Abstract
(1) Background: Among lung diseases, idiopathic pulmonary fibrosis (IPF) appears to be the most common type and causes scarring (fibrosis) of the lungs. IPF disease patients are recommended to undergo lung transplants, or they may witness progressive and irreversible lung damage that will subsequently lead to death. In cases of irreversible damage, it becomes important to predict the patient’s mortality status. Traditional healthcare does not provide sophisticated tools for such predictions. Still, because artificial intelligence has effectively shown its capability to manage crucial healthcare situations, it is possible to predict patients’ mortality using machine learning techniques. (2) Methods: This research proposed a soft voting ensemble model applied to the top 30 best-fit clinical features to predict mortality risk for patients with idiopathic pulmonary fibrosis. Five machine learning algorithms were used for it, namely random forest (RF), support vector machine (SVM), gradient boosting machine (GBM), XGboost (XGB), and multi-layer perceptron (MLP). (3) Results: A soft voting ensemble method applied with the combined results of the classifiers showed an accuracy of 79.58%, sensitivity of 86%, F1-score of 84%, prediction error of 0.19, and responsiveness of 0.47. (4) Conclusions: Our proposed model will be helpful for physicians to make the right decision and keep track of the disease, thus reducing the mortality risk, improving the overall health condition of patients, and managing patient stratification.
1. Introduction
Idiopathic pulmonary fibrosis (IPF) belongs to the interstitial lung diseases (ILDs) group, a mixed group of parenchymal lung diseases described by fluctuating levels of fibrosis and inflammation [1]. IPF appears to be the most common and aggressive form of ILD, known for its progressive respiratory failure, inevitable deterioration in lung function, and high mortality risk [2]. While there are some causes of IPF in patients, others remain with no identifiable causes [3,4]. Though people in some conditions, such as exposure to pollution, certain medicines, and infection, are likely to develop IPF disease, the exact causes remain unknown to physicians [5,6]. However, many related risk factors may cause someone to probably get infected by IPF disease, and the common symptoms include dry cough and chronic dyspnea on exertion. These risk factors include age, gender, genetics, smoking status, and the presence of acid flux diseases [5,7]. IPF patients usually face difficulties breathing, making them feel more tired; more so, they face involuntary weight loss problems and present aches in joints and muscles. After being diagnosed, IPF patients must undergo some follow-up by a physician; this may not lead to a total treatment but careful monitoring because there is no proven therapy for this disease [8]. Most therapies facilitate patients’ respiration, while some reduce lung deterioration speed. In any case, IPF disease is a serious disease, and patients must learn how to live with it. In the worst cases where the patient’s lungs are severely damaged, a lung transplant is recommended to increase the patient’s lifetime [9]. This alternative is expensive, and patients who can not afford it will be exposed to death. Nowadays, mortality in IPF is high; based on historical data analyzed by [10] it is reported that the average survival time for IPF patients turns around 2–3 years after diagnosis, making this disease a threat to people’s lives. In addition to that, ref. [11] investigated the IPF patient mortality rate and concluded that there are about 64.3 deaths per million in men and 58.4 deaths per million in women. A study by [12] showed that older individuals, sixty years of age and older, are the most vulnerable to this disease. Though much research has been carried out on IPF diseases, it is still a challenge for medical personnel to predict the disease’s outcome because baseline lung function alone is a poor predictor of mortality [13].
The integration of digitalization in the healthcare sector and the applications offered by artificial intelligence (AI) appear to be promising solutions for handling IPF patient follow-up. Bhatt et al. [14] developed an AI-driven federated learning for heart stroke prediction in healthcare 4.0 underlying 5G that can be deployed on wearables for real-time monitoring of heart diseases. Similarly, author [15] developed Eboost, a novel AI innovation for COVID-19 prediction. Also, ref. [16] implemented a convergence approach that combines AI and computer vision technology for monitoring, compliance, and curtailment of communicable diseases in real-time. Additionally, the prediction of diseases associated with the lungs and other respiratory organs is replete in the literature, of which IPF is one.
In the past, several traditional methods have been used to diagnose IPF disease. These methods are generally time-consuming and less effective, with low accuracy. An example is a non-data-driven method proposed by [13,17] based on statistical models such as the regression or Cox proportional hazard models. There have been many other attempts to handle IPF disease, but most have failed to be accurate and effective. AI techniques open new avenues for addressing IPF patients who manage the disease severity level and predict eventual survival. By leveraging AI detection techniques, healthcare providers can identify individuals with IPF more accurately and promptly [18]. AI in IPF diagnostics not only aids in the early detection of IPF but also offers patients more options to manage the disease effectively and maintain a good quality of life [18]. One such AI solution, the Fibresolve system, has demonstrated promising diagnostic performance as an adjunct in predicting the diagnosis of IPF, with a specificity of 87% and superior sensitivity compared to traditional methods [19]. Additionally, the ZCoR-IPF tool utilizes predictive comorbidity signatures from medical encounters to enhance the accuracy of diagnosing IPF, potentially enabling earlier diagnosis and access to appropriate treatments [20]. By identifying subtle characteristics within medical data and analyzing predictive medical history, AI technologies offer a promising avenue for improving the accuracy and efficiency of diagnosing IPF, ultimately leading to better patient outcomes and earlier intervention opportunities [21].
This research aims to apply AI techniques such as machine learning (ML) for forecasting mortality risk in patients with IPF, which will serve as a tool for physicians to make the right decision and keep track of the disease, thus reducing the mortality risk, improving the overall health condition of patients, and managing patient stratification. Unlike the statistically proposed model, ours is an ML-based and data-driven solution; hence, it will be more effective, reliable, and accurate.
The research paper is organized as follows: Section 2 presents related works in line with this research paper. Section 3 discusses the data collection and the methods used in this research. Section 4 contains the results of the proposed method. Section 5 and Section 6 present the discussion and conclusion of this research paper, respectively.
2. Related Work
Over the past years, researchers have investigated IPF patients’ conditions to detect disease exacerbation levels or survival chances. Numerous methods and approaches have been utilized to address these issues. This section reviews some previous related research carried out to manage IPF disease patients.
Evgeni et al. [22] surveyed the application of AI techniques, such as machine learning, in respiratory medicine. The authors demonstrated that, though AI cannot completely replace a physician, the proposed AI models are significant tools for clinical decision-making and improving medical care, reducing human errors and treatment costs. AI has been proven to be a promising solution for healthcare issues. In a systematic review carried out by S. Soffer et al. [23], the previous claim was supported by highlighting the role of AI in managing interstitial lung disease (ILD) analysis using chest computed tomography. The research shows that AI has revolutionized medical image analysis, thus improving patient care for IDL.
Recently, Mäkelä et al. [24] developed an AI model able to quantify fibroblast foci and inflammatory cells using a convolutional neural network (CNN). The study was carried out on 71 patients with IPF, and the proposed model could detect histological features that were difficult to quantify manually, hence providing novel information on the prognostic estimation of the disease. Similarly, Handa, T. et al. [25] proposed an AI-based model for chest computed tomography analysis of IPF, which provides more predictive information using images in addition to gender-age-lung physiology to detect IPF exacerbation levels. In research conducted by Yu et al. [26] on 50 IPF subjects, an ML model was developed with a novel hybrid algorithm derived from quantum particle swarm optimization and random forest (QPSO-RF) able to predict IPF disease progression using computed tomography with an overall accuracy of 82.1% for the obtained classifier. Using CT scans of the lungs of IPF patients, S. Mandal [27] proposed the best-fit machine learning model to predict patients’ lung function in severe conditions. The proposed system can analyze and compare the performance of various ML models and predict the confidence value and the final forced volume capacity measurements for each patient. Ziyuan Wang [28] used a deep learning (DL) approach for auto-detect IPF prediction. The proposed model was developed using a neural network with DensNet and applied to a combination of patients’ CT scan images and clinical features to effectively predict lung function developments and predict whether a patient has IPF disease. The above-mentioned studies utilized medical images, mostly CT images, for their analysis.
Though CT images have been widely used for diagnosis purposes, some researchers have been able to use clinical data for detecting IPF alone. For instance, Sikandar et al. [26] proposed a soft voting ensemble model for early predicting IPF severity in lung disease. Their ensemble model is derived from three base classifiers (GBM, RF, and XGB) and achieved an accuracy of 71% with a precision of 64%, recall of 71%, and F1 scores of 66%. The proposed model supports physicians and patients in assessing the severity of the IPF disease in its early stages to manage the disease evolution in patients effectively. The current research uses the same dataset, emphasizing patient survival prediction, and carries out robust feature engineering and model analysis to improve the model performance and reliability of prediction. Some research on mortality prediction in IPF includes the study carried out by Wu et al. [29]. The authors proposed a prediction risk model called CTPF trained using CT images and physiological feature parameters such as FVC, DLco, SpO2, age, and gender. The model was developed using DL techniques, and the results demonstrated a positive correlation between high-risk patients and their mortality risk. Thillai et al. [30] also predicted mortality in IPF patients using CT scans. The authors aim to automate imaging biomarkers using deep learning for segmentation, achieving more than 97.8% success in all the training sets and demonstrating a strong correlation with forced vital capacity (FVC), a pulmonary function test to assess lung function. The proposed model is a fast tool for CT scan segmentation that can determine accurate prognostic values for the near and long term. Unlike the previous solutions, our proposed approach uses only clinical data to predict the survival of a patient with IPF, considering the average survival time from the dataset. To achieve this, thorough data preprocessing and feature engineering were carried out on the dataset to ascertain data quality and model veracity. Also, considering the sensitivity attached to the prediction outcome by the proposed AI model and its impact on the survivability of IPF patients, a robust performance evaluation was carried out to validate the authenticity of the prediction outcome by the proposed AI model. The nature of our dataset makes our research and the proposed method unique, as described hereafter.
3. Methods and Materials
This section describes the method and material used to carry out this research.
3.1. Data Source and Implementation Environment
The data used to carry out this research study was collected from Korean interstitial lung disease cohort (KICO) patients. Data was collected on 2424 patients, giving significant information about 502 different features of IPF disease, and all the participants consented to participate in this study. The dataset contains complete patient information, such as patient demographic information, previous medical records regarding IPF tests, drug records, survival/death, exacerbation of IPF, pulmonary function information, and many others.
Many approaches have been used to address IPF prediction; from the traditional approach to the AI-based approach, there is a need for data availability and processing. Sikandar et al. [31] used this dataset with different research objectives. The authors explored the severity of the IPF disease in the patients and classified four labels (class 0 to class 3) for IPF patients’ exacerbations. However, in this study, we explore the IPF disease with a new research direction in which the “survival” and “death” of IPF patients are analyzed and investigated based on different clinical features. These features highlight the state of the patient; in case of death, we may know and identify the death reason, which can be either acute exacerbation, pneumonia, trans-infection/sepsis, pulmonary embolism, lung cancer, heart disease, or heart failure. Our dataset has three different class labels, i.e., survival, death, and tracking failed. The “Survival” class describes the IPF patients who escaped from death; the “Death” class denotes patients who died of IPF; and “Tracking Failed” is the patients who have no follow-up record and could not get the final survival or death state. This study predicts the patient’s survival and death condition based on the patient’s clinical features, and we excluded the patient’s records with the “tracking failed” label as it was useless to determine the state of the IPF patient.
All the experiments in building the proposed model were executed on a computer workstation equipped with a Windows 10 operating system, an Intel (R) Core (TM) i7-10700 processor, and 16 GB of RAM. Python 3.8 was used as the programming language under the Jupyter Notebook framework. Specifically, TensorFlow v2.13, Keras 2.13, Scikit-learn libraries, etc., were used for implementation.
3.2. Data Preprocessing
An appropriate data preprocessing of the dataset is required to get optimal output from the AI model. Data preprocessing techniques include missing data treatment, scaling, feature selection, case selection, etc. [32,33]. This section will elaborate on the major steps in preparing the dataset for the AI model.
3.2.1. Feature Selection
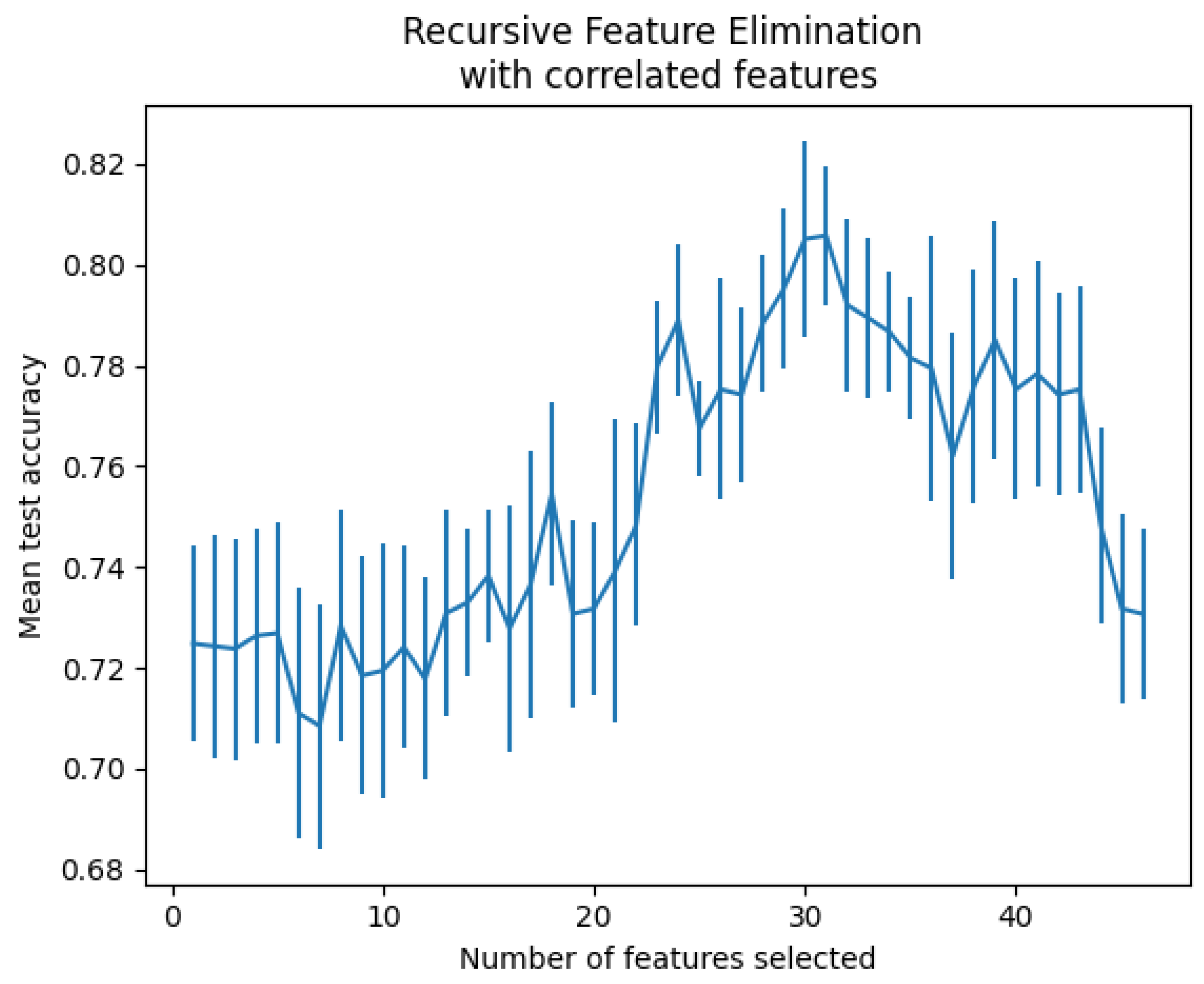
When a dataset contains many feature variables, it is sometimes unnecessary to use them because they do not contribute to the expected prediction. In some cases, they deteriorate the model’s performance. Feature selection helps get the features that best fit the model, leading to good performance. Best practices require working with the minimum set of predictive features to reduce the complexity and computational cost [34,35]. There are several feature selection techniques, among which we experimented with three of them on our dataset, namely feature selection with feature importance techniques [36], recursive feature elimination with cross-validation [37,38], and automated feature selection with Boruta [39]. Recursive feature elimination with cross-validation techniques was shown to be the best suited for our data. This method is commonly used in machine learning because it can select the most relevant feature while avoiding overfitting. A recursive feature elimination object was used with the gradient boosting classifier and a 5-fold validation on the accuracy scoring strategy to optimize the proportion of well-classified samples. The processing resulted in 30 features that were found to be the most optimal, as shown in Figure 1.
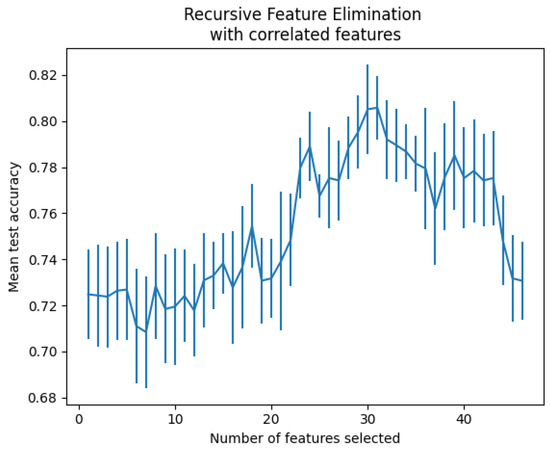
Figure 1.
Number of features vs. cross-validation scores.
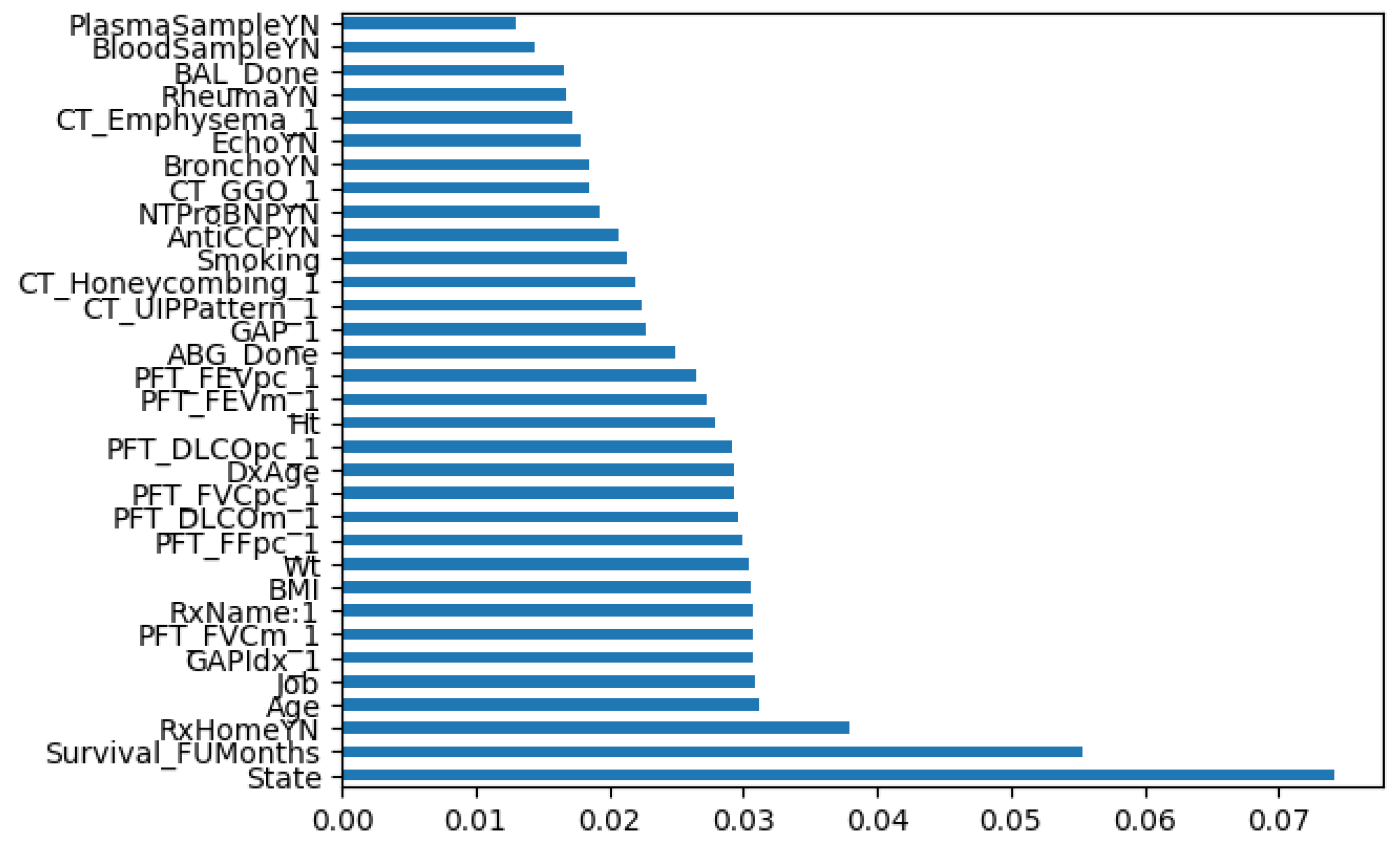
Based on the feature selection results and the interviews with the medical experts, we could consider the 30 best-fitted features from our dataset according to their importance, as shown in Figure 2.
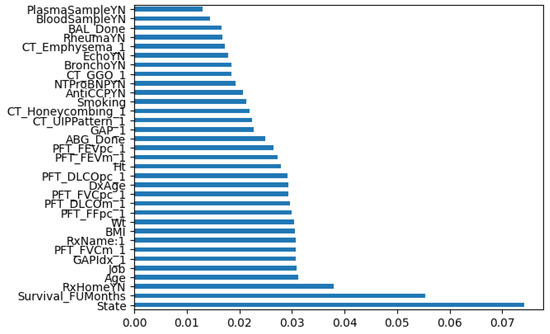
Figure 2.
Feature classification according to their importance.
Table 1 shows a succinct description of the 30 features selected for this experiment.

Table 1.
Selected features and descriptions.
3.2.2. Data Sampling
Data sampling is a statistical analysis technique used to identify patterns and trends in a larger dataset under investigation by selecting, manipulating, and analyzing a representative subset of data points. D bata sampling is also used to handle data imbalances [40,41]. Data imbalance in a dataset refers to a situation where the target class (“survival” in our case) has an unequal distribution of observations [32]. The challenge with these types of datasets is that most machine learning models will ignore the minority class. However, the minority class is significant in determining the model’s performance. To address the imbalance in our dataset, we opted to oversample the minority class. This was done using the Synthetic Minority Oversampling Technique (SMOTE) method, one of the most popular oversampling approaches [41]. SMOTE uses one of the k-nearest neighbors while generating synthetic instances randomly to create a new data sample for the minority classes and has proven to be a reliable method for data balancing [32]. This method improves the learning of the model by reducing bias due to class imbalance [41].
3.3. Proposed Machine-Learning Model
In this study, some ML models were used to predict the survival state (death or survival) of IPF patients. The following state-of-the-art ML classifiers: multi-layer perceptron (MLP), random forest (RF), support vector machine (SVM), gradient boosting machine (GBM), and XGBoost (XGB) were used to accurately determine the survival and death state of a patient suffering from IPF disease. However, the individual classifier appears not to be ideal because of the diversity of the input hyperparameters. Table 2 shows the various hyperparameters considered per classifier with the assigned values to make a robust and efficient model.
Table 2.
Specifications of based classifiers for IPF mortality risk prediction.
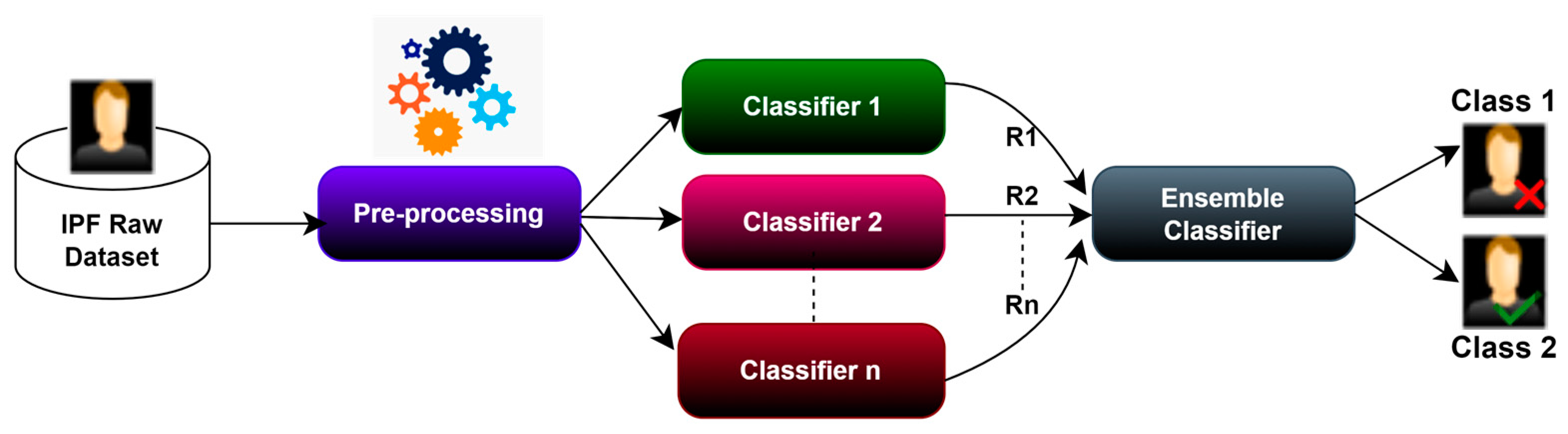
To benefit from multiple classifiers and overcome any overfitting of any single classifier, we opted for a soft voting ensemble method that combines many classifiers to make one most efficient model. The basic architecture of our ensemble classifier is shown in Figure 3. A soft voting ensemble approach uses different machine learning classifiers or different sets of training data to generate a model to predict outcomes [32]. The ensemble model aggregates the predictions from each base classifier and then produces a final prediction of the resulting unseen data. The motivation for using the ensemble model is to reduce the prediction’s generalization error. Using a global approach where the base classifier is diverse and independent reduces the model’s prediction errors. The set classifier has several base classifiers in the model, but it works and functions as a single model. Most practical machine-learning solutions use ensemble modeling techniques.
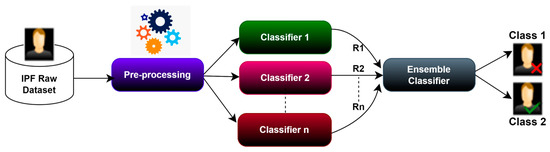
Figure 3.
Basic Architecture of the Proposed Ensemble Classifier with the arrows highlighting the participation of different classifiers in determining the best predictor.
3.4. Performance Evaluation Metrics
The proposed ELIPF model performance is evaluated in terms of model accuracy (A+), sensitivity/recall (R+), average precision (P+), rationale behavior/average F1-score (F1), reliability/error minimization (MSE MCC, K, and ROC-AUC), and response time/latency (Time) as the evaluation metrics. A succinct description of these evaluation metrics is presented in Equations (1)–(8).
Accuracy: The ELIPF model accuracy informs us about the overall accuracy in both “Survived” and “Death” states. Model accuracy is obtained as indicated in Equation (1) and attempts to determine the number of correct overall predictions.
TP: True Positive; TN: True Negative; FN: False Negative; FP: False Negative.
Recall: The recall attempts to estimate the proportion of actual positives that were identified correctly. In the scope of this research work, the recall provides information on the number of samples our model has correctly identified for a specific class. We calculated the recall in each class to determine the average percentage of correct predictions using the below Equation (2).
Precision: On the other hand, precision attempts to estimate the correct proportion of positive identification. In this study, precision was calculated using Equation (3) to determine the confidence of a particular prediction to belong to a specific class.
F1-Score (F1): Moreover, the F1-score helps measure the average of both recall and precision as a single metric. The F1-score is calculated using Equation (4) and helps balance the metric across positive/negative samples, penalizing the score for all the wrongly predicted samples of a particular class.
To validate the reliability and efficiency of the proposed model, we equally evaluated its performance using other quantitative measures specifically designed to assess its performance and efficacy, providing valuable insights into how well the model is performing and where improvements can be made.
Mean Squared Error (MSE): The MSE is commonly used to measure the average squared difference between predicted and actual values, as shown in Equations (5) and (6).
The MSE metric is crucial when assessing the reliability of a model, as it provides valuable insights into the accuracy and generalization ability of the model. The MSE value is inversely proportional to the model’s prediction reliability. A smaller MSE justifies a more reliable model.
Matthews Correlation Coefficient (MCC): MCC considers true positives, true negatives, false positives, and false negatives to evaluate the performance of binary classification models. It provides a balanced measure even when classes are imbalanced, making it a robust metric for model evaluation in various domains. In our case, where we deal with an imbalanced dataset, the MCC has been chosen to confirm the quality of each binary classifier and the results from the accuracy and F1-score because it uses all confusion matrix values and shows the inter-relationship between the items used by the ELIPF model in making its final prediction. The MCC is computed as shown in Equation (7).
Cohen’s Kappa Coefficient (K): K measures items’ inter-rater agreement, particularly in classification tasks. The values of the confusion matrix are used to compute the Kappa coefficient as follows:
Latency/Time (s): Latency, also known as inference time, measures the degree of responsiveness of the ELIPF model in processing input and returning resultant predictions.
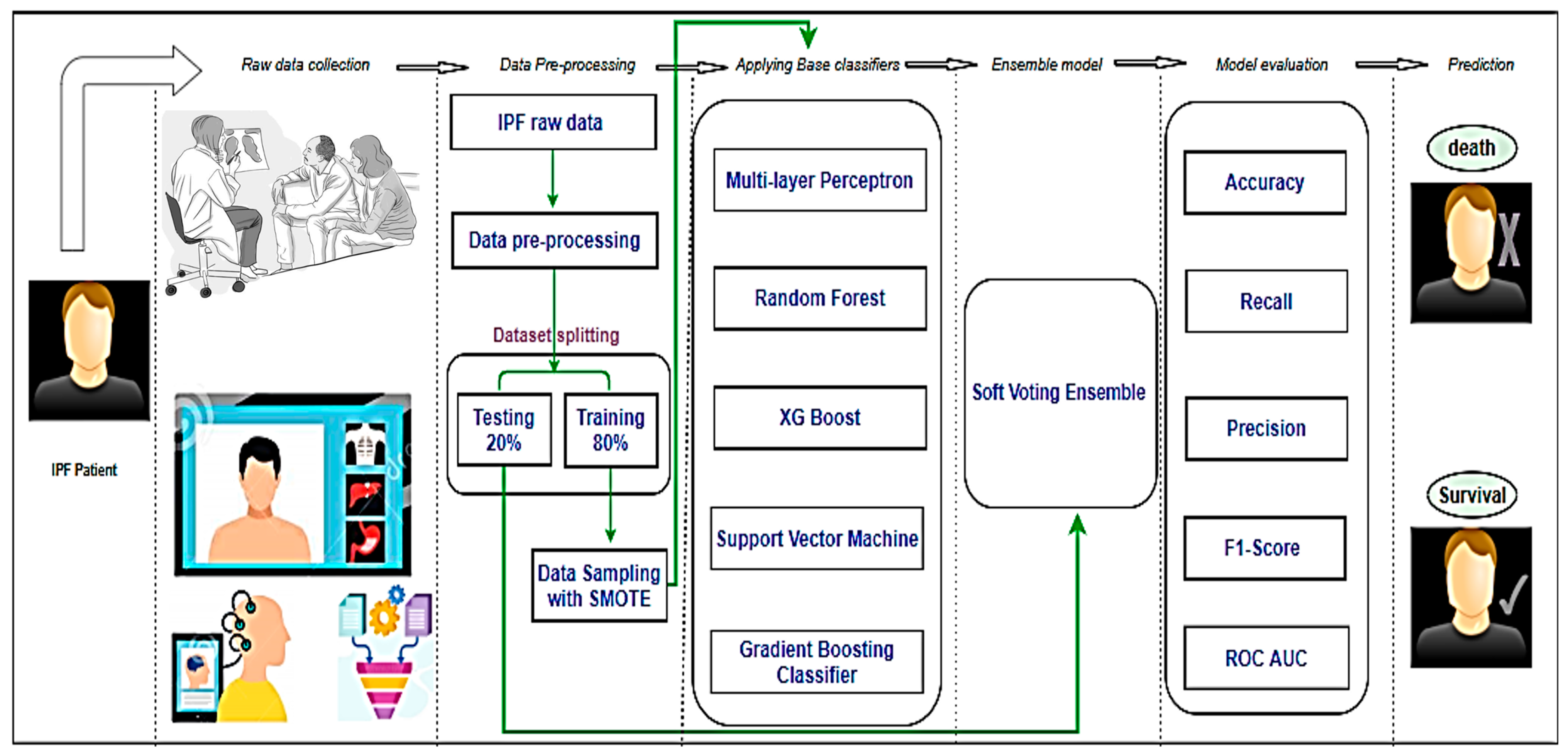
3.5. Process Workflow
The overall process for developing the system to predict the two classes, i.e., “Survived” and “Death” of IPF patients is presented in Figure 4. The process is divided into six major stages, some of which have been deeply explained above. The six stages include data collection, preprocessing, application of base classifiers, the proposed ensemble model, model evaluation, and prediction. Medical experts collected data on IPF patients. This stage resulted in the production of our dataset, during which we carried out some preprocessing tasks such as feature selection and KNN imputation. The prepared data were split into training and testing sets following a ratio of 80:20 based on the Pareto principle. The data was imbalanced, which ultimately created model overfitting. To address the imbalance in the dataset, we applied a data oversampling technique known as SMOTE. Many base classifiers were applied to the training set, among which five classifiers, namely MLP, RF, XG Boost, SVM, and Gradient Boosting, showed optimal results with the most appropriate hyperparameters and were selected to build up an ensemble model. The performance of our proposed ensemble model was evaluated by calculating the accuracy, recall, precision, confusion matrix, ROC, and AUC to predict the best mortality state of a patient and distinguishing the “Survived” and “Death” states of patients suffering from IPF.
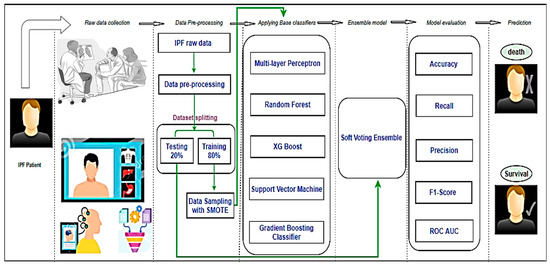
Figure 4.
Complete Process flow of the experiment.
4. Experimental Results
Five machine learning-based classifiers were used to build an ensemble model that could effectively predict the correct survival state of patients suffering from IPF disease. The classifiers were trained with 80% of the data split from the original dataset, on which the SMOTE oversampling technique was used to handle imbalances. The model prediction capability evaluation was done with 20% of the data assigned for testing, and the results are shown in Table 3.
Table 3.
Comparative analysis of classifiers’ performance.
From these results, it can be observed that the proposed ensemble model showed the best performance in terms of classifying the “Survival” and “Death” states of IPF patients, with the SVE having the best prediction outcome across the evaluation metrics with an accuracy of 79%, sensitivity of 86%, and F1-score of 84.2%, respectively. Although the GBM had a better sensitivity (recall) of 87.2% than the SVE (86.3%), across the metrics, the SVE is better than the GBM. Similarly, the XG Boost had a higher precision value of 86.2% but a lower accuracy and F1-score of 74% and 78.6%, respectively, which makes the SVE a better choice for predicting the state of IPF patients.
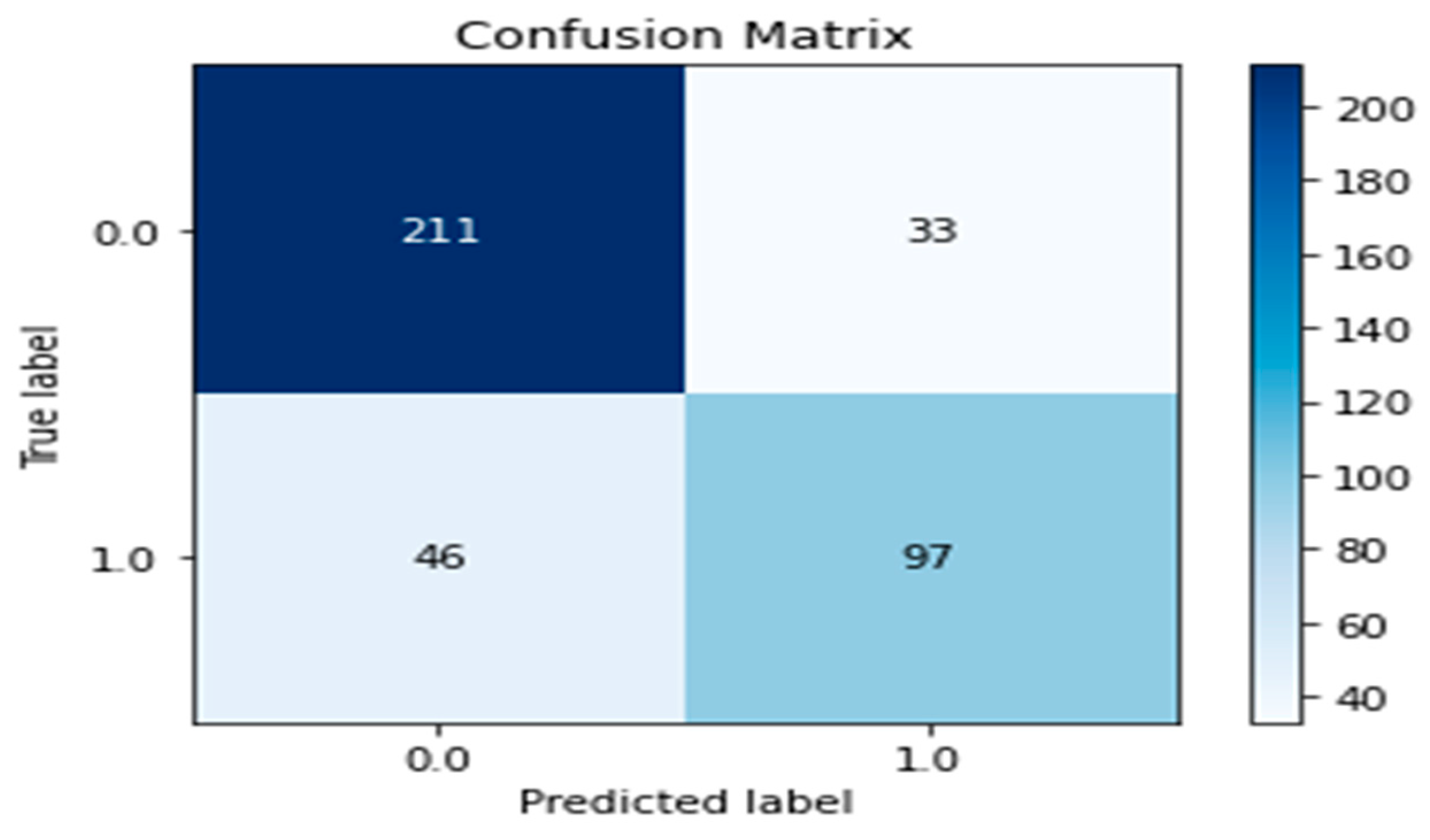
Also, a confusion matrix shows a summary of the model’s prediction results. It evaluates the model’s performance and is presented as a two-dimensional graph. The x-axis represents the actual class labeled 0 and 1, which denotes the survival state of IPF patients, while the y-axis represents the predicted labels. The values at the diagonal express the survival state for each class and are satisfactory for our expected prediction. Figure 5 shows the confusion matrix obtained by our proposed soft voting ensemble model for the classification problem.
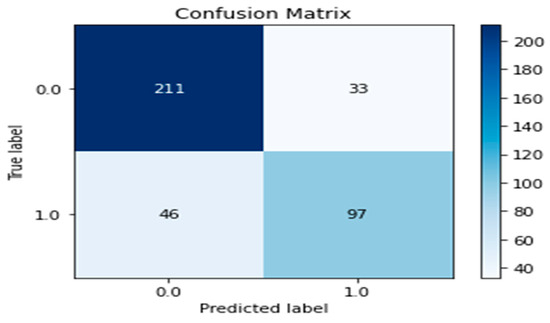
Figure 5.
Confusion matrix of our proposed ensemble model.
The values in Figure 3 show that the proposed ELIPF model experienced a minimal misclassification outcome by predicting 211 labels as actual positives and 97 labels as actual negatives. These results validate the proposed ELIPF model prediction capacity as sufficient for determining the states of IPF patients at any given instance.
Furthermore, the values in Table 4 show the proposed model prediction reliability and efficiency across the selected ML-classifiers.
Table 4.
Classifiers’ Performance Evaluation.
Across the metrics, the GBM had the best inference time of 0.0166 s (with the fastest responsiveness), while the SVM had the least inference time of 2.3360 s. On the other hand, the SVE had 0.4740 responsiveness. This suggests that GBM has a faster prediction time (latency) than the SVE. However, in terms of prediction error minimization and classification generationalization, the SVE is more reliable than the GBM, with an MSE value of 0.1925, an MCC value of 0.555, and a K value of 0.58484. Hence, since a health monitoring system is precision-conscious, the SVE, with a lower latency of 0.4740 s, is considered more reliable and efficient than the GBM, with a poor error minimization of 0.3927 and prediction generalizations of 0.0197 and 0.0170, respectively.
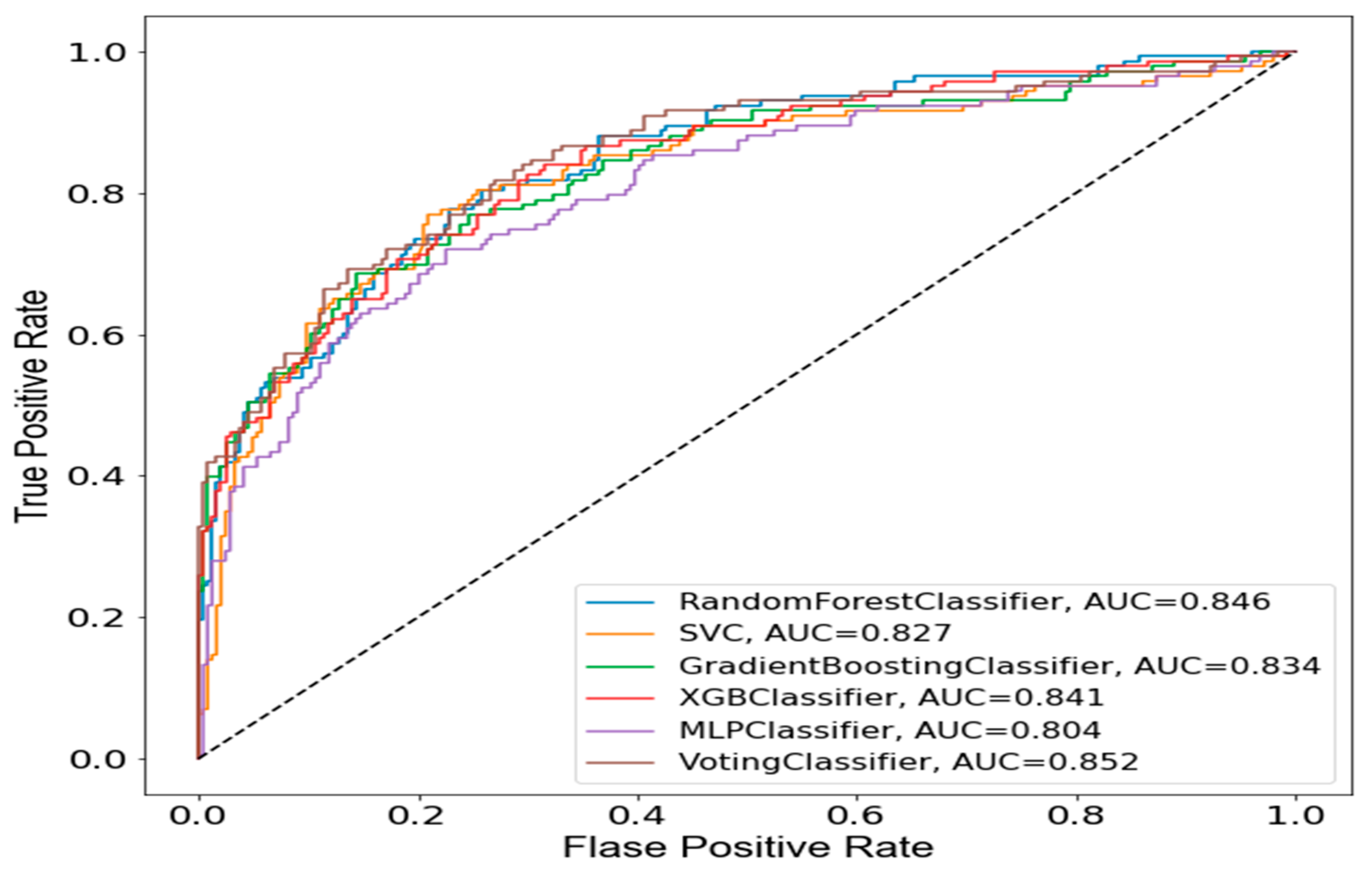
To substantiate the reliability of the SVE model over other ML classifiers that participated in the ensemble learning, the Area Under the Receiver Operating Characteristic Curve (AUC-ROC) of the proposed model is presented in Figure 6.
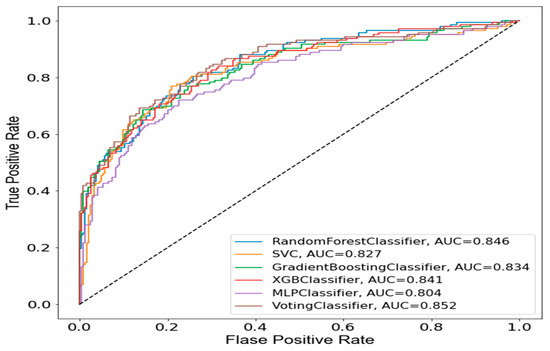
Figure 6.
AUC-ROC of the proposed ensemble model.
The AUC-ROC curve is an evaluation metric used to visualize the performance of a model and validate its reliability in predicting an outcome. The formula for AUC-ROC is given as
where is the integral of the true positive rate (TPR) over the range of 0 to 1, and dx is the differential change in the false positive rate (FPR). The AUC-ROC is a probability curve plotted using true positive and false positive rates to show model performance for every possible threshold. From Figure 4, it can be observed that the SVE model shows proof of best generalizability (0.852) in terms of prediction at several thresholds.
5. Discussion
In this study, we developed a framework for predicting the “Survival” and “Death” states of IPF patients using clinical data instead of CT scan images like other researchers [23,42,43]. Using the data collected from the Korea Interstitial Lung Disease Cohort (KICO), Haeundae Paik Hospital, Busan, South Korea, we applied numerous state-of-the-art machine learning algorithms for binary classification of IPF patients regarding their survival state. Some machine learning algorithms applied to our dataset perform better than others. We selected the five best models, multi-layer perceptron, random forest, extra gradient boosting, support vector machine, and gradient boosting, to develop an ensemble model that performed better than every single classifier, as shown in Table 3. For this research’s cost, we applied soft and hard voting ensembles. The hard voting classifier classifies input data based on the mode of all the predictions made by the various classifiers, and the majority voting is considered the outcome.
In contrast, the soft voting classifier classifies input data based on the probability of all the predictions made by various classifiers. We chose soft voting over the hard voting classifier because of the good performance shown by the soft voting approach. The proposed model was evaluated using specific performance metrics, as shown in Table 3. The results confirm that the proposed soft-voting ensemble remains the best model to address IPF patients’ survival state using our dataset in terms of model prediction efficiency, reliability, and cost-effectiveness. Hence, an efficient and reliable early warning tool for forecasting mortality risk in patients with idiopathic pulmonary fibrosis (IPF) disease with clinical features using machine learning is possible. Compared to other related research, it can be noticed that this study is focused on predicting the survival or death of a patient, while others conduct survival analysis. The dataset used in this experiment is solely made of clinical data and is not accompanied by CT images. This fact has driven this research in a unique direction. However, it can be noticed that there is a limitation to this research work; it can be seen that the overall performance of our model could be increased if we had more data. Model training and testing required tremendous data for a super-accurate prediction, and we did not have that much data in our dataset. We intend to collect more data to retrain our model for better performance and also avoid missing values during the data collection process to get optimal results in the near future.
6. Conclusions
In this study, we proposed a machine learning model that helps detect the “Survival” and “Death” states of IPF patients using clinical features. The proposed machine learning model automates a binary classification of two states. For this purpose, we selected the top 30 best features that best fit our model for the available 2424 patients ‘data through the recursive feature elimination technique. Preprocessing techniques were applied to the dataset. First, we filled in missing values using K-nearest neighbors’ imputation. Secondly, data imbalance was handled using the SMOTE oversampling technique. Several base classifiers were applied to the preprocessed data, and five were elected to develop a soft-voting ensemble model that showed the best performance. The proposed soft voting ensemble model showed an accuracy of 79.58%, a recall of 86%, and an F-measure score of 84%, appearing to outperform the state-of-the-art base classifiers. Consequently, it generates optimal predictions and classifications. Our proposed model will be helpful for physicians in making the right decisions and keeping track of the disease, thus reducing mortality risk, improving the overall health condition of patients, and managing patient stratification. We intend to enhance this research by collecting more data on which we shall apply advanced artificial intelligence techniques like deep learning to produce an optimized model with higher accuracy.
Author Contributions
Conceptualization, T.P.T.A. and M.A.I.M.; methodology, T.P.T.A., M.A.I.M. and O.D.-O.; software, T.P.T.A. and K.S.C.; validation, T.P.T.A. and M.A.I.M.; investigation, H.-C.K. and S.O.A.; resources, H.-C.K.; data curation, T.P.T.A. and M.A.I.M.; writing—original draft preparation, T.P.T.A., M.A.I.M. and K.S.C.; writing—review and editing, T.P.T.A., M.A.I.M. and S.O.A.; visualization, T.P.T.A. and M.A.I.M.; supervision, H.-C.K. and S.O.A.; project administration, H.-C.K.; funding acquisition, H.-C.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study was approved by the institutional review board with IRB No. 2021-07-017 for Haeundae Paik Hospital, Busan, South Korea, and the requirement for written informed consent was waived due to the retrospective nature of this study.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting this study’s findings are available on request from the corresponding author.
Acknowledgments
Authors extend their gratitude to the doctors who made available the dataset.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kalchiem-Dekel, O.; Galvin, J.R.; Burke, A.P.; Atamas, S.P.; Todd, N.W. Interstitial lung disease and pulmonary fibrosis: A practical approach for general medicine physicians with a focus on the medical history. J. Clin. Med. 2018, 7, 476. [Google Scholar] [CrossRef]
- Barratt, S.L.; Creamer, A.; Hayton, C.; Chaudhuri, N. Idiopathic pulmonary fibrosis (IPF): An overview. J. Clin. Med. 2018, 7, 201. [Google Scholar] [CrossRef] [PubMed]
- Katzenstein, A.-L.A.; Myers, J.L. Idiopathic pulmonary fibrosis: Clinical relevance of pathologic classification. Am. J. Respir. Crit. Care Med. 1998, 157, 1301–1315. [Google Scholar] [CrossRef] [PubMed]
- Society, A.T. ATS/ERS International consensus statement: Idiopathic pulmonary fibrosis: Diagnosis and treatment. Am. J. Respir. Crit. Care Med. 2000, 161, 646–664. [Google Scholar]
- Ley, B.; Collard, H.R. Epidemiology of idiopathic pulmonary fibrosis. Clin. Epidemiol. 2013, 5, 483. [Google Scholar] [CrossRef] [PubMed]
- King, T.E., Jr.; Pardo, A.; Selman, M. Idiopathic pulmonary fibrosis. Lancet 2011, 378, 1949–1961. [Google Scholar] [CrossRef] [PubMed]
- Song, J.W.; Hong, S.-B.; Lim, C.-M.; Koh, Y.; Kim, D.S. Acute exacerbation of idiopathic pulmonary fibrosis: Incidence, risk factors and outcome. Eur. Respir. J. 2011, 37, 356–363. [Google Scholar] [CrossRef]
- Selman, M.; Pardo, A. Idiopathic pulmonary fibrosis: An epithelial/fibroblastic cross-talk disorder. Respir. Res. 2001, 3, 3. [Google Scholar] [CrossRef] [PubMed]
- Kistler, K.D.; Nalysnyk, L.; Rotella, P.; Esser, D. Lung transplantation in idiopathic pulmonary fibrosis: A systematic review of the literature. BMC Pulm. Med. 2014, 14, 139. [Google Scholar] [CrossRef]
- Raghu, G.; Collard, H.R.; Egan, J.J.; Martinez, F.J.; Behr, J.; Brown, K.K.; Colby, T.V.; Cordier, J.-F.; Flaherty, K.R.; Lasky, J.A.; et al. An official ATS/ERS/JRS/ALAT statement: Idiopathic pulmonary fibrosis: Evidence-based guidelines for diagnosis and management. Am. J. Respir. Crit. Care Med. 2011, 183, 788–824. [Google Scholar] [CrossRef]
- Nalysnyk, L.; Cid-Ruzafa, J.; Rotella, P.; Esser, D. Incidence and prevalence of idiopathic pulmonary fibrosis: Review of the literature. Eur. Respir. Rev. 2012, 21, 355–361. [Google Scholar] [CrossRef] [PubMed]
- Raghu, G.; Weycker, D.; Edelsberg, J.; Bradford, W.Z.; Oster, G. Incidence and prevalence of idiopathic pulmonary fibrosis. Am. J. Respir. Crit. Care Med. 2006, 174, 810–816. [Google Scholar] [CrossRef] [PubMed]
- King, T.E., Jr.; Tooze, J.A.; Schwarz, M.I.; Brown, K.R.; Cherniack, R.M. Predicting survival in idiopathic pulmonary fibrosis: Scoring system and survival model. Am. J. Respir. Crit. Care Med. 2001, 164, 1171–1181. [Google Scholar] [CrossRef]
- Bhatt, H.; Jadav, N.K.; Kumari, A.; Gupta, R.; Tanwar, S.; Polkowski, Z.; Tolba, A.; Hassanein, A.S. Artificial neural network-driven federated learning for heart stroke prediction in healthcare 4.0 underlying 5G. Concurr. Comput. Pract. Exp. 2024, 36, e7911. [Google Scholar] [CrossRef]
- Vekaria, D.; Kumari, A.; Tanwar, S.; Kumar, N. ξboost: An AI-based data analytics scheme for COVID-19 prediction and economy boosting. IEEE Internet Things J. 2020, 8, 15977–15989. [Google Scholar] [CrossRef] [PubMed]
- Ajakwe, S.O.; Arkter, R.; Ahakonye, L.A.C.; Kim, D.S.; Lee, J.M. Real-time monitoring of COVID-19 vaccination compliance: A ubiquitous IT convergence approach. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; pp. 440–445. [Google Scholar]
- Ryerson, C.J.; Hartman, T.; Elicker, B.M.; Ley, B.; Lee, J.S.; Abbritti, M.; Jones, K.D.; King, T.E., Jr.; Ryu, J.; Collard, H.R. Clinical features and outcomes in combined pulmonary fibrosis and emphysema in idiopathic pulmonary fibrosis. Chest 2013, 144, 234–240. [Google Scholar] [CrossRef] [PubMed]
- Alsomali, H.; Palmer, E.; Aujayeb, A.; Funston, W. Early diagnosis and treatment of idiopathic pulmonary fibrosis: A narrative review. Pulm. Ther. 2023, 9, 177–193. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, Y.; Mooney, J.; Allen, I.E.; Seaman, J.; Kalra, A.; Muelly, M.; Reicher, J. A Machine Learning System to Indicate Diagnosis of Idiopathic Pulmonary Fibrosis Non-Invasively in Challenging Cases. Diagnostics 2024, 14, 830. [Google Scholar] [CrossRef] [PubMed]
- Onishchenko, D.; Marlowe, R.J.; Ngufor, C.G.; Faust, L.J.; Limper, A.H.; Hunninghake, G.M.; Martinez, F.J.; Chattopadhyay, I. Screening for idiopathic pulmonary fibrosis using comorbidity signatures in electronic health records. Nat. Med. 2022, 28, 2107–2116. [Google Scholar] [CrossRef]
- Dack, E.; Christe, A.; Fontanellaz, M.; Brigato, L.; Heverhagen, J.T.; Peters, A.A.; Huber, A.T.; Hoppe, H.; Mougiakakou, S.; Ebner, L. Artificial intelligence and interstitial lung disease: Diagnosis and prognosis. Investig. Radiol. 2023, 58, 602–609. [Google Scholar] [CrossRef]
- Mekov, E.; Miravitlles, M.; Petkov, R. Artificial intelligence and machine learning in respiratory medicine. Expert Rev. Respir. Med. 2020, 14, 559–564. [Google Scholar] [CrossRef] [PubMed]
- Soffer, S.; Morgenthau, A.S.; Shimon, O.; Barash, Y.; Konen, E.; Glicksberg, B.S.; Klang, E. Artificial Intelligence for Interstitial Lung Disease Analysis on Chest Computed Tomography: A Systematic Review. Acad. Radiol. 2021, 29, S226–S235. [Google Scholar] [CrossRef] [PubMed]
- Mäkelä, K.; Mäyränpää, M.I.; Sihvo, H.-K.; Bergman, P.; Sutinen, E.; Ollila, H.; Kaarteenaho, R.; Myllärniemi, M. Artificial intelligence identifies inflammation and confirms fibroblast foci as prognostic tissue biomarkers in idiopathic pulmonary fibrosis. Hum. Pathol. 2021, 107, 58–68. [Google Scholar] [CrossRef]
- Handa, T.; Tanizawa, K.; Oguma, T.; Uozumi, R.; Watanabe, K.; Tanabe, N.; Niwamoto, T.; Shima, H.; Mori, R.; Nobashi, T.W.; et al. Novel artificial intelligence-based technology for chest computed tomography analysis of idiopathic pulmonary fibrosis. Ann. Am. Thorac. Soc. 2022, 19, 399–406. [Google Scholar] [CrossRef]
- Shi, Y.; Wong, W.K.; Goldin, J.G.; Brown, M.S.; Kim, G.H.J. Prediction of progression in idiopathic pulmonary fibrosis using CT scans at baseline: A quantum particle swarm optimization-Random forest approach. Artif. Intell. Med. 2019, 100, 101709. [Google Scholar] [CrossRef]
- Mandal, S.; Balas, V.E.; Shaw, R.N.; Ghosh, A. Prediction analysis of idiopathic pulmonary fibrosis progression from OSIC dataset. In Proceedings of the 2020 IEEE International Conference on Computing, Power and Communication Technologies (GUCON), Greater Noida, India, 2–4 October 2020. [Google Scholar]
- Wang, Z. Deep Learning Approach for Auto-Detecting Idiopathic Pulmonary Fibrosis Prediction. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Industrial Design (AIID), Guangzhou, China, 28–30 May 2021; pp. 283–290. [Google Scholar]
- Wu, X.; Yin, C.; Chen, X.; Zhang, Y.; Su, Y.; Shi, J.; Weng, D.; Jiang, X.; Zhang, A.; Zhang, W.; et al. Idiopathic pulmonary fibrosis mortality risk prediction based on artificial intelligence: The CTPF model. Front. Pharmacol. 2022, 13, 878764. [Google Scholar] [CrossRef] [PubMed]
- Thillai, M.; Oldham, J.M.; Ruggiero, A.; Kanavati, F.; McLellan, T.; Saini, G.; Johnson, S.R.; Ble, F.X.; Azim, A.; Ostridge, K.; et al. Deep learning-based segmentation of CT scans predicts disease progression and mortality in IPF. Am. J. Respir. Crit. Care Med. 2024. Available online: https://www.atsjournals.org/doi/abs/10.1164/rccm.202311-2185OC (accessed on 2 March 2024). [CrossRef] [PubMed]
- Ali, S.; Hussain, A.; Aich, S.; Park, M.S.; Chung, M.P.; Jeong, S.H.; Song, J.W.; Lee, J.H.; Kim, H.C. A Soft Voting Ensemble-Based Model for the Early Prediction of Idiopathic Pulmonary Fibrosis (IPF) Disease Severity in Lungs Disease Patients. Life 2021, 11, 1092. [Google Scholar] [CrossRef]
- Ajakwe, S.O.; Ajakwe, I.U.; Jun, T.; Kim, D.S.; Lee, J.M. CIS-WQMS: Connected intelligence smart water quality monitoring scheme. Internet Things 2023, 23, 100800. [Google Scholar] [CrossRef]
- Huang, J.; Li, Y.-F.; Xie, M. An empirical analysis of data preprocessing for machine learning-based software cost estimation. Inf. Softw. Technol. 2015, 67, 108–127. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput. Surv. (CSUR) 2017, 50, 94. [Google Scholar] [CrossRef]
- Ajakwe, S.O.; Ihekoronye, V.U.; Ajakwe, I.U.; Jun, T.; Kim, D.S.; Lee, J.M. Connected Intelligence for Smart Water Quality Monitoring System in IIoT. In Proceedings of the 13th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2022; pp. 2386–2391. [Google Scholar]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [PubMed]
- Akhtar, F.; Li, J.; Pei, Y.; Xu, Y.; Rajput, A.; Wang, Q. Optimal features subset selection for large for gestational age classification using gridsearch based recursive feature elimination with cross-validation scheme. In Proceedings of the International Conference on Frontier Computing, Kitakyushu, Japan, 9–12 July 2019; Springer: Singapore, 2019. [Google Scholar]
- Ihekoronye, V.U.; Ajakwe, S.O.; Kim, D.S.; Lee, J.M. Hierarchical intrusion detection system for secured military drone network: A perspicacious approach. In Proceedings of the MILCOM 2022—2022 IEEE Military Communications Conference (MILCOM), Rockville, MD, USA, 28 November–2 December 2022; pp. 336–341. [Google Scholar]
- Yahaya, C.A.C.; Firdaus, A.; Mohamad, S.; Ernawan, F.; Razak, M.F.A. Automated Feature Selection using Boruta Algorithm to Detect Mobile Malware. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 9029–9036. [Google Scholar]
- Han, W.; Huang, Z.; Li, S.; Jia, Y. Distribution-sensitive unbalanced data oversampling method for medical diagnosis. J. Med. Syst. 2019, 43, 39. [Google Scholar] [CrossRef] [PubMed]
- Ajakwe, S.O.; Deji-Oloruntoba, O.; Olatubosun, S.; Duorinaah, F.; Bayode, I.A. Multidimensional Perspective to Data Preprocessing for Model Cognition Verity. In Recent Trends and Future Direction for Data Analytics; IGI Global Publishers: Hershey, PA, USA, 2024; ISBN 13 9798369336090. [Google Scholar] [CrossRef]
- Juarez, M.M.; Chan, A.L.; Norris, A.G.; Morrissey, B.M.; Albertson, T.E. Acute exacerbation of idiopathic pulmonary fibrosis. Chest 2007, 132, 1652–1658. [Google Scholar]
- Lee, H.J.; Im, J.-G.; Ahn, J.M.; Yeon, K.M. Lung cancer in patients with idiopathic pulmonary fibrosis: CT findings. J. Comput. Assist. Tomogr. 1996, 20, 979–982. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).