3. Materials and Methodology
3.9. Additional Hyperparameters Tuning
The different modules used to build our architecture are widely discussed in the academic literature. However, the originality of our method is in the way we conduct hyperparameter tuning. An incorrect or inappropriate choice of hyperparameters can lead even advanced methods to underperform. We chose not to utilize automated hyperparameter tuning tools and focused on deriving insights directly from the data instead. Our approach involves leveraging our knowledge in physiology and deep learning to specialize our architecture on eye movement gaze data.
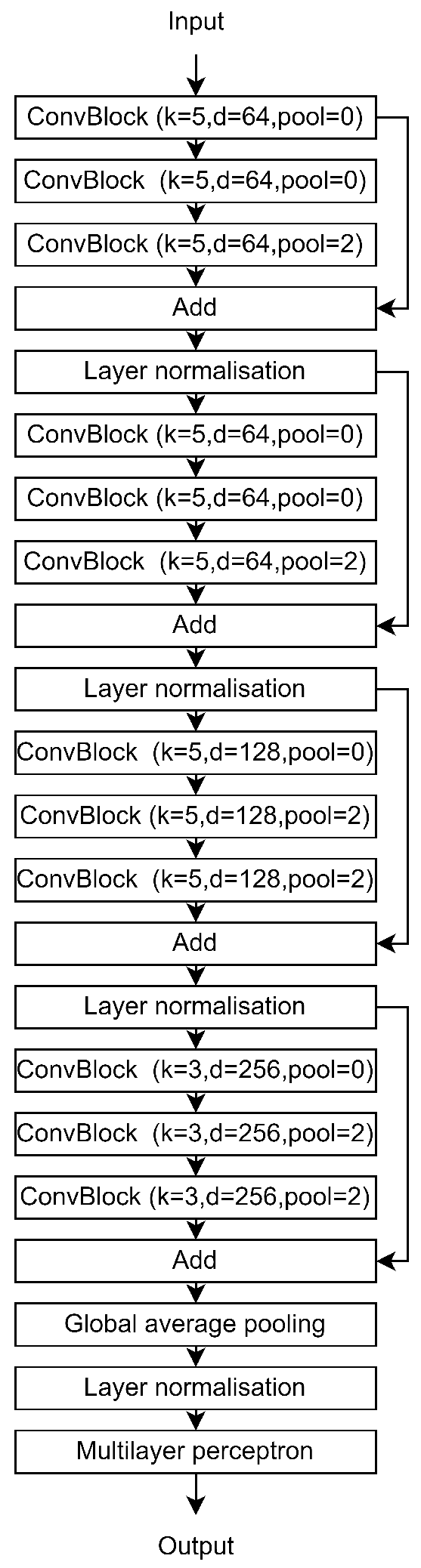
Furthermore, beyond the activation and dilation rates discussed previously, we fine-tune additional hyperparameters such as the number of filters, kernel size, and pooling size. The hyperparameters utilized for each stage and in every convolution block are detailed in
Table A1. It is important to note that each value represents a tuple of three elements, aligning with the configurations of the three distinct convolutional blocks within each stage. Additionally, all convolution layers within the same convolution block adhere to the same hyperparameter setting.
First, we optimize the number of filters for each convolution layer, a crucial parameter that controls the model’s capacity by adjusting the feature space size. A higher value without sufficient augmentation can lead to overfitting, while selecting smaller parameters may mitigate sample size on simple tasks but is prone to underfitting on complex tasks. In our studies, we aim to maintain the cardinality of the input space by reducing the temporal dimension while increasing the input dimension. We adopted an approach similar to ResNet, with a fixed-size feature space per stage and set the number of filters to 64, 64, 128, and 256 for the first, second, third, and the last stage, respectively.
Alongside the filter size, the kernel size controls the model’s capacity, determining the dimension of the parameter tensor for each layer. Using a larger kernel in the first layers where the filter size is smaller, and a smaller kernel size when the filter size becomes larger helps to keep the size of the weight tensor and of the corresponding layers relatively small. Thus, we set k to 5 for the first three stages, and to 3 for the last stage where the filter size is equal to 256.
The pooling layer is used to increase the receptive field of the last layers. In modern deep learning architectures, we progressively reduce the temporal dimension and increase the pooling size per stage. This allows the last layers to have a larger receptive field while letting the first layers take advantage of larger temporal space information. As a result, for the first two stages, we perform pooling only in the last ConvBlock, while in the last two stages, pooling is performed on the second and the last ConvBlocks.
4. Results and Evaluation
Author Contributions
Conceptualization, A.E.E.H. and V.S.F.G.; methodology, A.E.E.H.; software, A.E.E.H.; validation, A.E.E.H., V.S.F.G. and ZK; formal analysis, A.E.E.H.; investigation, A.E.E.H.; resources, ZK.; data curation, A.E.E.H.; writing—original draft preparation, A.E.E.H., V.S.F.G. and Z.K.; writing—review and editing, A.E.E.H., V.S.F.G. and Z.K.; visualization, A.E.E.H.; project administration, V.S.F.G. and Z.K.; funding acquisition, Z.K. All authors have read and agreed to the published version of the manuscript.
Funding
Alae Eddine El Hmimdi is funded by Orasis-Ear and ANRT, CIFRE.
Informed Consent Statement
This meta-analysis drew upon data sourced from Orasis Ear, in collaboration with clinical centers employing Remobi and Aideal technology. Participating centers agreed to store their data anonymously for further analysis.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are not publicly available. However, upon reasonable request, they are available from the corresponding author.
Conflicts of Interest
Zoï Kapoula is the founder of Orasis-EAR.
References
- Ward, L.M.; Kapoula, Z. Creativity, Eye-Movement Abnormalities, and Aesthetic Appreciation of Magritte’s Paintings. Brain Sci. 2022, 12, 1028. [Google Scholar] [CrossRef]
- Ward, L.M.; Kapoula, Z. Differential diagnosis of vergence and saccade disorders in dyslexia. Sci. Rep. 2020, 10, 22116. [Google Scholar] [CrossRef]
- El Hmimdi, A.E.; Ward, L.M.; Palpanas, T.; Kapoula, Z. Predicting dyslexia and reading speed in adolescents from eye movements in reading and non-reading tasks: A machine learning approach. Brain Sci. 2021, 11, 1337. [Google Scholar] [CrossRef]
- El Hmimdi, A.E.; Ward, L.M.; Palpanas, T.; Sainte Fare Garnot, V.; Kapoula, Z. Predicting Dyslexia in Adolescents from Eye Movements during Free Painting Viewing. Brain Sci. 2022, 12, 1031. [Google Scholar] [CrossRef]
- Nilsson Benfatto, M.; Öqvist Seimyr, G.; Ygge, J.; Pansell, T.; Rydberg, A.; Jacobson, C. Screening for dyslexia using eye tracking during reading. PLoS ONE 2016, 11, e0165508. [Google Scholar] [CrossRef]
- Asvestopoulou, T.; Manousaki, V.; Psistakis, A.; Smyrnakis, I.; Andreadakis, V.; Aslanides, I.M.; Papadopouli, M. Dyslexml: Screening tool for dyslexia using machine learning. arXiv 2019, arXiv:1903.06274. [Google Scholar]
- Jothi Prabha, A.; Bhargavi, R. Prediction of dyslexia from eye movements using machine learning. IETE J. Res. 2022, 68, 814–823. [Google Scholar] [CrossRef]
- Vajs, I.A.; Kvaščev, G.S.; Papić, T.M.; Janković, M.M. Eye-tracking Image Encoding: Autoencoders for the Crossing of Language Boundaries in Developmental Dyslexia Detection. IEEE Access 2023, 11, 3024–3033. [Google Scholar] [CrossRef]
- Nerušil, B.; Polec, J.; Škunda, J.; Kačur, J. Eye tracking based dyslexia detection using a holistic approach. Sci. Rep. 2021, 11, 15687. [Google Scholar] [CrossRef] [PubMed]
- Pooch, E.H.; Ballester, P.; Barros, R.C. Can we trust deep learning based diagnosis? The impact of domain shift in chest radiograph classification. In Proceedings of the Thoracic Image Analysis: Second International Workshop, TIA 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 8 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 74–83. [Google Scholar]
- Smyrnakis, I.; Andreadakis, V.; Selimis, V.; Kalaitzakis, M.; Bachourou, T.; Kaloutsakis, G.; Kymionis, G.D.; Smirnakis, S.; Aslanides, I.M. RADAR: A novel fast-screening method for reading difficulties with special focus on dyslexia. PLoS ONE 2017, 12, e0182597. [Google Scholar] [CrossRef] [PubMed]
- Rello, L.; Ballesteros, M. Detecting readers with dyslexia using machine learning with eye tracking measures. In Proceedings of the 12th International Web for All Conference, Mallorca, Spain, 20–23 September 2015; pp. 1–8. [Google Scholar]
- Bixler, R.; D’Mello, S. Automatic gaze-based user-independent detection of mind wandering during computerized reading. User Model. -User-Adapt. Interact. 2016, 26, 33–68. [Google Scholar] [CrossRef]
- Skaramagkas, V.; Ktistakis, E.; Manousos, D.; Kazantzaki, E.; Tachos, N.S.; Tripoliti, E.; Fotiadis, D.I.; Tsiknakis, M. eSEE-d: Emotional State Estimation Based on Eye-Tracking Dataset. Brain Sci. 2023, 13, 589. [Google Scholar] [CrossRef]
- JothiPrabha, A.; Bhargavi, R.; Rani, B.D. Prediction of dyslexia severity levels from fixation and saccadic eye movement using machine learning. Biomed. Signal Process. Control. 2023, 79, 104094. [Google Scholar] [CrossRef]
- Rizzo, A.; Ermini, S.; Zanca, D.; Bernabini, D.; Rossi, A. A machine learning approach for detecting cognitive interference based on eye-tracking data. Front. Hum. Neurosci. 2022, 16, 806330. [Google Scholar] [CrossRef]
- Ktistakis, E.; Skaramagkas, V.; Manousos, D.; Tachos, N.S.; Tripoliti, E.; Fotiadis, D.I.; Tsiknakis, M. COLET: A dataset for COgnitive workLoad estimation based on eye-tracking. Comput. Methods Programs Biomed. 2022, 224, 106989. [Google Scholar] [CrossRef]
- Vajs, I.; Ković, V.; Papić, T.; Savić, A.M.; Janković, M.M. Spatiotemporal eye-tracking feature set for improved recognition of dyslexic reading patterns in children. Sensors 2022, 22, 4900. [Google Scholar] [CrossRef]
- Hutt, S.; Hardey, J.; Bixler, R.; Stewart, A.; Risko, E.; D’Mello, S.K. Gaze-Based Detection of Mind Wandering during Lecture Viewing. In Proceedings of the International Educational Data Mining Society, Paper presented at the International Conference on Educational Data Mining (EDM), Wuhan, China, 25–28 June 2017. [Google Scholar]
- Vajs, I.; Ković, V.; Papić, T.; Savić, A.M.; Janković, M.M. Dyslexia detection in children using eye tracking data based on VGG16 network. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1601–1605. [Google Scholar]
- Uribarri, G.; von Huth, S.E.; Waldthaler, J.; Svenningsson, P.; Fransén, E. Deep Learning for Time Series Classification of Parkinson’s Disease Eye Tracking Data. arXiv 2023, arXiv:2311.16381. [Google Scholar]
- Sun, J.; Liu, Y.; Wu, H.; Jing, P.; Ji, Y. A novel deep learning approach for diagnosing Alzheimer’s disease based on eye-tracking data. Front. Hum. Neurosci. 2022, 16, 972773. [Google Scholar] [CrossRef]
- Elbattah, M.; Guérin, J.L.; Carette, R.; Cilia, F.; Dequen, G. NLP-Based Approach to Detect Autism Spectrum Disorder in Saccadic Eye Movement. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1581–1587. [Google Scholar]
- Chen, S.; Zhao, Q. Attention-based autism spectrum disorder screening with privileged modality. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1181–1190. [Google Scholar]
- Jiang, M.; Zhao, Q. Learning visual attention to identify people with autism spectrum disorder. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–20 October 2017; pp. 3267–3276. [Google Scholar]
- Zemblys, R.; Niehorster, D.C.; Holmqvist, K. gazeNet: End-to-end eye-movement event detection with deep neural networks. Behav. Res. Methods 2019, 51, 840–864. [Google Scholar] [CrossRef]
- Cole, Z.; Kuntzelman, K.; Dodd, M.D.; Johnson, M.R. Convolutional neural networks can decode eye movement data: A black box approach to predicting task from eye movements. J. Vis. 2020, 21, 9. [Google Scholar] [CrossRef]
- Uppal, K.; Kim, J.; Singh, S. Decoding Attention from Gaze: A Benchmark Dataset and End-to-End Models. In Proceedings of the Annual Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 219–240. [Google Scholar]
- Tao, Y.; Shyu, M.L. SP-ASDNet: CNN-LSTM based ASD classification model using observer scanpaths. In Proceedings of the 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 641–646. [Google Scholar]
- Bautista, L.G.C.; Naval, P.C. Gazemae: General representations of eye movements using a micro-macro autoencoder. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 7004–7011. [Google Scholar]
- Bautista, L.G.C.; Naval, P.C. CLRGaze: Contrastive Learning of Representations for Eye Movement Signals. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1241–1245. [Google Scholar]
- Lee, S.W.; Kim, S. Detection of Abnormal Behavior with Self-Supervised Gaze Estimation. arXiv 2021, arXiv:2107.06530. [Google Scholar]
- Harisinghani, A.; Sriram, H.; Conati, C.; Carenini, G.; Field, T.; Jang, H.; Murray, G. Classification of Alzheimer’s using Deep-learning Methods on Webcam-based Gaze Data. Proc. ACM Hum.-Comput. Interact. 2023, 7, 1–17. [Google Scholar] [CrossRef]
- Ahmed, I.A.; Senan, E.M.; Rassem, T.H.; Ali, M.A.; Shatnawi, H.S.A.; Alwazer, S.M.; Alshahrani, M. Eye tracking-based diagnosis and early detection of autism spectrum disorder using machine learning and deep learning techniques. Electronics 2022, 11, 530. [Google Scholar] [CrossRef]
- Pupila Capture Eye Tracker. Available online: http://https://pupil-labs.com/ (accessed on 13 April 2023).
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Gridach, M.; Voiculescu, I. OXENDONET: A dilated convolutional neural networks for endoscopic artefact segmentation. In Proceedings of the CEUR Workshop Proceedings, Padua, Italy, 4–9 October 2020; Volume 2595. [Google Scholar]
- Stein, J.F. Does dyslexia exist? Lang. Cogn. Neurosci. 2018, 33, 313–320. [Google Scholar] [CrossRef]
- Stein, J. What is developmental dyslexia? Brain Sci. 2018, 8, 26. [Google Scholar] [CrossRef]
- Elliott, J.G.; Gibbs, S. Does dyslexia exist? J. Philos. Educ. 2008, 42, 475–491. [Google Scholar] [CrossRef]
- Kapoula, Z.; Morize, A.; Daniel, F.; Jonqua, F.; Orssaud, C.; Bremond-Gignac, D. Objective evaluation of vergence disorders and a research-based novel method for vergence rehabilitation. Transl. Vis. Sci. Technol. 2016, 5, 8. [Google Scholar] [CrossRef]
- Daniel, F.; Morize, A.; Brémond-Gignac, D.; Kapoula, Z. Benefits from vergence rehabilitation: Evidence for improvement of reading saccades and fixations. Front. Integr. Neurosci. 2016, 10, 33. [Google Scholar] [CrossRef]
- Deane, O.; Toth, E.; Yeo, S.H. Deep-SAGA: A deep-learning-based system for automatic gaze annotation from eye-tracking data. Behav. Res. Methods 2023, 55, 1372–1391. [Google Scholar] [CrossRef]
- Ghosh, S.; Dhall, A.; Hayat, M.; Knibbe, J.; Ji, Q. Automatic gaze analysis: A survey of deep learning based approaches. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 61–84. [Google Scholar] [CrossRef] [PubMed]
- Bao, Y.; Liu, Y.; Wang, H.; Lu, F. Generalizing gaze estimation with rotation consistency. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4207–4216. [Google Scholar]
- Sun, Y.; Zeng, J.; Shan, S. Gaze estimation with semi-supervised eye landmark detection as an auxiliary task. Pattern Recognit. 2024, 146, 109980. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, Y.; Wang, H.; Liu, Z.; Cai, S.; Zheng, Z.; Zhou, Y.; Zhang, X. An eye tracker based on webcam and its preliminary application evaluation in Chinese reading tests. Biomed. Signal Process. Control. 2022, 74, 103521. [Google Scholar] [CrossRef]
- Jiang, H.; Hou, Y.; Miao, H.; Ye, H.; Gao, M.; Li, X.; Jin, R.; Liu, J. Eye tracking based deep learning analysis for the early detection of diabetic retinopathy: A pilot study. Biomed. Signal Process. Control. 2023, 84, 104830. [Google Scholar] [CrossRef]
- Wang, S.; Ouyang, X.; Liu, T.; Wang, Q.; Shen, D. Follow my eye: Using gaze to supervise computer-aided diagnosis. IEEE Trans. Med. Imaging 2022, 41, 1688–1698. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






