Combining Multi-Scale Wavelet Entropy and Kernelized Classification for Bearing Multi-Fault Diagnosis


Abstract
:1. Introduction
2. Wavelet Analysis and Entropy Measures
2.1. Stationary Wavelet Packet Transform
2.2. Stationary Wavelet Packet Dispersion Entropy
- Step 1:
- The wavelet sub-band signal is normalized between 0 and 1 using the normal cumulative distribution function as follows:where and are the mean and standard deviation of the raw vibration signal of N data points.
- Step 2:
- The normalized signal is mapped into c classes with integer indices from 1 to c using the following equation:where denotes the rounding operation.
- Step 3:
- Create multiples m-dimensional vector as follows:
- Step 4:
- Each embedding vector is mapped into a dispersion pattern , where . Thus, the number of possible dispersion patterns is equal to .
- Step 5:
- Calculate the probability of occurrence for each permutation pattern as follows:where denotes the total of embedding vectors.
- Step 6:
2.3. Stationary Wavelet Packet Permutation Entropy
- Step 1:
- Create a set of m-dimensional vectors as follows:where m is the embedding dimension of the vector .
- Step 2:
- Each vector is sorted in ascending order with permutation pattern as follows:where each vector in m-dimensional space can be mapped to one of the ordinal patters .
- Step 3:
- Calculate the probability of occurrence for each permutation pattern as follows:where denotes the total of embedding vectors.
- Step 4:
2.4. Stationary Wavelet Packet Singular Value Entropy
3. Bearing Fault Diagnosis Algorithm
3.1. Proposed Diagnosis Algorithm
- Step 1:
- Divide the discrete time raw vibration signal into multiple non-overlapped signals of N data points.
- Step 2:
- Decompose the non-overlapping signals into sub-band signals by using SWPT given as Equations (1) and (2).
- Step 3:
- Create a D-dimensional features vector based on multi-scale wavelet Shannon entropy as follows:where represents one of the SWPDE/SWPPE/SWPSVE value of the i-th wavelet sub-band signal and k corresponds to the k-th non-overlapping raw vibration signal.
- Step 4:
- Normalize the features matrix Z as follows:where corresponds to the i-th column of the feature matrix Z, and denote the minimum value and maximum value of the vector, respectively.
- Step 5:
- Create the KELM classifier based on both the feature matrix Z and k-fold cross-validation method.
3.2. Kernel-ELM Classifier
3.3. Experimental Setup
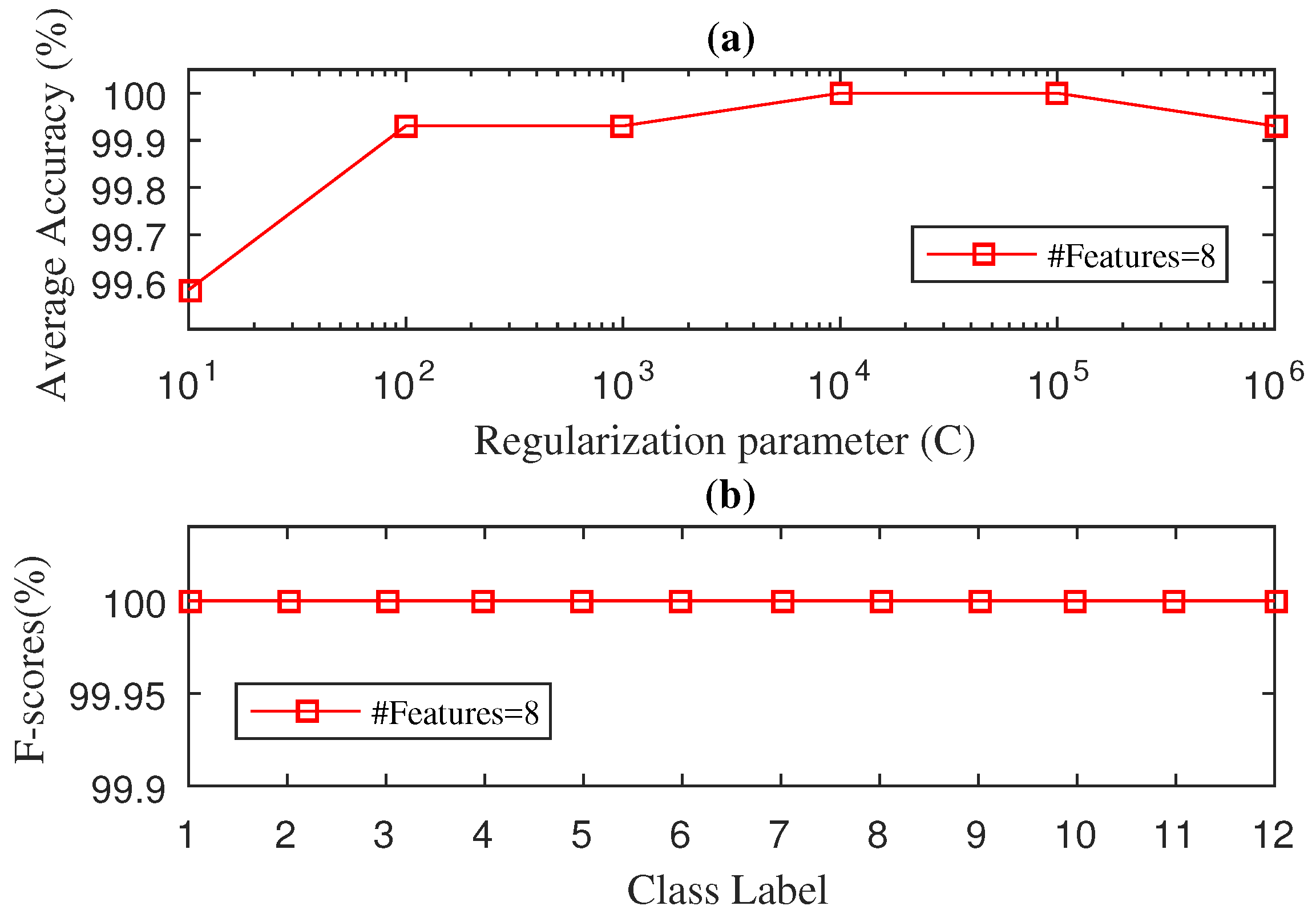
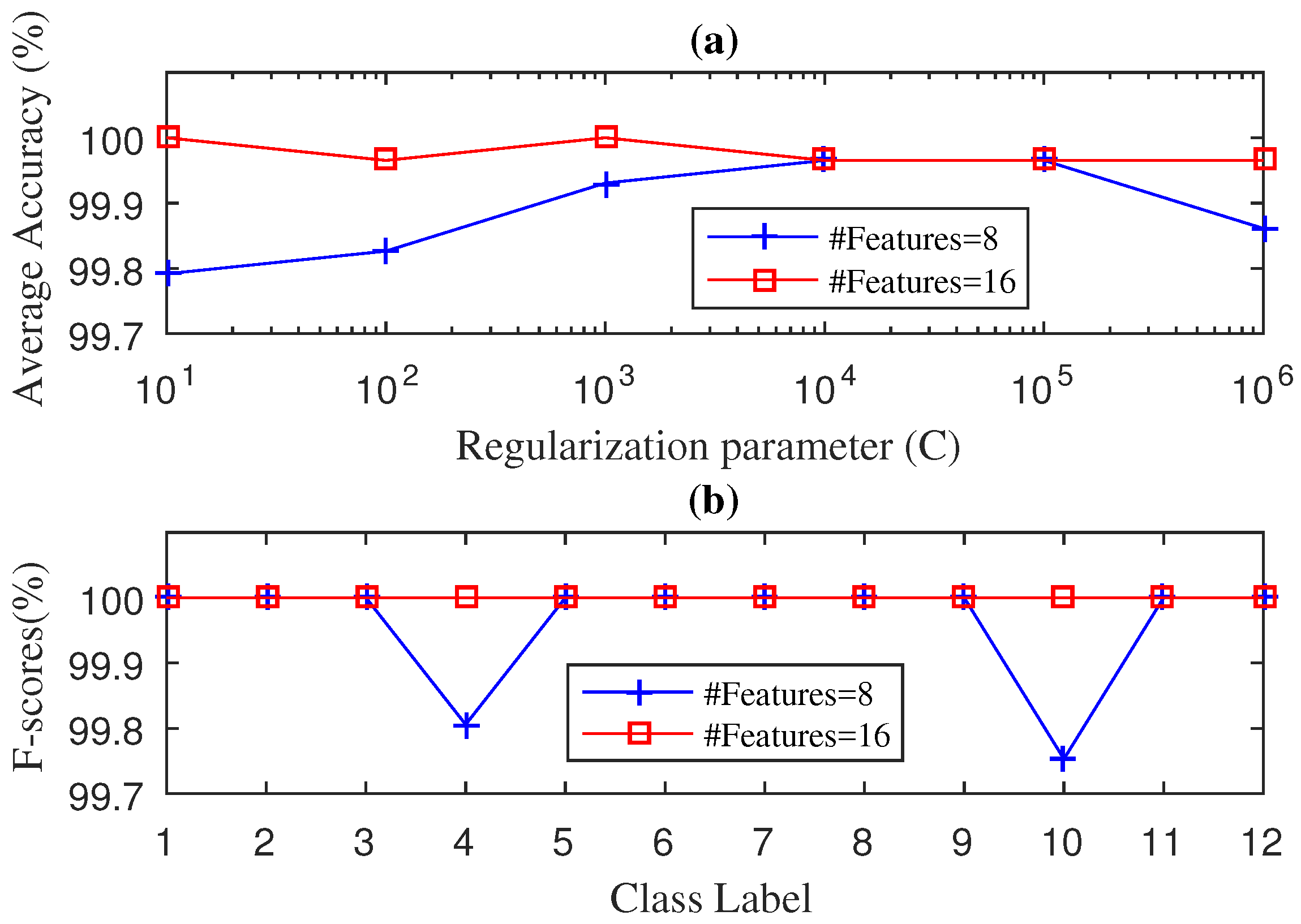
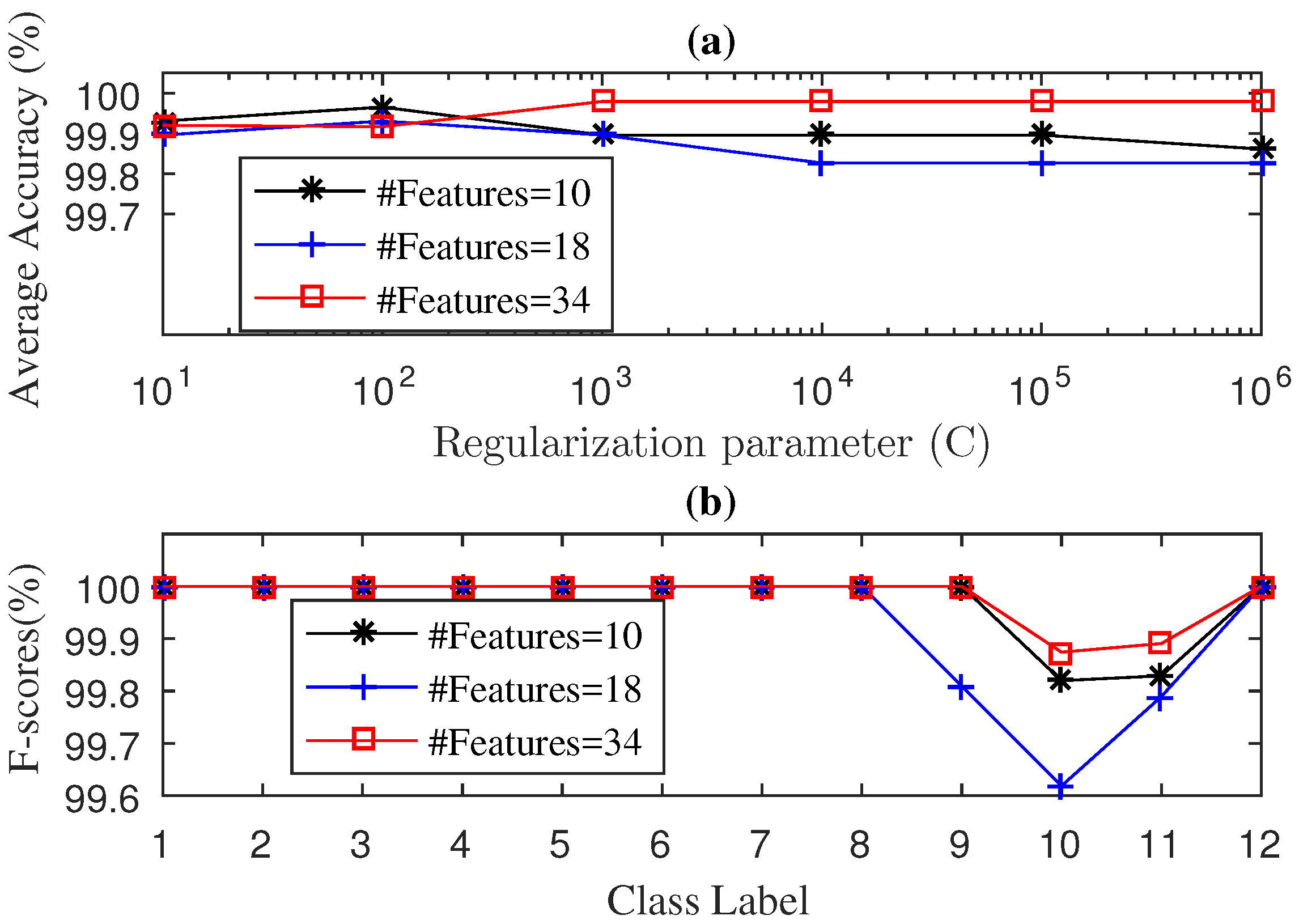
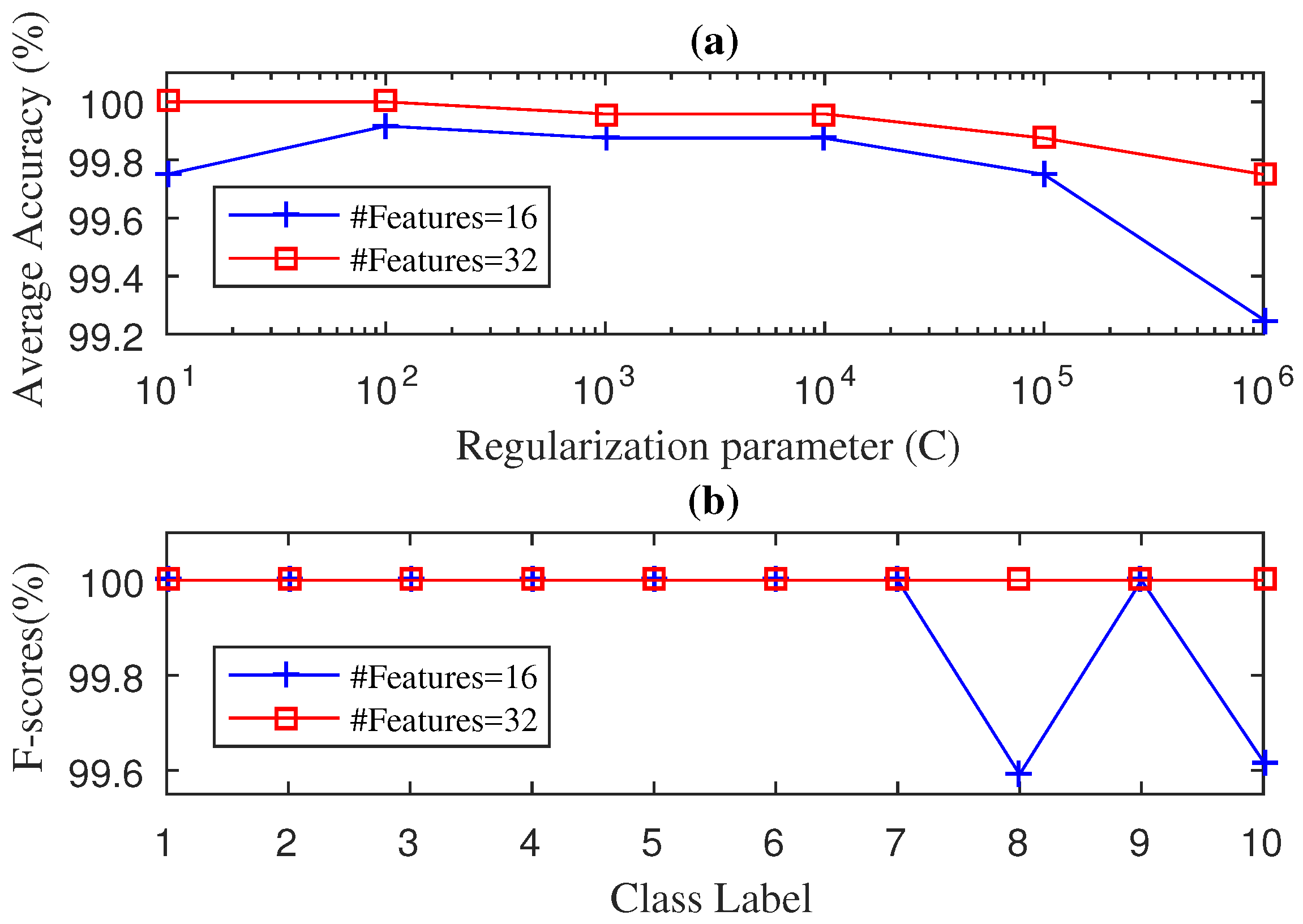
4. Experimental Results
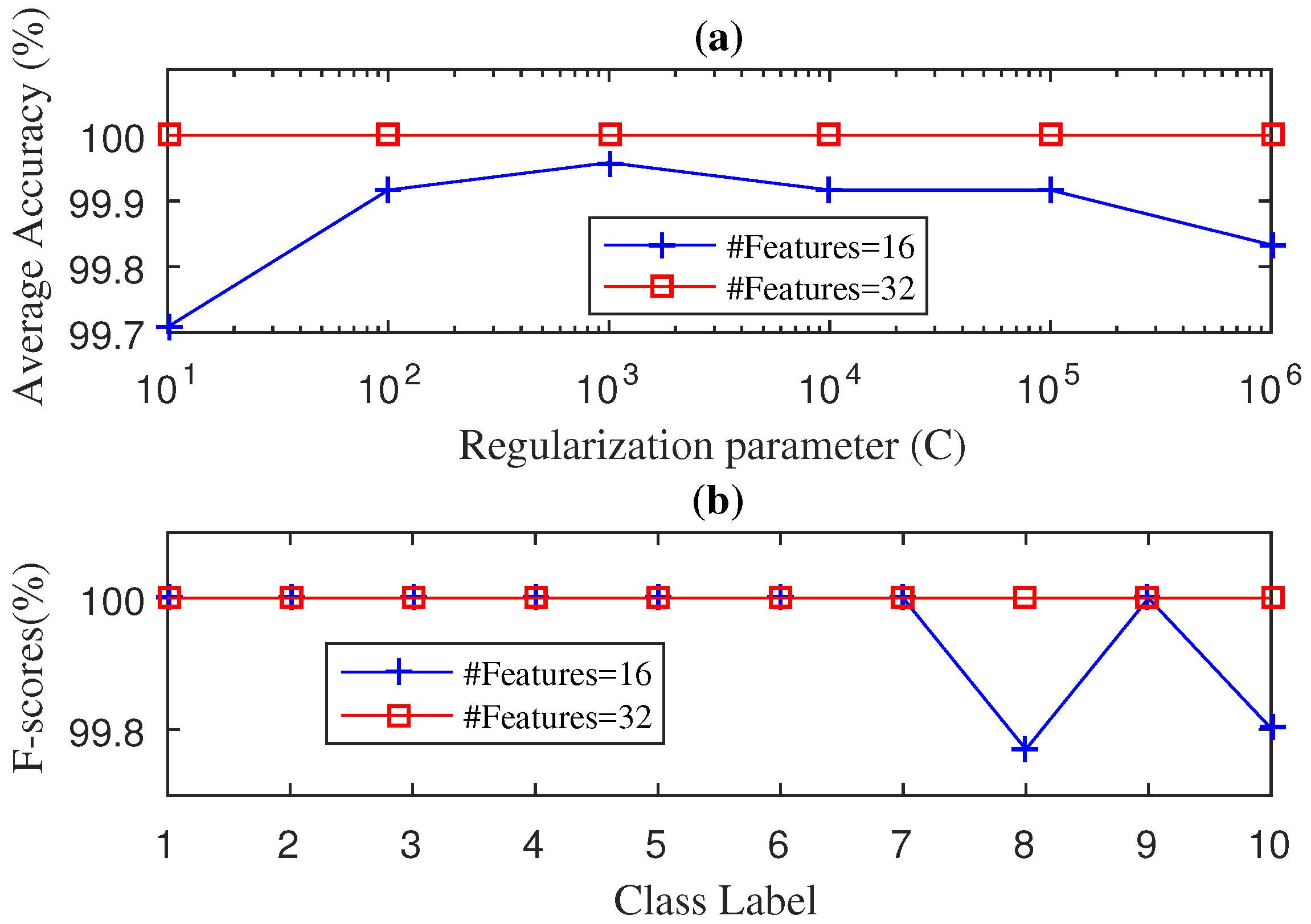
4.1. Case 1: Drive-End Bearing
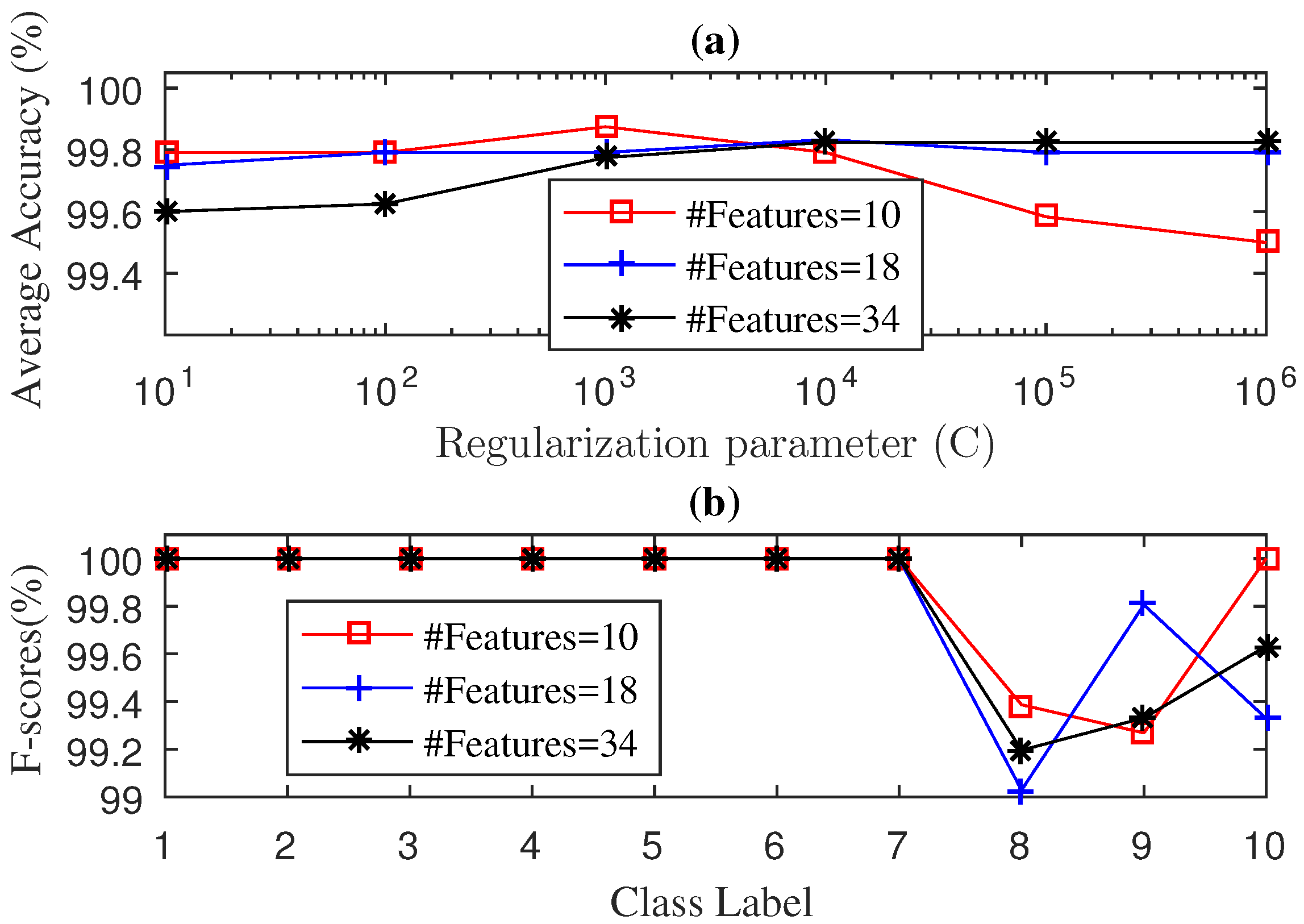
4.2. Case 2: Fan-End Bearing
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lei, Y.; Lin, J.; He, Z.; Zuo, M. A review on empirical mode decomposition in fault diagnosis of rotating machinery. Mech. Syst. Signal Process. 2013, 35, 108–126. [Google Scholar] [CrossRef]
- Smith, J.S. The local mean decomposition and its application to EEG perception data. J. R. Soc. Interface 2005, 2, 443–454. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Jian, M.; Chen, L.; Wang, Z. Rolling bearing fault diagnosis under variable conditions using LMD-SVD and extreme learning machine. Mech. Mach. Theory 2015, 90, 175–186. [Google Scholar] [CrossRef]
- Chen, J.; Li, Z.; Chen, G.; Zi, Y.; Yuan, J.; Chen, B.; He, Z. Wavelet transform based on inner product in fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2016, 70–71, 1–35. [Google Scholar] [CrossRef]
- Huang, N.E.; Zheng, S.; Long, S.; Wu, M.; Shih, H.; Zheng, Q.; Yen, N.; Tung, C.; Liu, H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Abbasion, S.; Rafsanjani, A.; Irani, A.F.A.; Rafsanjani, A. Rolling element bearings multi-fault classification based on the wavelet denoising and support vector machine. Mech. Syst. Signal Process. 2007, 21, 2933–2945. [Google Scholar] [CrossRef]
- Mishra, C.; Samantaray, A.; Chakraborty, G. Rolling element bearing fault diagnosis under slow speed operation using wavelet de-noising. Measurement 2017, 103, 77–86. [Google Scholar] [CrossRef]
- Purushotham, V.; Narayanan, S.; Suryanarayana, S.; Prasad, A.N. Multi-fault diagnosis of rolling bearing elements using wavelet analysis and hidden Markov model based fault recognition. NDT E Int. 2005, 38, 654–664. [Google Scholar] [CrossRef]
- Su, W.; Wang, F.; Zhu, H.; Zhang, Z.; Guo, Z. Rolling element bearing faults diagnosis based on optimal Morlet wavelet filter and autocorrelation enhancement. Mech. Syst. Signal Process. 2010, 41, 127–140. [Google Scholar] [CrossRef]
- Villecco, F.; Pellegrino, A. Entropic Measure of Epistemic Uncertainties in Multibody System Models by Axiomatic Design. Entropy 2017, 19, 291. [Google Scholar] [CrossRef]
- Villecco, F.; Pellegrino, A. Evaluation of Uncertainties in the Design Process of Complex Mechanical Systems. Entropy 2017, 19, 475. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, J. Multi-fault diagnosis for rolling element bearings based on ensemble empirical mode decomposition and optimized support vector machines. Mech. Syst. Signal Process. 2013, 41, 127–140. [Google Scholar] [CrossRef]
- Gligorijevic, J.; Gajic, D.; Brkovic, A.; Savic-Gajic, I.; Georgieva, O.; Di Gennaro, S. Online Condition Monitoring of Bearings to Support Total Productive Maintenance in the Packaging Materials Industry. Sensors 2016, 16, 316. [Google Scholar] [CrossRef]
- Brkovic, A.; Gajic, D.; Gligorijevic, J.; Savic-Gajic, I.; Georgieva, O.; Gennaro, S.D. Early fault detection and diagnosis in bearings for more efficient operation of rotating machinery. Energy 2017, 136, 63–71. [Google Scholar] [CrossRef]
- Han, M.; Pan, J. A fault diagnosis method combined with LMD, sample entropy and energy ratio for roller bearings. Measurement 2015, 76, 7–19. [Google Scholar] [CrossRef]
- Liu, H.; Han, M. A fault diagnosis method based on local mean decomposition and multi-scale entropy for roller bearings. Mech. Mach. Theory 2014, 75, 67–78. [Google Scholar] [CrossRef]
- Gao, Q.; Liu, W.; Tang, B.; Li, G. A novel wind turbine fault diagnosis method based on intergral extension load mean decomposition multiscale entropy and least squares support vector machine. Renew. Energy 2018, 116, 169–175. [Google Scholar] [CrossRef]
- Zhang, X.; Liang, Y.; Zhou, J.; Zang, Y. A novel bearing fault diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized SVM. Measurement 2015, 69, 164–179. [Google Scholar] [CrossRef]
- Yi, C.; Lv, Y.; Ge, M.; Xiao, H.; Yu, X. Tensor Singular Spectrum Decomposition Algorithm Based on Permutation Entropy for Rolling Bearing Fault Diagnosis. Entropy 2017, 19, 139. [Google Scholar] [CrossRef]
- Gao, Y.; Villecco, F.; Li, M.; Song, W. Multi-Scale Permutation Entropy Based on Improved LMD and HMM for Rolling Bearing Diagnosis. Entropy 2017, 19, 176. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Z.; Lu, C. Self-adaptive bearing fault diagnosis based on permutation entropy and manifold-based dynamic time warping. Mech. Syst. Signal Process. 2019, 114, 658–673. [Google Scholar] [CrossRef]
- Zhao, L.Y.; Wang, L.; Yan, R.Q. Rolling Bearing Fault Diagnosis Based on Wavelet Packet Decomposition and Multi-Scale Permutation Entropy. Entropy 2015, 17, 6447–6461. [Google Scholar] [CrossRef]
- Yasir, M.N.; Koh, B.H. Data Decomposition Techniques with Multi-Scale Permutation Entropy Calculations for Bearing Fault Diagnosis. Sensors 2018, 18, 1278. [Google Scholar] [CrossRef] [PubMed]
- Zheng, J.; Pan, H.; Yang, S.; Cheng, J. Generalized composite multiscale permutation entropy and Laplacian score based rolling bearing fault diagnosis. Mech. Syst. Signal Process. 2018, 99, 229–243. [Google Scholar] [CrossRef]
- Zheng, J.; Cheng, J.; Yang, Y.; Luo, S. A rolling bearing fault diagnosis method based on multi-scale fuzzy entropy and variable predictive model-based class discrimination. Mech. Mach. Theory 2014, 78, 187–200. [Google Scholar] [CrossRef]
- Zheng, J.; Pan, H.; Cheng, J. Rolling bearing fault detection and diagnosis based on composite multiscale fuzzy entropy and ensemble support vector machines. Mech. Syst. Signal Process. 2017, 85, 746–759. [Google Scholar] [CrossRef]
- Rostaghi, M.; Ashory, M.R.; Azami, H. Application of dispersion entropy to status characterization of rotary machines. J. Sound Vib. 2019, 438, 291–308. [Google Scholar] [CrossRef]
- Zhang, Y.; Tong, S.; Cong, F.; Xu, J. Research of Feature Extraction Method Based on Sparse Reconstruction and Multiscale Dispersion Entropy. Appl. Sci. 2018, 8, 888. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. Intelligent fault diagnosis of rotating machinery using improved multiscale dispersion entropy and mRMR feature selection. Knowl.-Based Syst. 2019, 163, 450–471. [Google Scholar] [CrossRef]
- Lei, Y.; He, Z.; Zi, Y. EEMD method and WNN for fault diagnosis of locomotive roller bearings. Expert Syst. Appl. 2011, 38, 7334–7341. [Google Scholar] [CrossRef]
- Yang, Y.; Dejie, Y.; Junsheng, C. A roller bearing fault diagnosis method based on EMD energy entropy and ANN. J. Sound Vib. 2006, 294, 269–277. [Google Scholar]
- Luo, M.; Li, C.; Zhang, X.; Li, R.; An, X. Compound feature selection and parameter optimization of ELM for fault diagnosis of rolling element bearings. ISA Trans. 2016, 65, 556–566. [Google Scholar] [CrossRef] [PubMed]
- Chen, F.; Tang, B.; Chen, R. A novel fault diagnosis model for gearbox based on wavelet support vector machine with immune genetic algorithm. Measurement 2013, 46, 220–232. [Google Scholar] [CrossRef]
- Yang, Y.; Yu, D.; Cheng, J. A fault diagnosis approach for roller bearing based on IMF envelope spectrum and SVM. Measurement 2007, 40, 943–950. [Google Scholar] [CrossRef]
- Li, Y.; Xu, M.; Wang, R.; Huang, W. A fault diagnosis scheme for rolling bearing based on local mean decomposition and improved multiscale fuzzy entropy. J. Sound Vib. 2016, 360, 277–299. [Google Scholar] [CrossRef]
- Huang, G.B. Universal Approximation Using Incremental Constructive Feedforward Networks with Random Hidden Nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Zhang, R.; Lan, Y.; Huang, G.; Xu, Z. Universal approximation of extreme learning machine with adaptive growth of hidden nodes. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 365–371. [Google Scholar] [CrossRef]
- Rodriguez, N.; Lagos, C.; Cabrera, E.; Canete, L. Extreme learning machine based on stationary wavelet singular values for bearing failure diagnosis. Stud. Inf. Control 2017, 26, 287–294. [Google Scholar] [CrossRef]
- Rodriguez, N.; Cabrera, G.; Lagos, C.; Cabrera, E. Stationary Wavelet Singular Entropy and Kernel Extreme Learning for Bearing Multi-Fault Diagnosis. Entropy 2017, 19, 541. [Google Scholar] [CrossRef]
- Coifman, R.; Donoho, D. Translation-invariant de-noising. Wavelets Stat. Lect. Notes Stat. 1995, 102, 125–150. [Google Scholar]
- Nason, G.; Silverman, B. The stationary wavelet transform and some statistical applications. Wavelets Stat. Lect. Notes Stat. 1995, 103, 281–300. [Google Scholar]
- Pesquet, J.C.; Krim, H.; Carfantan, H. Time-invariant orthonormal wavelet representations. IEEE Trans. Signal Process. 1996, 44, 1964–1970. [Google Scholar] [CrossRef]
- Daubechies, I. Ten Lectures on Wavelet; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1992. [Google Scholar]
- Mallat, S. A Wavelet Tour of Signal Processing; Academic Press: San Diego, CA, USA, 1999. [Google Scholar]
- Bearing Data Center. Case Western Reserve University Technical Report. , 2017. Available online: https://csegroups.case.edu/bearingdatacenter/home (accessed on 11 October 2017).
- Lou, X.; Loparo, K.A. Bearing fault diagnosis based on wavelet transform and fuzzy inference. Mech. Syst. Signal Process. 2004, 18, 1077–1095. [Google Scholar] [CrossRef]
- Rostaghi, M.; Azami, H. Dispersion Entropy: A Measure for Time-Series Analysis. IEEE Signal Process. Lett. 2016, 23, 610–614. [Google Scholar] [CrossRef]
- Azami, H.; Rostaghi, M.; Abásolo, D.; Escudero, J. Refined Composite Multiscale Dispersion Entropy and Its Application to Biomedical Signals. IEEE Trans. Biomed. Eng. 2017, 64, 2872–2879. [Google Scholar]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Klema, V.C.; Laub, A.J. The singular value decomposition: Its computation and some applications. IEEE Trans. Autom. Control 1980, 25, 164–176. [Google Scholar] [CrossRef]
- Huang, G.; Chen, L. Convex incremental extreme learning machine. Neurocomputing 2007, 70, 3056–3062. [Google Scholar] [CrossRef]
- Serre, D. Matrices: Theory and Applications; Springer: New York, NY, USA, 2002. [Google Scholar]
- Stone, M. Cross-Validatory Choice and Assessment of Statistical Predictions. J. R. Stat. Soc. Ser. B (Methodol.) 1974, 36, 111–142. [Google Scholar] [CrossRef]
- Geisser, S. The predictive sample reuse method with applications. J. Am. Stat. Assoc. 1975, 70, 320–328. [Google Scholar] [CrossRef]
- Sun, P.; Liao, Y.; Lin, J. The Shock Pulse Index and Its Application in the Fault Diagnosis of Rolling Element Bearings. Sensors 2017, 17, 535. [Google Scholar] [CrossRef] [PubMed]
- Ferri, C.; Hernández-Orallo, J.; Modroiu, R. An experimental comparison of performance measures for classification. Pattern Recognit. Lett. 2009, 30, 27–38. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Li, Y.; Xu, M.; Wei, Y.; Huang, W. A new rolling bearing fault diagnosis method based on multiscale permutation entropy and improved support vector machine based binary tree. Measurement 2016, 77, 80–94. [Google Scholar] [CrossRef]
- Zheng, J.; Cheng, J.; Yang, Y. A rolling bearing fault diagnosis approach based on LCD and fuzzy entropy. Mech. Mach. Theory 2013, 70, 441–453. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M.; Zhao, Z. A novel intelligent detection method for rolling bearing based on IVMD and instantaneous energy distribution-permutation entropy. Measurement 2018, 130, 435–447. [Google Scholar] [CrossRef]
- Mao, W.; He, J.; Li, Y.; Yan, Y. Bearing fault diagnosis with auto-encoder extreme learning machine: A comparative study. Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2017, 231, 1560–1578. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 2018, 313, 47–64. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Types | Speed (r/min) | Load (hp) | Fault Diameter (mils) | Samples Numbers | Class Label | Class Label |
|---|---|---|---|---|---|---|
| NB | 1797–1730 | 0–3 | 0 | 240 | 1 | 1 |
| ORF | 1797–1730 | 0–3 | 7 | 240 | 2 | 2 |
| 14 | 240 | 3 | 3 | |||
| 21 | 240 | 4 | 4 | |||
| IRF | 1797–1730 | 0–3 | 7 | 240 | 5 | 5 |
| 14 | 240 | 6 | 6 | |||
| 21 | 240 | 7 | 7 | |||
| 28 | 240 | 8 | – | |||
| BF | 1797–1730 | 0–3 | 7 | 240 | 9 | 8 |
| 14 | 240 | 10 | 9 | |||
| 21 | 240 | 11 | 10 | |||
| 28 | 240 | 12 | – |
| Method | Embedding (m) | Classes (c) | Avg. Accuracy |
|---|---|---|---|
| 3-level SWPDE | 2 | 5 | 100 |
| 6 | 100 | ||
| 7 | 100 | ||
| 8 | 100 | ||
| 4-level SWPPE | 4 | —— | 99.97 |
| 5 | 99.97 | ||
| 6 | 100 | ||
| 7 | 100 |
| Method | Embedding (m) | Clases (c) | Avg. Accuracy |
|---|---|---|---|
| 3-level SWPDE | 2 | 5 | 100 |
| 6 | 100 | ||
| 7 | 100 | ||
| 8 | 100 | ||
| 4-level SWPPE | 4 | —— | 99.93 |
| 5 | 99.97 | ||
| 6 | 100 | ||
| 7 | 100 |
| Reference | Feature Extraction | Classification Method | Classes Number | Average Accuracy (%) |
|---|---|---|---|---|
| Brkovic et al. [14] | Wavelet energy entropy | Quadratic Classifier | 4 | 100 |
| Li et al. [59] | MPE from LMD | SVM with Binary Tree | 4 | 100 |
| Zheng et al. [60] | FE from LCD | ANFIS | 7 | 100 |
| Yan et al. [61] | IED-PE from IVMD | KNN | 8 | 98.38 |
| [40] | Singular entropy from stationary wavelet | KELM | 10 | 100 |
| Mao et al. [62] | Fourier amplitude | Deep-ELM | 10 | 100 |
| Yan and Jia [63] | Multi-domain features with Laplace score | SVM with PSO | 12 | 100 |
| This work | DE and PE from stationary wavelet | KELM | 12 | 100 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez, N.; Alvarez, P.; Barba, L.; Cabrera-Guerrero, G. Combining Multi-Scale Wavelet Entropy and Kernelized Classification for Bearing Multi-Fault Diagnosis. Entropy 2019, 21, 152. https://doi.org/10.3390/e21020152
Rodriguez N, Alvarez P, Barba L, Cabrera-Guerrero G. Combining Multi-Scale Wavelet Entropy and Kernelized Classification for Bearing Multi-Fault Diagnosis. Entropy. 2019; 21(2):152. https://doi.org/10.3390/e21020152
Chicago/Turabian StyleRodriguez, Nibaldo, Pablo Alvarez, Lida Barba, and Guillermo Cabrera-Guerrero. 2019. "Combining Multi-Scale Wavelet Entropy and Kernelized Classification for Bearing Multi-Fault Diagnosis" Entropy 21, no. 2: 152. https://doi.org/10.3390/e21020152
APA StyleRodriguez, N., Alvarez, P., Barba, L., & Cabrera-Guerrero, G. (2019). Combining Multi-Scale Wavelet Entropy and Kernelized Classification for Bearing Multi-Fault Diagnosis. Entropy, 21(2), 152. https://doi.org/10.3390/e21020152