
Detection of Novel Objects without Fine-Tuning in Assembly Scenarios by Class-Agnostic Object Detection and Object Re-Identification

 , , , and
, , , and
Abstract
1. Introduction
- Firstly, we demonstrate that training a class-agnostic detector on a sufficiently large and densely labeled dataset is sufficient to generalize well to novel objects. We compare different models and determine which architectures can detect the most novel objects in an assembly scenario while being fast.
- Secondly, we show that an object re-identification approach can be trained on a 3D object reconstruction dataset and utilized to assign novel categories to proposals without the need for fine-tuning. Our experiments indicate that this training approach outperforms the alternative in related work, wherein classification and proposal generation utilize the same detection dataset.
- Thirdly, we incorporate an additional first-filtering step based on object re-identification before applying the class-agnostic detector. This pre-processing step demonstrates considerable potential to accelerate the overall pipeline and enhance the detection performance by reducing the search space of the detector.
2. Related Work
2.1. Handling Novel Categories
2.2. Novel Category Classification without Fine-Tuning
2.3. Few-Shot Object Detection without Fine-Tuning
2.4. Object Re-Identification
2.5. Content-Based Image Retrieval
3. Detection of Novel Objects without Fine-Tuning
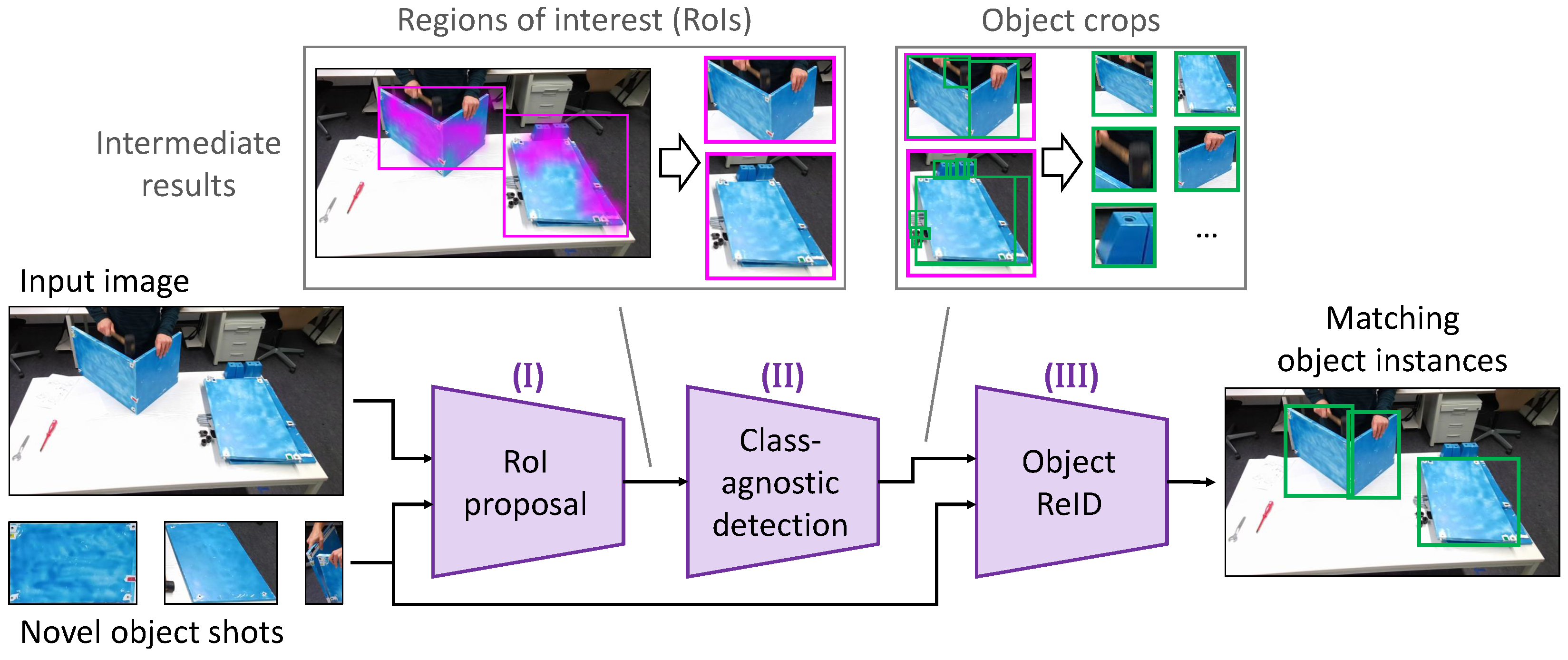
3.1. Processing Pipeline
- (I)
- RoI proposal
- (II)
- Class-agnostic detection
- (III)
- Object re-identification
3.2. Region of Interest Proposal
3.2.1. Reason Why This Preprocessing Step Is Necessary
3.2.2. How to Reduce the Search Space
3.2.3. Application of a Re-Identification Model for Feature Similarity Computation
3.2.4. Computation of Similarity Maps
3.2.5. Binarization of Similarity Maps
Why We Need a Shot-Specific Threshold
How to Use Dataset Statistics to Specify a Shot-Specific Threshold for Binarization
3.2.6. Region of Interest Creation, Combination and Refinement
- Most bounding boxes being the same size allows for more efficient batching during inference with the object-detection model without resizing and padding.
- Object detectors tend to struggle on very large images and on very small image crops, finding a suitable middle ground is advantageous.
3.3. Class-Agnostic Object Detection
3.4. Object Re-Identification
How to Learn Discriminative Embeddings
4. Experiments
4.1. Class-Agnostic Detection
4.1.1. Out-of-Domain Detection Test Dataset
Object Annotations
Benchmarks for Detection of Novel Objects
4.1.2. Evaluation Protocol
4.1.3. Implementation Details and Model Training
4.1.4. Model Comparison
4.1.5. Number of Predicted Object Proposals
4.1.6. Ablation Study: Other Factors Affecting Performance
4.2. Object ReID
4.2.1. Training Dataset
- Each object must be present in multiple different images.
- Objects must be labeled in a way that allows for their unique identities to be identified, i.e., object-category-level labels used in object detection and classification are insufficient.
4.2.2. Out-of-Domain ReID Test Datasets
4.2.3. Implementation Details and Model Training
4.2.4. Evaluation and Comparison
4.2.5. Influence Factors on the Re-Identification Pipeline
Data Augmentation
Input Resolution
Embedding Behavior and Dataset Quality
Embedding Dimension
Batch Sampling
Number of Categories in the Training Dataset
Image Backgrounds
Modern Loss Functions
Conclusion
4.3. Entire Processing Pipeline
4.3.1. Evaluation Protocol
4.3.2. Influence of Individual Hyperparameters
4.3.3. Comparison to State-of-the-Art Few-Shot Object Detector
4.3.4. Comparison of Generalization Abilities to Another Assembly Scenario
5. Limitations
6. Conclusions
Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Eisenbach, M.; Aganian, D.; Köhler, M.; Stephan, B.; Schroeter, C.; Gross, H.M. Visual Scene Understanding for Enabling Situation-Aware Cobots. In Proceedings of the IEEE International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021. [Google Scholar]
- Aganian, D.; Köhler, M.; Baake, S.; Eisenbach, M.; Groß, H.M. How object information improves skeleton-based human action recognition in assembly tasks. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–9. [Google Scholar]
- Li, W.; Wei, H.; Wu, Y.; Yang, J.; Ruan, Y.; Li, Y.; Tang, Y. TIDE: Test-Time Few-Shot Object Detection. IEEE Trans. Syst. Man Cybern. Syst. 2024. [Google Scholar] [CrossRef]
- Antonelli, S.; Avola, D.; Cinque, L.; Crisostomi, D.; Foresti, G.L.; Galasso, F.; Marini, M.R.; Mecca, A.; Pannone, D. Few-shot object detection: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–37. [Google Scholar] [CrossRef]
- Köhler, M.; Eisenbach, M.; Gross, H.M. Few-shot object detection: A comprehensive survey. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–21. [Google Scholar] [CrossRef]
- Aganian, D.; Stephan, B.; Eisenbach, M.; Stretz, C.; Gross, H.M. ATTACH dataset: Annotated two-handed assembly actions for human action understanding. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 11367–11373. [Google Scholar]
- Ben-Shabat, Y.; Yu, X.; Saleh, F.; Campbell, D.; Rodriguez-Opazo, C.; Li, H.; Gould, S. The ikea asm dataset: Understanding people assembling furniture through actions, objects and pose. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 847–859. [Google Scholar]
- Zhang, X.; Wang, Y.; Boularias, A. Detect everything with few examples. arXiv 2023, arXiv:2309.12969. [Google Scholar]
- Liang, S.; Wang, W.; Chen, R.; Liu, A.; Wu, B.; Chang, E.C.; Cao, X.; Tao, D. Object Detectors in the Open Environment: Challenges, Solutions, and Outlook. arXiv 2024, arXiv:2403.16271. [Google Scholar]
- Dhamija, A.; Gunther, M.; Ventura, J.; Boult, T. The overlooked elephant of object detection: Open set. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Seattle, WA, USA, 13–19 June 2020; pp. 1021–1030. [Google Scholar]
- Du, X.; Wang, Z.; Cai, M.; Li, Y. Vos: Learning what you don’t know by virtual outlier synthesis. In Proceedings of the International Conference of Learning Representations (ICLR), Virtual Event, 25–29 April 2022. [Google Scholar]
- Joseph, K.; Khan, S.; Khan, F.S.; Balasubramanian, V.N. Towards open world object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5830–5840. [Google Scholar]
- Zhao, X.; Ma, Y.; Wang, D.; Shen, Y.; Qiao, Y.; Liu, X. Revisiting open world object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 3496–3509. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Gupta, A.; Dollar, P.; Girshick, R. LVIS: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5356–5364. [Google Scholar]
- Singh, B.; Li, H.; Sharma, A.; Davis, L.S. R-FCN-3000 at 30fps: Decoupling detection and classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1081–1090. [Google Scholar]
- Michaelis, C.; Bethge, M.; Ecker, A.S. A Broad Dataset is All You Need for One-Shot Object Detection. arXiv 2020, arXiv:2011.04267. [Google Scholar]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2147–2154. [Google Scholar]
- Zhou, Z.; Yang, Y.; Wang, Y.; Xiong, R. Open-set object detection using classification-free object proposal and instance-level contrastive learning. IEEE Robot. Autom. Lett. 2023, 8, 1691–1698. [Google Scholar] [CrossRef]
- Jaiswal, A.; Wu, Y.; Natarajan, P.; Natarajan, P. Class-agnostic object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 919–928. [Google Scholar]
- Maaz, M.; Rasheed, H.; Khan, S.; Khan, F.S.; Anwer, R.M.; Yang, M.H. Class-agnostic object detection with multi-modal transformer. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 512–531. [Google Scholar]
- He, Y.; Chen, W.; Tan, Y.; Wang, S. Usd: Unknown sensitive detector empowered by decoupled objectness and segment anything model. arXiv 2023, arXiv:2306.02275. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 4015–4026. [Google Scholar]
- Han, J.; Ren, Y.; Ding, J.; Pan, X.; Yan, K.; Xia, G.S. Expanding low-density latent regions for open-set object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9591–9600. [Google Scholar]
- Bansal, A.; Sikka, K.; Sharma, G.; Chellappa, R.; Divakaran, A. Zero-shot object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 384–400. [Google Scholar]
- Zhu, P.; Wang, H.; Saligrama, V. Zero shot detection. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 998–1010. [Google Scholar] [CrossRef]
- Rahman, S.; Khan, S.H.; Porikli, F. Zero-shot object detection: Joint recognition and localization of novel concepts. Int. J. Comput. Vis. 2020, 128, 2979–2999. [Google Scholar] [CrossRef]
- Tan, C.; Xu, X.; Shen, F. A survey of zero shot detection: Methods and applications. Cogn. Robot. 2021, 1, 159–167. [Google Scholar] [CrossRef]
- Zareian, A.; Rosa, K.D.; Hu, D.H.; Chang, S.F. Open-vocabulary object detection using captions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14393–14402. [Google Scholar]
- Zhu, C.; Chen, L. A Survey on Open-Vocabulary Detection and Segmentation: Past, Present, and Future. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1–20. [Google Scholar] [CrossRef]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. YOLO-World: Real-Time Open-Vocabulary Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, 17–21 June 2024; pp. 16901–16911. [Google Scholar]
- Zhang, J.; Huang, J.; Jin, S.; Lu, S. Vision-language models for vision tasks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5625–5644. [Google Scholar] [CrossRef]
- Huang, Q.; Zhang, H.; Xue, M.; Song, J.; Song, M. A survey of deep learning for low-shot object detection. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-shot object detection with attention-RPN and multi-relation detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4013–4022. [Google Scholar]
- Li, X.; Zhang, L.; Chen, Y.P.; Tai, Y.W.; Tang, C.K. One-shot object detection without fine-tuning. arXiv 2020, arXiv:2005.03819. [Google Scholar]
- Li, Y.; Feng, W.; Lyu, S.; Zhao, Q.; Li, X. MM-FSOD: Meta and metric integrated few-shot object detection. arXiv 2020, arXiv:2012.15159. [Google Scholar]
- Perez-Rua, J.M.; Zhu, X.; Hospedales, T.M.; Xiang, T. Incremental few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13846–13855. [Google Scholar]
- Yang, Y.; Wei, F.; Shi, M.; Li, G. Restoring negative information in few-shot object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 3521–3532. [Google Scholar]
- Chen, T.I.; Liu, Y.C.; Su, H.T.; Chang, Y.C.; Lin, Y.H.; Yeh, J.F.; Chen, W.C.; Hsu, W.H. Dual-awareness attention for few-shot object detection. IEEE Trans. Multimed. 2021, 25, 291–301. [Google Scholar] [CrossRef]
- Han, G.; He, Y.; Huang, S.; Ma, J.; Chang, S.F. Query adaptive few-shot object detection with heterogeneous graph convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3263–3272. [Google Scholar]
- Zhang, L.; Zhou, S.; Guan, J.; Zhang, J. Accurate few-shot object detection with support-query mutual guidance and hybrid loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14424–14432. [Google Scholar]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.F. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 780–789. [Google Scholar]
- Kobayashi, D. Self-supervised prototype conditional few-shot object detection. In Proceedings of the International Conference on Image Analysis and Processing, Lecce, Italy, 23–27 May 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 681–692. [Google Scholar]
- Li, B.; Wang, C.; Reddy, P.; Kim, S.; Scherer, S. Airdet: Few-shot detection without fine-tuning for autonomous exploration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 427–444. [Google Scholar]
- Bulat, A.; Guerrero, R.; Martinez, B.; Tzimiropoulos, G. FS-DETR: Few-Shot DEtection TRansformer with prompting and without re-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 11793–11802. [Google Scholar]
- Yang, H.; Cai, S.; Deng, B.; Ye, J.; Lin, G.; Zhang, Y. Context-aware and Semantic-consistent Spatial Interactions for One-shot Object Detection without Fine-tuning. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 5424–5439. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Gao, C.; Hao, J.; Guo, Y. OSDet: Towards Open-Set Object Detection. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–8. [Google Scholar]
- Mallick, P.; Dayoub, F.; Sherrah, J. Wasserstein Distance-based Expansion of Low-Density Latent Regions for Unknown Class Detection. arXiv 2024, arXiv:2401.05594. [Google Scholar]
- Sarkar, H.; Chudasama, V.; Onoe, N.; Wasnik, P.; Balasubramanian, V.N. Open-Set Object Detection by Aligning Known Class Representations. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–6 January 2024; pp. 219–228. [Google Scholar]
- Wu, A.; Deng, C. TIB: Detecting Unknown Objects via Two-Stream Information Bottleneck. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 611–625. [Google Scholar] [CrossRef]
- Wu, A.; Chen, D.; Deng, C. Deep feature deblurring diffusion for detecting out-of-distribution objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 13381–13391. [Google Scholar]
- Wan, Q.; Wang, S.; Xiang, X. A Simple Unknown-Instance-Aware Framework for Open-Set Object Detection. In Proceedings of the 2023 13th International Conference on Information Science and Technology (ICIST), Cairo, Egypt, 8–14 December 2023; pp. 586–593. [Google Scholar]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Yang, Q.; Liu, C.L. Convolutional prototype network for open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2358–2370. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Li, W.; Hong, J.; Petersson, L.; Barnes, N. Towards open-set object detection and discovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3961–3970. [Google Scholar]
- Hayes, T.L.; de Souza, C.R.; Kim, N.; Kim, J.; Volpi, R.; Larlus, D. PANDAS: Prototype-based Novel Class Discovery and Detection. arXiv 2024, arXiv:2402.17420. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Gorlo, N.; Blomqvist, K.; Milano, F.; Siegwart, R. ISAR: A Benchmark for Single-and Few-Shot Object Instance Segmentation and Re-Identification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–6 January 2024; pp. 4384–4396. [Google Scholar]
- Jiang, S.; Liang, S.; Chen, C.; Zhu, Y.; Li, X. Class agnostic image common object detection. IEEE Trans. Image Process. 2019, 28, 2836–2846. [Google Scholar] [CrossRef]
- Nguyen, C.H.; Nguyen, T.C.; Vo, A.H.; Masayuki, Y. Single Stage Class Agnostic Common Object Detection: A Simple Baseline. arXiv 2021, arXiv:2104.12245. [Google Scholar]
- Guo, X.; Li, X.; Wang, Y.; Jiang, S. TransWeaver: Weave Image Pairs for Class Agnostic Common Object Detection. IEEE Trans. Image Process. 2023, 32, 2947–2959. [Google Scholar] [CrossRef]
- Dümmel, J.; Gao, X. Object Re-Identification with Synthetic Training Data in Industrial Environments. In Proceedings of the 2021 27th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Shanghai, China, 26–28 November 2021; pp. 504–508. [Google Scholar]
- Chen, W.; Liu, Y.; Wang, W.; Bakker, E.M.; Georgiou, T.; Fieguth, P.; Liu, L.; Lew, M.S. Deep Learning for Instance Retrieval: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7270–7292. [Google Scholar] [CrossRef]
- Radenović, F.; Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Weyand, T.; Araujo, A.; Cao, B.; Sim, J. Google Landmarks Dataset v2 - A Large-Scale Benchmark for Instance-Level Recognition and Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Shao, S.; Chen, K.; Karpur, A.; Cui, Q.; Araujo, A.; Cao, B. Global features are all you need for image retrieval and reranking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 11036–11046. [Google Scholar]
- Lee, S.; Seong, H.; Lee, S.; Kim, E. Correlation Verification for Image Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5374–5384. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. Fine-Tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1655–1668. [Google Scholar] [CrossRef]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: DETR with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2872–2893. [Google Scholar] [CrossRef]
- Aganian, D.; Eisenbach, M.; Wagner, J.; Seichter, D.; Gross, H.M. Revisiting Loss Functions for Person Re-identification. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN, Bratislava, Slovakia, 14–17 September 2021; Farkaš, I., Masulli, P., Otte, S., Wermter, S., Eds.; Springer: Cham, Switzerland, 2021; pp. 30–42. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Seichter, D.; Fischedick, S.B.; Köhler, M.; Groß, H.M. Efficient multi-task rgb-d scene analysis for indoor environments. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–10. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 1 August 2024).
- Reizenstein, J.; Shapovalov, R.; Henzler, P.; Sbordone, L.; Labatut, P.; Novotny, D. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10901–10911. [Google Scholar]
- Choi, S.; Zhou, Q.Y.; Miller, S.; Koltun, V. A large dataset of object scans. arXiv 2016, arXiv:1602.02481. [Google Scholar]
- Downs, L.; Francis, A.; Koenig, N.; Kinman, B.; Hickman, R.; Reymann, K.; McHugh, T.B.; Vanhoucke, V. Google scanned objects: A high-quality dataset of 3d scanned household items. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2553–2560. [Google Scholar]
- Ahmadyan, A.; Zhang, L.; Ablavatski, A.; Wei, J.; Grundmann, M. Objectron: A large scale dataset of object-centric videos in the wild with pose annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7822–7831. [Google Scholar]
- Henzler, P.; Reizenstein, J.; Labatut, P.; Shapovalov, R.; Ritschel, T.; Vedaldi, A.; Novotny, D. Unsupervised learning of 3d object categories from videos in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4700–4709. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation As Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-Identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Karaoguz, H.; Jensfelt, P. Fusing saliency maps with region proposals for unsupervised object localization. arXiv 2018, arXiv:1804.03905. [Google Scholar]
- Shilkrot, R.; Narasimhaswamy, S.; Vazir, S.; Hoai, M. WorkingHands: A Hand-Tool Assembly Dataset for Image Segmentation and Activity Mining. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Stephan, B.; Köhler, M.; Müller, S.; Zhang, Y.; Gross, H.M.; Notni, G. OHO: A Multi-Modal, Multi-Purpose Dataset for Human-Robot Object Hand-Over. Sensors 2023, 23, 7807. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Yokoo, S.; Ozaki, K.; Simo-Serra, E.; Iizuka, S. Two-Stage Discriminative Re-Ranking for Large-Scale Landmark Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Gong, Y.; Zeng, Z.; Chen, L.; Luo, Y.; Weng, B.; Ye, F. A person re-identification data augmentation method with adversarial defense effect. arXiv 2021, arXiv:2101.08783. [Google Scholar]
- Zhu, S.; Zhang, Y.; Feng, Y. GW-net: An efficient grad-CAM consistency neural network with weakening of random erasing features for semi-supervised person re-identification. Image Vis. Comput. 2023, 137, 104790. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, L.; Wang, Z.; Wei, Y. Circle Loss: A Unified Perspective of Pair Similarity Optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Permitted Proposals | Recall [%] |
|---|---|---|
| DINO [70] (LVIS) | 1000 | 88.6 |
| DINO [70] (LVIS) | 500 | 86.8 |
| DINO [70] (LVIS) | 300 | 85.4 |
| DINO [70] (LVIS) | 100 | 78.4 |
| DINO [70] (LVIS) | 50 | 70.5 |
| Faster R-CNN [10] (LVIS) | 1000 | 82.9 |
| Faster R-CNN [10] (LVIS) | 500 | 77.8 |
| Faster R-CNN [10] (LVIS) | 300 | 67.0 |
| Faster R-CNN [10] (LVIS) | 100 | 34.9 |
| Faster R-CNN [10] (LVIS) | 50 | 21.1 |
| Approach | Input Size | Recall [%] |
|---|---|---|
| DINO [70] (LVIS) | 640 × 640 | 88.6 |
| DINO [70] (LVIS) | 450 × 450 | 85.1 |
| DINO [70] (LVIS) | 320 × 320 | 81.9 |
| DINO [70] (LVIS) | 270 × 270 | 75.1 |
| DINO [70] (LVIS) | 224 × 224 | 60.8 |
| Faster R-CNN [10] (LVIS) | 640 × 640 | 82.9 |
| Faster R-CNN [10] (LVIS) | 450 × 450 | 82.3 |
| Faster R-CNN [10] (LVIS) | 320 × 320 | 69.4 |
| Faster R-CNN [10] (LVIS) | 270 × 270 | 60.3 |
| Faster R-CNN [10] (LVIS) | 224 × 224 | 48.7 |
| mAP | mAP | |
|---|---|---|
| Validation/Test Dataset | SuperGlobal [66] (CBIR) | Proposed (ReID) |
| CO3D validation set [81] (in-domain ReID) | - | |
| Oxford+1M (Medium) [64] (in-domain CBIR) | - | |
| Paris+1M (Medium) [64] (in-domain CBIR) | - | |
| OHO [90] | ||
| Google scanned objects [83] | ||
| OOD tool dataset. (ours, composed of [6,82,88,89]) |
| Horizontal Flip | Vertical Flip | Random Crop | Random Erasing | mAP |
|---|---|---|---|---|
| - | - | - | - | |
| - | - | - | ✓ | |
| ✓ | - | - | - | 47.3 |
| - | ✓ | - | - | |
| - | - | ✓ | - | |
| ✓ | ✓ | - | - | |
| - | ✓ | ✓ | - | |
| ✓ | - | ✓ | - | |
| ✓ | ✓ | ✓ | - |
| Resolution | |||
|---|---|---|---|
| mAP (OOD tool dataset) | 48.1 |
| Embedding Size | 2048 | 1024 | 256 |
|---|---|---|---|
| mAP validation (CO3D dataset) | 89.3 | ||
| mAP test (OOD tool dataset) | 40.7 |
| C, P | 1, 16 | 4, 4 | 8, 2 | 16, 1 |
|---|---|---|---|---|
| mAP (OOD tool dataset) | 44.3 | 44.7 | 45.8 | 46.0 |
| Training Dataset | CO3D100 | CO3D75 | CO3D50 |
|---|---|---|---|
| mAP (OOD tool dataset) | 44.5 | 44.4 | 43.0 |
| Parameter | Description | Range |
|---|---|---|
| p | p-quantile determining the similarity threshold , described in Section 3.2.5 | |
| a | Test-time augmentation for queries in the form of horizontal flipping when creating similarity maps | {on, off} |
| RoI box resolution after combining multiple boxes, described in Section 3.2.6 | ||
| RoI box resolution after expanding small boxes, described in Section 3.2.6 | ||
| RoI box area threshold, described in Section 3.2.6 | ||
| Class-agnostic objectness threshold of object detector | ||
| r | Resizing RoIs to a constant size before applying the class-agnostic object detector | {on, off} |
| mAP50 | Inference Time | p | a | r | |||||
|---|---|---|---|---|---|---|---|---|---|
| Operating point A | 40.9 | 0.73 s/image | 1.0 | on | 0.8 | 0.25 | on | ||
| Operating point B | 44.8 | 1.05 s/image | 1.0 | on | 0.8 | 0.15 | on |
| Mean Average Precision (mAP) | Inference Time (sec/image) | |||||
|---|---|---|---|---|---|---|
| 5 Shots | 10 Shots | 20 Shots | 5 Shots | 10 Shots | 20 Shots | |
| DE-ViT, vitl [8] | 20.01 | 16.62 | 13.52 | 1.043 | 1.127 | 1.027 |
| DE-ViT, vitb [8] | 18.60 | 14.76 | 11.85 | 1.043 | 0.973 | 0.972 |
| ours, operating point A | 15.74 | 18.42 | 20.21 | 0.551 | 0.553 | 0.537 |
| ours, operating point B | 26.78 | 32.93 | 35.45 | 1.052 | 1.031 | 1.009 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eisenbach, M.; Franke, H.; Franze, E.; Köhler, M.; Aganian, D.; Seichter, D.; Gross, H.-M. Detection of Novel Objects without Fine-Tuning in Assembly Scenarios by Class-Agnostic Object Detection and Object Re-Identification. Automation 2024, 5, 373-406. https://doi.org/10.3390/automation5030023
Eisenbach M, Franke H, Franze E, Köhler M, Aganian D, Seichter D, Gross H-M. Detection of Novel Objects without Fine-Tuning in Assembly Scenarios by Class-Agnostic Object Detection and Object Re-Identification. Automation. 2024; 5(3):373-406. https://doi.org/10.3390/automation5030023
Chicago/Turabian StyleEisenbach, Markus, Henning Franke, Erik Franze, Mona Köhler, Dustin Aganian, Daniel Seichter, and Horst-Michael Gross. 2024. "Detection of Novel Objects without Fine-Tuning in Assembly Scenarios by Class-Agnostic Object Detection and Object Re-Identification" Automation 5, no. 3: 373-406. https://doi.org/10.3390/automation5030023
APA StyleEisenbach, M., Franke, H., Franze, E., Köhler, M., Aganian, D., Seichter, D., & Gross, H.-M. (2024). Detection of Novel Objects without Fine-Tuning in Assembly Scenarios by Class-Agnostic Object Detection and Object Re-Identification. Automation, 5(3), 373-406. https://doi.org/10.3390/automation5030023