
Horizontal Autoscaling of Virtual Machines in Hybrid Cloud Infrastructures: Current Status, Challenges, and Opportunities



Abstract
:1. Introduction
1.1. Motivation and Scope of the Paper
- Precisely forecasting the future demand by analysing the historical trends with anomaly detection.
- Accurate autoscaling decision execution to address the VM provisioning or boot time delays (cold start).
- More flexibility in cloud native VM autoscaling solutions, where the VM autoscaling can be extended across hybrid clouds.
- Greater versatility in defining custom autoscaling policies using more user-defined and workload-specific autoscaling metrics.
- Reviewing the current research work related to VM autoscaling to identify the research directions and gaps in proactive autoscaling and hybrid cloud autoscaling.
- Identifying how proactive autoscaling and workload classification are introduced for container autoscaling using ML-based technologies.
- Performing a comparison of the autoscaling offerings of three major public cloud platforms and one open-source cloud platform to identify the current gaps and issues.
- Define future research directions to address the gaps identified in this review.
1.2. Structure of the Paper
2. Rapid Elasticity for VMs in Cloud Platforms and Current Challenges
2.1. Rapid Elasticity at Different Cloud Deployment Layers
- How do we determine the optimum number of VMs to provision to avoid SLA/QoS violations?
- How do we know exactly when to provide the additional required capacity?
- What are the measures we could take to reduce provisioning latency?
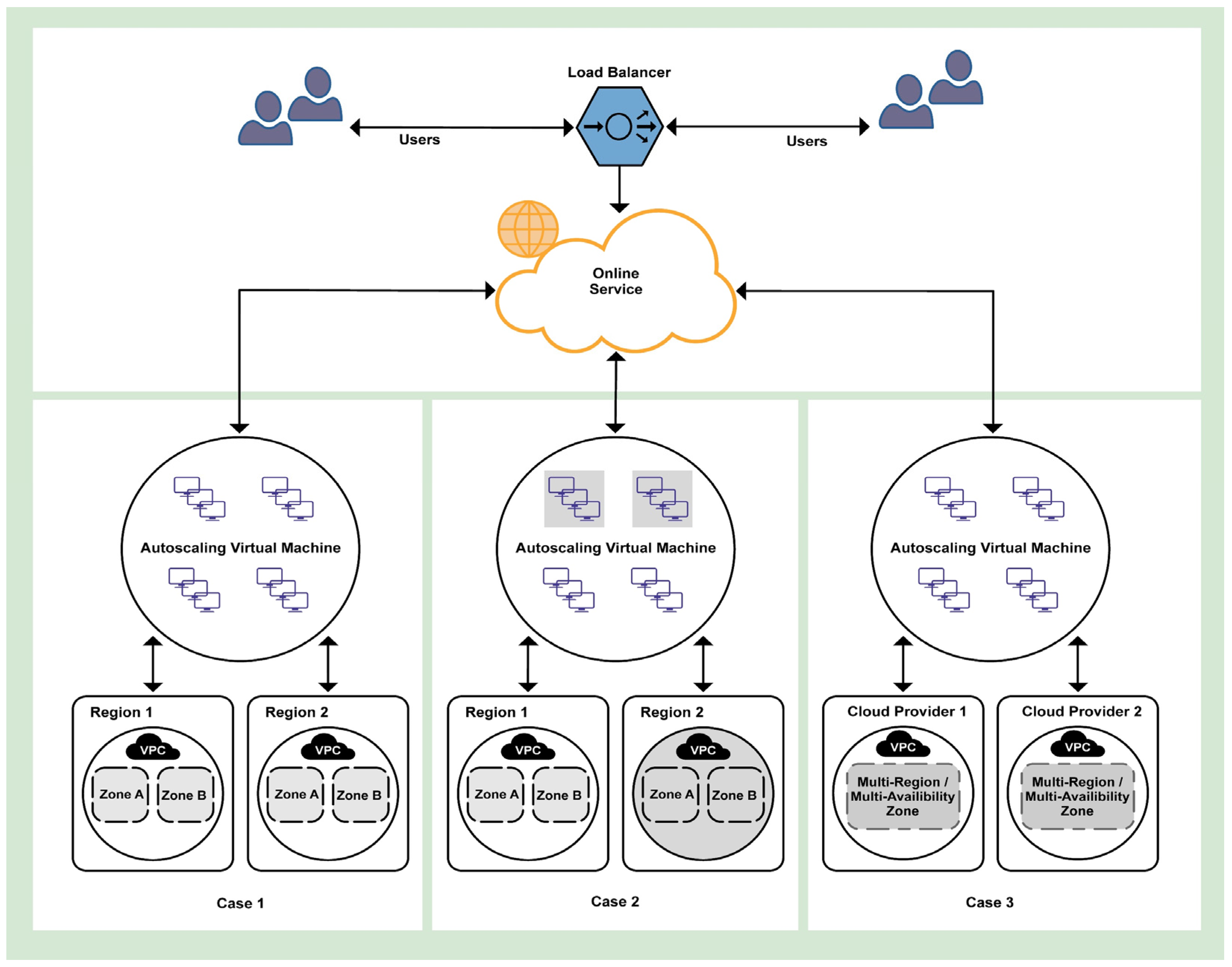
2.2. Capability of Multi-Cloud Support for Autoscaling
2.3. Proactive Autoscaling Support
3. Autoscaling in Clouds—Previous Work
3.1. Reactive Autoscaling
3.2. Autoscaling in a Single-Cloud Infrastructure with Dynamic or Predictive Scaling Support
3.3. Autoscaling Across Multiple Clouds
3.4. Discussion of the Comparative Analysis
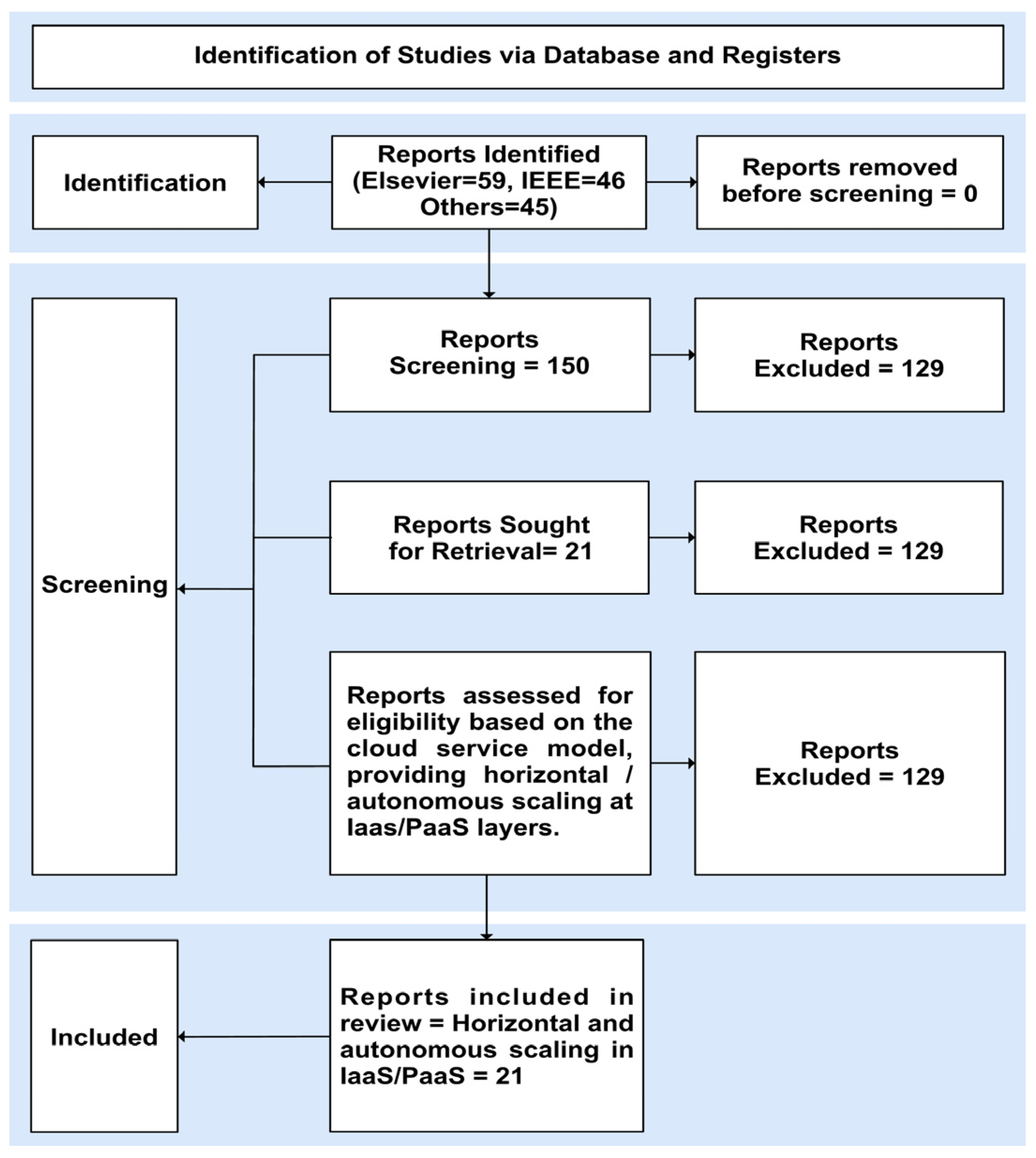
4. Methods and Materials
5. Classification of Autoscaling Techniques
5.1. Threshold-Based Rules
5.2. Reinforcement Learning
5.3. Queuing Theory
5.4. Control Theory
5.5. Time Series Analysis
6. Commercial Autoscaling Approaches in Public Cloud Environments
6.1. Amazon Web Services
6.2. Google Cloud Platform
6.3. Azure Cloud
6.4. Apache Cloud
7. What Are the Challenges to Achieving Horizontal Autoscaling at the IaaS Layer?
- Capacity estimation/load prediction errors: Capacity forecasting and load prediction errors might cause proactive capacity allocations to be either overprovisioned or under-provisioned. GCP best practice documentation suggests several guidelines on how to address this issue with careful manual intervention [88]. The literature indicates that previous attempts were made to resolve autoscaling challenges either by using proactive or reactive autoscaling approaches, but to the best of our knowledge, these attempts have yet to come up with a reliable solution. It is not straightforward to precisely estimate the capacity requirement for a particular workload and adjust additional resources without over/under-provisioning.
- Delays in capacity allocation when demand increases or with cold start: A time delay in provisioning the required resources to meet the increased demand will compromise the quality of service. This is a well-known problem in reactive autoscaling [89]. The above review addresses this issue by providing various frameworks for proactive autoscaling. In proactive autoscaling, this issue has been addressed using self-derived algorithms or machine learning technologies based on time series or reinforcement learning.
- Infrastructure failures: It can be argued that public clouds will overcome this issue by providing a more resilient and distributed environment; however, the recently reported public cloud failures prove this otherwise [90].
- Metric collection/alerting failures: Moghaddam et al. [91] highlighted that detecting anomalies in metrics can lead to autoscaling decision errors. Autoscaling operations are triggered by various system alerts generated during certain events. These alerts are implemented by means of various metric collections. The errors or inefficient analysis of these metrics could result in inefficient or incorrect predictions.
- Platform dependency: Currently, there are very limited options available for autoscaling multiple cloud platforms in the IaaS service model, e.g., the inability to use VM bursting across a hybrid cloud environment. This introduces vendor lock-in, which means resource dependency on one cloud platform. In the case of a single point of failure, services cannot be executed.
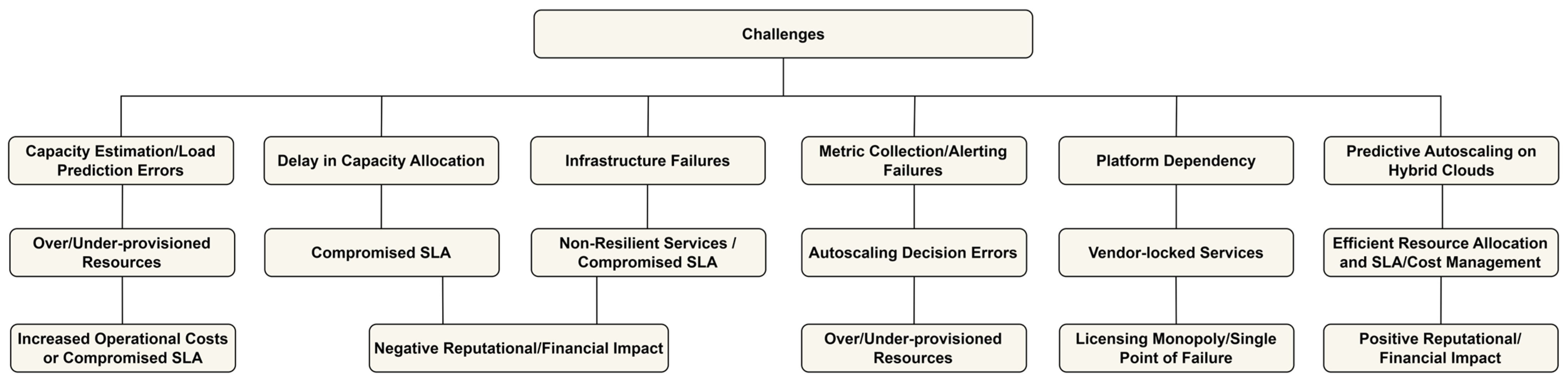
- Predictive (or proactive) Autoscaling: Currently, there are limitations in the commercial deployment of proactive autoscaling. For example, the offerings from AWS and GCP in this domain have limited capabilities and only use time series-based forecasting to perform autoscaling operations. These limitations are further exacerbated when proactive scaling is a requirement in hybrid cloud environments, where predictive autoscaling operations at IaaS span multiple clouds. Figure 6 depicts a holistic view of the above challenges for autoscaling in public hybrid cloud environments.
- 1.
- Identify common capacity- and load-related metrics, which can be derived from multiple cloud infrastructures.
- 2.
- Extend the support for horizontal autoscaling of virtual machines in a single cloud environment to a hybrid cloud setup with integrated proactive autoscaling capabilities.
- 3.
- Define evaluation metrics to evaluate the effectiveness of autonomous autoscaling, providing the required quality of service in a hybrid cloud.
8. Conclusions and Future Research Directions
- Identified various issues and challenges faced by autoscaling in cloud infrastructures both at the IaaS and PaaS layers in terms of metric collections and workload classification.
- Discussed the lack of support for hybrid cloud autoscaling, specifically for the autoscaling of VMs across hybrid clouds.
- Reviewed the proposed solutions and frameworks addressing these issues, which use a combination of machine learning and deep learning algorithms and open-source tools.
- Presented comparisons of those solutions, categorising them into three autoscaling domains: single cloud autoscaling, single cloud autoscaling with proactive/dynamic autoscaling support, and proactive autoscaling across hybrid clouds.
- Reviewed three of the most popular public cloud platforms and an open-source platform and conducted a comparison of VM autoscaling implementations.
- Developing a unified set of metrics that can serve as a benchmark for performing proactive autoscaling in hybrid cloud environments.
- Implementing autoscaling mechanisms at the IaaS layer that work across different platforms, ensuring consistency and performance in hybrid cloud environments without relying on platform-specific features.
- Identifying and defining suitable evaluation metrics to measure the success and reliability of autonomous autoscaling mechanisms, ensuring that they meet the performance and quality of service (QoS) requirements in a hybrid cloud setting.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Dhuraibi, Y.; Paraiso, F.; Djarallah, N.; Merle, P. Elasticity in cloud computing: State of the art and research challenges. IEEE Trans. Serv. Comput. 2018, 11, 430–447. [Google Scholar] [CrossRef]
- De Assuncao, M.D.; Cardonha, C.H.; Netto, M.A.; Cunha, R.L. Impact of user patience on auto-scaling resource capacity for cloud services. Future Gener. Comput. Syst. 2016, 55, 41–50. [Google Scholar] [CrossRef]
- Qu, C.; Calheiros, R.N.; Buyya, R. Auto-scaling web applications in clouds: A taxonomy and survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–33. [Google Scholar] [CrossRef]
- Mell, P.; Grance, T. The NISTDefinition of Cloud Computing Recommendations of the National Institute of Standards Technology [Online], NIST. 2011. Available online: https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf (accessed on 10 December 2023).
- Mirobi, G.J.; Arockiam, L. Service Level Agreement in Cloud Computing: An Overview. In Proceedings of the 2015 International Conference on Control, Instrumentation, Communication and Computational Technologies (ICCICCT), Kumaracoil, India, 18–19 December 2015. [Google Scholar] [CrossRef]
- Jelassi, M.; Ghazel, C.; Saïdane, L.A. A survey on quality of service in cloud computing. In Proceedings of the 2017 3rd International Conference on Frontiers of Signal Processing (ICFSP), Paris, France, 6–8 September 2017. [Google Scholar]
- Managed Kubernetes Service—Amazon EKS—Amazon Web Services. Available online: https://aws.amazon.com/eks/ (accessed on 2 January 2024).
- What Are Containers? | Google Cloud. Available online: https://cloud.google.com/learn/what-are-containers/ (accessed on 2 January 2024).
- Ashalatha, R.; Agarkhed, J. Evaluation of Auto Scaling and Load Balancing Features in Cloud. Int. J. Comput. Appl. 2015, 117, 30–33. [Google Scholar] [CrossRef]
- Amazon EC2 Spot. Available online: https://aws.amazon.com/ec2/spot/instance-advisor/ (accessed on 2 January 2024).
- Spot VMs | Compute Engine Documentation | Google Cloud. Available online: https://cloud.google.com/solutions/spot-vms/ (accessed on 2 January 2024).
- Predictive Scaling for Amazon EC2 Auto Scaling—Amazon EC2 Auto Scaling. Available online: https://docs.aws.amazon.com/autoscaling/ec2/userguide/ec2-auto-scaling-predictive-scaling.html (accessed on 2 January 2024).
- Google Cloud. Scaling Based on Predictions. 2016. Available online: https://cloud.google.com/compute/docs/autoscaler/predictive-autoscaling#suitable_workloads (accessed on 2 January 2024).
- Vemasani, P.; Vuppalapati, S.M.; Modi, S.; Ponnusamy, S. Achieving Agility through Au-to-Scaling: Strategies for Dynamic Resource Allocation in Cloud Computing. IJRASET 2024, 12, 3169–3177. [Google Scholar] [CrossRef]
- Multicloud Optimization Platform, Application Automatic Deployment Solution. Available online: https://www.melodic.cloud/ (accessed on 16 February 2024).
- Bouabdallah, R.; Lajmi, S.; Ghedira, K. Use of reactive and proactive elasticity to adjust resources provisioning in the cloud provider. In Proceedings of the 2016 IEEE 18th International Conference on High Performance Computing and Communications; IEEE 14th International Conference on Smart City; IEEE 2nd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Sydney, Australia, 12–14 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1155–1162. [Google Scholar]
- Arcaini, P.; Riccobene, E.; Scandurra, P. Modeling and analyzing MAPE-k feedback loops for self-adaptation. In Proceedings of the 2015 IEEE/ACM 10th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, Florence, Italy, 18–19 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 13–23. [Google Scholar]
- Iqbal, W.; Erradi, A.; Abdullah, M.; Mahmood, A. Predictive auto-scaling of multi-tier applications using performance varying cloud resources. IEEE Trans. Cloud Comput. 2019, 10, 595–607. [Google Scholar] [CrossRef]
- Rokach, L. Decision forest: Twenty years of research. Inf. Fusion 2016, 27, 111–125. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; IEEE: Piscataway, NJ, USA, 1995; Volume 1, pp. 278–282. [Google Scholar]
- Liu, C.; Shang, Y.; Duan, L.; Chen, S.; Liu, C.; Chen, J. Optimizing Workload Category for Adaptive Workload Prediction in Service Clouds; Springer: Berlin/Heidelberg, Germany, 2015; pp. 87–104. [Google Scholar]
- Lim, H.I. A linear regression approach to modeling software characteristics for classifying similar software. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; Volume 1, pp. 942–943. [Google Scholar]
- Jakkula, V. Tutorial on Support Vector Machine (SVM); School of EECS, Washington State University: Pullman, WA, USA, 2006; Volume 37, p. 3. [Google Scholar]
- Wadia, Y.; Gaonkar, R.; Namjoshi, J. Portable autoscaler for managing multi-cloud elasticity. In Proceedings of the 2013 International Conference on Cloud & Ubiquitous Computing & Emerging Technologies, Pune, India, 15–16 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 48–51. [Google Scholar]
- Si, W.; Pan, L.; Liu, S. A cost-driven online auto-scaling algorithm for web applications in cloud environments. Knowl.-Based Syst. 2022, 244, 108523. [Google Scholar] [CrossRef]
- Bibal Benifa, J.; Dejey, D. Rlpas: Reinforcement learning-based proactive auto-scaler for resource provisioning in cloud environment. Mob. Netw. Appl. 2019, 24, 1348–1363. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Dayan, P.; Niv, Y. Reinforcement learning: The good, the bad and the ugly. Curr. Opin. Neurobiol. 2008, 18, 185–196. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Wang, H.; Shao, K.; Zhu, Y. Deep reinforcement learning with experience replay based on SARSA. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016. [Google Scholar] [CrossRef]
- Arabnejad, H.; Jamshidi, P.; Estrada, G.; El Ioini, N.; Pahl, C. An Auto-Scaling Cloud Controller Using Fuzzy Q-Learning-Implementation in Openstack; Springer: Berlin/Heidelberg, Germany, 2016; pp. 152–167. [Google Scholar]
- Salehizadeh, M.R.; Soltaniyan, S. Application of fuzzy Q-learning for electricity market modeling by considering renewable power penetration. Renew. Sustain. Energy Rev. 2016, 56, 1172–1181. [Google Scholar] [CrossRef]
- Glorennec, P.Y.; Jouffe, L. Fuzzy Q-learning. In Proceedings of the 6th International Fuzzy Systems Conference, Barcelona, Spain, 5 July 1997; IEEE: Piscataway, NJ, USA, 1997; Volume 2, pp. 659–662. [Google Scholar]
- Golshani, E.; Ashtiani, M. Proactive auto-scaling for cloud environments using temporal convolutional neural networks. J. Parallel Distrib. Comput. 2021, 154, 119–141. [Google Scholar] [CrossRef]
- Chudasama, V.; Bhavsar, M. A dynamic prediction for elastic resource allocation in hybrid cloud environment. Scalable Comput. Pract. Exp. 2020, 21, 661–672. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent neural networks for time series forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Biswas, A.; Majumdar, S.; Nandy, B.; El-Haraki, A. A hybrid auto-scaling technique for clouds processing applications with service level agreements. J. Cloud Comput. 2017, 6, 29. [Google Scholar] [CrossRef]
- Gari, Y.; Monge, D.A.; Mateos, C. A Q-learning approach for the autoscaling of scientific workflows in the cloud. Future Gen-Eration Comput. Syst. 2022, 127, 168–180. [Google Scholar] [CrossRef]
- Alidoost Alanagh, Y.; Firouzi, M.; Rasouli Kenari, A.; Shamsi, M. Introducing an adaptive model for auto-scaling cloud computing based on workload classification. Concurr. Comput. Pract. Exp. 2023, 35, e7720. [Google Scholar] [CrossRef]
- Tournaire, T.; Castel-Taleb, H.; Hyon, E. Efficient Computation of Optimal Thresholds in Cloud Auto-Scaling Systems. ACM Trans. Model. Perform. Eval. Comput. Syst. 2023, 8, 1–31. [Google Scholar] [CrossRef]
- Chouliaras, S.; Sotiriadis, S. caling containerized cloud applications: A workload-driven approach. Simul. Model. Pract. Theory 2022, 121, 102654. [Google Scholar] [CrossRef]
- Tran, T.M.; Le, X.M.T.; Nguyen, H.T.; Huynh, V.N. A novel non-parametric method for time series classification based on k- Nearest Neighbors and Dynamic Time Warping Barycenter Averaging. Eng. Appl. Artif. Intell. 2019, 78, 173–185. [Google Scholar] [CrossRef]
- Wen, L.; Xu, M.; Toosi, A.N.; Ye, K. TempoScale: A Cloud Workloads Prediction Approach Integrating Short-Term and Long-Term Information. In Proceedings of the 2024 IEEE 17th International Conference on Cloud Computing (CLOUD), Shenzhen, China, 7–13 July 2024; pp. 183–193. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, W.; Fu, S.; Lu, Y. A Trend Detection-Based Auto-Scaling Method for Containers in High-Concurrency Scenarios. IEEE Access 2024, 12, 71821–71834. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, M.; Li, T.; Wang, H.; Li, C. Long sequence time-series forecasting with deep learning: A survey. Inf. Fusion 2023, 97, 101819. [Google Scholar] [CrossRef]
- Research.Google. Attention Is All You Need. Available online: https://research.google/pubs/attention-is-all-you-need/ (accessed on 25 February 2024).
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhou, W.; Wang, C.; Zhang, J.; Tang, W.; Qi, L.; Ai, T.; Li, G.; Yu, B.; Yang, X. PheScale: Leveraging Transformer Models for Proactive VM Auto-scaling. In International Conference on Advanced Data Mining and Applications; Lecture Notes in Computer Science; Springer: Singapore, 2024; pp. 47–61. [Google Scholar] [CrossRef]
- Nie, Y.; Nguyen, N.H.; Sinthong, P.; Kalagnanam, J. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. arXiv 2023. [Google Scholar] [CrossRef]
- Tanadechopon, T.; Kasemsontitum, B. Performance Evaluation of Programming Languages as API Services for Cloud Environments: A Comparative Study of PHP, Python, Node.js and Golang. In Proceedings of the 2023 7th International Conference on Information Technology (InCIT), Chiang Rai, Thailand, 16–17 November 2023. [Google Scholar] [CrossRef]
- Shreyas, M. Federated Cloud Services using Virtual API Proxy Layer in a Distributed Cloud Environment. In Proceedings of the 2017 Ninth International Conference on Advanced Computing (ICoAC), Chennai, India, 14–16 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 134–141. [Google Scholar]
- Harwalkar, S.; Sitaram, D.; Kidiyoor, D.V.; Milan, M.L.; D’souza, O.; Agarwal, R.; Agarwal, Y. Multicloud-auto scale with prediction and delta correction algorithm. In Proceedings of the 2019 2nd International Conference on Intelligent Computing, Instrumentation and Control Technologies (ICICICT), Kannur, Indi, 5–6 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 227–233. [Google Scholar]
- Eddy, S.R. What is a hidden Markov model? Nat. Biotechnol. 2004, 22, 1315–1316. [Google Scholar] [CrossRef] [PubMed]
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE Assp. Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Srirama, S.N.; Adhikari, M.; Paul, S. Application deployment using containers with auto-scaling for microservices in cloud en-vironment. J. Netw. Comput. Appl. 2020, 160, 102629. [Google Scholar] [CrossRef]
- Abdel Khaleq, A.; Ra, I. Intelligent microservices autoscaling module using reinforcement learning. Clust. Comput. 2023, 26, 2789–2800. [Google Scholar] [CrossRef]
- Sarkis-Onofre, R.; Catalá-López, F.; Aromataris, E.; Lockwood, C. How to properly use the PRISMA Statement. Syst. Rev. 2021, 10, 117. [Google Scholar] [CrossRef] [PubMed]
- Mueen Ahmed, K.; Dhubaib, B.E.A. Zotero: A bibliographic assistant to researcher. J. Pharmacol. Pharma-Cother-Apeutics 2011, 2, 304–305. [Google Scholar] [CrossRef] [PubMed]
- Sanad, A.J.; Hammad, M. Combining Spot Instances Hopping with Vertical Auto-scaling To Reduce Cloud Leasing Cost. In Proceedings of the 2020 International Conference on Innovation and Intelligence for Informatics, Computing and Technologies (3ICT), Sakheer, Bahrain, 20–21 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Lorido-Botran, T.; Miguel-Alonso, J.; Lozano, J.A. A review of auto-scaling techniques for elastic applications in cloud environments. J. Grid Comput. 2014, 12, 559–592. [Google Scholar] [CrossRef]
- Verma, S.; Bala, A. Auto-scaling techniques for IoT-based cloud applications: A review. Clust. Comput. 2021, 24, 2425–2459. [Google Scholar] [CrossRef]
- Sztrik, J. Basic Queuing Theory; University of Debrecen: Debrecen, Hungary, 2012; Volume 193, pp. 60–67. [Google Scholar]
- Sahni, J.; Vidyarthi, D.P. A cost-effective deadline-constrained dynamic scheduling algorithm for scientific workflows in a cloud environment. IEEE Trans. Cloud Comput. 2015, 6, 2–18. [Google Scholar] [CrossRef]
- Liu, Z.; Zhu, Z.; Gao, J.; Xu, C. Forecast Methods for Time Series Data: A Survey. IEEE Access 2021, 9, 91896–91912. [Google Scholar] [CrossRef]
- Gartner, I. Best Cloud Infrastructure and Platform Services Reviews 2023 | Gartner Peer Insights. Available online: https://www.gartner.com/reviews/market/cloud-infrastructure-and-platform-services (accessed on 22 January 2024).
- Selecting Cloud Computing Software for a Virtual Online Laboratory Supporting the Operating Systems Course | CTE Workshop Proceedings. Available online: https://acnsci.org/journal/index.php/cte/article/view/116 (accessed on 22 January 2024).
- Instance Auto Scaling—Amazon EC2 Autoscaling—AWS. Available online: https://aws.amazon.com/ec2/autoscaling/ (accessed on 22 January 2024).
- What Is Amazon EC2 Auto Scaling?—Amazon EC2 Auto Scaling. Available online: https://docs.aws.amazon.com/autoscaling/ec2/userguide/what-is-amazon-ec2-auto-scaling.html (accessed on 22 January 2024).
- Scheduled Scaling for Amazon EC2 Auto Scaling—Amazon EC2 Auto Scaling. Available online: https://docs.aws.amazon.com/autoscaling/ec2/userguide/ec2-auto-scaling-scheduled-scaling.html (accessed on 22 January 2024).
- Dynamic Scaling for Amazon EC2 Auto Scaling—Amazon EC2 Auto Scaling. Available online: https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-scale-based-on-demand.html (accessed on 22 January 2024).
- Use Amazon CloudWatch Metrics—Amazon CloudWatch. Available online: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/working_with_metrics.html (accessed on 22 January 2024).
- Scaling Based on Amazon SQS—Amazon EC2 Auto Scaling. Available online: https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-using-sqs-queue.html (accessed on 24 January 2024).
- Instance Groups Documentation Google Cloud. Available online: https://cloud.google.com/compute/docs/instance-groups (accessed on 24 January 2024).
- Scaling Based on CPU Utilization | Compute Engine Documentation | Google Cloud. Available online: https://cloud.google.com/compute/docs/autoscaler/scaling-cpu (accessed on 24 January 2024).
- Scale Based on Monitoring Metrics | Compute Engine Documentation | Google Cloud. Available online: https://cloud.google.com/compute/docs/autoscaler/scaling-cloud-monitoring-metrics (accessed on 24 January 2024).
- Scaling Based on Load Balancing Serving Capacity | Compute Engine Documentation | Google Cloud. Available online: https://cloud.google.com/compute/docs/autoscaler/scaling-load-balancing (accessed on 25 January 2024).
- Scaling Based on Schedules | Compute Engine Documentation | Google Cloud. Available online: https://cloud.google.com/compute/docs/autoscaler/scaling-schedules (accessed on 25 January 2024).
- Scaling Based on Predictions | Compute Engine Documentation | Google Cloud. Available online: https://cloud.google.com/compute/docs/autoscaler/predictive-autoscaling (accessed on 25 January 2024).
- Shim, J. Azure Virtual Machine Scale Sets Overview—Azure Virtual Machine Scale Sets. Available online: https://learn.microsoft.com/en-us/azure/virtual-machine-scale-sets/overview (accessed on 25 January 2024).
- Tomvcassidy. Overview of Azure Service Fabric—Azure Service Fabric. Available online: https://learn.microsoft.com/en-us/azure/service-fabric/service-fabric-overview (accessed on 25 January 2024).
- Fitzgeraldsteele. Orchestration Modes for Virtual Machine Scale Sets in Azure—Azure Virtual Machine Scale Sets. Available online: https://learn.microsoft.com/en-us/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-orchestration-modes (accessed on 26 January 2024).
- Bdeforeest. Associate a Virtual Machine Scale Set with Flexible Orchestration to a Capacity Reservation Group (Preview)—Azure Virtual Machines. Available online: https://learn.microsoft.com/en-us/azure/virtual-machines/capacity-reservation-associate-virtual-machine-scale-set-flex (accessed on 26 January 2024).
- Mimckitt. Manage Fault Domains in Azure Virtual Machine Scale Sets—Azure Virtual Machine Scale Sets. Available online: https://learn.microsoft.com/en-us/azure/virtual-machine-scale-sets/virtual-machine-scale-sets-manage-fault-domains (accessed on 26 January 2024).
- EdB-MSFT. Autoscale in Azure Monitor—Azure Monitor. Available online: https://learn.microsoft.com/en-us/azure/azure-monitor/autoscale/autoscale-overview (accessed on 26 January 2024).
- EdB-MSFT. Use Predictive Autoscale to Scale Out Before Load Demands in Virtual Machine Scale Sets—Azure Monitor. Available online: https://learn.microsoft.com/en-us/azure/azure-monitor/autoscale/autoscale-predictive (accessed on 26 January 2024).
- Apache Cloudstack. Apache Cloudstack. Available online: https://cloudstack.apache.org/ (accessed on 26 January 2024).
- Plan for Peak Traffic and Launch Events | Architecture Framework | Google Cloud. Available online: https://cloud.google.com/architecture/framework/operational-excellence/plan-for-peak-traffic-and-launch-events (accessed on 26 January 2024).
- Radhika, E.; Sadasivam, G.S. A review on prediction based autoscaling techniques for heterogeneous applications in cloud environment. Mater. Today Proc. 2021, 45, 2793–2800. [Google Scholar] [CrossRef]
- Giles, M. A Major Outage at AWS Has Caused Chaos at Amazon’s Own Operations, High-Lighting Cloud Computing Risks. Available online: https://www.forbes.com/sites/martingiles/2021/12/07/aws-outage-caused-chaos-at-amazon-underlining-cloud-computing-risks/?sh=5173d7496834 (accessed on 26 January 2024).
- Moghaddam, S.K.; Buyya, R.; Ramamohanarao, K. ACAS: An anomaly based cause aware auto-scaling framework for clouds. J. Parallel Distrib. Comput. 2019, 126, 107–120. [Google Scholar] [CrossRef]
- AWS. What Is Amazon CloudWatch?—Amazon CloudWatch. 2024. Available online: https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/WhatIsCloudWatch.html (accessed on 26 January 2024).
- Cloud Monitoring | Google Cloud. Available online: https://cloud.google.com/monitoring?hl=en (accessed on 26 January 2024).
- Rboucher. Azure Monitor Overview—Azure Monitor. Available online: https://learn.microsoft.com/en-us/azure/azure-monitor/overview (accessed on 26 January 2024).
- Documentation. OpenTelemetry. 2024. Available online: https://opentelemetry.io/docs (accessed on 3 March 2024).
- Lee, D.; Yannakakis, M. Principles and methods of testing finite state machines—A survey. Proc. IEEE 1996, 84, 1090–1123. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Section | Section Heading | Brief Description |
|---|---|---|
| Section 2 | Rapid elasticity for VMs in Cloud Platforms and current challenges | Discusses the commonly used autoscaling techniques in cloud computing within both the reactive and proactive autoscaling categories. |
| Section 3 | Autoscaling in Clouds—Previous Work | Provides an overview of the selected papers, discussing the strengths and weaknesses of each work. |
| Section 4 | Methods and Materials | Outlines the methodology used for the systematic review. |
| Section 5 | Classification of Autoscaling Techniques | Offers a classification of commonly employed autoscaling techniques, along with a brief description of each method. |
| Section 6 | Commercial Autoscaling Approaches in Public Cloud Environments | Discusses the autoscaling approaches used in three widely used commercial public cloud providers and one open-source-based cloud platform. |
| Section 7 | What are the Challenges to Achieve Autoscaling at IaaS Layer? | Summarises the challenges from the review of commercial deployments (Section 5) and autoscaling approaches proposed in the reviewed papers (Section 6). |
| Section 8 | Conclusions and future research directions | Concludes and offers future research directions are presented in this section. |
| Category | Pros | Cons |
|---|---|---|
| Reactive autoscaling | 1. Straightforward and simple to use. | 2. On-demand scaling introduces latency issues and SLA violations. |
| Single cloud with proactive scaling support | 1. Proactive resource forecasting addresses the latency and SLA issues. 2. Cost efficient due to predictive nature of resource usage forecasting. | 1. Cloud native and lack of hybrid cloud support. 2. Requirements of high-computing resources for ML-based algorithms. |
| Autoscaling across multiple clouds | 1. Hybrid cloud support to remove the platform dependency and improved resilience. | 1. Limited proactive autoscaling support. 2. Difficult to execute autoscaling decisions across hybrid cloud (API differences). |
| Ref. | Year | Reactive | Proactive | Hybrid Cloud Support | ML Based | Dynamic Scaling at Runtime | Workload Classification Support | Principle Techniques | IaaS /PaaS |
|---|---|---|---|---|---|---|---|---|---|
| [16] | 2016 | ✓ | × | × | × | ✓ | × | Control theory | IaaS |
| [18] | 2019 | ✓ | × | × | ✓ | × | ✓ | Decision Tree/Random Decision Forest | IaaS |
| [21] | 2015 | ✓ | × | × | ✓ | × | ✓ | Linear Regression (LR) and Support Vector Method (SVM) for classification. A 0–1 integer programming | IaaS |
| [24] | 2013 | ✓ | × | × | × | ✓ | × | Control theory-based using a customised open-source tool-set | IaaS |
| [25] | 2022 | ✓ | × | × | × | ✓ | × | Control theory-based mathematical formula based on request arrival rate | IaaS |
| [26] | 2022 | ✓ | × | × | ✓ | × | × | Reinforcement learning-based State Action Reward State Action (SARSA) | IaaS |
| [30] | 2016 | ✓ | ✓ | × | ✓ | ✓ | × | Reinforcement learning-based Fuzzy Q-Learning and control theory-based MAPE K | IaaS |
| [33] | 2021 | ✓ | ✓ | × | ✓ | ✓ | ✓ | Temporal Convolutional Neural Network | IaaS |
| [34] | 2020 | × | ✓ | × | ✓ | ✓ | ✓ | LSTM (Long Short-Term Memory) and Queuing Theory | IaaS |
| [37] | 2017 | ✓ | ✓ | × | ✓ | × | ✓ | Linear Regression and Support Vector Method for prediction | IaaS |
| [38] | 2022 | ✓ | ✓ | × | ✓ | × | × | Markov Decision Process and Q-Learning | IaaS |
| [39] | 2023 | ✓ | ✓ | × | ✓ | ✓ | ✓ | Time series-based (LR, SVM, ARIMA) | IaaS |
| [40] | 2023 | ✓ | ✓ | × | ✓ | ✓ | × | Continuous Time Markov Chains (CTMC) and Markov Decision Process (MDP) | IaaS |
| [41] | 2022 | ✓ | ✓ | × | ✓ | ✓ | × | Convolution Neural Networks (CNN) and K-means clustering | IaaS |
| [43] | 2024 | × | ✓ | × | ✓ | × | × | CEEMDAN, which is an extension of Empirical Mode Decomposition (EMD) | PaaS |
| [45] | 2024 | × | ✓ | × | ✓ | × | × | ARIMA, LSTM, Informer, and MAPE | PaaS |
| [49] | 2025 | × | ✓ | × | ✓ | × | × | PatchTST and Adaptive Sequence Transformation | IaaS |
| [52] | 2017 | ✓ | × | ✓ | × | × | × | Control Theory-based approach using OpenStack Nova API | IaaS |
| [53] | 2019 | ✓ | × | ✓ | × | × | ✓ | Hidden Markov Model | IaaS |
| [56] | 2020 | ✓ | ✓ | ✓ | ✓ | ✓ | × | Rule-based and heuristic-based Best Fit Dynamic Bin Packing | PaaS |
| [57] | 2023 | ✓ | ✓ | ✓ | ✓ | × | × | Reinforcement learning | PaaS |
| Stage | Description | Criteria | Outcome |
|---|---|---|---|
| 1 | Selection of databases | Selected the databases containing journals related to the cloud, distributed computing, and information systems | The following databases were chosen to perform the searches: 1. IEE Explore 2. Elsevier—Science Direct 3. ACM 4. Springer 5. ResearchGate |
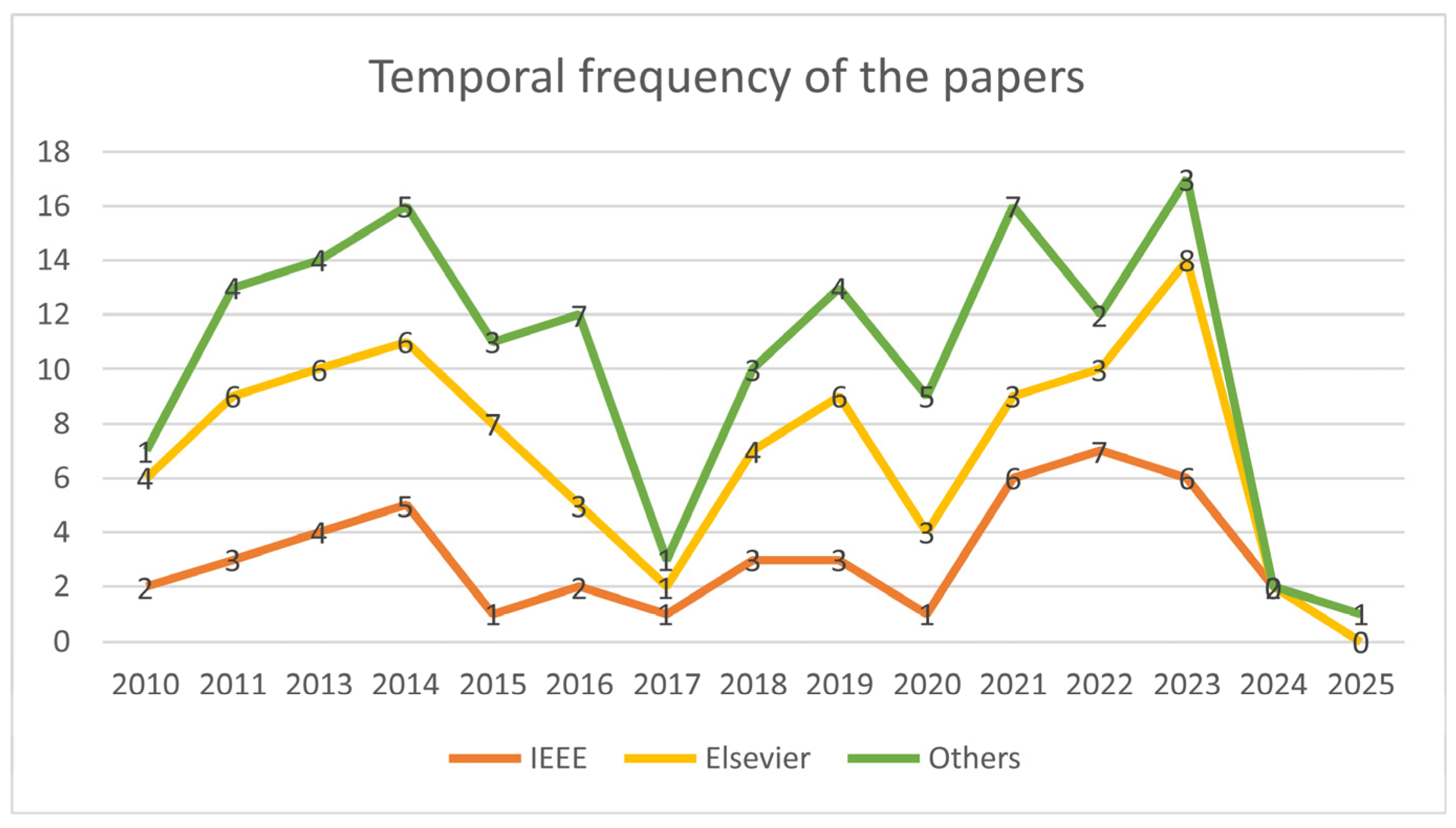
| 2 | Searched the databases to find relevant papers published during the past 10 years | Used the combinations of keywords: 1. Cloud autoscaling 2. Hybrid cloud autoscaling 3. Issues in cloud autoscaling 4. Autoscaling in IaaS 5. Proactive autoscaling | Based on the title and abstract, papers related to cloud autoscaling were selected and saved/downloaded to Zotero |
| 3 | Segregated papers further to filter out IaaS papers | Abstract, introduction, and conclusion sections of the papers were reviewed to identify how the papers could be organised into three cloud service models | Papers were organised into four separate folders in Zotero: 1. IaaS 2. PaaS 3. SaaS |
| 4 | Further reviewed and removed papers in IaaS and selected the most relevant papers | The contents of all papers were reviewed, selecting papers that address horizontal autoscaling only | 21 papers were selected for the survey. |
| Ref. | Autoscaling Technique | Key Methods | Key Features | Main Limitations | Use Cases |
|---|---|---|---|---|---|
| [61] | Threshold-based Rules | Uses one or more performance metrics like CPU load, average response time, or request rate to trigger the scaling action |
|
|
|
| [61,62] | Reinforcement Learning | MDP, Q-Learning, Parallel Learning, Neural Networks |
|
|
|
| [65] | Queuing Theory | Kendall’s Notation |
|
|
|
| [63,65] | Control theory | Open-loop, feedback, and feed forward controllers |
|
|
|
| [62] | Time series analysis | Time Series Regression, Exponential Smoothing, time series decomposition, ARIMA, RNN, LSTM |
|
|
|
| Cloud Platform | Control Theory | Queuing Theory | Threshold-Based | Time Series | Reinforcement Learning | Hybrid Cloud Support |
|---|---|---|---|---|---|---|
| AWS | ✓ | ✓ | ✓ | ✓ | × | × |
| GCP | ✓ | ✓ | ✓ | ✓ | × | × |
| Azure | ✓ | ✓ | ✓ | ✓ | × | × |
| Apache | ✓ | × | ✓ | × | × | × |
| Category | Specific Challenge | Consequences | Impact |
|---|---|---|---|
| Capacity Estimation/Load Prediction Errors | Over/Under-provisioned Resources | Increased Operational Costs or Compromised SLA | Financial and Performance Impact |
| Delay in Capacity Allocation | Compromised SLA | Negative Reputational/Financial Impact | Business Continuity Issues |
| Infrastructure Failures | Non-Resilient Services/Compromised SLA | Service Downtime and Reliability Issues | Operational Risk |
| Metric Collection/Alerting Failures | Autoscaling Decision Errors | Over/Under-provisioned Resources | Cost Inefficiency and SLA Violations |
| Platform Dependency | Vendor Locked Services | Licensing Monopoly/Single Point of Failure | Reduced Flexibility and Increased Costs |
| Predictive Autoscaling on Hybrid Clouds | Efficient Resource Allocation and SLA/Cost Management | Improved Workload Handling and Resource Optimisation | Positive Reputational/Financial Impact |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Betti Pillippuge, T.L.; Khan, Z.; Munir, K. Horizontal Autoscaling of Virtual Machines in Hybrid Cloud Infrastructures: Current Status, Challenges, and Opportunities. Encyclopedia 2025, 5, 37. https://doi.org/10.3390/encyclopedia5010037
Betti Pillippuge TL, Khan Z, Munir K. Horizontal Autoscaling of Virtual Machines in Hybrid Cloud Infrastructures: Current Status, Challenges, and Opportunities. Encyclopedia. 2025; 5(1):37. https://doi.org/10.3390/encyclopedia5010037
Chicago/Turabian StyleBetti Pillippuge, Thushantha Lakmal, Zaheer Khan, and Kamran Munir. 2025. "Horizontal Autoscaling of Virtual Machines in Hybrid Cloud Infrastructures: Current Status, Challenges, and Opportunities" Encyclopedia 5, no. 1: 37. https://doi.org/10.3390/encyclopedia5010037
APA StyleBetti Pillippuge, T. L., Khan, Z., & Munir, K. (2025). Horizontal Autoscaling of Virtual Machines in Hybrid Cloud Infrastructures: Current Status, Challenges, and Opportunities. Encyclopedia, 5(1), 37. https://doi.org/10.3390/encyclopedia5010037