


Enhancing User Profile Authenticity through Automatic Image Caption Generation Using a Bootstrapping Language–Image Pre-Training Model †
.jpeg)

Abstract
1. Introduction
- Object recognition: The method for recognizing and pinpointing any items in the image.
- Recognition of attributes: The algorithm must be able to determine the extent, color, and shape of the objects in the image.
- Image understanding: The methodology must be able to comprehend the relationships and context of the image’s visual components.
- Feature extraction: To create the caption, the computer extracts the pertinent features from the image.
- Natural language processing: The algorithm creates a statement that represents the image that is both grammatically and semantically sound using natural language processing techniques.
- Caption evaluation: The algorithm must assess the effectiveness of the generated caption. This is commonly done using metrics like BLEU (bilingual evaluation understudy), which uses metrics to measure bilingualism [6].
2. Related Work
3. Bootstrapping Process for Language-Image Pretraining Model
- Unimodal Encoders: The BLIP model employs separate encoders for processing images and text. The image encoder utilizes a vision transformer, while the text encoder is built upon BERT. To summarize this in a nutshell, a [CLS] token is inserted at the start of the text input.
- Image-Grounded Text Encoder: This feature integrates visual information by adding a cross-attention layer between the self-attention layer and the feedforward network for each transformer block within the text encoder. A task-specific [Encode] token is appended to the text, and the output embedding of [Encode] serves as the multimodal representation for the image–text pair.
- Image-Grounded Text Decoder: In the decoder part of the BLIP model, the bi-directional self-attention layers in the text encoder are replaced with causal self-attention layers. A special [Decode] token is employed to signify the start of a sequence.
4. Proposed Work
- The process begins by taking the user profile image and passing it through a CNN encoder, resulting in a feature vector represented as ‘f’ (as described in Equation (1)):
- 2.
- Subsequently, this feature vector is provided as input to an RNN decoder for the step-by-step generation of the image caption. Equation (2) demonstrates how the RNN decoder computes the probability of the next word (y_t) in the caption based on the previous words, the hidden state at time ‘t-1’ (h_{t-1}), and the feature vector ‘f’ from the image:
- 3.
- The RNN decoder then generates the caption by selecting the word with the highest likelihood, considering the preceding words and the image features, as depicted in Equation (3):
- Data Collection: A dataset is created by us for scam and real user profiles, for this study from scamdigger.com and datingnmore.com. After data collection, preprocessing is done.
- Text Pre-training: Pre-train a language model on the textual profile data classification.
- Image Pre-training: Convolutional neural networks (CNNs) should be trained beforehand on image data using ResNet algorithms.
- Joint Pre-training: To make the system more accurate, the pre-trained language model and CNN are combined to create a joint pre-training model. This involves fine-tuning the combined model on a dataset that includes both image and text data. The goal is to leverage the pre-trained language model’s ability to understand natural language and CNN’s ability to extract visual features.
- Transfer Learning: to train the model to extract visual features, to generate captions.
Algorithm
- Step 1: T = t1, t2,…, tm is a set of textual descriptions, and let I = I1, I2,…, In be a set of images. The pre-trained image encoder, pre-trained text encoder, and the jointly to-be-trained image–text encoder are represented by the variables f, g, and h, respectively.
- Step 2: The BLIP process revolves around the core objective of training the joint image–text encoder ‘h’ to maximize the likelihood of the joint distribution between images and their corresponding textual descriptions. This can be mathematically expressed, as shown in Equation (4): Maximizing the sum of the logarithm of conditional probabilities for each pair of images and their related textual descriptions is the central aim:where fi = f(Ii) is the encoded image representation, gj = g(tj) is the encoded textual representation, and P (tj | fi, gj) is the probability of the text explanation tj given the encoded image and textual representations.Maximize Σi = 1 to n Σj = 1 to m log P (tj | fi, gj)
- Step 3: In order to learn the combined image–text encoder, h, the negative log-likelihood of the aforementioned objective is minimized, which is expressed as in Equation (5):Minimize-Σi = 1^n Σj = 1^m log P(tj | fi, gj)
5. Results and Discussion
6. Conclusions and Future Work
- Improved User Experience: Automatic image caption generation could improve user experience by making it easier for users to search for and find relevant content on social media platforms. By generating informative and accurate captions for user profile images, users can better communicate their interests and preferences to others, leading to more meaningful interactions and connections.
- Multimodal Understanding: an approach to data analysis that combines different types of data, such as text and image data, to gain a more comprehensive understanding of a user or a system. In addition to text and image data, future research could explore ways to integrate other types of data, such as audio or video, to create even more robust multimodal models. By incorporating a wider range of data types, these models could capture the full richness of user profiles and provide a more complete understanding of users and their behaviors.
- Personalization: APCG could be used to personalize recommendations for users based on their interests and preferences. By analyzing the captions generated for user profile images, platforms could better understand what types of content users are interested in and tailor their recommendations accordingly.
- Accessibility: APCG could improve accessibility for users with visual impairments or other disabilities. By generating informative and accurate captions for user profile images, platforms could make their content more accessible to a wider range of users.
- Ethical Considerations and Potential Bias with APCG: As with any technology that uses personal data, there are ethical considerations to be addressed. APCG for user profiles raises ethical concerns regarding privacy, potential biases, accuracy, and transparency. Privacy must be protected by obtaining user consent and adhering to data protection regulations. Biases and discriminatory outputs should be addressed through diverse training data and fairness-aware algorithms. Ensuring the accuracy and reliability of generated captions is crucial to avoid misrepresentation or dissemination of false information. Future research could explore ways to ensure that user privacy and data security are maintained when generating captions for user profile images and to mitigate the risk of biases or stereotypes being introduced into the caption generation process.
- Challenges in handling diverse user profiles and noisy image content: Noisy or low-quality images can pose a challenge for the system, as it may struggle to extract meaningful features and context from such images. This can lead to inaccurate or irrelevant captions that do not effectively describe the profile image. To overcome this problem, we can use attention mechanisms in the caption generation models to improve the model’s ability to focus on relevant image regions and extract important features, even in the presence of noisy or complex visual content.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gan, C.; Yang, T.; Gong, B. Learning attributes equals multi-source domain generalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 87–97. [Google Scholar]
- Maji, S.; Bourdev, L.; Malik, J. Action recognition from a distributed representation of pose and appearance. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3177–3184. [Google Scholar]
- Chao, Y.W.; Wang, Z.; Mihalcea, R.; Deng, J. Mining semantic affordances of visual object categories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4259–4267. [Google Scholar]
- Huang, C.Y.; Hsu, T.Y.; Rossi, R.; Nenkova, A.; Kim, S.; Chan, G.Y.Y.; Koh, E.; Giles, L.C.; Huang, T.-H.K. Summaries as Captions: Generating Figure Captions for Scientific Documents with Automated Text Summarization. arXiv 2023, arXiv:2302.12324. [Google Scholar]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A Comprehensive Survey of Deep Learning for Image Captioning. ACM Comput. Surv. 2019, 51, 118. [Google Scholar]
- Jiang, M.; Huang, Q.; Zhang, L.; Wang, X.; Zhang, P.; Gan, Z.; Gao, J. Tiger: Text-to-image grounding for image caption evaluation. arXiv 2019, arXiv:1909.02050. [Google Scholar]
- Wang, S.; Yao, Z.; Wang, R.; Wu, Z.; Chen, X. Faier: Fidelity and adequacy ensured image caption evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14050–14059. [Google Scholar]
- Liu, X.; Xu, Q.; Wang, N. A survey on deep neural network-based image captioning. In The Visual Computer; Springer Nature: Berlin/Heidelberger, Germany, 2018. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Ordonez, V.; Kulkarni, G.; Berg, T.L. Im2Text: Describing images using 1 million captioned photographs. In Proceedings of the 24th International Conference on Neural Information Processing Systems (NIPS’11), Granada, Spain, 12–15 December 2011; Curran Associates Inc.: Red Hook, NY, USA, 2011; Volume 24, pp. 1143–1151. [Google Scholar]
- Soh, M. Learning CNN-LSTM Architectures for Image Caption Generation; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Hossain, M.Z. Deep Learning Techniques for Image Captioning. Ph.D. Thesis, Murdoch University, Perth, Australia, 2020. [Google Scholar]
- Yi, J.; Wu, C.; Zhang, X.; Xiao, X.; Qiu, Y.; Zhao, W.; Hou, T.; Cao, D. MICER: A pre-trained encoder–decoder architecture for molecular image captioning. Bioinformatics 2022, 38, 4562–4572. [Google Scholar] [CrossRef] [PubMed]
- Xiao, F.; Xue, W.; Shen, Y.; Gao, X. A New Attention-Based LSTM for Image Captioning. Neural Process. Lett. 2022, 54, 3157–3171. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. Int. Conf. Mach. Learn. 2015, 37, 2048–2057. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 652–663. [Google Scholar] [PubMed]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv 2023, arXiv:2301.12597. [Google Scholar]
- Predić, B.; Manić, D.; Saračević, M.; Karabašević, D.; Stanujkić, D. Automatic image caption generation based on some machine learning algorithms. Math. Probl. Eng. 2022, 2022, 4001460. [Google Scholar]
- Sasibhooshan, R.; Kumaraswamy, S.; Sasidharan, S. Image caption generation using Visual Attention Prediction and Contextual Spatial Relation Extraction. J. Big Data 2023, 10, 18. [Google Scholar]
- Gaurav; Mathur, P. A Survey on Various Deep Learning Models for Automatic Image Captioning. J. Phys. Conf. Ser. 2022, 1950, 012045. [Google Scholar] [CrossRef]
- Available online: https://datingnmore.com/ (accessed on 5 March 2023).
- Available online: http://scamdigger.com/ (accessed on 5 March 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
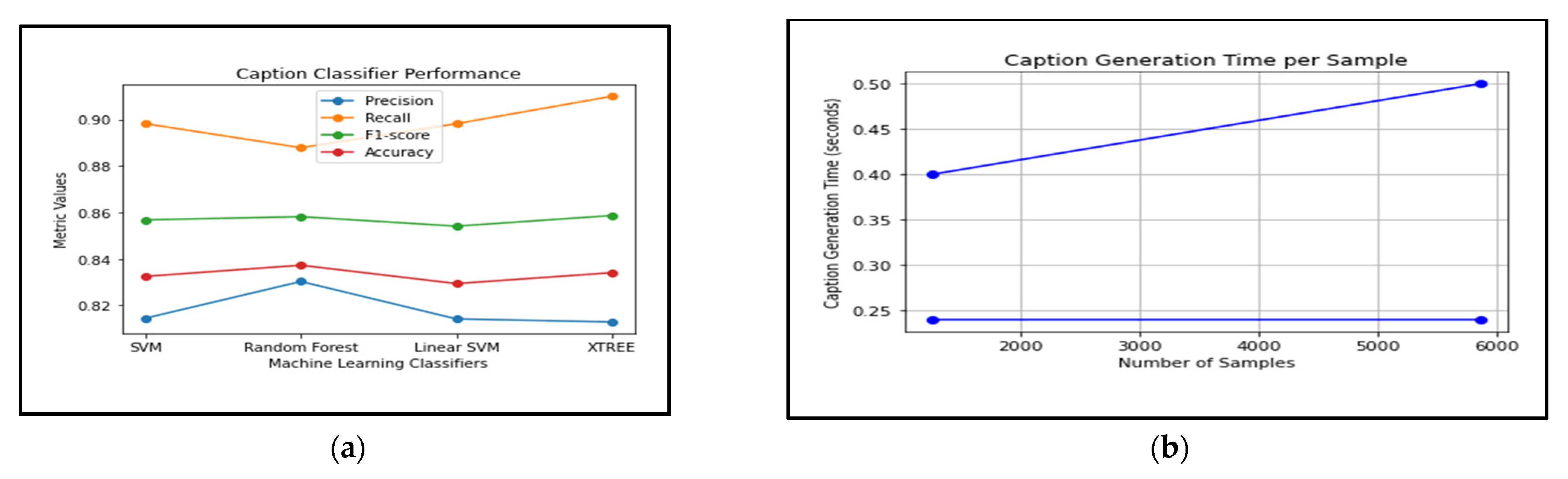
| Caption Classifier | Precision | Recall | F1 score | Accuracy |
|---|---|---|---|---|
| SVM | 0.8145 | 0.8982 | 0.8568 | 0.8325 |
| Random Forest | 0.8303 | 0.8879 | 0.8582 | 0.8373 |
| Linear SVM | 0.8142 | 0.8982 | 0.8541 | 0.8294 |
| XTree | 0.8129 | 0.91 | 0.8587 | 0.8341 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bharne, S.; Bhaladhare, P. Enhancing User Profile Authenticity through Automatic Image Caption Generation Using a Bootstrapping Language–Image Pre-Training Model. Eng. Proc. 2023, 59, 182. https://doi.org/10.3390/engproc2023059182
Bharne S, Bhaladhare P. Enhancing User Profile Authenticity through Automatic Image Caption Generation Using a Bootstrapping Language–Image Pre-Training Model. Engineering Proceedings. 2023; 59(1):182. https://doi.org/10.3390/engproc2023059182
Chicago/Turabian StyleBharne, Smita, and Pawan Bhaladhare. 2023. "Enhancing User Profile Authenticity through Automatic Image Caption Generation Using a Bootstrapping Language–Image Pre-Training Model" Engineering Proceedings 59, no. 1: 182. https://doi.org/10.3390/engproc2023059182
APA StyleBharne, S., & Bhaladhare, P. (2023). Enhancing User Profile Authenticity through Automatic Image Caption Generation Using a Bootstrapping Language–Image Pre-Training Model. Engineering Proceedings, 59(1), 182. https://doi.org/10.3390/engproc2023059182