
A Context-Aware Method-Based Cattle Vocal Classification for Livestock Monitoring in Smart Farm †


Abstract
:1. Introduction
2. Materials and Methods
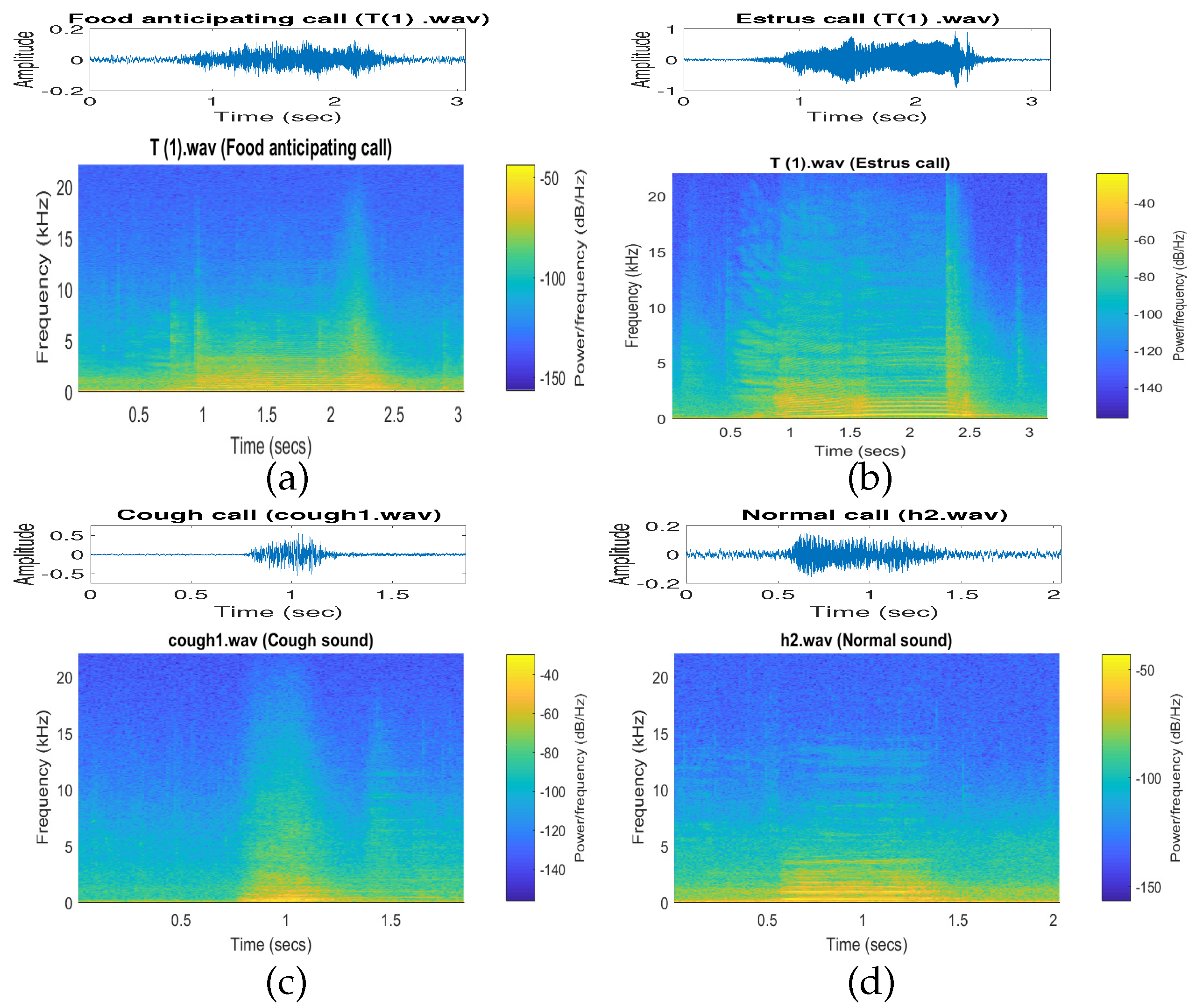
2.1. Database Used
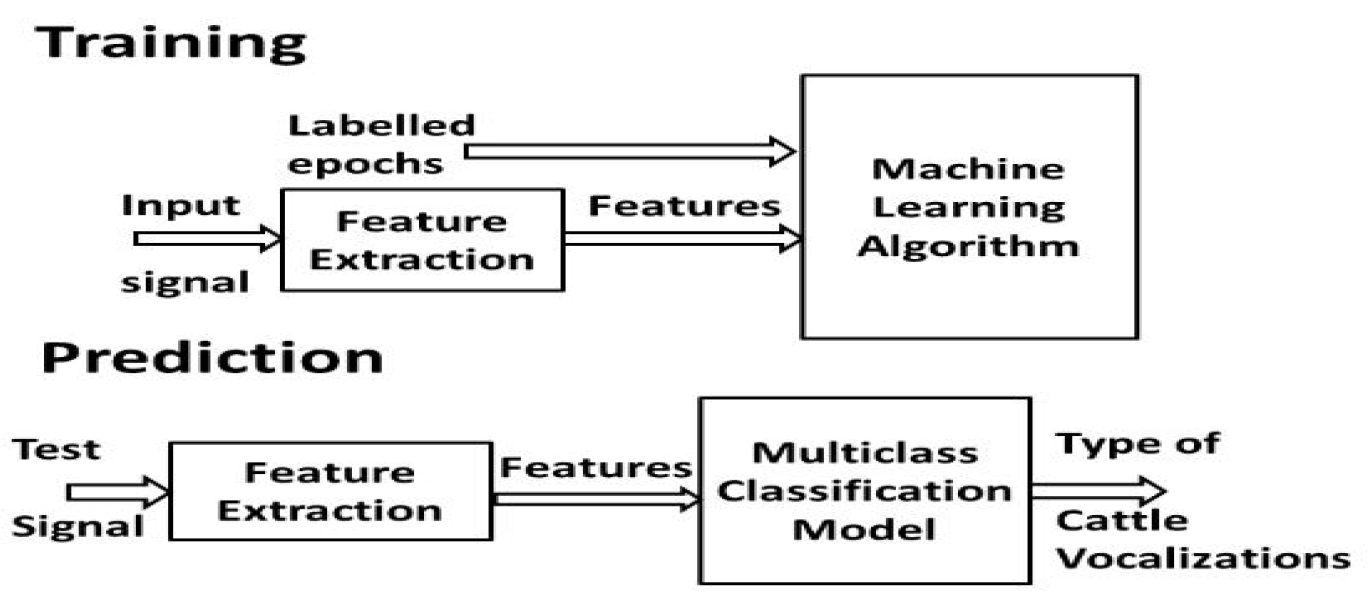
2.2. Proposed Method
2.2.1. Data Preprocessing
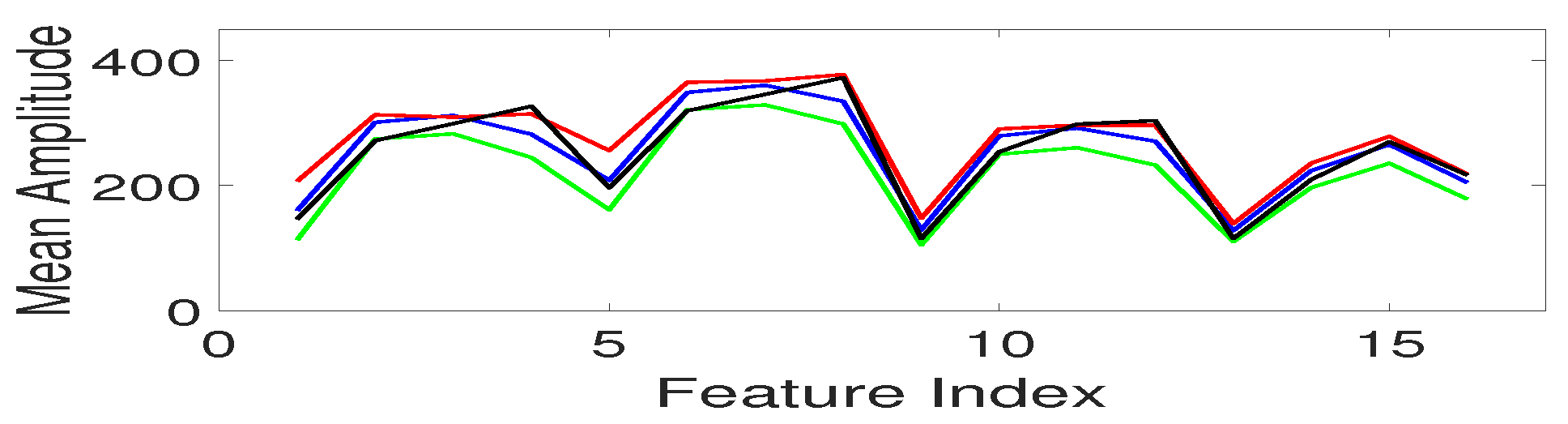
2.2.2. Contextual Acoustic Features
- Given input data, compute the first 32-channel cochleagram (CB1) followed by a log operation applied to each T-F unit.
- Similarly, the second cochleagram (CB2) is computed with the frame length of 200 msec and frame shift of 10 msec.
- The third cochleagram (CB3) is derived by averaging CB1 using a rectangular window of size (5 × 5) including five frequency channels and five time frames centered at a given T-F unit. If the window goes beyond the given cochleagram, the outside units take the value of zero (i.e., zero padding).
- The fourth cochleagram CB4 is computed in a similar way to CB3, except that a rectangular window of size (11 × 11) is used.
- Concatenate CB1-CB4 to generate a feature matrix F and integrate it along the time frame to obtain a set of contextual features of dimension (128 × 1).
2.2.3. MSVM Classification
3. Results and Discussion
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Banhazi, T.M.; Lehr, H.; Black, J.L.; Crabtree, H.; Schofield, C.P.; Tscharke, M.; Berckmans, D. Precision Livestock Farming: An International Review of Scientific and Commercial Aspects. Int. J. Agric. Biol. Eng. 2012, 5, 1–9. [Google Scholar] [CrossRef]
- Jung, D.-H.; Kim, N.Y.; Moon, S.H.; Jhin, C.; Kim, H.-J.; Yang, J.-S.; Kim, H.S.; Lee, T.S.; Lee, J.Y.; Park, S.H. Deep Learning-Based Cattle Vocal Classification Model and Real-Time Livestock Monitoring System with Noise Filtering. Animals 2021, 11, 357. [Google Scholar] [CrossRef] [PubMed]
- Vandermeulen, J.; Bahr, C.; Johnston, D.; Earley, B.; Tullo, E.; Fontana, I.; Guarino, M.; Exadaktylos, V.; Berckmans, D. Early Recognition of Bovine Respiratory Disease in Calves using Automated Continuous Monitoring of Cough Sounds. Comput. Electron. Agricult. 2016, 129, 15–26. [Google Scholar] [CrossRef] [PubMed]
- Galli, J.R.; Cangiano, C.A.; Pece, M.A.; Larripa, M.J.; Milone, D.H.; Utsumi, S.A.; Laca, E.A. Monitoring and Assessment of Ingestive Chewing Sounds for Prediction of Herbage Intake Rate in Grazing Cattle. Animal 2018, 12, 973–982. [Google Scholar] [CrossRef] [PubMed]
- Baciadonna, L.; Briefer, E.F.; Favaro, L.; McElligott, A.G. Goats Distinguish Between Positive and Negative Emotion-Linked Vocalisations. Front. Zool. 2019, 16, 2–11. [Google Scholar] [CrossRef] [PubMed]
- Röttgen, V.; Schön, P.C.; Becker, F.; Tuchscherer, A.; Wrenzycki, C.; Düpjan, S.; Puppe, B. Automatic Recording of Individual Oestrus Vocalisation in Group-Housed Dairy Cattle: Development of a Cattle Call Monitor. Animal 2020, 14, 98–205. [Google Scholar] [CrossRef] [PubMed]
- Schön, P.C.; Hämel, K.; Puppe, B.; Tuchscherer, A.; Kanitz, W.; Manteuffel, G. Altered Vocalization Rate During the Estrous Cycle in Dairy Cattle. J Dairy Sci. 2007, 90, 202–206. [Google Scholar] [CrossRef]
- Available online: https://www.mdpi.com/2076-2615/11/2/357/s1 (accessed on 24 September 2021).
- Oppenheim, A.V.; Schafer, R.W. Digital Signal Processing; Prentice-Hall: Hoboken, NJ, USA, 1975. [Google Scholar]
- Proakis, J.; Manolakis, D. Digital Signal Processing: Principles, Algorithms and Applications; Macmillan Publishing Company: New York, NY, USA, 1992. [Google Scholar]
- Crammer, K.; Singer, Y. On the Algorithmic Implementation of Multiclass Kernel-Based Vector Machines. J. Mach. Learn. Res. 2001, 2, 265–292. [Google Scholar]
- Mishra, A. Multi Class Support Vector Machine. MATLAB Central File Exchange. 2021. Available online: https://www.mathworks.com/matlabcentral/fileexchange/33170-multi-class-support-vector-machine (accessed on 15 October 2021).
- Devi, M.R.; Ravichandran, T. A Novel Approach for Speech Feature Extraction by Cubic-Log Compression in MFCC. In Proceedings of the IEEE Conference on Pattern Recognition, Informatics and Mobile Engineering, Salem, India, 21–22 February 2013. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Type of Vocalization | Number of Vocalization |
|---|---|
| Food anticipation | 100 |
| Estrus | 117 |
| Cough | 11 |
| Normal | 42 |
| Food Anticipation | Estrus | Cough | Normal | Specificity | |
|---|---|---|---|---|---|
| Food anticipation | 24 | 3 | 0 | 1 | 0.85 |
| Estrus | 6 | 29 | 0 | 0 | 0.82 |
| Cough | 0 | 0 | 1 | 1 | 0.50 |
| Normal | 1 | 0 | 0 | 9 | 0.90 |
| Sensitivity | 0.77 | 0.90 | 1 | 0.81 | 84.00 |
| M | 8 | 16 | 32 |
|---|---|---|---|
| Average accuracy (%) | 78.67 | 84.00 | 80.82 |
| Food Anticipation | Estrus | Cough | Normal | Specificity | |
|---|---|---|---|---|---|
| Food anticipation | 23 | 4 | 1 | 0 | 0.82 |
| Estrus | 18 | 15 | 0 | 1 | 0.44 |
| Cough | 2 | 0 | 0 | 0 | 0 |
| Normal | 3 | 0 | 0 | 7 | 0.70 |
| Sensitivity | 0.50 | 0.78 | 0 | 0.87 | 60.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sattar, F. A Context-Aware Method-Based Cattle Vocal Classification for Livestock Monitoring in Smart Farm. Chem. Proc. 2022, 10, 89. https://doi.org/10.3390/IOCAG2022-12233
Sattar F. A Context-Aware Method-Based Cattle Vocal Classification for Livestock Monitoring in Smart Farm. Chemistry Proceedings. 2022; 10(1):89. https://doi.org/10.3390/IOCAG2022-12233
Chicago/Turabian StyleSattar, Farook. 2022. "A Context-Aware Method-Based Cattle Vocal Classification for Livestock Monitoring in Smart Farm" Chemistry Proceedings 10, no. 1: 89. https://doi.org/10.3390/IOCAG2022-12233
APA StyleSattar, F. (2022). A Context-Aware Method-Based Cattle Vocal Classification for Livestock Monitoring in Smart Farm. Chemistry Proceedings, 10(1), 89. https://doi.org/10.3390/IOCAG2022-12233