
Metric Ensembles Aid in Explainability: A Case Study with Wikipedia Data


Abstract
1. Introduction
- 1.
- To what extent is the model’s particular selection of items from the corpus explicable to the user?
- 2.
- Are the metrics of similarity that the model optimizes for ones that are sufficiently close to the user’s preferences – in other words, how do we quantitatively specify, as closely as possible, a qualitative and subjective notion of “quality” in the eyes of the end user?
2. Related Work
2.1. Single Metrics Are a Problem
2.2. Ensembles Address This Problem
2.3. A Brief Literature Review of Neural Network Ensembles
2.4. Weak Supervision as an Extension of Metric Ensembles and Data Augmentation
2.5. Metrics for an Eventual Large-Scale Ensemble-Based Text Recommender System
3. Metric Ensembles Aid in Explainability: A Demonstration with Wikipedia Data
3.1. Recommending Wikipedia Articles: A Toy Example
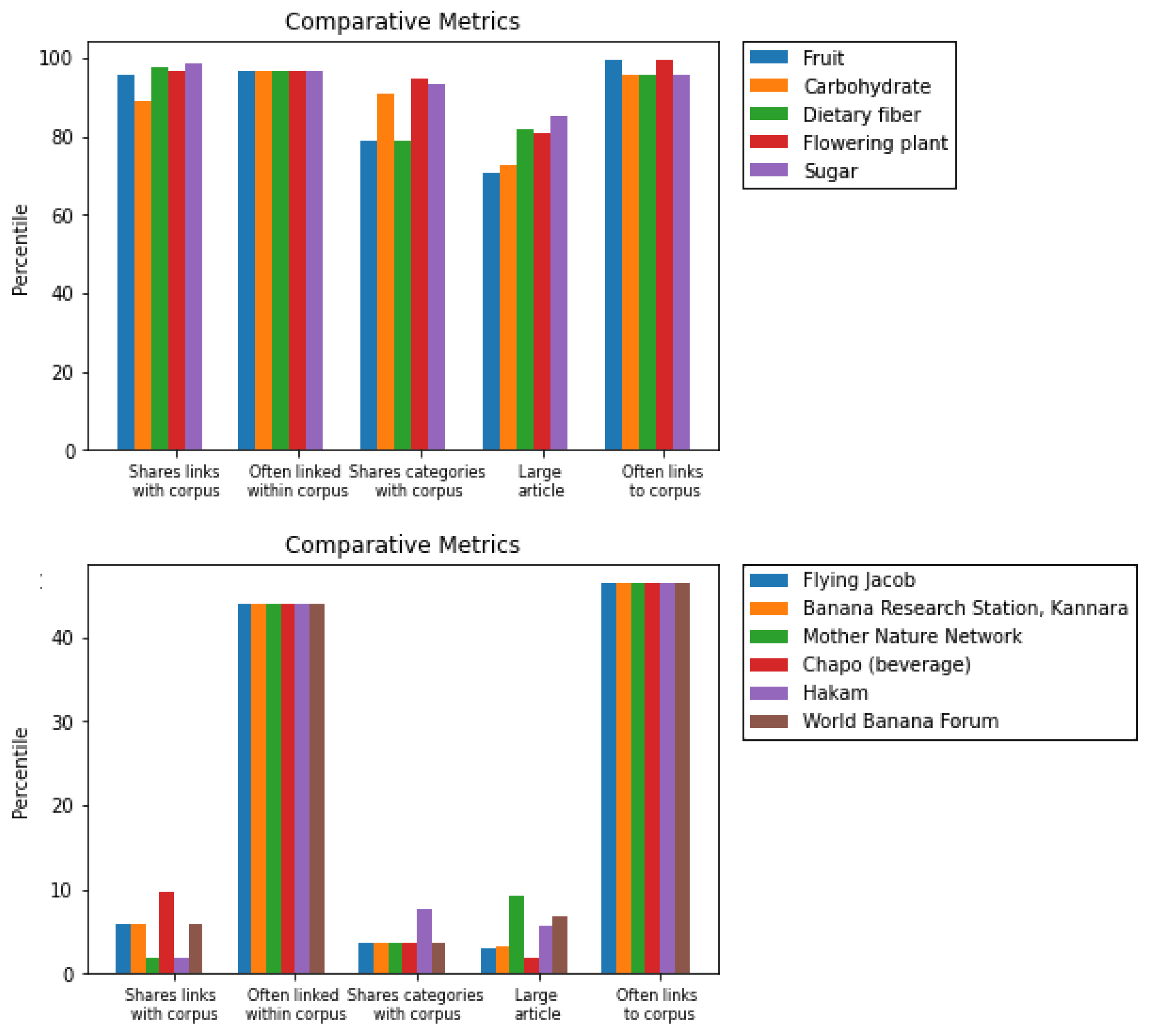
- Shared Links: this metric counts how many pages linked from the candidate are also linked in the corpus, and double-counts links that were linked by multiple items in the corpus.
- Links To Corpus: this metric counts how many pages within the corpus, if any, are linked to by the candidate.
- Linked From Corpus: aptly named, this metric counts how many pages in the corpus, if any, link to the candidate article.
- Shared Categories: this metric counts how many article categories (such as “Edible fruits”, “Staple foods”, or “Articles lacking reliable references from April 2022”) are shared between the candidate and pages in the corpus, double counting where appropriate.
- Large Article: this metric just counts the word length of the page content. Intuitively, this metric is assuming that larger articles are “more important”, and disincentivizes recommending stubs.
3.2. Further Extensions and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Thomas, R.L.; Uminsky, D. Reliance on metrics is a fundamental challenge for AI. Patterns 2022, 3, 100476. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.H.; Ottoni, R.; West, R.; Almeida, V.A.; Meira, W., Jr. Auditing radicalization pathways on YouTube. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 131–141. [Google Scholar]
- Hasan, M.R.; Jha, A.K.; Liu, Y. Excessive use of online video streaming services: Impact of recommender system use, psychological factors, and motives. Comput. Hum. Behav. 2018, 80, 220–228. [Google Scholar] [CrossRef]
- Seaver, N. Captivating algorithms: Recommender systems as traps. J. Mater. Cult. 2019, 24, 421–436. [Google Scholar] [CrossRef]
- Tversky, A.; Kahneman, D. The framing of decisions and the psychology of choice. In Behavioral Decision Making; Springer: Berlin/Heidelberg, Germany, 1985; pp. 25–41. [Google Scholar]
- Goodhart, C.A. Problems of monetary management: The UK experience. In Monetary Theory and Practice; Springer: Berlin/Heidelberg, Germany, 1984; pp. 91–121. [Google Scholar]
- Strathern, M. ‘Improving ratings’: Audit in the British University system. Eur. Rev. 1997, 5, 305–321. [Google Scholar] [CrossRef]
- Wu, F.; Qiao, Y.; Chen, J.H.; Wu, C.; Qi, T.; Lian, J.; Liu, D.; Xie, X.; Gao, J.; Wu, W.; et al. MIND: A Large-scale Dataset for News Recommendation. In Proceedings of the ACL 2020, Online, 6–8 July 2020. [Google Scholar]
- Manheim, D.; Garrabrant, S. Categorizing variants of Goodhart’s Law. arXiv 2018, arXiv:1803.04585. [Google Scholar]
- Zhuang, S.; Hadfield-Menell, D. Consequences of misaligned AI. Adv. Neural Inf. Process. Syst. 2020, 33, 15763–15773. [Google Scholar]
- Milli, S.; Belli, L.; Hardt, M. From optimizing engagement to measuring value. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual, 3–10 March 2021; pp. 714–722. [Google Scholar]
- Dawes, R.M. The robust beauty of improper linear models in decision making. Am. Psychol. 1979, 34, 571. [Google Scholar] [CrossRef]
- Buczak, A.L.; Grooters, B.; Kogut, P.; Manavoglu, E.; Giles, C.L. Recommender Systems for Intelligence Analysts. In Proceedings of the AAAI Spring Symposium: AI Technologies for Homeland Security, Stanford, CA, USA, 21–23 March 2005; pp. 25–31. [Google Scholar]
- Likierman, A. The five traps of performance measurement. Harv. Bus. Rev. 2009, 87, 96–101. [Google Scholar] [PubMed]
- Perrone, M.P.; Cooper, L.N. When Networks Disagree: Ensemble Methods for Hybrid Neural Networks; Technical Report; Brown Univ Providence Ri Inst for Brain and Neural Systems: Providence, RI, USA, 1992. [Google Scholar]
- Krogh, A.; Vedelsby, J. Neural network ensembles, cross validation, and active learning. Adv. Neural Inf. Process. Syst. 1994, 7, 231–238. [Google Scholar]
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep reinforcement learning from human preferences. Adv. Neural Inf. Process. Syst. 2017, 30, 4299–4307. [Google Scholar]
- Shahhosseini, M.; Hu, G.; Pham, H. Optimizing ensemble weights and hyperparameters of machine learning models for regression problems. Mach. Learn. Appl. 2022, 7, 100251. [Google Scholar] [CrossRef]
- Shen, Z.Q.; Kong, F.S. Dynamically weighted ensemble neural networks for regression problems. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 04EX826), Shanghai, China, 26–29 August 2004; IEEE: New York, NY, USA, 2004; Volume 6, pp. 3492–3496. [Google Scholar]
- Platanios, E.A.; Blum, A.; Mitchell, T.M. Estimating Accuracy from Unlabeled Data. In Proceedings of the UAI, Quebec City, QC, Canada, 23–27 July 2014; Volume 14, p. 10. [Google Scholar]
- Platanios, E.A.; Dubey, A.; Mitchell, T. Estimating accuracy from unlabeled data: A bayesian approach. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1416–1425. [Google Scholar]
- Platanios, E.; Poon, H.; Mitchell, T.M.; Horvitz, E.J. Estimating accuracy from unlabeled data: A probabilistic logic approach. Adv. Neural Inf. Process. Syst. 2017, 30, 4361–4370. [Google Scholar]
- Ratner, A.; Bach, S.H.; Ehrenberg, H.; Fries, J.; Wu, S.; Ré, C. Snorkel: Rapid training data creation with weak supervision. In Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases, Rio de Janeiro, Brazil, 27–31 August 2018; NIH Public Access: Bethesda, ML, USA, 2017; Volume 11, p. 269. [Google Scholar]
- Bach, S.H.; He, B.; Ratner, A.; Ré, C. Learning the structure of generative models without labeled data. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2017; pp. 273–282. [Google Scholar]
- Bekker, J.; Davis, J. Learning from positive and unlabeled data: A survey. Mach. Learn. 2020, 109, 719–760. [Google Scholar] [CrossRef]
- Raza, S.; Ding, C. News recommender system: A review of recent progress, challenges, and opportunities. Artif. Intell. Rev. 2022, 55, 749–800. [Google Scholar] [CrossRef] [PubMed]
- Kunaver, M.; Požrl, T. Diversity in recommender systems—A survey. Knowl.-Based Syst. 2017, 123, 154–162. [Google Scholar] [CrossRef]
- Bai, Y.; Jones, A.; Ndousse, K.; Askell, A.; Chen, A.; DasSarma, N.; Drain, D.; Fort, S.; Ganguli, D.; Henighan, T.; et al. Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv 2022, arXiv:2204.05862. [Google Scholar]
- Zhang, Y.; Chen, X. Explainable recommendation: A survey and new perspectives. In Foundations and Trends® in Information Retrieval; Now Publishers, Inc.: Delft, The Netherlands, 2020; Volume 14, pp. 1–101. [Google Scholar]
- Brown, E.T.; Liu, J.; Brodley, C.E.; Chang, R. Dis-function: Learning distance functions interactively. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; IEEE: New York, NY, USA, 2012; pp. 83–92. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Highest Scoring | Lowest Scoring |
|---|---|---|
| 1 | Sugar | Flying Jacob |
| 2 | Flowering Plant | Banana Research Station, Kannara |
| 3 | Dietary Fiber | Mother Nature Network |
| 4 | Carbohydrate | Chapo (beverage) |
| 5 | Fruit | Hakam |
| 6 | Maize | World Banana Forum |
| 7 | Soybean | Cayeye |
| 8 | Plant | Banana Custard |
| 9 | Fungus | Tacacho |
| 10 | Tomato | Bluggoe |
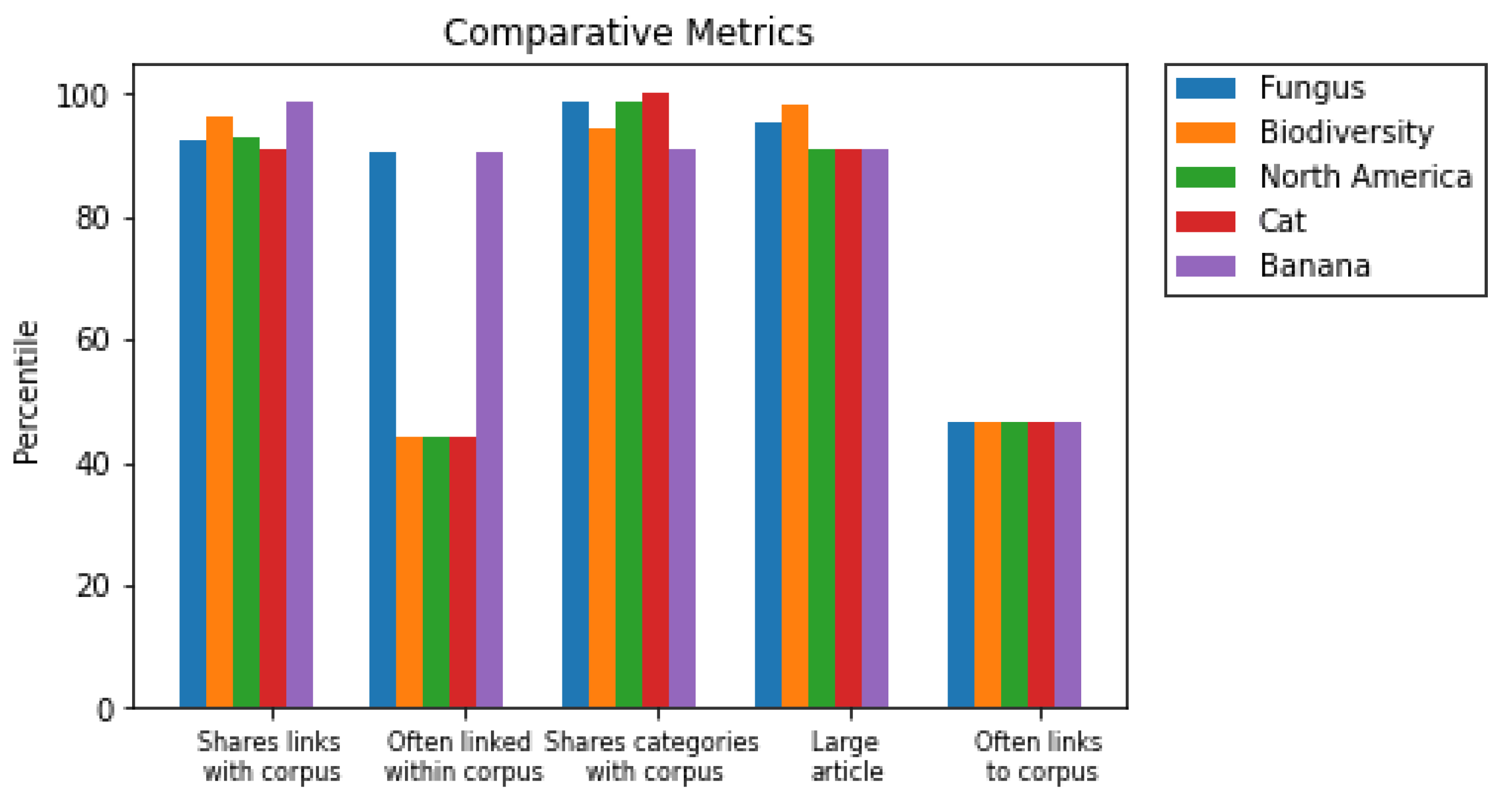
| Rank | Highest Scoring, 2nd Iteration |
|---|---|
| 1 | Coconut |
| 2 | Maize |
| 3 | Biodiversity |
| 4 | Plant |
| 5 | Soybean |
| 6 | Fungus |
| 7 | Tomato |
| 8 | North America |
| 9 | Cat |
| 10 | Banana |
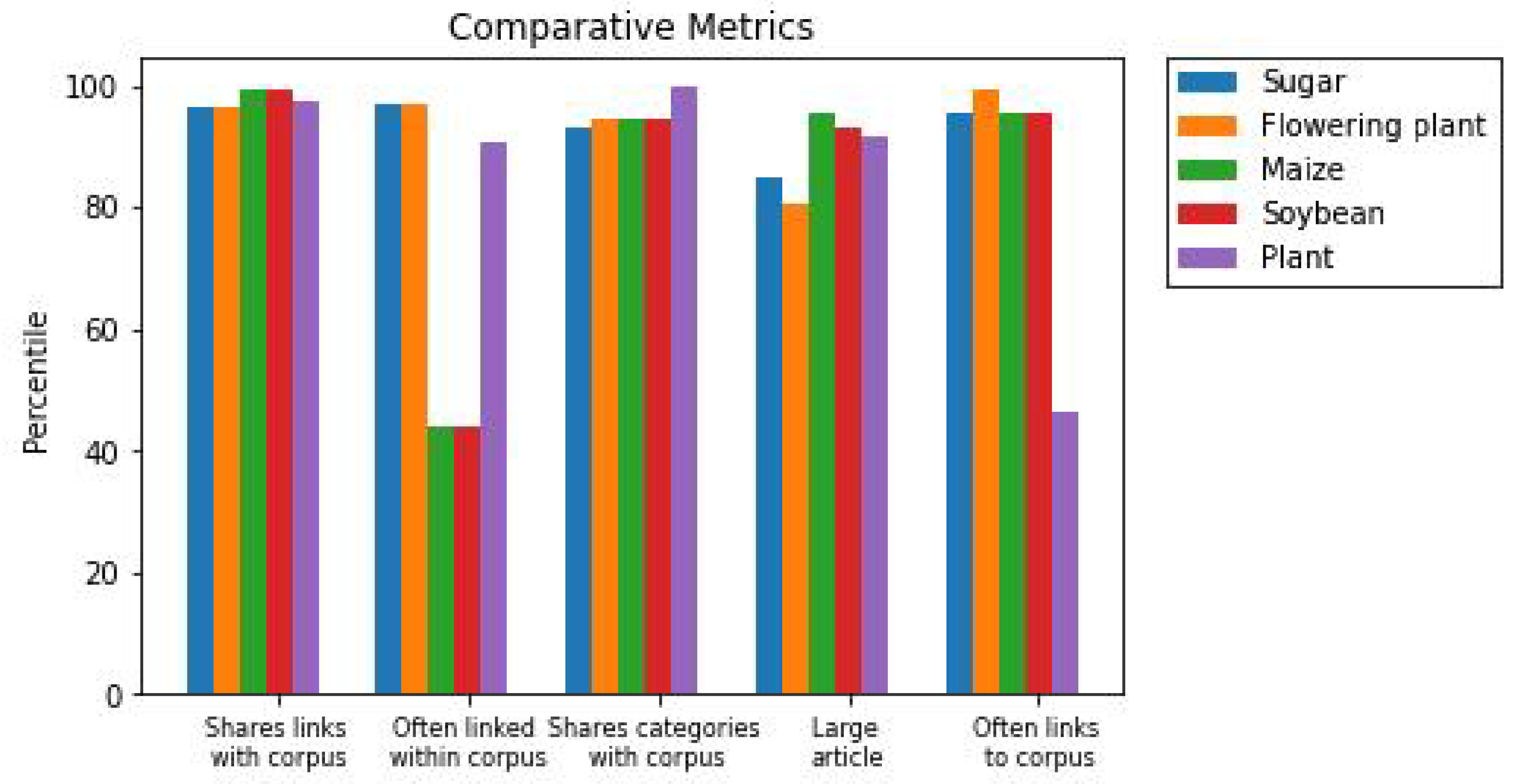
| Rank | 1st Iteration | 2nd Iteration | Final Iteration |
|---|---|---|---|
| 1 | Sugar | Coconut | Sugar |
| 2 | Flowering Plant | Maize | Flowering Plant |
| 3 | Dietary Fiber | Biodiversity | Maize |
| 4 | Carbohydrate | Plant | Soybean |
| 5 | Fruit | Soybean | Plant |
| 6 | Maize | Fungus | Tomato |
| 7 | Soybean | Tomato | Dietary Fiber |
| 8 | Plant | North America | Banana |
| 9 | Fungus | Cat | Fungus |
| 10 | Tomato | Banana | Fruit |
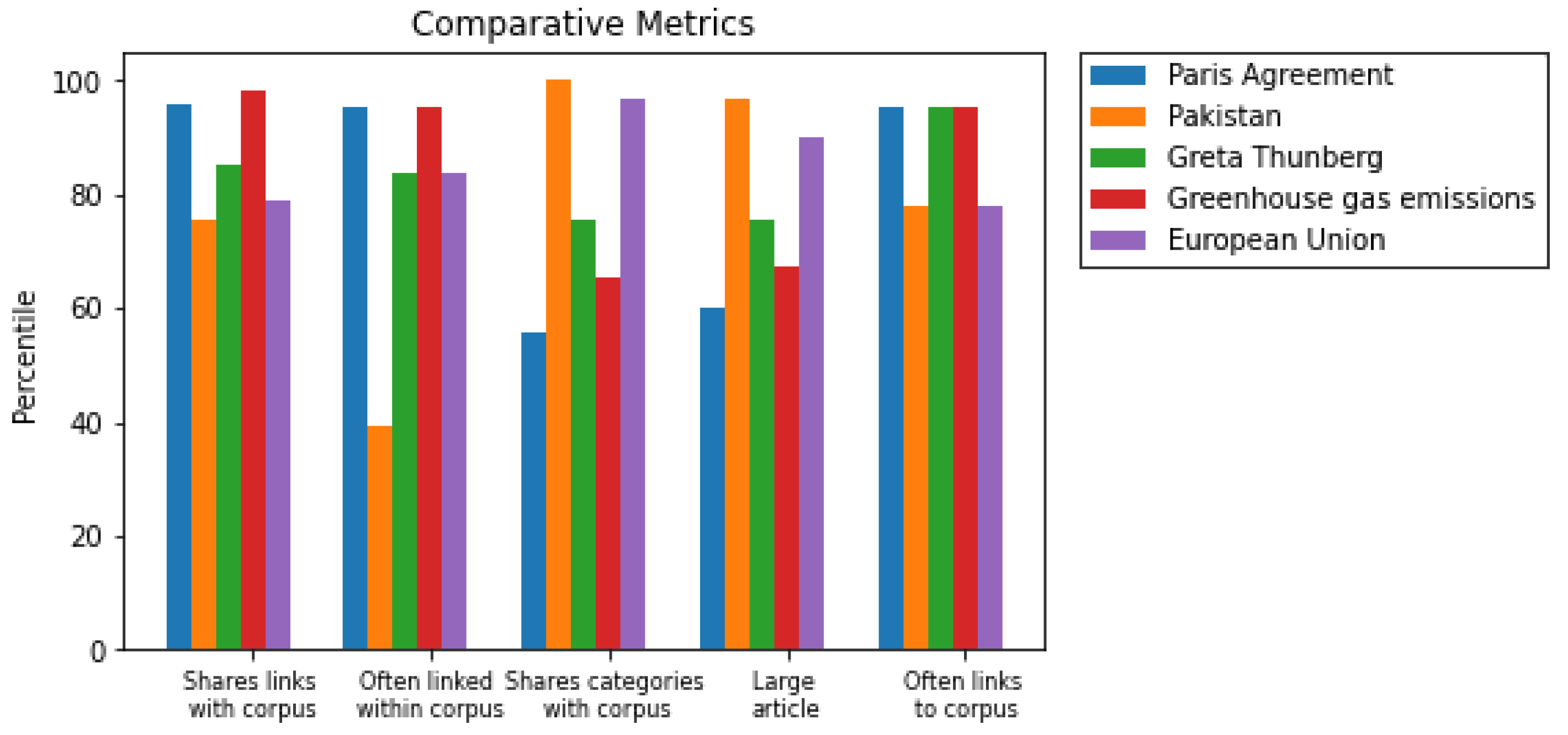
| Rank | Page |
|---|---|
| 1 | European Union |
| 2 | Greenhouse Gas Emissions |
| 3 | Greta Thunberg |
| 4 | Pakistan |
| 5 | Paris Agreement |
| 6 | Carbon Neutrality |
| 7 | Hungary |
| 8 | France |
| 9 | United States |
| 10 | Russia |
| Rank | Page |
|---|---|
| 1 | Biodiversity |
| 2 | Plant |
| 3 | Developing Country |
| 4 | Drought |
| 5 | Eutrophication |
| 6 | Agriculture |
| 7 | North America |
| 8 | London |
| 9 | Photosynthesis |
| 10 | Water Purification |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Forbes, G.; Crouser, R.J. Metric Ensembles Aid in Explainability: A Case Study with Wikipedia Data. Analytics 2023, 2, 315-327. https://doi.org/10.3390/analytics2020017
Forbes G, Crouser RJ. Metric Ensembles Aid in Explainability: A Case Study with Wikipedia Data. Analytics. 2023; 2(2):315-327. https://doi.org/10.3390/analytics2020017
Chicago/Turabian StyleForbes, Grant, and R. Jordan Crouser. 2023. "Metric Ensembles Aid in Explainability: A Case Study with Wikipedia Data" Analytics 2, no. 2: 315-327. https://doi.org/10.3390/analytics2020017
APA StyleForbes, G., & Crouser, R. J. (2023). Metric Ensembles Aid in Explainability: A Case Study with Wikipedia Data. Analytics, 2(2), 315-327. https://doi.org/10.3390/analytics2020017