

Whole Slide Image Understanding in Pathology: What Is the Salient Scale of Analysis?



Abstract
1. Introduction
2. Related Work
2.1. Introduction to Digital Pathology
2.2. Analysis of Whole Slide Images
Problems with Computational Analysis of Whole Slide Images
2.3. Patch-Based Whole Slide Image Analysis
- Pre-processing: Before the data is fed into a model, pre-processing must be applied first. For patch-based WSI analysis, there are four main steps for pre-processing:
- (a)
- Tissue segmentation detects unwanted areas of WSIs, such as any background or blurry areas. These areas are irrelevant in the analysis of the tissue and are usually large regions so take up a significant amount of computational power to process [10].
- (b)
- Colour normalisation alters the distribution of colour values in an image to standardise the range of colour used. In the case of WSIs, this ensures that only relevant colour differences appear between slides. This is essential in the pre-processing of WSIs as it minimises the stain variation between images which can lead to bias in the training data and affect the results [7,19].
- (c)
- Patch extraction involves taking square patches, often 256 × 256 pixels in size, from the WSI for patch-level analysis [5,6,7]. This step of pre-processing has many variables that can be optimised; patch size, magnification/resolution level, sampling method, and whether patches are tiled or overlapping. This is done due to the large size of WSIs and the limits of computational power to deal with images of this size.
- (d)
- Data augmentation is the transformation of training data to new training data. This prevents overfitting and can be used to deal with severe class imbalance.
- Architecture: Commonly, convolutional neural networks (CNNs) are used for the analysis of WSIs. Due to the insufficiency of training data, these models are often weakly supervised. A form of weakly supervised learning that can be used is multiple-instance learning (MIL). This is suitable for data where a class label is assigned to many instances, for example a slide label assigned to patches of that slide [13]. Originally, this algorithm would apply max pooling to the instances, meaning that if disease is predicted to be in one patch, the whole slide is predicted to be in the disease class [13].
- Classification: For the analysis of WSIs, there are two classifications, patch-level and slide-level classification [7]. Predictions for patches are aggregated to produce slide-level classifications. Heatmaps are often used to display the distribution of results for the patches in a slide which often correlates with a pathologist’s annotation of the slide.
2.3.1. Techniques Used in Related Work
2.3.2. Comparison of Patch Sizes
2.4. Relevant Concepts and Technology
- The hardware and software platform the system was trained and tested on.
- The source of the data and how it can be accessed.
- How the data was split into train, validation, and testing sets.
- How or if the slides were normalised.
- How the background and any artefacts were removed from the slides.
- How patches were extracted from the image and any data augmentation that was applied.
- How the patches were labelled.
- How the patch classifier was trained, including technique, architecture, and hyper-parameters.
- How the slide classifier was trained, including pre-processing, technique, architecture, and hyper-parameters.
- How lesion detection was performed.
- How the patient classifier was trained, including, pre-processing, technique, architecture, and hyper-parameters.
- All metrics that are relevant to all the tasks.
3. Proposed Methodology
3.1. Camelyon16 Winning Paper
3.2. GoogLeNet
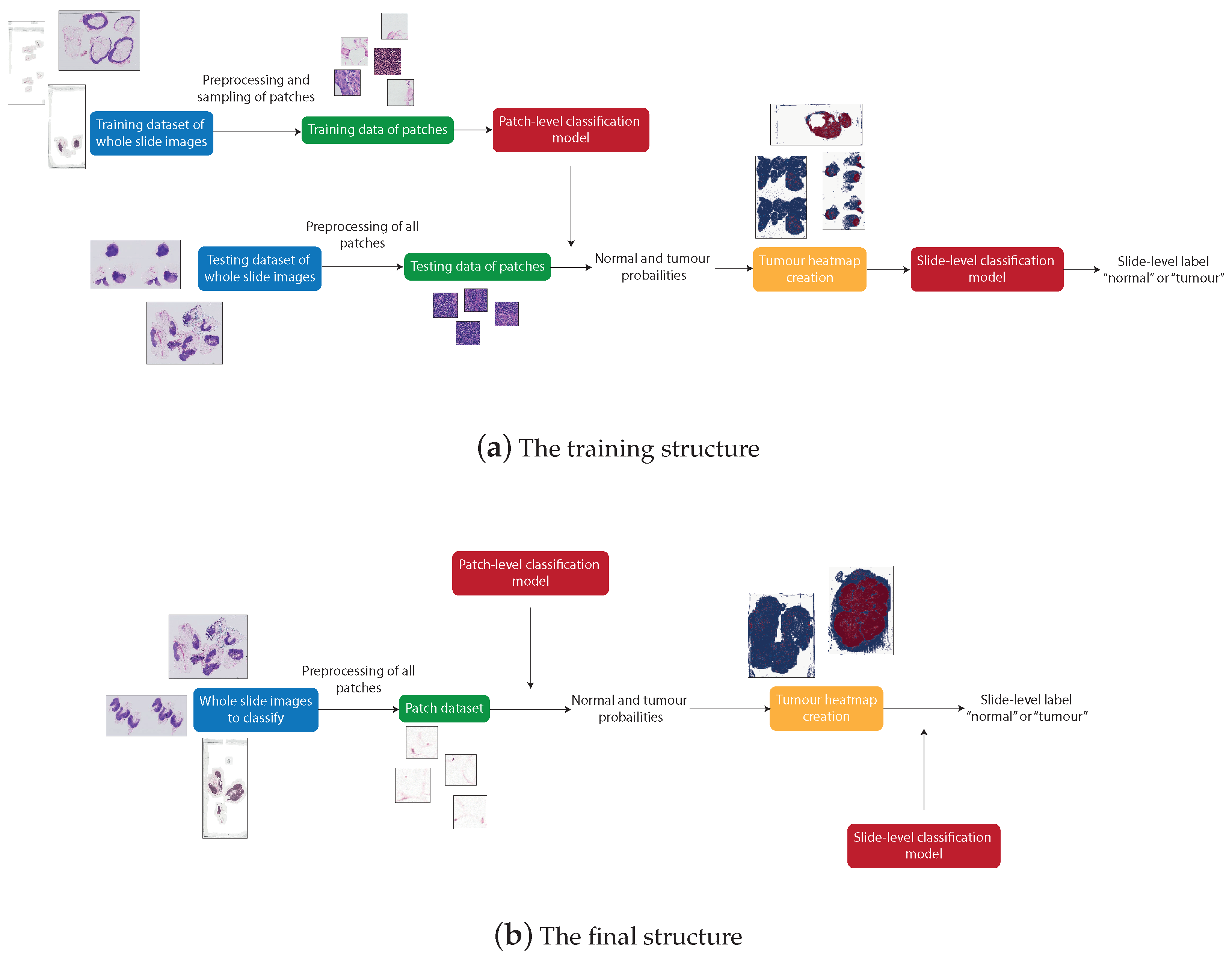
3.3. System Structure
3.4. Camelyon16 Dataset
3.5. OpenSlide
3.6. Pre-Processing
3.6.1. Background Removal
3.6.2. Random Sampling Method
3.6.3. Informed Sampling Method
3.7. Patch-Level Classification
3.7.1. Testing
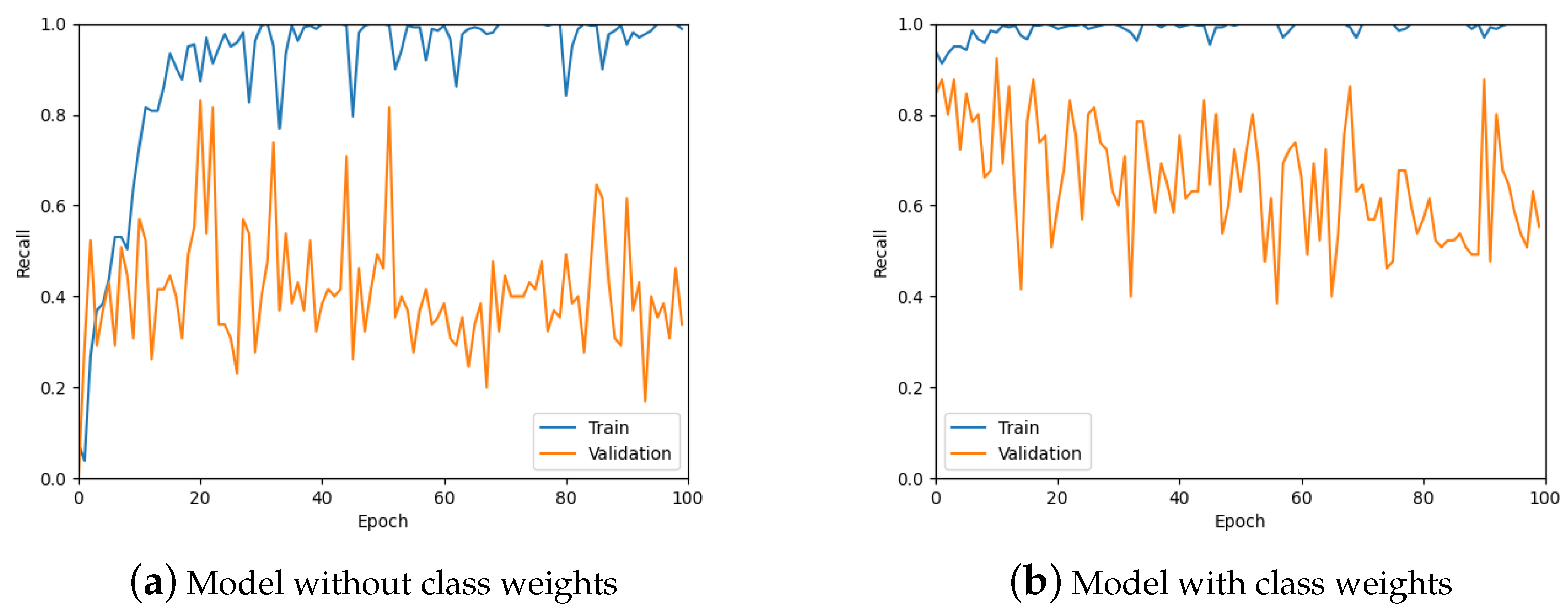
3.7.2. Hyper-Parameter Tuning
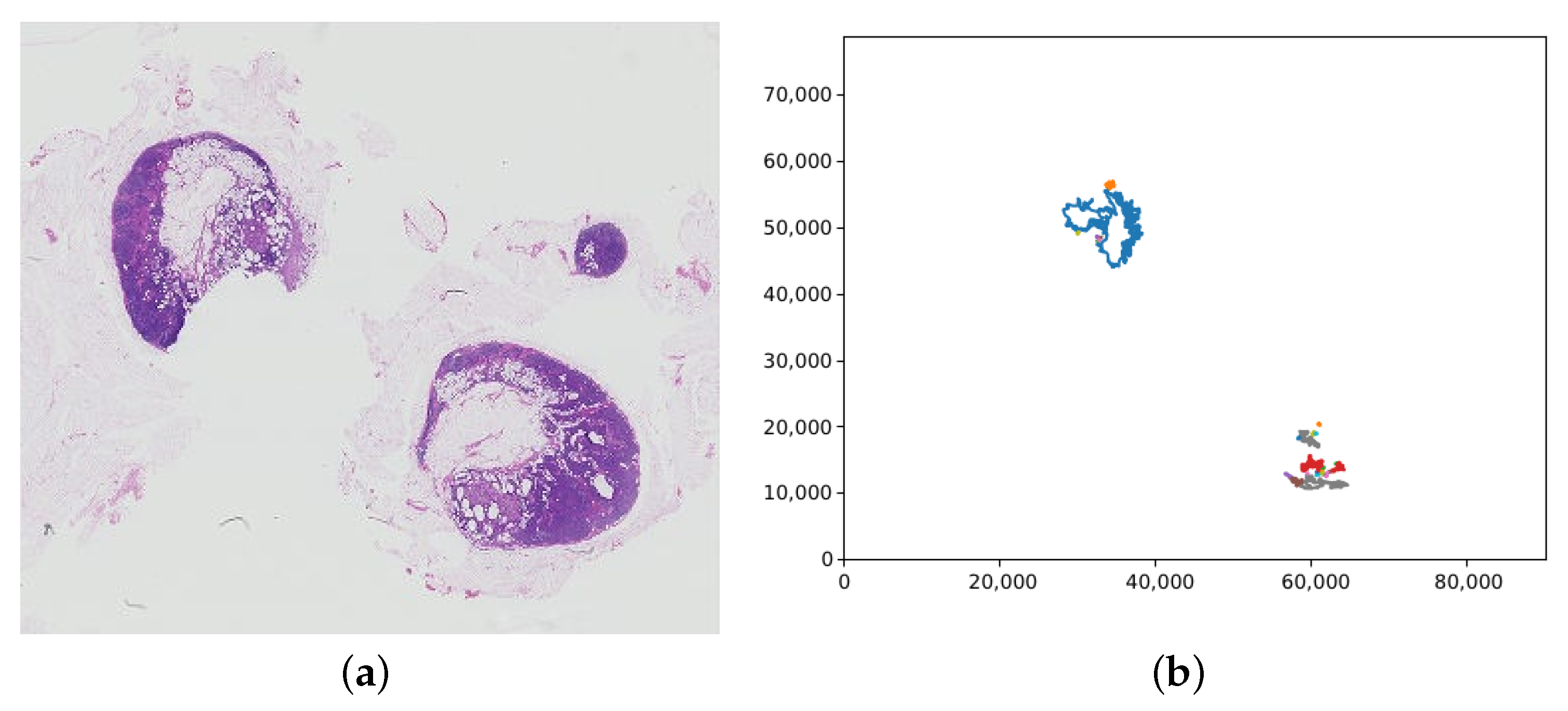
3.8. Production of Tumour Probability Map
Testing
3.9. Slide-Level Classification
3.9.1. Feature Extraction
3.9.2. Testing
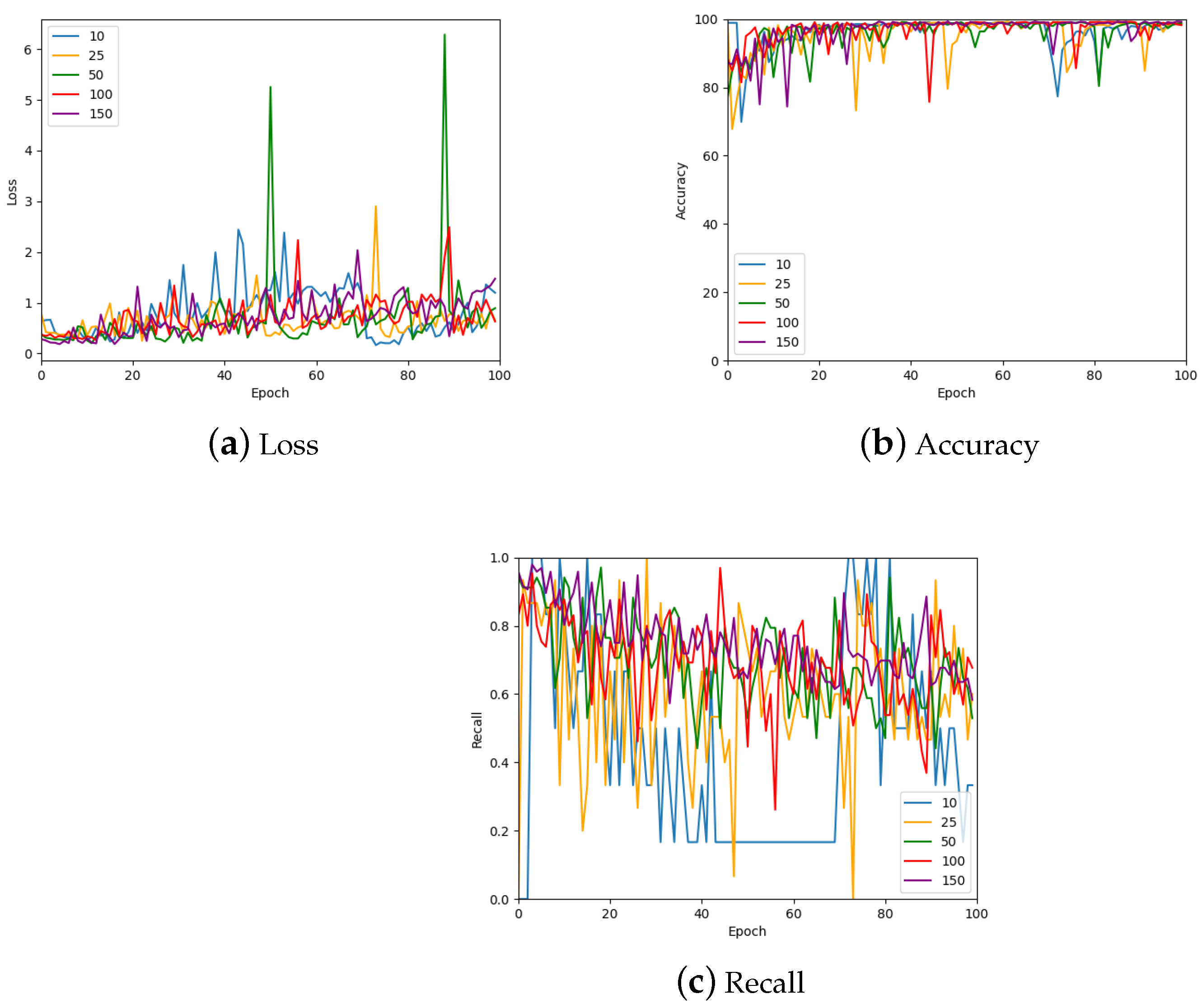
3.10. Testing the Effects of Patch Size
3.11. Downsampling Analysis Method
Testing
3.12. Metrics
4. Results and Evaluation
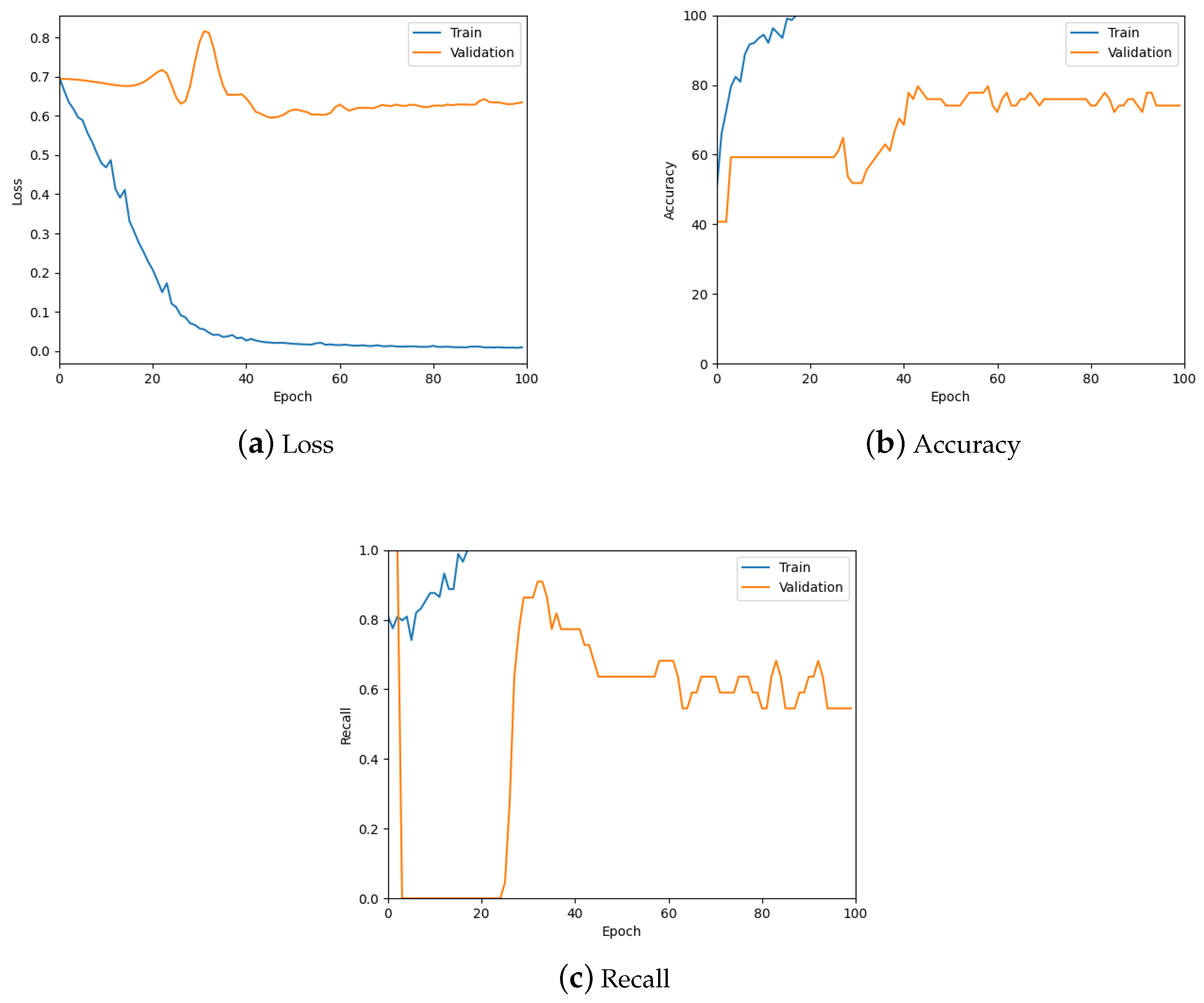
4.1. Results of the Effect of Patch Size
4.2. Comparison of Methods
4.3. Related Work
4.4. Conclusions
4.5. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feng, R.; Liu, X.; Chen, J.; Chen, D.Z.; Gao, H.; Wu, J. A deep learning approach for colonoscopy pathology WSI analysis: Accurate segmentation and classification. IEEE J. Biomed. Health Inform. 2020, 25, 3700–3708. [Google Scholar] [CrossRef]
- Dimitriou, N.; Arandjelović, O. Magnifying networks for images with billions of pixels. arXiv 2021, arXiv:2112.06121. [Google Scholar]
- Hou, L.; Samaras, D.; Kurc, T.M.; Gao, Y.; Davis, J.E.; Saltz, J.H. Patch-based convolutional neural network for whole slide tissue image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2424–2433. [Google Scholar]
- Lomacenkova, A.; Arandjelović, O. Whole slide pathology image patch based deep classification: An investigation of the effects of the latent autoencoder representation and the loss function form. In Proceedings of the IEEE EMBS International Conference on Biomedical and Health Informatics, Athens, Greece, 27–30 July 2021; pp. 1–4. [Google Scholar]
- Dimitriou, N.; Arandjelović, O.; Caie, P.D. Deep learning for whole slide image analysis: An overview. Front. Med. 2019, 6, 264. [Google Scholar] [CrossRef]
- Komura, D.; Ishikawa, S. Machine learning methods for histopathological image analysis. Comput. Struct. Biotechnol. J. 2018, 16, 34–42. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, J.P.M.; Rodriguez, R.; Silva, V.W.K.; Kitamura, F.C.; Corradi, G.C.A.; de Marchi, A.C.B.; Rieder, R. Artificial intelligence as a tool for diagnosis in digital pathology whole slide images: A systematic review. J. Pathol. Inform. 2022, 13, 100138. [Google Scholar] [CrossRef]
- Jamaluddin, M.F.; Fauzi, M.F.A.; Abas, F.S. Tumor detection and whole slide classification of H&E lymph node images using convolutional neural network. In Proceedings of the IEEE International Conference on Signal and Image Processing Applications, Kuching, Malaysia, 12–14 September 2017; pp. 90–95. [Google Scholar]
- Pantanowitz, L.; Sharma, A.; Carter, A.B.; Kurc, T.; Sussman, A.; Saltz, J. Twenty years of digital pathology: An overview of the road travelled, what is on the horizon, and the emergence of vendor-neutral archives. J. Pathol. Inform. 2018, 9, 40. [Google Scholar] [CrossRef] [PubMed]
- Fell, C.; Mohammadi, M.; Morrison, D.; Arandjelović, O.; Caie, P.; Harris-Birtill, D. Reproducibility of deep learning in digital pathology whole slide image analysis. PLoS Digit. Health 2022, 1, 21. [Google Scholar] [CrossRef]
- Bejnordi, B.E.; Veta, M.; Van Diest, P.J.; Van Ginneken, B.; Karssemeijer, N.; Litjens, G.; Van Der Laak, J.A.; Hermsen, M.; Manson, Q.F.; Balkenhol, M.; et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. JAMA 2017, 318, 2199–2210. [Google Scholar] [CrossRef]
- Caie, P.D.; Dimitriou, N.; Arandjelović, O. Precision medicine in digital pathology via image analysis and machine learning. In Artificial Intelligence and Deep Learning in Pathology; Elsevier: Amsterdam, The Netherlands, 2021; pp. 149–173. [Google Scholar]
- Mohammadi, M.; Cooper, J.; Arandjelović, O.; Fell, C.; Morrison, D.; Syed, S.; Konanahalli, P.; Bell, S.; Bryson, G.; Harrison, D.J.; et al. Weakly supervised learning and interpretability for endometrial whole slide image diagnosis. Exp. Biol. Med. 2022, 247, 2025–2037. [Google Scholar] [CrossRef] [PubMed]
- Janowczyk, A.; Madabhushi, A. Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases. J. Pathol. Inform. 2016, 7, 29. [Google Scholar] [CrossRef] [PubMed]
- Deng, S.; Zhang, X.; Yan, W.; Chang, E.I.C.; Fan, Y.; Lai, M.; Xu, Y. Deep learning in digital pathology image analysis: A survey. Front. Med. 2020, 14, 470–487. [Google Scholar] [CrossRef]
- Fell, C.; Mohammadi, M.; Morrison, D.; Arandjelović, O.; Syed, S.; Konanahalli, P.; Bell, S.; Bryson, G.; Harrison, D.J.; Harris-Birtill, D. Detection of malignancy in whole slide images of endometrial cancer biopsies using artificial intelligence. PLoS ONE 2023, 18, 28. [Google Scholar] [CrossRef]
- Zhang, X.; Ba, W.; Zhao, X.; Wang, C.; Li, Q.; Zhang, Y.; Lu, S.; Wang, L.; Wang, S.; Song, Z.; et al. Clinical-grade endometrial cancer detection system via whole-slide images using deep learning. Front. Oncol. 2022, 12, 11. [Google Scholar] [CrossRef]
- Bandi, P.; Geessink, O.; Manson, Q.; Van Dijk, M.; Balkenhol, M.; Hermsen, M.; Bejnordi, B.E.; Lee, B.; Paeng, K.; Zhong, A.; et al. From detection of individual metastases to classification of lymph node status at the patient level: The CAMELYON17 challenge. IEEE Trans. Med. Imaging 2019, 38, 550–560. [Google Scholar] [CrossRef]
- Yue, X.; Dimitriou, N.; Arandjelović, O. Colorectal cancer outcome prediction from H&E whole slide images using machine learning and automatically inferred phenotype profiles. In Proceedings of the International Conference on Bioinformatics and Computational Biology, Honolulu, HI, USA, 18–20 March 2019; pp. 139–149. [Google Scholar]
- Kumar, N.; Sharma, M.; Singh, V.P.; Madan, C.; Mehandia, S. An empirical study of handcrafted and dense feature extraction techniques for lung and colon cancer classification from histopathological images. Biomed. Signal Process. Control 2022, 75, 103596. [Google Scholar] [CrossRef]
- Kumaraswamy, E.; Kumar, S.; Sharma, M. An Invasive Ductal Carcinomas Breast Cancer Grade Classification Using an Ensemble of Convolutional Neural Networks. Diagnostics 2023, 13, 1977. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Chen, H.; Gan, C.; Lin, H.; Dou, Q.; Huang, Q.; Cai, M.; Heng, P.A. Weakly supervised learning for whole slide lung cancer image classification. In Proceedings of the Medical Imaging with Deep Learning, Montreal, QC, Canada, 6–8 July 2018. [Google Scholar]
- Khened, M.; Kori, A.; Rajkumar, H.; Krishnamurthi, G.; Srinivasan, B. A generalized deep learning framework for whole-slide image segmentation and analysis. Sci. Rep. 2021, 11, 14. [Google Scholar] [CrossRef] [PubMed]
- Nazki, H.; Arandjelovic, O.; Um, I.H.; Harrison, D. MultiPathGAN: Structure preserving stain normalization using unsupervised multi-domain adversarial network with perception loss. In Proceedings of the 38th ACM/SIGAPP Symposium on Applied Computing, Tallinn, Estonia, 27–31 March 2023; pp. 1197–1204. [Google Scholar]
- Kong, B.; Wang, X.; Li, Z.; Song, Q.; Zhang, S. Cancer metastasis detection via spatially structured deep network. In Proceedings of the Information Processing in Medical Imaging: 25th International Conference, Boone, NC, USA, 25–30 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 236–248. [Google Scholar]
- Wang, D.; Khosla, A.; Gargeya, R.; Irshad, H.; Beck, A.H. Deep learning for identifying metastatic breast cancer. arXiv 2016, arXiv:1606.05718. [Google Scholar]
- Cruz-Roa, A.; Gilmore, H.; Basavanhally, A.; Feldman, M.; Ganesan, S.; Shih, N.N.; Tomaszewski, J.; González, F.A.; Madabhushi, A. Accurate and reproducible invasive breast cancer detection in whole-slide images: A Deep Learning approach for quantifying tumor extent. Sci. Rep. 2017, 7, 14. [Google Scholar] [CrossRef]
- Ruan, J.; Zhu, Z.; Wu, C.; Ye, G.; Zhou, J.; Yue, J. A fast and effective detection framework for whole-slide histopathology image analysis. PLoS ONE 2021, 16, 22. [Google Scholar] [CrossRef]
- Ehteshami, B.; Geessink, O.; Hermsen, M.; Litjens, G.; van der Laak, J.; Manson, Q.; Veta, M.; Stathonikos, N. CAMELYON16—Grand Challenge. Available online: https://camelyon16.grand-challenge.org/ (accessed on 8 February 2024).
- Wölflein, G.; Ferber, D.; Meneghetti, A.R.; El Nahhas, O.S.; Truhn, D.; Carrero, Z.I.; Harrison, D.J.; Arandjelović, O.; Kather, J.N. A Good Feature Extractor Is All You Need for Weakly Supervised Learning in Histopathology. arXiv 2023, arXiv:2311.11772. [Google Scholar]
- Fu, H.; Mi, W.; Pan, B.; Guo, Y.; Li, J.; Xu, R.; Zheng, J.; Zou, C.; Zhang, T.; Liang, Z.; et al. Automatic pancreatic ductal adenocarcinoma detection in whole slide images using deep convolutional neural networks. Front. Oncol. 2021, 11, 665929. [Google Scholar] [CrossRef] [PubMed]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual | |||
|---|---|---|---|
| Positive | Negative | ||
| Predicted | Positive | 201 | 0 |
| Negative | 163 | 7798 | |
| Epoch | |||||
|---|---|---|---|---|---|
| 25 | 50 | 75 | 100 | ||
| Train | Accuracy (%) | 98.72/98.24 | 99.34/99.24 | 99.23/98.82 | 99.44/99.81 |
| Recall | 0.99/0.99 | 1.0/0.99 | 1.0/0.99 | 1.0/1.0 | |
| Loss | 0.04/0.04 | 0.01/0.02 | 0.01/0.02 | 0.01/0.01 | |
| Validation | Accuracy (%) | 90.03/94.94 | 99.03/98.72 | 99.03/98.72 | 98.83/98.93 |
| Recall | 0.80/0.73 | 0.63/0.69 | 0.48/0.54 | 0.55/0.56 | |
| Loss | 0.67/0.67 | 0.83/0.67 | 1.37/1.13 | 0.95/1.12 | |
| Epoch | |||||
|---|---|---|---|---|---|
| Learning Rate | 25 | 50 | 75 | 100 | |
| Accuracy (%) | 98.67/98.67 | 99.11/99.11 | 99.20/99.20 | 99.20/99.20 | |
| Recall | 0.18/0.30 | 0.47/0.41 | 0.37/0.43 | 0.33/0.31 | |
| Loss | 0.06/0.05 | 0.05/0.05 | 0.06/0.05 | 0.09/0.08 | |
| Accuracy (%) | 99.11/99.11 | 99.20/99.20 | 99.38/99.28 | 99.11/99.11 | |
| Recall | 0.31/0.35 | 0.49/0.47 | 0.43/0.41 | 0.32/0.28 | |
| Loss | 0.08/0.07 | 0.06/0.06 | 0.07/0.07 | 0.09/0.11 | |
| 0.001 | Accuracy (%) | 98.32/98.67 | 99.56/99.56 | 99.38/99.38 | 99.38/99.38 |
| Recall | 0.77/0.61 | 0.33/0.40 | 0.51/0.49 | 0.42/0.42 | |
| Loss | 0.07/0.06 | 0.08/0.07 | 0.07/0.07 | 0.13/0.13 | |
| 0.01 | Accuracy (%) | 99.38/99.38 | 98.94/98.58 | 99.47/99.47 | 99.38/99.38 |
| Recall | 0.52/0.39 | 0.43/0.64 | 0.23/0.43 | 0.23/0.40 | |
| Loss | 0.06/0.07 | 0.04/0.05 | 0.12/0.08 | 0.10/0.09 | |
| 0.1 | Accuracy (%) | 99.03/99.03 | 99.20/99.20 | 99.03/99.03 | 99.03/99.03 |
| Recall | 0.00/0.00 | 0.32/0.30 | 0.00/0.00 | 0.00/0.00 | |
| Loss | 0.07/0.05 | 0.04/0.04 | 0.05/0.04 | 0.04/0.04 | |
| Epoch | |||||
|---|---|---|---|---|---|
| No. Patches | 25 | 50 | 75 | 100 | |
| 10 | Accuracy (%) | 98.23/98.32 | 99.03/99.03 | 94.06/94.62 | 99.03/99.03 |
| Recall | 0.33/0.5 | 0.17/0.17 | 0.84/0.89 | 0.33/0.27 | |
| Loss | 0.76/0.48 | 1.26/1.38 | 0.22/0.22 | 1.27/1.28 | |
| 25 | Accuracy (%) | 97.96/98.32 | 94.42/94.83 | 88.74/88.74 | 98.85/98.96 |
| Recall | 0.51/0.51 | 0.73/0.73 | 0.81/0.85 | 0.47/0.60 | |
| Loss | 0.66/0.69 | 0.36/0.40 | 0.37/0.41 | 0.85/0.67 | |
| 50 | Accuracy (%) | 92.11/95.83 | 99.03/98.97 | 98.85/99.14 | 98.67/98.75 |
| Recall | 0.88/0.78 | 0.53/0.59 | 0.64/0.64 | 0.62/0.60 | |
| Loss | 0.32/0.39 | 5.26/2.22 | 0.70/0.72 | 0.84/0.80 | |
| 100 | Accuracy (%) | 96.19/97.96 | 99.03/98.29 | 98.85/94.71 | 98.49/98.49 |
| Recall | 0.77/0.64 | 0.45/0.64 | 0.62/0.70 | 0.71/0.64 | |
| Loss | 0.38/0.70 | 1.17/0.84 | 1.07/0.95 | 0.84/0.85 | |
| 150 | Accuracy (%) | 98.67/94.42 | 99.03/99.16 | 98.85/99.14 | 99.56/99.26 |
| Recall | 0.81/0.83 | 0.65/0.68 | 0.70/0.71 | 0.64/0.62 | |
| Loss | 0.57/0.63 | 0.92/0.98 | 0.89/0.88 | 1.37/1.39 | |
| Epoch | |||||
|---|---|---|---|---|---|
| 25 | 50 | 75 | 100 | ||
| Train | Accuracy (%) | 100.00/100.00 | 100.00/100.00 | 100.00/100.00 | 100.00/100.00 |
| Recall | 1.0/1.0 | 1.0/1.0 | 1.0/1.0 | 1.0/1.0 | |
| Loss | 0.11/0.11 | 0.02/0.02 | 0.01/0.01 | 0.01/0.01 | |
| Validation | Accuracy (%) | 59.35/60.00 | 74.26/74.26 | 76.04/76.04 | 74.26/74.26 |
| Recall | 0.04/0.13 | 0.64/0.64 | 0.64/0.62 | 0.55/0.55 | |
| Loss | 0.65/0.65 | 0.62/0.62 | 0.63/0.63 | 0.63/0.63 | |
| Patch Size (px) | Accuracy (%) | Recall | AUC |
|---|---|---|---|
| 256 | 73 | 0.60 | 0.71 |
| 384 | 54 | 0.30 | 0.49 |
| 512 | 69 | 0.50 | 0.66 |
| 786 | 62 | 0.60 | 0.61 |
| Patch Size (px) | Accuracy (%) | Recall | AUC |
|---|---|---|---|
| 256 | 81 | 0.60 | 0.79 |
| 512 | 65 | 0.30 | 0.59 |
| 1024 | 58 | 0.70 | 0.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jenkinson, E.; Arandjelović, O. Whole Slide Image Understanding in Pathology: What Is the Salient Scale of Analysis? BioMedInformatics 2024, 4, 489-518. https://doi.org/10.3390/biomedinformatics4010028
Jenkinson E, Arandjelović O. Whole Slide Image Understanding in Pathology: What Is the Salient Scale of Analysis? BioMedInformatics. 2024; 4(1):489-518. https://doi.org/10.3390/biomedinformatics4010028
Chicago/Turabian StyleJenkinson, Eleanor, and Ognjen Arandjelović. 2024. "Whole Slide Image Understanding in Pathology: What Is the Salient Scale of Analysis?" BioMedInformatics 4, no. 1: 489-518. https://doi.org/10.3390/biomedinformatics4010028
APA StyleJenkinson, E., & Arandjelović, O. (2024). Whole Slide Image Understanding in Pathology: What Is the Salient Scale of Analysis? BioMedInformatics, 4(1), 489-518. https://doi.org/10.3390/biomedinformatics4010028