
Analytics 2026, 5(2), 18; https://doi.org/10.3390/analytics5020018 - 4 May 2026
Abstract
►
Show Figures
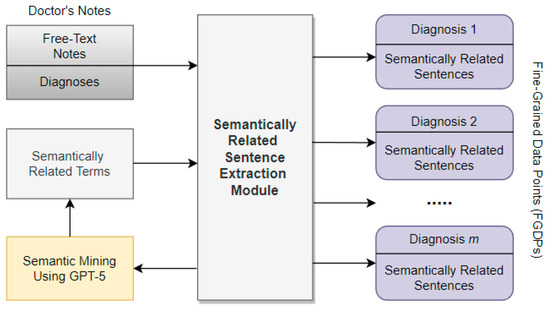
Narrative extraction builds coherent ordered sequences of documents that trace how concepts develop over time, and is a growing area of information retrieval. In this work we focus on scientific literature, using a corpus of 3549 IEEE visualization research papers (1990–2022). A natural
[...] Read more.
Narrative extraction builds coherent ordered sequences of documents that trace how concepts develop over time, and is a growing area of information retrieval. In this work we focus on scientific literature, using a corpus of 3549 IEEE visualization research papers (1990–2022). A natural hypothesis is that augmenting embedding-based pathfinding with explicit domain knowledge should improve narrative quality. We present the Knowledge-Coherence Framework (KCF), which integrates structured metadata from OpenAlex into narrative extraction (building on the Narrative Trails algorithm), and conduct a systematic empirical investigation along three axes: (1) the effect of embedding model choice (MiniLM vs. SPECTER), (2) the effect of knowledge augmentation (with and without, plus sensitivity to the knowledge weight

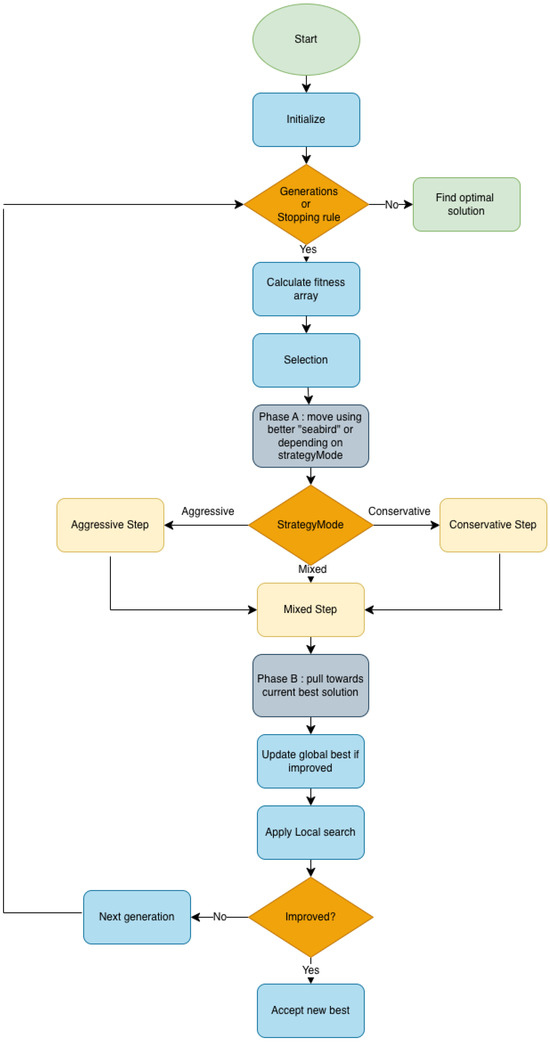
Figure 1


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}