
Correctness Verification of Mutual Exclusion Algorithms by Model Checking

Abstract
:1. Introduction
- The modeling and verification method is completely re-designed and its semantics and transformation on to the Timed Automata of Uppaal are clarified.
- The novel approach is applied to several ME algorithms proposed in the literature, thus retrieving known results and properties but also, sometimes, discovering new features about specific ME solutions.
- Both exhaustive model checking (MC) and statistical model checking (SMC) [24,25] can be exploited for property checking. Although SMC is based on simulations, the properties of an ME algorithm for processes can be extrapolated by estimations and probability, thus furnishing further arguments to the indications emerged from the exhaustive verification work accomplished until processes.
2. An Overview of Uppaal Timed Automata Modeling
2.1. Specification Aspects
2.2. Semantics and Verification Aspects
- (Possibly , i.e., a state exists where holds)
- (Invariantly , equivalent to )
- (Potentially Always , i.e., a state path exists over which always holds)
- (Always eventually equivalent to )
- ( always leads-to equivalent to )
3. A Modeling Method for Mutual Exclusion Algorithms
| Algorithm 1. General Code Structure of a Process Involved in Mutual Exclusion |
| global shared communication variables Process(i): local variables of the process loop NCS //Non Critical Section Entry CS //Critical Section Exit end-loop |
- (Safety) Absence of deadlocks in the processes attempting to use the shared resource.
- (Safety) At any time, only one process should be allowed to enter its critical section.
- (Bounded liveness) A competing process eventually enters its critical section. In other terms, the waiting time for a competing process should be finite and hopefully small. Equivalently, the number of by-passes or the overtaking factor which a waiting process experiments from other competing processes should be bounded. This property also expresses, for a competing process, the absence of starvation.
- (Liveness) A process in its non-critical section should never impede a competing process to enter its critical section.
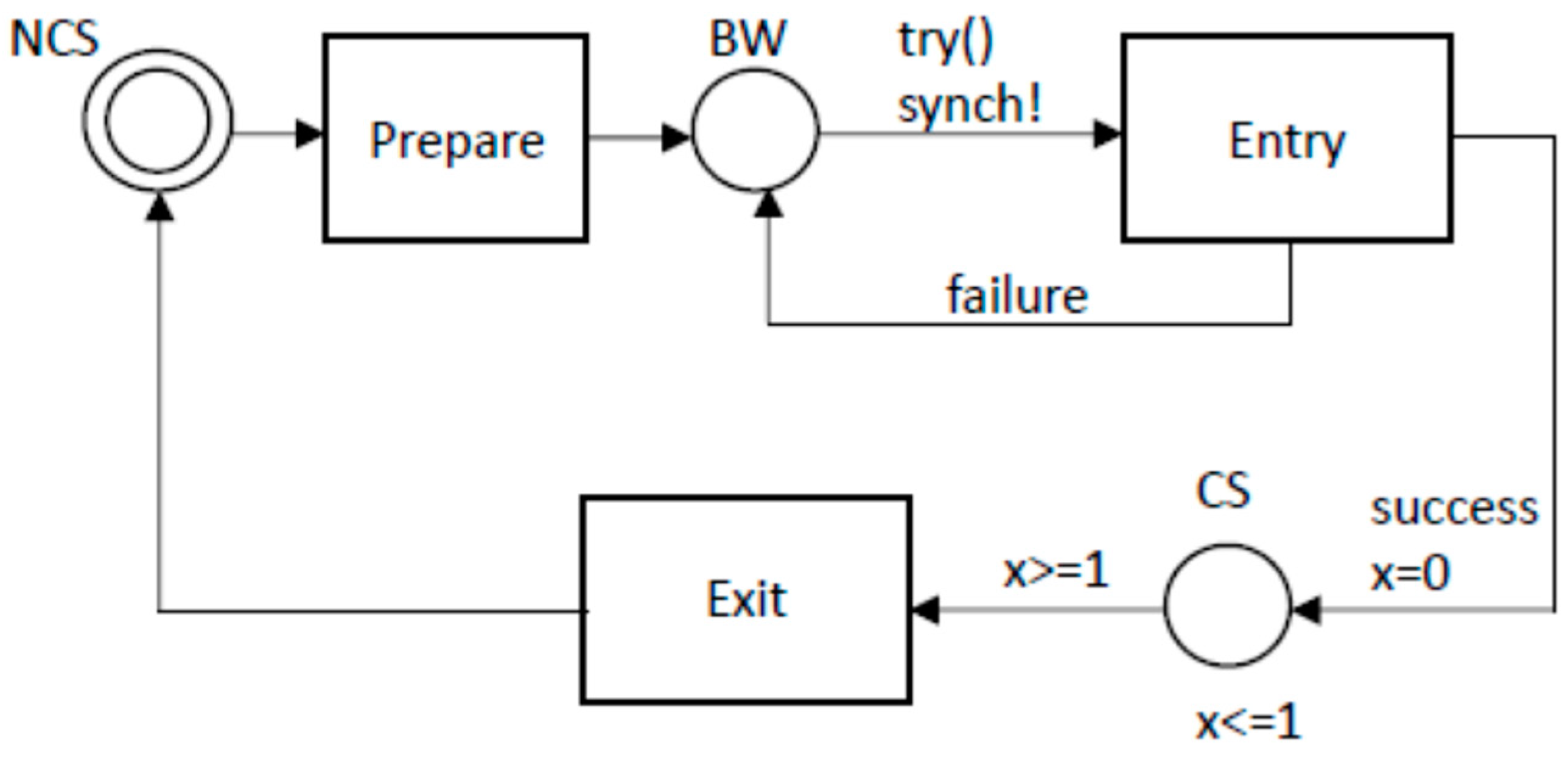
3.1. Uppaal Modeling Method
3.2. Predicting the Overtaking Factor
| const int N=…; //the number of processes |
| typedef int [1,N] pid; //the type of process unique identifiers |
| const pid tp=1; //target process example |
| clock x[pid]; //one clock per process |
| void reset( const pid i ){ |
| if( i==tp ) x[tp]=0; |
| }//reset |
3.3. Model Checking and TCTL Queries
| A[] Process(tp).BW imply x[tp]<=ov-bound |
3.4. Statistical Model Checking and MITL Queries
4. Modeling and Analysis of Mutual Exclusion Algorithms
4.1. Solutions for Two Processes
4.1.1. Dekker’s Algorithm
| bool flag [2], int [1,2] turn |
| Algorithm 2. Dekker’s Process(i) |
| Process(i): local constant: int j=3-i; while(true){ NCS; flag[i]=true; while( flag[j] ){ if( turn==j ){ flag[i]=false; wait-until( turn==i ); flag[i]=true; } } CS; turn=j; flag[i]=false; } |
| E<> Process(1).CS |
| E<> Process(2).CS |
| Process(1).W --> Process(1).CS |
4.1.2. Peterson’s Algorithm for Two Processes
| Algorithm 3. Peterson’s Process(i) |
| Process(i): local constant: int j=3-i; while(true){ NCS; flag[i]=true; turn=j; wait-until( !flag[j] || turn==i ); CS; flag[i]=false; } |
4.2. Solutions for Processes
4.2.1. Dijkstra’s Algorithm
| bool [1..N] b, c; int k |
| Algorithm 4. The E.W. Dijkstra Algorithm for the Processes |
| Process(i): local int j; Li0: b[i] := false; Lil: if k # i then Li2: begin c[i] := true; Li3 if b[k] then k:=i; go to Lil end else Li4: begin c[i] := false; for j := 1 step 1 until N do if j # i and not c[j] then go to Lil end; critical section; c[i] := true; b[i] := true; remainder of the cycle in which stopping is allowed; go to Li0 |
| Algorithm 5. try() Function of Figure 5 |
| bool try(){ int j; if( k!=i ){ return false; } else{ for( j=1; j<=N; ++j ) if( j!=i && !c[j] ) return false; } return true; }//try |
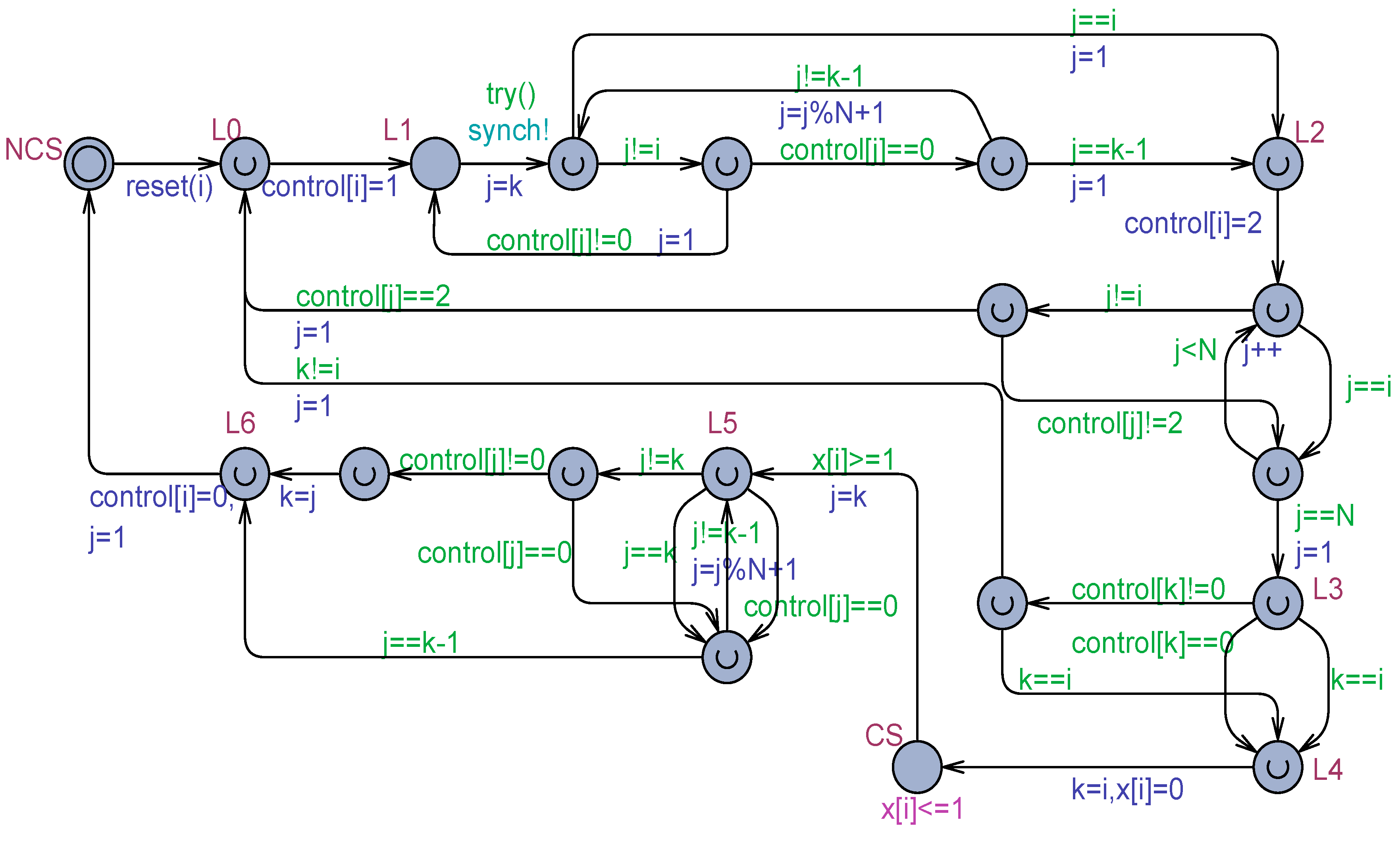
4.2.2. Knuth’s Algorithm
| int [1,N] control; int k |
| Algorithm 6. Knuth’s Algorithm for Processes |
| Process(i): begin int j; L0: control[i]=1; L1: for j=k step −1 until 1, N step −1 until 1 do begin if j==i then go to L2; if control[j]!=0 then go to L1; end; L2: control[i]=2; for j=N step −1 until 1 do if j!=i && (control[j]==2) then go to L0; L3: k=i; critical_section; k=if i==1 then N else i−1; L4: control[i]=0; remainder of the cycle in which stopping is allowed; go to L0; end |
| Algorithm 7. The try() and dec() Functions of the Uppaal Model in Figure 6 |
| bool try(){ int j; if( k>=i && i>=1 ){ for( j=k; j>i; --j ) if( control[j]!=0 ) return false; } else{ //k<i<=N for( j=N; j>i; --j ) if( control[j]!=0 ) return false; } for( j=N; j>=1; --j ) if( j!=i && control[j]==2 ) return false; return true; }//try int dec( int j ){ if( k>0 ) return (j==1)?N:j−1; return j−1; }//dec |
| Pr[<=10000](<>Process(tp).L1 && x[tp] > (N−1)) |
4.2.3. de Bruijn’s Algorithm
| L3: critical_section; |
| if( control[k]==0 || k==i ) then k= (if k==1 then N else k−1); |
| Pr[<=10000](<>Process(tp).L1 && x[tp]>(N*(N−1)/2)) |
4.2.4. The Eisenberg and McGuire Algorithm
| Process(1).L1 --> Process(1).CS |
| Algorithm 8. Eisenberg and McGuire’s Algorithm for N ≥ 2 Processes |
| Process(i): begin int j; L0: control[i]=1; L1: for j=k step 1 until N, 1 step 1 until k do begin if j==i then go to L2; if control[j]!=0 then go to L1; end; L2: control[i]=2; for j=1 step 1 until N do if j!=i && (control[j]==2) then go to L0; L3: if control[k]!=0 && k!=i then go to L0; L4: k=i; critical_section; L5: for j=k step 1 until N, 1 step 1 until k do if j!=k and control[j]!=0 then begin k=j; go to L6; end; L6: control[i]=0; remainder of the cycle; go to L0; end |
4.2.5. The Generalized Peterson’s Algorithm
| int [0,N] q [1,N]; int [1,N] turn [1,N−1] |
| Algorithm 9. Peterson’s solution for processes |
| Process(i): local int j; while( true ){ NCS; for j=1 step 1 until N−1 do begin q[i]=j; turn[j]=i; wait-until( k!=i, q[k]<j) or (turn[j]!=i) ); end; CS; q[i]=0; } |
| bool try(){ |
| return (forall(k:pid)(k==i || q[k]<j) || turn[j]!=i); |
| }//try |
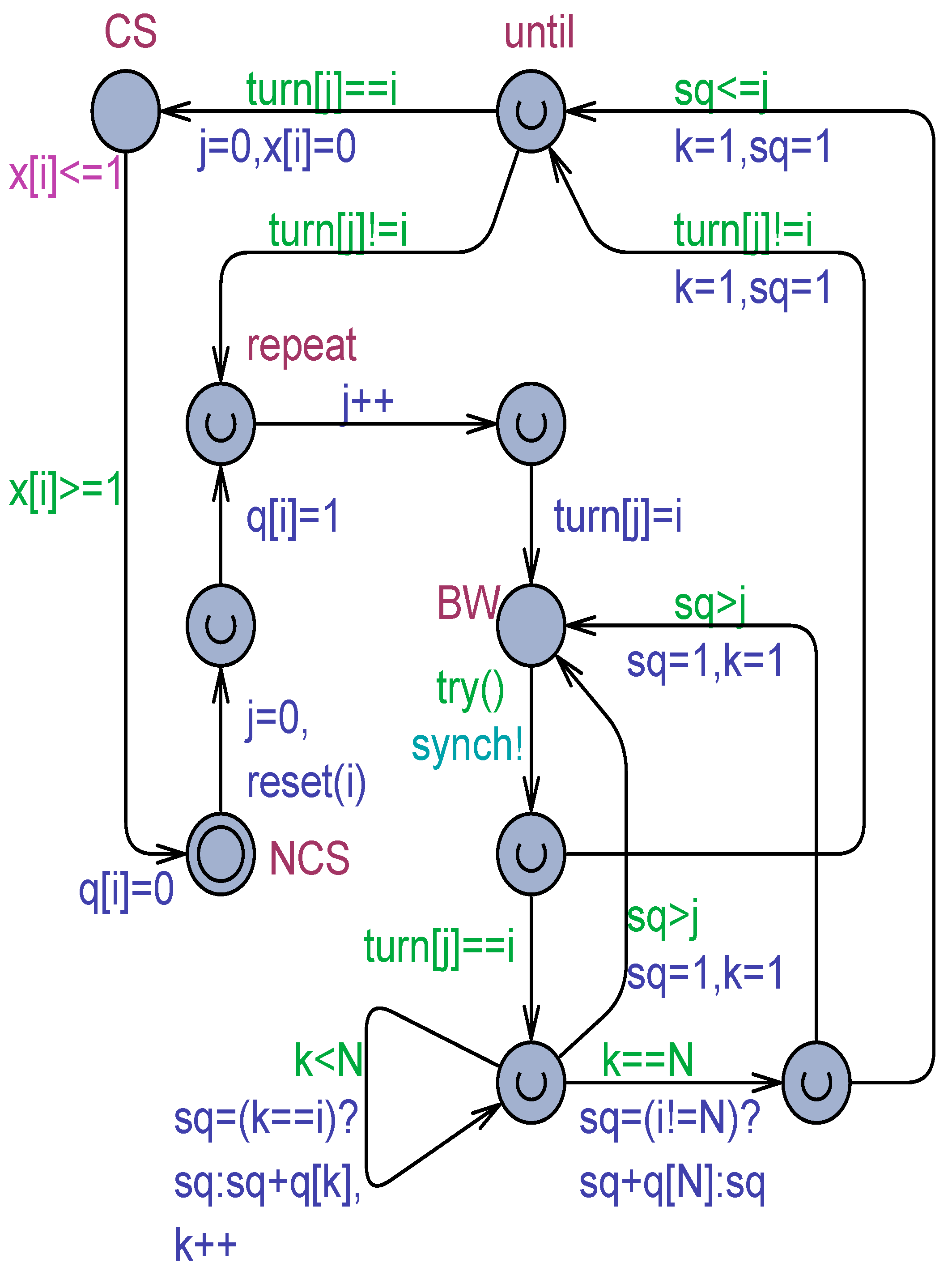
4.2.6. The Block and Woo Algorithm
| bool q [1,N]; int [1,N] turn [1,N] |
| Algorithm 10. The Block and Woo Algorithm for processes |
| Process(i): int j; while( true ){ NCS; j = 0; q[i] =1; repeat j = j+1; turn[j] =i; wait-until (turn[j]!=i) or (); until (turn[j]==i); CS; q[i] =0; } |
| bool try(){ |
| return turn[j]!=i || (sum(k:pid)q[k])<=j; |
| }//try |
4.2.7. The Aravind and Hesselink Algorithm
| bool act [1,N]; pid turn [0,N−1]; |
| Algorithm 11. The Aravind and Hesselink Algorithm for Mutual Exclusion |
| Process(i): local variables: int [0,N−1] level; bool bb; pid q; int [0,N−1] card; while( true ){ NCS; act[i]=true; level=N−1; while( level>0 ){ card=N−1-|{q,1<=q<=N : !act[q]}|; //number of not CS interested processes if( card<level ){ level=card; bb=false; } else if( !bb ){ turn[level]=i; bb=true; card=|{q,1<=q<=N, q!=i && act[q]}|; } else if( turn[level]!=i ){ level--; bb=false; } } CS; act[i]=false; } |
| bool try(){ |
| return level==0 || N−1-(sum(q:pid)!act[q])<level || !bb || turn[level]!=i; |
| }//try |
4.2.8. Solutions under the Weak Memory Model
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lamport, L. The mutual exclusion problem: Part I—A theory of interprocess communication. In Concurrency: The Works of Leslie Lamport 2019; ACM: New York, NY, USA, 2019; pp. 227–245. [Google Scholar]
- Lamport, L. The mutual exclusion problem: Part II—Statement and solutions. In Concurrency: The Works of Leslie Lamport 2019; ACM: New York, NY, USA, 2019; pp. 247–276. [Google Scholar]
- Raynal, M. Algorithms for mutual exclusion 1986; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Raynal, M.; Taubenfeld, G. A visit to mutual exclusion in seven dates. Theor. Comput. Sci. 2022, 919, 47–65. [Google Scholar] [CrossRef]
- Buhr, P.A.; Dice, D.; Hesselink, W.H. High-performance N-thread software solutions for mutual exclusion. Concurr.Comput. Pract. Exp. 2015, 27, 651–701. [Google Scholar] [CrossRef]
- Dijkstra, E.W. Co-operating sequential processes. In Programming Languages: NATO Advanced Study Institute: Lectures Given at a Three Weeks Summer School Held in Villard-le-Lans; Genuys, F., Ed.; Academic Press Inc.: Cambridge, MA, USA, 1966; pp. 43–112. [Google Scholar]
- Raynal, M. Concurrent Programming: Algorithms, Principles, and Foundations; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Misra, J. A foundation of parallel programming. In Constructive Methods in Computing Science: International Summer School Directed; Bauer, M.F.L., Dijkstra, B.E.W., Hoare, C.A.R., Eds.; Springer: Berlin/Heidelberg, Germany, 1989; pp. 397–445. [Google Scholar]
- Lamport, L. On interprocess communication. Distrib. Comput. 1986, 1, 77–101. [Google Scholar] [CrossRef]
- Nigro, L.; Cicirelli, F. Formal modeling and verification of embedded real-time systems: An approach and practical tool based on Constraint Time Petri Nets. Mathematics 2024, 12, 812. [Google Scholar] [CrossRef]
- Silbershatz, A.; Galvin, P.B.; Gagne, G. Operating System Concepts, 10th ed.; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Hofri, M. Proof of a mutual exclusion algorithm—A ‘Class’ic example. ACM SIGOPS Oper. Syst. Rev. 1990, 24, 18–22. [Google Scholar] [CrossRef]
- Aravind, A.A.; Hesselink, W.H. A queue based mutual exclusion algorithm. Acta Inform. 2009, 46, 73–86. [Google Scholar] [CrossRef]
- Hesselink, W.H. Verifying a simplification of mutual exclusion by Lycklama–Hadzilacos. Acta Inform. 2013, 50, 199–228. [Google Scholar] [CrossRef]
- Hesselink, W.H. Mutual exclusion by four shared bits with not more than quadratic complexity. Sci. Comput. Program. 2015, 102, 57–75. [Google Scholar] [CrossRef]
- Hesselink, W.H. Correctness and concurrent complexity of the Black-White Bakery Algorithm. Form. Asp. Comput. 2016, 28, 325–341. [Google Scholar] [CrossRef]
- Hesselink, W.H. Tournaments for mutual exclusion: Verification and concurrent complexity. Form. Asp. Comput. 2017, 29, 833–852. [Google Scholar] [CrossRef]
- Hafidi, Y.; Keiren, J.J.; Groote, J.F. Fair Mutual Exclusion for N Processes. In International Conference on Software Testing, Machine Learning and Complex Process Analysis; Springer Nature: Cham, Switzerland, 2021; pp. 149–160. [Google Scholar]
- Alur, R.; Dill, D.L. A theory of timed automata. Theor. Comput.Sci. 1994, 126, 183–235. [Google Scholar] [CrossRef]
- Behrmann, G.; David, A.; Larsen, K.G. A tutorial on UPPAAL. In Formal Methods for the Design of Real-Time Systems; Bernardo, M., Corradini, F., Eds.; LNCS 3185; Springer: Berlin/Heidelberg, Germany, 2004; pp. 200–236. [Google Scholar]
- Clarke, E.M. Model checking. In Proceedings of the Foundations of Software Technology and Theoretical Computer Science: 17th Conference, Kharagpur, India, 18–20 December 1997; Proceedings 17. Springer: Berlin/Heidelberg, Germany, 1997; pp. 54–56. [Google Scholar]
- Cicirelli, F.; Nigro, L. Modelling and verification of mutual exclusion algorithms. In Proceedings of the IEEE/ACM 20th International Symposium on Distributed Simulation and Real Time Applications (DS-RT), London, UK, 21–23 September 2016; pp. 136–144. [Google Scholar]
- Cicirelli, F.; Nigro, L.; Sciammarella, P.F. Model checking mutual exclusion algorithms using Uppaal. In Proceedings of the 5th Computer Science On-Line Conference, Zlin, Czech Republic, 27–30 April 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Agha, G.; Palmskog, K. A Survey of Statistical Model Checking. ACM Trans. Model. Comput. Simul. 2018, 28, 39. [Google Scholar]
- David, A.; Larsen, K.G.; Legay, A.; Mikucionis, M.; Poulsen, D.B. Uppaal SMC tutorial. Int. J. Softw. Tools Technol. Transf. 2015, 17, 397–415. [Google Scholar] [CrossRef]
- Buhr, P.A.; Dice, D.; Hesselink, W.H. Dekker’s mutual exclusion algorithm made RW-safe. Concurr.Comput. Pract. Experience 2016, 28, 144–165. [Google Scholar] [CrossRef]
- Lamport, L. The temporal logic of actions. ACM Trans. Program. Lang. Syst. 1994, 16, 872–923. [Google Scholar] [CrossRef]
- Bowman, H.; Gomez, R.; Su, L. A tool for the syntactic detection of zeno-timelocks in Timed Automata. Electron. Notes Theor. Comput. Sci. 2005, 139, 25–47. [Google Scholar] [CrossRef]
- Lee, E.A. Modeling in engineering and science. Commun. ACM 2018, 62, 35–36. [Google Scholar] [CrossRef]
- Peterson, G.L. Myths about the mutual exclusion problem. Inf. Process. Lett. 1981, 12, 115–116. [Google Scholar] [CrossRef]
- Kessels, J.L.W. Arbitration without common modifiable variables. Acta Inform. 1982, 17, 135–141. [Google Scholar] [CrossRef]
- Dijkstra, E.W. Solution of a problem in concurrent programming control. Commun. ACM 1965, 8, 569. [Google Scholar] [CrossRef]
- Knuth, D.E. Additional comments on a problem in concurrent programming control. Commun. ACM 1966, 9, 321–322. [Google Scholar] [CrossRef]
- de Bruijn, N.G. Additional comments on a problem in concurrent programming control. Commun. ACM 1967, 10, 137–138. [Google Scholar] [CrossRef]
- Eisenberg, M.A.; McGuire, M.R. Further comments on Dijkstra’s concurrent programming control problem. Commun. ACM 1972, 15, 999. [Google Scholar] [CrossRef]
- Kowalttowski, T.; Palma, A. Another solution of the mutual exclusion problem. Inf. Process. Lett. 1984, 19, 145–146. [Google Scholar] [CrossRef]
- Block, K.; Woo, T.K. A more efficient generalization of Peterson’s mutual exclusion algorithm. Inf. Process. Lett. 1990, 35, 219–222. [Google Scholar] [CrossRef]
- Frenzel, L.E. Dual-port SRAM accelerates smart-phone development. In Electronic Design; Endeavor Business Media: Nashville, TN, USA, 2004. [Google Scholar]
- Lamport, L. A new solution of Dijkstra’s concurrent programming problem. Commun. ACM 1974, 17, 453–455. [Google Scholar] [CrossRef]
- Burns, J.E.; Lynch, N.A. Mutual exclusion using indivisible reads and writes. In Proceedings of the 18th Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 8–10 October 1980; pp. 833–834. [Google Scholar]
- Peterson, G.L.; Fischer, M.J. Economical solutions for the critical section problem in a distributed system. In Proceedings of the Ninth Annual ACM Symposium on Theory of Computing, New York, NY, USA, 4 May 1977; pp. 91–97. [Google Scholar]
- Sorensen, T.; Gopalakrishnan, G.; Grover, V. Towards shared memory consistency models for GPUs. In Proceedings of the 27th International ACM Conference on International Conference on Supercomputing, New York, NY, USA, 10–14 June 2013; pp. 489–490. [Google Scholar]
- Mascarell, J.B. Formal Definitions of Memory Consistency Models. arXiv 2021, arXiv:2101.09527. [Google Scholar]
- Nigro, L. Parallel Theatre: An actor framework in Java for high performance computing. Simul. Model. Pract. Theory 2021, 106, 102189. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | TCTL query | Property |
| 1 | A[] !deadlock | Absence of deadlocks. |
| 2 | A[] (sum(i:pid)Process(i).CS)<=1 | At most one process can be in its critical section (CS). |
| 3 | Process(tp).CS | A process in BW eventually enters the critical section. |
| 4 | E<> Process(1).NCS && exists(j:pid) Process(j).CS | A process in NCS does not forbid another process from entering the CS. |
| 5 | sup{ Process(tp).BW } : x[tp] | The suprema value of the overtaking factor. |
| # | MITL query | Property |
| 1 | Pr[<=10000](<>(sum(i:pid)Process(i).CS)>1) | Probability that more than one process can be in CS. |
| 2 | simulate[<=100]{sum(i:pid)Process(i).CS} | Monitoring the number of processes simultaneously in CS in a simulation of 100 time units. |
| 3 | Pr[<=1000](<>Process(tp).CS) | Probability that a process can actually enter its CS. |
| 4 | Pr[<=10000](<>Process(tp).BW && x[tp]>expected-value) | Probability that the overtaking factor (x[tp]) can be found greater than the expected-value. |
| 5 | Pr[<=10000]([] Process(tp).NCS || x[tp]<=expected-value) | Probability that x[tp] is always found less than or equal its expected-value. |
| N | ov |
|---|---|
| 2 | 1 |
| 3 | 2 |
| 4 | 3 |
| 5 | 4 |
| N | ov |
|---|---|
| 2 | 1 |
| 3 | 3 |
| 4 | 5 |
| 5 | 7 |
| N | ov |
|---|---|
| 2 | 1 |
| 3 | 2 |
| 4 | 3 |
| 5 | 4 |
| N | ov |
|---|---|
| 2 | 1 |
| 3 | 3 |
| 4 | 6 |
| 5 | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nigro, L.; Cicirelli, F. Correctness Verification of Mutual Exclusion Algorithms by Model Checking. Modelling 2024, 5, 694-719. https://doi.org/10.3390/modelling5030037
Nigro L, Cicirelli F. Correctness Verification of Mutual Exclusion Algorithms by Model Checking. Modelling. 2024; 5(3):694-719. https://doi.org/10.3390/modelling5030037
Chicago/Turabian StyleNigro, Libero, and Franco Cicirelli. 2024. "Correctness Verification of Mutual Exclusion Algorithms by Model Checking" Modelling 5, no. 3: 694-719. https://doi.org/10.3390/modelling5030037