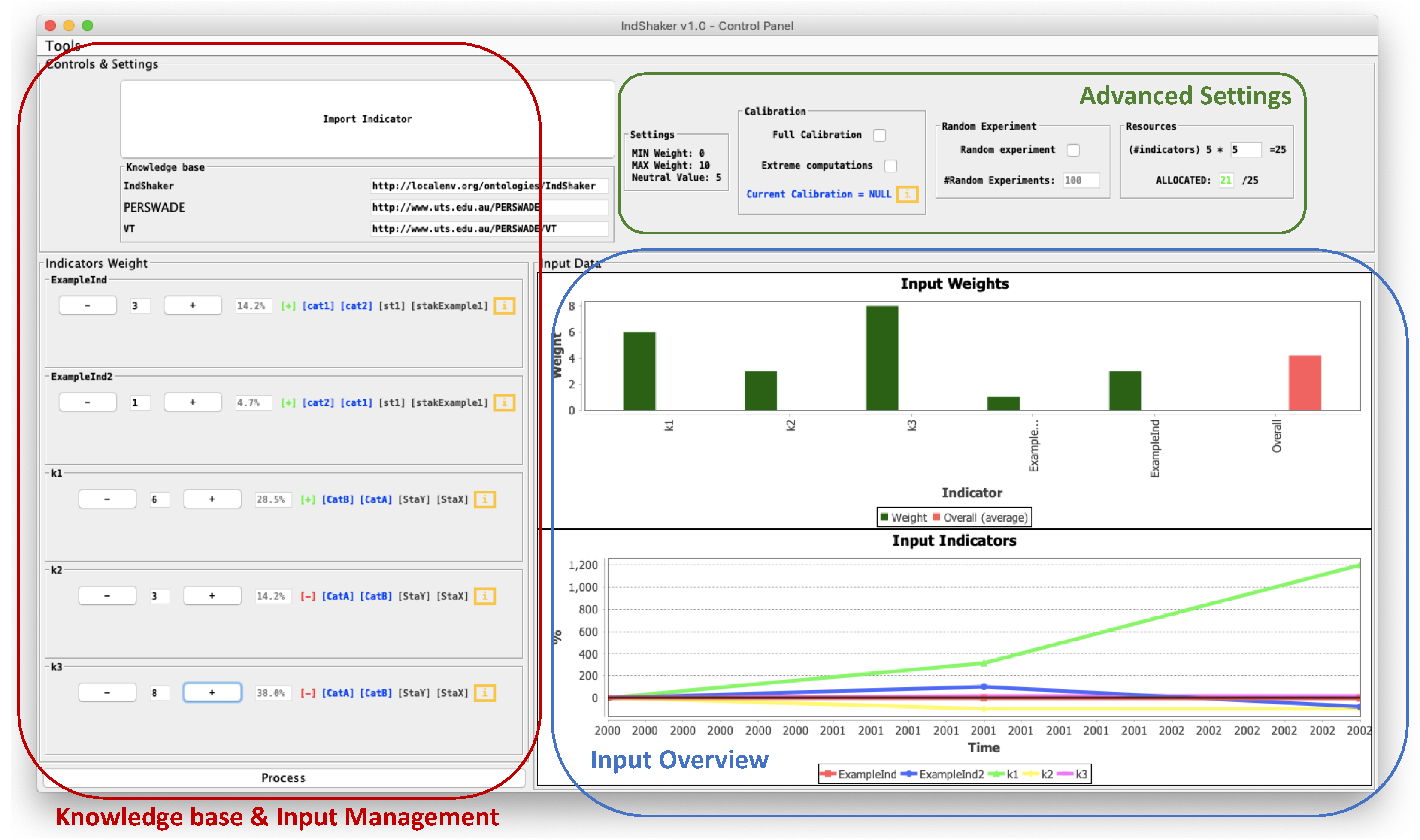
4.2.2. Graphic User Interface (GUI)
4.2.3. Current Limitations
5. A Knowledge-Based Approach
5.1. Ontological Support: An Overview

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ontology | Prefix | Scope | Reference |
|---|---|---|---|
| VirtualTable | VT | Data Integration purpose | [39] |
| FN-Indicator | IND | Specification of composed indicators | [40] |
| PERSWADE-CORE | PERSWADE | Project/Case Study description | [41] |
| EM-Ontology | EM | Stakeholder specification | [42] |



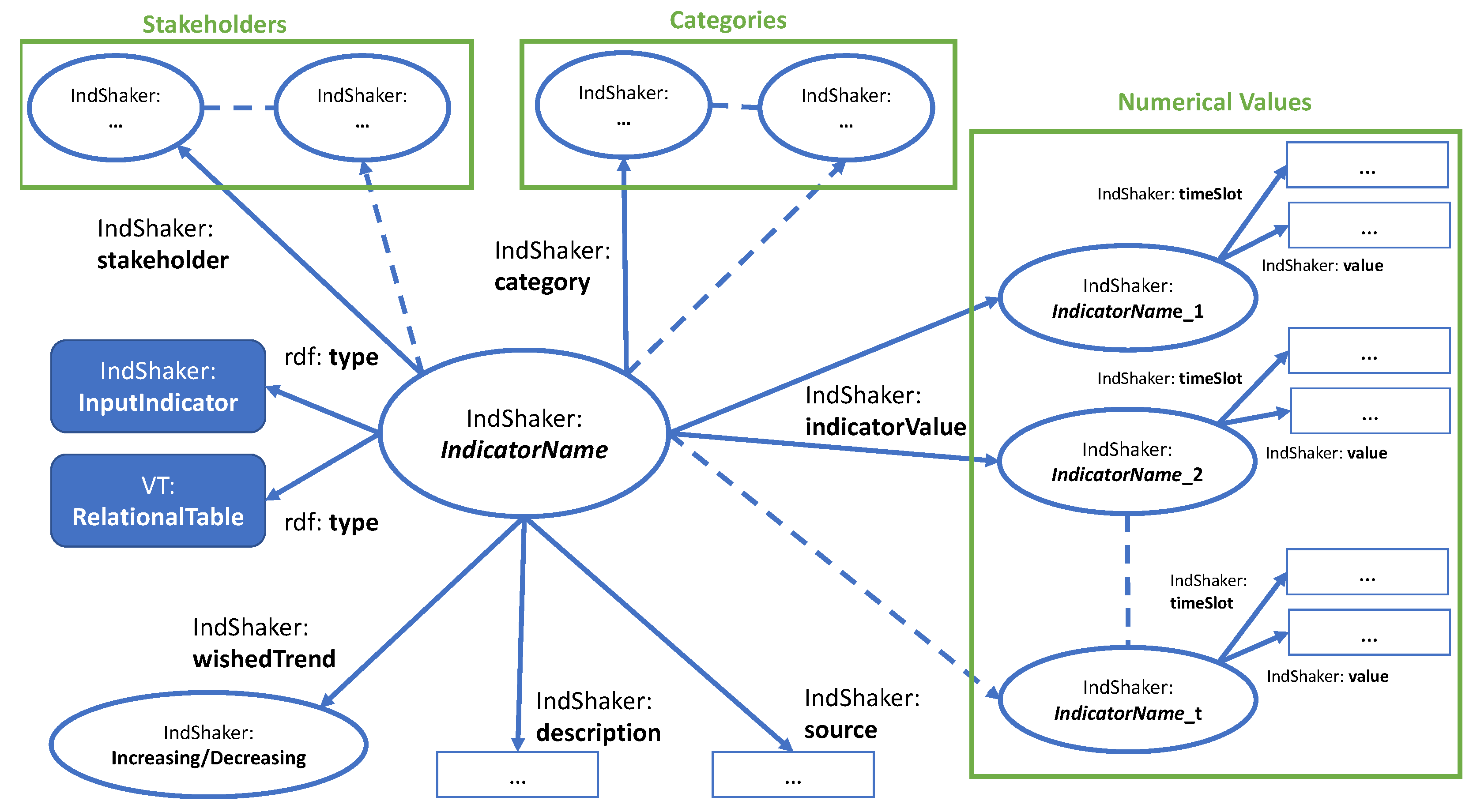
5.2. From Indicators to Input Knowledge
| Listing 1. Simplified example of an input structure in OWL. |
 |
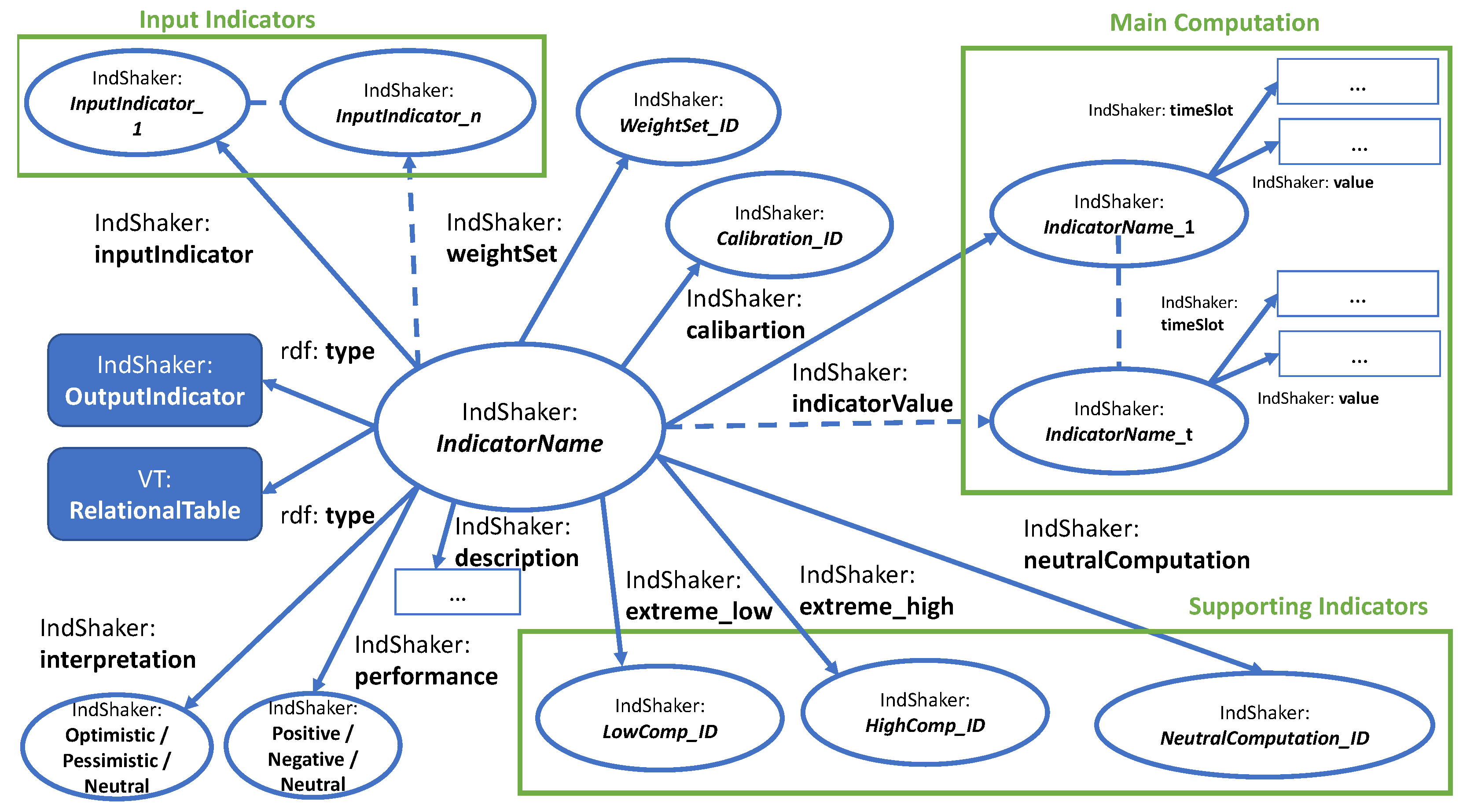
5.3. Describing Target Knowledge
| Listing 2. Simplified example of an output structure in OWL. |
 |
6. Applications
- Decision Making/System Analysis. It is the most generic possible understanding of the framework. Decision making is performed as a systematic analysis of system dynamics, which result by the combination of independent indicators. Such an approach becomes valuable and practical in the presence of a significant heterogeneity, as well as allowing the specification of ad hoc semantics to enforce transparency and, in the limit of the possible, to minimize bias.
- Communication Framework. The current focus, that includes both quantitative and qualitative aspects, can potentially contribute to enhance the proper communication of a given result, assessment or analysis. For instance, storytelling [44] may be empowered by adopting an effective visualization based on numerical indicators and trends integrated with user-level semantics.
- Gamification. Similarly, the framework can underpin gamification strategies [4] at multiple levels in different context to achieve different goals. Some of the features already available, such as the possibility to define constraints for weights, are intrinsically suitable to gamification.
- Research Tool. The current application in the field of Sustainable Global Development previously mentioned is a clear example of use of the framework as a research tool. Indeed, the framework is expected to facilitate system modeling though indicators and semantics and to support the formulation of research questions related to the target system assessment.
- Educational purpose. Intuitively, applications within the education domain follow the same mainstream and underlying principles of research, as case studies can be modeled from available data and analysis/assessment can be performed accordingly. A gamified approach to learning [45] could be a further added value.
- Stakeholders Analysis in Complex Environments. Stakeholders analysis [46] may become challenging in complex environments where unpredictable behaviors can potentially meet contrasting interests and resulting trade-offs. Upon data availability, IndShaker may integrate a quantitative dimension of analysis with qualitative ones (e.g., ref. [42]).
- Participatory Modeling. Decision-making and knowledge-building processes that require or involve multiple stakeholders [5] can be supported by providing a knowledge-based resource to process heterogeneous data in context.
7. Evaluation
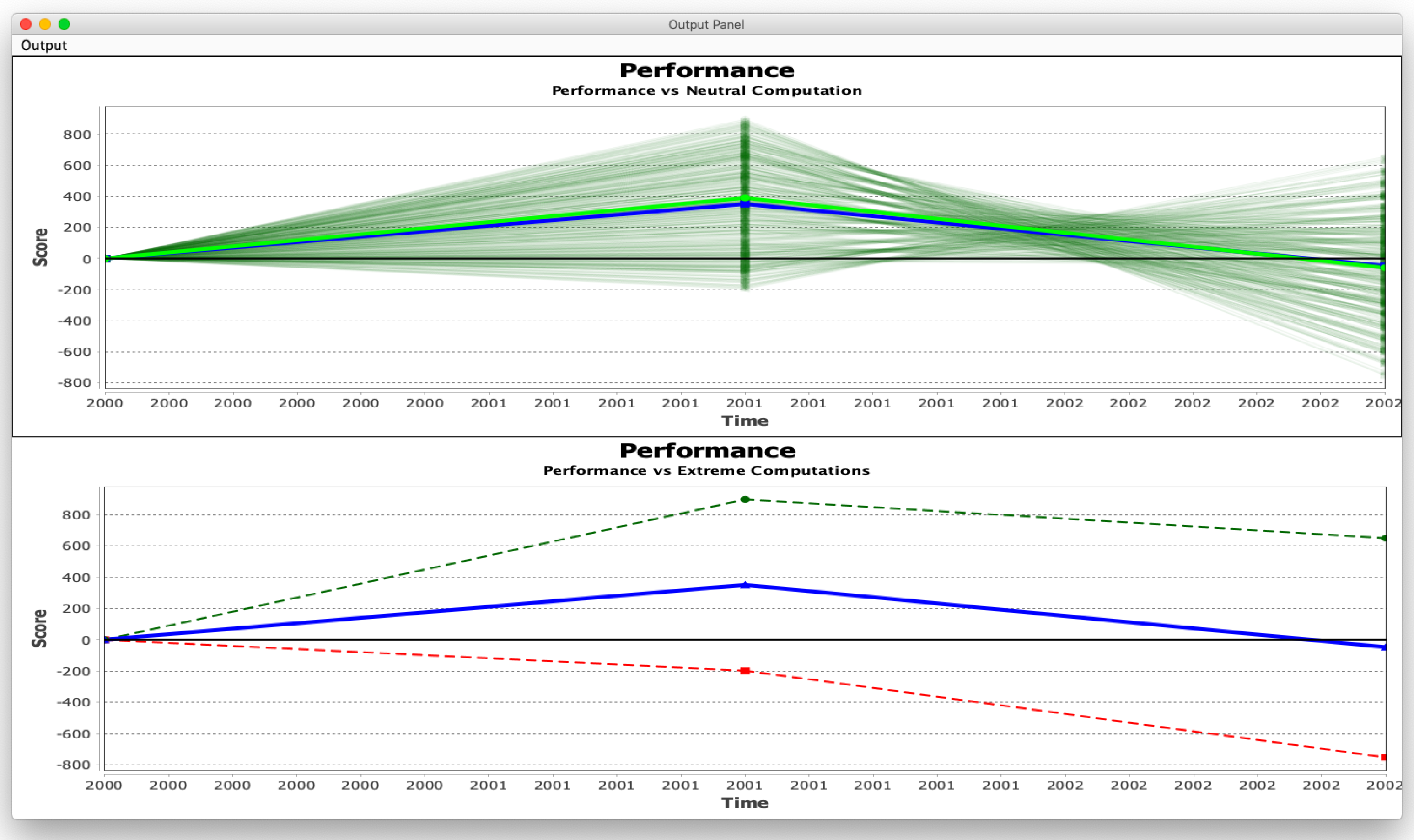
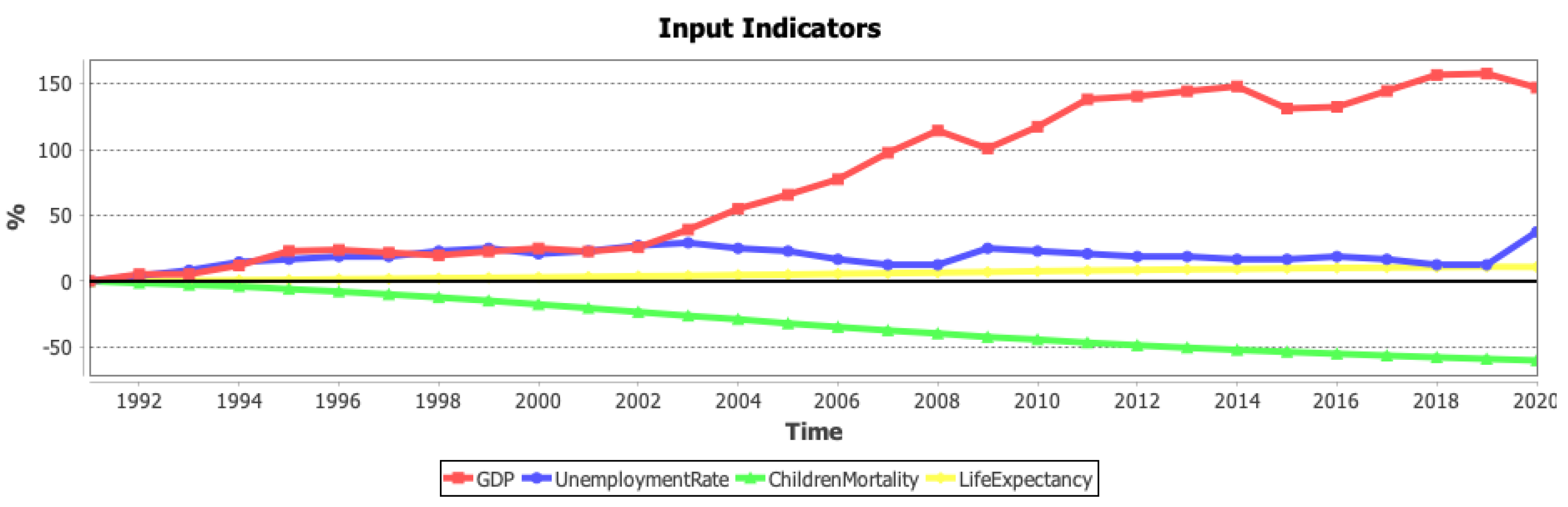
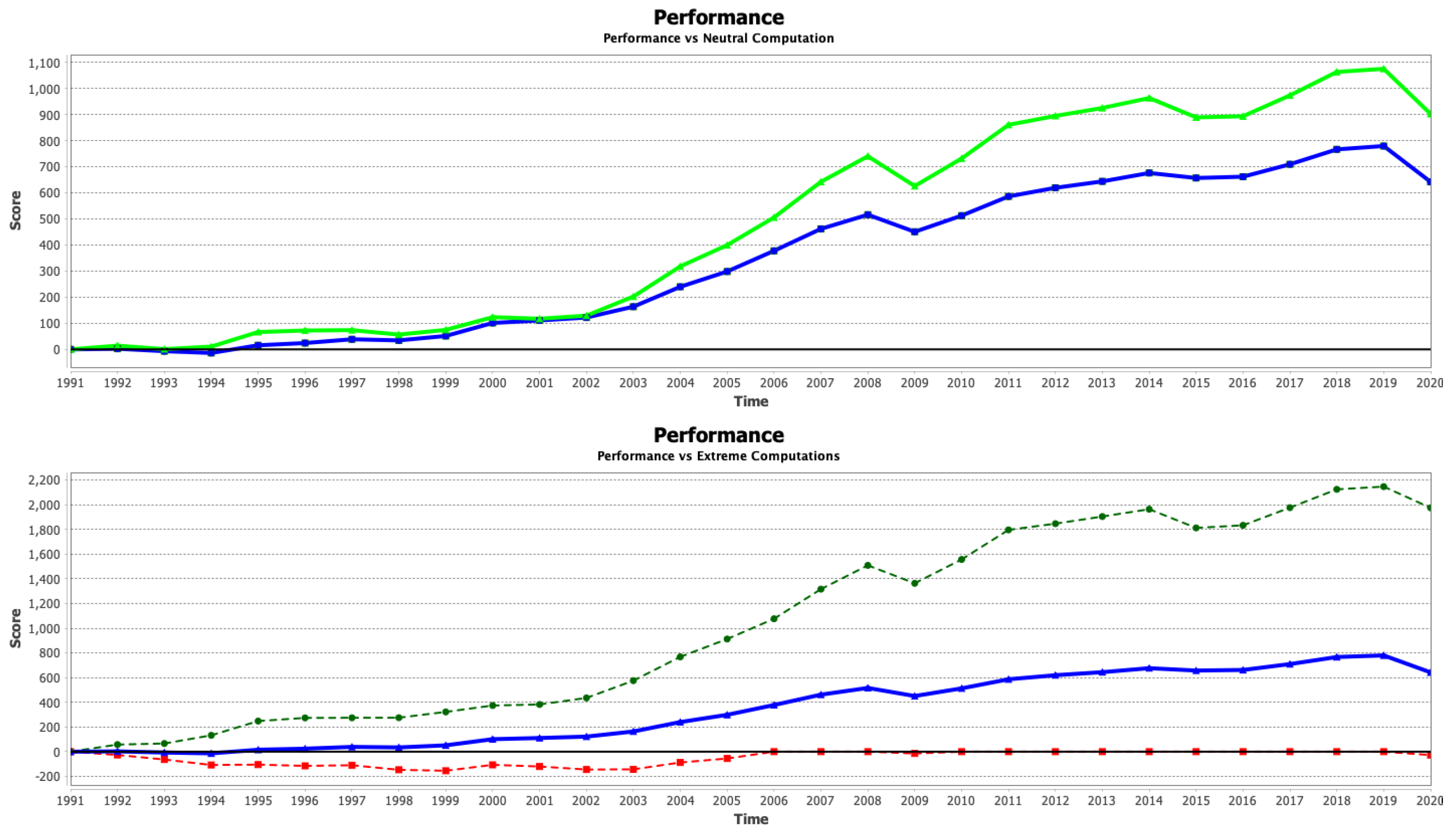
7.1. Case Study 1: Global Socio-Economic Growth
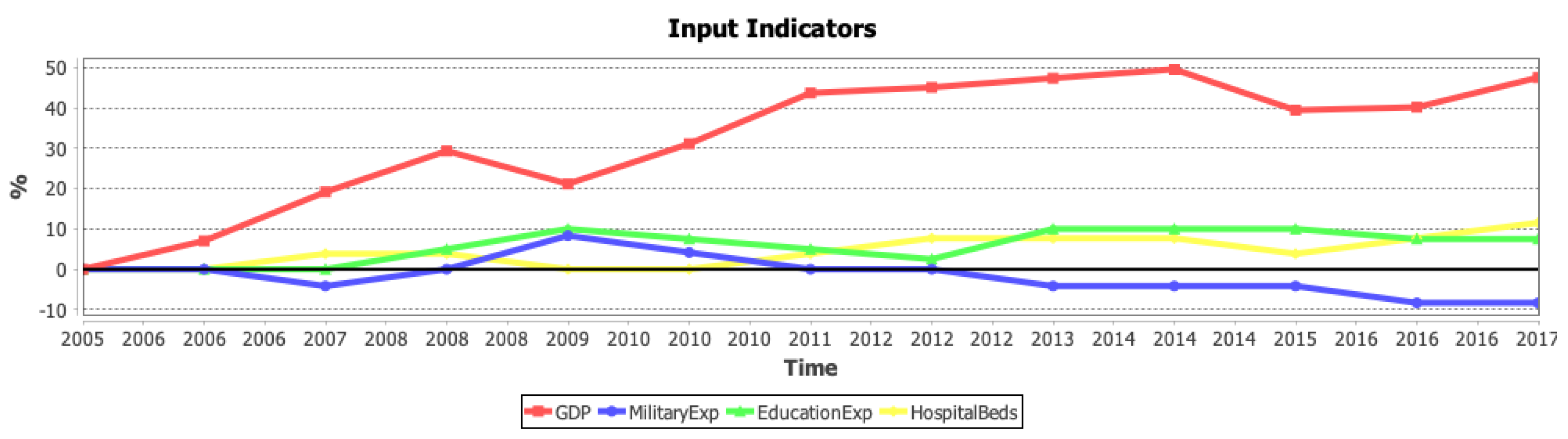
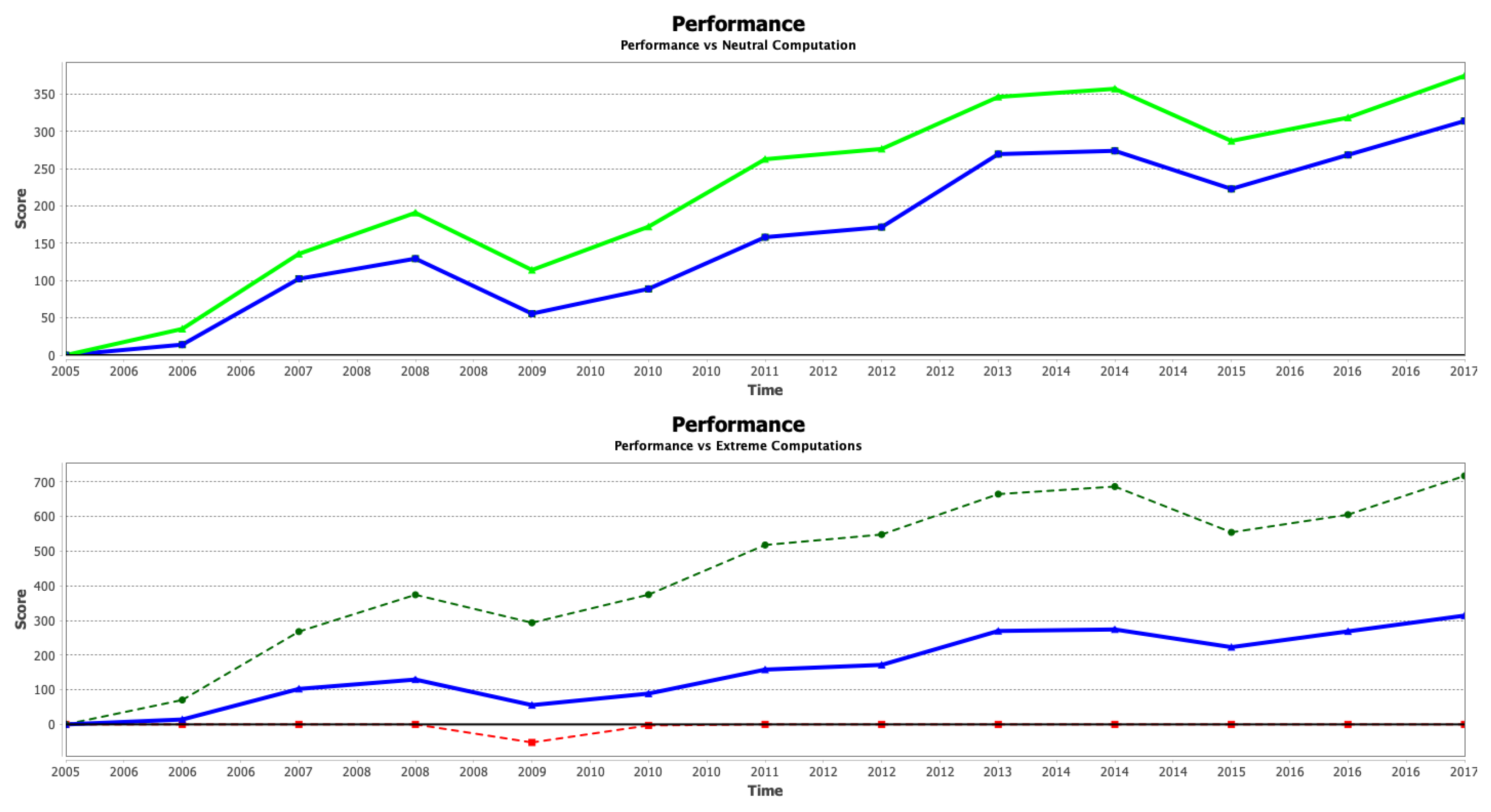
7.2. Case Study 2: Assessing Economic Growth
8. Conclusions and Future Work
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yim, N.H.; Kim, S.H.; Kim, H.W.; Kwahk, K.Y. Knowledge based decision making on higher level strategic concerns: System dynamics approach. Expert Syst. Appl. 2004, 27, 143–158. [Google Scholar] [CrossRef]
- Blomqvist, E. The use of Semantic Web technologies for decision support—A survey. Semant. Web 2014, 5, 177–201. [Google Scholar] [CrossRef]
- Hamari, J.; Koivisto, J.; Sarsa, H. Does gamification work?—A literature review of empirical studies on gamification. In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Washington, DC, USA, 6–9 January 2014; pp. 3025–3034. [Google Scholar]
- Seaborn, K.; Fels, D.I. Gamification in theory and action: A survey. Int. J. Hum.-Comput. Stud. 2015, 74, 14–31. [Google Scholar] [CrossRef]
- Basco-Carrera, L.; Warren, A.; van Beek, E.; Jonoski, A.; Giardino, A. Collaborative modelling or participatory modelling? A framework for water resources management. Environ. Model. Softw. 2017, 91, 95–110. [Google Scholar] [CrossRef]
- Cardoso, J. The semantic web vision: Where are we? IEEE Intell. Syst. 2007, 22, 84–88. [Google Scholar] [CrossRef]
- Fernández, M.; Overbeeke, C.; Sabou, M.; Motta, E. What makes a good ontology?A case-study in fine-grained knowledge reuse. In Proceedings of the Asian Semantic Web Conference, Shanghai, China, 7–9 December 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 61–75. [Google Scholar]
- García-Castro, R.; Gómez-Pérez, A. Interoperability results for Semantic Web technologies using OWL as the interchange language. J. Web Semant. 2010, 8, 278–291. [Google Scholar] [CrossRef]
- Pileggi, S.F. Is the World Becoming a Better or a Worse Place? A Data-Driven Analysis. Sustainability 2020, 12, 88. [Google Scholar] [CrossRef]
- Zacharewicz, G.; Daclin, N.; Doumeingts, G.; Haidar, H. Model driven interoperability for system engineering. Modelling 2020, 1, 94–121. [Google Scholar] [CrossRef]
- Pileggi, S.F. Life before COVID-19: How was the World actually performing? Qual. Quant. 2021, 55, 1871–1888. [Google Scholar] [CrossRef]
- Pileggi, S.F. Combining Heterogeneous Indicators by Adopting Adaptive MCDA: Dealing with Uncertainty. In Proceedings of the International Conference on Computational Science, Krakow, Poland, 16–18 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 514–525. [Google Scholar]
- Ishizaka, A.; Nemery, P. Multi-Criteria Decision Analysis: Methods and Software; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Klein, G. Naturalistic decision making. Hum. Factors 2008, 50, 456–460. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Liu, H.; Tang, Y.; Chen, Q. Semantic decision making using ontology-based soft sets. Math. Comput. Model. 2011, 53, 1140–1149. [Google Scholar] [CrossRef]
- Blanco-Mesa, F.; Merigó, J.M.; Gil-Lafuente, A.M. Fuzzy decision making: A bibliometric-based review. J. Intell. Fuzzy Syst. 2017, 32, 2033–2050. [Google Scholar] [CrossRef]
- Guarino, N.; Oberle, D.; Staab, S. What is an ontology? In Handbook on Ontologies; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–17. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data: The story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Hershey, PA, USA, 2011; pp. 205–227. [Google Scholar]
- Ottino, J.M. Engineering complex systems. Nature 2004, 427, 399. [Google Scholar] [CrossRef] [PubMed]
- Elia, G.; Margherita, A. Can we solve wicked problems? A conceptual framework and a collective intelligence system to support problem analysis and solution design for complex social issues. Technol. Forecast. Soc. Change 2018, 133, 279–286. [Google Scholar] [CrossRef]
- Checkland, P.; Poulter, J. Soft systems methodology. In Systems Approaches to Making Change: A Practical Guide; Springer: Berlin/Heidelberg, Germany, 2020; pp. 201–253. [Google Scholar]
- Roy, B.; Vincke, P. Multicriteria analysis: Survey and new directions. Eur. J. Oper. Res. 1981, 8, 207–218. [Google Scholar] [CrossRef]
- Velasquez, M.; Hester, P.T. An analysis of multi-criteria decision making methods. Int. J. Oper. Res. 2013, 10, 56–66. [Google Scholar]
- Baba, V.V.; HakemZadeh, F. Toward a theory of evidence based decision making. Manag. Decis. 2012, 50, 832–867. [Google Scholar] [CrossRef]
- Cheung, C.F.; Lee, W.B.; Wang, W.M.; Chu, K.; To, S. A multi-perspective knowledge-based system for customer service management. Expert Syst. Appl. 2003, 24, 457–470. [Google Scholar] [CrossRef]
- Li, G.; Kou, G.; Peng, Y. A group decision making model for integrating heterogeneous information. IEEE Trans. Syst. Man Cybern. Syst. 2016, 48, 982–992. [Google Scholar] [CrossRef]
- Brugha, C.M. The structure of qualitative decision-making. Eur. J. Oper. Res. 1998, 104, 46–62. [Google Scholar] [CrossRef]
- Chen, W.H. Quantitative decision-making model for distribution system restoration. IEEE Trans. Power Syst. 2009, 25, 313–321. [Google Scholar] [CrossRef]
- Glöckner, A.; Hilbig, B.E.; Jekel, M. What is adaptive about adaptive decision making? A parallel constraint satisfaction account. Cognition 2014, 133, 641–666. [Google Scholar] [CrossRef] [PubMed]
- Kunze, C.; Hecht, R. Semantic enrichment of building data with volunteered geographic information to improve mappings of dwelling units and population. Comput. Environ. Urban Syst. 2015, 53, 4–18. [Google Scholar] [CrossRef]
- Durbach, I.N.; Stewart, T.J. Modeling uncertainty in multi-criteria decision analysis. Eur. J. Oper. Res. 2012, 223, 1–14. [Google Scholar] [CrossRef]
- Stewart, T.J.; Durbach, I. Dealing with uncertainties in MCDA. In Multiple Criteria Decision Analysis; Springer: Berlin/Heidelberg, Germany, 2016; pp. 467–496. [Google Scholar]
- Guarino, N. Formal ontology, conceptual analysis and knowledge representation. Int. J. Hum.-Comput. Stud. 1995, 43, 625–640. [Google Scholar] [CrossRef]
- Shvaiko, P.; Euzenat, J. Ontology matching: State of the art and future challenges. IEEE Trans. Knowl. Data Eng. 2011, 25, 158–176. [Google Scholar] [CrossRef]
- Sirin, E.; Parsia, B.; Grau, B.C.; Kalyanpur, A.; Katz, Y. Pellet: A practical owl-dl reasoner. Web Semant. Sci. Serv. Agents World Wide Web 2007, 5, 51–53. [Google Scholar] [CrossRef]
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef]
- Pileggi, S.F.; Crain, H.; Yahia, S.B. An Ontological Approach to Knowledge Building by Data Integration. In Proceedings of the International Conference on Computational Science, Amsterdam, The Netherlands, 3–5 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 479–493. [Google Scholar]
- Pileggi, S.F.; Hunter, J. An ontological approach to dynamic fine-grained Urban Indicators. Procedia Comput. Sci. 2017, 108, 2059–2068. [Google Scholar] [CrossRef]
- Pileggi, S.F.; Voinov, A. PERSWADE-CORE: A core ontology for communicating socio-environmental and sustainability science. IEEE Access 2019, 7, 127177–127188. [Google Scholar] [CrossRef]
- Pileggi, S.F. Knowledge interoperability and re-use in Empathy Mapping: An ontological approach. Expert Syst. Appl. 2021, 180, 115065. [Google Scholar] [CrossRef]
- Musen, M.A. The protégé project: A look back and a look forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef]
- Kosara, R.; Mackinlay, J. Storytelling: The next step for visualization. Computer 2013, 46, 44–50. [Google Scholar] [CrossRef]
- Dicheva, D.; Dichev, C.; Agre, G.; Angelova, G. Gamification in education: A systematic mapping study. J. Educ. Technol. Soc. 2015, 18, 75–88. [Google Scholar]
- Brugha, R.; Varvasovszky, Z. Stakeholder analysis: A review. Health Policy Plan. 2000, 15, 239–246. [Google Scholar] [CrossRef]
- The World Bank—GDP per Capita (Current US$). Available online: https://data.worldbank.org/indicator/NY.GDP.PCAP.CD (accessed on 9 May 2022).
- The World Bank—Unemployment, Total (% of Total Labor Force). Available online: https://data.worldbank.org/indicator/SL.UEM.TOTL.ZS (accessed on 10 May 2022).
- The World Bank—Life Expectancy at Birth, Total (Years). Available online: https://data.worldbank.org/indicator/SP.DYN.LE00.IN (accessed on 10 May 2022).
- The World Bank—Mortality Rate, under-5 (per 1000 Live Births). Available online: https://data.worldbank.org/indicator/SH.DYN.MORT (accessed on 10 May 2022).
- The World Bank—Military Expenditure (% of GDP). Available online: https://data.worldbank.org/indicator/MS.MIL.XPND.GD.ZS (accessed on 10 May 2022).
- The World Bank—Government Expenditure on Education, Total (% of GDP). Available online: https://data.worldbank.org/indicator/SE.XPD.TOTL.GD.ZS (accessed on 10 May 2022).
- The World Bank—Hospital Beds (per 1000 People). Available online: https://data.worldbank.org/indicator/SH.MED.BEDS.ZS (accessed on 10 May 2022).











| Indicator | Source | Category | Wished Trend | Weight |
|---|---|---|---|---|
| GDP x capita | [47] | Economy | Increasing | 2/10 |
| Unemployment Rate | [48] | Socio-economic | Decreasing | 5/10 |
| Life Expectancy | [49] | Health | Increasing | 5/10 |
| Children Mortality | [50] | Health | Decreasing | 8/10 |
| Indicator | Source | Category | Wished Trend | Weight |
|---|---|---|---|---|
| GDP x capita | [47] | Economy | Increasing | 2/10 |
| Military expenditure (% of GDP) | [51] | Other | Decreasing | 8/10 |
| Gov. expenditure on education (% of GDP) | [52] | Social | Increasing | 8/10 |
| Hospital beds (x 1000 people) | [53] | Health | Increasing | 8/10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pileggi, S.F. IndShaker: A Knowledge-Based Approach to Enhance Multi-Perspective System Dynamics Analysis. Modelling 2023, 4, 19-34. https://doi.org/10.3390/modelling4010002
Pileggi SF. IndShaker: A Knowledge-Based Approach to Enhance Multi-Perspective System Dynamics Analysis. Modelling. 2023; 4(1):19-34. https://doi.org/10.3390/modelling4010002
Chicago/Turabian StylePileggi, Salvatore Flavio. 2023. "IndShaker: A Knowledge-Based Approach to Enhance Multi-Perspective System Dynamics Analysis" Modelling 4, no. 1: 19-34. https://doi.org/10.3390/modelling4010002
APA StylePileggi, S. F. (2023). IndShaker: A Knowledge-Based Approach to Enhance Multi-Perspective System Dynamics Analysis. Modelling, 4(1), 19-34. https://doi.org/10.3390/modelling4010002